经济时间序列波动率的度量与ARCH
- 格式:pdf
- 大小:360.57 KB
- 文档页数:4

EGARCH模型定义又称“广义ARCH模型(Generalized ARCH)”、“广义自回归条件异方差模型”自从Engle(1982)提出ARCH模型分析时间序列的异方差性以后,波勒斯列夫T.Bollerslev(1986)又提出了GARCH模型,GARCH模型是一个专门针对金融数据所量体订做的回归模型,除去和普通回归模型相同的之处,GARCH对误差的方差进行了进一步的建模。
特别适用于波动性的分析和预测,这样的分析对投资者的决策能起到非常重要的指导性作用,其意义很多时候超过了对数值本身的分析和预测。
基本原理一般的GARCH模型可以表示为:其中ht为条件方差,ut为独立同分布的随机变量,ht与ut互相独立,ut为标准正态分布。
(1)式称为条件均值方程;(3)式称为条件方差方程,说明时间序列条件方差的变化特征。
为了适应收益率序列经验分布的尖峰厚尾特征,也可假设服从其他分布,如Bollerslev (1987)假设收益率服从广义t-分布,Nelson(1991)提出的EGARCH模型采用了GED分布等。
另外,许多实证研究表明收益率分布不但存在尖峰厚尾特性,而且收益率残差对收益率的影响还存在非对称性。
当市场受到负冲击时,股价下跌,收益率的条件方差扩大,导致股价和收益率的波动性更大;反之,股价上升时,波动性减小。
股价下跌导致公司的股票价值下降,如果假设公司债务不变,则公司的财务杠杆上升,持有股票的风险提高。
因此负冲击对条件方差的这种影响又被称作杠杆效应。
由于GARCH模型中,正的和负的冲击对条件方差的影响是对称的,因此GARCH模型不能刻画收益率条件方差波动的非对称性。
发展为了衡量收益率波动的非对称性,Glosten、Jagannathan与Runkel(1989)提出了GJR模型,在条件方差方程(3)中加入负冲击的杠杆效应,但仍采用正态分布假设。
Nelson(1991)提出了EGARCH模型。
Engle等(1993)利用信息反应曲线分析比较了各种模型的杠杆效应,认为GJR模型最好地刻画了收益率的杠杆效应。

时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset 命令use gnp96.dta, clearlist in 1/20gen Lgnp = L.gnptsset datelist in 1/20gen Lgnp = L.gnp2)检查是否有断点:tsreport, reportuse gnp96.dta, cleartsset datetsreport, reportdrop in 10/10list in 1/12tsreport, reporttsreport, report list /*列出存在断点的样本信息*/3)填充缺漏值:tsfilltsfilltsreport, report listlist in 1/124)追加样本:tsappenduse gnp96.dta, cleartsset datelist in -10/-1sumtsappend , add(5) /*追加5个观察值*/list in -10/-1sum5)应用:样本外预测: predictreg gnp96 L.gnp96predict gnp_hatlist in -10/-16)清除时间标识: tsset, cleartsset, clear1.2变量的生成与处理1)滞后项、超前项和差分项 help tsvarlistuse gnp96.dta, cleartsset dategen Lgnp = L.gnp96 /*一阶滞后*/gen L2gnp = L2.gnp96gen Fgnp = F.gnp96 /*一阶超前*/gen F2gnp = F2.gnp96gen Dgnp = D.gnp96 /*一阶差分*/gen D2gnp = D2.gnp96list in 1/10list in -10/-12)产生增长率变量: 对数差分gen lngnp = ln(gnp96)gen growth = D.lngnpgen growth2 = (gnp96-L.gnp96)/L.gnp96gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/101.3日期的处理日期的格式 help tsfmt基本时点:整数数值,如 -3, -2, -1, 0, 1, 2, 3 ....1960年1月1日,取值为 0;1)使用 tsset 命令指定显示格式use B6_tsset.dta, cleartsset t, dailylistuse B6_tsset.dta, cleartsset t, weeklylist2)指定起始时点cap drop monthgenerate month = m(1990-1) + _n - 1format month %tmlist t month in 1/20cap drop yeargen year = y(1952) + _n - 1format year %tylist t year in 1/203)自己设定不同的显示格式日期的显示格式 %d (%td) 定义如下:%[-][t]d<描述特定的显示格式>具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符c y m l nd j h q w _ . , : - / ' !cC Y M L ND J W定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写) M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年 (1 or 2)q 一年中的第几季度 (1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号): display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !! to display an exclamation point)样式1:Format Sample date in format-----------------------------------%td 07jul1948%tdM_d,_CY July 7, 1948%tdY/M/D 48/07/11%tdM-D-CY 07-11-1948%tqCY.q 1999.2%tqCY:q 1992:2%twCY,_w 2010, 48-----------------------------------样式2:Format Sample date in format----------------------------------%d 11jul1948%dDlCY 11jul1948%dDlY 11jul48%dM_d,_CY July 11, 1948%dd_M_CY 11 July 1948%dN/D/Y 07/11/48%dD/N/Y 11/07/48%dY/N/D 48/07/11%dN-D-CY 07-11-1948----------------------------------clearset obs 100gen t = _n + d(13feb1978)list t in 1/5format t %dCY-N-D /*1978-02-14*/list t in 1/5format t %dcy_n_d /*1978 2 14*/list t in 1/5use B6_tsset, clearlisttsset t, format(%twCY-m)list4)一个实例:生成连续的时间变量use e1920.dta, clearlist year month in 1/30sort year monthgen time = _ntsset timelist year month time in 1/30generate newmonth = m(1920-1) + time - 1tsset newmonth, monthlylist year month time newmonth in 1/301.4图解时间序列1)例1:clearset seed 13579113sim_arma ar2, ar(0.7 0.2) nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _ttsline ar2 ma2* 亦可采用 twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t2)例2:增加文字标注sysuse tsline2, cleartsset daytsline calories, ttick(28nov2002 25dec2002, tpos(in)) /// ttext(3470 28nov2002 "thanks" ///3470 25dec2002 "x-mas", orient(vert)) 3)例3:增加两条纵向的标示线sysuse tsline2, cleartsset daytsline calories, tline(28nov2002 25dec2002) * 或采用 twoway line 命令 local d1 = d(28nov2002) local d2 = d(25dec2002)line calories day, xline(`d1' `d2')4)例4:改变标签tsline calories, tlabel(, format(%tdmd)) ttitle("Date (2002)") tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA 模型ARIMA 模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。

arch模型的原理-回复ARCH模型,即自回归条件异方差模型(Autoregressive Conditional Heteroskedasticity Model),是为了捕捉时间序列数据中异方差(heteroskedasticity)现象而生的一种经济计量模型。
在本文中,将一步一步回答“ARCH模型的原理”。
第一步,我们先了解什么是异方差。
异方差是指时间序列数据中,随着时间的推移,序列的方差出现明显变化的情况。
在金融市场,股票价格或金融资产的收益率常常呈现出异方差现象,即在某些时期波动较小,而在其他时期波动较大。
这种异方差现象对于风险度量和预测模型的构建都有很大的影响。
第二步,ARCH模型的基本思想是通过引入时间序列自己的过去序列的方差来解释序列的异方差现象。
也就是说,ARCH模型假设时间序列数据的方差是由过去的误差平方项决定的。
如果过去的方差较大,那么未来的方差也会较大;反之,如果过去的方差较小,那么未来的方差也会较小。
第三步,ARCH模型的具体形式是通过引入一个滞后期数的误差项平方的线性组合来表示方差的变化。
以ARCH(p)模型为例,其表达式为:σ^2_t = α_0 + α_1 * ε^2_(t-1) + α_2 * ε^2_(t-2) + ... + α_p * ε^2_(t-p)其中,σ^2_t表示时间t的方差,α_0为常数项,α_i(i=1,2,...,p)为参数,ε_t(t=1,2,...,p)为误差项。
在ARCH(p)模型中,根据过去p期的误差项平方的线性组合来估计当前时间的方差。
第四步,ARCH模型的参数估计可以使用最大似然估计法(Maximum Likelihood Estimation,简称MLE)进行。
MLE的思想是找到一组参数值,使得模型产生的数据的概率最大化。
对于ARCH模型,我们需要对误差项的平方进行参数估计,然后利用MLE来求解最优的参数。
第五步,ARCH模型的估计和预测过程需要进行模型检验。

基于ARMA-ARCH模型的沪深300指数预测研究基于ARMA-ARCH模型的沪深300指数预测研究摘要:本文基于ARMA-ARCH模型,对沪深300指数进行了预测研究。
通过对沪深300指数的历史数据进行分析,首先建立了ARMA模型,然后利用ARCH效应对残差序列进行建模,进一步提高预测的准确性。
研究结果表明,基于ARMA-ARCH模型的预测方法可以较好地反映沪深300指数的变动趋势,具有较高的预测精度和可靠性。
关键词:ARMA模型,ARCH模型,沪深300指数,预测准确性1. 引言沪深300指数是中国证券市场的重要指标之一,对于投资者制定投资策略和决策具有重要意义。
准确预测沪深300指数的变动趋势对于投资者和决策者来说都具有重要意义。
因此,通过建立合适的预测模型,提高对沪深300指数未来变动的预测能力具有重要的研究价值和实际意义。
2. ARMA模型ARMA模型是一种经典的时间序列分析模型,它由自回归(AR)和移动平均(MA)两部分组成。
自回归部分描述了序列的当前值与过去值之间的关系,移动平均部分描述了序列当前值与随机扰动项之间的关系。
ARMA(p, q)模型的数学表达式为:Y_t = φ_1Y_(t-1) + φ_2Y_(t-2) + ... + φ_pY_(t-p) + ε_t - θ_1ε_(t-1) - θ_2ε_(t-2) - ... -θ_qε_(t-q)其中,Y_t为时间序列的当前值,φ_1, φ_2, ...,φ_p为自回归系数,θ_1, θ_2, ..., θ_q为移动平均系数,ε_t为残差。
3. ARCH模型ARCH模型是一种波动率模型,它描述了时间序列的波动率与过去波动率的关系。
ARCH模型的基本形式为:σ_t^2 = α_0 + α_1ε_(t-1)^2 + α_2ε_(t-2)^2 + ... + α_qε_(t-q)^2其中,σ_t^2为时间序列的当前波动率,α_0,α_1, ..., α_q为模型参数,ε_t为残差。
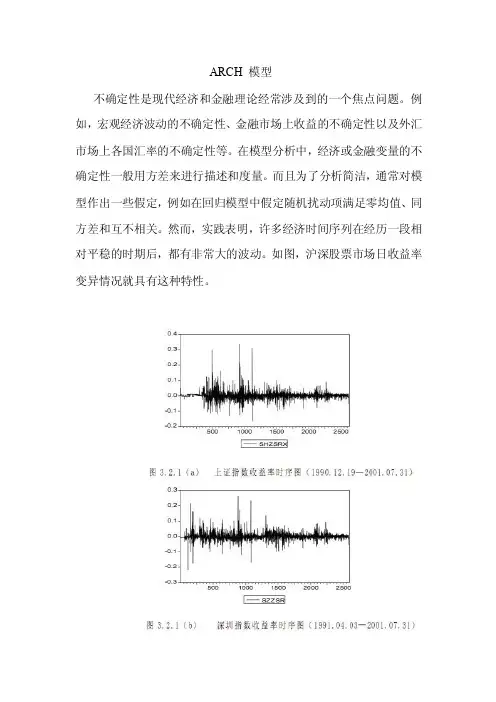
ARCH 模型不确定性是现代经济和金融理论经常涉及到的一个焦点问题。
例如,宏观经济波动的不确定性、金融市场上收益的不确定性以及外汇市场上各国汇率的不确定性等。
在模型分析中,经济或金融变量的不确定性一般用方差来进行描述和度量。
而且为了分析简洁,通常对模型作出一些假定,例如在回归模型中假定随机扰动项满足零均值、同方差和互不相关。
然而,实践表明,许多经济时间序列在经历一段相对平稳的时期后,都有非常大的波动。
如图,沪深股票市场日收益率变异情况就具有这种特性。
在这种情况下,同方差假定是不恰当的。
在这种情况下,人们关心的是如何预测序列的条件方差。
例如,作为资产持有者,他既关心收益率的预测值,同时也关心持有期内方差的大小。
如果一位投资者计划在第 t 时期买入某项资产,在第 t+1 时期售出,则无条件方差(即方差的长期预测值)对他来讲就不重要了。
对于这一类问题,可以使用自回归条件异方差模型 (autoregressive conditiona heteroskedastic model ,简称 ARCH 模型)来进行分析。
最早的 ARCH 模型是由 Robert Engle 于 1982 年建立的,因此它的发展历史不长。
但是,这种模型及其各种推广形式已被广泛应用于经济和金融数据序列的分析,ARCH 模型族已成为研究经济变量变异聚类特性的有效工具。
第一节 ARCH 模型的概念与性质 1、ARCH 过程ARCH 模型的一般性定义如下。
假设时间序列{}t y 服从如下回归模型:'t t ty x u ξ=+(8.1.1)其中 t x 是外生变量向量,它可以包含被解释变量的滞后项,ξ是回归参数向量。
如果扰动项序列{}t u 满足:11|~(0,)(,,)t t t t t t q u N h h h u u ---Ω= (8.1.2)其中:11122{,',,'}t t t t t y x y x -----Ω= 为t 时期以前的信息集。
EGARCH模型定义又称“广义ARCH模型(Generalized ARCH)”、“广义自回归条件异方差模型”自从Engle(1982)提出ARCH模型分析时间序列的异方差性以后,波勒斯列夫T.Bollerslev(1986)又提出了GARCH模型,GARCH模型是一个专门针对金融数据所量体订做的回归模型,除去和普通回归模型相同的之处,GARCH对误差的方差进行了进一步的建模。
特别适用于波动性的分析和预测,这样的分析对投资者的决策能起到非常重要的指导性作用,其意义很多时候超过了对数值本身的分析和预测。
基本原理一般的GARCH模型可以表示为:其中ht为条件方差,ut为独立同分布的随机变量,ht与ut互相独立,ut为标准正态分布。
(1)式称为条件均值方程;(3)式称为条件方差方程,说明时间序列条件方差的变化特征。
为了适应收益率序列经验分布的尖峰厚尾特征,也可假设服从其他分布,如Bollerslev (1987)假设收益率服从广义t-分布,Nelson(1991)提出的EGARCH模型采用了GED分布等。
另外,许多实证研究表明收益率分布不但存在尖峰厚尾特性,而且收益率残差对收益率的影响还存在非对称性。
当市场受到负冲击时,股价下跌,收益率的条件方差扩大,导致股价和收益率的波动性更大;反之,股价上升时,波动性减小。
股价下跌导致公司的股票价值下降,如果假设公司债务不变,则公司的财务杠杆上升,持有股票的风险提高。
因此负冲击对条件方差的这种影响又被称作杠杆效应。
由于GARCH模型中,正的和负的冲击对条件方差的影响是对称的,因此GARCH模型不能刻画收益率条件方差波动的非对称性。
发展为了衡量收益率波动的非对称性,Glosten、Jagannathan与Runkel(1989)提出了GJR模型,在条件方差方程(3)中加入负冲击的杠杆效应,但仍采用正态分布假设。
Nelson(1991)提出了EGARCH模型。
Engle等(1993)利用信息反应曲线分析比较了各种模型的杠杆效应,认为GJR模型最好地刻画了收益率的杠杆效应。

时间序列计量经济学模型概述时间序列计量经济学模型是在经济学研究中广泛使用的一种方法,用于分析经济变量随时间的变化。
该模型基于时间序列数据,即经济变量在一段时间内的观测值。
时间序列计量经济学模型的核心是建立经济变量之间的关系,以解释和预测经济现象的变化。
其中最常用的模型是自回归移动平均模型(ARMA)、自回归条件异方差模型(ARCH)和季节性时间序列模型。
自回归移动平均模型(ARMA)是一个包含自回归项和移动平均项的线性模型。
该模型以过去的观测值和随机项为输入,预测当前观测值。
ARMA模型基于假设,即经济变量的行为受到历史观测值的影响。
自回归条件异方差模型(ARCH)是一种考虑了随时间变化方差的模型。
该模型通过引入一个条件异方差项,模拟经济变量中的波动性。
ARCH模型的应用范围广泛,特别是在金融市场波动性分析中。
季节性时间序列模型用于分析具有明显季节性特征的经济变量,如销售额、就业人数等。
这些模型通常基于季节、趋势和随机成分的组合,以预测未来观测值。
在建立时间序列计量经济学模型时,常常需要进行模型识别、参数估计和模型诊断等步骤。
识别模型的目标是确定适当的模型结构,参数估计则是利用历史数据估计模型的参数值。
模型诊断用于检验模型的拟合程度和误差分布是否符合模型假设。
时间序列计量经济学模型在经济研究中有广泛的应用,例如预测未来经济指标、分析经济周期和波动性、评估政策效果等。
它提供了一种量化的方法,使经济学家可以更好地理解和解释经济变量的演变。
时间序列计量经济学模型是经济学研究中一种重要的统计工具,广泛应用于宏观经济、金融市场和企业经营等领域。
它可以帮助我们理解和解释经济变量随时间的变化规律,进行预测和政策分析。
本文将进一步探讨时间序列计量经济学模型的相关概念和应用。
在构建时间序列计量经济学模型之前,首先需要了解时间序列数据的特点。
时间序列数据是按照时间顺序排列的一系列观测值,通常具有趋势性、季节性、周期性和随机性等特征。

第三章波动模型有许多经济时间序列,可能在某一段时间内呈现出相对平稳性,接着可能会呈现出剧烈的波动性。
条件方差在变化,但无条件方差可能是个常数。
因为资产持有者总是关注持有期内收益的波动,而不是整个历史期间内的波动。
能够估计、预测某种特定资产的风险十分重要的。
本章将介绍条件异方差模型(ARCH)的建模方法。
3.1 经济时间序列:典型化特征图形3.1到3.6说明了重要的宏观经济变量的变化行径。
当然需要有正式的检验来证实这些第一印象。
在视觉上,这些序列是非平稳的,样本均值不是常量,有很强的异方差性等重要的典型化特征:(1)大多数序列都包含有明显的趋势。
虽然实际GDP中的实际投资、政府支出比实际GDP和消费波动性更大,实际GDP和消费有一个明显向上趋势。
(2)对序列的冲击显示很强的持久性短期利率和长期利率都没有明显的向上或向下的随机趋势。
但都有很强的持久性。
(联邦基金利率)(某种债券收益)(3) 许多时间序列的波动性并不是常量(上证指数)(取对数再差分)可以看出,平静的期间内也伴随着不同的波动程度。
虽然无条件(或长期)方差是常量,但也有方差变化较大的期间,这样的序列称为条件异方差。
(4)一些序列似乎是随机游走没有特别增加或减少的趋势,没有返到长期均值的趋势。
这种随机游动类型是典型的非平稳序列。
(上证指数收盘价)(5)一些序列与其它序列有着“公共趋势”联邦基金利率和10年期美国政府债券收益没有返回到长期均值的趋势。
但两个序列从未分离开太远,对联邦基金利率的冲击也同样出现在10年政府债券收益。
这种“共同运动”不足奇怪,因为推动短期、长期利益的原因是相同的。
这些增长率趋势之间是否统计上有显著差别,都需要正式的统计检验。
3.2 ARCH 过程在传统的计量经济模型中,扰动项的方差都被假设为常数。
但上一节我们看到,许多经济时间序列都显示了非常的大波动期之后又显示了一段相对平缓期,在这样情况下,常量方差的假设是不适当的。

arch效应一元回归模型arch效应是指在金融市场中存在的时间序列的波动率聚集性现象。
在金融市场中,价格的波动性是投资者非常关注的一个指标,因为波动率的变化会对投资决策产生重要影响。
arch效应的提出为我们解释金融市场中价格波动性的聚集性提供了一个重要的理论框架。
arch模型是用来描述金融市场中的波动性聚集性现象的一种经济学模型。
它是由罗伯特·恩格尔(Robert F. Engle)于1982年提出的,因此也被称为“恩格尔的arch模型”。
arch模型是一种条件异方差模型,它假设金融时间序列的波动率是与其历史波动率相关的。
在arch模型中,波动率被认为是时间序列中的一个随机变量,它的变化是受到历史波动率的影响的。
arch模型可以用来对金融市场中的价格波动性进行建模和预测。
在arch模型中,条件异方差被认为是一个滞后变量的函数,它可以通过对历史波动率的估计来预测未来的波动率。
arch模型的核心思想是,当前的波动率与过去的波动率有关,较高的波动率往往会导致未来较高的波动率,较低的波动率会导致未来较低的波动率。
arch 模型可以帮助我们理解金融市场中的波动率聚集性现象,并对未来的波动率进行预测。
arch模型的估计方法主要有两种,一种是最大似然估计法,另一种是广义最小二乘法。
最大似然估计法是通过最大化似然函数来估计模型的参数,而广义最小二乘法是通过最小化模型的加权残差平方和来估计模型的参数。
这两种方法在实际应用中都有一定的优缺点,选择哪种方法要根据实际情况来决定。
arch模型在金融领域中有着广泛的应用。
它可以用来对金融市场中的风险进行度量和管理,可以帮助投资者进行风险控制和资产配置。
arch模型还可以用来对金融市场中的波动率进行预测,帮助投资者做出更准确的投资决策。
此外,arch模型还可以用来对金融市场中的高频数据进行建模和分析,以及对金融市场中的异常波动进行检测和解释。
尽管arch模型在金融领域中有着广泛的应用,但它也存在一些局限性。

【时间序列】波动率建模之ARCH模型1. ARCH1.1 异方差在传统计量经济学模型中,都假设干扰项的方差为常数(同方差)。
但是在现实世界中,许多经济时间序列的波动具有丛聚性等特征。
例如:股市中可能存在的涨跌,当遇到结构性风险,股票价格可能存在大涨或者大跌的情况,这种类时间序列被称为条件异方差,即使无条件异方差是恒定的,但是也会存在方差相对较高的时候,而这个波动率是通常会呈现出持续性,这被称为波动丛聚性。
1.2 ARCH过程ARCH (atuoregressive conditional heteroskedastic,自回归条件异方差)模型可以描述一个序列阶段性的稳定和波动:表示白噪音过程,满足 ;相互独立,和都为常数,且把代入到中可得:这便是序列的一阶自回归异方模型ARCH(1),推广到高阶则可得我们为什么要用条件异方差呢,首先来考虑估计一个平稳的ARMA模型,则的条件均值为,用条件均值去预测下一期,则预测误差的方差为如果使用无条件预测,结果一般是时间序列的长期均值。
则无条件预测误差方差为其中白噪音过程,,,可得由此可得无条件预测方差大于条件预测方差,所以使用条件预测结果更好。
所以针对一些时间序列的异方差性,可以使用一些模型去拟合条件方差。
1.3 ARCH性质1.ARCH模型,误差项的条件均值和无条件均值都等于0.对于所有,因此,序列具有序列不相关性,但是误差并不相互独立(误差),换个角度看, ARCH(1) 的方差是等于AR(1)的:2.为条件异方差将导致也为异方差,所以ARCH模型可以表示出序列中阶段性的稳定和波动3.ARCH误差和序列的自相关参数相互作用。
的变化和序列的持续较大的方差有关,越大,持续时间越长,的变化越持久。
ARCH是使用AR(P)来对条件方差建模,如果加上MA(q) 过程又会如何呢?由此衍生出了GARCH2. GARCH假设误差过程为:表示白噪音过程,均值为0,方差为1,因此的条件与无条件均值都为0.此模型将自回归以及异方差的移动平均项结合了起来。

ARCH模型介绍σ_t^2=α_0+α_1*ε_(t-1)^2+α_2*ε_(t-2)^2+...+α_p*ε_(t-p)^2其中,σ_t^2表示在t时刻的波动性,α_0表示常数项,α_1,α_2,...,α_p是ARCH模型的参数,ε_t-1,ε_t-2,...,ε_t-p是t时刻的残差。
ARCH模型最重要的特点是它能够捕捉到波动性的聚集,即高波动性的时期往往会持续一段时间,而低波动性的时期也会持续一段时间。
这是因为ARCH模型中的参数可以控制波动性的趋势和持续性。
当参数值较大时,波动性的变化会更加剧烈;当参数值较小时,波动性的变化会更加平缓。
ARCH模型在金融领域特别受到关注,因为金融市场的波动性非常重要。
通过使用ARCH模型,我们可以对金融市场的波动性进行建模和预测。
例如,可以利用ARCH模型来估计股票价格的波动性,进而对股票的风险进行评估。
此外,ARCH模型还可以用于进行对冲策略的设计,以便在市场波动性较高时降低风险。
除了ARCH模型,还有一种更广义的模型叫做GARCH模型,即广义自回归条件异方差模型。
GARCH模型在ARCH模型的基础上增加了过去时刻波动性的指数加权平均项。
这允许GARCH模型能够更好地捕捉到波动性的长期记忆特性。
GARCH模型的一般形式可以表示为:σ_t^2=α_0+α_1*ε_(t-1)^2+α_2*ε_(t-2)^2+...+α_p*ε_(t-p)^2+β_1*σ_(t-1)^2+β_2*σ_(t-2)^2+...+β_q*σ_(t-q)^2其中,σ_t^2表示在t时刻的波动性,α_0表示常数项,α_1,α_2,...,α_p是ARCH模型的参数,β_1,β_2,...,β_q是GARCH 模型的参数,ε_t-1,ε_t-2,...,ε_t-p是t时刻的残差,σ_t-1,σ_t-2,...,σ_t-q是t时刻的波动性。
GARCH模型在金融领域的应用更为广泛,因为它可以更准确地描述金融市场中的波动性。
时间序列模型时间序列分析是现代计量经济学的重要内容,是研究经济变量的动态特征和周期特征及其相关关系的重要工具,被广泛应用经济分析和预测中。
时间序列按其平稳性与否又分为平稳时间序列和非平稳时间序列。
1.ARMA与ARCH模型2.协整与误差修正模型3.向量自回归模型第五讲ARMA与ARCH模型本讲中将讨论时间序列的平稳性(stationary)概念及自回归模型(Autoregressive models)、移动平均模型(Moving averagemodels)、自回归移动平均模型(Autoregressive moving average models)、自回归条件异方差模型(Autoregressivec conditional Heteroscedasticity models) 的识别、估计、检验、应用。
一、时间序列的平稳性(一)平稳时间序列所谓时间序列的平稳性,是指时间序列的统计规律不会随着时间的推移而发生变化。
严格地讲,如果一个随机时间序列t y ,对于任何时间t ,都满足下列条件: Ⅰ)均值()t E y μ=∞;Ⅱ)方差22()()t t Var y E y μσ=-=,是与时间t 无关的常数; Ⅲ)自协方差{}(,)t t k t t k k Cov y y E y y μμγ--=--=()(),是只与时期间隔k 有关,与时间t 无关的常数。
则称该随机时间序列是平稳的。
生成该序列的随机过程是平稳过程。
例5.1.一个最简单的随机时间序列是一具有零均值同方差的独立分布序列: t y =t εt ε~2(0,)iid σ该序列常被称为是一个白噪声(white noise )。
由于t y 具有相同的均值与方差,且协方差为零,满足平稳性条件,是平稳的。
例5.2.另一个简单的随机时间列序被称为随机游走(random walk ):1t t t y y ε-=+t ε~2(0,)iid σ,是一个白噪声。
经济学实证研究中的时间序列分析方法比较时间序列分析是经济学实证研究中一种常用的方法,它对经济数据的时间变化进行建模和预测。
然而,由于经济学数据的特殊性和复杂性,选择合适的时间序列分析方法至关重要。
本文将比较几种常见的时间序列分析方法,包括自回归移动平均模型(ARMA)、自回归条件异方差模型(ARCH)、广义自回归条件异方差模型(GARCH)、ARIMA模型和向量自回归模型(VAR)。
ARMA模型是最基本的时间序列分析方法之一。
它假设数据的未来观测值是过去观测值的线性组合,同时考虑了残差项的随机性。
ARMA模型适用于平稳时间序列数据,其主要优点是简单易懂、计算效率高。
然而,ARMA模型无法应对非平稳时间序列数据和异方差性的存在。
ARCH模型是针对ARMA模型的不足提出的改进方法,它考虑了数据的条件异方差性。
ARCH模型假设数据的条件方差是过去观测误差的加权和,可用于对金融市场波动性进行建模。
然而,ARCH模型无法处理高度异方差的数据,且对时间序列结构的假设限制较多。
GARCH模型是ARCH模型的扩展,考虑了条件异方差和波动性的长期记忆。
GARCH模型在金融领域得到广泛应用,能够更好地对金融市场的波动进行建模。
然而,GARCH模型对参数估计的要求较高,对数据的拟合效果较为敏感。
ARIMA模型是一种广泛应用于短期时间序列预测的方法,包括自回归、差分和移动平均三个部分。
ARIMA模型能够适应一定程度的非平稳数据,并考虑了序列的趋势和季节性变化。
然而,ARIMA模型对数据具有一定的处理要求,在应用时需要仔细选择阶数和滞后期。
VAR模型是多变量时间序列分析的方法,适用于多个相关变量之间的关系分析与预测。
VAR模型的优点在于能够捕捉不同变量之间的动态联动关系,可以考虑更多的信息。
然而,VAR模型对变量之间的相关性和滞后期的选择有一定要求,模型的估计和解释较为复杂。
综上所述,经济学实证研究中的时间序列分析方法有多种选择,每种方法都有其适用的场景和局限性。
基于VaR的中国股指期货风险实证研究-相关论文选题选题1:基于VaR的中国股指期货风险实证研究选题思路:2010年4月16日,我国推出了沪深300股指期货,在其推出以后,沪深300股指期货交易比较活跃,运行也较为平稳,但是在风险的度量及预测方面的研究略显不足。
VaR作为一种度量风险的指标,其应用较为广泛,国内外专家学者对其也有较多的研究。
为了测度中国股指期货VaR风险,选择中国股指期货当月连续IFO日对数收益率数据作为研究对象,首先对收益率序列进行了基本的统计分析,结果表明,中国股指期货对数收益率序列具有尖峰厚尾的特征,并具有ARCH效应,因此认为可以对此时间序列数据运用GARCH族模型来克服其异方差性。
介绍并选用了GARCH族模型中的GARCH-N,GARCH-t,GARCH-GED,TARCH与EGARCH模型度量了中国股指期货的风险,即其VaR数值,并根据各模型系数讨论了中国股指期货的杠杆效应等风险特征。
同时,文章还引入了神经网络中较为新颖的混合密度网络模型(MDN模型)对中国股指期货的风险VaR进行考察。
作为神经网络的一支,它特有的学习特性可以很好地拟合时间序列的事变特征,从而具有良好的预测能力。
最后将GARCH族模型与混合密度网络模型得到的VaR值进行了准确性检验——Kupiec失败频率检验,发现GARCH-GED、EGARCH与混合密度网络模型可以较为准确地预测中国股指期货的风险VaR值。
选题2:中国大豆价格波动性研究选题思路:文章综合分析中国大豆供、需现状,从期货价格理论、供给、需求三个角度对影响中国大豆价格的因素进行分类,并建立相应的指标体系,将影响因素归为国产大豆供给量、进口大豆量、国际大豆产量、国内大豆消费量、国际大豆消费量、农民人均纯收入中的农业收入、玉米现货价格、豆油现货价格、美元汇率指数、大豆现货价格、大豆期货价格滞后一期、美国芝加哥大豆期货价格。
然后利用逐步回归方法实证分析各类因素对中国大豆价格的影响,研究结果表明,相对于其它类因素,中国大豆期货价格更易受到大豆国内供给和需求因素、人均农业纯收入、豆油现货价格、美国芝加哥大豆期货价格以及滞后一期价格的影响,与这些因素之间存在显著的回归效应。