第05讲 数据字典与判定树判定表
- 格式:ppt
- 大小:3.55 MB
- 文档页数:22
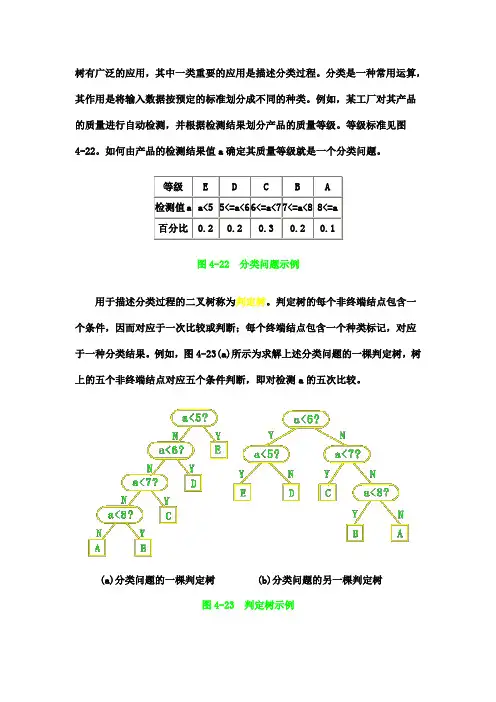
树有广泛的应用,其中一类重要的应用是描述分类过程。
分类是一种常用运算,其作用是将输入数据按预定的标准划分成不同的种类。
例如,某工厂对其产品的质量进行自动检测,并根据检测结果划分产品的质量等级。
等级标准见图4-22。
如何由产品的检测结果值a 确定其质量等级就是一个分类问题。
图4-22 分类问题示例用于描述分类过程的二叉树称为判定树。
判定树的每个非终端结点包含一个条件,因而对应于一次比较或判断;每个终端结点包含一个种类标记,对应于一种分类结果。
例如,图4-23(a)所示为求解上述分类问题的一棵判定树,树上的五个非终端结点对应五个条件判断,即对检测a 的五次比较。
(a)分类问题的一棵判定树(b)分类问题的另一棵判定树图4-23 判定树示例易知一棵判定树描述了一种分类方法。
图4-23(a)中判定树对应的分类算法如下:char classify1(float x)/ * 依给定标准将检测值x区分成相应的质量等级作为返回值 */{ if(x<5) return ('E');else if(x<6) return('D');else if(x<7)return('C');else if(x<8) return('B');else return('A');}利用这个算法,可由产品的检测结果值x确定其质量等级。
当一个分类算法需要反复使用时,其时间性能就值得进一步考虑。
假如进行上述产品质量自动分类(定等级)的工厂的产量很大,上述分类算法就将被频繁地重复使用,这时就需要考虑其时间性能。
假设需要分级的产品有N=100000件,并且这批产品的等级分布如图4-22中表格的第三行所示。
某等级产品总比较次数=某等级的“产品数”X单个检测的“比较次数”比如,D级产品数为N*20%个,为区分出一件产品是D级的,需进行2次比较。
那么,D级产品总比较次数=N*20%*2=100000*0.2*2=40000。

选择题
在判定树中,每一个非叶节点代表:
A. 一个属性测试的结果(正确答案)
B. 一个最终的分类结果
C. 一个数据集的样本
D. 一个判定表的条目
判定表与判定树相比,哪个更适合处理复杂的逻辑条件?
A. 判定树
B. 判定表(正确答案)
C. 两者相同
D. 都不适合
判定树的根节点通常表示:
A. 数据集的最优属性
B. 数据集的第一个属性(正确答案,若未优化则通常如此)
C. 数据集的最后一个属性
D. 数据集的类别标签
在构建判定树时,信息增益用于:
A. 选择最优的划分属性(正确答案)
B. 计算节点的纯度
C. 确定树的深度
D. 评估模型的准确率
判定表中,每一行代表:
A. 一个数据样本
B. 一个条件组合及其对应的动作(正确答案)
C. 一个判定树的节点
D. 一个属性的取值范围
判定树中,叶节点通常表示:
A. 数据集的划分结果
B. 一个属性的测试条件
C. 最终的分类或回归结果(正确答案)
D. 数据集的一个子集
当判定树的深度过大时,可能导致的问题是:
A. 过拟合(正确答案)
B. 欠拟合
C. 计算速度加快
D. 模型稳定性增强
在将判定表转换为判定树时,判定表中的每一个条件列对应:
A. 判定树的一个叶节点
B. 判定树的一个非叶节点(正确答案)
C. 判定树的一个根节点
D. 判定树的一条路径
判定树剪枝的目的是:
A. 提高模型的泛化能力(正确答案)
B. 增加模型的复杂度
C. 减少模型的训练时间
D. 提高模型在训练集上的准确率。

![专题4 判定树及判定表练习[1]](https://uimg.taocdn.com/6543e1972f60ddccda38a0c2.webp)

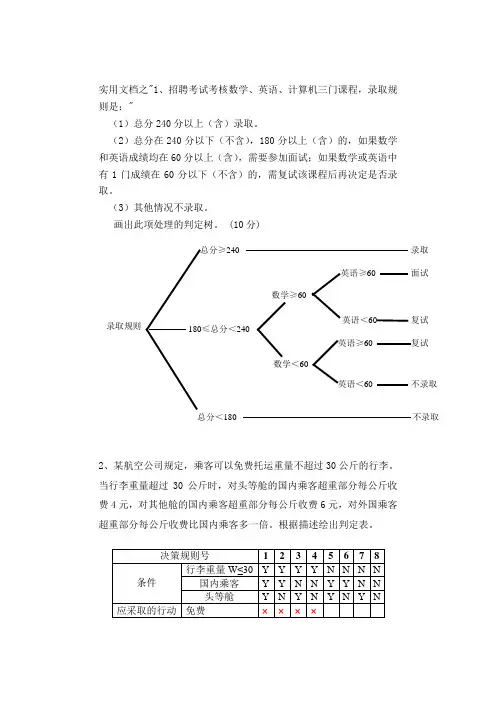
实用文档之"1、招聘考试考核数学、英语、计算机三门课程,录取规则是:"(1)总分240分以上(含)录取。
(2)总分在240分以下(不含),180分以上(含)的,如果数学和英语成绩均在60分以上(含),需要参加面试;如果数学或英语中有1门成绩在60分以下(不含)的,需复试该课程后再决定是否录取。
(3)其他情况不录取。
画出此项处理的判定树。
(10分)2、某航空公司规定,乘客可以免费托运重量不超过30公斤的行李。
当行李重量超过30公斤时,对头等舱的国内乘客超重部分每公斤收费4元,对其他舱的国内乘客超重部分每公斤收费6元,对外国乘客超重部分每公斤收费比国内乘客多一倍。
根据描述绘出判定表。
录取规则240录取 180≤总分<240总分<180不录取 数学≥60数学<60英语≥6060英语<6060面试复试 不录取3、某企业库存量监控的处理规则如下表:库存量≤0——————————————缺货处理库存下限<库存量≤储备定额——————订货处理储备定额<库存量≤库存上限——————正常处理库存量>库存上限——————————上限报警0<库存量≤库存下限—————————下限报警要求:画出判定表及判定树。
(1)判定表。
(2>储备定额正常处理>0库存量>上限订货处理<=储备定额<=上限上限报警<下限下限报警<=0 缺货处理4、某彩电生产企业根据销售商欠款时间长短和现有库存量情况处理彩电供货方案的结构化语言可表示为:IF 欠款时间≤30天IF 需要量≤库存量THEN 立即发货ELSE先按库存量发货,生产出来后再补发ELSEIF 欠款时间≤90天 THEN IF 需求量≤库存量 THEN 先付款再发货 ELSE不发货ELSE 要求先付欠款请将结构化语言表达的方案用判定表和判定树表达。
用判定表表达如下:用判定树表达如下:5.某工厂生产两种产品A 和B ,凡工人每月的实际生产量超过计划××要求先付欠款× 不发货 × 先付款,再发货 × 先按库存量发货,生产出来后再补发 × 立即发货应采取的 行 动 N Y N Y N Y 需求量≤库存量 N N Y Y N N 欠款时间>90天 N N N N Y Y 欠款时间≤30天 条 件6 5 4 3 2 1 决策规则号供货方案≤30天>30天 ≤90天>90天需求量≤库存需求量>库存量需求量≤库存量 需求量>库存量立即发货 先按库存发货, 生产后再补发 先付款,再发不发货 通知先付欠欠款时间需求与库存 处理结果指标者均有奖励。

判定树和判定表判定树⼜称决策树,是⼀种描述加⼯的图形⼯具,适合描述问题处理中具有多个判断,⽽且每个决策与若⼲条件有关。
使⽤判定树进⾏描述时,应该从问题的⽂字描述中分清哪些是判定条件,哪些是判定的决策,根据描述材料中的联结词找出判定条件的从属关系、并列关系、选择关系,根据它们构造判定树。
【例4.5】某⼯⼚对⼯⼈的超产奖励政策为:该⼚⽣产两种产品A和B。
凡⼯⼈每⽉的实际⽣产量超过计划指标者均有奖励。
奖励政策为:对于产品A的⽣产者,超产数N⼩于或等于100件时,每超产1件奖励2元;N⼤于100件⼩于等于150件时,⼤于100件的部分每件奖励2.5元,其余的每件奖励⾦额不变;N⼤于150件时,超过150件的部分每件奖励3元,其余按超产150件以内的⽅案处理。
对于产品B的⽣产者,超产数N⼩于或等于50件时,每超产1件奖励3元;N⼤于50件⼩于等于100件时,⼤于50件的部分每件奖励4元,其余的每件奖励⾦额不变;N⼤于100件时,超过100件的部分每件奖励5元,其余按超产100件以内的⽅案处理。
上述处理功能⽤判定树描述,如下图所⽰:这⼀判定树⽐起⽂字叙述,使⼈⼀⽬了然,清晰地表达了在什么情况下采取什么策略,不易产⽣逻辑上的混乱。
因⽽判定树是描述基本处理逻辑功能的有效⼯具。
==============================================判定表由四部分组成。
第⼀部分即①表⽰的部分,判定标的左上部称为基本条件项,列出各种可能的条件。
第⼆部分即②表⽰的部分,判定标的右上部称为条件项,它列出了各种可能的条件组合。
第三部分即③表⽰的部分,判定标的左下部称为基本动作项,它列出了所有的操作。
第四部分即④表⽰的部分,判定标的右下部称为动作项,它列出在对条件组合下所选的操作。
【例4.6】以学⽣的奖学⾦评定为例,说明判定表的应⽤。
奖励的⽬的在于⿎励学⽣的品学兼优,此处理功能是要合理确定奖学⾦评定等级。

(完整版)数据字典的含义与例子-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN数据字典的含义与例子数据字典是系统中各类数据描述的集合,是进行详细的数据收集和数据分析所获得的主要成果。
通常包括:数据项、数据结构、数据流、数据存储和处理过程五个部分。
数据字典是对数据流图的详细描述。
一、数据字典各部分的描述①数据项:数据流图中数据块的数据结构中的数据项说明数据项是不可再分的数据单位。
对数据项的描述通常包括以下内容:数据项描述={数据项名,数据项含义说明,别名,数据类型,长度,取值范围,取值含义,与其他数据项的逻辑关系}其中“取值范围”、“与其他数据项的逻辑关系”定义了数据的完整性约束条件,是设计数据检验功能的依据。
②数据结构:数据流图中数据块的数据结构说明数据结构反映了数据之间的组合关系。
一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或由若干个数据项和数据结构混合组成。
对数据结构的描述通常包括以下内容:数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}③数据流:数据流图中流线的说明数据流是数据结构在系统内传输的路径。
对数据流的描述通常包括以下内容:数据流描述={数据流名,说明,数据流来源,数据流去向,组成:{数据结构},平均流量,高峰期流量}其中“数据流来源”是说明该数据流来自哪个过程。
“数据流去向”是说明该数据流将到哪个过程去。
“平均流量”是指在单位时间(每天、每周、每月等)里的传输次数。
“高峰期流量”则是指在高峰时期的数据流量。
④数据存储:数据流图中数据块的存储特性说明数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一。
对数据存储的描述通常包括以下内容:数据存储描述={数据存储名,说明,编号,流入的数据流,流出的数据流,组成:{数据结构},数据量,存取方式}其中“数据量”是指每次存取多少数据,每天(或每小时、每周等)存取几次等信息。

判定表算法原理一、判定表组成判定表(Decision Table)是一种常见的问题解决方案,其核心思想是将复杂的逻辑关系用表格的形式表达,便于理解和维护。
判定表由四部分组成:条件桩(Condition Stub)、动作桩(Action Stub)、条件项(Condition Entry)和动作项(Action Entry)。
1.条件桩:问题中所有可能出现的独立条件,也称变量或因子。
2.动作桩:在给定条件下应执行的动作或决策。
3.条件项:对应条件桩的取值,即各种可能的输入或状态。
4.动作项:对应动作桩的执行结果或动作。
二、条件与动作1.条件:影响决策的因素或变量,通常以“是”或“否”的形式表示。
2.动作:在给定条件下应执行的操作或决策,通常以实际业务逻辑表示。
三、条件判断逻辑判定表的逻辑基于条件的组合进行动作的判断。
通过逐一检查条件项,确定相应的动作项,从而得到最终结果。
在处理复杂逻辑时,判定表能够清晰地表达各个条件之间的关系以及相应的操作。
四、简化与优化对于复杂的逻辑问题,判定表可以通过合并相似条件、提取公因子等方法进行简化与优化,提高可读性和维护性。
优化判定表的关键在于合理安排条件和动作,减少冗余,使整个逻辑更加清晰明了。
五、适用场景判定表适用于具有多个独立变量且逻辑关系明确的场景,如业务规则管理、故障排除等。
判定表的优势在于直观表达复杂逻辑,便于阅读和维护,尤其在业务规则经常变更的场景中具有较好的适应性。
六、与其他算法比较与其他算法相比,判定表具有以下特点:1.易于理解:判定表以表格形式展示逻辑关系,直观易懂,便于阅读和维护。
2.逻辑清晰:判定表能够清晰地表达各个条件之间的关系以及相应的操作,降低逻辑错误的风险。
3.易于扩展:通过合并相似条件和提取公因子等方法,判定表可以快速扩展处理更复杂的逻辑关系。
4.可维护性强:当业务规则发生变化时,只需修改判定表中的相应部分,无需修改程序代码,提高了可维护性。
(完整版)数据字典的含义与例子-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN数据字典的含义与例子数据字典是系统中各类数据描述的集合,是进行详细的数据收集和数据分析所获得的主要成果。
通常包括:数据项、数据结构、数据流、数据存储和处理过程五个部分。
数据字典是对数据流图的详细描述。
一、数据字典各部分的描述①数据项:数据流图中数据块的数据结构中的数据项说明数据项是不可再分的数据单位。
对数据项的描述通常包括以下内容:数据项描述={数据项名,数据项含义说明,别名,数据类型,长度,取值范围,取值含义,与其他数据项的逻辑关系}其中“取值范围”、“与其他数据项的逻辑关系”定义了数据的完整性约束条件,是设计数据检验功能的依据。
②数据结构:数据流图中数据块的数据结构说明数据结构反映了数据之间的组合关系。
一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或由若干个数据项和数据结构混合组成。
对数据结构的描述通常包括以下内容:数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}③数据流:数据流图中流线的说明数据流是数据结构在系统内传输的路径。
对数据流的描述通常包括以下内容:数据流描述={数据流名,说明,数据流来源,数据流去向,组成:{数据结构},平均流量,高峰期流量}其中“数据流来源”是说明该数据流来自哪个过程。
“数据流去向”是说明该数据流将到哪个过程去。
“平均流量”是指在单位时间(每天、每周、每月等)里的传输次数。
“高峰期流量”则是指在高峰时期的数据流量。
④数据存储:数据流图中数据块的存储特性说明数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一。
对数据存储的描述通常包括以下内容:数据存储描述={数据存储名,说明,编号,流入的数据流,流出的数据流,组成:{数据结构},数据量,存取方式}其中“数据量”是指每次存取多少数据,每天(或每小时、每周等)存取几次等信息。
