多重共线性案例
- 格式:docx
- 大小:18.50 KB
- 文档页数:5

解决多重共线性实例天津市1974-1987年与粮食销售量有关的影响因素如下表。
建立粮食销售量模型。
年份 Y2X 3X 4X 5X 6X 1974 98.45 560.20 153.20 6.53 1.23 1.89 1975 100.70 603.11 190.00 9.12 1.30 2.03 … … … … … … … 1987 178.69 828.73 1094.67 23.53 11.68 23.37天津统计年鉴(1988)其中:Y 是粮食销售量(万吨);2X 常住人口(万人); 3X 人均收入(元); 4X 肉类销售量(万吨); 5X 蛋类销售量(万吨); 6X 鱼虾销售量(万吨); 一、初步模型及存在的问题多元线性回归模型估计结果如下:65432491445336782073670125305003X X X X X Y......ˆ-++++-=(2.119)(1.945)(2.130)(1.409)(-2.028) 970402.=R 5352.=F7205.ˆ=σ9731.=DW 方程中可决系数2R 和F 统计量很大,但t 统计量较小。
临界值30626140250.)(t .=-,所有参数估计值都不能通过显著性检验。
这是存在多重共线性的典型特征。
如果利用相关系数检验法,可以得到各解释变量之间的相关系数分别为8666023.=r 8823024.=r 8524025.=r 8213026.=r 9459034.=r 9648035.=r 9825036.=r 9405045.=r 9484046.=r 9820056.=r 可见任何两个解释变量之间都有很强的正线性相关关系。
因此样本存在严重的多重共线性。
二、模型的修正由以上结果表明,任何一个解释变量与被解释变量之间的关系都是显著的。
从经济意义角度来看,人口数和人均收入应该构成影响粮食销售量的主要因素,因此建模时常住人口数X和人均收入3X应作为基本解释2变量予以保留。

实验五 多重共线性检验实验时间: 姓名:学号: 成绩:【实验目的】1、掌握多元线性回归模型的估计、检验和预测;2、掌握多重共线性问题的检验方法3、掌握多重共线性问题的修正方法 【实验内容】1、数据的读取和编辑;2、多元回归模型的估计、检验、预测;3、多重共线性问题的检验4、多重共线性问题的修正 【实验背景】为了评价报账最低工资(负收入税)政策的可行性,兰德公司进行了一项研究,以评价劳动供给(平均工作小时数)对小时工资提高的反应,词研究中的数据取自6000户男户主收入低于15000美元的一个国民样本,这些数据分成39个人口组,并放在表1中,由于4个人口组中的某些变量确实,所以只给出了35个组的数据,用于分析的各个变量的定义如下:Y 表示该年度平均工作小时数;X1表示平均小时工资(美元);X2表示配偶平均收入(美元);X3表示其他家庭成员的平均收入(美元);X4表示年均非劳动收入(美元);X5表示平均家庭资产拥有量;X6表示被调查者的平均年龄;X7表示平均赡养人数;X 8表示平均受教育年限。
μ为随机干扰项,考虑一下回归模型:μβββββββββ+++++++++=87654321876543210X X X X X X X X Y (1) 将该年度平均工作小时数Y 对X 进行回归,并对模型进行简单分析; (2) 计算各变量之间的相关系数矩阵,利用相关系数法分析变量间是否具有多重共线性;(3) 利用逐步回归方法检验并修正回归模型,最后再对模型进行经济意义检验、统计检验。
表5观测组Y X1 X2 X3 X4 X5 X6 X7 X81 2157 2.905 1121 291 380 7250 38.5 2.34 10.52 2174 2.97 1128 301 398 7744 39.3 2.335 10.53 2062 2.35 1214 326 185 3068 40.1 2.851 8.94 2111 2.511 1203 49 117 1632 22.4 1.159 11.55 2134 2.791 1013 594 730 1271057.7 1.229 8.86 2185 3.04 1135 287 382 776 38.6 2.602 10.77 2210 3.222 1100 295 474 9338 39 2.187 1128 2105 2.495 1180 310 255 4730 39.9 2.616 9.39 2267 2.838 1298 252 431 8317 38.9 2.024 11.110 2205 2.356 885 264 373 6489 38.8 2.662 9.511 2121 2.922 1251 328 312 5907 39.8 2.287 10.312 2109 2.499 1207 347 271 5069 39.7 3.193 8.913 2108 2.796 1036 300 259 4614 38.2 2.4 9.214 2047 2.453 1213 397 139 1987 40.3 2.545 9.115 2174 3.582 1141 414 498 1023940 2.064 11.716 2067 2.909 1805 290 239 4439 39.1 2.301 10.517 2159 2.511 1075 289 308 5621 39.3 2.486 9.518 2257 2.516 1093 176 392 7293 37.9 2.042 10.119 1985 1.423 553 381 146 1866 40.6 3.833 6.620 2184 3.636 1091 291 560 1124039.1 2.328 11.621 2084 2.983 1327 331 296 5653 39.8 2.208 10.222 2051 2.573 1197 279 172 2806 40 2.362 9.123 2127 3.263 1226 314 408 8042 39.5 2.259 10.824 2102 3.234 1188 414 352 7557 39.8 2.019 10.725 2098 2.28 973 364 272 4400 40.6 2.661 8.426 2042 2.304 1085 328 140 1739 41.8 2.444 8.227 2181 2.912 1072 304 383 9340 39 2.337 10.228 2186 3.015 1122 30 352 7292 37.2 2.046 10.929 2188 3.01 990 366 374 7325 38.4 2.847 10.630 2077 1.901 350 209 95 1370 37.4 4.158 8.231 2196 3.009 947 294 342 6888 37.5 3.047 10.632 2093 1.899 342 311 120 1425 37.5 4.512 8.133 2173 2.959 1116 296 387 7625 39.2 2.342 10.534 2179 2.959 1116 296 387 7625 39.2 2.342 10.535 2200 2.98 1126 204 393 7885 39.2 2.341 10.6 【实验过程】一、利用Evie ws软件建立年度平均工作小时数y的回归模型。

《多重共线性案例分析》实验报告表2由此可见,该模型,可决系数很高,F 检验值173.3525,明显显著。
但是当时,不仅、系数的t 检验不显著,而且系数的符号与预期的相反,这表明很可能存在严重的多重共线性。
9954.02=R 9897.02=R 05.0=α776.2)610()(025.02=-=-t k n t α2X 6X 6X②.计算各解释变量的相关系数,选择X2、X3、X4、X5、X6数据,点”view/correlations ”得相关系数矩阵表3由关系数矩阵可以看出:各解释变量相互之间的相关系数较高,证实确实存在严重多重共线性相。
4.消除多重共线性①采用逐步回归的办法,去检验和解决多重共线性问题。
分别作Y 对X2、X3、X4、X5、X6的一元回归 如下图所示变量 X2 X3 X4 X5 X6 参数估计值0.08429.0523 11.6673 34.3324 2014.146 t 统计量8.665913.1598 5.1967 6.4675 8.74870.90370.95580.77150.83940.9054表4 按的大小排序为:X3、X6、X2、X5、X4。
以X3为基础,顺次加入其他变量逐步回归。
首先加入X6回归结果为:t=(2.9086) (0.46214)2R 2R 631784.285850632.7639.4109ˆX X Y t ++-=957152.02=R1995 1375.7 62900 464.0 61.5 115.70 5.97 1996 1638.4 63900 534.1 70.5 118.58 6.49 1997 2112.7 64400 599.8 145.7 122.64 6.60 1998 2391.2 69450 607.0 197.0 127.85 6.64 1999 2831.9 71900 614.8 249.5 135.17 6.74 2000 3175.5 74400 678.6 226.6 140.27 6.87 2001 3522.4 78400 708.3 212.7 169.80 7.01 2002 3878.4 87800 739.7 209.1 176.52 7.19 2003 3442.3 87000 684.9 200.0 180.98 7.30表1:1994年—2003年中国游旅收入及相关数据表2:OLS 回归表3:关系数矩阵变量 X2 X3 X4 X5 X6 参数估计值0.08429.0523 11.6673 34.3324 2014.146 t 统计量8.665913.1598 5.1967 6.4675 8.74870.90370.95580.77150.83940.9054表4:Y 对X2、X3、X4、X5、X6的一元回归六、实验结果及分析1. 在参数估计模型和关系数矩阵中, ,可决系数很高,F 检验值173.3525,明显显著。
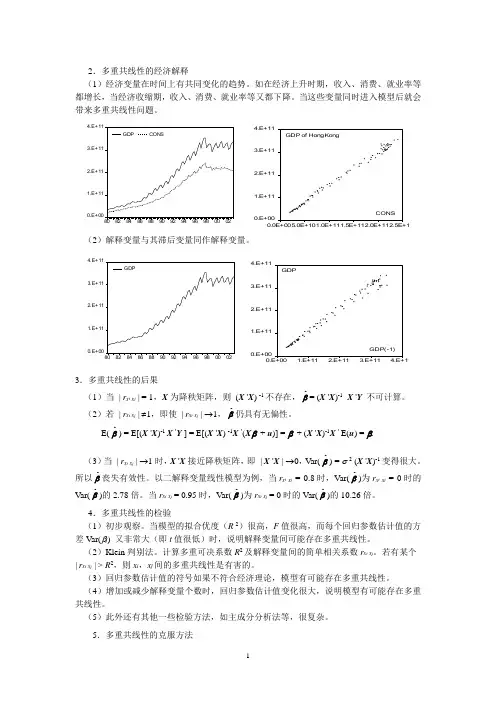
2.多重共线性的经济解释(1)经济变量在时间上有共同变化的趋势。
如在经济上升时期,收入、消费、就业率等都增长,当经济收缩期,收入、消费、就业率等又都下降。
当这些变量同时进入模型后就会带来多重共线性问题。
0.E+001.E+112.E+113.E+114.E+11808284868890929496980002GDPCONS0.E+001.E+112.E+113.E+114.E+110.0E+005.0E+101.0E+111.5E+112.0E+112.5E+11CONSGDP of HongKong(2)解释变量与其滞后变量同作解释变量。
0.E+001.E+112.E+113.E+114.E+11808284868890929496980002GDP0.E+001.E+112.E+113.E+114.E+110.E+001.E+112.E+113.E+114.E+11GDP(-1)GDP3.多重共线性的后果(1)当 | r x i x j | = 1,X 为降秩矩阵,则 (X 'X ) -1不存在,βˆ= (X 'X )-1 X 'Y 不可计算。
(2)若 | r x i x j | ≠1,即使 | r x i x j | →1,βˆ仍具有无偏性。
E(βˆ) = E[(X 'X )-1 X 'Y ] = E[(X 'X ) -1X '(X β + u )] = β + (X 'X )-1X ' E(u ) = β. (3)当 | r x i x j | →1时,X 'X 接近降秩矩阵,即 | X 'X | →0,V ar(βˆ) = σ 2 (X 'X )-1变得很大。
所以βˆ丧失有效性。
以二解释变量线性模型为例,当r x i x j = 0.8时,Var(βˆ)为r x i x j = 0时的Var(βˆ)的2.78倍。


理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。
为此,收集了中国能源消费总量Y (万吨标准煤)、国民总收入(亿元)X1(代表收入水平)、国内生产总值(亿元)X2(代表经济发展水平)、工业增加值(亿元)X3、建筑业增加值(亿元)X4、交通运输邮电业增加值(亿元)X5(代表产业发展水平及产业结构)、人均生活电力消费(千瓦小时)X6(代表人民生活水平提高)、能源加工转换效率(%)X7(代表能源转换技术)等在1985-2007年期间的统计数据,具体如表4.2所示。
表4.12 1985~2007年统计数据资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。
要求:1)建立对数多元线性回归模型,分析回归结果。
2)如果决定用表中全部变量作为解释变量,你预料会遇到多重共线性的问题吗?为什么?3)如果有多重共线性,你准备怎样解决这个问题?明确你的假设并说明全部计算。
参考解答:(1)建立对数线性多元回归模型,引入全部变量建立对数线性多元回归模型如下:生成: lny=log(y), 同样方法生成: lnx1,lnx2,lnx3,lnx4,lnx5,lnx6,lnx7.作全部变量对数线性多元回归,结果为:从修正的可决系数和F统计量可以看出,全部变量对数线性多元回归整体对样本拟合很好,,各变量联合起来对能源消费影响显著。
可是其中的lnX3、lnX4、lnX6对lnY影响不显著,而且lnX2、lnX5的参数为负值,在经济意义上不合理。
所以这样的回归结果并不理想。
(2) 预料此回归模型会遇到多重共线性问题, 因为国民总收入与GDP本来就是一对关联指标;而工业增加值、建筑业增加值、交通运输邮电业增加值则是GDP的组成部分。
这两组指标必定存在高度相关。
解释变量国民总收入(亿元)X1(代表收入水平)、国内生产总值(亿元)X2(代表经济发展水平)、工业增加值(亿元)X3、建筑业增加值(亿元)X4、交通运输邮电业增加值(亿元)X5(代表产业发展水平及产业结构)、人均生活电力消费(千瓦小时)X6(代表人民生活水平提高)、能源加工转换效率(%)X7(代表能源转换技术)等很可能线性相关,计算相关系数如下:可以看出lnx1与lnx2、lnx3、lnx4、lnx5、lnx6之间高度相关,许多相关系数高于0.900以上。



影响贵州省旅游业收入的分析-----多重共线性问题的处理案例一.问题的提出近年来,由于中国经济的稳定高速增长,人们的消费水平和收入水平逐步提高,可支配人均收入的增加使得人们有更多的机会和经济基础出门旅游。
因此旅游业的发展逐渐成为一个重要的产业,所以,有必要对影响旅游业发展的因素进行分析,抓住主要因素更好的发展旅游业。
贵州省地处西南,旅游线路和资源相当丰富。
但是,经济却处于欠发达状态,如何有效地开发利用旅游资源发展旅游产业将对贵州经济增长是值得深入研究的问题。
众所周知,推动贵州旅游业发展的因素众多,如交通运输条件的改善、信息技术的发展、居民收入水平的提高等。
2008年,贵州省旅游总收入创下了653.13亿元的好成绩,较2007年净增140亿元,增长27.50%,旅游总收入在全国的排名由18位上升至17位;接待总人数8190.23万人次,同比增长30.77%。
2009年,贵州省全年共接待游客1.043亿人次,同比增长27.46%,旅游总收入805.23亿元,同比增长23.29%,远远超过了预期的780亿和20%的增长率。
本文主要对五个方面的因素进行多重共线性的分析,剔除具有严重共线性的解释变量,改善计量模型。
并最终确定影响贵州旅游发展的重要因素。
二. 模型设定1. 旅游影响因素的选择影响旅游市场收入的主要因素,除了国内旅游人数和居民消费外还有很多,但是应该挑选在长期内具有较稳定的变动趋势的因素、剔除随机性较强的因素如:自然灾害的发生;国内外突发事件或重大活动,如2008年的凝冻灾害、农运会的举办等。
此外还可能与基础设施建设有关,由于发达的交通方便了人们出门旅游,而收入的增加提供了经济支持。
综合上述分析,我们选取五个解释变量如下:X1:国内旅游人数(万人次); X2:城镇居民人均消费性支出(元); X3:农村居民人均消费性支出(元); X4:公路里程数(公里); X5:铁路旅程(公里); 2.模型形式的设计由于是根据实际数据进行实证分析,所以将被解释变量(Y )与五个解释变量进行回归分析,形式为 γγγγγγββββββ55443322110XXXXX +++++=Y三. 数据的收集本文收集了贵州省从1984年-2007年的24组数据。

实验五 多重共线性检验实验时间: 姓名:学号: 成绩:【实验目的】1、掌握多元线性回归模型的估计、检验和预测;2、掌握多重共线性问题的检验方法3、掌握多重共线性问题的修正方法 【实验内容】1、数据的读取和编辑;2、多元回归模型的估计、检验、预测;3、多重共线性问题的检验4、多重共线性问题的修正 【实验背景】为了评价报账最低工资(负收入税)政策的可行性,兰德公司进行了一项研究,以评价劳动供给(平均工作小时数)对小时工资提高的反应,词研究中的数据取自6000户男户主收入低于15000美元的一个国民样本,这些数据分成39个人口组,并放在表1中,由于4个人口组中的某些变量确实,所以只给出了35个组的数据,用于分析的各个变量的定义如下:Y 表示该年度平均工作小时数;X1表示平均小时工资(美元);X2表示配偶平均收入(美元);X3表示其他家庭成员的平均收入(美元);X4表示年均非劳动收入(美元);X5表示平均家庭资产拥有量;X6表示被调查者的平均年龄;X7表示平均赡养人数;X8表示平均受教育年限。
μ为随机干扰项,考虑一下回归模型:μβββββββββ+++++++++=87654321876543210X X X X X X X X Y(1) 将该年度平均工作小时数Y 对X 进行回归,并对模型进行简单分析; (2) 计算各变量之间的相关系数矩阵,利用相关系数法分析变量间是否具有多重共线性;(3) 利用逐步回归方法检验并修正回归模型,最后再对模型进行经济意义检验、统计检验。
表5观测组Y X1 X2 X3 X4 X5 X6 X7 X81 2157 2.905 1121 291 380 7250 38.5 2.34 10.52 2174 2.97 1128 301 398 7744 39.3 2.335 10.53 2062 2.35 1214 326 185 3068 40.1 2.851 8.94 2111 2.511 1203 49 117 1632 22.4 1.159 11.55 2134 2.791 1013 594 730 12710 57.7 1.229 8.86 2185 3.04 1135 287 382 776 38.6 2.602 10.77 2210 3.222 1100 295 474 9338 39 2.187 1128 2105 2.495 1180 310 255 4730 39.9 2.616 9.39 2267 2.838 1298 252 431 8317 38.9 2.024 11.110 2205 2.356 885 264 373 6489 38.8 2.662 9.511 2121 2.922 1251 328 312 5907 39.8 2.287 10.312 2109 2.499 1207 347 271 5069 39.7 3.193 8.913 2108 2.796 1036 300 259 4614 38.2 2.4 9.214 2047 2.453 1213 397 139 1987 40.3 2.545 9.115 2174 3.582 1141 414 498 10239 40 2.064 11.716 2067 2.909 1805 290 239 4439 39.1 2.301 10.517 2159 2.511 1075 289 308 5621 39.3 2.486 9.518 2257 2.516 1093 176 392 7293 37.9 2.042 10.119 1985 1.423 553 381 146 1866 40.6 3.833 6.620 2184 3.636 1091 291 560 11240 39.1 2.328 11.621 2084 2.983 1327 331 296 5653 39.8 2.208 10.222 2051 2.573 1197 279 172 2806 40 2.362 9.123 2127 3.263 1226 314 408 8042 39.5 2.259 10.824 2102 3.234 1188 414 352 7557 39.8 2.019 10.725 2098 2.28 973 364 272 4400 40.6 2.661 8.426 2042 2.304 1085 328 140 1739 41.8 2.444 8.227 2181 2.912 1072 304 383 9340 39 2.337 10.228 2186 3.015 1122 30 352 7292 37.2 2.046 10.929 2188 3.01 990 366 374 7325 38.4 2.847 10.630 2077 1.901 350 209 95 1370 37.4 4.158 8.231 2196 3.009 947 294 342 6888 37.5 3.047 10.632 2093 1.899 342 311 120 1425 37.5 4.512 8.133 2173 2.959 1116 296 387 7625 39.2 2.342 10.534 2179 2.959 1116 296 387 7625 39.2 2.342 10.535 2200 2.98 1126 204 393 7885 39.2 2.341 10.6 【实验过程】一、利用Eviews软件建立年度平均工作小时数y的回归模型。
实验五__多重共线性检验参考案例多重共线性检验是用来检验自变量之间是否存在高度相关性的一种方法。
在回归分析中,如果自变量之间存在高度相关性,会导致回归方程中的相关系数估计值不稳定,难以准确地解释自变量对因变量的影响。
因此,进行多重共线性检验是非常重要的。
下面将以一个案例来说明如何进行多重共线性检验。
假设我们想研究一些城市的房价与以下自变量相关性的影响:房屋面积、房间数量、距离市中心的距离。
我们采集了100个样本,并进行了回归分析。
首先,我们可以查看自变量之间的相关系数矩阵,以判断是否存在高度相关性。
下面是自变量之间的相关系数矩阵:房屋面积房间数量距离市中心的距离房屋面积10.80.2房间数量0.810.1距离市中心的距离0.20.11从相关系数矩阵可以看出,房屋面积和房间数量之间存在高度相关性,相关系数为0.8、这可能意味着两个自变量提供了类似的信息,在回归分析中可能会造成多重共线性的问题。
接下来,我们可以计算自变量的方差膨胀因子(VIF)来进一步检验多重共线性。
VIF是用来度量自变量之间相关度的指标,VIF值越大,说明自变量之间的共线性越强。
计算VIF的公式如下:VIF_i=1/(1-R_i^2)其中,VIF_i表示自变量i的VIF值,R_i^2表示通过其他自变量对自变量i进行回归分析得到的决定系数。
下面是计算三个自变量的VIF值:VIF_房屋面积=1/(1-0.8^2)=1.67VIF_房间数量=1/(1-0.8^2)=1.67VIF_距离市中心的距离=1/(1-0.1^2)=1.01从计算结果可以看出,三个自变量的VIF值都在可接受的范围内,说明它们之间并不存在严重的多重共线性问题。
最后,我们可以绘制自变量对因变量的散点图,以观察它们之间的关系。
如果自变量之间存在高度相关性,会导致散点图中观测点呈现出一种线性的形态。
综上所述,通过相关系数矩阵、VIF值以及散点图的分析,我们可以得出结论:在这个案例中,房屋面积、房间数量和距离市中心的距离之间不存在严重的多重共线性问题,可以继续进行回归分析。
多重共线性案例:变量Y,X1,X2,X3,X4,X5的数据年Y X1X2X3X4X51974 98.45 560.2 153.20 6.53 1.23 1.891975 100.70 603.11 190.00 9.12 1.30 2.031976 102.80 668.05 240.30 8.10 1.80 2.711977 133.95 715.47 301.12 10.10 2.09 3.001978 140.13 724.27 361.00 10.93 2.39 3.291979 143.11 736.13 420.00 11.85 3.90 5.241980 146.15 748.91 491.76 12.28 5.13 6.831981 144.60 760.32 501.00 13.50 5.47 8.361982 148.94 774.92 529.20 15.29 6.09 10.071983 158.55 785.30 552.72 18.10 7.97 12.571984 169.68 795.50 771.16 19.61 10.18 15.121985 162.14 804.80 811.80 17.22 11.79 18.251986 170.09 814.94 988.43 18.60 11.54 20.591987 178.69 828.73 1094.65 23.53 11.68 23.37资料来源:《天津统计年鉴》1988.用1974-1987年数据建立天津市粮食需求模型如下,Y = -3.49 + 0.13 X1 + 0.07 X2 + 2.67 X3 + 3.44 X4– 4.49 X5(-0.11) (2.12) (1.95) (2.13) (1.41) (-2.03)R2 = 0.97, F = 52.59, T = 14, t0.05(8) = 2.31, (1974-1987)其中Y:粮食销售量(万吨/ 年),X1:市常住人口数(万人),X2:人均收入(元/ 年),X3:肉销售量(万吨/ 年),X4:蛋销售量(万吨/ 年),X5:鱼虾销售量(万吨/ 年)。
多重共线性分析案例例用1974-1987年数据建立天津市粮食需求模型如下:表1 变量y,x1,x2,x3,x4,x5的数据年y x1x2x3x4x51974 98.45 560.2 153.20 6.53 1.23 1.891975 100.70 603.11 190.00 9.12 1.30 2.031976 102.80 668.05 240.30 8.10 1.80 2.711977 133.95 715.47 301.12 10.10 2.09 3.001978 140.13 724.27 361.00 10.93 2.39 3.291979 143.11 736.13 420.00 11.85 3.90 5.241980 146.15 748.91 491.76 12.28 5.13 6.831981 144.60 760.32 501.00 13.50 5.47 8.361982 148.94 774.92 529.20 15.29 6.09 10.071983 158.55 785.30 552.72 18.10 7.97 12.571984 169.68 795.50 771.16 19.61 10.18 15.121985 162.14 804.80 811.80 17.22 11.79 18.251986 170.09 814.94 988.43 18.60 11.54 20.591987 178.69 828.73 1094.65 23.53 11.68 23.37资料来源:《天津统计年鉴》1988.设回归模型:Y=β0+β1X1+β2X2+β3X3+β4X4+β5X5+ε利用spss统计软件进行线性回归(点选Statistics选项框中Collinearity共线性诊断选项),设显著性水平0.05,输出结果如下:从回归方程的P检验结果看出Sig=0,整体通过显著性检验。
从输出结果看,在0.05的显著性水平下,βi的t统计量单独对因变量y都无显著性影响(P 值都大于0.05)。
能源消耗量多重共线性
数据来源:《2001年一2015年中国统计年鉴》
最小二乘法:
Dep endent Sample: 20Q1 2015
In eluded observatio ns: 15
Vanable CoefUaent Std Error t-Statistic Prob C 132334.0 103956.8 1.272849 0.2437 GDP -0.344084 0.212689 -1.6177S4 0 1497 QC -2096395 2060207 -1.017566 0.3428 FDL 7.647163 2.353612 3.249118 0.0141 HXXW 3559803 23.04932 1.269123 0.2450 TU 1337.533 729.2753 1.834058 0.1093 HF -3.055542 8.653656 -0.353208 0.7343 LSCL
-1.669657 2.724030
-0.612936
0.5593 R-squared
0.996149 Mean dependentvar 290620 1 Adjusted R-squared 0.992297 S.D dependent var 90737 42 S.E. of regression 7963.604 Akaike info criterion 21.10768 Sum squared resid 4 44E+0S Schwarz critenon 21.48530 Log liKelifiood -1503076 Hannan-Quinn criter. 21.10366 F-statistic
258 6471 Durbin-Watson stat
2.66U01
Prob(F-statistic)
0.000000
得到的回归模型为
Y = 132333.984713 - 0.344084350491*GDP - 20.9639535518*QC + 7.64716297259*FDL +
35.5980328128*HXXW + 1337.53288876*TLJ - 3.0565********HF - 1.66965708916*LSCL
258.6471,明显显著。
但是当 G =0.05时,口2
(n - k-1)=鮎.02
5(15 — 8) = 1.7531 不仅 HF 、HXXW 的系数t 检验不显著,而且 GDP 、QC 、LSCL 系数的符号与预期相反,这样表明可能存在严重的多重共线 性。
计算各解释变量的相关系数,选择 GDP 、QC 、FDL 、HXXW 、TLJ 、HF 、LSCL 的数据
¥
GDP
QC FDL HXXW TLJ HF
LSCL Y
1.D000G0 0 978962 0.9715M 0.993906 0.392043 0 982450 0.95517B OJ70274 GDP
097G962
1 000000
0.933772 0 992184
0993639 098S076 0906618
0936553
t= ( 1.273) (-1.617) (1.269)
(1.834)
R2=0.996,F =258.647 : ,DW=2.661
由以上结果可见,该模型
(-0.353 )
(-1.018 ) (-0.613 )
(3.249 )
2
R =0.996149,修正的可决系数为
0.992297,可决系数非常高, F 检验值为
全部解释变量的相关系数矩阵
由相关系数矩阵可以看岀,各解释变量相互之间的相关系数较高吗,证实确实存在严重的多重共线性。
多重共线性的修正
为消除共线性的影响,首先分别拟合Y对GDP QC FDL HXXW TLJ HF LSCL 的一元回归,得到七个回归模型的参数估计结果。
7个解释变量分别进行一元回归模型的参数估计结果
可以发现,变量FDL拟合效果最佳,且整体拟合效果最好。
即发电量对能源消耗量起主要作用。
按照各个
解释变量一元回归模型的拟合优度大小进行排序:FDL,HXXW,TLJ,GDP,LSCL,QC,HF ,以FDL 为基础依次加入其他解释变量进行逐步回归。
加入HXXW
Y = 79506.7054599 + 4.7901720539*FDL + 15.018962978*HXXW
t = ( 5.08510) ( 2.011848) ( 0.550224)
R =0.988,F=500.22,RSS=1.37*10A9
系数为正
加入TLJ
Y = 83502.3622712 + 4.7662124355*FDL + 10.3033091555*HXXW + 296.631527853*TLJ
t= (4.1385 ) ( 1.925450) (0.325176) (0.334023)
R2
=0.988266 , F=308.8278 , RSS=1.35*10A9
系数为正
加入TLJ
Y = 57002.1055085 + 5.90241783797*FDL + 49.5728951535*HXXW - 0.311419040916*GDP t= (4.088001 ) ( 3.191238 ) ( 2.101646 ) (-3.107994 )
R =0.993689 , F=577.3510 , RSS=7.27*10A8
系数为负,剔除GDP
加入LSCL
Y = 165163.157653 + 5.61116988855*FDL + 16.2680580598*HXXW - 2.25051469861*LSCL
t= ( 1.420467 ) ( 2.104788 ) ( 0.583718 ) (-0.743696 )
R2=0.988715 , F=321.2445 , RSS=1.3*10A9
系数为负,剔除LSCL
加入QC
Y = 56459.2268715 + 6.33133390691*FDL + 21.8258849727*HXXW - 40.2663627237*QC
t= ( 3.160903 ) ( 2.821108 ) ( 0.891906 ) (-2.051861)
R =0.991428 , F=424.0930 , RSS=9.88*10A8
系数为负,剔除QC
加入HF
Y = 49317.0081576 + 3.58414062424*FDL + 18.0157355404*HXXW + 11.3550355173*HF
t=(2.315445) (1.593152 ) ( 0.726667 ) ( 1.898782 )
R? =0.991073 , F=407.0851 RSS=1.03*10A9
最后,从此模型中可以看出,发电量、化学纤维、和化肥对能源消耗量有显著影响。