《生物信息学》课程期末报告
- 格式:doc
- 大小:1.27 MB
- 文档页数:8

⽣物信息学总结第⼀章⽣物信息学导论1、什么是⽣物信息学?学习⽣物信息学⼀般需要哪⼏个⽅⾯的基础?研究对象?研究内容?答:⽣物信息学(Bioinformatics) 是⼀门交叉学科,它综合运⽤数理科学和信息科学中的理论和⽅法,以计算机为⼯具对⽣物学实验数据进⾏收集、加⼯、储存、传播、检索和分析,以揭⽰数据所蕴含的⽣物学意义。
基础:数学、信息学、计算机科学研究对象:核酸、蛋⽩质等⽣物⼤分⼦数据库。
研究内容:开发数据库和⼯具来存储、管理、使⽤⽣物学数据,开发算法、软件来对⽣物学数据进⾏分析和解释,出版⽣物信息学⽂献、书籍、资料第⼆章⽣物信息学数据库1、数据库分类,⼀级数据库,⼆级数据库答:数据库的分类:⼀级数据库:数据库中的数据直接来源于实验获得的原始数据,只经过简单的归类整理和注释1、核酸序列数据库2、蛋⽩质序列数据库3、⽣物⼤分⼦结构数据库4、基因组数据库⼆级数据库:对原始⽣物分⼦数据进⾏整理、分类的结果,是在⼀级数据库、实验数据和理论分析的基础上针对特定的应⽤⽬标⽽建⽴的三⼤核酸序列数据库:美国⽣物技术信息中⼼的GenBank ,欧洲⽣物信息学研究所的EMBL ,⽇本国⽴遗传研究所的DDBJ2、Entrez检索系统,常⽤的数据库有哪些,有什么⽤途?Entrez是NCBI开发的综合数据库检索⼯具GenBank: 核酸序列数据RefSeq:Reference Sequence (参考序列数据)Genome:基因组数据Gene: 为每个基因建⽴⼀个⽂本描述条⽬UniGene: 归纳每⼀个基因的EST, mRNA, 蛋⽩质序列GEO: 基因表达数据SNP: SNP位点数据库Structure: 记录⼤分⼦三维结构数据第三章Blast与数据库搜索1、序列similarity和序列homology有何区别和联系?(1)相似性(similarity):是⼀种数量关系,⽐如部分相同或相似的百分⽐或其它⼀些合适的度量。

生物信息学课程报告生物信息学是一门跨学科的科学,致力于从大量的生物学数据中发现信息。
它涉及系统生物学、计算机科学和生物技术,目的是深入研究和理解生物基因组、蛋白质和微生物等分子水平的进化过程和相关的生物功能。
生物信息学的发展主要基于当前的高通量测序技术,这种技术在分子生物学社区中得到了广泛的应用,它允许科学家以迅速、低成本的方式获得大量的基因组学数据,使得生物信息学技术变得更加重要。
生物信息学课程是一种综合性的学科。
它涉及到系统生物学、计算机科学、数学、统计学、软件工程和生物技术等多方面,致力于帮助学生从繁杂的大量生物学数据中发现更有价值的信息。
生物信息学课程一般包括以下内容:1.物信息学的概述,引入有关的概念、术语和理论。
2.物信息资源的探索和利用,如基因数据库和其它生物信息数据库等。
3.据挖掘技术,如机器学习和模式识别。
4.物序列比对和生物信息分析,如序列比对、序列特征提取、序列聚类等。
5.物信息可视化,如基因组和蛋白质结构可视化等。
6.用生物信息学解决实际问题,如药物研究和基因疾病的关联分析等。
生物信息学的应用范围非常广泛,其影响力也不断增强。
现今,它已被广泛用于生物医学研究、药物开发、基因组等领域。
未来,它还可能在农业、环境研究和其它领域发挥重要作用。
因此,当今所有需要分析和预测生物数据的专业人士都应学习生物信息学的基础知识和最新技术,以解决实际问题。
在当今的世界,大数据分析和人工智能技术的发展正日益引起关注。
生物信息学也受到了这些技术的推动和影响,并在一定程度上受益于这些技术之间的相互作用。
未来,随着各种可计算、可学习、可模拟的技术及工具的不断发展,生物信息学将进行更加深入、更加广泛的应用,并可能成为生物学和医学研究的重要推动力。
综上所述,生物信息学是一门重要的学科,可为医学研究带来巨大的潜力,其发展有助于深入解释和分析大量的生物学数据,从而使我们能够更好地理解生物过程,为各种生物技术的进步奠定基础。

生物信息学课程报告
生物信息学是一门新兴的科学,它将生物学与电脑科学相结合,以研究与生物数据有关的内容。
它使用大量的数字工具,如计算机程序、数据库等,用于研究影响生物学的不同因素。
生物信息学的应用范围很广,可以帮助人们更好地理解某些生物学问题,比如基因组学、蛋白质结构预测和药物设计等。
生物信息学课程非常多样化,可以分为三个不同的阶段:一是基础阶段,主要是学习生物信息学的基本概念;二是中等阶段,主要是学习生物信息学的应用和实践各种方法;三是高级阶段,主要是学习使用不同的生物信息学软件编写程序和分析大量的生物信息数据。
学习生物信息学的过程需要学习数学、统计学和计算机程序设计语言等,以便更好地掌握生物信息学的技术。
现在越来越多的大学开设生物信息学的课程,很多学生都增加了对这一领域的关注,也帮助许多公司把生物信息学应用于产品开发。
例如,药物研究开发公司可以利用生物信息学来研究新药物,金融公司可以利用生物信息学来预测股票和期货等金融产品的行情,还可以用来研究生物抗性和生物资源分配等等。
生物信息学不仅能够帮助人类学习更多关于生物系统的知识,而且还能够帮助人们更好地了解生物系统的复杂性。
通过系统的研究和分析,生物学家可以更好地理解不同因素对生命过程的影响,并能够发现新的生物过程、分子机制、生物学原理等。
随着科学技术的进步,未来生物信息学将发挥着越来越重要的作
用。
它将在基础研究中起重要作用,同时也可以作为一种新的工具,应用于许多不同的研究领域,有助于改善人类的健康和环境保护。
而随着研究的不断发展,生物信息学也将不断完善和发展,以适应新的生物学任务。
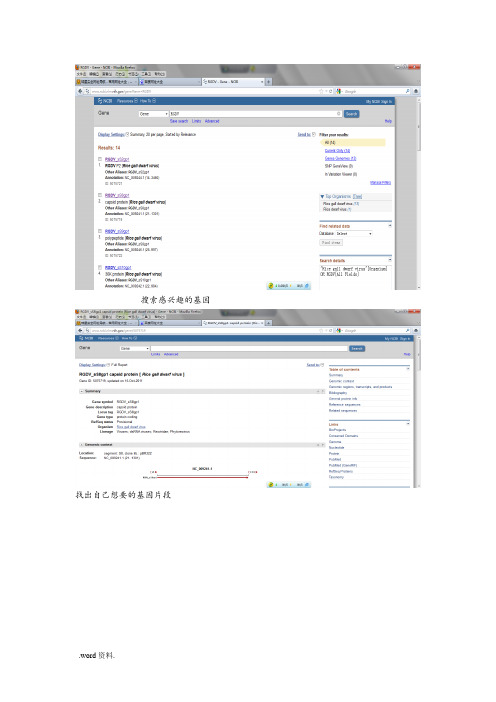
搜索感兴趣的基因找出自己想要的基因片段找出FASTA格式的基因序列,复制下来,保存在文本文档中水稻瘤矮病发生与危害水稻瘤矮病于1976年在地区发现,局部县市危害严重,近年在两广陆续有此病危害的报告,且有逐年加重的趋势,我国地区曾大面积发生危害,近年在以南的一些县零星发生。
症状识别水稻瘤矮病是由电光叶蝉、黑尾叶蝉和二点黑尾叶蝉传播的一种病毒病。
病苗明显矮缩,叶色深绿,叶背和叶鞘长有淡黄绿色近球形小瘤状突起,有时沿叶脉连成长条,叶尖卷转,个别新叶的一边叶缘灰白坏死,形成2-3个缺刻。
病株根细弱,抽穗迟、细小、空粒多。
水稻瘤矮病感病植株病原及发病条件为水稻瘤矮病毒 [Rice gall dwarf Virus (RGDV)]。
病毒粒体球状,直径65nm,由单一粒体组分和十二个片段的双链RNA组成。
此病可由电光叶蝉、二条黑尾叶蝉;二点黑尾叶蝉、黑尾叶蝉和马来亚黑尾叶蝉以持久性方式传播,也能通过二条黑尾叶蝉的卵传给下一代。
国以电光叶蝉和二点黑尾叶蝉为有效介体。
二点黑尾叶蝉亦可经卵传播。
防治方法:1)治虫防病,力争将传毒媒介昆虫电光叶蝉、二条黑尾叶蝉;二点黑尾叶蝉、黑尾叶蝉和马来亚黑尾叶蝉消灭在传毒前。
杀虫药剂可用25%喹硫磷或40%乐果1000-1500倍稀释液,或菊酯类农药5000倍稀释液喷雾。
2)及早毁除病株,或踩入泥土,或集中烧毁,以防止蔓延。
3)如插后不久发病,还可立即补苗。
4)稻株大胎期用“九二0”纯品50000倍稀释液喷雾,使病株提早抽穗,可减轻为害。
5)每亩用10%叶蝉散可湿性粉剂200克;或每亩用25%速灭威可湿性粉剂150克;每亩用50%杀螟松乳油 + 40%稻温净乳油各50毫升均加水50千克喷雾搜索对应的蛋白质序列Proparam软件分析蛋白质理化性质从分析结果可知:RGDV p8 各个氨基酸所占的比重,如上图。
分子质量为47422da,氨基酸数目为426,正负电荷残基总数30/30,分子式为C2126H3316O623S15,在M-1 cm-1单位在280海里的水里测量的消光系数为48610和48360,脂肪指数为92.68,组氨酸His (H)最少为0.5%,丝氨酸含量最多Ser (S) 9.9%。

生物信息报告课程名称:生物信息课题名称:生物信息在当代的应用学号:8000113047姓名:张永龙班级:东软131生物信息学是80年代以来新兴的一门边缘学科,信息在其中具有广阔的前景。
伴随着人类基因组计划的胜利完成与生物信息学的发展有着密不可分的联系,生物信息学的发展为生命科学的发展为生命科学的研究带来了诸多的便利,对此作了简单的分析。
一、生物信息学的产生21世纪是生命科学的世纪,伴随着人类基因组计划的胜利完成,与此同时,诸如大肠杆菌、结核杆菌、啤酒酵母、线虫、果蝇、小鼠、拟南芥、水稻、玉米等等其它一些模式生物的基因组计划也都相继完成或正在顺利进行。
人类基因组以及其它模式生物基因组计划的全面实施,使分子生物数据以爆炸性速度增长。
在计算机科学领域,按照摩尔定律飞速前进的计算机硬件,以及逐步受到各国政府重视的信息高速公路计划的实施,为生物信息资源的研究和应用带来了福音。
及时、充分、有效地利用网络上不断增长的生物信息数据库资源,已经成为生命科学和生物技术研究开发的必要手段,从而诞生了生物信息学。
二、生物信息学研究内容(一)序列比对比较两个或两个以上符号序列的相似性或不相似性。
序列比对是生物信息学的基础。
两个序列的比对现在已有较成熟的动态规划算法,以及在此基础上编写的比对软件包BALST 和FASTA,可以免费下载使用。
这些软件在数据库查询和搜索中有重要的应用。
有时两个序列总体并不很相似,但某些局部片断相似性很高。
Smith-Waterman算法是解决局部比对的好算法,缺点是速度较慢。
两个以上序列的多重序列比对目前还缺乏快速而又十分有效的算法。
(二)结构比对比较两个或两个以上蛋白质分子空间结构的相似性或不相似性。
研究了蛋白质结构和功能的预测及分析领域中几个相关问题。
主要工作如下:(1)研制了一个二级结构预测工具。
通过分析蛋白质二级结构端点位置附近氨基酸分布特征,发现这些位置上的氨基酸分布具明显的特异性。

第1篇随着生命科学的快速发展,生物信息学作为一门新兴的交叉学科,逐渐成为生物科学研究的重要工具。
生物信息学教学旨在培养学生的生物信息学知识、技能和创新能力。
本文将对生物信息学教学实践进行总结,分析教学过程中的亮点、不足及改进措施。
一、教学实践概述生物信息学教学实践主要包括理论教学和实践教学两部分。
理论教学主要介绍生物信息学的基本概念、研究方法、常用工具和数据库等;实践教学则侧重于培养学生运用生物信息学工具解决实际问题的能力。
二、教学实践亮点1. 注重基础知识与前沿技术的结合:在理论教学中,我们不仅注重基础知识的传授,还结合当前生物信息学领域的最新研究成果和前沿技术,如人工智能、大数据分析等,使学生能够紧跟学科发展。
2. 实践教学与科研相结合:实践教学环节中,我们鼓励学生参与科研项目,将所学知识应用于实际研究中,提高学生的科研能力和创新能力。
3. 多元化的教学方法:采用讲授、讨论、案例分析、实验操作等多种教学方法,激发学生的学习兴趣,提高教学效果。
4. 注重培养学生的团队合作精神:在实践教学过程中,引导学生进行团队合作,培养学生的沟通能力、协作能力和团队精神。
5. 关注学生个性化发展:针对不同学生的学习特点和需求,开展个性化教学,使每位学生都能在生物信息学领域取得优异成绩。
三、教学实践不足1. 理论与实践脱节:部分学生在理论学习过程中,对实际应用缺乏兴趣,导致理论与实践脱节。
2. 教学资源不足:生物信息学涉及众多软件和数据库,而教学资源有限,难以满足学生实践需求。
3. 师资力量不足:生物信息学师资力量相对薄弱,难以满足日益增长的教学需求。
4. 课程设置不够完善:部分课程设置与实际应用脱节,导致学生所学知识难以应用于实际问题解决。
四、改进措施1. 加强实践教学环节:增加实验课时,引入更多实际案例,提高学生的实践能力和创新意识。
2. 丰富教学资源:利用网络资源、数据库等,为学生提供丰富的学习资料和实践平台。
生物信息学学习心得第一篇:生物信息学生物信息学是上世纪90年代初人类基因组计划(hgp)依赖,随着基因组学、蛋白组学等新兴学科的建立,逐渐发展起来的生物学、数学和计算机信息科学的一门交叉应用学科。
目前生物信息学的研究领域主要包括基于生物序列数据的整理和注释、生物信息挖掘工具开发及利用这些工具揭示生物学基础理论知识等领域。
生物信息学作为新型交叉应用学科,可以依托本校已有的计算机科学、信息学、生物学和数学等学科优势,充分展现投入少、见效快、起点高的特色,推动学校学科建设和本科教学水平。
本实验指导书中的8个实验均设计为综合性开发实验,面向生物信息学院全体本科学生和研究生,以及全校对生物信息学感兴趣的其他专业学生开放。
生物信息学实验室将提供系统的保障,包括采用mail服务器和linux帐号管理等进行实验过程管理和支持。
限选《生物信息学及实验》的生物技术专业本科生至少选择其中5个实验,并不少于8个学时,即为课程要求的0.5个学分。
其他选修者按照课时和学校相关规定计算创新学分。
实验一熟悉生物信息学网站及其数据的生物学意义实验目的:培养学生利用互联网资源获取生物信息学研究前沿和相关数据的能力,熟悉生物信息学相关的一些重要国内外网站,及其核酸序列、蛋白质序列及代谢途径等功能相关数据库,学会下载生物相关的信息数据,了解不同的数据文件格式和其中重要的生物学意义。
实验原理:利用互联网资源检索相关的国内外生物信息学相关网站,如:ncbi、sanger、tigr、kegg、swissport、ensemble、中科院北京基因组研究所、北大生物信息学中心等,下载其中相关的数据,如fasta、genbank格式的核算和蛋白质序列、pathway等数据,理解其重要的生物学意义。
实验内容:1.浏览和搜索至少10个国外和至少5个国内生物信息学相关网站,并描述网站特征;2.下载各网站的代表性数据各10条(组)以上,并说明其生物学意义;3.讨论各网站适合做何种生物信息学研究的平台,并设计一个研究设想。
生物信息学课后感想与收获在完成生物信息学课程后,我深感收获颇丰。
这门课程不仅让我对生物信息学有了更深入的了解,还让我对生命科学领域产生了更浓厚的兴趣。
以下是我对这门课程的感想与收获。
一、课程内容的深度与广度生物信息学课程涵盖了多个领域,包括基因组学、蛋白质组学、代谢组学等。
课程内容丰富多样,既有理论知识的讲解,也有实际应用的案例分析。
通过这门课程,我不仅了解了生物信息学的基本概念和原理,还学会了如何运用生物信息学的方法和技术来解决实际问题。
二、理论与实践的结合生物信息学课程注重理论与实践的结合。
在课程中,我们不仅学习了理论知识,还进行了实验操作。
通过实验操作,我更加深入地理解了生物信息学的原理和方法,也更加熟练地掌握了相关的软件和工具。
这种理论与实践的结合方式,让我对生物信息学有了更全面的认识。
三、团队合作与交流在课程中,我们进行了多次小组讨论和项目实践。
通过与同学们的交流和合作,我不仅提高了自己的沟通能力,还学会了如何与他人合作解决问题。
这种团队合作和交流的方式,让我更加自信和从容地面对未来的挑战。
四、对生命科学领域的兴趣通过这门课程,我对生命科学领域产生了更浓厚的兴趣。
我意识到,生物信息学在生命科学领域中扮演着重要的角色,它可以帮助我们更好地理解生命的本质和规律。
同时,我也意识到,生物信息学是一个充满挑战和机遇的领域,它需要我们不断地学习和探索。
五、对未来的展望通过这门课程的学习,我对生物信息学的未来充满了期待。
我相信,随着科技的不断进步和创新,生物信息学将会在生命科学领域中发挥更大的作用。
我也相信,随着自己的不断学习和努力,我将会在这个领域中取得更好的成绩。
总之,生物信息学课程让我受益匪浅。
它不仅让我对生物信息学有了更深入的了解,还让我对生命科学领域产生了更浓厚的兴趣。
我相信,在未来的学习和工作中,我会继续努力学习和探索,为生命科学领域的发展做出自己的贡献。
生物信息学课程期末报告精编W O R D版IBM system office room 【A0816H-A0912AAAHH-GX8Q8-GNTHHJ8】《生物信息学》1.描述NCBI或ExPASy主页结构和主要内容NCBI数据库介绍下面按照检索框上的顺序分别介绍各数据库。
Nucleotide该数据库由国际核苷酸序列数据库成员美国国立卫生研究院GenBank、日本DNA数据库(DDBJ)和英国Hinxton Hall的欧洲分子生物学实验室数据库(EMBL)三部分数据组成。
这三个组织联合组成国际核苷酸序列数据库协作体,每天交换各自数据库中的新增序列记录实现数据共享。
其中的序列数据也通过与基因组序列数据库(GSDB)合作获取;专利序列数据通过与美国专利与商标局、国际专利局合作获取。
Genome即基因组数据库,提供了多种基因组、完全染色体、Contiged序列图谱以及一体化基因物理图谱。
Structures即结构数据库或称分子模型数据库(MMDB),包含来自X线晶体学和三维结构的实验数据。
MMDB的数据从PDB(Protein Data Bank)获得。
NCBI已经将结构数据交叉链接到书目信息、序列数据库和NCBI的Taxonomy中运用NCBI的3D结构浏览器和Cn3D,可以很容易地从Entrez获得分子的分子结构间相互作用的图像。
Taxonomy即生物学门类数据库,可以按生物学门类进行检索或浏览其核苷酸序列、蛋白质序列、结构等。
PopSet包含研究一个人群、一个种系发生或描述人群变化的一组组联合序列。
PopSet既包含核酸序列数据又包含蛋白质序列数据。
Entrez 功能强大,在于它的大多数记录可相互链接,既可在同一数据库内链接,也可在数据库之间进行链接。
当运用BLAST软件比较某氨基酸或DNA序列与库中其他氨基酸或DNA序列差异即进行相似性检索时,则会涉及到蛋白质库或核苷酸库的库内链接。
库间链接发生在核苷酸数据库内的记录与PubMed库中已发表序列的引文间的链接,或蛋白质序列记录与核苷酸序列库中编码它的核苷酸序列间的链接。
《生物信息学》
1.描述NCBI或ExPASy主页结构和主要容
NCBI数据库介绍
下面按照检索框上的顺序分别介绍各数据库。
Nucleotide
该数据库由国际核苷酸序列数据库成员美国国立卫生研究院GenBank、日本DNA数据库(DDBJ)和英国Hinxton Hall的欧洲分子生物学实验室数据库(EMBL)三部分数据组成。
这三个组织联合组成国际核苷酸序列数据库协作体,每天交换各自数据库中的新增序列记录实现数据共享。
其中的序列数据也通过与基因组序列数据库(GSDB)合作获取;专利序列数据通过与美国专利与商标局、国际专利局合作获取。
Genome
即基因组数据库,提供了多种基因组、完全染色体、Contiged序列图谱以及一体化基因物理图谱。
Structures
即结构数据库或称分子模型数据库(MMDB),包含来自X线晶体学和三维结构的实验数据。
MMDB的数据从PDB(Protein Data Bank)获得。
NCBI已经将结构数据交叉到书目信息、序列数据库和NCBI的Taxonomy中运用NCBI的3D结构浏览器和Cn3D,可以很容易地从Entrez 获得分子的分子结构间相互作用的图像。
Taxonomy
即生物学门类数据库,可以按生物学门类进行检索或浏览其核苷酸序列、蛋白质序列、结构等。
PopSet
包含研究一个人群、一个种系发生或描述人群变化的一组组联合序列。
PopSet既包含核酸序列数据又包含蛋白质序列数据。
Entrez 功能强大,在于它的大多数记录可相互,既可在同一数据库,也可在数据库之间进行。
当运用BLAST软件比较某氨基酸或DNA序列与库中其他氨基酸或DNA序列差异即进行相
似性检索时,则会涉及到蛋白质库或核苷酸库的库。
库间发生在核苷酸数据库的记录与PubMed库中已发表序列的引文间的,或蛋白质序列记录与核苷酸序列库中编码它的核苷酸序列间的。
NCBI数据库检索
NCBI数据库的检索方法很简单,在检索框中输入检索词,检索词间默认逻辑关系为AND,检索规则基本同PubMed。
可以通过下拉菜单选择记录的显示格式,通常选择GenBank Report格式或FASTA Report 格式。
当选择GenBank Report格式后,屏幕显示较完整的基因记录,其容包括:基因位点(Locus)、基因定义(Definition)、基因存取号(Accession)、核酸编号(NID )、关键词(Keywords)、来源(Source)、组织分类(Organism)、参考文献(Reference)、著者(Author)、题目(Title)、期刊Journal)、Medline存取号(Medline)、序列特征(Features)、基因(Gene)、CDS(cDNA)、等位基因(Allele) 对等的肽(Mat-Peptide )、计算碱基数(Base Count)、原序列(Origin)。
而FASTA Report格式仅包括检出序列的简要特征描述。
2.Search the human preproinsulin sequence from the NCBI dat
abases.Describe your searching process and results.
评论:此项目是由组装并取代先前的入口<HSINS1>和<HSINSUZ1>,并包含其他新的数据。
一些序列和功能数据已经改编自洛杉矶洛斯阿拉莫斯序列数据库录入HUMINS1。
该基因的直接翻译产物是前胰岛素原。
该信号肽促进胰岛素的膜转运前体,并在此过程中被切割掉。
在产生的胰岛素原分子,肽链A和B由接合连接肽C,这被认为是在形成的,以帮助需要胰岛素的二硫键。
来自于人类第1到110个前胰岛素原的氨基酸序列,第1到24个氨基酸是信号肽,第25到54个氨基酸是胰岛素原肽B,第55到89个氨基酸是胰岛素原肽C,第90到110个氨基酸是胰岛素原肽A。
3.将人,猪,牛,狗,鼠,羊,马,兔的胰岛素制成进化树。
4.structure of human preproinsulin position of -s-s-
A链的第六个和第十一个半胱氨酸中的巯基形成二硫键。
A链的第七个和B链的第七个半胱氨酸中的巯基形成二硫键。
A链的第二十个和B链的第十九个半胱氨酸中的巯基形成二硫键。