统计学案例——相关回归分析
- 格式:doc
- 大小:1.18 MB
- 文档页数:15

统计学案例——相关回归分析报告《统计学》案例——相关回归分析案例⼀质量控制中的简单线性回归分析1、问题的提出某⽯油炼⼚的催化装置通过⾼温及催化剂对原料的作⽤进⾏反应,⽣成各种产品,其中液化⽓⽤途⼴泛、易于储存运输,所以,提⾼液化⽓收率,降低不凝⽓体产量,成为提⾼经济效益的关键问题。
通过因果分析图和排列图的观察,发现回流温度是影响液化⽓收率的主要原因,因此,只有确定⼆者之间的相关关系,寻找适当的回流温度,才能达到提⾼液化⽓收率的⽬的。
经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化⽓收率⽐去年同期增长1个百分点的⽬标,即达到12.24%的液化⽓收率。
2、数据的收集⽬标值确定之后,我们收集了某年某季度的回流温度与液化⽓收率的30组数据(如上表),进⾏简单直线回归分析。
3.⽅法的确⽴设线性回归模型为εββ++=x y 10,估计回归⽅程为x b b y10?+= 将数据输⼊计算机,输出散点图可见,液化⽓收率y 具有随着回流温度x的提⾼⽽降低的趋势。
因此,建⽴描述y 与x 之间关系的模型时,⾸选直线型是合理的。
从线性回归的计算结果,可以知道回归系数的最⼩⼆乘估计值b 0=21.263和b 1=-0.229,于是最⼩⼆乘直线为x y229.0263.21?-= 这就表明,回流温度每增加1℃,估计液化⽓收率将减少0.229%。
(3)残差分析为了判别简单线性模型的假定是否有效,作出残差图,进⾏残差分析。
从图中可以看到,残差基本在-0.5—+0.5左右,说明建⽴回归模型所依赖的假定是恰当的。
误差项的估计值s=0.388。
(4)回归模型检验 a.显著性检验在90%的显著⽔平下,进⾏t 检验,拒绝域为︱t ︱=︱b 1/ s b1︱>t α/2=1.7011。
由输出数据可以找到b 1和s b1,t=b 1/ s b1=-0.229/0.022=-10.313,于是拒绝原假设,说明液化⽓收率与回流温度之间存在线性关系。

spss多元回归分析案例SPSS多元回归分析案例。
在统计学中,多元回归分析是一种用于探究多个自变量与因变量之间关系的方法。
通过多元回归分析,我们可以了解不同自变量对因变量的影响程度,以及它们之间的相互作用情况。
在本篇文档中,我将通过一个实际案例来介绍如何使用SPSS软件进行多元回归分析。
案例背景:假设我们是一家电子产品公司的市场营销团队,在推出新产品之前,我们希望了解不同因素对产品销量的影响。
我们收集了一些数据,包括产品的售价、广告投入、竞争对手的售价、季节等因素,以及产品的销量作为因变量。
数据准备:首先,我们需要将数据录入SPSS软件中。
在SPSS中,我们可以通过导入Excel文件的方式将数据导入到软件中,并进行必要的数据清洗和处理。
确保数据的准确性和完整性对于后续的多元回归分析非常重要。
模型建立:接下来,我们需要建立多元回归模型。
在SPSS中,我们可以通过依次选择“分析”-“回归”-“线性回归”来进行多元回归分析。
在“因变量”栏中输入销量,然后将所有自变量依次输入到“自变量”栏中。
在建立模型之前,我们还需要考虑是否需要进行变量转换或交互项的添加,以更好地拟合数据。
模型诊断:建立模型后,我们需要对模型进行诊断,以确保模型的准确性和有效性。
在SPSS中,我们可以通过查看残差的正态性、异方差性以及自相关性来进行模型诊断。
如果模型存在严重的偏差或违反了多元回归分析的假设,我们需要进行相应的修正或改进。
模型解释:最后,我们需要解释多元回归模型的结果。
在SPSS的输出结果中,我们可以看到各个自变量的系数、显著性水平、调整R方等统计指标。
通过这些指标,我们可以了解不同自变量对销量的影响程度,以及它们之间的相互作用情况。
同时,我们还可以进行各种假设检验,来验证模型的有效性和可靠性。
结论:通过以上多元回归分析,我们可以得出不同自变量对产品销量的影响程度,以及它们之间的相互作用情况。
这些结果对于我们制定产品的定价策略、广告投放策略以及市场营销策略都具有重要的指导意义。
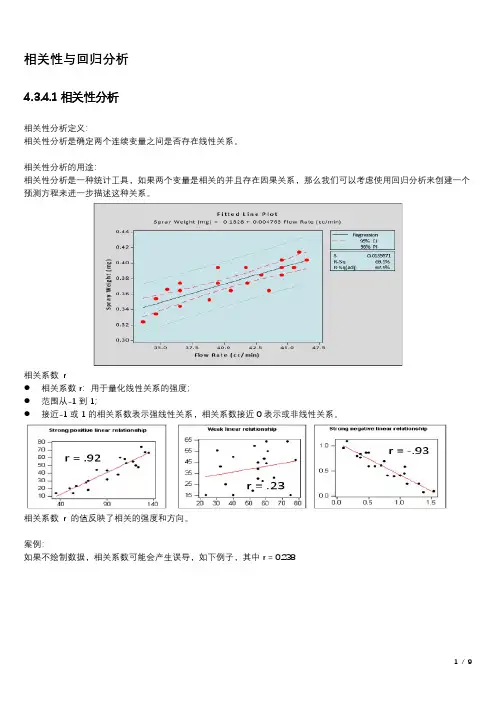
相关性与回归分析4.3.4.1相关性分析相关性分析定义:相关性分析是确定两个连续变量之间是否存在线性关系。
相关性分析的用途:相关性分析是一种统计工具,如果两个变量是相关的并且存在因果关系,那么我们可以考虑使用回归分析来创建一个预测方程来进一步描述这种关系。
相关系数r●相关系数r:用于量化线性关系的强度;●范围从-1到1;●接近-1或1的相关系数表示强线性关系,相关系数接近0表示或非线性关系。
相关系数r 的值反映了相关的强度和方向。
案例:如果不绘制数据,相关系数可能会产生误导,如下例子,其中r = 0.238尽管相关系数表示弱线性关系,但图形显示强曲线关系-始终绘制数据相关VS因果例如,犯罪率和冰淇淋销售之间的相关系数为r=0.96,那么强相关系数是否意味着因果关系?高冰激凌销量会导致高犯罪率吗?相关性只意味着存在一种线性关系,而未必是因果关系。
相关性分析案例:黑带想知道在更高的流速和更多附着在灯丝上的物质之间是否存在线性关系?收集历史数据并计算相关系数。
相关检验的原假设是相关系数r=0(更高的流速和更多附着在灯丝上的物质之间无线性关系),备择假设是相关系数r ≠0(更高的流速和更多附着在灯丝上的物质之间有线性关系)。
●p > 0.05,无法拒绝原假设,更高的流速和更多附着在灯丝上的物质之间无线性关系(无显著性差异);●p < 0.05,拒绝原假设,更高的流速和更多附着在灯丝上的物质之间有线性关系(有显著性差异)。
复制数据-统计(S)-基本统计(B)-相关(C):变量(V):点击C15、C16?-方法(M):选择pearson相关系数-点击显示P值(D)-确定P值决定了统计的显著性,皮尔逊相关系数r = 0.834为正,正相关,中等强度(较强)相关性。
判定准则(结论):p值= 0.000 < 0.05,拒绝原假设,接收备择假设,更高的流速和更多附着在灯丝上的物质之间有线性关系。
皮尔逊相关系数r = 0.834,为较强的正相关。

统计学案例分析(总3页)
--本页仅作为文档封面,使用时请直接删除即可--
--内页可以根据需求调整合适字体及大小--
统计学期末考试
y=a+bx
关于江西省GDP与全国GDP的数据分析
一:相关于回归分析
由上图可知:y=
相关系数:R=5836
所以江西省GDP与全国GDP确实存在着线性相关关系
二:时间趋势分析
对比上列数据图表可知:江西省GDP增速在2005年低于全国平均水平,随后逐渐赶超,至2008-
2009年时增速差距最明显,至2014-2015年,江西省GDP增
速又遇到阻碍,低于全国均值
y=a+bx b=
a=y=
故y=+
三:图表分析
对比上列数据图表可知:江西省GDP增速在2005年低于全国平均水平,随后逐渐赶超,至2008-2009年时增速差距最明显,至2014-2015年,江西省GDP增速又遇到阻碍,低于全国均值。

多元线性回归分析案例多元线性回归分析是统计学中常用的一种分析方法,它可以用来研究多个自变量对因变量的影响,并建立相应的数学模型。
在实际应用中,多元线性回归分析可以帮助我们理解变量之间的关系,预测未来的趋势,以及制定相应的决策。
本文将通过一个实际案例来介绍多元线性回归分析的基本原理和应用方法。
案例背景。
假设我们是一家电子产品制造公司的市场营销团队,我们想要了解产品销量与广告投入、产品定价和市场规模之间的关系。
我们收集了过去一年的数据,包括每个月的产品销量(千台)、广告投入(万元)、产品定价(元/台)和市场规模(亿人)。
数据分析。
首先,我们需要对数据进行描述性统计分析,以了解各变量的分布情况和相关性。
我们计算了产品销量、广告投入、产品定价和市场规模的均值、标准差、最大最小值等统计量,并绘制了相关性矩阵图。
通过分析发现,产品销量与广告投入、产品定价和市场规模之间存在一定的相关性,但具体的关系还需要通过多元线性回归分析来验证。
多元线性回归模型。
我们建立了如下的多元线性回归模型:\[Sales = \beta_0 + \beta_1 \times Advertising + \beta_2 \times Price + \beta_3 \times MarketSize + \varepsilon\]其中,Sales表示产品销量,Advertising表示广告投入,Price表示产品定价,MarketSize表示市场规模,\(\beta_0, \beta_1, \beta_2, \beta_3\)分别为回归系数,\(\varepsilon\)为误差项。
模型验证。
我们利用最小二乘法对模型进行参数估计,并进行了显著性检验和回归诊断。
结果表明,广告投入、产品定价和市场规模对产品销量的影响是显著的,模型的拟合效果较好。
同时,我们还对模型进行了预测能力的验证,结果表明模型对未来产品销量的预测具有一定的准确性。
决策建议。



回归分析是统计学中一种重要的分析方法,用于探究自变量和因变量之间的关系。
在实际应用中,回归分析常常用于预测、解释和控制变量。
本文将通过几个实际案例,对回归分析进行深入解读和分析。
案例一:销售数据分析某电商平台想要分析不同广告投放对销售额的影响,他们收集了一段时间内的广告投放数据和销售额数据。
为了进行分析,他们利用回归分析建立了一个模型,以广告费用作为自变量,销售额作为因变量。
通过回归分析,他们发现广告费用与销售额之间存在着显著的正相关关系,即广告费用的增加会带动销售额的增加。
通过该分析,电商平台可以更好地制定广告投放策略,优化营销预算,提高销售效益。
案例二:医疗数据分析一家医疗机构收集了一组患者的基本信息、生活习惯以及健康指标等数据,希望通过回归分析来探究生活习惯对健康指标的影响。
他们建立了一个回归模型,以吸烟、饮酒、饮食习惯等自变量,健康指标作为因变量。
通过回归分析,他们发现吸烟和饮酒对健康指标有负向影响,而良好的饮食习惯与健康指标呈正相关关系。
这些发现可以帮助医疗机构更好地进行健康干预和宣教,促进患者的健康改善。
案例三:金融数据分析一家金融机构收集了一段时间内的股票价格、市场指数等数据,希望通过回归分析来探究市场指数对股票价格的影响。
他们建立了一个回归模型,以市场指数作为自变量,股票价格作为因变量。
通过回归分析,他们发现市场指数与股票价格存在着较强的正相关关系,即市场指数的波动会对股票价格产生显著影响。
这些结果可以帮助金融机构更好地进行投资策略的制定和风险控制。
通过以上案例分析,我们可以看到回归分析在不同领域的应用。
回归分析不仅可以帮助人们理解变量之间的关系,还可以用于预测和控制变量。
在实际应用中,我们需要注意回归分析的假设条件、模型选择和结果解释等问题,以确保分析的准确性和可靠性。
在回归分析中,我们需要注意变量选择、模型拟合度和结果解释等问题。
另外,回归分析也有一些局限性,比如无法确定因果关系、对异常值敏感等问题。

统计学中的非线性回归模型与应用案例统计学是一门研究数据收集、分析和解释的学科。
在统计学中,回归分析是一种常用的方法,用于研究自变量与因变量之间的关系。
传统的回归模型假设自变量与因变量之间的关系是线性的,然而在现实世界中,很多情况下变量之间的关系并不是简单的线性关系。
因此,非线性回归模型应运而生。
非线性回归模型允许自变量与因变量之间的关系呈现出曲线、指数、对数等非线性形式。
这种模型的应用非常广泛,可以用于解决各种实际问题。
下面将介绍一些非线性回归模型的应用案例。
案例一:生长曲线模型生长曲线模型是一种常见的非线性回归模型,用于描述生物体、经济指标等随时间变化的增长过程。
以植物的生长为例,我们可以将植物的高度作为因变量,时间作为自变量,建立一个非线性回归模型来描述植物的生长过程。
通过拟合模型,我们可以预测植物在未来的生长情况,为农业生产提供参考依据。
案例二:Logistic回归模型Logistic回归模型是一种常用的非线性回归模型,用于研究二分类问题。
例如,我们可以使用Logistic回归模型来预测一个人是否患有某种疾病。
以心脏病的预测为例,我们可以将心脏病的发生与各种危险因素(如年龄、性别、血压等)建立一个Logistic回归模型。
通过拟合模型,我们可以根据个体的危险因素预测其是否患有心脏病,从而采取相应的预防措施。
案例三:多项式回归模型多项式回归模型是一种常用的非线性回归模型,用于描述自变量与因变量之间的高阶关系。
例如,我们可以使用多项式回归模型来研究温度与气压之间的关系。
通过拟合模型,我们可以得到温度与气压之间的高阶关系,从而更好地理解气象变化规律。
案例四:指数回归模型指数回归模型是一种常用的非线性回归模型,用于描述自变量与因变量之间的指数关系。
例如,我们可以使用指数回归模型来研究广告投入与销售额之间的关系。
通过拟合模型,我们可以得到广告投入对销售额的指数影响,从而为企业制定广告投放策略提供决策依据。
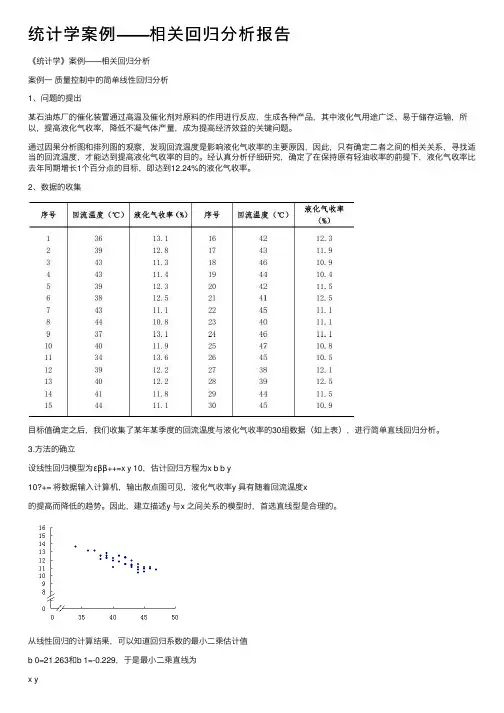
《统计学》案例——相关回归分析案例一质量控制中的简单线性回归分析1、问题的提出某石油炼厂的催化装置通过高温及催化剂对原料的作用进行反应,生成各种产品,其中液化气用途广泛、易于储存运输,所以,提高液化气收率,降低不凝气体产量,成为提高经济效益的关键问题。
通过因果分析图和排列图的观察,发现回流温度是影响液化气收率的主要原因,因此,只有确定二者之间的相关关系,寻找适当的回流温度,才能达到提高液化气收率的目的。
经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化气收率比去年同期增长1个百分点的目标,即达到12.24%的液化气收率。
2、数据的收集序号回流温度(℃)液化气收率(%)序号回流温度(℃)液化气收率(%)1 2 3 4 5 6 7 8 9 10 11 12 13 14 1536 39 43 43 39 38 43 44 37 40 34 39 40 41 4413.1 12.8 11.3 11.4 12.3 12.5 11.1 10.8 13.1 11.9 13.6 12.2 12.2 11.8 11.116 17 18 19 20 21 22 23 24 25 26 27 28 29 3042 43 46 44 42 41 45 40 46 47 45 38 39 44 4512.3 11.9 10.9 10.4 11.5 12.5 11.1 11.1 11.1 10.8 10.5 12.1 12.5 11.5 10.9目标值确定之后,我们收集了某年某季度的回流温度和液化气收率的30组数据(如上表),进行简单直线回归分析。
3.方法的确立设线性回归模型为εββ++=x y 10,估计回归方程为x b b y10ˆ+= 将数据输入计算机,输出散点图可见,液化气收率y 具有随着回流温度x 的提高而降低的趋势。
因此,建立描述y 和x 之间关系的模型时,首选直线型是合理的。
从线性回归的计算结果,可以知道回归系数的最小二乘估计值b 0=21.263和b 1=-0.229,于是最小二乘直线为x y229.0263.21ˆ-= 这就表明,回流温度每增加1℃,估计液化气收率将减少0.229%。
统计学中的回归分析与相关性回归分析与相关性是统计学中重要的概念和方法,用于研究变量之间的关系和预测。
本文将介绍回归分析和相关性分析的基本原理、应用领域以及实际案例。
一、回归分析回归分析是研究两个或多个变量之间关系的一种统计方法。
它的基本思想是通过对一个或多个自变量与一个因变量之间的关系进行建模,来预测因变量的取值。
1.1 简单线性回归简单线性回归是回归分析中最基本的形式,用于研究一个自变量和一个因变量之间的关系。
其数学模型可以表示为:Y = β0 + β1X + ε,其中Y是因变量,X是自变量,β0和β1是回归系数,ε是误差项。
1.2 多元回归多元回归是回归分析的扩展形式,用于研究多个自变量对一个因变量的影响。
其数学模型可以表示为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε。
1.3 回归诊断回归分析需要对建立的模型进行诊断,以确保模型的有效性和合理性。
常见的回归诊断方法包括检验残差的正态性、检验变量之间的线性关系、检验残差的独立性和方差齐性等。
二、相关性分析相关性分析是统计学中用来研究两个变量之间线性关系强弱的方法。
通过计算两个变量的相关系数,可以判断它们之间的相关性。
2.1 皮尔逊相关系数皮尔逊相关系数是最常用的衡量两个连续变量之间线性相关强度的指标,取值范围在-1到1之间。
当相关系数接近1时,表示两个变量呈正相关;当相关系数接近-1时,表示两个变量呈负相关;当相关系数接近0时,表示两个变量之间没有线性关系。
2.2 斯皮尔曼相关系数斯皮尔曼相关系数是一种非参数统计量,用于衡量两个变量之间的等级相关性。
与皮尔逊相关系数不同,斯皮尔曼相关系数不要求变量呈线性关系。
三、回归分析与相关性的应用回归分析和相关性分析在各个领域都有广泛的应用。
下面以两个实际案例来说明其应用:3.1 股票市场分析在股票市场分析中,可以使用回归分析来研究某只股票的收益率与市场整体指数之间的关系。
《统计学》案例——相关回归分析案例一质量控制中的简单线性回归分析1、问题的提出某石油炼厂的催化装置通过高温及催化剂对原料的作用进行反应,生成各种产品,其中液化气用途广泛、易于储存运输,所以,提高液化气收率,降低不凝气体产量,成为提高经济效益的关键问题。
通过因果分析图和排列图的观察,发现回流温度是影响液化气收率的主要原因,因此,只有确定二者之间的相关关系,寻找适当的回流温度,才能达到提高液化气收率的目的。
经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化气收率比去年同期增长1个百分点的目标,即达到12.24%的液化气收率。
2、数据的收集目标值确定之后,我们收集了某年某季度的回流温度与液化气收率的30组数据(如上表),进行简单直线回归分析。
3.方法的确立设线性回归模型为εββ++=x y 10,估计回归方程为x b b y10ˆ+= 将数据输入计算机,输出散点图可见,液化气收率y 具有随着回流温度x 的提高而降低的趋势。
因此,建立描述y 与x 之间关系的模型时,首选直线型是合理的。
从线性回归的计算结果,可以知道回归系数的最小二乘估计值b 0=21.263和b 1=-0.229,于是最小二乘直线为x y229.0263.21ˆ-= 这就表明,回流温度每增加1℃,估计液化气收率将减少0.229%。
(3)残差分析为了判别简单线性模型的假定是否有效,作出残差图,进行残差分析。
从图中可以看到,残差基本在-0.5—+0.5左右,说明建立回归模型所依赖的假定是恰当的。
误差项的估计值s=0.388。
(4)回归模型检验 a.显著性检验在90%的显著水平下,进行t 检验,拒绝域为︱t ︱=︱b 1/ s b1︱>t α/2=1.7011。
由输出数据可以找到b 1和s b1,t=b 1/ s b1=-0.229/0.022=-10.313,于是拒绝原假设,说明液化气收率与回流温度之间存在线性关系。
b.拟合度检验判定系数r 2=0.792。
这意味着液化气收率的样本变差大约有80%可以由它与回流温度的线性关系来解释。
2r r ==-0.89这样,r 值为y 与x 之间存在中高度的负线性关系提供了进一步的证据。
由于n ≥30,我们近似确定y 的90%置信区间为:s z y)(ˆ2α±=21.263-0.229x ±1.282×0.388 = 21.263-0.229x ± 0.4974、结果分析由回归直线图可知,要保持液化气收率在12.24%以上,回流温度必须控制在34℃以下。
因为装置工艺卡片要求回流温度在33—40℃之间,为确保液化气质量合格,可以将回流温度控制在33—34℃之间。
为此,应当采取各项有效措施,改善外部操作环境,将液化气收率控制在目标值范围内。
案例二:轿车生产与GDP等关系研究中国的轿车生产是否与GDP、城镇居民人均可支配收入、城镇居民家庭恩格尔系数、私人载客汽车拥有量、公路里程等都有密切关系?如果有关系,它们之间是种什么关系?关系强度如何?(数据见《中国统计年鉴》)(1)分析轿车生产量与私人载客汽车拥有量之间的关系:首先,求的因变量轿车生产量y和自变量私人载客汽车拥有量x1的相关系数r=0.992018,说明两者间存在一定的线性相关关系且正相关程度很强。
然后以轿车生产量为因变量y,私人载客汽车拥有量x1为自变量进行一元线性回归分析,结果如下:①由回归统计中的R=0.984101看出,所建立的回归模型对样本观测值的拟合程度很好;②估计出的样本回归函数为:ŷ=1.775687+0.206783x1,说明私人载客汽车拥有量每增加1万辆,轿车生产量增加2067.83辆;③由上表中â和βˆ的p值分别是0.709481543和6.60805E-15,显然â的p值大于显著性水平α=0.05,不能拒绝原假设α=0,而βˆ的p值远小于显著性水平α=0.05,拒绝原假设β=0,说明私人载客汽车拥有量对轿车生产量有显著影响。
(2)分析轿车生产量与城镇居民家庭恩格尔系数之间的关系:首先,求的因变量轿车生产量y和自变量城镇居民家庭恩格尔系数x2的相关系数r=-0.77499,说明两者间存在一定的线性相关关系但负相关程度一般。
然后以轿车生产量为因变量y,城镇居民家庭恩格尔系数x2为自变量进行一元线性回归分析,结果如下:由回归统计中的R=0.600608看出,所建立的回归模型对样本观测值的拟合程度一般,综合其相关系数值可知此二者关系不太符合所建立的线性模型,说明二者间没有密切的线性相关关系。
(3)分析轿车生产量与公路里程之间的关系:首先,求的因变量轿车生产量y和自变量公路里程x3的相关系数r=0.941214,说明两者间存在一定的线性相关关系且正相关程度较强。
然后以轿车生产量为因变量y,公路里程x3为自变量进行一元线性回归分析,结果如下:①由回归统计中的R=0.885883看出,所建立的回归模型对样本观测值的拟合程度较好;②估计出的样本回归函数为:ŷ=-125.156+1.403022x3,说明公路里程每增加1万公里,轿车生产量增加1.403022万辆;③由上表中â和βˆ的p值分别是5.64E-05和1.82E-08,显然â和βˆ的p 值均远小于显著性水平α=0.05,拒绝原假设α=0、β=0,但由于β对两者的影响更为显著,所以可以说明公路里程对轿车生产量有显著影响。
(4)分析轿车生产量与GDP之间的关系:首先,求的因变量轿车生产量y和自变量GDP x4的相关系数r=0.939995,说明两者间存在一定的线性相关关系且正相关程度较强。
然后以轿车生产量为因变量y,GDP x4为自变量进行一元线性回归分析,结果如下:①由回归统计中的R=0.88359看出,所建立的回归模型对样本观测值的拟合程度较好;②估计出的样本回归函数为:ŷ=-70.7127+0.001829x4,说明GDP每增加1亿元,轿车生产量增加18.29辆;③由上表中â和βˆ的p值分别是0.001534和2.11E-08,显然â和βˆ的p 值均小于显著性水平α=0.05,拒绝原假设α=0、β=0,但由于β对两者的影响更为显著,所以可以说明GDP对轿车生产量有较显著影响。
(5)分析轿车生产量与城镇居民人均可支配收入x5之间的关系:首先,求的因变量轿车生产量y和自变量城镇居民人均可支配收入x5的相关系数r=0.917695,说明两者间存在一定的线性相关关系且正相关程度较强。
然后以轿车生产量为因变量y,城镇居民人均可支配收入x5为自变量进行一元线性回归分析,结果如下:①由回归统计中的R=0.842164看出,所建立的回归模型对样本观测值的拟合程度较好;②估计出的样本回归函数为:ŷ=-92.9054+0.032928x5,说明城镇居民人均可支配收入每增加1元,轿车生产量增加329.28辆;③由上表中â和βˆ的p值分别是0.001444和2.12E-07,显然â和βˆ的p 值均小于显著性水平α=0.05,拒绝原假设α=0、β=0,但由于β对两者的影响更为显著,所以可以说明城镇居民人均可支配收入对轿车生产量有显著影响。
案例三:子女身高与父母身高的回归分析1、问题的提出早在19世纪后期,英国生物学家Galton通过观察1078个家庭中父亲、母亲身高的平均值x和其中一个成年儿子身高y,建立了关于父母身高与子女身高的线性方程:y=33.73+0.516x从方程可以看出,子女身高有回归平均的倾向。
那么,时隔一百多年后的今天,人类的物质生活和精神生活都已发生巨大的变化,父母身高与子女身高之间将呈现出什么样的关系呢?在现实生活中,我们都知道父母身高对子女身高是有影响的,但父亲与母亲的影响分别有多大?他们对儿子和女儿的影响程度是否相同?能否用定量的形式回答这个问题呢?如果可以利用回归方法,进一步揭示父亲身高、母亲身高与子女身高之间量化关系的秘密,将有助于那些关注自己后代身高的年轻父母们进行早期预测,同时也可为那些未婚青年男女在选择理想配偶时提供科学的参考依据。
2、数据的收集为了问题的研究,我们要求所调查的家庭满足下列条件:(1)家庭中有一个或多个子女(2)家庭成员身体健康,发育正常,无先天性和遗传性疾病,无残疾(3)子女的年龄均在23岁(含23岁)以上。
考虑到调查范围的广泛性,我们随机抽取了机关干部、职员、工人、农民、城市居民、军人、大学生家庭,并特意选择了一所全国招生的院校应届毕业生,他们来自于全国各地,家庭背景相对复杂,这样使得样本更具代表性。
在收回的410份(发放460份)调查表中,符合要求的有290个家庭,其中,有儿子405人,有女儿270人。
3、方法的确定根据所收集的数据,应用二元回归分析方法,研究父亲身高、母亲身高与儿子或女儿身高的关系。
(1)建立回归方程设X1为父亲身高,X2为母亲身高,Y为儿子或女儿身高。
则父母身高与子女身高的回归模型为:Y=β0+β1X1+β2X2+ε根据样本数据建立估计二元回归方程:yˆ=b0+b1x1+b2x2(2)显著性检验对回归方程进行F检验,拒绝区域为F﹥Fα(2,n-3);对回归系数进行t检验,拒绝区域为t﹥tα/2(n-3)。
(3)预测若某一家庭父亲和母亲身高分别为x10和x20,则子女身高的点估计为:yˆ=b0+b1x10+b2x20区间估计方法已超出大纲要求,在此不要求。
4、结果分析(1)父母身高对儿子身高的影响yˆ=53.640+0.368x1+0.349x2显著性检验:在α=0.01的显著水平下,F=62.714﹥Fα(2,400)=4.68t1=7.85﹥tα/2(400)=2.689t2=6.71﹥tα/2(400)=2.689结果说明回归方程显著,两个偏回归系数显著。
因此,所建立回归方程是有意义的,即父母身高与儿子身高有显著的线性关系。
(2)父母身高对女儿身高的影响yˆ=47.140+0.249x1+0.455x2显著性检验:在α=0.01的显著水平下,F=46.81﹥Fα(2,300)=4.68t1=4.92﹥tα/2(300)=2.68t2=7.61﹥tα/2(300)=2.689结果说明回归方程显著,回归系数显著,故所建立回归方程有效,即女儿身高与父母身高有显著的线性关系,特别是母亲身高对女儿身高的影响更为重要。
(3)从以上结果可以看出,在某种程度上,父母身高对子女身高有重要影响,且在不同时期,子女身高有回归平均身高的趋势,即个子矮的父母,其子女身高未必低于自己,个子高的父母,其子女身高未必高于自己。
下表给出了部分家庭子女身高的预测值,其中,区间估计的把握程度为95%。