自回归分布滞后模型(ADL)的运用实验指导
- 格式:doc
- 大小:184.50 KB
- 文档页数:5
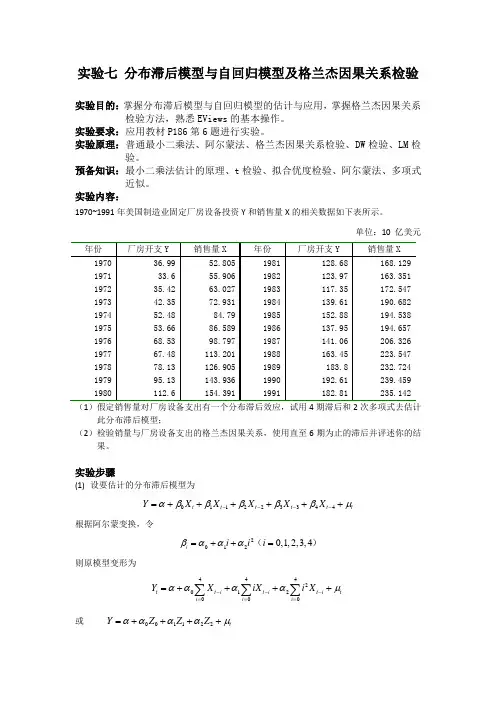
实验七 分布滞后模型与自回归模型及格兰杰因果关系检验实验目的:掌握分布滞后模型与自回归模型的估计与应用,掌握格兰杰因果关系检验方法,熟悉EViews 的基本操作。
实验要求:应用教材P186第6题进行实验。
实验原理:普通最小二乘法、阿尔蒙法、格兰杰因果关系检验、DW 检验、LM 检验。
预备知识:最小二乘法估计的原理、t 检验、拟合优度检验、阿尔蒙法、多项式近似。
实验内容:1970~1991年美国制造业固定厂房设备投资Y 和销售量X 的相关数据如下表所示。
单位:10 亿美元(1)假定销售量对厂房设备支出有一个分布滞后效应,试用4期滞后和2次多项式去估计此分布滞后模型;(2)检验销量与厂房设备支出的格兰杰因果关系,使用直至6期为止的滞后并评述你的结果。
实验步骤(1) 设要估计的分布滞后模型为011223344t t t t t t Y X X X X X αβββββμ----=++++++根据阿尔蒙变换,令20120,1,2,3,4i i i i βααα=++=()则原模型变形为44420120t t i t i t i t i i i Y X iX i X ααααμ---====++++∑∑∑或 001122t Y Z Z Z ααααμ=++++其中,01234t t t t t Z X X X X X ----=++++ 11234234t t t t Z X X X X ----=+++ 212344916t t t t Z X X X X ----=+++ 在Eviews 软件下,可通过选择Quick\Generate Series …,在出现的Generate Series by Eq …窗口分别输入“Z0=X+X(-1)+X(-2)+X(-3)+X(-4)”、“Z1=X(-1)+2*X(-2)+3*X(-3)+4*X(-4)”、“Z2=X(-1)+4*X(-2)+9*X(-3)+16*X(-4)”,生成三个序列Z0、Z1、Z2;然后作Y 关于Z0、Z1、Z2的OLS 回归,估计结果如图1.1所示。

实验六自回归分布滞后模型(ADL)的运用实验指导一、实验目的理解ADL模型的原理与应用条件,学会运用ADL模型来估计变量之间长期稳定关系。
理解从经济理论上来说,两个经济变量之间的确有长期关系采用使用该模型进行估计。
理解ADL模型的优点:不管回归项是不是1阶单整或平稳都可以进行检验和估计。
而进行标准的协整分析前,必须把变量分类成和。
二、基本概念Jorgenson(1966提出的()阶自回归分布滞后模型ADL(autoregressive distributedlag:,其中是滞后期的外生变量向量(维数与变量个数相同),且每个外生变量的最大滞后阶数为,是参数向量。
当不存在外生变量时,模型就退化为一般ARMA()模型。
如果模型中不含有移动平均项,可以采用OLS方法估计参数,若模型中含有移动平均项,线性OLS估计将是非一致性估计,应采用非线性最小二乘估计。
三、实验内容及要求(1)实验内容运用ADL模型研究1992年1月到1998年12月我国城镇居民月对数人均生活费支出yt 和对数可支配收入xt之间的长期稳定关系。
(2)实验要求在认真理解模型应用条件的基础上,通过实验掌握ADL模型的实际应用方法,并熟悉Eniews 的具体操作过程。
四、实验指导(1)数据录入打开Eviews软件,选择“File”菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Dated-regular frequency”,在“Data specification”栏中“Frequency”中选择“Monthly”即月份数据,起始时间输入1992m1即1992年1月份,止于1998m12,点击ok,见图6-1,这样就建立了一个工作文件。
图6-1 建立工作文件窗口点击File/Import,找到相应的Excel数据集,打开数据集,出现图6-2的窗口,在“Data order”选项中选择“By observation”即按照观察值顺序录入,第一个数据是从a2开始的,所以在“Upper-left data cell”中输入a2,本例有2列数据,在“Names for series or number if named in file”中输入序列的名字2,点击ok,则录入了数据,图6-3显示的xt和yt便是录入的对数可支配收入和对数人均生活费支出。




计量经济学上机操作 8实验八 分布滞后模型与自回归模型及格兰杰因果关系检验一 实验目的:掌握分布滞后模型与自回归模型的估计与应用,掌握格兰杰因果关系检验方法,熟 悉EViews 的基本操作。
二 实验要求:应用教材P168例子522案例,利用阿尔蒙法做有限分布滞后模型的估计;应用教材P173例子5.2.3案例做分布滞后模型与自回归模型的估计;应用教材 P176例子5.2.4案例额做格兰杰因果关系检验。
三实验原理:普通最小二乘法、阿尔蒙法、格兰杰因果关系检验、 DW 检验、LM 检验。
四预备知识:最小二乘法估计的原理、t 检验、拟合优度检验、阿尔蒙法、多项式近似。
五实验步骤【案例1】分布滞后模型与阿尔蒙法为了研究|1975――2002年期间中国电力基本建设投资与发电量的关系,我们可以对教材 P168例5.2.2采用经验加权法估计分布滞后模型。
尽管经验加权法具有一些优点, 但是设置权数的主观随意性较大,要求分析者对实际问题的特征有比较透彻的了解。
1建立工作工作文件并录入数据,如图8.1.图8.12模型估计与检验为了测算电力行业固定资产投资与发电量增长之间的变动关系,我们拟建立如下双对数线性模 型:slnY t = a +刀6 In Xt-i+ 他,i=0由于无法预知电力行业基本建设投资对发电量影响的时间滞后期,需要取不同的时间滞后期进 行试算。
经过试算发现,在「2阶阿尔蒙多项式变换下,滞后期数取到第 7期估计结果的经验意义 比较合理(即应该参数前面为正号,而且通过 t 检验,AIC,SC 值达到最小)。
针对所研究的问题,为 了进行比较分析,我们给出以下几个分布滞后模型无约束限制的估计结果,如表T 8.1所示(例如, 在2阶阿尔蒙多项式变换下,滞后期数取到第7期的估计结果由图8.2得到)。
表8.1多个无约束限制的分布滞后模型估计结果图8.2图8.35 2 0.9 94123-3.364143 -3.166666 无 6 2 0.9 94648-3.520954 -3.32258 有 7 2 0.9 94404-3.555819-3.356862 有 8 2 0.9 93686-3.525502 -3.326355 有 9 2 0.9 92580-3.464352-3.265523 有 10 20.991531-3.445304-3.247444无从表8.1可以看出,滞后变量参数有经济意义的只有(3,2), (6,2),(7,2),(8,2) ,(9,2)五个模型。

第六章分布滞后模型与自回归模型分析分布滞后模型(Distributed Lag Models)和自回归模型(Autoregressive Models)是常用于时间序列分析的两种方法。
本章将分别介绍这两种模型以及其在经济学和社会科学领域中的应用。
分布滞后模型是一种广义的线性回归模型,用于分析变量之间的滞后效应。
它的基本形式可以表示为:Yt = α + β1Xt + β2Xt-1 + ... + βpXt-p + et其中,Yt是被解释变量,Xt是解释变量,β1到βp是与解释变量相关的系数,et是误差项。
模型中的滞后项Xt-1到Xt-p表示X在当前时间以及过去的一段时间内对Y的影响。
分布滞后模型可以用来研究两个或多个变量之间的滞后效应,并帮助研究者了解这些变量之间的动态关系。
分布滞后模型在经济学和社会科学领域中有广泛的应用。
例如,在宏观经济学中,可以用分布滞后模型来研究货币政策对经济增长的长期影响。
在健康经济学中,可以用分布滞后模型来研究疫苗接种对流行病传播的影响。
在社会学研究中,可以用分布滞后模型来研究教育程度对就业机会的影响。
自回归模型是一种基于时间序列的统计模型,用于预测一个变量在时间上的变化。
它的基本形式可以表示为:Yt = α + φ1Yt-1 + φ2Yt-2 + ... + φpYt-p + et其中,Yt是被预测的变量,φ1到φp是自回归系数,et是误差项。
自回归模型假设当前时间的值与过去时间的值有关,并且根据过去时间的值来预测未来时间的值。
自回归模型可以帮助研究者预测变量的趋势和周期性,并提供关于未来值的信息。
自回归模型在经济学和社会科学领域中也有广泛的应用。
例如,在金融学中,可以用自回归模型来预测股票价格的变化。
在气象学中,可以用自回归模型来预测天气变化。
在市场研究中,可以用自回归模型来预测产品销售量。
总之,分布滞后模型和自回归模型是两种常用的时间序列分析方法。
它们可以帮助研究者了解变量之间的滞后效应和趋势,并用于预测未来值。

一、实训背景随着社会经济的快速发展,经济活动中滞后效应的存在愈发显著。
为了更好地理解和分析滞后效应,我们进行了分布滞后模型的实训,旨在掌握分布滞后模型的基本原理、建模方法和应用技巧。
二、实训目的1. 理解滞后效应的产生原因及其在经济活动中的表现。
2. 掌握分布滞后模型的基本原理和建模方法。
3. 学习使用R语言进行分布滞后模型的实证分析。
4. 培养实际应用分布滞后模型解决实际问题的能力。
三、实训内容1. 滞后效应的产生原因滞后效应的产生主要源于以下几个方面:(1)心理预期因素:人们的心理定势及社会习惯的作用,适应新经济条件和经济环境需要一个过程,从而表现为决策滞后。
(2)技术因素:从生产到流通再到使用,每一个环节都需要一段时间,从而形成时滞。
(3)信息传递和反馈机制:经济活动中的信息传递和反馈需要时间,导致滞后效应的产生。
2. 分布滞后模型的基本原理分布滞后模型(Distributed Lag Model,简称DLM)是一种用于分析滞后效应的统计模型。
其基本原理是将滞后变量引入回归模型,以反映滞后效应。
(1)滞后变量:滞后变量是指过去时期的、对当前被解释变量产生影响的变量。
可分为滞后解释变量与滞后被解释变量。
(2)滞后阶数:滞后阶数表示滞后变量的数量,通常根据实际研究问题和数据特点来确定。
(3)滞后结构:滞后结构描述滞后变量的时间分布,如线性滞后、非线性滞后等。
3. R语言进行分布滞后模型的实证分析(1)数据准备:收集相关数据,包括解释变量、被解释变量和滞后变量。
(2)模型选择:根据研究问题和数据特点,选择合适的分布滞后模型,如线性DLM、非线性DLM等。
(3)模型估计:使用R语言中的相关函数(如dlnm、dlnmnp等)进行模型估计。
(4)模型诊断:对估计出的模型进行诊断,如残差分析、参数检验等。
(5)结果分析:根据模型估计结果,分析滞后效应的存在、大小和方向。
四、实训过程1. 数据收集:收集我国某地区GDP、投资和消费等数据。

分布滞后模型与自回归模型实验目的:设定模型,按照一定的处理方法估计模型参数,并解释模型的经济意义,探测模型扰动项的一阶自相关性。
实验要求:(1)设定模型t tu tXY ++=βα*运用局部调整假定(其中Yt*为预期最佳值)。
(2)设定模型e X Yu tttβα=*运用局部调整假定(其中Yt*为预期最佳值)。
(3)设定模型u X Yttt++=*βα运用自适应预期假定(其中Xt*为预期值)。
(4)运用阿尔蒙多项式变换法,估计分布滞后模型u XX Yt t tt++⋯+++=-X4-t 411βββα实验原理:最小二乘估计 实验步骤:一、在局部调整假定下,先估计回归模型:*1*1*0*t t t t u Y X Y +++=-ββα得到以下回归结果:Dependent Variable: YMethod: Least Squares Date: 11/16/10 Time: 19:39 Sample (adjusted): 1981 2001 Included observations: 21 after adjustmentsVariable Coefficien t Std. Error t-StatisticProb. C -15.10403 4.729450 -3.193613 0.0050 X 0.629273 0.097819 6.433031 0.0000 Y(-1) 0.271676 0.114858 2.365315 0.0294R-squared 0.987125 Mean dependent var109.2167 Adjusted R-squared 0.985695 S.D. dependent var 51.78550 S.E. of regression 6.193728 Akaike info criterion 6.616515 Sum squared resid 690.5208 Schwarz criterion 6.765733 Log likelihood -66.47341 F-statistic 690.0561 Durbin-Watson stat 1.518595 Prob(F-statistic)0.000000t Y ^=-15.10403+0.629273Xt+0.271676Yt 1-(4.729450)(0.097819) (0.114858) t=(-3.193613)(6.433031)(2.365315)R2=0.9871252R -=0.985695F=690.0561 DW=1.518595由局部调整模型的参数关系,有:α*=δα,δββ=*0,δβ-=1*1,u u t t δ=*将上述估计结果代入得到:βδ*11-==1-0.271676=0.728324δαα*==-20.738064δββ*0==0.864001故局部调整模型的估计结果为:=Yt* -20.738064+0.864001X t模型的经济意义:该地区的销售额每增加一亿元,其预期最佳固定资产投资将增加0.864001亿元。

计量经济学课件:第七章-分布滞后模型与自回归模型上课讲义第七章分布滞后模型与自回归模型第一节分布滞后模型与自回归模型的基本概念一、问题的提出1、滞后效应的出现。
(1)在经济学分析中,研究消费函数,人们的消费行为不仅要受到当期收入的影响(绝对收入假设),还要受到前期收入的影响,甚至要受到前期消费的影响(相对收入假设)。
(2)研究投资问题,由于投资周期的原因,本年度投资的形成,与上年度,甚至再上年度的投资形成有关。
(3)运用经济政策调控宏观经济运行,经济政策的实施所产生的政策效果是一个逐步波及的扩散过程。
用计量经济学模型研究这类问题,怎样度量变量的滞后影响?怎样估计有滞后变量的模型?对于上述消费的情况,设C 表示消费,Y 表示收入,则123141t t t t t C Y Y C u ββββ--=++++对于上述投资的情况,设I 表示投资,Y 表示收入,则12314253t t t t t tI Y I I I u ααααα---=+++++ 2、静态计量经济学模型向动态计量经济学模型的扩展。
什么为“动态计量经济学模型”?二、产生滞后效应的原因1、心理预期因素的作用。
2、技术因素的作用。
3、制度因素的作用。
上述原因的结果表现为经济现象中的“惯性作用”。
二、滞后变量模型的类型1、分布滞后模型。
如果模型中没有滞后的被解释变量,即01122t t t t s t s t Y X X X X u αββββ---=++++++则模型为分布滞后模型。
由于s 可以是有限数,也可以是无限数,则分布滞后模型可分为有限分布滞后模型和无限分布滞后模型。
在分布滞后模型中,有关系数的解释如下:⑴乘数(又称倍数)的解释。
该概念首先由英国的卡恩提出(R.F.Kahn ,1931)。
所谓乘数是指,在一个模型体系里,外生变量变化一个单位,对内生变量产生的影响程度。
据此进行的经济分析称为乘数分析或乘数效应分析。
如投资乘数,是指在边际消费倾向一定的情况下,投资变动对收入带来的影响,亦即增加一笔投资,可以引起收入倍数的增加。
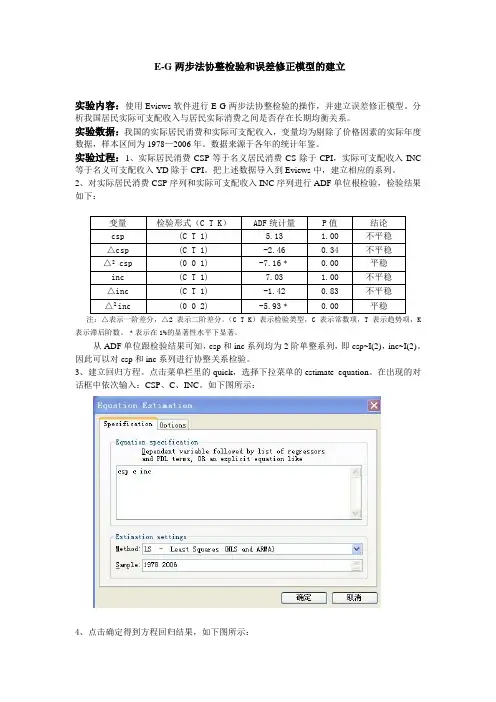
E-G两步法协整检验和误差修正模型的建立实验内容:使用Eviews软件进行E-G两步法协整检验的操作,并建立误差修正模型。
分析我国居民实际可支配收入与居民实际消费之间是否存在长期均衡关系。
实验数据:我国的实际居民消费和实际可支配收入,变量均为剔除了价格因素的实际年度数据,样本区间为1978—2006年。
数据来源于各年的统计年鉴。
实验过程:1、实际居民消费CSP等于名义居民消费CS除于CPI,实际可支配收入INC 等于名义可支配收入YD除于CPI。
把上述数据导入到Eviews中,建立相应的系列。
2、对实际居民消费CSP序列和实际可支配收入INC序列进行ADF单位根检验,检验结果如下:变量检验形式(C T K)ADF统计量P值结论csp (C T 1) 5.13 1.00 不平稳△csp (C T 1) -2.46 0.34 不平稳△2 csp (0 0 1) -7.16﹡0.00 平稳inc (C T 1) 7.03 1.00 不平稳△inc (C T 1) -1.42 0.83 不平稳△2 inc (0 0 2) -5.93﹡0.00 平稳注:△表示一阶差分,△2 表示二阶差分。
(C T K)表示检验类型,C表示常数项,T表示趋势项,K 表示滞后阶数。
﹡表示在1%的显著性水平下显著。
从ADF单位跟检验结果可知,csp和inc系列均为2阶单整系列,即csp~I(2),inc~I(2)。
因此可以对csp和inc系列进行协整关系检验。
3、建立回归方程。
点击菜单栏里的quick,选择下拉菜单的estimate equation。
在出现的对话框中依次输入:CSP、C、INC。
如下图所示:4、点击确定得到方程回归结果,如下图所示:5、在方程对象框中,单击proc,选择 make residual series,生成方程的残差系列,命名为“e”。
并对e系列进行ADF单位根检验,检验结果如下图所示:检验形式为即不包含常数项也不包含趋势项。
五 单位根检验、协整与误差修正模型【实验目的与要求】1.准确掌握单位根检验方程的形式和检验原理。
2.准确掌握单整、协整和误差修正模型的概念和形式。
3.学会利用单位根检验方法对样本序列进行协整关系检验。
4.熟练掌握运用误差修正模型对样本序列间的短期、长期关系进行分析。
5. 在老师的指导下独立完成实验,得到正确的结果,并完成实验报告。
【实验准备知识】在上个实验中,我们学习了如何运用相关分析图判断随机过程是否平稳,但这种方法比较粗略。
检验随机过程是否平稳的一种比较正式的方法就是单位根检验。
在介绍单位根检验之前,我们有必要认识几种典型的非平稳随机过程。
1. 几种典型的非平稳随机过程(1) 随机游走过程t t t u y y +=-1,t u ~ IID(0, 2σ) (5.1)随机游走过程上个实验已经介绍,这里不再赘述。
图5—1为一个00=y ,t u ~ IID(0, 1)的随机游走过程的序列图。
-8-6-4-2图5—1 一个随机游走过程的序列图(2) 随机趋势过程t t t u a y y ++=-1,t u ~ IID(0, 2σ) (5.2) 其中a 称作位移项或漂移项。
将上式作如下迭代变换:∑=---++==++++=++=t i it t t t t t u y at u a u a y u a y y 10121)( (5.3)可知,t y 由时间趋势项at 和∑=+ti iu y 10(可看作截距项)组成。
在不存在任何冲击t u 的情况下,截距项为0y 。
而每个冲击t u 都表现为截距的移动。
每个冲击u t 对截距项的影响都是持久的,导致序列的条件均值发生变化,所以称这样的过程为随机趋势过程或有漂移项的随机游走过程。
图5—2为一个t t t u y y ++=-3.01,00=y ,t u ~ IID(0, 1)的随机趋势过程的序列图。
图5—2 一个随机趋势过程的序列图图5—2表明,虽然总趋势不变,但该过程围绕趋势项上下游动。
8-3自回归分布滞后模型Ch8平稳时间序列模型8.1 分布滞后模型8.2分布滞后模型估计8.3 自回归分布滞后模型8.4案例分析8.3自回归分布滞后模型自适应预期模型局部调整模型自回归分布滞后模型1.自适应预期模型举例1.自适应预期模型我们可以将某些变量的预期值作为解释变量,纳入模型,即)6(*10ttt u X Y ++=ββ其中: 是在t时刻,预测变量X在t+1时刻的值。
由于,预期变量的预期值是不可观测的,因此,需要根据预期形成机理,对其作出某种假定。
*tX自适应预期理论(一种预期形成机理的假定)根据过去所作预期的经验,不断修正当前预期,使当前预期趋于合理。
•即,是在上期预期值的基础上,按上期预期值与当期实际值之间偏差的一定比例,去 修正当期预期值。
• 本期预期值 = 上期预期值 + 修正值)(*1*1*---+=t t t tX X XXγ其中,修正值是上期预期误差的一部分, 是修正系数。
或改写为:预期形成机理:说明t期预期值 是t期实际值与t-1期预期值的加权平均,权数是 和(1 -) γγ())7(1*1*--+=t t tXX X γγ建模代换(由于预期值无法观测,通过代换在模型中消去预期值)ttt u X Y ++=*10ββtt t t u X X Y +-++=-])1([*110γγββ*1110(1)t t t tY uXX ββγβγ--=+++11*110((1)(1)1)(1)t t t Y u Xβγγβγγ----=-++--即得●将式(7)代入原模型式(6),(8)●将原模型滞后一期并乘(1 - )得γ由(8)式减(9)式, 得,1011(1)[(1)]t t t t t Y Y X u u γγβγβγ----=++--])1([)1(1110----+-++=t t t t t u u Y X Y γγγβγβ*0β*1β*2βtv tt t t v YX Y +++=-1*2*1*0βββ(10)(11)*ˆjβ这是一个与库伊克变换相似的一阶自回归模型,通过可以计算出原模型的参数。
ARDL 模型的运用实验指导一、实验目的:理解ARDL 模型的原理与应用条件,运用ARDL 模型,估计变量之间长期关系的系数。
注意,只有当能够确定第一步所估计的变量间的长期关系是肯定存在的,而不是伪回归,那么才能应用该模型进行估计。
二、基本概念:ARDL(autoregressive distributed lag)称为自回归分布滞后模型。
ARDL 模型的一大优点,就是我们不用管变量是否同为 过程,或同为 过程,都可以用ARDL 模型来检验变量之间的长期关系,而这是标准的协整检验所做不到的。
三、实验内容及要求:运用ARDL 模型研究美国非耐用消费品支出LC(取对数形式)与真实可支配收入L Y(取对数形式),通胀率PI 之间的关系,数据为1960年1季度到1994年1季度的季度数据。
要求:在认真理解本章内容的基础上,通过实验掌握ARDL 模型的实际应用方法,并熟悉Microfit 软件的基本使用方法。
四、实验指导:ARDL 模型的主要优点在于不管回归项是(0)I 还是(1)I ,都可以进行检验和估计。
而进行标准的协整分析前,必须把变量分类成(0)I 和(1)I 。
首先,我们调用Microfit 软件读入EX6.1的数据文件。
对原始数据进行取对数作差分的处理。
由于观测值是季度数据,ARDL 模型中最大滞后阶数取4阶,利用1960年1季度到1992年4季度的样本区间进行估计,1993年1季度到1994年1季度的数据进行预测。
对应于ARDL(4,4,4)中变量LC ,L Y 和DP 的误差修正模型(ECM )如下:4440111112131t i t i i t i i t ii i i t t t t DLC a b DLC d DLY e DPI LC LY PI u δδδ---===---=+++++++∑∑∑ (6.4)检验的原假设是:变量间不存在稳定的长期关系。
即:0123:0H δδδ===备择假设是:11:0H δ≠或20δ≠或30δ≠检验123,,δδδ联合显著的统计量就是我们熟悉的F 统计量。
实验六 自回归分布滞后模型(ADL )的运用实验指导
一、实验目的
理解ADL 模型的原理与应用条件,学会运用ADL 模型来估计变量之间长期稳定关系。
理解从经济理论上来说,两个经济变量之间的确有长期关系采用使用该模型进行估计。
理解ADL 模型的优点:不管回归项是不是1阶单整或平稳都可以进行检验和估计。
而进行标准的协整分析前,必须把变量分类成(0)I 和(1)I 。
二、基本概念
Jorgenson(1966)提出的(,p q )阶自回归分布滞后模型ADL(autoregressive distributed lag):011111
i t t p t p t t q t q i t i i y y y ταφφεθεθεβ-----='=++++--+∑x ,其中t i -x 是滞后i 期
的外生变量向量(维数与变量个数相同),且每个外生变量的最大滞后阶数为i τ,i β是参数向量。
当不存在外生变量时,模型就退化为一般ARMA (,p q )模型。
如果模型中不含有移动平均项,可以采用OLS 方法估计参数,若模型中含有移动平均项,线性OLS 估计将是非一致性估计,应采用非线性最小二乘估计。
三、实验内容及要求
(1)实验内容
运用ADL 模型研究1992年1月到1998年12月我国城镇居民月对数人均生活费支出yt 和对数可支配收入xt 之间的长期稳定关系。
(2)实验要求
在认真理解模型应用条件的基础上,通过实验掌握ADL 模型的实际应用方法,并熟悉Eniews 的具体操作过程。
四、实验指导
(1)数据录入
打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,在“Workfile structure type ”栏选择“Dated-regular frequency ”,在“Data specification ”栏中“Frequency ”中选择“Monthly ”即月份数据,起始时间输入1992m1即1992年1月份,止于1998m12,点击ok ,见图6-1,这样就建立了一个工作文件。
图6-1 建立工作文件窗口
点击File/Import,找到相应的Excel数据集,打开数据集,出现图6-2的窗口,在“Data order”选项中选择“By observation”即按照观察值顺序录入,第一个数据是从a2开始的,所以在“Upper-left data cell”中输入a2,本例有2列数据,在“Names for series or number if named in file”中输入序列的名字2,点击ok,则录入了数据,图6-3显示的xt和yt便是录入的对数可支配收入和对数人均生活费支出。
图6-2
图6-3
宏观经济理论告诉我们,支出来源于收入,尤其是可支配收入,因此,从长期来看,人均生活费支出和可支配收入之间必定存在长期稳定关系。
因此可以考虑用分布滞后模型来描述二者之间的长期关系。
(2)建立一般模型
消费具有惯性,即当期消费会受历史消费支出的影响,同时也会受当期收入和当前经济实力的影响,而当前经济实力主要取决于历史收入情况,也就是说当期支出受历史收入和支出,以及当期收入影响,我们可以把当期支出关于当期收入,历史收入和支出进行回归,另外,考虑到是月份数据,还应该考虑滞后12期的可支配收入和支出。
在主窗口命令栏里输入ls yt c yt(-1) yt(-2) yt(-3) yt(-12) xt xt(-1) xt(-2) xt(-3) xt(-12),回车,即得回归结果图6-4。
从回归结果看出,模型拟合很好,但有些变量t检验未能通过,按照p值从大到小的顺序逐步剔除不显著的变量,直到每个解释变量都高度显著为止。
首先剔除xt(-3),得回归模型见
图6-5,其他解释变量的p值都有所减小,继续剔除p值最大的xt(-2),得回归结果图6-6。
图6-4
图6-5
图6-6显示,仍有yt(-3)的p值较大,继续剔除yt(-3),得回归结果6-7。
在逐步剔除不显著的解释变量过程中,模型的拟合效果变化并不大,且AIC和SC值在逐步减少,说明历史较久远的收入和支出对当期支出影响的确不大。
图6-6
图6-7
考虑到滞后1期和滞后2期的生活费支出对当期生活费支出影响的实际情况,从6-7中继续剔除p值较小的yt(-2),得回归结果图6-8。
图6-8
从6-8的的参数估计结果看出,包括常数项在内的各解释变量在显著性水平0.05下都显著,模型的R 2也很大,模型整体的显著性F 检验显示模型高度显著。
(3)模型诊断
对最后拟合模型后的残差序列进行检验,在方程估计窗口,点击view/Residual Test/Correlogram-Q-Test ,出现图6-9的对话框,在滞后阶数中输入10(84),得出模型残差的相关图6-10,显然残差为白噪声序列,说明模型拟合很好见图6-11。
也说明该模型可以作为反映城镇居民月人均生活费支出和可支配收入关系的自回归分布滞后模型(ADL )。
图6-9
-.10
-.05
.00
.05
.10
.15
5.0
5.5
6.0
6.5
1993199419951996
19971998Residual Actual Fitted。