K-means聚类分析
- 格式:pdf
- 大小:205.82 KB
- 文档页数:3
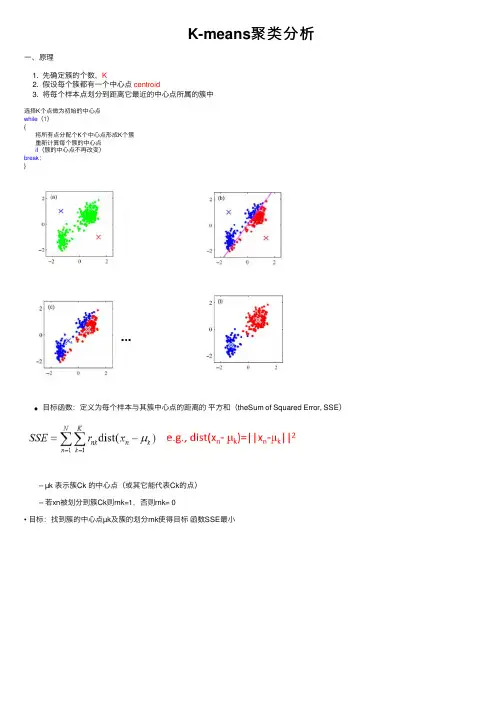
K-means聚类分析⼀、原理1. 先确定簇的个数,K2. 假设每个簇都有⼀个中⼼点centroid3. 将每个样本点划分到距离它最近的中⼼点所属的簇中选择K个点做为初始的中⼼点while(1){将所有点分配个K个中⼼点形成K个簇重新计算每个簇的中⼼点if(簇的中⼼点不再改变)break;}⽬标函数:定义为每个样本与其簇中⼼点的距离的平⽅和(theSum of Squared Error, SSE) – µk 表⽰簇Ck 的中⼼点(或其它能代表Ck的点) – 若xn被划分到簇Ck则rnk=1,否则rnk= 0• ⽬标:找到簇的中⼼点µk及簇的划分rnk使得⽬标函数SSE最⼩初始中⼼点通常是随机选取的(收敛后得到的是局部最优解)不同的中⼼点会对聚类结果产⽣不同的影响:1、2、此时你⼀定会有疑问:如何选取"较好的"初始中⼼点?1. 凭经验选取代表点2. 将全部数据随机分成c类,计算每类重⼼座位初始点3. ⽤“密度”法选择代表点4. 将样本随机排序后使⽤前c个点作为代表点5. 从(c-1)聚类划分问题的解中产⽣c聚类划分问题的代表点 结论:若对数据不够了解,可以直接选择2和4⽅法需要预先确定K Q:如何选取K SSE⼀般随着K的增⼤⽽减⼩A:emmm你多尝试⼏次吧,看看哪个合适。
斜率改变最⼤的点⽐如k=2总结:简单的来说,K-means就是假设有K个簇,然后通过上⾯找初始点的⽅法,找到K个初始点,将所有的数据分为K个簇,然后⼀直迭代,在所有的簇⾥⾯找到找到簇的中⼼点µk及簇的划分rnk使得⽬标函数SSE最⼩或者中⼼点不变之后,迭代完成。
成功把数据分为K类。
预告:下⼀篇博⽂讲K-means代码实现。

k-means聚类和fcm聚类的原理概念摘要:一、聚类分析概述1.定义与作用2.常用的聚类算法二、K-means 聚类原理1.算法基本思想2.计算过程3.特点与优缺点三、FCM 聚类原理1.算法基本思想2.计算过程3.特点与优缺点四、K-means 与FCM 聚类的比较1.相似之处2.不同之处3.适用场景正文:一、聚类分析概述聚类分析是一种无监督学习方法,通过将相似的数据对象归为一类,从而挖掘数据集的潜在结构和模式。
聚类分析在数据挖掘、模式识别、图像处理、生物学研究等领域具有广泛应用。
常用的聚类算法有K-means 聚类和FCM 聚类等。
二、K-means 聚类原理1.算法基本思想K-means 聚类是一种基于划分的聚类方法,通过迭代计算数据点与当前中心点的距离,将数据点分配到距离最近的中心点所属的簇,然后更新中心点。
这个过程持续进行,直到满足停止条件。
2.计算过程(1)随机选择k 个数据点作为初始中心点。
(2)计算其他数据点与初始中心点的距离,将数据点分配到距离最近的簇。
(3)计算每个簇的中心点。
(4)重复步骤2 和3,直到中心点不再发生变化或达到最大迭代次数。
3.特点与优缺点特点:简单、易于实现,适用于大规模数据集。
优点:可以处理大规模数据集,对噪声数据具有一定的鲁棒性。
缺点:对初始中心点敏感,可能导致局部最优解;计算过程中需要反复计算距离,计算量较大。
三、FCM 聚类原理1.算法基本思想FCM 聚类是一种基于模糊划分的聚类方法,通过计算数据点与当前中心点的模糊距离,将数据点分配到距离最近的簇。
模糊距离是基于隶属度函数计算的,可以反映数据点对簇的隶属程度。
2.计算过程(1)随机选择k 个数据点作为初始中心点。
(2)计算其他数据点与初始中心点的模糊距离,将数据点分配到距离最近的簇。
(3)计算每个簇的中心点。
(4)重复步骤2 和3,直到中心点不再发生变化或达到最大迭代次数。
3.特点与优缺点特点:考虑了数据点对簇的隶属程度,具有更好的全局优化性能。

Python中的聚类分析方法和应用聚类分析是一种数据挖掘技术,在数据分析、机器学习、人工智能等领域都有广泛的应用。
它的基本思想是将相似的样本归为同一类,不同的样本归为不同的类,从而实现对数据的分类和整理。
Python作为一种强大的编程语言,也提供了多种聚类分析算法的实现,以下是聚类分析在Python中的应用及其方法。
一、K-Means算法K-Means算法是一种经典的聚类算法,常用于分析数量较大的数据集。
K-Means算法通过不断迭代的方式,将数据集中的每一个样本归为k个簇中的某一个。
它的基本流程如下:首先从数据集中随机选取k个样本作为簇的中心点,然后计算数据集中其他样本与这k个簇中心点的距离,并将距离最近的样本分配给它所对应的簇。
接着重新计算每个簇的中心点,并重复这个过程,直到目标函数收敛或达到指定的迭代次数。
在Python中,K-Means算法的实现非常简单,主要依托于scikit-learn库。
引入sklearn.cluster包,并使用KMeans类即可。
以下是一个简单的Python代码示例:```from sklearn.cluster import KMeansimport numpy as npdata = np.random.rand(1000, 2)kmeans = KMeans(n_clusters=3, random_state=0).fit(data) labels = bels_centers = kmeans.cluster_centers_```其中,随机生成1000个二维数据作为数据集,然后使用KMeans 类进行聚类,将数据集划分为3个簇。
最后,通过labels和centers 变量获取分类信息和中心点坐标。
二、层次聚类算法层次聚类算法是另一种经典的聚类算法,在Python中同样得到了广泛的应用。
层次聚类算法又被称为自底向上聚类(bottom-up clustering)或自上而下聚类(top-down clustering),它的基本思想是不断合并距离最近的样本,直到所有的样本都被归为一类为止。

聚类算法:K-Means和DBSCAN的比较聚类是一种无监督学习的方法,它将数据分组成具有相似特征的集合,称为簇(cluster)。
簇分析是统计学、计算机科学、机器学习和数据挖掘等领域中的常用技术之一。
目前,聚类算法已广泛应用于用户行为分析、市场营销、图像处理、生物信息学、搜索引擎、社交网络等领域。
在聚类算法中,K-Means和DBSCAN是两种具有代表性的算法。
本文将从算法原理、优缺点、适用场景等方面对它们进行比较分析。
一、K-Means算法K-Means算法是一种基于距离的聚类算法。
它的基本思想是从数据集中选取k个初始聚类中心,不断迭代,把每个数据点归为距离最近的聚类中心所在的簇。
K-Means算法的优点是计算简单、速度快、可并行计算,适用于处理大规模数据集。
但是K-Means算法的聚类结果受初始聚类中心的影响较大,算法的性能对于簇的形状、大小和分布较为敏感。
算法流程:1.选择k个聚类中心2.对于每个数据点,计算距离最近的聚类中心,将其划分到相应的簇中3.对于每个簇,重新计算该簇的聚类中心4.重复步骤2和步骤3,直到聚类中心不再变化或达到最大迭代次数二、DBSCAN算法DBSCAN算法是一种基于密度的聚类算法。
它的基本思想是将密度高于某一阈值的数据点定义为核心点(Core Points),将与核心点距离不超过一定距离的数据点归为同一个簇(Cluster),将距离较远的数据点称为噪声点(Noise)。
DBSCAN算法的优点是可以自动识别任意形状的簇,对初始聚类中心不敏感,适用于处理稠密数据集。
但是DBSCAN算法的聚类结果对于数据点密度分布的敏感度较高,平均时间复杂度较高。
算法流程:1.对于每个数据点,计算其邻域(Neighborhood)内的数据点个数,如果邻域内的数据点个数大于等于密度阈值,则该点为核心点,否则该点为噪声点2.将所有核心点加入到一个簇中,对每个核心点进行扩展,将邻域内的数据点加入到该簇中,直到不能再扩展3.继续处理下一个未被归类的核心点,直到所有核心点都在某个簇中或被标记为噪声点三、K-Means和DBSCAN的比较1.聚类精度K-Means算法适用于簇形状较为规则且大小相似的数据集,但对于不规则形状、大小差异较大的数据集,其聚类效果并不理想。

kmeans 聚类算法Kmeans聚类算法Kmeans聚类算法是一种基于距离的无监督机器学习算法,它可以将数据集分为多个类别。
Kmeans算法最初由J. MacQueen于1967年提出,而后由S. Lloyd和L. Forgy独立提出。
目前,Kmeans算法已经成为了机器学习领域中最常用的聚类算法之一。
Kmeans算法的基本思想是将数据集划分为k个不同的簇,每个簇具有相似的特征。
簇的数量k是由用户指定的,算法会根据数据集的特征自动将数据集分成k个簇。
Kmeans算法通过迭代的方式来更新每个簇的中心点,以此来不断优化簇的划分。
Kmeans算法的步骤Kmeans算法的步骤可以概括为以下几个步骤:1. 随机选择k个点作为中心点;2. 将每个数据点与离它最近的中心点关联,形成k个簇;3. 对于每个簇,重新计算中心点;4. 重复2-3步骤,直到簇不再变化或达到最大迭代次数。
Kmeans算法的优缺点Kmeans算法的优点包括:1. 算法简单易实现;2. 能够处理大规模数据集;3. 可以处理多维数据。
Kmeans算法的缺点包括:1. 需要用户指定簇的数量;2. 对于不规则形状的簇,效果不佳;3. 对于包含噪声的数据集,效果不佳。
Kmeans算法的应用Kmeans算法在机器学习和数据挖掘中有着广泛的应用。
以下是Kmeans算法的一些应用:1. 图像分割:将图像分为多个不同的区域;2. 文本聚类:将文本数据划分为多个主题;3. 市场分析:将消费者分为不同的群体,以便进行更好的市场分析;4. 生物学研究:将生物数据分为不同的分类。
总结Kmeans聚类算法是一种基于距离的无监督机器学习算法,它可以将数据集分为多个类别。
Kmeans算法的步骤包括随机选择中心点、形成簇、重新计算中心点等。
Kmeans算法的优缺点分别是算法简单易实现、需要用户指定簇的数量、对于不规则形状的簇效果不佳等。
Kmeans算法在图像分割、文本聚类、市场分析和生物学研究等领域有着广泛的应用。


数据聚类分析方法
数据聚类分析方法是一种将数据分组或分类的技术。
聚类分析的目标是将相似的数据聚集在一起,同时将不相似的数据分开。
以下是常见的数据聚类分析方法:
1. K-means聚类算法:K-means算法是一种迭代的聚类算法。
它将数据集分为预先指定的K个簇,其中每个数据点属于距离该数据点最近的簇。
该算法通过不断迭代更新簇的中心来优化聚类结果。
2. 层次聚类算法:层次聚类算法通过以下两种方法进行聚类分析:聚合和分裂。
聚合方法将每个数据点作为一个单独的簇,并逐渐将相似的簇合并在一起。
分裂方法则是从一个包含所有数据点的簇开始,并逐渐将不相似的数据点分离开来。
3. 密度聚类算法:密度聚类算法将数据点密度作为聚类的基础。
该算法通过确定数据点周围的密度来划分不同的簇。
常见的密度聚类算法有DBSCAN和OPTICS。
4. 基于网格的聚类算法:基于网格的聚类算法将数据空间划分为网格,并将数据点分配到各个网格中。
该算法通常适用于高维数据集,可以减少计算复杂度。
5. 谱聚类算法:谱聚类算法将数据点表示为一个图的拉普拉斯矩阵,并通过谱分解将数据点分配到不同的簇中。
该算法通常用于非线性可分的数据集。
需要根据具体的数据集和分析目标来选择适合的数据聚类分析方法。




K-Means聚类分析一、实验方法K-Means聚类分析二、实验目的根据2001年全国31省市自治区各类小康和现代化指数的数据,用Spass对地区进行K-Means 聚类分析。
三、实验数据综合指数社会结构经济与技术发展人口素质生活质量法制与治安北京93.2 100 94.7 108.4 97.4 55.5上海92.3 95.1 92.7 112 95.4 57.5天津87.9 93.4 88.7 98 90 62.7浙江80.9 89.4 85.1 78.5 86.6 58广东79.2 90.4 86.9 65.9 86.5 59.4江苏77.8 82.1 74.8 81.2 75.9 74.6辽宁76.3 85.8 65.7 93.1 68.1 69.6福建72.4 83.4 71.7 67.7 76 60.4山东71.7 70.8 67 75.7 70.2 77.2黑龙江70.1 78.1 55.7 82.1 67.6 71吉林67.9 81.1 51.8 85.8 56.8 68.1湖北65.9 73.5 48.7 79.9 56 79陕西65.9 71.5 48.2 81.9 51.7 85.8河北65 60.1 52.4 75.6 66.4 76.6山西64.1 73.2 41 73 57.3 87.8海南64.1 71.6 46.2 61.8 54.5 100重庆64 69.7 41.9 76.2 63.2 77.9内蒙古63.2 73.5 42.2 78.2 50.2 81.4湖南60.9 60.5 40.3 73.9 56.4 84.4青海59.9 73.8 43.7 63.9 47 80.1四川59.3 60.7 43.5 71.9 50.6 78.5宁夏58.2 73.5 45.9 67.1 46.7 61.6新疆64.7 71.2 57.2 75.1 57.3 64.6安徽56.7 61.3 41.2 63.5 52.5 72.6云南56.7 59.4 49.8 59.8 48.1 72.3甘肃56.6 66 36.6 66.2 45.8 79.4 四、分析方法与结果表一31个省市自治区小康和现代化指数的K-Means聚类分析结果(一)初始聚类中心聚类1 2 3综合指数79.20 92.30 51.10社会结构90.40 95.10 61.90经济与技术发展86.90 92.70 31.50人口素质65.90 112.00 56.00生活质量86.50 95.40 41.00法制与治安59.40 57.50 75.60ANOVA聚类误差均方自由度均方自由度F 显著性综合指数1633.823 2 22.518 28 72.556 .000 社会结构1539.872 2 47.312 28 32.547 .000 经济与技术发展4381.296 2 56.760 28 77.190 .000 人口素质1817.856 2 74.363 28 24.446 .000 生活质量3315.174 2 59.276 28 55.928 .000 法制与治安530.188 2 76.284 28 6.950 .004由于已选择聚类以使不同聚类中个案之间的差异最大化,因此 F 检验只应该用于描述目的。
k-means聚类法标准化数值概述及解释说明1. 引言1.1 概述在数据分析和机器学习领域中,聚类算法是一种常用的无监督学习方法,它可以将具有相似特征的数据点划分为不同的组或簇。
其中,k-means聚类法是一种经典且广泛使用的聚类算法。
它通过迭代计算数据点与各个簇中心之间的距离,并将数据点划分到距离最近的簇中心。
k-means聚类法在数据挖掘、图像处理、模式识别等领域有着广泛的应用。
1.2 文章结构本文主要围绕着k-means聚类法以及标准化数值展开讨论。
首先介绍了k-means聚类法的原理和应用场景,详细解释了其算法步骤和常用的聚类质量评估指标。
接下来对标准化数值进行概述,并阐述了常见的标准化方法以及标准化所具有的优缺点。
随后,文章从影响因素分析角度探讨了k-means聚类算法与标准化数值之间的关系,并深入剖析了标准化在k-means中的作用及优势。
最后,通过实例解释和说明,对文中所述的理论和观点进行了验证与分析。
1.3 目的本文旨在向读者介绍k-means聚类法及其在数据分析中的应用,并深入探讨标准化数值在k-means聚类算法中扮演的重要角色。
通过本文的阐述,希望读者能够理解k-means聚类法的基本原理、运行步骤以及质量评估指标,并认识到标准化数值对于提高聚类算法性能以及结果准确性的重要性。
最终,通过结论与展望部分,给出对未来研究方向和应用领域的展望和建议,为相关领域研究者提供参考和启示。
2. k-means聚类法:2.1 原理及应用场景:k-means聚类算法是一种常用的无监督学习方法,主要用于将数据集划分为k 个不同的簇(cluster)。
该算法基于距离度量来确定样本之间的相似性,其中每个样本被划分到距离最近的簇。
它的主要应用场景包括图像分割、文本分类、市场细分等。
2.2 算法步骤:k-means聚类算法具有以下几个步骤:1. 初始化: 选择k个随机点作为初始质心。
2. 分配: 对于每个数据点,计算其与各个质心之间的距离,并将其分配到最近的质心所属的簇中。
Matlab中的聚类分析工具简介聚类分析作为一种常用的数据分析方法,在不同领域和应用中发挥着重要的作用。
而Matlab作为一种支持数值计算和数据可视化的软件,为用户提供了方便且强大的聚类分析工具。
本文将介绍Matlab中几个常用的聚类分析工具及其使用方法。
一、K-means聚类分析工具K-means是一种常见的划分聚类算法,它的基本思想是将n个样本划分为K个不相交的簇,以使得簇内的样本之间的相似度最大化,而簇间的相似度最小化。
在Matlab中,我们可以使用`kmeans`函数来实现K-means聚类分析。
使用`kmeans`函数时,我们需要提供待聚类的样本数据矩阵以及聚类的簇数K作为输入参数。
函数将返回每个样本所属的簇的索引,以及簇的中心点坐标。
我们可以根据簇的索引和中心点坐标进行进一步的分析和可视化。
二、层次聚类分析工具层次聚类是一种基于距离的聚类算法,其基本思想是根据样本之间的相似性将它们逐步地合并为更大的簇,从而形成一个层次化的聚类结果。
在Matlab中,我们可以使用`linkage`函数和`cluster`函数来实现层次聚类分析。
首先,我们可以使用`linkage`函数计算样本之间的距离,并得到一个距离矩阵。
然后,我们可以使用`cluster`函数基于距离矩阵进行聚类,指定簇数或者距离阈值。
该函数将返回每个样本所属的簇的索引。
通过层次聚类分析工具,我们可以获得一个层次化的聚类结果,以及聚类过程中形成的类别树图。
这些结果可以帮助我们更好地理解数据的相似性和结构。
三、密度聚类分析工具与划分和层次聚类不同,密度聚类不依赖于簇的形状和个数的先验知识,而是通过找寻高密度区域来划分数据。
在Matlab中,我们可以使用`dbscan`函数来实现基于密度的聚类分析。
`dbscan`函数需要提供待聚类的样本数据矩阵、邻域半径和邻域密度阈值作为输入参数。
函数将返回每个样本所属的簇的索引,以及噪音点的索引。
密度聚类可以有效地处理数据中的噪音和离群点,并且适用于各种形状和密度不均的数据集。
python 一维数据的k-means算法概述及解释说明1. 引言1.1 概述本文将介绍K-means算法在处理一维数据上的应用。
K-means算法是一种常用的聚类分析方法,可帮助我们将数据集划分为不同的簇。
聚类分析是一种无监督学习方法,通过找到数据中的相似性来对其进行分类,从而提取出隐藏在数据背后的模式和特征。
1.2 文章结构本文共包含以下几个部分:引言、K-means算法概述、一维数据的K-means 算法解释、示例与实现讲解以及结论与展望。
在引言部分,我们将提供一个简要介绍并概括本文所要讨论的主题。
接下来,在K-means算法概述中,我们将详细解释该算法的原理、步骤说明以及适用的场景。
然后,我们会详细探讨如何在一维数据上应用K-means算法,并对其中涉及到的数据预处理、聚类中心计算与更新以及聚类结果评估与迭代调整进行解释。
紧接着,在示例与实现讲解部分,我们将通过具体示例来演示如何使用Python 编写代码实现一维数据的K-means算法,并给出结果可视化和分析解读。
最后,在结论与展望部分,我们将总结本文的主要观点和发现,并展望未来关于K-means算法在一维数据上的研究方向和应用场景的拓展。
1.3 目的本文的目标是为读者提供对K-means算法在处理一维数据时的全面了解和应用指导。
通过阅读本文,读者将了解K-means算法的基本原理、步骤说明以及适用场景,并能够根据具体需求编写代码实现该算法并进行结果分析和解释。
同时,我们还希望通过本文对一维数据的K-means算法进行详细讲解,加深读者对该算法在实际问题中的应用理解和掌握能力。
2. K-means算法概述:2.1 算法原理:K-means算法是一种基于聚类的机器学习算法,主要用于将一组数据分成k 个不同的簇。
该算法通过计算数据点与各个簇中心之间的距离来确定每个数据点所属的簇,并且不断迭代更新簇中心以优化聚类结果。
其核心思想是最小化数据点到其所属簇中心的欧氏距离平方和。
k-means聚类算法简介k-means 算法是一种基于划分的聚类算法,它以k 为参数,把n 个数据对象分成k 个簇,使簇内具有较高的相似度,而簇间的相似度较低。
1. 基本思想k-means 算法是根据给定的n 个数据对象的数据集,构建k 个划分聚类的方法,每个划分聚类即为一个簇。
该方法将数据划分为n 个簇,每个簇至少有一个数据对象,每个数据对象必须属于而且只能属于一个簇。
同时要满足同一簇中的数据对象相似度高,不同簇中的数据对象相似度较小。
聚类相似度是利用各簇中对象的均值来进行计算的。
k-means 算法的处理流程如下。
首先,随机地选择k 个数据对象,每个数据对象代表一个簇中心,即选择k 个初始中心;对剩余的每个对象,根据其与各簇中心的相似度(距离),将它赋给与其最相似的簇中心对应的簇;然后重新计算每个簇中所有对象的平均值,作为新的簇中心。
不断重复以上这个过程,直到准则函数收敛,也就是簇中心不发生明显的变化。
通常采用均方差作为准则函数,即最小化每个点到最近簇中心的距离的平方和。
新的簇中心计算方法是计算该簇中所有对象的平均值,也就是分别对所有对象的各个维度的值求平均值,从而得到簇的中心点。
例如,一个簇包括以下 3 个数据对象{(6,4,8),(8,2,2),(4,6,2)},则这个簇的中心点就是((6+8+4)/3,(4+2+6)/3,(8+2+2)/3)=(6,4,4)。
k-means 算法使用距离来描述两个数据对象之间的相似度。
距离函数有明式距离、欧氏距离、马式距离和兰氏距离,最常用的是欧氏距离。
k-means 算法是当准则函数达到最优或者达到最大的迭代次数时即可终止。
当采用欧氏距离时,准则函数一般为最小化数据对象到其簇中心的距离的平方和,即。
其中,k 是簇的个数,是第i 个簇的中心点,dist(,x)为X 到的距离。
2. Spark MLlib 中的k-means 算法Spark MLlib 中的k-means 算法的实现类KMeans 具有以下参数。
k-means 聚类数的确定是一个重要且困难的问题。
以下是一些常用的方法:
1. 观察数据的可视化效果。
通过绘制数据的散点图等可视化方法,尝试找到最佳的聚类数。
如果聚类数太少,可能会使得聚类结果信息不够丰富; 如果聚类数太多,则可能造成噪声点也被分到簇中。
具体使用的方法可以是肘部法则、轮廓系数法等。
2. 手肘法则(Elbow Method)。
在聚类数逐渐增加时,对应的误差开始缓慢下降,直到达到一个拐点,之后误差下降的速度减缓。
通过这个拐点的位置来确定最佳的聚类数。
3. 轮廓系数法(Silhouette method)。
这是一种基于内部聚合度和分散度的度量方法,用于判断聚类结果的质量。
可以通过绘制轮廓系数随聚类数变化的曲线图,找到最佳的聚类数。
轮廓系数越大,表示聚类结果越好。
4. 基于统计学习理论的方法。
使用基于统计学习理论的数据分析方法、特征选择方法或其他交叉验证方法来优化聚类数使得聚类精度最优。
5. 专家经验法。
人工或专家经验对聚类数的选取能够提供直观或主观的指导,但是其准确性和普适性不够理想。
总的来说,k-means 聚类数的确定需要综合考虑多种因素,在具体应用中根据实际情况和经验来确定最佳的聚类数。
K-means聚类算法与熵聚类算法是机器学习和数据挖掘领域常用的无监督学习方法。
它们都是通过对数据进行分组来寻找数据内在的结构和模式。
一、 K-means聚类算法的原理和流程1.1 K-means算法的原理K-means聚类算法是一种基于中心点的聚类算法。
它的基本思想是将数据集划分为K个簇,每个簇内的数据点与该簇的中心点具有最小的距离,而不同簇之间的数据点的距离较大。
K-means算法的目标是最小化簇内数据点与其对应中心点之间的距离之和。
1.2 K-means算法的流程K-means算法的流程大致可以分为以下几步:(1)初始化K个中心点,可以随机选择数据集中的K个样本作为中心点;(2)对每个样本,计算其与K个中心点的距离,并将其归类到距离最近的簇中;(3)更新每个簇的中心点,将其设置为该簇内所有样本的平均值;(4)重复步骤(2)和(3),直到簇内数据点的分配不再发生变化或达到预设的迭代次数。
1.3 K-means算法的优缺点K-means算法的优点包括简单易实现、计算效率高等。
但其也存在一些缺点,例如K值需事先确定、对初始中心点敏感等。
二、熵聚类算法的原理和流程2.1 熵聚类算法的原理熵聚类算法是一种基于信息论的聚类方法。
其基本思想是通过最小化簇内数据点的信息熵来进行聚类。
熵聚类算法可以分为两种:簇内熵最小化算法和簇间熵最大化算法。
2.2 簇内熵最小化算法簇内熵最小化算法的目标是使得每个簇内的数据点相似度较高,即簇内的数据点之间的差异较小。
这可以通过最小化每个簇的熵来实现。
2.3 簇间熵最大化算法簇间熵最大化算法的目标是使得不同簇之间的差异较大,即簇之间的数据点之间的差异较大。
这可以通过最大化不同簇之间的信息熵来实现。
2.4 熵聚类算法的流程熵聚类算法的流程主要包括以下几步:(1)计算簇内每个数据点的信息熵;(2)将数据点归类到信息熵最小的簇中;(3)重复步骤(1)和(2),直到满足停止条件。
2.5 熵聚类算法的优缺点熵聚类算法的优点包括不需要预先设定簇的个数、对初始值不敏感等。