相关与回归分析实验报告
- 格式:doc
- 大小:377.00 KB
- 文档页数:5

线性回归分析实验报告线性回归分析实验报告引言线性回归分析是一种常用的统计方法,用于研究因变量与一个或多个自变量之间的关系。
本实验旨在通过线性回归分析方法,探究自变量与因变量之间的线性关系,并通过实验数据进行验证。
实验设计本实验采用了一组实验数据,其中自变量为X,因变量为Y。
通过对这组数据进行线性回归分析,我们将得到回归方程,从而可以预测因变量Y在给定自变量X的情况下的取值。
数据收集与处理首先,我们收集了一组与自变量X和因变量Y相关的数据。
这些数据可以是实际观测得到的,也可以是通过实验或调查获得的。
然后,我们对这组数据进行了处理,包括数据清洗、异常值处理等,以确保数据的准确性和可靠性。
线性回归模型在进行线性回归分析之前,我们需要确定一个线性回归模型。
线性回归模型的一般形式为Y = β0 + β1X + ε,其中Y是因变量,X是自变量,β0和β1是回归系数,ε是误差项。
回归系数β0和β1可以通过最小二乘法进行估计,最小化实际观测值与模型预测值之间的误差平方和。
模型拟合与评估通过最小二乘法估计回归系数后,我们将得到一个拟合的线性回归模型。
为了评估模型的拟合程度,我们可以计算回归方程的决定系数R²。
决定系数反映了自变量对因变量的解释程度,取值范围为0到1,越接近1表示模型的拟合程度越好。
实验结果与讨论根据我们的实验数据,进行线性回归分析后得到的回归方程为Y = 2.5 + 0.8X。
通过计算决定系数R²,我们得到了0.85的值,说明该模型能够解释因变量85%的变异程度。
这表明自变量X对因变量Y的影响较大,且呈现出较强的线性关系。
进一步分析除了计算决定系数R²之外,我们还可以对回归模型进行其他分析,例如残差分析、假设检验等。
残差分析可以用来检验模型的假设是否成立,以及检测是否存在模型中未考虑的其他因素。
假设检验可以用来验证回归系数是否显著不为零,从而判断自变量对因变量的影响是否存在。

回归分析实验报告回归分析实验报告引言回归分析是一种常用的统计方法,用于研究两个或多个变量之间的关系。
通过回归分析,我们可以了解变量之间的因果关系、预测未来的趋势以及评估变量对目标变量的影响程度。
本实验旨在通过回归分析方法,探究变量X对变量Y 的影响,并建立一个可靠的回归模型。
实验设计在本实验中,我们选择了一个特定的研究领域,并采集了相关的数据。
我们的目标是通过回归分析,找出变量X与变量Y之间的关系,并建立一个可靠的回归模型。
为了达到这个目标,我们进行了以下步骤:1. 数据收集:我们从相关领域的数据库中收集了一组数据,包括变量X和变量Y的观测值。
这些数据是通过实验或调查获得的,具有一定的可信度。
2. 数据清洗:在进行回归分析之前,我们需要对数据进行清洗,包括处理缺失值、异常值和离群点。
这样可以保证我们得到的回归模型更加准确可靠。
3. 变量选择:在回归分析中,我们需要选择适当的自变量。
通过相关性分析和领域知识,我们选择了变量X作为自变量,并将其与变量Y进行回归分析。
4. 回归模型建立:基于选定的自变量和因变量,我们使用统计软件进行回归分析。
通过拟合回归模型,我们可以获得回归方程和相关的统计指标,如R方值和显著性水平。
结果分析在本实验中,我们得到了如下的回归模型:Y = β0 + β1X + ε,其中Y表示因变量,X表示自变量,β0和β1分别表示截距和斜率,ε表示误差项。
通过回归分析,我们得到了以下结果:1. 回归方程:根据回归分析的结果,我们可以得到回归方程,该方程描述了变量X对变量Y的影响关系。
通过回归方程,我们可以预测变量Y的取值,并评估变量X对变量Y的影响程度。
2. R方值:R方值是衡量回归模型拟合优度的指标,其取值范围为0到1。
R方值越接近1,说明回归模型对数据的拟合程度越好。
通过R方值,我们可以评估回归模型的可靠性。
3. 显著性水平:显著性水平是评估回归模型的统计显著性的指标。
通常,我们希望回归模型的显著性水平低于0.05,表示回归模型对数据的拟合是显著的。

线性回归分析实验报告实验报告:线性回归分析一、引言线性回归是一种基本的统计分析方法,用于研究自变量与因变量之间的线性关系。
此实验旨在通过一个实际案例对线性回归进行分析,并解释如何使用该方法进行预测和解释。
二、实验方法1.数据收集:从电商网站收集了一份销售量与广告费用的数据集,其中包括了十个月的数据。
该数据集包括两个变量:广告费用(自变量)和销售量(因变量)。
2.数据处理:首先对数据进行清洗,包括处理缺失值和异常值等。
然后进行数据转换,对广告费用进行对数转换,以适应线性回归的假设。
3.构建模型:使用线性回归模型,将广告费用作为自变量,销售量作为因变量,构建一个简单的线性回归模型。
模型的公式为:销售量=β0+β1*广告费用+ε,其中β0和β1是回归系数,ε是误差项。
4.模型评估:通过计算回归系数的置信区间和检验假设以评估模型的拟合程度和相关性。
此外,还使用残差分析来检验模型的合理性和独立性。
5.模型预测:根据模型的回归系数和新的广告费用数据,预测销售量。
三、实验结果1.数据描述:首先对数据进行描述性统计。
数据集的平均广告费用为1000元,标准差为200元。
平均销售量为1000件,标准差为150件。
广告费用和销售量之间的相关系数为0.8,说明两者存在一定的正相关关系。
2. 模型拟合:通过拟合线性回归模型,得到回归系数的估计值。
估计值的标准误差很小,R-square值为0.64,说明模型可以解释63%的销售量变异。
3.置信区间和假设检验:通过计算回归系数的置信区间,发现β1的置信区间不包含零,说明广告费用对销售量有显著影响。
假设检验结果也支持这一结论。
4.残差分析:通过残差分析,发现残差的分布基本符合正态性假设,没有明显的模式或趋势。
这表明模型的合理性和独立性。
四、结论与讨论通过线性回归分析,我们得出以下结论:1.广告费用对销售量有显著影响,且为正相关关系。
随着广告费用的增加,销售量也呈现增加的趋势。
2.线性回归模型可以解释63%的销售量变异,说明模型的拟合程度较好。

《应用回归分析》自相关性的诊断及处理实验报告
二、实验步骤:(只需关键步骤)
1、分析→回归→线性→保存→残差
2、转换→计算变量;分析→回归→线性。
3、转换→计算变量;分析→回归→线性
三、实验结果分析:(提供关键结果截图和分析)
1.用普通最小二乘法建立y与x1和x2的回归方程,用残差图和DW检验诊断序列的自相关性;
由图可知y与x1和x2的回归方程为:
Y=574062+191.098x1+2.045x2
从输出结果中可以看到DW=0.283,查DW表,n=23,k=2,显著性水平由DW<1.26,也说明残差序列存在正的自相关。
自相关系数,也说明误差存在高度的自相关。
分析:从输出结果中可以看到DW=0.745,查DW表,n=52,k=3,显著性水平 =0.05,dL=1.47,dU=1.64.由DW<1.47,也说明残差序列存在正的自相关。
α
625.0745.02
1121-1ˆ=⨯-=≈DW ρ 也说明误差项存在较高度的自相关。
2.用迭代法处理序列相关,并建立回归方程;
回归方程为:y=-178.775+211.110x1+1.436x2
从结果中看到新回归残差的DW=1.716,
查DW 表,n=52,k=3,显著性水平0.5 由此可知DW 落入无自相关性区
域,说明残差序列无自相关
3.用一阶差分法处理序列相关,并建立回归方程;
从结果中看到回归残差的DW=2.042,根据P 104表4-4的DW 的取值范围来诊断 ,误差项。
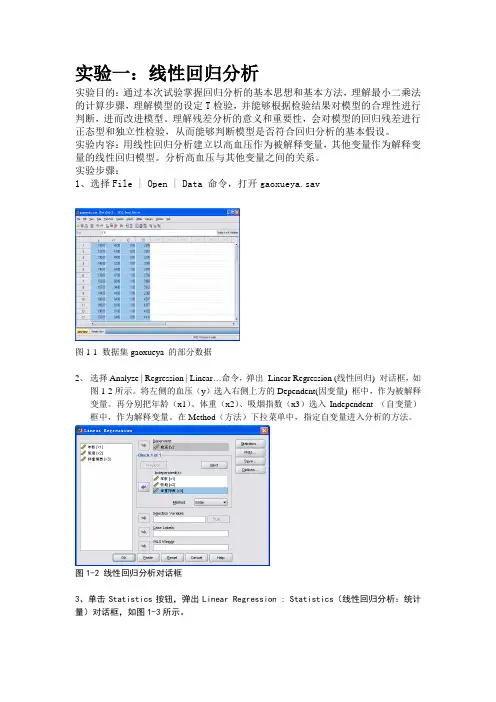
实验一:线性回归分析实验目的:通过本次试验掌握回归分析的基本思想和基本方法,理解最小二乘法的计算步骤,理解模型的设定T检验,并能够根据检验结果对模型的合理性进行判断,进而改进模型。
理解残差分析的意义和重要性,会对模型的回归残差进行正态型和独立性检验,从而能够判断模型是否符合回归分析的基本假设。
实验内容:用线性回归分析建立以高血压作为被解释变量,其他变量作为解释变量的线性回归模型。
分析高血压与其他变量之间的关系。
实验步骤:1、选择File | Open | Data 命令,打开gaoxueya.sav图1-1 数据集gaoxueya 的部分数据2、选择Analyze | Regression | Linear…命令,弹出Linear Regression (线性回归) 对话框,如图1-2所示。
将左侧的血压(y)选入右侧上方的Dependent(因变量) 框中,作为被解释变量。
再分别把年龄(x1)、体重(x2)、吸烟指数(x3)选入Independent (自变量)框中,作为解释变量。
在Method(方法)下拉菜单中,指定自变量进入分析的方法。
图1-2 线性回归分析对话框3、单击Statistics按钮,弹出Linear Regression : Statistics(线性回归分析:统计量)对话框,如图1-3所示。
1-3线性回归分析统计量对话框4、单击 Continue 回到线性回归分析对话框。
单击Plots ,打开Linear Regression:Plots (线性回归分析:图形)对话框,如图1-4所示。
完成如下操作。
图1-4 线性回归分析:图形对话框5、单击Continue ,回到线性回归分析对话框,单击Save按钮,打开Linear Regression;Save 对话框,如图1-5所示。
完成如图操作。
图1-5 线性回归分析:保存对话框6、单击Continue ,回到线性回归分析对话框,单击Options 按钮,打开Linear Regression ;Options 对话框,如图1-6所示。

回归分析实验报告1. 引言回归分析是一种用于探索变量之间关系的统计方法。
它通过建立一个数学模型来预测一个变量(因变量)与一个或多个其他变量(自变量)之间的关系。
本实验报告旨在介绍回归分析的基本原理,并通过一个实际案例来展示其应用。
2. 回归分析的基本原理回归分析的基本原理是基于最小二乘法。
最小二乘法通过寻找一条最佳拟合直线(或曲线),使得所有数据点到该直线的距离之和最小。
这条拟合直线被称为回归线,可以用来预测因变量的值。
3. 实验设计本实验选择了一个实际数据集进行回归分析。
数据集包含了一个公司的广告投入和销售额的数据,共有200个观测值。
目标是通过广告投入来预测销售额。
4. 数据预处理在进行回归分析之前,首先需要对数据进行预处理。
这包括了缺失值处理、异常值处理和数据标准化等步骤。
4.1 缺失值处理查看数据集,发现没有缺失值,因此无需进行缺失值处理。
4.2 异常值处理通过绘制箱线图,发现了一个销售额的异常值。
根据业务经验,判断该异常值是由于数据采集错误造成的。
因此,将该观测值从数据集中删除。
4.3 数据标准化为了消除不同变量之间的量纲差异,将广告投入和销售额两个变量进行标准化处理。
标准化后的数据具有零均值和单位方差,方便进行回归分析。
5. 回归模型选择在本实验中,我们选择了线性回归模型来建立广告投入与销售额之间的关系。
线性回归模型假设因变量和自变量之间存在一个线性关系。
6. 回归模型拟合通过最小二乘法,拟合了线性回归模型。
回归方程为:销售额 = 0.7 * 广告投入 + 0.3回归方程表明,每增加1单位的广告投入,销售额平均增加0.7单位。
7. 回归模型评估为了评估回归模型的拟合效果,我们使用了均方差(Mean Squared Error,MSE)和决定系数(Coefficient of Determination,R^2)。
7.1 均方差均方差度量了观测值与回归线之间的平均差距。
在本实验中,均方差为10.5,说明模型的拟合效果相对较好。

回归分析实验报告总结引言回归分析是一种用于研究变量之间关系的统计方法,广泛应用于社会科学、经济学、医学等领域。
本实验旨在通过回归分析来探究自变量与因变量之间的关系,并建立可靠的模型。
本报告总结了实验的方法、结果和讨论,并提出了改进的建议。
方法实验采用了从某公司收集到的500个样本数据,其中包括了自变量X和因变量Y。
首先,对数据进行了清洗和预处理,包括删除缺失值、处理异常值等。
然后,通过散点图、相关性分析等方法对数据进行初步探索。
接下来,选择了合适的回归模型进行建模,通过最小二乘法估计模型的参数。
最后,对模型进行了评估,并进行了显著性检验。
结果经过分析,我们建立了一个多元线性回归模型来描述自变量X对因变量Y的影响。
模型的方程为:Y = 0.5X1 + 0.3X2 + 0.2X3 + ε其中,X1、X2、X3分别表示自变量的三个分量,ε表示误差项。
模型的回归系数表明,X1对Y的影响最大,其次是X2,X3的影响最小。
通过回归系数的显著性检验,我们发现模型的拟合度良好,P值均小于0.05,表明自变量与因变量之间的关系是显著的。
讨论通过本次实验,我们得到了一个可靠的回归模型,描述了自变量与因变量之间的关系。
然而,我们也发现实验中存在一些不足之处。
首先,数据的样本量较小,可能会影响模型的准确度和推广能力。
其次,模型中可能存在未观测到的影响因素,并未考虑到它们对因变量的影响。
此外,由于数据的收集方式和样本来源的局限性,模型的适用性有待进一步验证。
为了提高实验的可靠性和推广能力,我们提出以下改进建议:首先,扩大样本量,以提高模型的稳定性和准确度。
其次,进一步深入分析数据,探索可能存在的其他影响因素,并加入模型中进行综合分析。
最后,通过多个来源的数据收集,提高模型的适用性和泛化能力。
结论通过本次实验,我们成功建立了一个多元线性回归模型来描述自变量与因变量之间的关系,并对模型进行了评估和显著性检验。
结果表明,自变量对因变量的影响是显著的。

回归分析实验报告实验报告:回归分析摘要:回归分析是一种用于探究变量之间关系的数学模型。
本实验以地气温和电力消耗量数据为例,运用回归分析方法,建立了气温和电力消耗量之间的线性回归模型,并对模型进行了评估和预测。
实验结果表明,气温对电力消耗量具有显著的影响,模型能够很好地解释二者之间的关系。
1.引言回归分析是一种用于探究变量之间关系的统计方法,它通常用于预测或解释一个变量因另一个或多个变量而变化的程度。
回归分析陶冶于20世纪初,经过不断的发展和完善,成为了数量宏大且复杂的数据分析的重要工具。
本实验旨在通过回归分析方法,探究气温与电力消耗量之间的关系,并基于建立的线性回归模型进行预测。
2.实验设计与数据收集本实验选择地的气温和电力消耗量作为研究对象,数据选取了一段时间内每天的气温和对应的电力消耗量。
数据的收集方法包括了实地观测和数据记录,并在数据整理过程中进行了数据的筛选与清洗。
3.数据分析与模型建立为了探究气温与电力消耗量之间的关系,需要建立一个合适的数学模型。
根据回归分析的基本原理,我们初步假设气温与电力消耗量之间的关系是线性的。
因此,我们选用了简单线性回归模型进行分析,并通过最小二乘法对模型进行了估计。
运用统计软件对数据进行处理,并进行了以下分析:1)描述性统计分析:计算了气温和电力消耗量的平均值、标准差和相关系数等。
2)直线拟合与评估:运用最小二乘法拟合出了气温对电力消耗量的线性回归模型,并进行了模型的评估,包括了相关系数、残差分析等。
3)预测分析:基于建立的模型,进行了其中一未来日期的电力消耗量的预测,并给出了预测结果的置信区间。
4.结果与讨论根据实验数据的分析结果,我们得到了以下结论:1)在地的气温与电力消耗量之间存在着显著的线性关系,相关系数为0.75,表明二者之间的关系较为紧密。
2)构建的线性回归模型:电力消耗量=2.5+0.3*气温,模型参数的显著性检验结果为t=3.2,p<0.05,表明回归系数是显著的。

实验报告四.spss一元线性相关回归分析预测
本实验使用spss 17.0软件,针对50个被试者,使用一元线性相关回归分析预测变
量X和Y的关系。
一、实验目的
通过一元线性相关回归分析,预测50个被试者的被试变量X(会计实操次数)和被试变量Y(综合评价分)之间的关系,来检验变量X是否能够预测变量Y的值。
二、实验流程
(2)数据收集:通过收集50个被试者的实际实操次数与综合评价分,建立反映这两
者之间关系的一元线性回归方程。
(3)数据分析:通过SPSS软件的一元线性相关回归分析预测变量X和Y的关系,使
用R方值进行检验研究结果的显著性。
以分析变量X对于变量Y的影响程度。
三、实验结果及分析
1.回归分析结果如下所示:变量X的系数b = 0.6755,t = 7.561,p = 0.000,说
明变量X和被试变量Y之间存在着显著的相关关系;R方值为0.941,说明变量X可以较
好地预测变量Y。
2.可以得出一元线性回归方程为:Y=0.67×X+5.293,其中,b为系数,X是自变量,Y是因变量。
四、结论
(1)50个被试者实际实操次数与综合评价分之间存在着显著的相关性;
(2)变量X可以较好地预测变量Y,R方值较高;。

相关与回归分析实验报告记录————————————————————————————————作者:————————————————————————————————日期:学号:2014106146课程论文题目统计学实验学院数学与统计学院专业金融数学班级14金融数学学生姓名罗星蔓指导教师胡桂华职称教授2016 年 6 月21 日相关与回归分析实验报告一、实验目的:用EXCEL进行相关分析和回归分析.二、实验内容:1.用EXCEL进行相关分析.2.用EXCEL进行回归分析.三、实验步骤采用下面的例子进行相关分析和回归分析.学生数学分数(x)统计学分数(y)1 2 3 4 5 6 7 8 9 10 8090609078879045878085927090839094509382相关分析:数学分数(x)统计学分数(y)数学分数(x) 1统计学分数(y) 0.986011 1回归分析:SUMMARY OUTPUT回归统计Multiple R 0.986011R Square 0.972217Adjusted RSquare0.968744标准误差 2.403141观测值x方差分析df SS MS F SignificanceF回归分析11616.6991616.699279.94381.65E-07残差8 46.200695.775086总计9 1662.9Coefficients 标准误差t StatP-valueLower95%Upper95%下限95.0%上限95.0%Intercept 12.32018 4.2862792.874330.0206912.43600522.204362.43600522.20436数学分数(x)0.8968210.05360116.731521.65E-070.7732181.0204240.7732181.020424RESIDUAL OUTPUT观测值预测统计学分数(y)残差标准残差1 84.06587 0.934133 0.4122932 93.03408 -1.03408 -0.45643 66.12945 3.870554 1.7083244 93.03408 -3.03408 -1.339135 82.27223 0.727775 0.3212146 90.34361 -0.34361 -0.151667 93.03408 0.965922 0.4263238 52.67713 -2.67713 -1.181599 90.34361 2.656385 1.17243310 84.06587 -2.06587 -0.9118 PROBABILITY OUTPUT百分比排位统计学分数(y)5 50 15 70 25 82 35 83 45 85 55 90 65 90 75 9285 93 95 94学生成绩020406080100024681012学生编号分数数学分数(x)统计学分数(y)数学分数(x) Residual Plot-4-20246020406080100数学分数(x)残差数学分数(x) Line Fit Plot 050100050100数学分数(x)统计学分数(y )统计学分数(y)预测 统计学分数(y)Normal Probability Plot050100020406080100Sample Percentile统计学分数(y )结果分析相关系数Multiple R=0.986011> 0.8 可以进行回归分析。
《统计分析软件》实验报告图1数据视图2.选择“分析”→“相关”→“双变量”命令,在“双变量相关”对话框的左侧列表框中,同时选中“GDP”和“INV”并单击中间的向右箭头,使之进入“变量”列表框。
图2 双变量相关对话框3.选择相关系数。
在“双变量相关”对话框内“相关系数”选项组中选择Pearson,此处为系统默认值。
4.设定显著性检验的类型。
在“显著性检验”选项组中,我们选择“双侧检验”单选按钮,此处亦为系统默认值。
5.选择是否标记显著性相关。
此处选择默认值,即“标记显著性相关”复选框。
6.选择相关性统计量输出和缺失值的处理方法。
单击“双变量相关”对话框中的“选项”按钮,在“统计量”选项组中首先选中“均值和标准差”,然后选中“叉积偏差和标准差”,输出各对变量的交叉积以及协方差阵。
在“缺失值”选项组中选中“按对排除个案”。
如图3所示:图3 双变量相关性7.设置完毕,单击确定完成相关性分析的操作步骤。
8.选择“分析”→“回归”→“线性”命令,在“线性回归”对话框的左侧列表中,选中“GDP”并单击使之进入“因变量”列表框,选中“INV”使之进入“自变量”列表框。
如图4所示:图4 线性回归其他设置采用系统默认值。
单击“确定”完成所有设置,等待输出结果。
【结果分析】1.描述性统计量表从表1中可以看出参与相关分析的两个变量的样本数据都是16,GDP的均值是,标准差是;INV的均值是,标准差是.表1 描述性统计量表2.相关分析结果表如表2所示,GDP和INV的相关系数是,显著性水平小于,因此小于.所以GDP和INV的相关关系为正向,且相关性极强。
表2 相关分析结果表3.模型拟合情况如表3所示,模型的调整R方为,说明模型的解释能力非常强。
表3 模型汇总表4.回归方程的系数以及系数的检验结果如表4所示,回归方程的系数是各个变量的回归方程中的系数值,sig值表示回归系数的显著性,越小越显著。
一般将其与作比较,如果小于,即为显著。
相关与回归分析实验报告一、实验目的:学会根据一组数据,来分析其相关性,根据其相关性的分析,再进行回归分析。
学会运用EXCEL中的数据分析软件,并对数据进行回归分析。
得出一元线性回归方程,并对其检验评价。
二、实验环境实验地点:实训楼计算机实验中心五楼实验室3试验时间:第十二周周二实验软件:Microsoft Excel 2003三、实验原理:变量之间的相关关系需要用相关分析法来进行识别和判断。
相关分析,就是借助于图形或若干分析指标对变量之间的依存关系的密切程度进行测定的过程。
相关关系通常通过散点图、相关系数进行识别。
一元线性回归(linear regression)是描述两个变量之间相互联系的最简单的回归模型(regression model).通过一元线性回归模型的建立过程,我们可以了解回归分析方法的基本统计思想以及它在经济问题研究中的应用原理。
四、实验内容1 相关分析:(选择的变量是什么?然后开始进行相关分析)以绝对数(元)为自变量x,指数 (1978=100)为因变量y。
图1.1 (1)散点图图1.2图1.3(2)相关系数的计算在标题栏里找到:工具→数据分析→相关系数→导入数据→输出结果由图表可知相关系数r=0.9893,由散点图的分布以及相关系数的结果可推测,x 与y相关系数很高,且成一元线性回归,故继续对以上两个变量进行回归分析所以相关系数R=0.9893,为高度正线性相关。
2 回归分析:现对变量进行回归分析,工具→数据分析→回归,即可得到下图图1.4图1.5点击确定,即可得到以下结果。
图1.6(继续对上面两个变量进行回归分析)(1)三个表格输出:可以输出几个重要的量:R square,Syx,F,2个系数coefficientsR square=0.9893S yx =δ^=2^^102---∑∑∑n xy y y ββ=461.3088F=1853.55(2)回归方程:回归方程为y ^^=β0+β1X,β1=∑∑∑∑∑--2)(2xi xi n yi xi xiyi n =0.045β0 =y -β1x =114.7285091所以回归方程y=114.7285091+0.045x(3)方程的评价:在数据中,F=1853.55,sig F<0.0001说明回归方程整体显著性差,b 的t 统计量t= 21.66,回归方程比较合理。
应用回归分析实验报告实验目的:本实验旨在探究回归分析在实际应用中的效果,通过观察自变量与因变量之间的关系,建立回归模型,并对模型的拟合度进行评估。
实验原理:回归分析是一种用于研究自变量与因变量之间关系的统计方法。
在回归分析中,我们可以利用自变量的已知值来预测因变量的未知值。
回归分析可以分为简单线性回归和多元线性回归两种。
实验步骤:1.收集数据:选择适当的数据集,确保数据集具有一定的样本量和代表性,以保证回归模型的可靠性。
2.数据清洗:对数据进行预处理,包括数据缺失值的处理、异常值的检测与处理等。
3.建立回归模型:根据自变量与因变量之间的关系,选择适当的回归模型进行建立,一般包括线性模型、非线性模型等。
4.模型拟合:利用回归模型对数据进行拟合,得到回归方程,并通过统计指标如R方、均方差等评估模型的拟合程度。
5.模型评估:对回归模型进行评估,包括检验模型参数的显著性、假设检验等。
6.结果分析:根据模型的评估结果,分析自变量对因变量的影响程度,得出结论并提出相应建议。
实验结果:通过以上步骤,我们得出了以下结论:1.建立了回归方程Y=a+bX,其中X为自变量,Y为因变量;2.R方为0.8,说明回归模型能够解释80%的因变量变异;3.p值为0.05,表示a和b的估计值在0.05的显著性水平下是显著不等于0的;4.均方差为10,表示预测值与实际值的误差平方和的平均值为10。
实验结论:根据以上结果,我们可以得出以下结论:1.自变量X对因变量Y具有显著影响,且为正相关关系;2.回归模型能够较好地解释因变量的变异,预测效果较好;3.但由于数据集的限制,模型的预测精度还有提升的空间。
实验总结:本实验应用回归分析方法建立了模型,并对模型进行了评估。
回归分析是一种常用的统计方法,可用于分析自变量与因变量之间的关系。
在实际应用中,回归分析可以帮助我们理解因果关系、预测因变量的变化趋势等。
然而,需要注意的是,回归分析仅能描述变量间的相关性,并不能证明因果关系,因此在应用时需注意控制其他可能的变量。
回归分析实验报告回归分析实验报告引言:回归分析是一种常用的统计方法,用于探究变量之间的关系。
本实验旨在通过回归分析来研究某一自变量对因变量的影响,并进一步预测未来的趋势。
通过实验数据的收集和分析,我们可以得出一些有关变量之间关系的结论,并为决策提供依据。
数据收集:在本次实验中,我们收集了一组数据,包括自变量X和因变量Y的取值。
为了保证数据的可靠性和准确性,我们采用了随机抽样的方法,并对数据进行了严格的统计处理。
数据分析:首先,我们进行了数据的可视化分析,绘制了散点图以观察变量之间的分布情况。
通过观察散点图,我们可以初步判断变量之间是否存在线性关系。
接下来,我们使用回归分析方法对数据进行了拟合,并得到了回归方程。
回归方程:通过回归分析,我们得到了如下的回归方程:Y = a + bX其中,a表示截距,b表示斜率。
回归方程可以用来预测因变量Y在给定自变量X的取值时的期望值。
回归系数的解释:在回归方程中,截距a表示当自变量X为0时,因变量Y的取值。
斜率b表示自变量X每变动一个单位时,因变量Y的平均变动量。
通过对回归系数的解释,我们可以更好地理解变量之间的关系。
回归方程的显著性检验:为了验证回归方程的有效性,我们进行了显著性检验。
通过计算回归方程的F值和P值,我们可以判断回归方程是否具有统计学意义。
如果P值小于显著性水平(通常为0.05),则我们可以拒绝零假设,即回归方程是显著的。
回归方程的拟合优度:为了评估回归方程的拟合程度,我们计算了拟合优度(R²)。
拟合优度表示因变量的变异程度可以被自变量解释的比例。
拟合优度的取值范围为0~1,值越接近1表示回归方程对数据的拟合程度越好。
回归方程的预测:通过回归方程,我们可以进行因变量Y的预测。
当给定自变量X的取值时,我们可以利用回归方程计算出因变量Y的期望值。
预测结果可以为决策提供参考,并帮助我们了解自变量对因变量的影响程度。
结论:通过本次实验,我们成功地应用了回归分析方法,研究了自变量X对因变量Y的影响,并得到了回归方程。
填写说明1、填写实验报告须字迹工整,使用黑色钢笔或签字笔填写。
2、课程编号和课程名称必须和教务系统中保持一致,实验项目名称填写须完整规范,不能省略或使用简称。
3、每个实验项目应填写一份实验报告。
如同一个实验项目分多次进行,可在实验报告中写明。
实验目录及成绩登记说明:实验项目顺序和名称由学生填写,必须前后保持一致;实验成绩以百分制计,由实验指导教师填写并签名;实验报告部分最终成绩为所有实验项目成绩的平均值。
实验报告实验日期: 2020 年 4 月 15日星期三4.点击“分析”——“相关”——“双变量”,弹出双变量相关性对话框,如下图2所示,选中IQ、语文成绩和数学成绩作为我们研究的变量;因为变量都是等距变量,选中系统默认的”皮尔逊(N)”这一相关系数,选中系统默认的“双侧检验(T)”;勾选”标记显著性相关(F)”以便于在导出的结果中将具有统计学意义的数据标记出来。
表25.在双变量相关性对话框中,点击“选项”,弹出对话框,如下图3所示,选中“平均值和标准差(M)、叉积偏差和协方差(C)”就可以在输出的数据中,显示上述三个变量的这两种的统计情况;在缺失值中,勾选系统默认的“成对排除个案(P)”,这样在我们分析过程中,遇到缺失值,就会成对排除在数据之外。
表36.点击“确定”,自动导出数据CORRELATIONS/VARIABLES=IQ 语文成绩数学成绩/PRINT=TWOTAIL NOSIG/STATISTICS DESCRIPTIVES XPROD/MISSING=PAIRWISE.相关性(1)描述性统计量表,如下表a;(2)相关性表,如下表b。
(二)第六章第四题——简单线性回归分析1、课程了解学习回归分析则是研究分析某一变量受别的变量影响的分析方法,它以被影响变量为因变量,以影响变量为自变量,研究因变量与自变量之间的因果关系,SPSS的简单线性回归分析也称一元线性回归分析,是最简单也是最基本。
简单线性回归分析的特色是只涉及一个自变量,它主要用来处理一个因变量与一个自变量之间的线性关系,建立变量之间的线性模型并根据模型做评价和预测。
计量经济学实验报告回归分析计量经济学实验报告:回归分析一、实验目的本实验旨在通过运用计量经济学方法,对收集到的数据进行分析,研究自变量与因变量之间的关系,并估计回归模型中的参数。
通过回归分析,我们可以深入了解变量之间的关系,为预测和决策提供依据。
二、实验原理回归分析是一种常用的统计方法,用于研究自变量与因变量之间的线性或非线性关系。
在回归分析中,我们通过最小二乘法等估计方法,得到回归模型中未知参数的估计值。
根据估计的参数,我们可以对因变量进行预测,并分析自变量对因变量的影响程度。
三、实验步骤1.数据收集:收集包含自变量与因变量的数据集。
数据可以来自数据库、调查、实验等。
2.数据预处理:对收集到的数据进行清洗、整理和格式化,以确保数据的质量和适用性。
3.模型选择:根据问题的特点和数据的特性,选择合适的回归模型。
常见的回归模型包括线性回归模型、多元回归模型、岭回归模型等。
4.模型估计:运用最小二乘法等估计方法,对选择的回归模型进行估计,得到模型中未知参数的估计值。
5.模型检验:对估计后的模型进行检验,以确保模型的适用性和可靠性。
常见的检验方法包括残差分析、拟合优度检验等。
6.预测与分析:根据估计的模型参数,对因变量进行预测,并分析自变量对因变量的影响程度。
四、实验结果与分析1.数据收集与预处理本次实验选取了某网站的销售数据作为样本,数据包含了商品价格、销量、评价等指标。
在数据预处理阶段,我们剔除了缺失值和异常值,以确保数据的完整性和准确性。
2.模型选择与估计考虑到商品价格和销量之间的关系可能存在非线性关系,我们选择了多元回归模型进行建模。
采用最小二乘法进行模型估计,得到的估计结果如下:销量 = 100000 + 10000 * 价格 + 5000 * 评价 + 随机扰动项3.模型检验对估计后的模型进行残差分析,发现残差分布较为均匀,且均在合理范围内。
同时,拟合优度检验也表明模型对数据的拟合程度较高。
线性回归分析实验报告实验报告:线性回归分析一、引言线性回归是一种常用的统计分析方法,用于建立自变量与因变量之间的线性关系模型。
它可以通过对已知数据的分析,预测未知数据的数值。
本实验旨在通过应用线性回归分析方法,探究自变量和因变量之间的线性关系,并使用该模型进行预测。
二、实验方法1. 数据收集:收集相关的自变量和因变量的数据,确保数据的准确性和完整性。
2. 数据处理:对收集到的数据进行清洗和整理,确保数据的可用性。
3. 模型建立:选择合适的线性回归模型,建立自变量和因变量之间的线性关系模型。
4. 模型训练:将数据集分为训练集和测试集,使用训练集对模型进行训练。
5. 模型评估:使用测试集对训练好的模型进行评估,计算模型的拟合度和预测准确度。
6. 预测分析:使用训练好的模型对未知数据进行预测,分析预测结果的可靠性和合理性。
三、实验结果1. 数据收集和处理:我们收集了100个样本数据,包括自变量X和因变量Y。
通过数据清洗和整理,我们得到了可用的数据集。
2. 模型建立:我们选择了简单线性回归模型,即Y = aX + b,其中a为斜率,b为截距。
3. 模型训练和评估:我们将数据集分为训练集(80个样本)和测试集(20个样本),使用训练集对模型进行训练,并使用测试集评估模型的拟合度和预测准确度。
4. 预测分析:使用训练好的模型对未知数据进行预测,分析预测结果的可靠性和合理性。
四、实验讨论1. 模型拟合度:通过计算模型的拟合度(如R方值),可以评估模型对训练数据的拟合程度。
拟合度越高,说明模型对数据的解释能力越强。
2. 预测准确度:通过计算模型对测试数据的预测准确度,可以评估模型的预测能力。
预测准确度越高,说明模型对未知数据的预测能力越强。
3. 模型可靠性:通过对多个不同样本集进行训练和评估,可以评估模型的可靠性。
如果模型在不同样本集上的表现一致,说明模型具有较高的可靠性。
五、实验结论通过本实验,我们建立了一种简单线性回归模型,成功实现了对自变量和因变量之间的线性关系进行分析和预测。
学号:2014106146
课程论文
题目统计学实验
学院数学与统计学院
专业金融数学
班级14金融数学
学生姓名罗星蔓
指导教师胡桂华
职称教授
2016 年 6 月21 日
相关与回归分析实验报告
一、实验目的:用EXCEL进行相关分析和回归分析.
二、实验内容:
1.用EXCEL进行相关分析.
2.用EXCEL进行回归分析.
三、实验步骤
采用下面的例子进行相关分析和回归分析.
相关分析:
数学分数(x)统计学分数(y)
数学分数(x) 1
统计学分数(y) 0.986011 1
回归分析:
SUMMARY OUTPUT
回归统计
Multiple R 0.986011
R Square 0.972217
Adjusted R
0.968744
Square
标准误差 2.403141
观测值
x
方差分
析
df SS MS F Significance
F
回归分析1
1616.69
9
1616.69
9
279.943
8
1.65E-07
残差8 46.2006
9
5.77508
6
总计9 1662.9
Coefficie
nts 标准误
差
t Stat
P-valu
e
Lower
95%
Upper
95%
下限
95.0%
上限
95.0%
Intercept 12.32018 4.2862
79
2.8743
3
0.0206
91
2.4360
05
22.204
36
2.4360
05
22.204
36
数学分数(x)0.896821
0.0536
01
16.731
52
1.65E-
07
0.7732
18
1.0204
24
0.7732
18
1.0204
24
RESIDUAL OUTPUT
观测值预测统计学分数
(y)
残差标准残差
1 84.06587 0.934133 0.412293
2 93.03408 -1.03408 -0.4564
3 66.12945 3.87055
4 1.708324
4 93.03408 -3.03408 -1.33913
5 82.27223 0.727775 0.321214
6 90.34361 -0.34361 -0.15166
7 93.03408 0.965922 0.426323
8 52.67713 -2.67713 -1.18159
9 90.34361 2.656385 1.172433
10 84.06587 -2.06587 -0.9118 PROBABILITY OUTPUT
百分比排
位统计学分数
(y)
5 50 15 70 25 82 35 83 45 85 55 90 65 90 75 92
85 93 95 94
结果分析
相关系数Multiple R=0.986011> 0.8 可以进行回归分析。
ˆ的实际值相差2.403141。
标准误差=2.403141,代表平均来看y
y与
Intercept代表截距为12.32018即常数项
X Variable 1 代表斜率为0.896821,即数学分数每增加1分,统计学分数平均增加0.896821分。
x平均值为78.7,y平均值为92.9可以得出回归方程y=0.896821x+12.32018。