协整检验及误差修正模型定稿版
- 格式:docx
- 大小:111.04 KB
- 文档页数:5

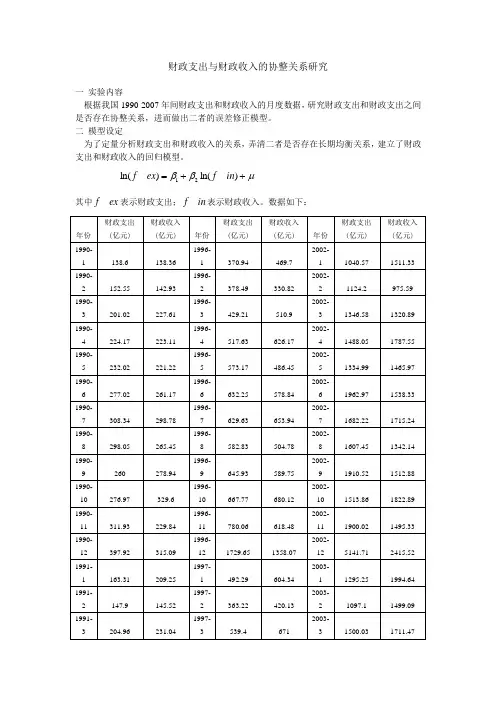
财政支出与财政收入的协整关系研究一 实验内容根据我国1990-2007年间财政支出和财政收入的月度数据,研究财政支出和财政支出之间是否存在协整关系,进而做出二者的误差修正模型。
二 模型设定为了定量分析财政支出和财政收入的关系,弄清二者是否存在长期均衡关系,建立了财政支出和财政收入的回归模型。
μββ++=)_ln()_ln(21in f ex f其中ex f _表示财政支出;in f _表示财政收入。
数据如下:数据来源:统计年鉴三、实证分析 1、数据处理由数据结构可以看出,数据存在季节波动。
首先利用X-12季节调整方法对这两个指标进行季节调整,消除季节因素,然后去对数。
2、单位根检验经济时间序列数据往往出现非平稳的情况,如果直接对数据建立回归模型,可能会出现伪回归的现象,因此在做回归之前,运用ADF 方法,对数据进行单位根检验。
对ln(ex f _)、ln(in f _)及其一阶差分进行单位根检验,具体检验结果如下所示:ln(ex f _)原值单位根检验Null Hypothesis: LNF_EX has a unit rootExogenous: ConstantLag Length: 5 (Automatic based on SIC, MAXLAG=14)t-StatisticProb.*Augmented Dickey-Fuller test statistic 0.519686 0.9871 Test critical values: 1% level -3.4614785% level -2.87512810% level -2.574090*MacKinnon (1996) one-sided p-values.f_)一阶差分单位根检验ln(exNull Hypothesis: D(LNF_EX) has a unit rootExogenous: ConstantLag Length: 4 (Automatic based on SIC, MAXLAG=14)t-Statistic Prob.* Augmented Dickey-Fuller test statistic -10.83446 0.0000 Test critical values: 1% level -3.4614785% level -2.87512810% level -2.574090*MacKinnon (1996) one-sided p-values.f_)原值单位根检验ln(inNull Hypothesis: LNF_IN has a unit rootExogenous: ConstantLag Length: 11 (Automatic based on SIC, MAXLAG=14)t-Statistic Prob.* Augmented Dickey-Fuller test statistic 0.763850 0.9932 Test critical values: 1% level -3.4624125% level -2.87553810% level -2.574309*MacKinnon (1996) one-sided p-values.f_)一阶差分单位根检验ln(inNull Hypothesis: D(LNF_IN) has a unit rootExogenous: ConstantLag Length: 10 (Automatic based on SIC, MAXLAG=14)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -8.161494 0.0000Test critical values:1% level -3.462412 5% level -2.87553810% level-2.574309*MacKinnon (1996) one-sided p-values.汇总检验结果如下表所示:财政收入和财政支出的对数的原值和一阶差分的单位根检验结果指标 ADF 值P 值ln(ex f _) 0.519686 0.9871 ln(ex f _)的一阶差分-10.83446 0.0000 ln(in f _) 0.763850 0.9932 ln(in f _)的一阶差分 -8.1614940.0000从上表中的ADF 值和P 值可以看出:当显著性水平为0.05时,对ln(ex f _)和ln(in f _)的原值进行检验时,检验结果都表明不能拒绝“存在单位根”的原假设;而当对ln(ex f _)和ln(in f _)的一阶差分进行检验时,检验结果都表明拒绝“存在单位根”的原假设。

协整与误差修正模型第六讲协整与误差修正模型一、非平稳过程与单位根检验二、长期均衡关系与协整三、误差修正模型一、非平稳过程与单位根检验1、非平稳过程1)随机游走过程(random walk)。
y t = y t-1 + u t, u t~ IID(0, σ2)10y=y(-1)+u5-5-10204060140160差分平稳过程(difference- stationary process)。
2)有漂移项的非平稳过程(non-stationary process with drift )或随机趋势非平稳过程(stochastic trend process )。
y t = μ + y t -1 + u t , u t ~ IID(0, σ2)迭代变换:y t = μ + (μ + y t -2 + u t -1) + u t = … = y 0 + μ t +∑-t i i u 1= μ t +∑-ti i u 120406080100-80-60-40-2020差分平稳过程3)趋势平稳过程(trend-stationary process)或退势平稳过程。
y t = μ+ α t + u t, u t~ IID(0, σ2)2520151055101520253035404550趋势平稳过程的差分过程是过度差分过程:?y t = α + u t - u t-1。
所以应该用退势的方法获得平稳过程。
y t - α t = μ+ u t。
4)确定性趋势非平稳过程(non-stationary process with deterministic trend)y t = μ+ α t + y t-1+ u t, u t~ IID(0, σ2) 1801601401201008060400450500550600650700750800确定性趋势非平稳过程的差分过程是退势平稳过程,?yt = μ + α t + ut。


实验八:协整关系检验与误差修正模型(ECM)new实验八:协整关系检验与误差修正模型(ECM)一、实验目的通过上机实验,使学生加深对时间序列之间协整关系的理解,能够运用Eviews 软件检验时间序列数据之间的协整关系并以此估计误差修正模型(ECM)。
二、预备知识(1)用EViews估计线性回归模型的基本操作;(2)时间序列数据的协整关系及其检验方法;(3)误差修正模型的结构及估计方法。
三、实验内容(1)用EViews检验两个时间序列数据的协整关系;(2)用EViews估计误差修正模型;四、实验步骤(一)、建立工作文件sy8.wf1及导入数据打开sy8.xls文件,运用前面学过的方法,在EViews新建一个工作文件sy8.wf1,把sy8.xls的数据导入到EViews,并根据得到人均消费(consp)和人均GDP(gdpp)两个序列,分别计算对应的自然对数,即lnc=log(consp)、lngdp=log(gdpp)。
(二)、分别检验序列lnc和lngdp的单整阶数。
运用图示法观察序列的时间路径图,如图8-1所示。
可见,lnc和lngdp都随时间不断上升,表明两者都是非平稳的。
(再运用自相关函数法,判断lnc 的平稳性。
打开lnc 序列的窗口,点击view\Correlogram ,设定滞后阶数为12,可得样本自相关系数图,操作和结果分别如图8-2和图8-3所示。
可见,lnc 是非平稳的。
再分析lnc 的一阶差分是否平稳。
在自相关函数图中,设定显示序列的一阶差分(1st differenc )后,再观察其样本自相关函数图,设定和结果如图8-4和图8-5所示。
可见,lnc 取一阶差分后就达到平稳,因此,lnc 是一阶单整序列,即I(1)序列。
如果采用单位根检验,结果相同。
同理,也可检验得到lngdp 序列是I(1)序列。
(三)运用Engle-Granger 方法(即EG 检验)检验consp 与gdpp 的协整关系。


协整分析与误差修正模型演示文稿尊敬的老师、亲爱的同学们:大家好!我今天的演讲题目是“协整分析与误差修正模型”。
随着经济的发展和变化,我们经常会遇到不平衡的现象,例如两个变量之间的长期均衡关系。
这时,我们就需要使用协整分析来研究变量之间的平衡关系。
首先,让我们来了解一下什么是协整分析。
协整分析是在时间序列数据分析中常用的方法,用于寻找可能存在的长期均衡关系。
简单来说,协整分析可以帮助我们确定两个或多个非平稳序列之间的平衡关系。
接下来,我将向大家介绍协整分析的具体方法。
首先,我们需要收集两个或多个非平稳序列的数据。
然后,我们通过计算这些序列的差分来得到它们的差分序列。
接着,我们需要进行单位根检验来确定这些差分序列是否是平稳的。
如果差分序列是平稳的,那么我们可以进行协整检验来确定它们是否存在长期均衡关系。
最后,如果协整检验的结果是显著的,说明这些序列之间存在协整关系。
在协整检验的基础上,我们可以建立误差修正模型(Error Correction Model,ECM)来进行进一步的研究。
误差修正模型是一种常用的时间序列模型,用于研究不平衡的长期均衡关系。
它可以帮助我们分析短期冲击对长期均衡的调整速度和程度。
通过误差修正模型,我们可以对变量之间的平衡关系进行更深入的研究。
例如,我们可以通过模型的残差项来检验平衡关系是否稳定,或者通过模型的参数来分析短期调整的速度和程度。
协整分析和误差修正模型在经济学、金融学等领域中具有广泛的应用。
它们可以帮助我们理解经济变量之间的关系,预测未来的趋势,以及制定有效的政策和决策。
综上所述,协整分析与误差修正模型是研究经济变量之间平衡关系的重要工具。
通过这些方法,我们可以更好地理解和预测经济变量的变化,促进经济的稳定和可持续发展。
谢谢大家!。

第三节协整理论——时间序列模型的协整关系一、问题来源来源:伪回归(虚假回归)现象MC(蒙特卡罗)的模拟结果发现:利用2个相互独立的非平稳序列、或者2个都包含时间趋势但彼此无关的序列,可能建立显著的回归模型;称这种现象为“伪回归”现象,所建立的模型是伪回归模型。
伪回归现象意味着传统统计检验方法失去意义,需要重新讨论对非平稳序列能否直接建立回归模型的问题。
二、平稳性(一)平稳时间序列定义:μ=)(t y E)(),(s r y y COV s t t =- (序列的相关性只与间隔有关,与时刻无关) 推论:)0()(r y D t = = 常数图形特征:(1)在均值周围波动,频繁穿越均值;(2)波动幅度大致相同;-2-112240260340360DJ PY图1 日元兑美元差分序列 图2上证综指收益率平稳时间序列的含义:任何外来冲击(或振动)对序列变动轨迹的影响是短暂的,t时刻的振动影响在t+1期会减弱,t+2期会更弱,随着时间推移这种影响会逐渐消失,序列将恢复到其平均水平(称外来冲击影响具有“短记忆”特征)。
但是,对于非平稳时间序列,振动的影响会无限地持续下去,t时刻的振动影响不会在以后的时期中衰减,所以序列也难以恢复到一个稳定状态,外来冲击影响有长记忆性。
(二)常见平稳序列1.白噪声过程(white noise )0)(=t y E 2)(σ=t y D 0),(=-s t t y y COV记成: y t ~ i.i.d (0, σ2)古典回归模型中的随机误差项即为白噪声序列。
2.自回归过程(Auto regression —AR 过程)1t t t y y ρε-=+ ||1ρ<,εt ~ i.i.d (0, σ2)(三)常见非平稳序列1.趋势平稳过程(trend stationary)(又称为:退势平稳过程,确定趋势过程)。
y t =α + βt + εt , εt~i.i.d(0, σ2)性质:(1)E (y t )=α + βt , D (y t ) = σ2 , COV(y t ,y t-s ) = 0(2)图形:围绕趋势线等幅波动,外来冲击影响短暂;(3)可以扩展成带趋势的AR 过程:1t t t y t y αβρε-=+++ ||1ρ<特点:由于存在长期趋势使得均值不是常数,所以是非平稳序列;但是序列始终围绕着趋势线波动,外来冲击是短记忆的,所以又具备平稳序列的特征。



一、长期均衡关系与协整二、协整检验三、误差修正模型第三节协整与误差修正模型12一、长期均衡关系与协整0、问题的提出•经典回归模型(classical regression model)是建立在稳定数据变量基础上的,对于非稳定变量,不能使用经典回归模型,否则会出现虚假回归等诸多问题。
•由于许多经济变量是非稳定的,这就给经典的回归分析方法带来了很大限制。
•但是,如果变量之间有着长期的稳定关系,即它们之间是协整的(cointegration ,则是可以使用经典回归模型方法建立回归模型的。
•例如,中国居民人均消费水平与人均GDP变量的例子中:因果关系回归模型要比ARMA模型有更好的预测功能,其原因在于,从经济理论上说,人均GDP 决定着居民人均消费水平,而且它们之间有着长期的稳定关系,即它们之间是协整的(cointegration )。
31、长期均衡经济理论指出,某些经济变量间确实存在着长期均衡关系,这种均衡关系意味着经济系统不存在破坏均衡的内在机制,如果变量在某时期受到干扰后偏离其长期均衡点,则均衡机制将会在下一期进行调整以使其重新回到均衡状态。
假设X 与Y 间的长期“均衡关系”由式描述Y t =α0+α1X t +μt式中:μt是随机扰动项。
该均衡关系意味着:给定X 的一个值,Y 相应的均衡值也随之确定为α0+α1X 。
4在t-1期末,存在下述三种情形之一:(1)Y 等于它的均衡值:Y t-1= α0+α1X t ;(2)Y 小于它的均衡值:Y t-1< α0+α1X t ;(3)Y 大于它的均衡值:Y t-1>α0+α1X t ;在时期t ,假设X 有一个变化量ΔX t ,如果变量X 与Y 在时期t 与t-1末期仍满足它们间的长期均衡关系,则Y 的相应变化量由式给出:ΔY t =α1ΔX t +v t式中,v t =μt -μt-1。
5实际情况往往并非如此如果t-1期末,发生了上述第二种情况,即Y 的值小于其均衡值,则Y 的变化往往会比第一种情形下Y 的变化ΔY t 大一些;反之,如果Y 的值大于其均衡值,则Y 的变化往往会小于第一种情形下的ΔY t 。
案例五上证A、B股指数协整关系检验及误差修正模型在本案例中,我们利用我国上海证券交易所A、B股指数1998年1月9日到2008年3月7日周收盘价数据①(参见数据集/单位根检验、协整与误差修正模型数据/上证A、B股指数周数据.xls),介绍单位根检验、协整关系检验的基本方法以及误差修正模型的应用。
1. 创建Eviews工作文件(Workfile)从Eviews主选单中选File/New/Workfile 选择Undated or irregular选项,输入Start date:1 End date:500,方法如案例一介绍。
虽然是周数据,但是由于我国股票市场受五一、十一、春节等假期的影响,数据只能选择Undated or irregular类型。
2.录入数据,并对序列进行初步分析在workfile窗口中选Objects/New Object,新建一个序列对象,命名为SHA,用来保存上证A股指数周收盘价数据,并将数据导入。
该序列的折线图如图5—1。
①数据来源:大智慧软件下载并整理。
图5—1 上证A股指数周收盘价序列的折线图再新建一个序列对象,命名为SHB,用来保存上证B股指数周收盘价数据,并2。
将数据导入。
该序列的折线图如图5—图5—2 上证B股指数周收盘价序列的折线图从图5—1和图5—2我们可以看到,上证A、B股指数周收盘价数据序列总体上来说有类似于随机游走过程的形式,都是非平稳的。
为了更好地观察两者的关系,我们将两个序列以组的形式打开,并观察折线图,结果如图5—3。
100200300400图5—3 上证A 、B 股指数周收盘价序列的折线图从图5—3我们可以看到,上证A 、B 股指数周收盘价数据序列具有大致相同的趋势和变化规律,说明两者可能存在协整关系。
3. 单位根检验为了避免虚假回归问题,我们首先对SHA 和SHB 序列进行单位根检验。
(1)SHA 序列单位根检验为了确定SHA 序列的非平稳性,首先我们观察相关分析图,方法如案例四介绍。
实验四协整检验及误差修正模型实验报告一、实验目的协整检验及误差修正模型是时间序列分析中常用的方法。
本实验的目的是通过对两个时间序列数据的协整检验,并建立误差修正模型,来研究两个变量之间的长期关系以及短期波动情况。
二、实验步骤1.数据准备本实验所用数据为两个变量的时间序列数据。
我们需要确保数据的平稳性,并进行必要的数据预处理,如差分、对数化等。
2.协整检验协整检验是用来判断两个变量之间是否存在长期的关系。
本实验使用了Johansen协整检验方法。
该方法是基于向量自回归(VAR)模型的极大似然估计,用于检验多个时间序列之间的协整关系。
在进行协整检验之前,需要明确时间序列的滞后阶数,以及是否需要进行季节调整。
3.误差修正模型误差修正模型(ECM)是一种动态模型,用来描述变量之间的长期关系以及短期波动调整过程。
该模型基于协整检验的结果,使用差分变量进行建模,其中包含了误差修正项。
实验中,我们需要确定模型的滞后阶数,以及是否需要引入滞后差分变量等。
4.模型评估建立模型后,我们需要进行模型的评估与诊断,确保模型的有效性与准确性。
评估指标包括模型的拟合度、残差的正态性、自相关性以及异方差性等。
三、实验结果通过进行协整检验,我们得到了两个变量之间的协整关系。
根据检验结果,我们建立了误差修正模型,并进行参数估计与显著性检验。
最终的模型结果显示,模型的拟合效果良好,残差的正态性与自相关性得到了充分的满足。
四、实验分析根据实验结果1.两个变量存在着长期的关系,即它们在长期内呈现出稳定的均衡状态。
2.模型中的误差修正项描述了两个变量之间的短期波动调整过程,即使两个变量之间存在着均衡关系,也需要通过误差修正项来实现调整。
3.通过模型的参数估计与显著性检验,我们可以得到两个变量对于均衡关系的贡献程度,以及它们之间的动态调整速度。
五、实验总结协整检验及误差修正模型是时间序列分析中常用的方法,用于研究变量之间的长期关系以及短期波动调整过程。
协整和误差修正模型刘欢81120325数据来源:从外管局和人行网站选取2000年到2011年我国货币供应量和外汇储备的年度数据,来分析货币供应量和外汇储备之间的影响关系。
年份货币供应量(M2)/亿外汇储备(WHCB)/亿美元元2000 128887.40 1655.742001 146157.582121.652002 183246.942864.072003 219226.814032.512004 253207.706099.322005 298755.48 8188.722006 345577.9110663.442007 403401.3015282.492008 475166.60 19460.302009 610224.5223991.522010 725851.79 28473.382011 851590.9031811.48表1 货币供应量和外汇储备的年度数据数据处理:以货币供应量(M2)为被解释变量,以外汇储备(WHCB)为解释变量。
对各变量取对数进行分析,一方面取对数有压缩数据的作用,可以消除异方差性;另一方面变量取对数后自变量前面的系数表示解释变量每变化一个百分点,引起被解释变量变化的百分比。
这正符合本模型的需要。
(一)变量平稳性检验(1)lnM2的趋势图图一:lnm2的趋势图从趋势图中可以看出,呈上升趋势,带有截距项,数据非平稳。
(2) 采用单位根检验中的ADF检验来检验各变量的平稳性。
Dickey-Fuller test for l_M2sample size 11unit-root null hypothesis: a = 1test with constantmodel: (1-L)y = b0 + (a-1)*y(-1) + e1st-order autocorrelation coeff. for e: -0.161estimated value of (a - 1): 0.00868329test statistic: tau_c(1) = 0.408558p-value 0.9726with constant and trendmodel: (1-L)y = b0 + b1*t + (a-1)*y(-1) + e1st-order autocorrelation coeff. for e: 0.154estimated value of (a - 1): -0.668644test statistic: tau_ct(1) = -1.99019p-value 0.5425with constant and quadratic trendmodel: (1-L)y = b0 + b1*t + b2*t^2 + (a-1)*y(-1) + e1st-order autocorrelation coeff. for e: 0.046estimated value of (a - 1): -0.762043test statistic: tau_ctt(1) = -2.08007p-value 0.6843图二:lnm2的单位根检验三种模型的p值都很大,接受原假设H0(非平稳),说明数据是非平稳的。
协整检验及误差修正模
型
HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】
协整检验及误差修正模型
设随机向量t X 中所含分量均为d 阶单整,记为t X I(d )。
如果存在一个非零向量β,使得随机向量()~t t Y X I d b =-β,0b >,则称随机向量t X 具有d ,b 阶协整关系,记为t X CI(d ,b ),向量β被称为协整向量。
特别地,t y 和t x 为随机变量,并且t y ,
~(1)t x I ,当01()~I(0)t t t y x εββ=-+,即t y 和t x 的线性组合与I(0)变量有相同的统计性质,则称t y 和t x 是协整的,()01,ββ称为协整系数。
更一般地,如果一些I(1)变量的线性组合是I(0),那么我们就称这些变量是协整的。
用Eviews5.1来分析1978年到2002年中国农村居民对数生活费支出序列{ln }t y 和对数人均纯收入{ln t x }序列之间的关系。
1、对两个数据序列分别进行平稳性检验:
(1)做时序图看二者的平稳性
首先按前面介绍的方法导入数据,在workfile 中按住ctrl 选择要检验的二变量,击右键,选择open —as group ,此时他们可以作为一个数据组被打开。
点击“View ”―“graph ”—“line ”,对两个序列做时序图见图8-1,两个序列都呈上升趋势,显然不平稳,但二者有大致相同的增长和变化趋势,说明二者可能存在协整关系。
但若要证实二者有协整关系,必须先看二者的单整阶数,如果都是一阶单整,则可能存在协整关系,若单整地阶数不相同,则需采取差分的方式,将他们变成一阶单整序列。
图8-1 ln t x 和ln t y 时序图
(2)用ADF 检验分别对序列ln t x 和ln t y 进行单整检验
双击每个序列,对其进行ADF 单位根检验,有两种方法。
方法一:“view ”—“unit root test ”;方法二:点击菜单中的“quick ”―“series statistic ”―“unit root test ”。
序列ln t x 和ln t y 都有明显的上升趋势,采用带常数项和趋势项的模型进行检验,见图8-2,对对数序列的原水平进行带趋势项和常数项的ADF 检验,采用SC 准则自动选择滞后阶数,检验结果见图8-3和8-4,在0.05的显着性水平下,都接受存在一个单位根的原假设,说明这两个序列都不平稳。
图8-2 单位根检验图
图8-3 序列ln t x 的ADF 检验结果
图8-4 序列ln t y 的ADF 检验结果
于是尝试对其一阶差分序列采用带常数项的模型进行ADF 检验,首先点击主菜单
Quick/Generate series ,出现图8-5的对话框,在方程设定栏里分别输入dlnxt=lnxt-lnxt(-1)和dlnyt=lnyt-lnyt(-1),产生ln t x 和ln t y 的一阶差分序列,为了方便,简记为ln t x ∇和ln t y ∇,一阶差分能初步消除增长的趋势,于是可以对其进行只带常数项的ADF 检验,检验结果见图8-6和图8-7:
图8-5
图8-6 序列ln t x ∇的ADF 检验结果
图8-7 序列ln t y ∇的ADF 检验结果
由图8-6和图8-7,得出两个一阶差分序列在=0.05α下都拒绝存在单位根的原假设的结论,说明ln t x ∇和ln t y ∇序列在=0.05α下平稳,即ln (0)t
x I ∇,ln (0)t y I ∇,也就是ln (1)t x I ,ln (1)t y I ,这样我们就可以对二者进行协整关系的检验。
2、协整检验:
首先用变量ln t y 对ln t x 进行普通最小二乘回归,在命令栏里输入ls lnyt c lnxt ,得
到回归方程的估计结果:
在此基础上我们得到回归残差,现在的任务是检验残差是否平稳,对残差进行ADF 检验见图8-8,在0.05显着性水平下拒绝存在单位根的原假设,说明残差平稳,又因为ln t x 和ln t y 都是1阶单整序列,所以二者具有协整关系。
图8-8 回归残差ADF 检验
3、误差纠正模型ECM 的建立(error correction mechanism )
即使两个变量之间有长期均衡关系,但在短期内也会出现失衡(例如收突发事件的影响)。
此时,我们可以用ECM 来对这种短期失衡加以纠正。
我们利用差分序列{ln }t y ∇关于{ln t x ∇}和前期误差序列1{}t ECM -进行OLS 回归,构建如下ECM 模型:
其中111ln 0.07360.9573ln t t t ECM y x ---=--
参数估计结果见图8-9:
图8-9 ECM 模型估计结果
ECM 模型可表示为:
另外,我们可以用(1,1)阶分布滞后形式:
对序列进行估计,在命令栏里输入ls lnyt c lnyt(-1) lnxt lnxt(-1),得到参数估计结果见图8-10:
图8-10 短期波动模型估计结果
两种方法建立的误差修正模型是等价的,在进行预测时,第二种方法更方便。
方程检验结果均显示方程显着线相关,参数检验结果显示人均纯收入当期波动对生活费支出的当期波动有显着性影响,上期误差对当期波动的影响不显着;同时,从回归系数的绝对值大小可以看出可支配收入的当期波动对生活费支出的当期波动调整幅度很大,每增加1元的可支配收入便会增加0.9551元的人均生活费支出,上期误差对当期人均生活费支出的当期波动调整幅度很小,单位调整比例为-0.1715。
y和对通过上述分析发现,1978年到2002年中国农村居民对数生活费支出序列{ln}
t
x}序列都是不平稳的,但对其进行一阶差分后序列平稳,且都是一阶单数人均纯收入{ln
t
整的,进行普通最小二乘回归后,残差在0.05的显着性水平下也平稳,说明二者存在协整关系,进而建立了短期波动的误差修正模型。
误差修正模型显示:人均纯收入当期波动对生活费支出的当期波动有显着性影响,上期误差对当期波动的影响不显着;同时,从回归系数的绝对值大小可以看出可支配收入的当期波动对生活费支出的当期波动调整幅度很大,每增加1元的可支配收入便会增加0.9551元的人均生活费支出,上期误差对当期人均生活费支出的当期波动调整幅度很小,单位调整比例为-0.1715。