应用回归分析-实用回归分析
- 格式:ppt
- 大小:243.50 KB
- 文档页数:20


数据分析方法:回归分析实用指南引言数据分析在当今社会中扮演着至关重要的角色。
通过收集、整理和分析数据,我们可以获得有关特定问题或现象的深入洞察。
回归分析是一种常用的统计分析方法,可以帮助我们理解变量之间的关系,并预测未来的趋势。
本文将为您介绍回归分析的概念、应用和常见方法,希望能够为您在实际应用中提供一些有用的指导。
什么是回归分析?回归分析是一种用于研究变量之间关系的统计方法。
它通过建立一个数学模型来描述自变量(独立变量)与因变量(依赖变量)之间的关系。
回归分析可以帮助我们理解变量之间的关联性,从而探索隐藏在数据背后的规律。
回归分析的应用领域回归分析在各个领域都有广泛的应用,以下是一些常见的应用领域:1. 经济学在经济学中,回归分析被用来研究各种经济变量之间的关系,如GDP与投资、通货膨胀与失业率等。
通过回归分析,经济学家可以预测未来的经济趋势,为政府和企业提供决策支持。
2. 市场营销在市场营销领域,回归分析被广泛应用于市场调研和销售预测。
通过分析市场数据和消费者行为,市场营销人员可以确定哪些因素对产品销售额产生积极影响,并相应地调整营销策略。
3. 医学研究医学研究中也常用回归分析来探索疾病与生活方式、遗传因素等之间的关系。
通过回归分析,医生和研究人员可以找到影响疾病发生和发展的风险因素,从而提供更有效的预防和治疗方法。
4. 社会科学回归分析在社会科学研究中也是一个重要的工具。
通过回归分析,社会科学家可以研究教育、犯罪、就业等不同社会现象之间的关系,从而为社会政策制定提供依据。
简单线性回归分析在回归分析中,最简单的一种形式是简单线性回归分析。
在简单线性回归中,我们只考虑一个自变量和一个因变量之间的关系。
1. 模型表达式简单线性回归模型的表达式为:Y=β0+β1X+ɛ其中,Y是因变量,X是自变量,β0和β1是回归系数,ɛ是误差项。
2. 回归系数解释回归系数β0和β1分别表示截距和斜率。
截距β0表示当自变量X为0时,因变量Y 的预测值。

回归分析法原理及应用回归分析法是一种常用的统计方法,旨在探究自变量和因变量之间的关系。
在回归分析中,自变量是可以用于预测或解释因变量的变量,而因变量是被预测或被解释的变量。
利用回归分析,我们可以确定这些变量之间的关系,从而预测未来的趋势和结果。
回归分析法的原理非常简单,通过一系列统计方法来评估自变量和因变量之间的关系。
最常用的回归分析是线性回归分析,它建立在一条直线上,通过最小二乘法来寻找自变量和因变量之间的线性关系。
其它类型的回归分析包括多元回归分析、二元分类回归分析等。
回归分析法的应用非常广泛,它可以应用于医学、社会科学、金融、自然科学等领域。
举个例子,在医学领域,回归分析可用于预测疾病的发病率或死亡率。
在金融领域,回归分析可用于预测股票价格趋势或汇率变化。
在社会科学领域,回归分析可用于解释人类行为、心理和社会变化。
要使用回归分析法,需要完成以下步骤:1. 收集数据。
这包括自变量和因变量的数据,例如市场规模和销售额。
2. 进行数据预处理。
这包括检查数据是否有缺失、异常值或离群值。
必要时,可对数据进行清理并进行适当的转换或标准化。
3. 选择合适的回归模型。
这需要考虑自变量和因变量之间的关系类型,例如线性、非线性和分类。
根据实际情况和目标,选择最适合的回归模型。
4. 训练模型。
这需要将数据分为训练数据集和测试数据集,并利用训练数据集来建立回归模型。
模型的性能可以通过测试数据集的预测能力来评估。
5. 评估模型性能。
测试数据集可以用来评估模型的性能如何,例如模型的准确度、召回率或F1分数。
这些指标可以用来比较不同的回归模型。
回归分析法的优点包括:1. 提供对自变量与因变量之间的关系的量化估计。
2. 可以帮助我们理解变量之间的相互作用。
3. 可以预测未来的行为或趋势。
4. 可以作为一种基本的统计工具,应用于各种具体应用领域。
回归分析法的缺点包括:1. 回归模型只能处理自变量和因变量之间的线性关系,而不能处理非线性关系。

3.1.2 虚拟变量的应用例3.1.2.1:为研究美国住房面积的需求,选用3120户家庭为建模样本,回归模型为:123log log P Y βββ++logQ=其中:Q ——3120个样本家庭的年住房面积(平方英尺) 横截面数据P ——家庭所在地的住房单位价格 Y ——家庭收入经计算:0.247log 0.96log P Y -+logy=4.17 20.371R =()() ()上式中2β=0.247-的价格弹性系数,3β=0.96的收入弹性系数,均符合经济学的常识,即价格上升,住房需求下降,收入上升,住房需求也上升。
但白人家庭与黑人家庭对住房的需求量是不一样的,引进虚拟变量D :01i D ⎧=⎨⎩黑人家庭白人家庭或其他家庭模型为:112233log log log log D P D P Y D Y βαβαβα+++++logQ=例3.1.2.2:某省农业生产资料购买力和农民货币收入数据如下:(单位:十亿元)①根据上述数据建立一元线性回归方程:ˆ 1.01610.09357yx =+ 20.8821R = 0.2531y S = 67.3266F = ②带虚拟变量的回归模型,因1979年中国农村政策发生重大变化,引入虚拟变量来反映农村政策的变化。
01i D ⎧=⎨⎩19791979i i <≥年年 建立回归方程为: ˆ0.98550.06920.4945yx D =++ ()() ()20.9498R = 0.1751y S = 75.6895F =虽然上述两个模型都可通过显着性水平检验,但可明显看出带虚拟变量的回归模型其方差解释系数更高,回归的估计误差(y S )更小,说明模型的拟合程度更高,代表性更好。
3.5.4 岭回归的举例说明企业为用户提供的服务多种多样,那么在这些服务中哪些因素更为重要,各因素之间的重要性差异到底有多大,这些都是满意度研究需要首先解决的问题。
国际上比较流行并被实践所验证,比较科学的方法就是利用回归分析确定客户对不同服务因素的需求程度,具体方法如下:假设某电信运营商的服务界面包括了A1……Am 共M 个界面,那么各界面对总体服务满意度A 的影响可以通过以A 为因变量,以A1……Am 为自变量的回归分析,得出不同界面服务对总体A 的影响系数,从而确定各服务界面对A 的影响大小。

回归分析方法及其应用实例环境与规划学院2012级地理科学2014年11月回归分析方法及其应用实例摘要:回归分析方法,就是研究要素之间具体数量关系的一种强有力的工具,运用这种方法能够建立反应地理要素之间具体数量关系的数学模型,即回归模型。
本文首先给出回归分析方法的主要内容及解决问题的一般步骤,简单的介绍了回归分析建模的一般过程,进而引出了基本的一元线性回归分析方法的数学模型。
其次,叙述了多元线性回归理论模型,列举了多元线性回归模型应遵从的假定条件,探讨了多元线性回归模型中未知参数的估计方法及其参数的检验问题。
最后通过具体的案例来总结了多元回归分析的应用。
关键词:多元线性回归模型;模型检验;SPSS;实例应用。
引言:用回归分析建模的一般过程:(1)画散点图(2)设定模型(3)最小二乘估计模型中的参数并写出回归方程(4)拟合优度的测量(5)回归参数的显著性检验及其置信区间(6)残差分析(回归分析的前提假定)(7)预测(点、区间)在利用回归分析解决问题时,首先要建立模型,即函数关系式,其自变量称为回归变量,因变量称为应变量或响应变量。
如果模型中只含有一个回归变量,称为一元回归模型,否则称为多元回归模型(实际中所见到的大都是线性回归模型,非线性的一般可以化为线性的来处理)。
一、一元线性回归模型有一元线性回归模型(统计模型)如下:Y t =β0+β1 x t + u t上式表示变量y t和x t之间的真实关系。
其中yt称被解释变量(因变量),xt称解释变量(自变量),ut称随机误差项,β0称常数项,β1称回归系数(通常未知)。
上模型可以分为两部分。
(1)回归函数部分,E(y t) =β0+ β1 x t,(2)随机部分,u t(包含了所有没有考虑在内的影响因素对因变量的影响,越小越好)二、多元线性回归模型2.1 当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元线性回归。
设可预测的随机变量为y,它受到k个非随机因素X1,X2,X3``````X k 和不可预测的随机因素ε的影响。
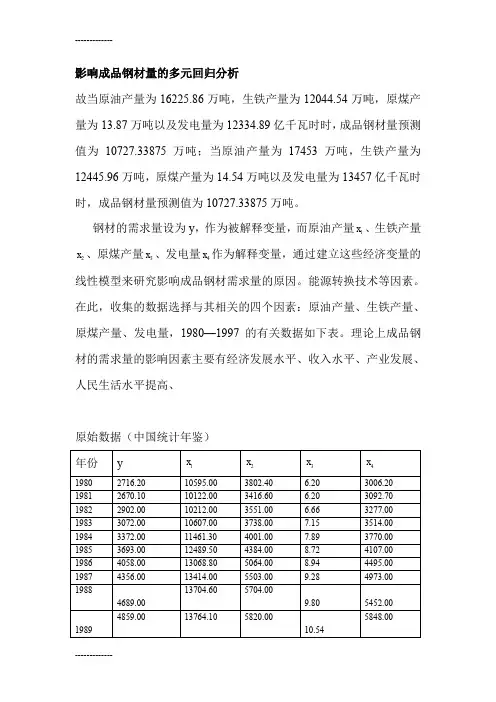
影响成品钢材量的多元回归分析故当原油产量为16225.86万吨,生铁产量为12044.54万吨,原煤产量为13.87万吨以及发电量为12334.89亿千瓦时时,成品钢材量预测值为10727.33875万吨;当原油产量为17453万吨,生铁产量为12445.96万吨,原煤产量为14.54万吨以及发电量为13457亿千瓦时时,成品钢材量预测值为10727.33875万吨。
钢材的需求量设为y,作为被解释变量,而原油产量x、生铁产量1x、原煤产量3x、发电量4x作为解释变量,通过建立这些经济变量的2线性模型来研究影响成品钢材需求量的原因。
能源转换技术等因素。
在此,收集的数据选择与其相关的四个因素:原油产量、生铁产量、原煤产量、发电量,1980—1997的有关数据如下表。
理论上成品钢材的需求量的影响因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、原始数据(中国统计年鉴)将中国成品一、 模型的设定设因变量y 与自变量1x 、2x 、3x 、4x 的一般线性回归模型为:y = 0β+11223344x x x x ββββε++++ε是随机变量,通常满足()0εE =;Var(ε)=2σ二 参数估计再用spss 做回归线性,根据系数表得出回归方程为:1234170.2870.0410.55417.8180.389y x x x x =-+-+ 再做回归预测,得出如下截图:故当原油产量为16225.86万吨,生铁产量为12044.54万吨,原煤产量为13.87万吨以及发电量为12334.89亿千瓦时时,成品钢材量预测值为10727.33875万吨;当原油产量为17453万吨,生铁产量为12445.96万吨,原煤产量为14.54万吨以及发电量为13457亿千瓦时时,成品钢材量预测值为10727.33875万吨。
三 回归方程检验由相关系数表看出,因变量与各个自变量的相关系数都很高,都在0.9 以上,说明变量间的线性相关程度很高,适合做多元线性回归模型。


第一章习题1.1变量间统计关系和函数关系的区别是什么?1.2回归分析与相关分析的区别和联系是什么?1.3回归模型中随机误差项的意义是什么?1.4线性回归模型中的基本假设是什么?1.5回归变量设置的理论依据是什么?在设置回归变量时应注意哪些问题?1.6收集、整理数据包括哪些基本内容?1.7构造回归理论模型的基本依据是什么?1.8为什么要对回归模型进行检验?1.9回归模型有哪几个方面的应用?1.10为什么强调运用回归分析研究经济问题要定性分析和定量分析相结合?第二章 习题2.1一元线性回归模型有哪些基本假定? 2.2 考虑过原点的线性回归模型1,1,,i i i y x i n βε=+=误差1,,n εε仍满足基本假定。
求1β的最小二乘估计。
2.3证明(2.27)式,10nii e==∑,10ni i i x e ==∑。
2.4回归方程01Ey x ββ=+的参数01,ββ的最小二乘估计与极大似然估计在什么条件下等价?给出证明。
2.5 证明0ˆβ是0β的无偏估计。
2.6 证明(2.42)式 ()()222021,i x Var n x x βσ⎡⎤=+⎢⎥-⎢⎥⎣⎦∑成立 2.7 证明平方和分解式SST SSR SSE =+2.8 验证三种检验的关系,即验证:(1)t ==(2)2212ˆ1ˆ2xx L SSR F t SSE n βσ===-2.9 验证(2..63)式:()()221var 1i i xx x x e n L σ⎡⎤-=--⎢⎥⎢⎥⎣⎦2.10 用第9题证明()2211ˆˆ2n i ii y y n σ==--∑是2σ的无偏估计。
2.11* 验证决定系数2r 与F 值之间的关系式 22Fr F n =+-以上表达式说明2r 与F 值是等价的,那么我们为什么要分别引入这两个统计量,而不是只使用其中的一个。
2.12* 如果把自变量观测值都乘以2,回归参数的最小二乘估计0ˆβ和1ˆβ会发生什么变化?如果把自变量观测值都加上2,回归参数的最小二乘估计0ˆβ和1ˆβ会发生什么变化? 2.13 如果回归方程01ˆˆˆy x ββ=+相应的相关系数r 很大,则用它预测时,预测误差一定较小。

应用回归分析有哪些方法回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。
这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。
例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是回归。
回归分析是建模和分析数据的重要工具。
这些技术主要有三个度量(自变量的个数,因变量的类型以及回归线的形状)。
1、线性回归(Linear Regression)它是最为人熟知的建模技术之一。
线性回归通常是人们在学习预测模型时首选的技术之一。
在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。
线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。
用一个方程式来表示它,即Y=a+b*X + e,其中a表示截距,b 表示直线的斜率,e 是误差项。
这个方程可以根据给定的预测变量(s)来预测目标变量的值。
一元线性回归和多元线性回归的区别在于,多元线性回归有(>1)个自变量,而一元线性回归通常只有1个自变量。
现在的问题是:我们如何得到一个最佳的拟合线呢?这个问题可以使用最小二乘法轻松地完成。
最小二乘法也是用于拟合回归线最常用的方法。
对于观测数据,它通过最小化每个数据点到线的垂直偏差平方和来计算最佳拟合线。
因为在相加时,偏差先平方,所以正值和负值没有抵消。
2、逻辑回归(Logistic Regression)逻辑回归是用来计算「事件=Success」和「事件=Failure」的概率。
当因变量的类型属于二元(1 / 0,真/假,是/否)变量时,我们就应该使用逻辑回归。
这里,Y的值从0到1,它可以用下方程表示。
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrenceln(odds) = ln(p/(1-p))logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk它广泛的用于分类问题。

可编辑修改精选全文完整版实用回归分析第四版第一章回归分析概述1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章一元线性回归分析思考与练习参考答案2.1一元线性回归有哪些基本假定?答:假设1、解释变量X是确定性变量,Y是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(εi)=0 i=1,2, …,nVar (εi)=σ2i=1,2, …,nCov(εi,εj)=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X之间不相关:Cov(X i, εi)=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布εi~N(0, σ2) i=1,2, …,n2.3 证明(2.27式),∑e i =0 ,∑e i X i=0 。
证明:∑∑+-=-=niiiniXYYYQ12121))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =02.5 证明0ˆβ是β0的无偏估计。
证明:)1[)ˆ()ˆ(1110∑∑==--=-=ni i xxi ni i Y L X X X Y n E X Y E E ββ)] )(1([])1([1011i i xx i n i i xx i ni X L X X X n E Y L X X X n E εββ++--=--=∑∑==01010)()1(])1([βεβεβ=--+=--+=∑∑==i xxi ni i xx i ni E L X X X n L X X X n E 2.6 证明 证明:)] ()1([])1([)ˆ(102110i i xxi ni i xx i n i X Var L X X X n Y L X X X n Var Var εβββ++--=--=∑∑==222212]1[])(2)1[(σσxx xx i xx i ni L X n L X X X nL X X X n +=-+--=∑=2.7 证明平方和分解公式:SST=SSE+SSR证明:2.8 验证三种检验的关系,即验证: (1)21)2(r r n t --=;(2)2221ˆˆ)2/(1/t L n SSE SSR F xx ==-=σβ 证明:(1)01ˆˆˆˆi i i i iY X e Y Y ββ=+=-())1()1()ˆ(222122xx ni iL X n X XX nVar +=-+=∑=σσβ()()∑∑==-+-=-=n i ii i n i i Y Y Y Y Y Y SST 1212]ˆ()ˆ[()()()∑∑∑===-+--+-=ni ii ni i i i ni iY Y Y Y Y Y Y Y 12112)ˆˆ)(ˆ2ˆ()()SSE SSR )Y ˆY Y Y ˆn1i 2i i n1i 2i+=-+-=∑∑==0100ˆˆQQββ∂∂==∂∂ˆt======(2)2222201111 1111ˆˆˆˆˆˆ()()(())(()) n n n ni i i i xxi i i iSSR y y x y y x x y x x Lβββββ=====-=+-=+--=-=∑∑∑∑2212ˆ/1ˆ/(2)xxLSSRF tSSE nβσ∴===-2.9 验证(2.63)式:2211σ)L)xx(n()e(Varxxii---=证明:0112222222ˆˆˆvar()var()var()var()2cov(,)ˆˆˆvar()var()2cov(,())()()11[]2[]()1[1]i i i i i i ii i i ii ixx xxixxe y y y y y yy x y y x xx x x xn L n Lx xn Lβββσσσσ=-=+-=++-+---=++-+-=--其中:222221111))(1()(1))(,()()1,())(ˆ,(),())(ˆ,(σσσββxxixxiniixxiiiniiiiiiiiLxxnLxxnyLxxyCovxxynyCovxxyCovyyCovxxyyCov-+=-+=--+=-+=-+∑∑==2.10 用第9题证明是σ2的无偏估计量证明:2221122112211ˆˆ()()()22()111var()[1]221(2)2n ni ii in niii i xxE E y y E en nx xen n n Lnnσσσσ=====-=---==----=-=-∑∑∑∑第三章1.一个回归方程的复相关系数R=0.99,样本决定系数R2=0.9801,我们能2ˆ22-=∑neiσ判断这个回归方程就很理想吗? 答:不能断定这个回归方程理想。

第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑2n01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75))[]1169049363110/3=++++=6.1σ∧= (5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2||(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)22001()(,())xxx N n L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()nii nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈/2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
实用回归分析第四版第一章回归分析概述1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章一元线性回归分析思考与练习参考答案2.1一元线性回归有哪些基本假定?答:假设1、解释变量X是确定性变量,Y是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(εi)=0 i=1,2, …,nVar (εi)=σ2i=1,2, …,nCov(εi,εj)=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X之间不相关:Cov(X i, εi)=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布εi~N(0, σ2) i=1,2, …,n2.3 证明(2.27式),∑e i =0 ,∑e i X i=0 。
证明:∑∑+-=-=niiiniXYYYQ12121))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =02.5 证明0ˆβ是β0的无偏估计。
证明:)1[)ˆ()ˆ(1110∑∑==--=-=ni i xxi n i i Y L X X X Y n E X Y E E ββ )] )(1([])1([1011i i xx i n i i xx i ni X L X X X n E Y L X X X n E εββ++--=--=∑∑==1010)()1(])1([βεβεβ=--+=--+=∑∑==i xx i ni i xx i ni E L X X X nL X X X n E 2.6 证明 证明:)] ()1([])1([)ˆ(102110i i xxi ni ixx i ni X Var L X X X n Y L X X X n Var Var εβββ++--=--=∑∑== 222212]1[])(2)1[(σσxx xx i xx i ni L X n L X X X nL X X X n +=-+--=∑=2.7 证明平方和分解公式:SST=SSE+SSR证明:2.8 验证三种检验的关系,即验证: (1)21)2(r r n t --=;(2)2221ˆˆ)2/(1/t L n SSE SSR F xx ==-=σβ 01ˆˆˆˆi i i i iY X e Y Y ββ=+=-())1()1()ˆ(222122xx ni iL X n X XX nVar +=-+=∑=σσβ()()∑∑==-+-=-=n i ii i n i i Y Y Y Y Y Y SST 1212]ˆ()ˆ[()()()∑∑∑===-+--+-=ni ii ni i i i ni iY Y Y Y Y Y Y Y 12112)ˆˆ)(ˆ2ˆ()()SSESSR )Y ˆY Y Y ˆn1i 2ii n1i 2i +=-+-=∑∑==0100ˆˆQQββ∂∂==∂∂证明:(1)ˆt======(2)2222201111 1111ˆˆˆˆˆˆ()()(())(()) n n n ni i i i xxi i i iSSR y y x y y x x y x x Lβββββ=====-=+-=+--=-=∑∑∑∑2212ˆ/1ˆ/(2)xxLSSRF tSSE nβσ∴===-2.9 验证(2.63)式:2211σ)L)xx(n()e(Varxxii---=证明:0112222222ˆˆˆvar()var()var()var()2cov(,)ˆˆˆvar()var()2cov(,())()()11[]2[]()1[1]i i i i i i ii i i ii ixx xxixxe y y y y y yy x y y x xx x x xn L n Lx xn Lβββσσσσ=-=+-=++-+---=++-+-=--其中:222221111))(1()(1))(,()()1,())(ˆ,(),())(ˆ,(σσσββxxixxiniixxiiiniiiiiiiiLxxnLxxnyLxxyCovxxynyCovxxyCovyyCovxxyyCov-+=-+=--+=-+=-+∑∑==2.10 用第9题证明是σ2的无偏估计量证明:2221122112211ˆˆ()()()22()111var()[1]221(2)2n ni ii in niii i xxE E y y E en nx xen n n Lnnσσσσ=====-=---==----=-=-∑∑∑∑第三章2ˆ22-=∑neiσ1.一个回归方程的复相关系数R=0.99,样本决定系数R 2=0.9801,我们能判断这个回归方程就很理想吗? 答:不能断定这个回归方程理想。
3.1.2虚拟变量的应用例3.1.2.1:为研究美国住房面积的需求,选用3120户家庭为建模样本,回归模型为:123log log P Y βββ++logQ=其中:Q ——3120个样本家庭的年住房面积(平方英尺)横截面数据P ——家庭所在地的住房单位价格 Y ——家庭收入经计算:0.247log 0.96log P Y -+logy=4.1720.371R =(0.11)(0.017)(0.026)上式中2β=0.247-的价格弹性系数,3β=0.96的收入弹性系数,均符合经济学的常识,即价格上升,住房需求下降,收入上升,住房需求也上升。
但白人家庭与黑人家庭对住房的需求量是不一样的,引进虚拟变量D :01i D ⎧=⎨⎩黑人家庭白人家庭或其他家庭模型为:112233log log log log D P D P Y D Y βαβαβα+++++logQ=例3.1.2.2:某省农业生产资料购买力和农民货币收入数据如下:(单位:十亿元)①根据上述数据建立一元线性回归方程:ˆ 1.01610.09357yx =+20.8821R =0.2531y S =67.3266F = ②带虚拟变量的回归模型,因1979年中国农村政策发生重大变化,引入虚拟变量来反映农村政策的变化。
01i D ⎧=⎨⎩19791979i i <≥年年建立回归方程为: ˆ0.98550.06920.4945yx D =++ (9.2409)(6.3997)(3.2853)20.9498R =0.1751y S =75.6895F =虽然上述两个模型都可通过显著性水平检验,但可明显看出带虚拟变量的回归模型其方差解释系数更高,回归的估计误差(y S )更小,说明模型的拟合程度更高,代表性更好。
3.5.4岭回归的举例说明企业为用户提供的服务多种多样,那么在这些服务中哪些因素更为重要,各因素之间的重要性差异到底有多大,这些都是满意度研究需要首先解决的问题。
4、回归分析方法应用实例在制定运动员选材标准时,理论上要求先对不同年龄的运动员,各测试一个较大的样本,然后,计算出各年龄的平均数、标准差,再来制定标准。
但是,在实际工作中,有时某些年龄组不能测到较大的样本。
这时能不能使用统计的方法,进行处理呢?我们遇到一个实例。
测得45名11至18岁男田径运动员的立定三级跳远数据。
其各年龄组人数分布如表一。
由于受到许多客观因素的限制,一时无法再扩大样本,因此决定使用统计方法进行处理。
第一步,首先用原始数据做散点图,并通过添加趋势线,看数据的变化趋势是否符合随年龄增长而变化的趋势,决定能否使用回归方程制定标准。
如果趋势线不符合随年龄增长而变化的趋势,或者相关程度很差就不能用了。
本例作出的散点图如图1,图上用一元回归方法添加趋势线,并计算出年龄和立定三级跳远的:一元回归方程:Y=2.5836+0.3392 X相关系数 r=0.7945(P<0.01)由于从趋势线可以看出,立定三级跳远的成绩是随年龄增加而逐渐增加,符合青少年的发育特点。
而且, 相关系数r=0.7945,呈高度相关。
因此,可以认为计算出的一元回归方程,反映了11至18岁男运动员年龄和立定三级跳远成绩的线性关系。
决定用一元回归方程来制定各年龄组的标准。
第二步,用一元回归方程:Y=2.5836+0.3392 X 推算出各年龄的立定三级跳远回归值,作为各年龄组的第2等标准。
第三步,用45人的立定三级跳远数据计算出标准差为:0.8271。
由于在正态分布下,如把平均数作为标准约有50%的人可达到标准,用平均数-0.25标准差制定标准则约有60%的人可达到,用平均数+0.25、+0.52、+0.84标准差制定标准约有40%、30%、20%的人可达到标准。
本例用各年龄组回归值-0.25标准差、+0.25标准差、+0.52标准差、+0.84标准差计算出1至5等标准如表2、图2。
2、应用方差分析方法进行数据统计分析的研究。