判定树判定表举例
- 格式:ppt
- 大小:1.62 MB
- 文档页数:7
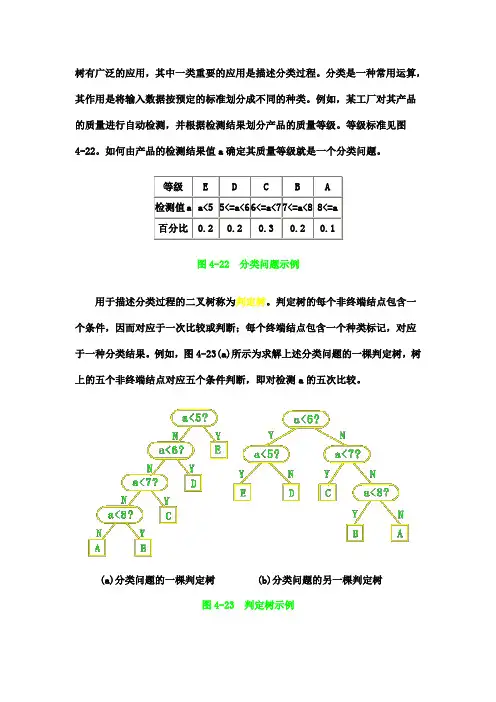
树有广泛的应用,其中一类重要的应用是描述分类过程。
分类是一种常用运算,其作用是将输入数据按预定的标准划分成不同的种类。
例如,某工厂对其产品的质量进行自动检测,并根据检测结果划分产品的质量等级。
等级标准见图4-22。
如何由产品的检测结果值a 确定其质量等级就是一个分类问题。
图4-22 分类问题示例用于描述分类过程的二叉树称为判定树。
判定树的每个非终端结点包含一个条件,因而对应于一次比较或判断;每个终端结点包含一个种类标记,对应于一种分类结果。
例如,图4-23(a)所示为求解上述分类问题的一棵判定树,树上的五个非终端结点对应五个条件判断,即对检测a 的五次比较。
(a)分类问题的一棵判定树(b)分类问题的另一棵判定树图4-23 判定树示例易知一棵判定树描述了一种分类方法。
图4-23(a)中判定树对应的分类算法如下:char classify1(float x)/ * 依给定标准将检测值x区分成相应的质量等级作为返回值 */{ if(x<5) return ('E');else if(x<6) return('D');else if(x<7)return('C');else if(x<8) return('B');else return('A');}利用这个算法,可由产品的检测结果值x确定其质量等级。
当一个分类算法需要反复使用时,其时间性能就值得进一步考虑。
假如进行上述产品质量自动分类(定等级)的工厂的产量很大,上述分类算法就将被频繁地重复使用,这时就需要考虑其时间性能。
假设需要分级的产品有N=100000件,并且这批产品的等级分布如图4-22中表格的第三行所示。
某等级产品总比较次数=某等级的“产品数”X单个检测的“比较次数”比如,D级产品数为N*20%个,为区分出一件产品是D级的,需进行2次比较。
那么,D级产品总比较次数=N*20%*2=100000*0.2*2=40000。
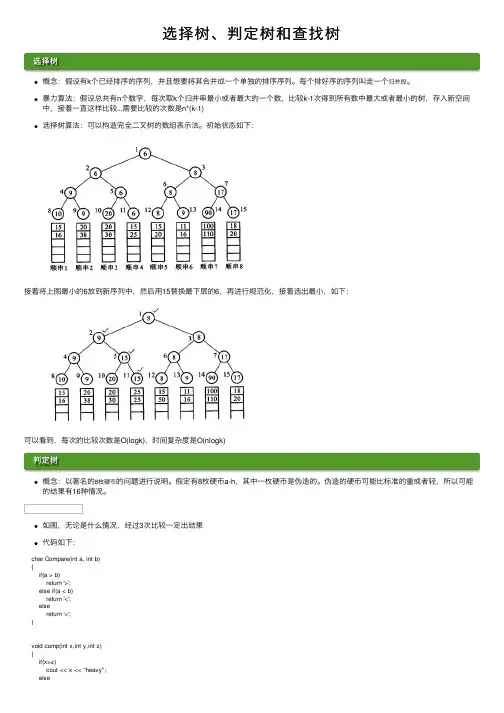
选择树、判定树和查找树选择树概念:假设有k个已经排序的序列,并且想要将其合并成⼀个单独的排序序列。
每个排好序的序列叫⾛⼀个归并段。
暴⼒算法:假设总共有n个数字,每次取k个归并串最⼩或者最⼤的⼀个数,⽐较k-1次得到所有数中最⼤或者最⼩的树,存⼊新空间中,接着⼀直这样⽐较...需要⽐较的次数是n*(k-1)选择树算法:可以构造完全⼆叉树的数组表⽰法。
初始状态如下:接着将上图最⼩的6放到新序列中,然后⽤15替换最下层的6,再进⾏规范化,接着选出最⼩,如下:可以看到,每次的⽐较次数是O(logk),时间复杂度是O(nlogk)判定树概念:以著名的8枚硬币的问题进⾏说明。
假定有8枚硬币a-h,其中⼀枚硬币是伪造的。
伪造的硬币可能⽐标准的重或者轻,所以可能的结果有16种情况。
如图,⽆论是什么情况,经过3次⽐较⼀定出结果代码如下:char Compare(int a, int b){if(a > b)return '>';else if(a < b)return '<';elsereturn '=';}void comp(int x,int y,int z){if(x>z)cout << x << "heavy";elsecout << y << "light";}void eightcoins(){int a,b,c,d,e,f,g,h;cin >> a >> b >> ... >> h;switch(Compare(a+b+c,d+e+f)) {case '=':if(g>h)comp(g,h,a)elsecomp(h,g,a);break;case '>':switch(Compare(a+d,b+e)) {case '=':comp(c,f,a);break;case '>':comp(a,e,b);break;case '<':comp(b,d,a);break;}break;case '<':switch(Compare(a+d,b+e)) {case '=':comp(f,c,a);break;case '>':comp(d,b,a);break;case '<':comp(e,a,b);break;}break;}}查找树 ⼀般来说,查找树指的是⼆叉查找树,其查找过程是从根结点⼀直向下查找,时间复杂度为O(logn)。

折半查找判定树及平均查找长度从折半查找的过程看,以有序表的中间记录作为比较对象,并以中间记录将表分割为两个子表,对子表继续上述操作。
所以,对表中每个记录的查找过程,可用二叉树来描述,二叉树中的每个结点对应有序表中的一个记录,结点中的值为该记录在表中的位置。
通常称这个描述折半查找过程的二叉树为折半查找判定树。
长度为n的折半查找判定树的构造方法为:⑴当n=0时,折半查找判定树为空;⑵当n>0时,折半查找判定树的根结点是有序表中序号为mid=(n+1)/2的记录,根结点的左子树是与有序表r[1] ~ r[mid-1]相对应的折半查找判定树,根结点的右子树是与r[mid+1] ~ r[n]相对应的折半查找判定树。
例如,长度为10的折半查找判定树的具体生成过程为:⑴在长度为10的有序表中进行折半查找,不论查找哪个记录,都必须先和中间记录进行比较,而中间记录的序号为(1+10)/2=5(注意是整除即向下取整),即判定树的根结点是5,如图7-2(a)所示;⑵考虑判定树的左子树,即将查找区间调整到左半区,此时的查找区间是[1,4],也就是说,左分支上为根结点的值减1,代表查找区间的高端high,此时,根结点的左孩子是(1+4)/2=2,如图7-2(b)所示;⑶考虑判定树的右子树,即将查找区间调整到右半区,此时的查找区间是[6,10],也就是说,右分支上为根结点的值加1,代表查找区间的低端low,此时,根结点的右孩子是(6+10)/2=8,如图7-2(c)所示;⑷重复⑵⑶步,依次确定每个结点的左右孩子,如图7-2(d)所示。
历史老照片不能说的秘密慈禧军阀明末清初文革晚清对于折半查找判定树,需要补充以下两点:⑴折半查找判定树是一棵二叉排序树,即每个结点的值均大于其左子树上所有结点的值,小于其右子树上所有结点的值;⑵折半查找判定树中的结点都是查找成功的情况,将每个结点的空指针指向一个实际上并不存在的结点——称为外结点,所有外结点即是查找不成功的情况,如图7-2(e)所示。


软件工程判定表和判定树题目摘要:1.软件工程判定表和判定树的概念2.判定表的构成和应用3.判定树的构成和应用4.判定表和判定树在软件工程中的重要性5.总结正文:软件工程是一门以计算机软件开发与维护为主要研究对象的学科。
在软件开发过程中,判定表和判定树是经常使用的工具,它们可以帮助开发人员更好地理解需求、设计方案以及测试软件。
下面,我们来详细了解一下这两个工具。
1.软件工程判定表和判定树的概念判定表是一种用于描述软件需求的表格,它由行和列组成,行表示各种条件,列表示各种结果。
判定树则是一种图形化的表示方法,它由若干个判定节点和结果节点组成,根据不同的条件进行分支,最终得到一个结果。
2.判定表的构成和应用判定表通常由四个要素构成,分别是:条件、动作、条件结果和动作结果。
条件是用于判断的依据,动作是在满足条件时需要执行的操作,条件结果和动作结果分别表示条件满足和不满足时的结果。
判定表的应用十分广泛,它可以用于需求分析、设计方案和测试用例的编写等。
3.判定树的构成和应用判定树是一种层次化的判定表,它由多个判定节点和结果节点组成。
判定节点表示一个条件,结果节点表示一个结果。
判定树通常采用“自上而下”的方式进行判定,即从根节点开始,根据条件选择不同的分支,最终得到一个结果。
判定树在软件工程中的应用主要包括:功能测试、性能测试和兼容性测试等。
4.判定表和判定树在软件工程中的重要性判定表和判定树是软件工程中非常重要的工具,它们可以帮助开发人员更好地理解需求、设计方案以及测试软件。
通过使用判定表和判定树,可以提高软件开发的效率和质量,降低维护成本。
5.总结判定表和判定树是软件工程中常用的工具,它们在需求分析、设计方案和测试用例编写等方面发挥着重要作用。


软件工程判定表和判定树题目
摘要:
1.软件工程判定表和判定树的概念
2.软件工程判定表的特点与应用
3.软件工程判定树的特点与应用
4.判定表和判定树在软件工程中的重要性
正文:
在软件工程领域,判定表和判定树是两种常用的工具,用于分析和解决复杂的问题。
它们可以帮助工程师们更好地理解问题,从而找到有效的解决方案。
首先,让我们来看看软件工程判定表。
判定表是一个二维表,其中行表示条件,列表示动作或结果。
它可以用来描述一个系统的行为,或者用来测试一个系统的功能。
判定表的主要特点是灵活性和清晰性。
通过判定表,工程师们可以清晰地看到所有可能的情况和相应的处理方法。
这使得判定表在软件设计和测试过程中非常有用。
接下来,我们看看软件工程判定树。
判定树是一种分层结构,它把一个复杂问题分解为一系列简单的问题。
每个内部节点表示一个条件,每个分支表示一个结果,每个叶子节点表示一个解决方案。
判定树的主要特点是逻辑性和层次性。
通过判定树,工程师们可以清晰地看到问题的逻辑关系和解决方案的层次关系。
这使得判定树在软件设计和测试过程中也非常有用。
判定表和判定树在软件工程中都非常重要。
它们可以帮助工程师们更好地
理解问题,找到有效的解决方案,提高软件的质量和效率。
同时,它们也可以用来培训新员工,提高团队的协作效率。

判定表设计用例案例
# 场景一:正常购买。
用户:普通乔。
操作:投入硬币,选择商品,按下购买按钮。
预期结果:售货机吐出商品,找零(如果有的话)。
测试用例:
1. 乔投入5块钱,买了一瓶3块钱的可乐,机器应该吐出可乐和2块钱的零钱。
2. 乔投入10块钱,买了一包5块钱的薯片,机器应该吐出薯片和5块钱的零钱。
# 场景二:找零不足。
用户:小气李。
操作:投入硬币,选择商品,按下购买按钮。
预期结果:售货机吐出商品,但由于找零不足,应该显示“找零不足”并退还硬币。
测试用例:
1. 小气李投入1块钱,想买一瓶2块钱的矿泉水,机器应该退还1块钱,并显示“找零不足”。
2. 小气李投入3块钱,想买一瓶2块钱的可乐,机器应该吐出可乐,但因为找零不足,不退还1块钱。
# 场景三:商品缺货。
用户:贪心赵。
操作:投入硬币,选择一个已经售罄的商品,按下购买按钮。
预期结果:售货机显示“商品缺货”,并退还硬币。
测试用例:
1. 贪心赵投入5块钱,选择了一个已经卖完的巧克力棒,机器应该退还5块钱,并显示“商品缺货”。
2. 贪心赵投入10块钱,选择了一个还有库存的饮料,机器应该正常吐出饮料和找零。
# 场景四:机器故障。
用户:倒霉钱。
操作:投入硬币,选择商品,按下购买按钮。
预期结果:售货机显示“机器故障”,并退还所有硬币。
测试用例:
1. 倒霉钱投入5块钱,机器突然卡住,应该退还5块钱,并显示“机器故障”。
2. 倒霉钱投入10块钱,机器正常工作,应该吐出商品和找零。
![专题4 判定树及判定表练习[1]](https://uimg.taocdn.com/6543e1972f60ddccda38a0c2.webp)

软件⼯程详细设计在完成前置的总体设计报告后,就应该开始着⼿于详细设计了,在这⼀步骤中,我们将需要去细化总体设计中提出的模块,详细的设计出每个模块的作⽤、算法,各个模块间的结构关系,通过需求分析中的结果,利⽤总体设计提出的⼤致框架设计出满⾜客户需求的软件系统产品。
⼀、为什么需要详细设计在总体设计完成后,应当对系统的整体有了⼤概的⼀个了解,但在没有对各个模块提出更为详细的要求的情况下,程序员难以对系统拥有准确的判断,从⽽导致系统运⾏效率低下,结构不清晰等等的问题,⽽在详细设置中,将会提出对每⼀个模块的性能要求、流程要求、⽤户界⾯要求等⼀系列详细的要求,这将会令编码者在编码实现的过程中思路更为清晰,减少编程过程中因合作产⽣的混乱,提⾼整个程序的开发效率。
⼆、程序的结构化设计“模块化设计是指在进⾏程序设计时将⼀个⼤程序按照功能划分为若⼲个⼩程序模块,每个⼩程序模块完成⼀个确定的功能,并在这些模块间建⽴必要的联系,通过模块的互相协作完成整个功能的程序设计⽅法。
”在我们刚开始学习c语⾔程序设计时,我们通常习惯将所有的代码按照⾃⼰的思路写在同⼀个.c⽂件当中,虽然程序可以实现相应的功能,并且作者只需要标注良好的注释,就能在回看代码时重新理解代码的含义。
但当程序需要分享或者⼯程量过于庞⼤需要多⼈协作完成⼀项程序时,这种⾯向过程编程的⽅式将是极其没有效率的,就如同在运动会上的接⼒赛跑,唯有当⼀个⼈完成了指定的任务和功能后,后⾯的成员才能开始其负责部分的代码,所以这种编程⽅法并不适⽤于⼤项⽬。
⽽程序的结构化设计很好的弥补了⾯向过程编程难以多⼈协作的问题,它将⼀个⼤程序拆分成⼀个⼀个⼩零件,每⼀个零件都有其⾃⾝的功能,并且零件便于程序测试,在每完成⼀个零件后可单独对其进⾏各种测试保证程序的运⾏正确⽆误,在完成所有的零件后,由⼀根主轴将所有的零件穿起来,利⽤零件的相互转换作为参数和返回值实现不同的程序功能。
同时模块化设计实现的程序也便于后期程序的维护,就如同⼀辆汽车,某个部件出现损坏或过时了,只需更换对应的部件即可,⽽模块化程序在出现错误时也只需对相应的部分进⾏修改更新,⽽在程序需要添加功能时,也只需要再制造所需要的零件进⾏组装即可。

软件工程判定表和判定树题目(原创实用版)目录1.软件工程判定表和判定树的概念2.软件工程判定表的特点与应用3.软件工程判定树的特点与应用4.判定表与判定树在软件工程中的重要性正文软件工程是一门关于计算机软件设计、开发、测试、维护和管理的学科。
在软件工程中,判定表和判定树是常用的工具,用于帮助开发人员分析和解决各种问题。
本文将详细介绍软件工程判定表和判定树的概念、特点与应用,以及它们在软件工程中的重要性。
一、软件工程判定表和判定树的概念1.判定表:判定表是一种表格,用于表示一个或多个条件与一个动作之间的关系。
它通常由条件列、动作列和条件动作关系列组成。
条件动作关系列描述了在特定条件下应该采取的动作。
判定表通常用于处理复杂的条件判断,以指导程序的执行流程。
2.判定树:判定树是一种决策树,用于表示一个或多个条件与一个动作之间的关系。
它通常由条件节点、动作节点和条件动作边构成。
条件节点表示一个条件,动作节点表示一个动作。
条件动作边表示在特定条件下应该采取的动作。
判定树通常用于处理复杂的条件判断,以指导程序的执行流程。
二、软件工程判定表的特点与应用1.特点:判定表具有明确的结构,易于理解和维护;可以处理复杂的条件判断;可以有效地降低程序的复杂度。
2.应用:判定表广泛应用于软件工程的各个领域,例如,在编译器中用于语法分析,在数据库系统中用于数据完整性检查,在业务流程管理中用于工作流设计等。
三、软件工程判定树的特点与应用1.特点:判定树具有层次结构,易于理解和维护;可以处理复杂的条件判断;可以有效地降低程序的复杂度。
2.应用:判定树广泛应用于软件工程的各个领域,例如,在编译器中用于语法分析,在数据库系统中用于数据完整性检查,在业务流程管理中用于工作流设计等。
四、判定表与判定树在软件工程中的重要性判定表和判定树在软件工程中具有重要意义,因为它们可以帮助开发人员更好地处理复杂的条件判断,降低程序的复杂度,提高软件的可读性、可维护性和可扩展性。
1、招聘考试考核数学、英语、计算机三门课程,录取规则是: (1)总分240分以上(含)录取。
(2)总分在240分以下(不含),180分以上(含)的,如果数学和英语成绩均在60分以上(含),需要参加面试;如果数学或英语中有1门成绩在60分以下(不含)的,需复试该课程后再决定是否录取。
(3)其他情况不录取。
画出此项处理的判定树。
(10分)2、某航空公司规定,乘客可以免费托运重量不超过30公斤的行李。
当行李重量超过30公斤时,对头等舱的国内乘客超重部分每公斤收费4元,对其他舱的国内乘客超重部分每公斤收费6元,对外国乘客超重部分每公斤收费比国内乘客多一倍。
根据描述绘出判定表。
3、某企业库存量监控的处理规则如下表:录取规则240录取 180≤总分<240总分<180不录取 数学≥60数学<606060英语<6060面试复试 不录取库存量≤0——————————————缺货处理库存下限<库存量≤储备定额——————订货处理储备定额<库存量≤库存上限——————正常处理库存量>库存上限——————————上限报警0<库存量≤库存下限—————————下限报警要求:画出判定表及判定树。
(1)判定表。
(2>储备定额正常处理>0库存量>上限订货处理<=储备定额<=上限上限报警<下限下限报警<=0 缺货处理4、某彩电生产企业根据销售商欠款时间长短和现有库存量情况处理彩电供货方案的结构化语言可表示为:IF 欠款时间≤30天IF 需要量≤库存量THEN 立即发货ELSE先按库存量发货,生产出来后再补发ELSEIF 欠款时间≤90天 THENIF 需求量≤库存量THEN 先付款再发货ELSE不发货ELSE 要求先付欠款请将结构化语言表达的方案用判定表和判定树表达。
用判定表表达如下:用判定树表达如下:5.某工厂生产两种产品A和B ,凡工人每月的实际生产量超过计划指标者均有奖励。
实用文档之"1、招聘考试考核数学、英语、计算机三门课程,录取规则是:"(1)总分240分以上(含)录取。
(2)总分在240分以下(不含),180分以上(含)的,如果数学和英语成绩均在60分以上(含),需要参加面试;如果数学或英语中有1门成绩在60分以下(不含)的,需复试该课程后再决定是否录取。
(3)其他情况不录取。
画出此项处理的判定树。
(10分)2、某航空公司规定,乘客可以免费托运重量不超过30公斤的行李。
当行李重量超过30公斤时,对头等舱的国内乘客超重部分每公斤收费4元,对其他舱的国内乘客超重部分每公斤收费6元,对外国乘客超重部分每公斤收费比国内乘客多一倍。
根据描述绘出判定表。
录取规则240录取 180≤总分<240总分<180不录取 数学≥60数学<60英语≥6060英语<6060面试复试 不录取3、某企业库存量监控的处理规则如下表:库存量≤0——————————————缺货处理库存下限<库存量≤储备定额——————订货处理储备定额<库存量≤库存上限——————正常处理库存量>库存上限——————————上限报警0<库存量≤库存下限—————————下限报警要求:画出判定表及判定树。
(1)判定表。
(2>储备定额正常处理>0库存量>上限订货处理<=储备定额<=上限上限报警<下限下限报警<=0 缺货处理4、某彩电生产企业根据销售商欠款时间长短和现有库存量情况处理彩电供货方案的结构化语言可表示为:IF 欠款时间≤30天IF 需要量≤库存量THEN 立即发货ELSE先按库存量发货,生产出来后再补发ELSEIF 欠款时间≤90天 THEN IF 需求量≤库存量 THEN 先付款再发货 ELSE不发货ELSE 要求先付欠款请将结构化语言表达的方案用判定表和判定树表达。
用判定表表达如下:用判定树表达如下:5.某工厂生产两种产品A 和B ,凡工人每月的实际生产量超过计划××要求先付欠款× 不发货 × 先付款,再发货 × 先按库存量发货,生产出来后再补发 × 立即发货应采取的 行 动 N Y N Y N Y 需求量≤库存量 N N Y Y N N 欠款时间>90天 N N N N Y Y 欠款时间≤30天 条 件6 5 4 3 2 1 决策规则号供货方案≤30天>30天 ≤90天>90天需求量≤库存需求量>库存量需求量≤库存量 需求量>库存量立即发货 先按库存发货, 生产后再补发 先付款,再发不发货 通知先付欠欠款时间需求与库存 处理结果指标者均有奖励。
判定树和判定表判定树⼜称决策树,是⼀种描述加⼯的图形⼯具,适合描述问题处理中具有多个判断,⽽且每个决策与若⼲条件有关。
使⽤判定树进⾏描述时,应该从问题的⽂字描述中分清哪些是判定条件,哪些是判定的决策,根据描述材料中的联结词找出判定条件的从属关系、并列关系、选择关系,根据它们构造判定树。
【例4.5】某⼯⼚对⼯⼈的超产奖励政策为:该⼚⽣产两种产品A和B。
凡⼯⼈每⽉的实际⽣产量超过计划指标者均有奖励。
奖励政策为:对于产品A的⽣产者,超产数N⼩于或等于100件时,每超产1件奖励2元;N⼤于100件⼩于等于150件时,⼤于100件的部分每件奖励2.5元,其余的每件奖励⾦额不变;N⼤于150件时,超过150件的部分每件奖励3元,其余按超产150件以内的⽅案处理。
对于产品B的⽣产者,超产数N⼩于或等于50件时,每超产1件奖励3元;N⼤于50件⼩于等于100件时,⼤于50件的部分每件奖励4元,其余的每件奖励⾦额不变;N⼤于100件时,超过100件的部分每件奖励5元,其余按超产100件以内的⽅案处理。
上述处理功能⽤判定树描述,如下图所⽰:这⼀判定树⽐起⽂字叙述,使⼈⼀⽬了然,清晰地表达了在什么情况下采取什么策略,不易产⽣逻辑上的混乱。
因⽽判定树是描述基本处理逻辑功能的有效⼯具。
==============================================判定表由四部分组成。
第⼀部分即①表⽰的部分,判定标的左上部称为基本条件项,列出各种可能的条件。
第⼆部分即②表⽰的部分,判定标的右上部称为条件项,它列出了各种可能的条件组合。
第三部分即③表⽰的部分,判定标的左下部称为基本动作项,它列出了所有的操作。
第四部分即④表⽰的部分,判定标的右下部称为动作项,它列出在对条件组合下所选的操作。
【例4.6】以学⽣的奖学⾦评定为例,说明判定表的应⽤。
奖励的⽬的在于⿎励学⽣的品学兼优,此处理功能是要合理确定奖学⾦评定等级。
1、招聘考试考核数学、英语、计算机三门课程,录取规则是:欧阳歌谷(2021.02.01)(1)总分240分以上(含)录取。
(2)总分在240分以下(不含),180分以上(含)的,如果数学和英语成绩均在60分以上(含),需要参加面试;如果数学或英语中有1门成绩在60分以下(不含)的,需复试该课程后再决定是否录取。
(3)其他情况不录取。
画出此项处理的判定树。
(10分)2、某航空公司规定,乘客可以免费托运重量不超过30公斤的行李。
当行李重量超过30公斤时,对头等舱的国内乘客超重部分每公斤收费4元,对其他舱的国内乘客超重部分每公斤收费6元,对外国乘客超重部分每公斤收费比国内乘客多一倍。
根据描述绘出判定表。
录取规则240录取 180≤总分<240总分<180不录取 数学≥60数学<606060英语<6060面试复试 不录取3库存量≤0——————————————缺货处理库存下限<库存量≤储备定额——————订货处理 储备定额<库存量≤库存上限——————正常处理 库存量>库存上限——————————上限报警 0<库存量≤库存下限—————————下限报警 要求:画出判定表及判定树。
(1(2)判定树。
>储备定额正常处理 >0 库存量>上限订货处理<=储备定额<=上限上限报警 <下限下限报警<=0 缺货处理4、某彩电生产企业根据销售商欠款时间长短和现有库存量情况处理彩电供货方案的结构化语言可表示为: IF 欠款时间≤30天 IF 需要量≤库存量THEN 立即发货 ELSE先按库存量发货,生产出来后再补发 ELSEIF 欠款时间≤90天 THEN IF 需求量≤库存量 THEN 先付款再发货 ELSE 不发货ELSE 要求先付欠款请将结构化语言表达的方案用判定表和判定树表达。
用判定表表达如下:用判定树表达如下:5.某工厂生产两种产品A 和B ,凡工人每月的实际生产量超过计划指标者均有奖励。