实验三统计回归模型Matlab求解
- 格式:doc
- 大小:273.50 KB
- 文档页数:9

使用Matlab技术进行回归分析的基本步骤回归分析是统计学中一种用于研究变量间关系的方法,可以用来预测和解释变量之间的相关性。
在实际应用中,使用计算工具进行回归分析可以提高分析效率和准确性。
本文将介绍使用Matlab技术进行回归分析的基本步骤,并探讨其中的一些关键概念和技巧。
一、数据准备在进行回归分析之前,首先需要收集和整理相关的数据。
这些数据通常包括自变量和因变量。
自变量是用来解释或预测因变量的变量,而因变量是需要解释或预测的变量。
在Matlab中,可以将数据保存为数据矩阵,其中每一列代表一个变量。
二、模型建立在回归分析中,需要建立一个数学模型来描述自变量和因变量之间的关系。
最简单的线性回归模型可以表示为:Y = βX + ε,其中Y是因变量,X是自变量,β是回归系数,ε是误差项。
在Matlab中,可以使用regress函数来进行线性回归分析。
三、模型拟合模型拟合是回归分析的核心步骤,它的目标是找到最佳的回归系数,使得预测值与实际观测值之间的差异最小。
在Matlab中,可以使用OLS(Ordinary Least Squares)方法来进行最小二乘法回归分析。
该方法通过最小化残差平方和来估计回归系数。
四、模型诊断模型诊断是回归分析中非常重要的一步,它可以帮助我们评估模型的合理性和有效性。
在Matlab中,可以使用多种诊断方法来检验回归模型是否满足统计假设,例如残差分析、方差分析和假设检验等。
这些诊断方法可以帮助我们检测模型是否存在多重共线性、异方差性和离群值等问题。
五、模型应用完成模型拟合和诊断之后,我们可以使用回归模型进行一些实际应用。
例如,可以使用模型进行因变量的预测,或者对自变量的影响进行解释和分析。
在Matlab中,可以使用该模型计算新的观测值和预测值,并进行相关性分析。
六、模型改进回归分析并不是一次性的过程,我们经常需要不断改进模型以提高预测的准确性和解释的可靠性。
在Matlab中,可以使用变量选择算法和模型改进技术来优化回归模型。

统计回归模型(理论+实例+Matlab 代码)一、一元线性回归回归分析中最简单的形式是x y 10ββ+=,y x ,均为标量,10,ββ为回归系数,称一元线性回归。
这里不多做介绍,在线性回归中以介绍多元线性回归分析为主。
二、多元线性回归(regress )多元线性回归是由一元线性回归推广而来的,把x 自然推广为多元变量。
m m x x y βββ+++= 110 (1)2≥m ,或者更一般地)()(110x f x f y m m βββ+++= (2)其中),,(1m x x x =,),,1(m j f j =是已知函数。
这里y 对回归系数),,,(10m ββββ =是线性的,称为多元线性回归。
不难看出,对自变量x 作变量代换,就可将(2)化为(1)的形式,所以下面以(1)为多元线性回归的标准型。
1.1 模型在回归分析中自变量),,,(21m x x x x =是影响因变量y 的主要因素,是人们能控制或能观察的,而y 还受到随机因素的干扰,可以合理地假设这种干扰服从零均值的正态分布,于是模型记作⎩⎨⎧++++=),0(~2110σεεβββN x x y m m (3) 其中σ未知。
现得到n 个独立观测数据),,,(1im i i x x y ,m n n i >=,,,1 ,由(3)得⎩⎨⎧=++++=ni N x x y i i im m i i ,,1),,0(~2110 σεεβββ (4) 记⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=nm n m x x x x X 111111, ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=n y y Y 1 (5) T n ][1εεε =,T m ][10ββββ =(4)表示为⎩⎨⎧+=),0(~2σεεβN X Y (6) 1.2 参数估计用最小二乘法估计模型(3)中的参数β。
由(4)式这组数据的误差平方和为∑=--==ni T i X Y X Y Q 12)()()(ββεβ (7)求β使)(βQ 最小,得到β的最小二乘估计,记作βˆ,可以推出 Y X X X T T 1)(ˆ-=β(8) 将βˆ代回原模型得到y 的估计值mm x x y βββˆˆˆˆ110+++= (9) 而这组数据的拟合值为βˆˆX Y =,拟合误差Y Y e ˆ-=称为残差,可作为随机误差ε的估计,而∑∑==-==n i ni i i iy y e Q 1122)ˆ( (10) 为残差平方和(或剩余平方和),即)ˆ(βQ 。

一Matlab作方差分析方差分析是分析试验(或观测)数据的一种统计方法。
在工农业生产和科学研究中,经常要分析各种因素及因素之间的交互作用对研究对象某些指标值的影响。
在方差分析中,把试验数据的总波动(总变差或总方差)分解为由所考虑因素引起的波动(各因素的变差)和随机因素引起的波动(误差的变差),然后通过分析比较这些变差来推断哪些因素对所考察指标的影响是显著的,哪些是不显著的。
【例1】(单因素方差分析)一位教师想要检查3种不同的教学方法的效果,为此随机地选取水平相当的15位学生。
把他们分为3组,每组5人,每一组用一种方法教学,一段时间以后,这位教师给15位学生进行统考,成绩见下表1。
问这3种教学方法的效果有没有显著差异。
表1 学生统考成绩表Matlab中可用函数anova1(…)函数进行单因子方差分析。
调用格式:p=anova1(X)含义:比较样本m×n的矩阵X中两列或多列数据的均值。
其中,每一列表示一个具有m 个相互独立测量的独立样本。
返回:它返回X中所有样本取自同一总体(或者取自均值相等的不同总体)的零假设成立的概率p。
解释:若p 值接近0(接近程度有解释这自己设定),则认为零假设可疑并认为至少有一个样本均值与其它样本均值存在显著差异。
Matlab 程序:Score=[75 62 71 58 73;81 85 68 92 90;73 79 60 75 81]’; P=anova1(Score)输出结果:方差分析表和箱形图ANOVA TableSource SS df MS F Prob>F Columns 604.9333 2302.46674.2561 0.040088Error 852.8 12 71.0667Total1457.7333 1412360657075808590V a l u e sColumn Number由于p 值小于0.05,拒绝零假设,认为3种教学方法存在显著差异。



Matlab中的回归分析技术实践引言回归分析是统计学中常用的一种分析方法,用于研究因变量和一个或多个自变量之间的关系。
Matlab是一种强大的数值计算软件,具有丰富的统计分析工具和函数。
通过Matlab中的回归分析技术,我们可以深入理解数据背后的规律,并预测未来的趋势。
本文将介绍Matlab中常用的回归分析方法和技巧,并通过实例演示其实践应用。
一、简单线性回归分析简单线性回归是回归分析的最基本形式,用于研究一个自变量和一个因变量之间的线性关系。
在Matlab中,可以使用`fitlm`函数进行简单线性回归分析。
以下是一个示例代码:```Matlabx = [1, 2, 3, 4, 5]';y = [2, 4, 6, 8, 10]';lm = fitlm(x, y);```这段代码中,我们定义了两个向量x和y作为自变量和因变量的观测值。
使用`fitlm`函数可以得到一个线性回归模型lm。
通过这个模型,我们可以获取回归系数、拟合优度、显著性检验等信息。
二、多元线性回归分析多元线性回归分析允许我们研究多个自变量与一个因变量的关系。
在Matlab中,可以使用`fitlm`函数进行多元线性回归分析。
以下是一个示例代码:```Matlabx1 = [1, 2, 3, 4, 5]';x2 = [0, 1, 0, 1, 0]';y = [2, 4, 6, 8, 10]';X = [ones(size(x1)), x1, x2];lm = fitlm(X, y);```这段代码中,我们定义了两个自变量x1和x2,以及一个因变量y的观测值。
通过将常数项和自变量组合成一个设计矩阵X,使用`fitlm`函数可以得到一个多元线性回归模型lm。
通过这个模型,我们可以获取回归系数、拟合优度、显著性检验等信息。
三、非线性回归分析在实际问题中,很多情况下变量之间的关系并不是线性的。
非线性回归分析可以更准确地建模非线性关系。


如何在MATLAB中进行统计回归分析统计回归分析是一种被广泛应用于数据科学和统计学领域的技术。
它被用来分析变量之间的关系,并预测一个或多个自变量对因变量的影响。
在MATLAB中,有许多强大的工具和函数可以帮助我们进行统计回归分析。
本文将讨论如何在MATLAB中使用这些功能进行统计回归分析。
1. 数据导入与预处理在进行回归分析之前,首先需要将数据导入到MATLAB中。
MATLAB支持多种数据格式,如CSV、Excel、文本文件等。
可以使用readmatrix或readtable等函数读取数据,根据数据的特点选择合适的函数。
在导入数据之后,通常需要对数据进行预处理。
这包括处理缺失值、异常值以及数据的标准化。
MATLAB提供了一系列函数来处理这些问题,如isnan、isoutlier和zscore等。
2. 单变量回归分析单变量回归分析是最基本的回归分析方法。
它用于分析一个自变量对一个因变量的影响。
在MATLAB中,可以使用fitlm函数进行单变量回归分析。
fitlm函数需要输入自变量和因变量的数据,然后可以对回归模型进行拟合,并得到回归系数、残差等统计信息。
使用plot函数可以绘制回归模型的拟合曲线,以及残差的散点图。
通过观察残差的分布,可以评估拟合模型的合理性。
3. 多变量回归分析多变量回归分析是在一个或多个自变量对一个因变量的影响进行分析。
在MATLAB中,可以使用fitlm函数或者fitlmulti函数实现多变量回归分析。
fitlm函数可以处理多个自变量,但是需要手动选择自变量,并提供自变量和因变量的数据。
fitlmulti函数则可以自动选择最佳的自变量组合,并进行回归拟合。
它需要提供自变量和因变量的数据矩阵。
多变量回归分析的结果可以通过查看回归系数和残差来解释。
还可以使用plot函数绘制回归模型的拟合曲面或曲线,以便更好地理解自变量对因变量的影响。
4. 方差分析方差分析是一种常用的统计方法,用于比较两个或多个因素对因变量的影响。
实验报告的书写是一项重要的基本技能训练。
它不仅是对每次实验的总结,更重要的是它可以初步地培养和训练学生的逻辑归纳能力、综合分析能力和文字表达能力,是科学论文写作的基础。
因此,参加实验的每位学生,均应及时认真地书写实验报告。
要求内容实事求是,分析全面具体,文字简练通顺,誊写清楚整洁。
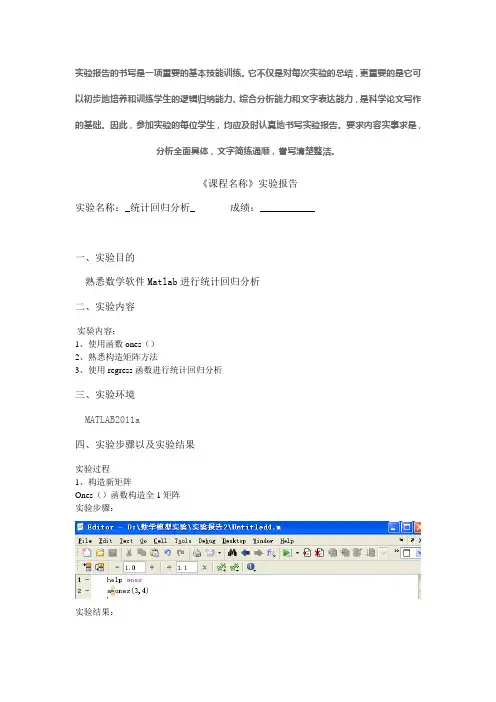
《课程名称》实验报告实验名称:_统计回归分析_ 成绩:___________一、实验目的熟悉数学软件Matlab进行统计回归分析二、实验内容实验内容:1、使用函数ones()2、熟悉构造矩阵方法3、使用regress函数进行统计回归分析三、实验环境MATLAB2011a四、实验步骤以及实验结果实验过程1、构造新矩阵Ones()函数构造全1矩阵实验步骤:实验结果:注意“矩阵乘法即‘*’”与”元素乘法‘.*’”,即矩阵或数组的对应元素相乘,例如X=[1,2,3]则a=x.*x 结果为对应元素相乘即:[1,4,9]实验步骤://Untitled5.m//实验结果:2、画数据散点图函数格式:输入数据X=[数据]Y=[数据]注意x、y维数相同画图plot(x,y。
‘选择颜色与线型’)运行结果:图形输出在figure窗口详细情况使用:help plot 实验步骤://*Untitled6.m*//实验结果:实验步骤:/*Untitled7.m*/实验结果:3、牙膏销售模型分析(书第294页到第302页)//Untitle 8///画散点图统计回归分析regress()统计回归分析函数,注意函数对应的模型及模型检验指标‘基本模型分析实验结果:Y对X1的散点图(plot(X1,Y,'o'))Y对X2的散点图。
(plot(X2,Y,'o'))实验结果:模型二:(x2=[a X1' X2' (X2.*X2)' (X1.*X2)'][b,bint,r,rint,stats]=regress(Y',x2,alpha))计算结果:模型三:4、软件开发人员的薪金(书第302页到第308页)画散点图统计回归分析regress()统计回归分析函数,注意函数对应的模型及模型检验指标模型一:试验结果:试验结果:去掉异常点33号:六、实验讨论、结论1、根据实例一步步去分析,和模型进行拟合。


matlab中基本统计和回归命令(可编辑)例3 设某商品的需求量与消费者的平均收入、商品价格的统计数据如下,建立回归模型,预测平均收入为1000、价格为6时的商品需求量. 法一直接用多元二项式回归: x1[1000 600 1200 500 300 400 1300 1100 1300 300]; x2 [5 7 6 6 8 7 5 4 3 9];y [100 75 80 70 50 65 90 100 110 60]'; x [x1' x2']; rstoolx,y,'purequadratic' 在画面左下方的下拉式菜单中选”all”, 则beta、rmse和residuals都传送到Matlab工作区中. 在左边图形下方的方框中输入1000,右边图形下方的方框中输入6。
则画面左边的“Predicted Y”下方的数据变为88.47981,即预测出平均收入为1000、价格为6时的商品需求量为88.4791. 在Matlab工作区中输入命令: beta, rmse 结果为: b 110.53130.1464 -26.5709 -0.00011.8475 stats 0.9702 40.6656 0.0005 法二将化为多元线性回归: 非线性回归 (1)确定回归系数的命令: [beta,r,J] nlinfit(x,y,’model’, beta0) (2)非线性回归命令:nlintool (x,y,’model’, beta0,alpha) 1、回归: 残差 Jacobian矩阵回归系数的初值是事先用m-文件定义的非线性函数估计出的回归系数输入数据x、y 分别为矩阵和n维列向量,对一元非线性回归,x为n维列向量。
2、预测和预测误差估计: [Y,D ELTA] nlpredci(’model’, x,beta,r,J) 求nlinfit 或nlintool所得的回归函数在x处的预测值Y及预测值的显著性为1-alpha的置信区间Y DELTA. * * 一、数据的录入、保存和调用例1 上海市区社会商品零售总额和全民所有制职工工资总额的数据如下统计工具箱中的基本统计命令 1、年份数据以1为增量,用产生向量的方法输入。
利用MATLAB进行回归分析一、实验目的:1.了解回归分析的基本原理,掌握MATLAB实现的方法;2. 练习用回归分析解决实际问题。
二、实验内容:题目1社会学家认为犯罪与收入低、失业及人口规模有关,对20个城市的犯罪率y(每10万人中犯罪的人数)与年收入低于5000美元家庭的百分比1x、失业率2x和人口总数3x(千人)进行了调查,结果如下表。
(1)若1x~3x中至多只许选择2个变量,最好的模型是什么?(2)包含3个自变量的模型比上面的模型好吗?确定最终模型。
(3)对最终模型观察残差,有无异常点,若有,剔除后如何。
理论分析与程序设计:为了能够有一个较直观的认识,我们可以先分别作出犯罪率y与年收入低于5000美元家庭的百分比1x、失业率2x和人口总数x(千人)之间关系的散点图,根据大致分布粗略估计各因素造3成的影响大小,再通过逐步回归法确定应该选择哪几个自变量作为模型。
编写程序如下:clc;clear all;y=[11.2 13.4 40.7 5.3 24.8 12.7 20.9 35.7 8.7 9.6 14.5 26.9 15.736.2 18.1 28.9 14.9 25.8 21.7 25.7];%犯罪率(人/十万人)x1=[16.5 20.5 26.3 16.5 19.2 16.5 20.2 21.3 17.2 14.3 18.1 23.1 19.124.7 18.6 24.9 17.9 22.4 20.2 16.9];%低收入家庭百分比x2=[6.2 6.4 9.3 5.3 7.3 5.9 6.4 7.6 4.9 6.4 6.0 7.4 5.8 8.6 6.5 8.36.7 8.6 8.4 6.7];%失业率x3=[587 643 635 692 1248 643 1964 1531 713 749 7895 762 2793 741 625 854 716 921 595 3353];%总人口数(千人)figure(1),plot(x1,y,'*');figure(2),plot(x2,y,'*');figure(3),plot(x3,y,'*');X1=[x1',x2',x3'];stepwise(X1,y)运行结果与结论:犯罪率与低收入散点图犯罪率与失业率散点图犯罪率与人口总数散点图低收入与失业率作为自变量低收入与人口总数作为自变量失业率与人口总数作为自变量在图中可以明显看出前两图的线性程度很好,而第三个图的线性程度较差,从这个角度来说我们应该以失业率和低收入为自变量建立模型。
实验三:统计回归模型Matlab求解一、实验目的[1] 通过范例学习建立统计回归的数学模型以及求解全过程;[2] 熟悉MATLAB求解统计回归模型的过程。
二、实验原理问题:一家技术公司人事部门为研究软件开发人员的薪金与他们的资历、管理责任、教育程度等因素之间的关系,要建立一个数学模型,以便分析公司人事策略的合理性,并作为新聘用人员薪金的参考。
他们认为目前公司人员的薪金总体上是合理的,可以作为建模的依据,于是调查来46名软件开发人员的档案资料,如表4,其中资历一列指从事专业工作的年数,管理一列中1表示管理人员,0表示非管理人员,教育一列中1表示中学程度,2表示大学程度,3表示更高程度(研究生)分析与假设按照常识,薪金自然随着资历的增长而增加,管理人员的薪金应高于非管理人员,教育程度越高薪金也越高。
薪金记作y,资历记作x1,为了表示是否管理人员,定义:21 0,x⎧=⎨⎩,管理人员非管理人员.为了表示3种教育程度,定义:31,0,x ⎧=⎨⎩中学其它 41,0,x ⎧=⎨⎩大学其它这样,中学用x 3=1,x 4=0表示,大学用x 3=0,x 4=1表示,研究生则用x 3=0,x 4=0表示。
假定资历对薪金的作用是线性的,即资历每加一年,薪金的增长是常数;管理责任、教育程度、资历诸因素之间没有交互作用,建立线性回归模型。
基本模型 薪金y 与资历x1, 管理责任x2,教育程度x3,x4之间的多元线性回归模型为011223344y a a x a x a x a x ε=+++++ (1)其中014,,a a a …,是待估计的回归系数,ε是随机误差。
MATLAB 的统计工具箱基本函数regress:[b,bint,r,rint,stats]=regress(y,x,alpha) 输入:y: n 维数据向量x: n ⨯5数据矩阵, 第1列为全1向量 alpha: 置信水平,0.05输出:b: 参数估计值bint: b 的置信区间 r : 残差向量y -xb rint:r 的置信区间stats: 第一个数为残差平方即回归方程之决定系数 R^2(R 为相关系数)越接近1,回归方程显著;第二个数为统计量F 检验的值,越大回归方程越显著;第三个数为F 对应概率P ,越接近零越好;第四个数是误差项的方差估计值在MA TLAB 命令窗口输入代码:y=[13876;11608;18701;11283;11767;20872;11772;10535;12195;12313;14975;21371;19800;11417;20263;13231;12884;13245;13677;15965;12366;21352;13839;22884;16978;14803;17404;22184;13548;14467;15942;23174;23780;25410;14861;16882;24170;15990;26330;17949;25685;27837;18838;17483;19207;19346];x1=[1;1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;6;6;6;6;7;8;8;8;8;10;10;10;10;11;11;12;12;13;13;14;15;16;16;16;17;20];x2=[1;0;1;0;0;1;0;0;0;0;1;1;1;0;1;0;0;0;0;1;0;1;0;1;1;0;1;1;0;0;0;1;1;1;0;0;1;0;1;0;1;1;0;0;0;0]; x3=[1;0;0;0;0;0;0;1;0;0;1;0;0;1;0;0;0;0;0;1;1;0;0;0;1;0;1;0;1;1;0;0;0;0;1;0;0;1;0;0;0;0;0;1;0;1]; x4=[0;0;0;1;0;1;1;0;0;1;0;1;0;0;0;0;1;1;0;0;0;0;1;1;0;1;0;0;0;0;1;0;1;1;0;1;0;0;1;1;0;1;1;0;1;0];xb5=[ones(46,1),x1,x2,x3,x4]; [b,bint,r,rint,stats]=regress(y,xb5)可以得到回归系数及其置信区间(置信水平a=0.05)、检验统计量R 2,F ,p 结果,结果分析: R 2=0.957,即因变量(薪金)的95.7%可由模型确定,F 值远远超过F 检验的临界值,p 远小于a ,因而模型(1)从整体来看是可用的。
比如,利用模型可以估计(或预测)一个大学毕业、有2年资历、管理人员的薪金为01234ˆ*2*0*0*112273ya a a a a =++++= 模型中各个回归系数的含义可初步解释如下:x1的系数为546,说明资历每增加1年,薪金增长546;x2的系数为6883,说明管理人员的薪金比非管理人员多6883;x3的系数为-2994,说明中学程度的薪金比研究生少2994;x4的系数为148,说明大学程度的薪金比研究生多148,但是应该注意到4a 的置信区间包含零点,所以这个系数的解释是不可靠的。
需要指出,以上理解是就平均值来说,并且,一个因素改变引起的因变量的变化量,都是在其它因素需不变的条件下才成立的。
进一步的讨论4a 的置信区间包含零点,说明基本模型(1)存在缺点。
为寻找改进的方向,常用残差分析法(残差ε指薪金的实际值y 与用模型估计的薪金ˆy之差,是模型(1)中随机误差ε的估计值,这里用了同一个符号)。
为了对残差进行分析,作图给出ε与资历x1的关系(图1),%图1yj=11032+546*x1+6883*x2+(-2994*x3)+148*x4; eb=y-yj;plot(x1,eb,'r+')图1: e 与资历x 1的关系从图1中看出,残差大概分成3个水平,这是由于6种管理-教育组合混在一起,在模型中未被正确反映的结果我们将影响因素分成资历与管理——教育组合两类,管理——教育组合的定义如下表把组合标号1,2,3,4,5,6作为变量X5,则由原数据可得x5=[2;5;6;3;5;4;3;1;5;3;2;4;6;1;6;5;3;3;5;2;1;6;3;4;2;3;2;6;1;1;3;6;4;4;1;3;6;1;4;3;6;4;3;1;3;1];作图给出ε与管理x2——教育x3,x4组合间的关系(图2)。
%图2x5=[2;5;6;3;5;4;3;1;5;3;2;4;6;1;6;5;3;3;5;2;1;6;3;4;2;3;2;6;1;1;3;6;4;4;1;3;6;1;4;3;6;4;3;1;3;1]; plot(x5,eb,'r+')图2: e 与管理—教育组合的关系从图2看,对于前4个管理——教育组合,残差或者全为正,或者全为负,也表明——教育组合在模型中处理不当。
在模型(1)中管理责任和教育程度是分别起作用的,事实上,二者可能起着交互作用,如大学程度的管理人员的薪金会比二者分别得薪金之和高一点。
以上分析提示我们,应在基本模型(1)中增加管理x2与教育x3,x4的交互项,建立新的回归模型。
更好的模型 增加x2与x3,x4的交互项后,模型记作011223344523624y a a x a x a x a x a x x a x x ε=+++++++ 利用MATLAB 的统计工具箱xb7=[ones(46,1),x1,x2,x3,x4,x2.*x3,x2.*x4]; [b,bint,r,rint,stats]=regress(y,xb7)得到的结果:R和F值都比模型(1)中的有所改进,并且所有回归系数的置信可知,模型(2)的2区间都不含零点,表明模型(2)是完全可用的。
与模型(1)类似,做模型(2)的两个残差分析图(图11,图12),可以看出,已经消除了图1和图2中的不正常现象,这也说明了模型(2)的适用性。
%图11yj=11204+497*x1+7048*x2-1727*x3-348*x4-3071*x2.*x3+1836*x2.*x4;eb=y-yj;plot(x1,eb,'r+')%图12x5=[2;5;6;3;5;4;3;1;5;3;2;4;6;1;6;5;3;3;5;2;1;6;3;4;2;3;2;6;1;1;3;6;4;4;1;3;6;1;4;3;6;4;3;1;3;1]; plot(x5,eb,'r+')从图11、图12还可以发现一个异常点:具有10年策略、大学程度的管理人员(从表4可以查出是33号),他的实际薪金明显低于模型的估计值,也明显低于他有类似经历的其他人的薪金。
这可能是由于我们未知的原因造成的。
为了是个别的数据不致影响整个模型,应该将这个异常数据去掉,对模型(2)重新估计回归系数,得到的结果如表8,残差分析图见图13,图14。
可以看出,去掉异常数据结果又有改善。
%表8y=[13876;11608;18701;11283;11767;20872;11772;10535;12195;12313;14975;21371;19800;1141 7;20263;13231;12884;13245;13677;15965;12366;21352;13839;22884;16978;14803;17404;22184 ;13548;14467;15942;23174;25410;14861;16882;24170;15990;26330;17949;25685;27837;18838; 17483;19207;19346];x1=[1;1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;6;6;6;6;7;8;8;8;8;10;10;10;11;11;12;12;13;13;14;15;16;16;16;17;20];x2=[1;0;1;0;0;1;0;0;0;0;1;1;1;0;1;0;0;0;0;1;0;1;0;1;1;0;1;1;0;0;0;1;1;0;0;1;0;1;0;1;1;0;0;0;0]; x3=[1;0;0;0;0;0;0;1;0;0;1;0;0;1;0;0;0;0;0;1;1;0;0;0;1;0;1;0;1;1;0;0;0;1;0;0;1;0;0;0;0;0;1;0;1]; x4=[0;0;0;1;0;1;1;0;0;1;0;1;0;0;0;0;1;1;0;0;0;0;1;1;0;1;0;0;0;0;1;0;1;0;1;0;0;1;1;0;1;1;0;1;0]; x5=[2;5;6;3;5;4;3;1;5;3;2;4;6;1;6;5;3;3;5;2;1;6;3;4;2;3;2;6;1;1;3;6;4;1;3;6;1;4;3;6;4;3;1;3;1]; xb8=[ones(45,1),x1,x2,x3,x4,x2.*x3,x2.*x4];[b,bint,r,rint,stats]=regress(y,xb8)%图13yj=11200+498*x1+7041*x2-1737*x3-356*x4-3056*x2.*x3+1997*x2.*x4;eb=y-yj;plot(x1,eb,'r+')%图14plot(x5,eb,'r+')三、实验内容(1) 解答实验原理中的问题:一家技术公司人事部门为研究软件开发人员的薪金与他们的资历、管理责任、教育程度等因素之间的关系,要建立一个数学模型,以便分析公司人事策略的合理性,并作为新聘用人员薪金的参考。