Web日志挖掘最新
- 格式:ppt
- 大小:255.50 KB
- 文档页数:19




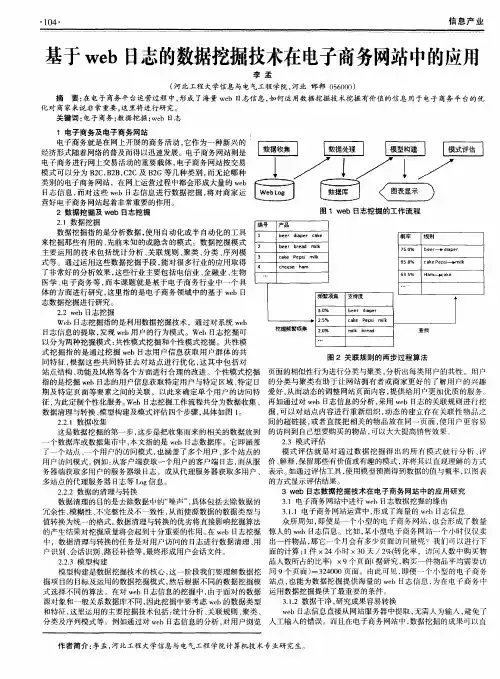
web数据挖掘的处理流程对web数据的处理可以分为数据获取、数据预处理、数据的转换集成、知识发现和模式分析几个过程,如图6-2所示。
(1) web数据的获取Web数据的来源包括:log日志,记录了用户的访问页面、时间、IP地址等主要信息;web内容,用户所浏览的文字、图片等;用户注册信息,web站点采集的用户输入的自身信息;web结构数据,指web本身在频道、链接上的布局。
Web数据的获取方法有:a) 服务器端信息。
web服务器端产生3种类型的日志文件:Server logs,Error logs,Cookie logs,这些日志记录了用户访问的基本情况,是Web使用挖掘中最重要的数据来源。
服务器日志(Server logs)记录了多个用户对单个站点的用户访问行为。
错误日志(Error log)记录存取请求失败的数据。
Cookie logs用于识别用户和用户会话。
b) 客户端的数据收集。
用户客户端log记录了该用户对各个网站的访问情况,比服务器端Log数据更能准确地反映用户的访问行为,但由于隐私保护,需要用户同意才能获得。
c) 代理服务器端的数据收集。
代理端log数据记载了通过该代理进入Internet 的所有用户对各个网站的访问行为。
但是由于Cache的大量存在,使得代理服务器中的log数据不能准确地确定用户和时间,采集信息也不全面[50]。
(2) web数据的预处理Web数据的预处理包含数据清洗、用户识别、会话识别和事务识别等过程。
a) web数据的清洗数据的清洗,是指删除Web日志中与挖掘任务无关的数据。
将有用的web 日志记录转换为适当的数据格式,同时对用户请求页面时发生错误的记录进行适当处理。
在web日志中,包含许多对挖掘任务毫无意义的数据。
数据清洗的目标是消除冗余数据,方便于数据分析。
常见的数据清洗方法包括:删除日志文件中后缀为gif, jpg, jpeg的自动下载项;删除访问返回错误记录等。




M oder n sci ence6今日科苑科苑论坛K E Y U A N LU N TA N摘要:互联网发展到今天已经成为了人们生活中不可缺少的一部分了,而互联网从某种意义上讲也可以看作是一个庞大的数据库,并且涉及到各个领域。
那么在这个庞大的数据库中,数据挖掘技术有什么用武之地呢?本文通过对互联网上数据挖掘的简单论述,说明现在互联网上数据挖掘的一些趋势和相关技术,并且着重分析一下其中一种互联网上数据挖掘的应用方向相关的技术——W eb 使用记录的挖掘。
关键词:w eb 数据挖掘;W eb 日志;数据预处理一、引言目前,互联网已经和我们的生活密不可分,它可以说是一个巨大的、分布广泛和全球性的信息服务中心。
它涉及新闻、广告、消息信息、金融信息、教育、政府、电子商务和许多其他信息服务。
根据有关机构统计,目前互联网的数据以几百兆字节来计算,而且增长速度很快,如果将这个庞大的数据库用一般的统计分析来处理的话,显然是有心无力的。
自从数据挖掘技术成功地应用于传统数据库领域之后,人们对于数据挖掘在像互联网数据这样的一些特殊数据源的应用也寄予了厚望,并且做了许多相应的研究和发展了相应的技术。
将数据挖掘技术应用到互联网数据上,理论上可行,但是由于互联网自身的特点,也使它面临一些需要克服的技术难点。
可以说,在互联网上应用数据挖掘技术的前途是光明的,但道路也是曲折的。
目前互联网上的数据挖掘技术主要根据挖掘的方向一般分为三类:W eb 内容挖掘,W eb 结构挖掘和W eb 使用记录的挖掘。
而结构本来就蕴藏在内容中,是内容的骨,因此有些分类方法又分为W eb 内容挖掘和W eb 使用记录挖掘。
这里按照后一种分类方法来看一下目前的相关技术和应用。
二、技术(一)W eb 日志目前市面上比较流行的W eb 服务器,例如I I S 通常都保存了对W eb 页面的每一次访问的日志项。
它忠实地记录了访问该W eb 服务器的数据流的信息。

Web日志挖掘技术在电子商务网站中的应用
董立凯;曲守宁
【期刊名称】《济南大学学报(自然科学版)》
【年(卷),期】2008(022)003
【摘要】在电子商务网站中,根据客户的访问日志挖掘出有价值的信息,划分客户群体和发现潜在的客户,使网站可以提供个性化信息服务.Web日志挖掘是数据挖掘在Web页面上的应用,给出Web日志挖掘的步骤和方法,对Web日志挖掘工具进行分析,并应用到电子商务网站中,取得较好的效果.
【总页数】4页(P251-254)
【作者】董立凯;曲守宁
【作者单位】济南大学,信息科学与工程学院,山东,济南,250022;济南大学,信息科学与工程学院,山东,济南,250022
【正文语种】中文
【中图分类】TP311.13
【相关文献】
1.Web日志挖掘在中小型电子商务网站中的应用探析 [J], 顾黎萍;胡芳
2.Web日志挖掘技术在电子商务网站中的应用 [J], 董立凯;曲守宁
3.Web日志挖掘技术在校园网信息处理中的应用研究 [J], 张琳
4.Web日志挖掘技术在电子商务网站优化中的应用 [J], 裴大容
5.基于web日志的数据挖掘技术在电子商务网站中的应用 [J], 李孟
因版权原因,仅展示原文概要,查看原文内容请购买。

自适应遗传模拟退火的Web日志关联挖掘摘要:提出一种基于自适应遗传模拟退火策略的Web日志关联规则挖掘算法。
该算法在遗传模拟退火策略基础上,引入自适应的交叉概率和变异概率,使其具有较强的全局搜索能力,有效地避免了早熟的现象。
实验结果证明,该算法能有效地解决Web日志关联规则挖掘问题。
关键词:关联规则;遗传算法;模拟退火算法;Web挖掘;自适应1关联规则挖掘模型在关联规则系统中,规则本身是“如果条件怎么样、怎么样,那么结果或者情况就怎么样”的形式。
可表示为“A B联A前件可以包括一个或多个条件,在某个给定的正确率中,要使后件为真,前件中的所有条件必须同时为真。
后件一般只包括一种情况。
如:购买计算机有购买财务软件趋向的关联规则、年龄在30至40岁之间并且年收入在4200元至5000元之间的客户购买高清晰度彩色电视机趋向的关联规则可分别表示为:buy(x,″computer)buy(x,″finacial_management_software″)age(″30…40″)∧income(″4200…5000″) buy(x,″high_resolution_tv″)数据项集合A B策属性和任务属性。
通过对问题的分析,可以发现,决策属性相互间是无序的。
因此可以将决策属性一次性排定顺序组成属性串,且在挖掘过程中不变其顺序。
为了便于问题的分析,作以下形式定义。
定义1( Web事务。
)在事务文件中出现的所有页面集合表示为P={p1,p2,…,pn}。
其中每个页面pi(i=1,2,…,n)通过其URL一表示。
事务集合U表示为U={u1,u2,…,un},每个事务ui={i=1,2,…,m}均为页面集合P的子集定义2 (页面权值。
)假定将用户访问页面的平均停留时间作为该页面的权值。
整个事务的权值为weight(uk)=∑[DD(]|uk|[]i=1[DD)]w(pI,uk)/|uk|。
定义3 (向量空间。
)事务集合中的每一个事务ui(i=1,2,…,m)可以转换为页面空间上的n维向量,u=<w(p1,u),w(p2,u),…,w(pn,u)。
Web日志挖掘在网站优化中的应用摘要:网站成为互联网信息的主要来源。
由站点主体提出需求,设计者规划实现,站点结构和网页布局按照需求设计为固定模式,用户必须按照这种模式对网站进行浏览。
提出了对用户访问站点的行为进行挖掘来改进站点设计和布局,达到方便用户访问站点和实现客户个性化服务的目的。
关键词:Web挖掘;Web日志;网站优化;关联性分析;聚类分析0 引言WWW是全球最大、最方便的信息来源,积聚了海量信息,成为人们工作、学习的最大支持平台。
众多网站每天需要搜集和处理大量的数据,积累大量的数据,数据量呈指数级增长,这些浩瀚信息往往隐藏了许多重要的信息。
面对海量数据,人们往往无所适从,无法快速地找到自己想要的信息或有潜在价值的知识。
为了解决上述问题,本人提出了一种有效解决的方法:通过挖掘用户访问站点的日志构建或优化站点。
Web服务器日志记录了Web 服务器请求以及运行状态的各种原始信息,记录了关于用户访问和交互的信息,对其挖掘的主要目标则是从访问记录中提取用户感兴趣的知识。
1 网站优化服务模型一个较为成功的站点,一定是保持较高回头率和较长客户驻留时间的站点,针对这一特征,除了站点信息的自身质量外,要解决的问题主要是站点和页面的合理布局问题,这正如超市商品摆设一样,摆放在一起有助于销售。
利用关联规则发现有用的客户,动态调整站点的结构,使客户访问的有关联文件间的链接能够比较直接,让客户更容易访问到想访问的页面。
根据用户访问习惯,将页面信息合理地呈现眼前也是站点优化任务之一,这正如顾客经常进入同一商场购买常买的商品一样,购买行为给他可能有两种感觉一样:方便和不方便,对于他来说要是他常买的商品摆放在商场入口将会给他的购买活动带来很大的方便。
利用聚类分析将众多的访问行为分类,最大可能呈现给用户的是用户常用的信息。
假设用户访问样本集W={w1,w2,…,wK},wi为用户的访问行为。
样本数据预处理的目的是标准化数据、清除垃圾数据,删除与挖掘无关的样本属性内容。