正则表达式学习心得体会
- 格式:docx
- 大小:37.28 KB
- 文档页数:2
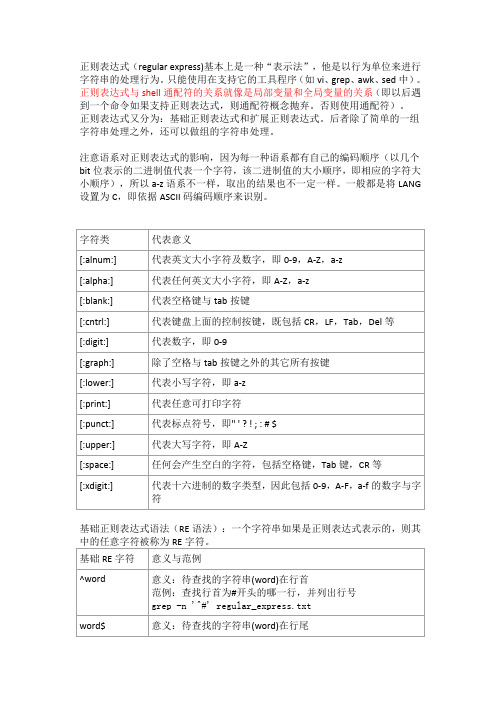
正则表达式(regular express)基本上是一种“表示法”,他是以行为单位来进行字符串的处理行为。
只能使用在支持它的工具程序(如vi、grep、awk、sed中)。
正则表达式与shell通配符的关系就像是局部变量和全局变量的关系(即以后遇到一个命令如果支持正则表达式,则通配符概念抛弃。
否则使用通配符)。
正则表达式又分为:基础正则表达式和扩展正则表达式。
后者除了简单的一组字符串处理之外,还可以做组的字符串处理。
注意语系对正则表达式的影响,因为每一种语系都有自己的编码顺序(以几个bit位表示的二进制值代表一个字符,该二进制值的大小顺序,即相应的字符大小顺序),所以a-z语系不一样,取出的结果也不一定一样。
一般都是将LANG 设置为C,即依据ASCII码编码顺序来识别。
基础正则表达式语法(RE语法):一个字符串如果是正则表达式表示的,则其扩展的正则表达式语法:(若要支持:grep需加-E (或者使用到扩展符号时加\)sed需加-r (或者使用到扩展符号时加\)awk,perl本身支持扩展这则表达式(也就是说awk中如果要引用(为普通字符重新引用成为可能,可以使用如\1,\2这样的反向引用来匹配圆括号中的字符串。
grep -E "(m)\1" 1.txtsed -n 's/\(ap.le\)/APPLE\1/gp' 1.txtsed -nr 's/(ap.le)/APPLE\1/gp' 1.txtsed -nr 's/((ap.le)(ap.le))/\1\2\3/p' 1.txt12 3注:如何区分那个括号是第几组?只要数左括号(包括嵌套的括号)的序号就可以了.元字符:是一种perl风格的正则表达式,只有一部分文本处理工具支持它,并不是所有的工具都支持。
正则表达式:如果输出不是自己想要的,一种较大的可能:正则表达式不正确编写正则表达式的四个步骤:1、知道要匹配的内容以及它如何出现在文本中;2、编写一个模式来描述要匹配的内容;3、测试模式来查看它匹配的内容;4、重复2,3步骤,直到得到正确的结果。

正则表达式学习总结引⾔⽤户消息,⼀般都有固定格式,利⽤正则匹配到想要的字段。
如⽤户字段:============================================================================================\n" + // "IP 地址 - ⼦⽹掩码 - 唯⼀的 ID - 租⽤过期 - 种类\n" +// "==================================================================================\n" +// "\n" +// "192.100.100.209 - 255.255.255.0 - 56-50-4d-98-00-02-00-2021/3/6 15:35:39 -D\n" +// "192.100.100.210 - 255.255.255.0 - 56-50-4d-98-00-02-00-2021/3/6 15:38:16 -D\n" +// "192.100.100.211 - 255.255.255.0 - 69-73-63-6f-20-53-79-2021/3/12 10:39:47 -D\n" +// "192.100.100.212 - 255.255.255.0 - 00-50-56-83-57-e3 -2021/3/12 10:42:40 -D\n" +// "192.100.100.213 - 255.255.255.0 - 00-50-56-a6-75-80 -2021/3/12 10:43:07 -D\n" +// "\n" +// "作⽤域 : 192.100.100.0 中的客户端数⽬(版本 4): 19。

正则表达式心得体会正则表达式是一种强大的文本处理工具,能够快速、灵活地匹配、查找或替换文本中的特定模式。
在我使用正则表达式的过程中,我深刻体会到了它的便捷性和实用性。
首先,正则表达式可以帮助我们在海量文本中快速准确地筛选出我们需要的信息。
比如,在一个由许多邮箱组成的文本文件中,如果我想要提取出所有包含特定域名的邮箱地址,使用正则表达式就可以非常轻松地实现这个目标。
只需要简单地构造一个符合特定域名格式的模式,并在文本中进行匹配,就能够很快地找到所需的邮箱地址。
其次,正则表达式还可以方便地进行文本替换。
当我们需要将一段文本中的某个特定字符或字符串进行替换时,使用正则表达式可以快速高效地实现这个功能。
无论是替换一个固定字符,还是替换模式匹配到的字符串,正则表达式都可以帮助我们快速完成任务。
比如,当我需要将一个HTML文档中的所有图片标签替换成相应的图片URL时,使用正则表达式可以轻松实现这一操作。
此外,正则表达式还可以帮助我们进行文本格式的校验和验证。
比如,在用户进行表单填写时,我们经常需要对用户输入的内容进行格式验证,确保输入的内容符合特定的规则。
使用正则表达式可以非常方便地实现这个功能。
我们只需要编写相应的表达式,然后对用户输入的内容进行匹配,就能够迅速判断输入是否合法。
无论是验证邮箱格式、手机号码格式还是身份证号码格式,正则表达式都可以帮助我们快速准确地完成。
另外,正则表达式还可以进行文本分割和提取。
在一些需要对文本进行进一步处理的场景中,我们常常需要将文本按照特定的分隔符进行分割,或者从文本中提取出特定的信息。
使用正则表达式可以轻松实现这个功能。
只需要编写相应的规则,然后对文本进行匹配,就能够快速地将文本进行分割或提取。
尽管正则表达式功能强大,但它的学习曲线也比较陡峭。
在我学习正则表达式的过程中,最常遇到的困难是理解语法规则和表达式的构造方式。
正则表达式使用一系列特殊字符和操作符来表示匹配的规则,初学者往往会感到晦涩难懂。

使用正则表达式优化代码处理效率正则表达式是一种用于匹配和处理文本的强大工具。
在编写代码时,使用正则表达式可以大大简化复杂的文本处理逻辑,并提高代码的执行效率。
1.提高代码简洁性:使用正则表达式可以将复杂的字符串匹配和替换操作转化为简洁的几行代码,使代码更易于读写和维护。
例如,使用正则表达式可以轻松地提取HTML标签中的内容,而不需要手动解析整个HTML文档。
2.加速字符串匹配:正则表达式引擎在内部使用高度优化的算法来加速字符串匹配操作。
相对于手动编写循环和条件判断的方式,使用正则表达式可以提供更高效的字符串搜索和匹配功能。
3.优化字符串替换:正则表达式提供了强大的字符串替换功能。
通过使用正则表达式,可以将多个替换操作合并为一个操作,从而提高代码的执行效率。
此外,正则表达式还支持使用回调函数进行替换,进一步扩展了代码处理能力。
4.灵活处理复杂模式:正则表达式支持使用元字符和特殊语法来表示复杂的匹配模式。
这使得我们可以灵活地处理各种复杂的需求,例如匹配邮箱地址、URL、日期等。
通过适当选择和组合元字符,我们可以轻松地满足多种不同的需求。
尽管正则表达式提供了这么多的优势,但是也存在一些需要注意的问题:1.性能问题:虽然正则表达式引擎在内部进行了优化,但复杂的正则表达式仍可能导致性能问题。
当正则表达式包含大量的字符和分组时,匹配速度可能会变慢。
因此,在编写正则表达式时需要注意避免使用过于复杂的模式。
2.可读性:由于正则表达式的语法较为复杂,使用复杂的正则表达式可能会降低代码的可读性。
为了提高代码的可维护性,应尽量避免过于复杂的正则表达式,或者使用注释和说明来解释其含义。
3.错误处理:由于正则表达式本身具有一定的复杂性,编写错误的正则表达式可能导致代码的执行出错。
因此,在使用正则表达式时需要仔细检查其语法和逻辑,避免潜在的错误。
综上所述,正则表达式是一种强大的工具,可以用于优化代码的处理效率。
然而,尽管正则表达式提供了很多优势,但仍需要注意性能、可读性和错误处理等问题。

正则表达式(正则表达式括号的作⽤)正则表达式之前学习的时候,因为很久没怎么⽤,或者⽤的时候直接找⽹上现成的,所以都基本忘的差不多了。
所以这篇⽂章即是笔记,也让⾃⼰再重新学习⼀遍正则表达式。
其实平时在操作⼀些字符串的时候,⽤正则的机会还是挺多的,之前没怎么重视正则,这是⼀个错误。
写完这篇⽂章后,发觉⼯作中很多地⽅都可以⽤到正则,⽽且⽤起来其实还是挺爽的。
正则表达式作⽤ 正则表达式,⼜称规则表达式,它可以通过⼀些设定的规则来匹配⼀些字符串,是⼀个强⼤的字符串匹配⼯具。
正则表达式⽅法基本语法,正则声明js中,正则的声明有两种⽅式1. 直接量语法:1var reg = /d+/g/2. 创建RegExp对象的语法1var reg = new RegExp("\\d+", "g");这两种声明⽅式其实还是有区别的,平时的话我⽐较喜欢第⼀种,⽅便⼀点,如果需要给正则表达式传递参数的话,那么只能⽤第⼆种创建RegExp的形式格式:var pattern = new RegExp('regexp','modifier');regexp:匹配的模式,也就是上⽂指的正则规则。
modifier: 正则实例的修饰符,可选值有:i : 表⽰区分⼤⼩写字母匹配。
m :表⽰多⾏匹配。
g : 表⽰全局匹配。
传参的形式如下:我们⽤构造函数来⽣成正则表达式1var re = new RegExp("^\\d+$","gim");这⾥需要注意,反斜杠需要转义,所以,直接声明量中的语法为\d,这⾥需要为\\d那么,给它加变量,就和我们前⾯写的给字符串加变量⼀样了。
1 2var v = "bl";var re =new RegExp("^\\d+" + v + "$","gim"); // re为/^\d+bl$/gim⽀持正则的STRING对象⽅法1. search ⽅法作⽤:该⽅法⽤于检索字符串中指定的⼦字符串,或检索与正则表达式相匹配的字符串基本语法:stringObject.search(regexp);返回值:该字符串中第⼀个与regexp对象相匹配的⼦串的起始位置。

正则表达式学习笔记(1)正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
列目录时,dir *.txt或ls *.txt中的*.txt就不是一个正则表达式,因为这里*与正则式的*的含义是不同的。
为便于理解和记忆,先从一些概念入手,所有特殊字符或字符组合有一个总表在后面,最后一些例子供理解相应的概念。
正则表达式是由普通字符(例如字符 a 到z)以及特殊字符(称为元字符)组成的文字模式。
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
可以通过在一对分隔符之间放入表达式模式的各种组件来构造一个正则表达式,即/expression/普通字符由所有那些未显式指定为元字符的打印和非打印字符组成。
这包括所有的大写和小写字母字符,所有数字,所有标点符号以及一些符号。
非打印字符特殊字符所谓特殊字符,就是一些有特殊含义的字符,如上面说的"*.txt"中的*,简单的说就是表示任何字符串的意思。
如果要查找文件名中有*的文件,则需要对*进行转义,即在其前加一个\。
ls \*.txt。
正则表达式有以下特殊字符。
构造正则表达式的方法和创建数学表达式的方法一样。
也就是用多种元字符与操作符将小的表达式结合在一起来创建更大的表达式。
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
限定符限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。
有*或+或?或{n}或{n,}或{n,m}共6种。
*、+和?限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
正则表达式的限定符有:定位符用来描述字符串或单词的边界,^和$分别指字符串的开始与结束,\b描述单词的前或后边界,\B表示非单词边界。
正则表达式心得体会正则表达式是一种功能强大的文本处理工具,它可以方便地查找、替换、验证字符串等操作。
在我的工作中,我经常使用正则表达式来处理各种数据,下面是我对正则表达式的一些心得体会。
首先,正则表达式的语法比较复杂,但一旦学会了,就可以大大提高工作效率。
我在学习正则表达式的过程中,发现最好的教材是《正则表达式必知必会》这本书,它详细地介绍了正则表达式的基本语法和常用功能,让我能够快速掌握这一工具。
其次,正则表达式的灵活性非常高,因为它可以使用不同的元字符来表示不同的字符或字符串。
例如,“.”可以匹配任意单个字符,“*”可以匹配任意多个字符,而“[ ]”可以用来匹配一组字符。
掌握了这些元字符,我们就可以根据具体情况选择合适的字符来搭配使用,从而达到最佳的效果。
另外,在处理复杂的文本时,我们还可以使用正则表达式的“分组”、“反向引用”等功能来处理不同的部分。
例如,在处理邮件地址时,我们可以使用“([a-zA-Z0-9._%+-]+)@([a-zA-Z0-9.-]+\.[a-zA-Z]{2,})”这一正则表达式来匹配邮件地址中的用户名和域名,从而更好地进行数据处理。
最后,我认为,正则表达式还需要配合实践来提高自己的技能水平。
我们可以通过练习、实践,不断优化自己的正则表达式,提升自己在数据处理方面的能力。
同时,在学习和使用正则表达式时,我们还需要注意规范编写格式,以便于维护和管理代码。
综上所述,正则表达式是一种非常实用的工具,可以帮助我们在处理文本数据时提高效率和准确性。
我们需要不断学习、掌握和实践,才能更好地利用它来解决实际问题。
使用正则表达式进行文本处理的技巧与方法正则表达式是一种强大的文本处理工具,它可以帮助我们快速有效地处理各种文本数据。
无论是在编程领域还是数据分析领域,正则表达式都是一项必备技能。
本文将介绍一些使用正则表达式进行文本处理的技巧与方法。
一、了解正则表达式的基本语法正则表达式是一种用于匹配、查找和替换文本的模式。
在使用正则表达式之前,我们需要了解一些基本的语法规则。
例如,使用"."表示匹配任意字符,使用"*"表示匹配前面的字符任意次数,使用"^"表示匹配字符串的开头,使用"$"表示匹配字符串的结尾等等。
二、使用正则表达式进行字符串匹配正则表达式最常见的用途之一就是进行字符串匹配。
我们可以使用正则表达式来判断一个字符串是否符合某种模式。
例如,我们可以使用正则表达式匹配一个邮箱地址,判断一个字符串是否是有效的手机号码等等。
三、使用正则表达式进行文本提取除了字符串匹配,正则表达式还可以用于提取文本中的特定内容。
例如,我们可以使用正则表达式提取一个网页中的所有链接,提取一段文本中的所有日期等等。
通过灵活运用正则表达式,我们可以快速高效地从大量文本数据中提取所需信息。
四、使用正则表达式进行文本替换正则表达式不仅可以用于匹配和提取文本,还可以用于替换文本中的特定内容。
例如,我们可以使用正则表达式将一段文本中的所有数字替换为"#",将一段文本中的所有空格替换为下划线等等。
通过使用正则表达式进行文本替换,我们可以快速完成一些批量处理的任务。
五、使用正则表达式进行文本分割有时候,我们需要将一段文本按照特定的规则进行分割。
正则表达式可以帮助我们实现这一目标。
例如,我们可以使用正则表达式将一个长句子分割为多个短句,将一个文本文件按照空行进行分割等等。
通过使用正则表达式进行文本分割,我们可以更好地组织和处理文本数据。
六、使用正则表达式进行文本格式化正则表达式还可以用于对文本进行格式化。
Python正则表达式总结正则表达式练习:1、匹配⼀⾏⽂字中的所有开头的字母内容import res = "I love you not because of who you are, but because of who i am when i am with you"content = re.findall(r'\b\w', s)print(content)['I', 'l', 'y', 'n', 'b', 'o', 'w', 'y', 'a', 'b', 'b', 'o', 'w', 'i', 'a', 'w', 'i', 'a', 'w', 'y']2、匹配⼀⾏⽂字中的最后的数字内容import res = "I love you not because 12sd 34er 56df e4 54434"content = re.findall(r'\d\b', s)print(content)['4', '4']3、匹配⼀⾏⽂字中的所有开头的数字内容import reprint(re.match(r'\w+', '123sdf').group())123sdf4、只匹配包含字母和数字的⾏import res = "i love you not because\n12sd 34er 56\ndf e4 54434"content = re.findall(r'\w\d', s, re.M)print(content)['12', '34', '56', 'e4', '54', '43']5、写⼀个正则表达式,使其能同时识别下⾯所有的字符串:'bat', 'bit', 'but', 'hat', 'hit', 'hut‘import res = "'bat', 'bit', 'but', 'hat', 'hit', 'hut"content = re.findall(r'..t', s)print(content)['bat', 'bit', 'but', 'hat', 'hit', 'hut']6、匹配所有合法的python标识符import res = "awoeur awier !@# @#4_-asdf3$^&()+?><dfg$\n$"content = re.findall(r'.*', s, re.DOTALL)print(content)['awoeur awier !@# @#4_-asdf3$^&()+?><dfg$\n$', '']7、提取每⾏中完整的年⽉⽇和时间字段import res = """se234 1987-02-09 07:30:001987-02-10 07:25:00"""content = re.findall(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', s, re.M)print(content)['1987-02-09 07:30:00', '1987-02-10 07:25:00']8、使⽤正则表达式匹配合法的邮件地址:import res = """xiasd@, sdlfkj@.com sdflkj@ solodfdsf@ sdlfjxiaori@ oisdfo@""" content = re.findall(r'\w+@\w+.com', s)print(content)['xiasd@', 'sdflkj@', 'solodfdsf@', 'sdlfjxiaori@']9、将每⾏中的电⼦邮件地址替换为你⾃⼰的电⼦邮件地址import res = """693152032@, werksdf@, sdf@sfjsdf@, soifsdfj@pwoeir423@"""content = re.sub(r'\w+@\w+.com', '1425868653@', s)print(content)1425868653@, 1425868653@, 1425868653@1425868653@, 1425868653@1425868653@10、匹配\home关键字:import reprint(re.findall(r'\\home', "skjdfoijower \home \homewer"))['\\home', '\\home']11、使⽤正则提取出字符串中的单词import res = """i love you not because of who 234 you are, 234 but 3234ser because of who i am when i am with you"""content = re.findall(r'\b[a-zA-Z]+\b', s)print(content)['i', 'love', 'you', 'not', 'because', 'of', 'who', 'you', 'are', 'but', 'because', 'of', 'who', 'i', 'am', 'when', 'i', 'am', 'with', 'you']摘抄供参考学习:校验数字的表达式1. 数字:^[0-9]*$2. n位的数字:^\d{n}$3. ⾄少n位的数字:^\d{n,}$4. m-n位的数字:^\d{m,n}$5. 零和⾮零开头的数字:^(0|[1-9][0-9]*)$6. ⾮零开头的最多带两位⼩数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$7. 带1-2位⼩数的正数或负数:^(\-)?\d+(\.\d{1,2})?$8. 正数、负数、和⼩数:^(\-|\+)?\d+(\.\d+)?$9. 有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$10. 有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$11. ⾮零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$12. ⾮零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$13. ⾮负整数:^\d+$ 或 ^[1-9]\d*|0$14. ⾮正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$15. ⾮负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$16. ⾮正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$17. 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$18. 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$19. 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$校验字符的表达式1. 汉字:^[\u4e00-\u9fa5]{0,}$2. 英⽂和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$3. 长度为3-20的所有字符:^.{3,20}$4. 由26个英⽂字母组成的字符串:^[A-Za-z]+$5. 由26个⼤写英⽂字母组成的字符串:^[A-Z]+$6. 由26个⼩写英⽂字母组成的字符串:^[a-z]+$7. 由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$8. 由数字、26个英⽂字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$9. 中⽂、英⽂、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$10. 中⽂、英⽂、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$11. 可以输⼊含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+ 12 禁⽌输⼊含有~的字符:[^~\x22]+特殊需求表达式1. Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2. 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?4. ⼿机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5. 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6. 国内电话号码(0511-*******、021-********):\d{3}-\d{8}|\d{4}-\d{7}7. ⾝份证号(15位、18位数字):^\d{15}|\d{18}$8. 短⾝份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9. 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10. 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11. 强密码(必须包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12. ⽇期格式:^\d{4}-\d{1,2}-\d{1,2}13. ⼀年的12个⽉(01~09和1~12):^(0?[1-9]|1[0-2])$14. ⼀个⽉的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15. 钱的输⼊格式:16. 1.有四种钱的表⽰形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$17. 2.这表⽰任意⼀个不以0开头的数字,但是,这也意味着⼀个字符"0"不通过,所以我们采⽤下⾯的形式:^(0|[1-9][0-9]*)$18. 3.⼀个0或者⼀个不以0开头的数字.我们还可以允许开头有⼀个负号:^(0|-?[1-9][0-9]*)$19. 4.这表⽰⼀个0或者⼀个可能为负的开头不为0的数字.让⽤户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下⾯我们要加的是说明可能的⼩数部分:^[0-9]+(.[0-9]+)?$20. 5.必须说明的是,⼩数点后⾯⾄少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$21. 6.这样我们规定⼩数点后⾯必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$22. 7.这样就允许⽤户只写⼀位⼩数.下⾯我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$23 8.1到3个数字,后⾯跟着任意个逗号+3个数字,逗号成为可选,⽽不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$24. 备注:这就是最终结果了,别忘了"+"可以⽤"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在⽤函数时去掉去掉那个反斜杠,⼀般的错误都在这⾥25. xml⽂件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$26. 中⽂字符的正则表达式:[\u4e00-\u9fa5]27. 双字节字符:[^\x00-\xff] (包括汉字在内,可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1))28. 空⽩⾏的正则表达式:\n\s*\r (可以⽤来删除空⽩⾏)29. HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (仅仅能匹配部分,对于复杂的嵌套标记⽆能为⼒)30. ⾸尾空⽩字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式)31. 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)32. 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)33. IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有⽤)34. IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))。
正则表达式学习心得体会
正则表达式(Regular Expression)是一种强大的文本处理工具,用于在字符串中匹配、查找、替换和提取特定的模式。
在学习和使用正则表达式时,我深刻体会到了它的灵活性和效率,下面是我的心得体会。
首先,正则表达式具有很强的灵活性。
它可以通过使用特定的语法规则来描述和匹配字符串中的各种模式,从而实现精确的匹配和搜索。
例如,通过使用元字符和限定符,可以指定模式的匹配次数和位置,如使用星号*表示模式出现0次或多次,
加号+表示模式出现1次或多次,问号?表示模式出现0次或1次,花括号{}表示模式出现指定次数等。
通过这些灵活的匹配规则,可以根据具体需求对字符串进行精确的处理。
其次,正则表达式具有很高的效率。
由于正则表达式是通过编译成为内部的状态机来实现匹配的,相对于遍历字符串的方法,其处理速度更快。
例如,如果要查找字符串中的手机号码,可以使用正则表达式`^1[3-9]\d{9}$`进行匹配,这个正则表达式
在查找时可以直接跳过不满足条件的部分,提高了查找的效率。
而如果使用遍历字符串的方法,需要逐个字符进行比较和判断,处理速度较慢。
因此,在需要处理大量字符串的任务中,使用正则表达式可以大大提高处理效率。
另外,正则表达式在文本处理方面有着广泛的应用。
无论是在搜索引擎中对网页进行关键词匹配,还是在编辑器中对代码进行搜索和替换,亦或是在日志分析中提取特定的信息,都可以使用正则表达式来方便地实现。
正则表达式可以处理的模式非
常多,例如匹配数字、字母、特殊字符,匹配日期、邮箱、URL等常见的模式,还可以进行分组匹配、反向引用、前后
查找等高级操作,满足了各种各样的文本处理需求。
此外,学习正则表达式还需要进行练习和实践。
和其他编程语言一样,正则表达式的学习也需要通过实际的练习来掌握。
只有在不断的实践中,才能熟悉各种常用的元字符和限定符,掌握灵活运用的技巧。
可以通过编写小型的程序或使用正则表达式在线验证工具进行练习。
同时,阅读正则表达式的相关文档和书籍,了解其详细的语法规则和用法,也能够帮助更好地理解和掌握。
总结起来,正则表达式是一种非常强大的文本处理工具,具有灵活性和高效性。
学习和掌握正则表达式需要不断进行练习和实践,在实际的应用中结合具体的需求进行匹配和处理。
只有通过不断的实践和积累,才能真正掌握正则表达式的使用技巧,提高文本处理的效率。
相信在今后的学习和工作中,正则表达式会成为我处理字符串和文本的得力助手。