第七章分布滞后模型与自回归模型
- 格式:ppt
- 大小:564.00 KB
- 文档页数:56


计量经济学复习知识点重点难点计量经济学知识点第一章导论1、计量经济学的研究步骤:模型设定、估计参数、模型检验、模型应用。
2、计量经济学是统计学、经济学和数学的结合。
3、计量经济学作为经济学的一门独立学科被正式确立的标志:1930年12月国际计量经济学会的成立。
4、计量经济学是经济学的一个分支学科。
第二章简单线性回归模型1、在总体回归函数中引进随机扰动项的原因:①作为未知影响因素的代表;②作为无法取得数据的已知因素的代表;③作为众多细小影响因素的综合代表;④模型的设定误差;⑤变量的观测误差;⑥经济现象的内在随机性。
2、简单线性回归模型的基本假定:①零均值假定;②同方差假定;③随机扰动项和解释变量不相关假定;④无自相关假定;⑤正态性假定。
3、OLS回归线的性质:①样本回归线通过样本均值;②估计值的均值等于实际值的均值;③剩余项ei的均值为零;④被解释变量的估计值与剩余项不相关;⑤解释变量与剩余项不相关。
4、参数估计量的评价标准:无偏性、有效性、一致性。
5、OLS估计量的统计特征:线性特性、无偏性、有效性。
6、可决系数R2的特点:①可决系数是非负的统计量;②可决系数的取值范围为[0,1];③可决系数是样本观测值的函数,可决系数是随抽样而变动的随机变量。
第三章多元线性回归模型1、多元线性回归模型的古典假定:①零均值假定;②同方差和无自相关假定;③随机扰动项和解释变量不相关假定;④无多重共线性假定;⑤正态性假定。
2、估计多元线性回归模型参数的方法:最小二乘估计、极大似然估计、矩估计、广义矩估计。
3、参数最小二乘估计的性质:线性性质、无偏性、有效性。
4、可决系数必定非负,但是根据公式计算的修正的可决系数可能为负值,这时规定为0。
5、可决系数只是对模型拟合优度的度量,可决系数越大,只是说明列入模型中的解释变量对被解释变量的联合影响程度越大,并非说明模型中各个解释变量对被解释变量的影响程度也大。
6、当R2=0时,F=0;当R2越大时,F值也越大;当R2=1时,F→∞。


练习题7.1参考解答(1)先用第一个模型回归,结果如下:22216.4269 1.008106 t=(-6.619723) (67.0592)R 0.996455 R 0.996233 DW=1.366654 F=4496.936PCE PDI =-+==利用第二个模型进行回归,结果如下:122233.27360.9823820.037158 t=(-5.120436) (6.970817) (0.257997)R 0.996542 R 0.996048 DW=1.570195 F=2017.064t t t PCE PDI PCE -=-++==(2)从模型一得到MPC=1.008106;从模型二得到,短期MPC=0.982382,长期MPC= 0.982382+(0.037158)=1.01954 练习题7.2参考答案(1)在局部调整假定下,先估计如下形式的一阶自回归模型:*1*1*0*t t t t u Y X Y +++=-ββα 估计结果如下:122ˆ15.104030.6292730.271676 se=(4.72945) (0.097819) (0.114858)t= (-3.193613) (6.433031) (2.365315)R =0.987125 R =0.985695 F=690.0561 DW=1.518595t t t Y X Y -=-++根据局部调整模型的参数关系,有****11 ttu u αδαβδββδδ===-=将上述估计结果代入得到: *1110.2716760.728324δβ=-=-=*20.738064ααδ==-*0.864001ββδ==故局部调整模型估计结果为:*ˆ20.7380640.864001ttYX =-+ 经济意义解释:该地区销售额每增加1亿元,未来预期最佳新增固定资产投资为0.864001亿元。
运用德宾h 检验一阶自相关:(121(1 1.34022d h =-=-⨯=在显著性水平05.0=α上,查标准正态分布表得临界值21.96h α=,由于21.3402 1.96h h α=<=,则接收原假设0=ρ,说明自回归模型不存在一阶自相关。

第七章 分布滞后模型与自回归模型一、判断题1. 无限分布滞后模型不可以转换为一阶自回归模型。
( F )2. 局部调整模型变换后得到的一阶自回归模型可以应用OLS 法估计。
( T )3. 估计自回归模型的问题仅在于滞后被解释变量的存在可能导致它与随机扰动项相关。
(F )4. 自回归模型的产生背景都是相同的。
( F )5. 库伊克模型和自适应预期模型都存在解释变量与随机扰动项相关问题。
( T ) 二、单项选择题1.设无限分布滞后模型为t 0t 1t-12t-2t Y = + X + X +X ++ U αβββ,且该模型满足Koyck 变换的假定,则长期影响系数为( C )。
A .0βλB . 01βλ+C .01βλ- D .不确定 2.对于分布滞后模型,时间序列的序列相关问题,就转化为( B )。
A .异方差问题B .多重共线性问题C .多余解释变量D .随机解释变量3.在分布滞后模型01122t t t t t Y X X X u αβββ--=+++++中,短期影响乘数为( D )。
A .11βα- B . 1β C .01βα- D .0β 4.对于自适应预期模型变换后的自回归模型,估计模型参数应采用( D ) 。
A .普通最小二乘法B .间接最小二乘法C .二阶段最小二乘法D .工具变量法5.经过库伊克变换后得到自回归模型,该模型参数的普通最小二乘估计量是( D ) 。
A .无偏且一致B .有偏但一致C .无偏但不一致D .有偏且不一致6.下列属于有限分布滞后模型的是( D )。
A .01122t t t t t Y X Y Y u αβββ--=+++++B .01122t t t t k t k t Y X Y Y Y u αββββ---=++++++ C . 01122t t t t t Y X X X u αβββ--=+++++ D .01122t t t t k t k t Y X X X X u αββββ---=++++++7.消费函数模型12ˆ4000.50.30.1t t t t C I I I --=+++,其中I 为收入,则当期收入t I 对未来消费2t C +的影响是:t I 增加一单位,2t C +增加( C )。



第七章滞后变量实验报告一、研究目的改革开放以来,我国对外贸易和吸引外资都取得了较快的发展,特别是20世纪90年代以来,FDI流入一直保持着迅猛的势头,对外贸易额和FDI在数量上呈现出稳定增长的趋势。
而且通常FDI对我国对外贸易额的影响会持续一定的时间段。
为了研究FDI对我国对外贸易发展规模的影响时间分布,以我国对外贸易总额为解释变量,FDI(外商直接投资)为被解释变量,建立回归模型,进行定量分析。
二、模型设定设定初始模型为:+β1X t+ U tY t=β参数说明:Y——对外贸易总额 (单位:亿元)tX——外商直接投资FDI(单位:亿美元)tU t——随机误差项收集到数据如下(见表2-1)表2-1 1985-2011年对外贸易总额和FDI数据为了考察FDI对我国对外贸易总额的影响,首先估计如下模型:+β1X t+ U tY t=β在Eviews主菜单中,命令栏中输入:Y C X,得到如下回归结果。
表2-2 初步回归结果Dependent Variable: YMethod: Least SquaresDate: 12/07/13 Time: 20:05Sample: 1985 2011Included observations: 27Coefficient Std. Error t-Statistic Prob.C -22706.10 8422.495 -2.695887 0.0124X 198.7327 15.60700 12.73356 0.0000 R-squared 0.866413 Mean dependent var 62696.55 Adjusted R-squared 0.861069 S.D. dependent var 71023.40 S.E. of regression 26472.85 Akaike info criterion 23.27681 Sum squared resid 1.75E+10 Schwarz criterion 23.37280 Log likelihood -312.2370 Hannan-Quinn criter. 23.30536 F-statistic 162.1436 Durbin-Watson stat 0.254949 Prob(F-statistic) 0.000000从回归结果来看,当期FDI对我国对外贸易额影响显著。

空间自回归模型和空间滞后模型空间自回归模型和空间滞后模型,这两个名字听起来就像是从数学教室里跑出来的怪兽,但其实它们在分析数据的时候可是大有用处哦。
想象一下,你在一个小镇上,大家的房子都挨得很近,街坊邻里关系那是密不可分。
你的朋友小张如果今天心情好,邻居小李也可能会受到影响。
空间自回归模型就是要把这种“情绪传染”的现象给捉住。
它就像是在说,哎呀,咱们小镇上,如果小张心情好,没准大家的幸福指数也跟着蹭蹭上涨呢。
再说说空间滞后模型。
这家伙有点像是你等了很久的公交车,虽然你在这儿等着,但那辆车的到来还得看其他路上的情况。
空间滞后模型就告诉我们,某个地方的现象,不光是看自己这片区域,还得考虑周围的影响。
比如说,经济发展,某个城市的增长往往跟邻近城市的经济状况息息相关。
一个地方经济繁荣,附近的地方也会跟着水涨船高。
这就好比是,你的小区里开了一家超级火爆的餐厅,周围的店铺也跟着吸引了不少顾客,大家都是捞一把。
再想象一下,如果你在聚会上,大家都在聊最近的电影,你一来就提到那部让你失望的烂片。
可别小看了这个发言,可能会影响其他人的观感哦。
空间自回归模型和空间滞后模型就是在做这种事情,分析区域之间的互动,研究他们是如何影响彼此的,真的是个非常巧妙的想法。
就像是我们日常生活中,朋友圈子里的影响,谁都逃不掉。
听起来可能有点复杂,但其实它们的运用在我们生活中随处可见。
比如说,城市规划、环境监测,甚至是疫情的传播。
这些模型就像是研究人员的秘密武器,帮助他们了解各种现象背后的奥秘。
说到疫情,谁能忘记那段特殊的日子呢?在那时,研究人员就用这些模型来分析病毒的传播路径,看看哪个地方可能会成为“重灾区”,这对公共卫生决策真是至关重要。
哎,空间模型可不是只有学术界的专属。
咱们日常生活中,有时候也得用用这些思维,想想自己的行为会对周围的人造成怎样的影响。
就像你买了新衣服,如果你开心地穿出去,朋友们看到后也可能会去买,时尚就是这样流行开来的。


空间滞后模型和空间自回归模型空间滞后模型(Spatial Lag Model)和空间自回归模型(Spatial Autoregressive Model)是空间计量经济学中常用的两种模型,用于分析空间数据中的空间依赖性。
空间滞后模型是一种描述因变量与其邻近地区的自变量之间的依赖关系的模型。
它假设一个地区的因变量取决于该地区的自身特征以及其邻近地区的特征。
换句话说,该模型认为一个地区的因变量受到其邻近地区因变量的影响。
空间滞后模型可以用以下公式表示:Y = ρWy + Xβ + ε。
其中,Y是因变量,Wy是空间权重矩阵,ρ是空间滞后参数,X是自变量矩阵,β是自变量系数,ε是误差项。
空间滞后模型考虑了空间上的依赖性,可以用来解释因变量的空间聚集现象。
空间自回归模型是一种描述因变量与其邻近地区的因变量之间的依赖关系的模型。
它假设一个地区的因变量取决于该地区的自身特征以及其邻近地区的因变量。
换句话说,该模型认为一个地区的因变量受到其邻近地区因变量的影响。
空间自回归模型可以用以下公式表示:Y = ρWY + Xβ +ε。
其中,Y是因变量,W是空间权重矩阵,ρ是空间自回归参数,X是自变量矩阵,β是自变量系数,ε是误差项。
空间自回归模型考虑了空间上的依赖性,可以用来解释因变量的空间自相关现象。
这两种模型都考虑了空间上的依赖性,但是它们的依赖关系不同。
空间滞后模型是因变量与邻近地区的自变量之间的依赖关系,而空间自回归模型是因变量与邻近地区的因变量之间的依赖关系。
在实际应用中,选择使用哪种模型取决于具体问题和数据的特征。
总结起来,空间滞后模型和空间自回归模型是两种常用的空间计量经济学模型,用于分析空间数据中的空间依赖性。
它们都考虑了因变量与邻近地区之间的依赖关系,但是依赖关系的对象不同,一个是自变量,一个是因变量。
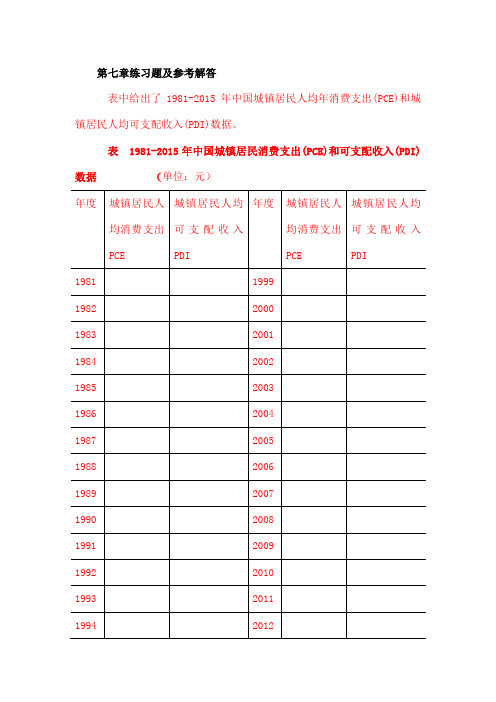
第七章练习题及参考解答表中给出了1981-2015年中国城镇居民人均年消费支出(PCE)和城镇居民人均可支配收入(PDI)数据。
表 1981-2015年中国城镇居民消费支出(PCE)和可支配收入(PDI)数据(单位:元)估计下列模型:(1) 解释这两个回归模型的结果。
(2) 短期和长期边际消费倾向(MPC)是多少分析该地区消费同收入的关系。
(3) 建立适当的分布滞后模型,用库伊克变换转换为库伊克模型后进行估计,并对估计结果进行分析判断。
【练习题参考解答】(1) 解释这两个回归模型的结果。
Dependent Variable: PCEMethod: Least SquaresDate: 03/10/18 Time: 09:12Sample: 1981 2005Included observations: 25Variable CoefficientStd.Errort-StatisticProb.CPDIR-squared Mean dependentvarAdjusted R-squared . dependent var. of regression Akaike infocriterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watsonstat Prob(F-statistic)收入跟消费间有显着关系。
收入每增加1元,消费增加元。
Dependent Variable: PCEMethod: Least SquaresDate: 03/10/18 Time: 09:13Sample(adjusted): 1982 2005Included observations: 24 after adjusting endpointsVariable CoefficientStd.Errort-StatisticProb.C PDIPCE(-1)R-squared Mean dependentvarAdjusted R-squared . dependent var. of regression Akaike infocriterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watsonstat Prob(F-statistic)(2) 短期和长期边际消费倾向(MPC)是多少分析该地区消费同收入的关系。



自回归分布滞后模型自回归分布滞后模型(ARIMA)是一种可用于自回归过程的统计建模技术。
它的主要优点是它能够使用时间序列数据预测未来或者检测和调整自回归过程中可能存在的性质变化。
ARIMA是一种重要的时间序列分析技术,它可以用来预测变量的自回归过程(AR),如动量(MA)和季节性过程(I)。
一、什么是自回归分布滞后模型(ARIMA)自回归分布滞后模型(ARIMA)是一种用于分析和预测时间序列数据的统计学方法。
ARIMA模型可以帮助研究者分析并预测事件的发生情况,以及由事件的发生情况产生的结果。
ARIMA模型的结构可以被定义为简单的一般线性二阶拟合模型。
二、ARIMA模型的有效性ARIMA模型通常证明是有效预测时间序列数据的一种有效方法。
无论是实现和应用于单变量和多变量时间序列上,ARIMA模型都可以为研究者提供可靠的预测结果。
在单变量的时间序列数据分析中,ARIMA 模型可以帮助研究者发现一些未知的趋势,从而判断该变量在未来的运动趋势。
三、ARIMA模型的应用ARIMA模型的应用,可以分为零度模型和非零度模型应用。
它们可以应用于单变量时间序列(零度模型)和多变量时间序列(非零度模型)上。
零度模型可以用来描述和预测单变量时间序列,而非零度模型可以用来描述和预测多变量时间序列中变量之间的关系。
此外,ARIMA模型还可以应用于时间序列平滑、广义线性模型、转换型自回归等领域。
四、ARIMA模型的优缺点ARIMA模型的优点是它能够有效地描述时间序列的差异性,可以使用时间序列数据预测未来或者检测已经发生的变化,进而找出时间序列中可能存在的自回归过程的特征,从而可以有效的预测和预测时间序列的发展趋势。
缺点是在使用自回归过程时,数据分析人员必须对变量进行较小的调整,以保持变量在ARIMA模型中是稳定的,而如果调整失败,将无法得到良好的分析结果。