基于XML智能答疑系统知识库的构建
- 格式:pdf
- 大小:376.11 KB
- 文档页数:14

基于人工智能的知识库问答系统研究随着人工智能技术的不断发展,越来越多的应用场景开始向人工智能方向转移。
其中,知识库问答系统已经成为了人工智能技术在知识领域的重要应用之一。
本文将探讨基于人工智能的知识库问答系统研究,以及其发展前景和挑战。
一、知识库问答系统的概念知识库问答系统(KBQA)是一种基于自然语言理解、知识表达和知识推理技术,为用户提供自然语言接口,能够以智能化的方式回答用户关于某个特定领域的问题。
与传统的关键词搜索引擎相比,知识库问答系统更侧重于理解用户提出的问题,并给出精确的回答。
在发展过程中,知识库问答系统逐渐从基于规则的技术向深度学习、神经网络等技术转移,并逐步实现了真正的人机对话。
二、基于人工智能的知识库问答系统研究基于人工智能的知识库问答系统主要包含自然语言处理、知识表示与推理、语义匹配等技术。
1. 自然语言处理自然语言处理是知识库问答系统的基础。
该技术主要包括分词、词性标注、实体识别、语义角色标注、句法分析等环节。
通过这些环节,系统能够对自然语言文本进行深入的理解。
2. 知识表示与推理知识表示与推理技术是知识库问答系统的核心技术。
该技术主要包括知识图谱、本体论、规则等,通过这些技术,系统可以对知识进行表达,推理和存储。
3. 语义匹配语义匹配技术是知识库问答系统高效回答问题的关键技术。
通过该技术,系统可以将用户提出的自然语言问题与知识库中的实体、属性及关系进行匹配,找到最合适的答案。
三、基于人工智能的知识库问答系统的发展前景随着人工智能技术的进一步研究和应用,基于人工智能的知识库问答系统也将迎来更加广阔的发展前景。
1. 实现真正的人机对话基于人工智能的知识库问答系统将实现真正的人机对话,使得用户可以通过自然语言与系统进行沟通,从而实现更加智能、高效的知识获取。
2. 对知识库的更新和维护提出更高的要求基于人工智能的知识库问答系统将对知识库的更新和维护提出更高的要求,需要保证知识的完整性、准确性和时效性。
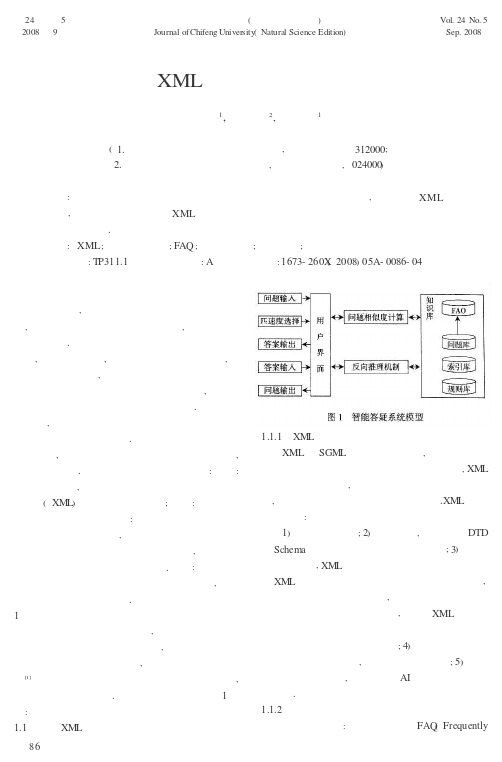
智能答疑系统是目前自然语言处理领域中的一个研究热点,它既能让用户用自然语言语句提问,又能为用户返回一个简洁的答案,而不是一些相关的网页.目前的答疑系统大多都是基于某一平台的,不具有通用性,仅限在一定的范围内使用,没有达到充分的共享,另外当前的答疑系统存在智能程度不够、查找速度不理想、答疑手段单一,答案或知识的结构不良、呈现方式不够等不足.要解决以上不足,必须从开发的工具、问题库的表示和存储组织策略等方面进行研究.为此,开发一个与平台无关的智能答疑系统,是很有必要的.本系统主要有以下几个特点:第一:系统的通用性,采用了基于与平台无关的可扩展标记语言(XM L )来对问题库的表示;第二:系统的智能性主要体现在两个方面:一方面是对用户提出的问题进行充分的“理解”,另一方面是系统的问题库能够通过一定的推理机制进行自动扩充,使得系统能够回答用户提出的更多的问题.第三:系统的查找速度方面采用了基于单字的倒排索引机制,大大地提高了系统的查找速度.1智能答疑系统的基本模型在具体的远程教育环境中,用户提出的问题是针对某一专业的某一课程而言的,提出的问题相同或类似的问题的频率比较大,本文主要针对具体课程[1]以通用性、智能性、查找速度三个方面为重点,阐述系统的研究情况系统的基本模型如图所示采用XM L 语言对知识库的表示1.1.1XM L 语言XML 是SGM L 的一个优化子集,它以统一、开放、基于文本格式的模式来描述和交换数据,XM L 是一种元数据语言,它提供了一种描述数据的格式,方便了内容和查询结果平台的声明.XM L 具有以下特点:1)内容的独立性;2)可扩充性,通过底层DTD或Schema 的扩展增加新的知识表示能力;3)内容的自描述性,XM L 文档中的数据可以被任何能够对XM L 数据进行解析的应用所提取、分析和处理,并以所需要的格式显示出来,它的这种数据表示方式真正做到了独立于应用系统,采用XML 描述的文档无论从逻辑结构还是语义关系都为信息的检索等深层次提供了良好的基础;4)可以对不同的信息源的信息进行集成,并形成统一的文档;5)可以实现数据的结构化,提供不同AI 应用之间知识库的交换知识库知识库包括常见问题库F Q (F q y基于XML 的智能答疑系统研究王常亮1,闫利华2,吴曦德1(1.浙江工业职业技术学院计算机系,湖南绍兴312000;2.赤峰学院计算机科学与技术系,内蒙古赤峰,024000)摘要:分析了当前答疑系统在通用性、智能性和查找速度上存在的不足,提出基于XML 的智能答疑系统模型,并围绕该模型就基于XML 的问题库的表示、问题相似度计算、基于单字的倒排索引和反向推理机制进行了论述.关键词:XML ;智能答疑系统;FAQ ;问题相似度;倒排索引;反向推理中图分类号:T P311.1文献标识码:A文章编号:1673-260X (2008)05A-0086-04Vol.24No.5Sep.2008第24卷第5期2008年9月赤峰学院学报(自然科学版)Journal of Chifeng Univer sity (Natura l Sc ience Edition)图1智能答疑系统模型6.1:1.1.1.1.2:A re uentl 8Asked Questio ns)、问题库、索引库、规则库、常用词库、专业词库、同义词库.模型中只给出前四个库,知识库均采用XM L文档来存储,这样做有以下特点:1)系统的知识库具有通用性,系统的可移植性强.2)XM L存储数据的方式是以树型结构存储,采用XM L文档来存储知识更加符合知识的本来面目和人们对知识的认知过程.要了解一本教材的知识点,可以从教材的目录中快速的获取,进一步细化可以到每一章节了解较小的知识点,每个小的知识点还可以分为更小的知识点,这些都可以采用一个树型结构来体现,采用XML文档来存储知识是一个不错的选择.采用巴科斯.诺尔范式(BNF)形式的知识表示策略描述文献[1]的问题库,其中∷=表示“定义为”,|表示“或”,问题库的数据结构如下:1)<系统问题库知识>∷=<操作系统知识点>2)<操作系统知识点>∷=(<章名称>|<章节知识点>)3)<章节知识点>∷=(<节名称>|<节知识点>|<常用词集合>|<专业词集合>|<问题与答案>|<知识点内容>)4)|<问题与答案>∷=(|<问题与答案编号>|<访问最新时间>|<访问的次数>|<问题与答案内容>|<问题类型>)1.2匹配度的选择和问题相似度计算系统在智能方面的关键点是什么呢?通过分析发现,是用户提出的问题与标准的问题的匹配程度,匹配的程度又与采用的问题相似度计算方法有着直接的关系.系统中问题相似度采用文献[2]中的语句相似度计算公式:SentenceSim(X,Y)=λ1Wo rdSim(X,Y)+λ2LenSim(X,Y)+λ3OrderSim(X,Y)SentenceSim(X,Y),表示两个语句的相似度, WordSim(X,Y)表示两个语句的词形相似度,LenSim (X,Y)表示两个语句的长度相似度,OrderSim(X,Y)表示两个语句的词序相似度,λ1,λ2,λ3是常数,且满足λ1+λ2,+λ3=1,SentenceSim(X,Y)∈[0,1].其中词形相似度起着主要作用,语句长度相似度和词序相似度起着次要的作用.采用这个相似度计算的优点是:可以保证当一个语句的分句或短语整体发生了移动后仍与原来的语句相似.语句相似度计算应用到智能系统中,会使查找的准确度大大提高.系统的匹配度设定了:精确匹配、语义匹配、关联匹配、模糊匹配精确匹配是指用户输入的问题与标准的问题完全一样,直接在答案库中查询,不需经过问题相似度计算,系统必须返回标准的问题的答案给用户.语义匹配:指用户提出的问题与标准的问题在语义上很相似(系统设定问题的相似度为80%就认为语义很相似),那么就应该返回标准问题所对应答案给用户.这一点很重要,因为用户输入的问题很大程度上不固定,存在形式上都不同但有着相同的语义.如:“操作系统的概念”、“操作系统是什么”、“什么是操作系统”、“操作系统定义”这些问题在语义上都很相似.关联匹配:指答案库中没有以上两种情况的答案,那么最好返回与之有关联的标准问题所对应的答案.系统设定问题相似度为45%以上的属于关联匹配.如:“操作系统的分类”与“操作系统的定义”可以看作是关联的,这种情况下可以将“操作系统定义”的答案作为参考答案供用户参考.模糊匹配:指问题相似度不为零的情况.1.3索引机制答疑系统中问题的答案全部放在问题答案库中,如果每次提问都去访问数据库的话,肯定会影响查找速度,另外当数据库文件记录的数目和数据量都很大时,查找速度也会明显下降,因此,为了提高查找速度,必须对问题库建立相应的索引机制. 1.3.1基于单字的倒排索引在问题相似度计算中需要计算SameWC(Input, q),SameWC(Input,q)表示输入问题与FAQ中标准问题相同字数,Input表示输入的问题,q表示FAQ 中的标准问题.计算SameWC(Input,q),如果将FAQ 中的问题一一读出来和Input进行比较,效率比较低的,达不到预期的效果.对于Input中的某个字,为了能够快速地统计FAQ中究竟有多少问句含有这个字,设计了如下数据结构,如图2所示:图中的F Q库记录了所有的原始的问题与答案对,表记录了F Q库中每个问句在库文件中的位置,索引表中的W,W,W3,…,. :2APos Aord1ord2ord87Wordm是FAQ库中的问句所包含的词经过排序后所形成的链表,每个w ordi指向一个s链表,这个s 链表中的每个节点记录FAQ库中含有w ordi的一个问句的语句号.算法1:单字倒排索引表和语句长度表建立算法.输入:Q输出:单字倒排索引表InvTab和语句长度表LenT ab.Fo r each q in Q求出q的偏移量pos(q)把pos(q)及Len(q)插入LenTab表中for each w ord in q把pos(q)插入到Inv Tab[hashW(w ord)]→ILINKwo rd中输出InvTab和LenT ab.算法中的Q为FAQ库中所有问句的集合,可以用数组的结构来表示.InvTab为单字倒排索引表的每个记录为二元组<w ord,ILINKWord>,其中IL INKWord为单字w ord出现的语句的偏移量的链表,该索引表按单字以散列方式组织,能够实现快速建立和查找.设散列函数为hashW(wo rd),可用任何一种方法解决散列地址冲突问题,为使算法描术简明,这里假设没有冲突,即可直接通过InvTab [hashW(wo rd)]→IL INKw ord存取wo rd的索引集合.语句长度表LenT ab的每个记录为二元组<pos, len>,其中po s表示一个语句的偏移量,len表示该语句的长度.该表也以以散列方式组织.设散列函数为hashpo s(pos),即可通过LenTab[hashpos(po s)]→len存取偏移量为po s的语句的长度.单字倒排索引表作用是在不读FAQ的情况下就可计算SameWC(Input,q),而且与Input相似度为0的语句不参与计算.语句长度表的作用是在不读FAQ的情况下就计算Wo rdSim(Input,q).1.3.2相似问题的查找设输入语句Input共有m个不同的单字,各单字的倒排索引为图2所示的索引表.系统从所有的Samew c(Input,q(Si))中选出最大的前k1个就会包含相似度最大的语句.再根据Si 可从LenT ab中读出语句q(Si)的长度,计算出WordSim(Input,q(Si)),这个过程实现的算法时间复杂度为O(k1).语句相似度中词形相似度起决定作用,所以与Input语句相似最大的语句Wo rdSim (I,q)也一定较大,因此从已计算出的所有的W S(I,q(S))值中选出最大的(<)个就会包含相似度最大的语句,然后再计算出语句长度相似度(选出最大的k3<k2个)和词序相似度,最后计算出SentenceSim(Input,q(Si)),取出最相似的语句(一般取最大的前五个)按降序排列输出.相似问题的查找算法如下:算法2:相似语句查找算法输入:Input,Inv Tab,LenT ab,Q输出:相似语句前五个按降序排列for each不同的单字Word in Input从InvT ab读出Wo rd的倒排索引计算所有非零的Samewc(Input,q)根据LenT ab计算Samew c(Input,q)的最大的前k1个的语句的WordSim(Input,q)计算Wo rdSim(Input,q)前k2语句的L enSim (Input,q)根据Q计算LenSim(Input,q)前k3个语句的OrderSim(Input,q)计算SentenceSim(Input,q)输出SentenceSim(Input,q)最大的前五个语句.1.4规则库和反向推理机制1.4.1规则库规则库主要用来描述提供控制策略、表达有关如何相应操作、演算和行为等的比较、判断和决策的一系列规则.答疑系统的规则库是由规则表和条件表构成,规则所用到的概念、操作描述在概念上和问题库保持一致.如条件表Conditon(cond_ID, Object,Value,D),其中co nd_ID表示条件号,唯一标识一个条件,Object条件的主体,Value主体的属性,D为对应的规则号.规则表定义为一个多元组Rule(D,Value,Ob-ject,Relationship,Operation),其中D表示规则号,唯一标识一条规则;Value表示规则的类型,包括基本规则,方法,策略;Object表示该规则包括条件的集合;Relationship表示条件之间以及不同层次的条件间存在的交互作用和影响的集合;Operation表示满足逻辑表达式后进行的操作,即规则的结果部分.规则库用RuleXM L(Rule Ex tensible M arkup Lang uage)[3]描述,由一组有序或无序的规则构成. 1.4.2反向推理机制反向推理是一个问题的求解过程是从未被证实的假设出发,并试图对其进行证明,这种策略包括寻找能说明该假设成立的一些规则,然后检验那些使规则能够运行的事实、反向推理方法从目标出发,具有目的性强,有利于用户提供解释的优势避免了正向推理效率,答疑系统的推理机制采用反向推理,提高了系统的工作效率[]nputord im nput i k2k2k1.4.88推理机采用DOM提供的标准接口API与XM L标记的逻辑树型结构进行动态操作,具体过程是:在初始化阶段载入问题库和规则库,推理机就通过遍历内存中创建的文档树结构的节点和对节点属性进行访问与操作,来实现搜索、匹配等任务.比如假设推理机在初始化时载入如下的标准问题和规则(见图3),要证明新的问题X是否成立.①要证明X是否成立.使用深度优先遍历在问题库中查找X,当未找到时,再在规则库中的规则表中查找Operation中有没有X,查到第二条规则中含X.此时看该条规则中的条件是否满足,即C、M是否成立.②确认C、M成立否.C已在系统的问题库中,只需证明M成立即可,重复第一步工作,得到第三条中含M,该条规则反映出证明M成立否需要得到H、P成立的证明.③确认H、P成立否.H C存在系统的问题库中,只需证明P成立即可,重复第一步工作,得到第三条中含P,该条规则反映出证明M成立否需要得到L成立的证明.④L已在系统的问题库中,条件满足,推理成功,把新问题X写入问题库中.2答疑过程系统为了提高答疑的效率,采用了二级问题库,即FAQ和问题库,当用户输入问题、选择匹配程度时,系统通过分词处理、问题相似计算,进行相似查找(先从FAQ中查找,找不到后再从问题库中查找),若找到按相似程度的高低降序排列将答案返回给用户,若没找到则自动启用反向推理机,若成功,返回给用户相应的答案,同时对问题库进行扩充,若还没有找到,系统将会给用户返回相应的提示信息,同时将问题发送到专门负责的专家教师的留言箱中.专家教师将对该问题进行解答,并把该问题放到问题库中,同时根据情况增加相应的规则到规则库中专家教师解答后,系统将会把相关的信息发送到用户的留言箱中图是答疑系统实现的测试结果界面,单击图中的超级链接“进程是什么”会得到图5的界面.3结束语答疑系统的通用性、智能性、查找速度都是当前研究的热点,利用XML技术表示问题库解决了系统的通用性问题,系统采用的问题相似度计算、反向推理机制和基于单字的倒排索引机制,使智能性和查找速度得到了一定的提高.系统的智能性、查找速度是否有更合理的方案还有待做进一步的探讨.———————————————————参考文献:〔1〕柯敏毅.计算机操作系统教程[M].北京:中国水利水电出版社,2003,7.〔2〕王常亮,滕至阳.语句相似度计算在FAQ中的应用[J].2006,(2):24-26.〔3〕孔繁胜.知识库系统原理[M].杭州:浙江大学出版社,1999.〔4〕王士同.人工智能教程[M].北京:电子工业出版社,2001.〔5〕XML中国论坛.XML实用进阶教程[M].北京:清华大学出版社,〔6〕李素建基于语义计算的语句相关度研究[] ,()356(责任编辑白海龙)图4问题查找结果图5详细答案界面..442001..J. 200278:7-7.89。

基于知识库的智能问答系统设计与实现随着人工智能技术的不断发展,越来越多的人开始将目光投向了机器人和智能问答系统这些科技前沿领域。
智能问答系统对于企业和个人来说都具有非常广泛的应用场景,可以有效地提高工作效率、节省时间和降低成本。
本文将从技术实现层面出发,探讨如何基于知识库设计和实现一个高效、智能的问答系统。
一、智能问答系统的基本概念智能问答系统是一种能够自动地处理自然语言(NLP)输入并输出相应答案的软件应用程序。
在用户和问答系统之间进行沟通交流时,系统利用自然语言处理技术分析和理解问题,从知识库中检索相关信息,并根据问题类型和语义关系生成相应答案。
随着机器学习和深度学习技术的不断发展,智能问答系统在诸多领域中有着广泛的应用,如客服机器人、智能家居、人工助手等。
目前智能问答系统中最普遍的类型分为两类:基于规则和基于机器学习。
基于规则的智能问答系统是通过在系统中内置人类编写的规则集,对输入问题进行逐一匹配和处理,最终返回相应答案。
这种方法需要将所有的信息都先定义好,才能准确地匹配到答案,因此难以覆盖所有的问题类型和场景,而且维护和更新规则集也比较复杂。
基于机器学习的智能问答系统则是利用机器学习技术对海量的语料数据进行学习,提取问题和答案之间的语义关系,从而实现高效的问答匹配。
这种方法通过学习数据集中的相关信息,能够更好地适应自然语言环境的复杂性和变化性,提高了问答系统的健壮性和可扩展性。
二、基于知识库的智能问答系统基于知识库的智能问答系统是一种利用已有领域专业知识构建的知识库来回答用户问题的问答系统。
知识库可以是行业标准、法规政策、常见问题等,通过将知识结构化和存储,再借助问答程序获取问题答案。
在实际应用中,比较典型的知识库型问答系统有百度知道、Quora等问答社区。
这类问答系统一般都是通过手动或自动构造知识库来实现问题的快速响应和准确性,能够有效地提高用户对问题的掌握和领域知识的理解。
但这种方法也存在一些问题,比如完整性、准确性、更新速度等方面并不能完全保证。

基于XML智能农业专家咨询系统的设计与实现摘要本文以农业专家咨询系统为例。
提出了一种基于XML和知识库的农业智能专家咨询系统模型,并对系统进行了功能模块的划分和详细分析。
该系统充分结合农业科类知识库和FAQ库,灵活采用多种形式进行咨询。
关键词 XML;智能农业专家咨询系统;知识库;DTD托普物联网指出智能农业是指在相对可控的环境条件下,采用工业化生产,实现集约高效可持续发展的现代超前农业生产方式,就是农业先进设施与露地相配套、具有高度的技术规范和高效益的集约化规模经营的生产方式。
它集科研、生产、加工、销售于一体,实现周年性、全天候、反季节的企业化规模生产;它集成现代生物技术、农业工程、农用新材料等学科,以现代化农业设施为依托,科技含量高,产品附加值高,土地产出率高和劳动生产率高,是我国农业新技术革命的跨世纪工程。
智能农业产品通过实时采集温室内温度、土壤温度、CO2浓度、湿度信号以及光照、叶面湿度、露点温度等环境参数,自动开启或者关闭指定设备。
可以根据用户需求,随时进行处理,为设施农业综合生态信息自动监测、对环境进行自动控制和智能化管理提供科学依据。
通过模块采集温度传感器等信号,经由无线信号收发模块传输数据,实现对大棚温湿度的远程控制。
智能农业还包括智能粮库系统,该系统通过将粮库内温湿度变化的感知与计算机或手机的连接进行实时观察,记录现场情况以保证量粮库的温湿度平衡。
随着多媒体技术和网络技术日益成熟,各种咨询系统日益盛行,越来越多的企事业单位和政府部门提供了网络咨询的窗口,让外界更好地了解自己,更好地提供服务并发布信息。
农业生产、工业生产和商贸经营管理都离不开专家咨询。
但是,目前大多数咨询系统重点突出专家咨询,主要对在线专家进行了详细介绍,而应用主体则有限,不能自动学习和适应咨询者遇到的各种千变万化的问题。
笔者以农业专家咨询系统为例,提出了一种基于XML和知识库的农业智能专家咨询系统。
农业智能专家咨询系统是运用人工智能的专家系统技术,集成了信息网络、智能计算、知识发现、优化模拟和虚拟现实等多方面高新技术,汇集了农业领域知识和专家经验等,采用恰当的知识表示技术和推理策略,运用多媒体技术并能以信息网络为载体,为农业生产管理提供咨询服务,指导科学种田的农业综合系统。

远程教育中智能答疑系统的设计与实现完整文档资料可直接使用,可编辑,欢迎下载北京交通大学硕士学位论文远程教育中智能答疑系统的设计与实现姓名:胡娜申请学位级别:硕士专业:教育技术学指导教师:赵宏20071201jb塞銮道盔堂亟±堂僮迨塞生塞翅垂中文摘要摘要:随着网络技术的发展和网络应用的普及,依托于网络技术的远程教育正在迅猛地发展。
基于网络环境下的教育模式,采用的是探索式学习方式,它支持学生根据自己的情况,浏览相关的教学资源,实现优秀教育资源和教育方法的共享。
但是,在远程教学中,学生和教师是时空相对分离的,学生无法与教师直接交流,于是答疑作为其教学活动中的一个重要环节,正日益引起人们的关注。
设计一个好的远程教育答疑系统,能及时有效地解决学生在学习过程中历产生的疑问,这样可以提高远程学生的学习效率,保证远程教育的质量。
一般的答疑系统采用的是基于搜索引擎的关键字查询方式,这种答疑系统需要学生自己输入关键字进行提问,对学生提炼总结关键字的能力有一定要求,并且搜索的效果并不理想,需要学生进一步来筛选系统反馈的答案,使得学习效率不高,这种答疑系统有必要进一步优化。
智能答疑系统是一个具有知识记忆、数据计算统计、逻辑推理、知识学习和实现友好人机交互的智能系统,其本质是一个具有智能性的知识系统。
它支持自然语言的提问、自动检索问题并呈现有效答案,能够通过学习自动扩展和更新答案知识库。
它的这些特点,使学生在学习时能够使用自己熟悉的方式表达问题,并能够及时获得与问题较为相关的一些反馈答案。
本文首先论述了研究智能答疑系统的背景和意义,并在分析了远程教育模式特点及对比了现有的答疑系统的基础上,对答疑系统做了统一的设计和开发,提出了一个基于本体以及XML的智能答疑系统的设计,初步建立了本体库以及知识库,给出了完整的体系结构及其架构开发模式,并对开发智能答疑系统环境中的关键技术进行了深入的研究,最后给出了智能答疑系统的实现方法。

(19)中华人民共和国国家知识产权局(12)发明专利申请(10)申请公布号 (43)申请公布日 (21)申请号 201910298906.9(22)申请日 2019.04.15(71)申请人 南京邮电大学地址 210003 江苏省南京市鼓楼区新模范马路66号(72)发明人 薛景 李洲洋 孙彤 施寅端 林丹 (74)专利代理机构 南京苏科专利代理有限责任公司 32102代理人 姚姣阳(51)Int.Cl.G06F 17/27(2006.01)(54)发明名称一种程序设计类课程课后答疑系统的知识库建立方法(57)摘要一种程序设计类课程课后答疑系统的知识库建立方法,包括如下步骤,步骤S1、根据交互信息获取并整理收到问题语句;步骤S2、生成问题语句的词向量矩阵,并通过预设模型判断问题语句的问题类型;步骤S3、计算问题语句与同类型其他问题语句之间的语义相似度;步骤S4、根据语义相似度构建候选答案,再通过排序算法对候选答案进行排序,更新问题语句的知识库。
该方法利用模型判断问题语句的类型,再根据同类语句之间语义相似度构建候选答案,最后通过排序算法排序候选答案构建问题的知识库,使课后答疑系统的表现更佳。
权利要求书1页 说明书7页 附图2页CN 109977421 A 2019.07.05C N 109977421A1.一种程序设计类课程课后答疑系统的知识库建立方法,其特征在于,包括如下步骤,步骤S1、根据交互信息获取并整理收到问题语句;步骤S2、生成问题语句的词向量矩阵,并通过预设模型判断问题语句的问题类型;步骤S3、计算问题语句与同类型其他问题语句之间的语义相似度;步骤S4、根据语义相似度构建候选答案,再通过排序算法对候选答案进行排序,更新问题语句的知识库。
2.根据权利要求1所述的一种程序设计类课程课后答疑系统的知识库建立方法,其特征在于,所述步骤S2具体方法为:步骤S21、对训练语料中的语句进行解析,获取各训练语句的词向量矩阵,根据各训练语句的词向量矩阵和自身的语句类型训练预设模型;步骤S22、对问题语句进行分词处理,获取一系列词语,生成每个词语的词向量,并组合生成问题语句的词向量矩阵;步骤S23、根据词向量矩阵,利用预设模型判断语句的问句类型。
智能答疑系统的设计与实现
宋万里;卜磊
【期刊名称】《电脑知识与技术》
【年(卷),期】2017(013)036
【摘要】教师不能有效及时的回答学生学习过程中遇到的问题,会影响学生的学习兴趣及学习效率.该文通过自然语言处理技术、模板分类技术、支持向量机技术构建智能答疑系统,对问题和答案进行分词处理、模板匹配和分类训练,自动对问题和答案进行课程类别判断.再通过余弦相似性算法对问题和答案计算相似度,返回相似度最大的答案.如用户对系统反馈答案不满意,可以将问题抛入公共问答区,来寻求其他用户帮助.系统将对用户答案进行审核,审核通过则将此问题答案对添加到题库中,使得题库中的问句不断扩充.该文是以网络论坛中的用户提问作为问题库,通过此库进行答案的反馈.测试结果表明,该系统能够很好地服务于大学生,体现出教学的智能化.
【总页数】3页(P163-165)
【作者】宋万里;卜磊
【作者单位】南京晓庄学院,江苏南京211171;南京晓庄学院,江苏南京211171【正文语种】中文
【中图分类】TP391
【相关文献】
1.基于Lucene的网络学习智能答疑系统的设计与实现 [J], 郁红英;高英
2.基于Internet的智能自适应答疑系统的设计与实现 [J], 廖东民
3.\"Python程序设计\"课程智能答疑系统的设计与实现 [J], 郝光兆;杨静;吴迪;生龙
4.基于Web的特定领域智能答疑系统的设计与实现 [J], 石凤贵
5.基于Web的特定领域智能答疑系统的设计与实现 [J], 石凤贵
因版权原因,仅展示原文概要,查看原文内容请购买。
分类号UDC单位代码10642密级公开学号2002452067重庆文理学院学士学位论文基于XML智能答疑系统知识库的构建论文作者:何国强指导教师:学科专业:计算机科学与技术研究方向:智能计算机辅助教学提交论文日期:2006年5月22日论文答辩日期:2006年6月3日学位授予单位:重庆文理学院中国 重庆2006年6月目录基于XML智能答疑系统知识库的构建计算机科学与技术专业2班何国强指导教师**摘要:本文从本体论与XML相结合的角度研究了知识库的构建。
文章首先介绍了知识、知识库、智能答疑系统和本体论,这些理论是构建知识库的理论基础,然后,着重阐述了构建知识库两大技术,即Microsoft Visio和XML,前者作为本体建模的图形工具,后者用于本体模型的形式化。
基于以上对理论基础和关键技术的介绍,本文针对《计算机操作系统教程》一书的部分知识进行了本体建模。
出于知识和问题的特点,对本体组成的理论作了局部的改造,同时定义了四种图形符号的精确含义,以便于用Microsoft Visio进行图形化本体模型。
就具体的建模过程,本文提出了本体建模三个步骤:第一,明确建模的范围和目的;第二,知识的获取;第三,知识模型的图形化。
通过上述步骤得到了直观的本体模型,然后利用XML技术作为知识库的开发平台,以DTD作为本体与XML的结合点,通过精心设计DTD完成了本体论与XML的结合,实现了从本体模型到XML文档的映射。
文章最后完成了本体模型的编码即生成了XML文档。
关键词:XML;本体;知识;知识库;智能答疑系统Design Repository of Intelligent Question Answering System Based on XMLMajor:Computer Science and Technology Class:2Author:He Guoqiang Supervisor:Gu QiyuanAbstract:This paper has researched the designing repository from the view of combination between Ontology and XML.At first,this paper introduced some theories such as knowledge,repository,IQAS and XML.These are the basic theories of designing repository.And then it expatiated on two key techniques to design repository.The one is Microsoft Visio and the other is XML.The former is the graphic tool of ontology modeling and the latter is used to formalize the ontology model.Based on basic theories and key techniques above,this paper has built the ontology model of the partial knowledge in the book called COMPUTER OS TEXT.Because of the trait of OS’knowledge and problem,the author has modified Ontology theory in part and defined four symbols’meanings accurately in order to use these symbols to build Ontology model graphically with Microsoft Visio.As to concrete modeling process,the author has brought forward the three steps in Ontology modeling.The first is confirming the purpose and scope;the second is acquiring knowledge and the last is changing knowledge model to graph.According to the three steps above,this paper has given birth to graphic Ontology model.Then,using the XML as the platform of designing repository and using the DTD as the bridge between Ontology and XML,the author has completed the combination between Ontology and XML,and actualized the map from Ontology model to XML document via designing DTD carefully.Finally paper has coded the Ontology via DTD namely has created XML Document.Keywords:XML;Ontology;Knowledge;Repository;IQAS1引言1.1研究背景随着远程教学的发展,智能答疑系统也变得倍受关注,对智能答疑系统的需求也与日俱增。
知识库作为智能答疑系统的大脑运行在系统的后台。
它是问题求解的基础,为了使智能答疑系统取得理想的效果,领域知识库本身的建设也至关重要,领域知识库中知识的数量与质量,在很大程度上决定了系统的有效性与智能性[24]。
目前人们对知识库的研究越来越重视,同时产生了大量的知识库,但是这些知识库都是基于一定的系统,其独立性和跨平台性都较差,共享能力和重用能力都较弱。
这两大弱点是构建知识库极难克服的障碍。
1.2研究内容基于上述所提到的知识库的不足,本文从本体论和XML技术相结合的角度研究知识库的构建。
领域知识的本体建模和XML文档的生成是本文研究的重点内容。
首先,本体论满足了知识的共享和重用,可避免知识库的重复开发,领域知识的本体建模就是通过对领域知识特点的分析,在充分掌握领域知识结构的基础上,对领域知识进行抽象,建立本体模型的过程。
其次,XML是一种纯文本格式,XML技术能够保证知识库的独立性和跨平台性。
本文利用DTD作为本体与XML的结合点,给出了从本体模型到DTD的映射算法,并生成了一个以《计算机操作系统教程》作为领域知识的DTD实例,在该DTD的指导了完成了XML文档的生成。
本体论和XML技术还具有一层互补的关系。
本体论能够精确定义语义,而XML在形式上统一了语法的表示。
统一语义的本体和统一语法的XML相结合成为了构造知识库的一把利刃。
本文分四部分阐述了基于XML智能答疑系统知识库的构建,分别是:○1理论基础,○2相关技术,○3领域知识的本体建模,○4XML文档的生成。
1.3研究意义(1)以XML文档作为知识库,大大提高了知识库的可移植性,使得知识库的独立性得到的提高。
XML 本身是一种开放的标准,很多人都可以参与到XML文档的开发工作中来,这样XML便成了一个构建知识库的平台,从而促进了知识的融化与集成。
(2)由于本体建模目前还没有形成统一的标准,更没有统一的工程方法论用以指导本体的建模,所以本文也对本体建模作了尝试,并结合图形工具完成了一个本体模型的构建。
2理论基础2.1知识2.1.1知识的定义所谓知识,简而言之,就是人类对世界的认识。
这里的世界既包括远到宇宙深处的外部世界、也包括触及人类心灵的内心世界;既包括大到天体宏观世界,也包括小到原子的微观世界;即包括能够被人类直接经验的世界,也包括不能被人类经验的世界。
这里的认识是人的头脑对客观世界的反映[1]。
2.1.2知识的类型为了便于对知识进行表征,需要对知识进行分类。
通常情况下,知识可以分为陈述性知识和程序性知识。
陈述性知识包括事件、概念、定理、公理和规则等。
事件如“爱因斯坦发现了相对论”;概念有抽象和具体之分,如“学生”是一个具体概念,指“在学校读书的人[1]”,而“函数”则是一个抽象概念,其定义是“给定两个实数集D和M,若有对应法则f,使对D内每一个数x,都有唯一的一个数My与它相对应,则称f是定义在数集D上的函数[2]”。
程序性知识是指作为技巧性动作基础的知识,倾向于动力的(变化的)[3]。
直观地说,程序性知识就是指描述做某事的过程,使人或计算机照此去做[4]。
2.1.3知识的表示知识表示实际上就是对人类知识的一种描述,以把人类知识表示成计算机能够处理的数据结构[18]。
在人类世界,除了少数领域如数学领域外,知识主要是用自然语言表示的。
由于自然语言的三位一体性,即思想、方法、对象三者同时融于语言之中,因此,人类自然语言既是交流的工具,又是认知的工具,同时也是思维的工具[5]。
知识表示语言应该仿生自然语言,所谓知识表示就是指知识的形式化。
在知识表示的过程中要遵循以下一些原则[4]:①表示知识的范围是否广泛?②是否适合于推理?③是否适合于计算机处理?④是否有高效的算法?⑤能否表示不精确知识?⑥能否模块化,以便于知识分层?⑦知识和元知识能否用统一的形式表示?⑧是否适合于加入启发式信息?⑨过程性表示还是说明性表示?⑩表示方式是否自然?知识表示有两个层次,第一层是用某种数据结构如语义网络来描述知识,这个层次的知识表示主要用于对知识进行抽象,生成知识模型。
工作在这个层次上的知识表示方法(数据结构)有语义网络、框架、谓词逻辑、产生式等。
第二层是用某种具体的语言如XML、Prolog来表示实现第一层建立起的知识模型,其结果就是一个具体的知识库。
这一层的作用把知识模型转化成计算机可以存储和处理的代码。
2.2知识库简单地说,知识库就是知识的集合。
人的大脑就是一个知识库,里面存放着形形色色、内容繁杂的知识。
一台智能计算机或者一个智能系统必须要有一个知识库,这个知识库是计算机或系统做出行为的根据。
一个良好的知识库能够对系统提供很好的支持,这种支持尤其表现在系统的搜索和推理能力。
目前,知识库主要以以下几种形式存在于各种系统中:(1)嵌入源程序;(2)知识文件;(3)知识数据库[20]。