计量经济学Eviews多重共线性实验报告记录
- 格式:doc
- 大小:719.50 KB
- 文档页数:16
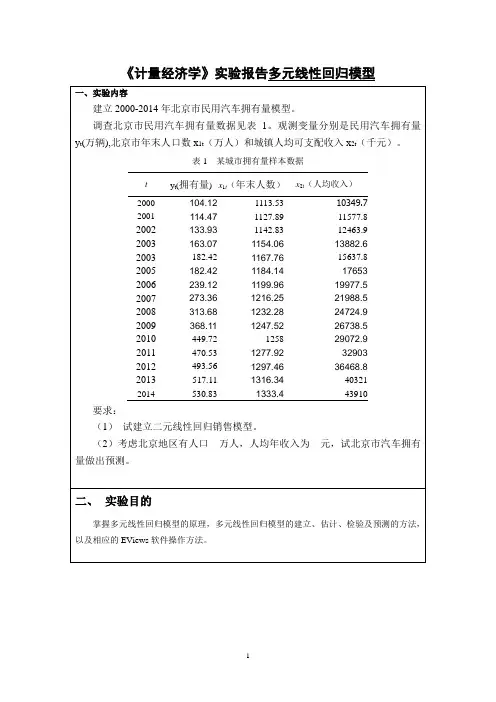
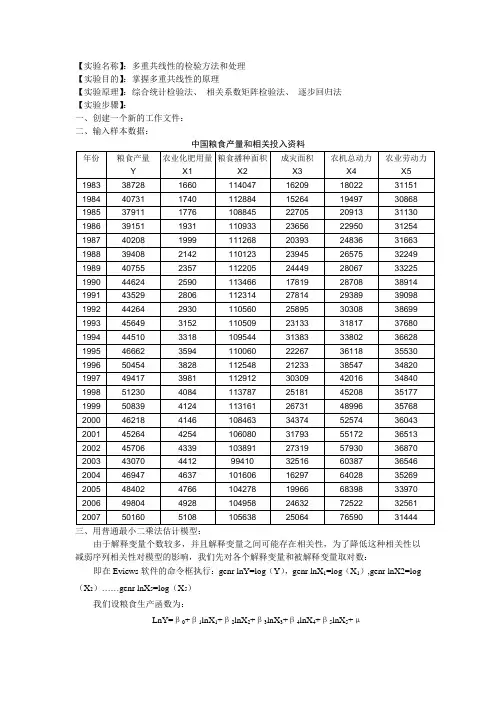
【实验名称】:多重共线性的检验方法和处理【实验目的】:掌握多重共线性的原理【实验原理】:综合统计检验法、相关系数矩阵检验法、逐步回归法【实验步骤】:一、创建一个新的工作文件:二、输入样本数据:三、用普通最小二乘法估计模型:由于解释变量个数较多,并且解释变量之间可能存在相关性,为了降低这种相关性以减弱序列相关性对模型的影响,我们先对各个解释变量和被解释变量取对数:即在Eviews软件的命令框执行:genr lnY=log(Y),genr lnX1=log(X1),genr lnX2=log (X2)……genr lnX5=log(X5)我们设粮食生产函数为:LnY=β0+β1lnX1+β2lnX2+β3lnX3+β4lnX4+β5lnX5+μ用运普通最小二乘法估计:下表给出了采用Eviews软件对表一的数据进行回归分析的统计结果:Dependent Variable: LNYMethod: Least SquaresDate: 12/19/13 Time: 10:05Sample: 1983 2007C -4.173174 1.923624 -2.169434 0.0429LNX1 0.381145 0.050242 7.586182 0.0000 LNX2 1.222289 0.135179 9.042030 0.0000 LNX3 -0.081110 0.015304 -5.300024 0.0000 LNX4 -0.047229 0.044767 -1.054980 0.3047R-squared 0.981597 Mean dependent var 10.70905 Adjusted R-squared 0.976753 S.D. dependent var 0.093396 S.E. of regression 0.014240 Akaike info criterion -5.459968 Sum squared resid 0.003853 Schwarz criterion -5.167438 Log likelihood 74.24960 F-statistic 202.6826 Durbin-Watson stat 1.791427 Prob(F-statistic) 0.000000根据上表估计出的参数,可以得到如下普通最小二乘法估计模型:lnY=‐4.17+0.381lnX1+1.222lnX2‐0.081lnX3‐0.047lnX4‐0.101lnX5四、模型检验:1、数学检验:由于R2为0.9816接近于一,且F=202.68>F0.05(5,9)=2.74,故认为粮食产量和上述解释变量之间的总体线性关系显著;但是就X4,X5来说,其t检验的参数较小,尚不能通过t检验,因此怀疑模型中存在多重共线性。
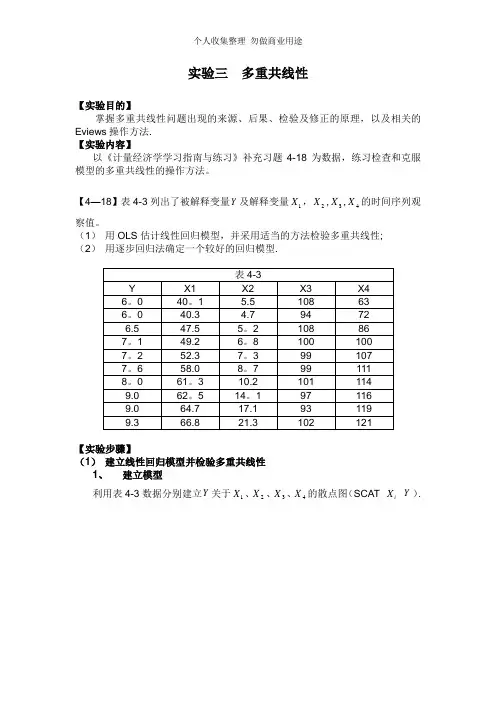
实验三 多重共线性【实验目的】掌握多重共线性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews 操作方法. 【实验内容】以《计量经济学学习指南与练习》补充习题4-18为数据,练习检查和克服模型的多重共线性的操作方法。
【4—18】表4-3列出了被解释变量Y 及解释变量1X ,2X ,3X ,4X 的时间序列观察值。
(1) 用OLS 估计线性回归模型,并采用适当的方法检验多重共线性; (2) 用逐步回归法确定一个较好的回归模型.【实验步骤】(1) 建立线性回归模型并检验多重共线性1、 建立模型利用表4-3数据分别建立Y 关于1X 、2X 、3X 、4X 的散点图(SCAT i X Y ).可以看到Y 与1X 、2X 、4X 都呈现正的线性相关,与3X 关系不明显。
首先建立一个多元线性回归模型(LS Y C 1X 2X 3X 4X ).输出结果中,C 、1X 、3X 、4X 的系数都通不过显著性检验。
2、 检验多重共线性进一步选择Covariance Analysis 的Correlation,得到变量之间的偏相关系数矩阵,观察偏相关系数。
可以发现,Y 与1X 、2X 、4X 的相关系数都在0.9以上,但输出结果中,解释变量1X 、4X 的回归系数却无法通过显著性检验。
认为解释变量之间存在多重共线性。
(2) 用逐步回归法克服多重共线性1、 找出最简单的回归形式分别作Y 与1X 、2X 、3X 、4X 间的回归(LS Y C i X )。
即:(1)1122.0942.0X Y +=∧(1。
64) (11。
7)9383.02=RD.W.=1。
6837(2)2205.0497.5X Y +=∧(17。
9) (7。
63)8640.02=RD.W.=0。
6130(3)3095.0090.17X Y -=∧(2。
14) (-1.19)0450.02=RD.W.=0。
6471(4)4055.0018.2X Y +=∧(2.25) (6。

《计量经济学》上机实验报告一题目:多元回归模型和多重共线性实验日期和时间:2013年4月18日班级:学号:姓名:实验室:实验楼104实验环境:Windows XP ; EViews 3.1实验目的:利用相关数据建立多元回归模型,分析在不同的经济条件下一定的要素对某个经济体发展的影响程度并建立一定的关系模型。
检验设定的模型是否存在多重共线性,分析产生多重共线性的原因及作用因素,并对存在多重共线性的模型进行必要的修正。
实验内容:1、中国进出口额Y、国内生产总值GDP、居民消费价格指数CPI,根据提供的模型估计参数,判断多重共线性是否存在,表述多重共线性的性质。
2、检验能源消费需求总量Y的影响因素,选取国民总收入X1、国内生产总值X2、工业增加值X3、建筑业增加值X4、交通运输邮电业增加值X5、人均生活电力消费X6和能源加工转换效率X7七个变量,模拟回归,检验修正多重共线性。
3、为什么会产生“农业的发展反而会减少财政收入”的异常结果,如何解决这种异常。
实验步骤:一、中国进出口额Y、国内生产总值GDP、居民消费价格指数CPI(一)建立多元回归模型,估计参数在命令窗口依次键入以下命令:1、建立工作文件:CREATE A 1985 20072:输入统计资料:DATA Y GDP CPI3、生成变量:GENR LNY=LOG(Y)GENR LNGDP=LOG(GDP)GENR LNCPI=LOG(CPI)4、建立回归模型:LS LNY C LNGDP LNCPI得出回归结果为:由此可见,该模型的参数形式为:LNŶt=-3.06+1.66LNGDP t-1.06LNCPI t,其中该模型R2=0.9922,R2=0.9914可决系数很高,F检验值1275.093,明显显著,且T检验的临界概率均非常小,回归效果较好。
(二)检验多重共线性利用简单相关系数法进行检验,输入命令COR LNY LNGDP LNCPI,得到相关系数矩阵:由相关系数矩阵可以看出,各解释变量相互之间的相关系数均很高,说明数据中存在严重的多重共线性。

计量经济学实验报告四
[实验名称] 多重共线性
[实验目的] 用Eviews 软件检验模型的多重共线性.
[实验内容] (1)根据表列出的家庭消费支出Y与可支配收入X1和个人财富X2的统计数据,在Eviews软件下,OLS的估计结果为
所以模型为Yˆ=245.52+0.57X1-0.0058X2
(3.53)(0.79)(-0.08)
R2=0.962 F=88.845 D.W.=2.708
由拟合优度知,收入和财富一起解释了消费支出的96%.然而两者的t检验都在5%的显著性水平下是不显著的.不仅如此,财富变量的符号也与经济理论不相符合.但从F的检验值看,对收入与财富的参数同时为零的假设显然是拒绝的.因此,显著的F检验值与不显著t检验值,说明了收入与财富存在较高的相关性,使得无法分辨二者各自对消费的影响.只作消费支出关于收入的一元回归模型.如下
所以模型为Yˆ=244.55+0.509X1
(3.813)(14.24)
R2=0.962 F=202.87 D.W.=2.68
我们将上面模型与之相比,新引入的变量并没有带来拟合优度的显著变化,所以该引入的变量不是一个独立的解释变量.因此应该只作消费支出关于收入或财富的一元回归模型来对二元模型进行修正.。

Eviews多重共线性实验报告-V1本文主要将Eviews多重共线性实验报告进行整理,旨在帮助读者更好地理解和应用多重共线性实验结果。
1. 研究背景多重共线性是指在回归模型中,自变量之间存在高度相关的情况。
这种相关关系会导致模型的不稳定性,降低模型的解释能力和预测能力。
因此,在进行回归分析时,需要对多重共线性进行检测和处理。
2. 数据来源和处理本次实验所使用的数据来自某公司销售数据,共有18个自变量和1个因变量。
在进行回归分析之前,需要对数据进行预处理。
首先,我们通过观察变量间的相关系数矩阵来初步判断是否存在多重共线性。
如果存在高度相关的自变量,可以考虑通过主成分分析等方法来降维,减少变量间的冗余。
本实验中,我们发现变量间的相关性较小,因此没有进行降维操作。
3. 模型建立我们采用逐步回归的方法建立回归模型,并对模型的适配度和稳定性进行评估。
首先,我们使用全模型(包含所有自变量)进行回归分析,并得到如下统计结果:R-squared:0.7767Adj. R-squared:0.7152F-statistic:12.38(显著)通过观察模型的系数,我们发现存在一些变量的系数非常大,而一些变量的系数非常小甚至为0,这也是多重共线性的表现之一。
为了进一步检验模型的稳定性和解释能力,我们采用逐步回归的方法进行变量筛选。
在此过程中,我们设置的入模标准是F统计量显著,出模标准是T统计量显著或P值小于0.05。
最终,我们得到了一个包含4个自变量的最优模型,其统计结果如下:R-squared:0.7224Adj. R-squared:0.6812F-statistic:17.69(显著)通过观察模型的系数,我们发现所有自变量的系数都显著,且大小合理。
这说明通过逐步回归的方法,我们成功地排除了多重共线性的影响,建立了一个具有较好稳定性和解释能力的模型。
4. 结论和建议在本实验中,我们成功地应用了Eviews工具,通过逐步回归的方法检验和处理多重共线性,建立了一个较为稳定和解释能力强的回归模型。
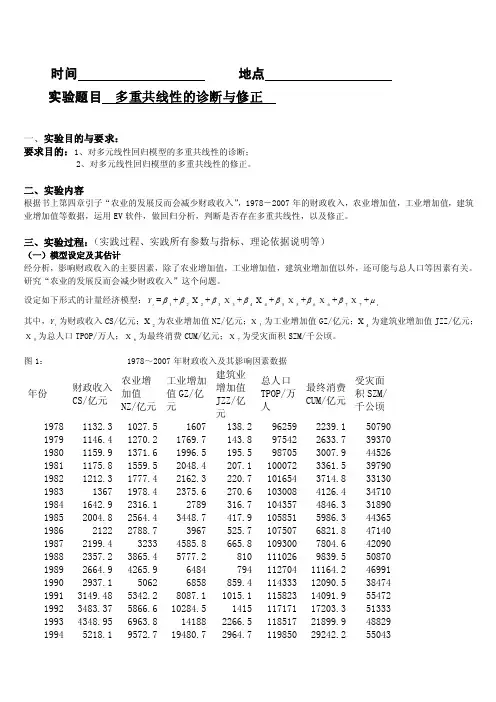
时间 地点 实验题目 多重共线性的诊断与修正一、实验目的与要求:要求目的:1、对多元线性回归模型的多重共线性的诊断;2、对多元线性回归模型的多重共线性的修正。
二、实验内容根据书上第四章引子“农业的发展反而会减少财政收入”,1978-2007年的财政收入,农业增加值,工业增加值,建筑业增加值等数据,运用EV 软件,做回归分析,判断是否存在多重共线性,以及修正。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)(一)模型设定及其估计经分析,影响财政收入的主要因素,除了农业增加值,工业增加值,建筑业增加值以外,还可能与总人口等因素有关。
研究“农业的发展反而会减少财政收入”这个问题。
设定如下形式的计量经济模型:i Y =1β+2β2X +3β3X +4β4X +5β5X +6β6X +7β7X +i μ其中,i Y 为财政收入CS/亿元;2X 为农业增加值NZ/亿元;3X 为工业增加值GZ/亿元;4X 为建筑业增加值JZZ/亿元;5X 为总人口TPOP/万人;6X 为最终消费CUM/亿元;7X 为受灾面积SZM/千公顷。
图1: 1978~2007年财政收入及其影响因素数据年份财政收入CS/亿元 农业增加值NZ/亿元 工业增加值GZ/亿元 建筑业增加值JZZ/亿元总人口TPOP/万人最终消费CUM/亿元受灾面积SZM/千公顷 1978 1132.3 1027.5 1607 138.2 96259 2239.1 50790 1979 1146.4 1270.2 1769.7 143.8 97542 2633.7 39370 1980 1159.9 1371.6 1996.5 195.5 98705 3007.9 44526 1981 1175.8 1559.5 2048.4 207.1 100072 3361.5 39790 1982 1212.3 1777.4 2162.3 220.7 101654 3714.8 33130 1983 1367 1978.4 2375.6 270.6 103008 4126.4 34710 1984 1642.9 2316.1 2789 316.7 104357 4846.3 31890 1985 2004.8 2564.4 3448.7 417.9 105851 5986.3 44365 1986 2122 2788.7 3967 525.7 107507 6821.8 47140 1987 2199.4 3233 4585.8 665.8 109300 7804.6 42090 1988 2357.2 3865.4 5777.2 810 111026 9839.5 50870 1989 2664.9 4265.9 6484 794 112704 11164.2 46991 1990 2937.1 5062 6858 859.4 114333 12090.5 38474 1991 3149.48 5342.2 8087.1 1015.1 115823 14091.9 55472 1992 3483.37 5866.6 10284.5 1415 117171 17203.3 51333 1993 4348.95 6963.8 14188 2266.5 118517 21899.9 48829 19945218.1 9572.7 19480.7 2964.7 11985029242.2550431995 6242.2 12135.8 24950.6 3728.8 121121 36748.2 45821 1996 7407.99 14015.4 29447.6 4387.4 122389 43919.5 46989 1997 8651.14 14441.9 32921.4 4621.6 123626 48140.6 53429 1998 9875.95 14817.6 34018.4 4985.8 124761 51588.2 50145 1999 11444.08 14770 35861.5 5172.1 125786 55636.9 49981 2000 13395.23 14944.7 40036 5522.3 126743 61516 54688 2001 16386.04 15781.3 43580.6 5931.7 127627 66878.3 52215 2002 18903.64 16537 47431.3 6465.5 128453 71691.2 47119 2003 21715.25 17381.7 54945.5 7490.8 129227 77449.5 54506 2004 26396.47 21412.7 65210 8694.3 129988 87032.9 37106 2005 31649.29 22420 76912.9 10133.8 130756 96918.1 38818 2006 38760.2 24040 91310.9 11851.1 131448 110595.3 41091 2007 51321.78 28095 107367.2 14014.1 132129 128444.6 48992利用EV 软件,生成i Y 、2X 、3X 、4X 、5X 、6X 、7X 等数据,采用这些数据对模型进行OLS 回归。
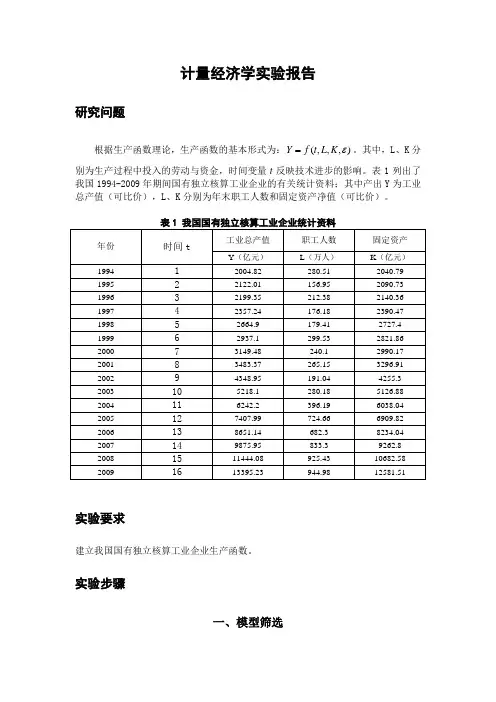
计量经济学实验报告研究问题根据生产函数理论,生产函数的基本形式为:),,,(εK L t f Y =。
其中,L 、K 分别为生产过程中投入的劳动与资金,时间变量t 反映技术进步的影响。
表1列出了我国1994-2009年期间国有独立核算工业企业的有关统计资料;其中产出Y 为工业总产值(可比价),L 、K 分别为年末职工人数和固定资产净值(可比价)。
实验要求建立我国国有独立核算工业企业生产函数。
实验步骤一、模型筛选(一)建立多元线性回归方程回归结果如下:图1因此,我国国有独立工业企业的生产函数为:K L t Y 00998.171897.022674.90897.191+++-=∧(模型1)t =(-5.4) (0.862) (3.57) (40.44)999742.02=R 999677.02=R 57.15483=F模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为0.71897,资金的边际产出为1.00998,技术进步的影响使工业总产值平均每年递增9.22674亿元。
回归系数的符号和数值是较为合理的。
999742.02=R ,说明模型有很高的拟合优度,F 检验也是高度显著的,说明职工人数L 、资金K 和时间变量t 对工业总产值的总影响是显著的。
从图1看出,解释变量资金K 的t 统计量值为40.44,表明资金对企业产出的影响是显著的。
但是,模型中时间变量T 的t 统计量值都较小,未通过检验。
因此,需要对以上三元线性回归模型做适当的调整,按照统计检验程序,一般应先剔除t 统计量较小的变量(即时间变量)而重新建立模型。
(二)建立剔除时间变量的二元线性回归模型回归结果如下:图2因此,我国国有独立工业企业的生产函数为:K L Y 026137.1669964.02778.176++-=∧(模型2)t =(-5.76) (3.5) (62.79)999726.02=R 999684.02=R 95.23692=F(三)建立非线性回归模型——C-D 生产函数C-D 生产函数为:εβαe K AL Y =。

计量经济学实验报告一、实验目的:1、熟悉和掌握Eviews在多重共线性模型中的应用,如何判断和解决多重共线性问题。
2、加深对课程理论知识的理解和应用。
二、实验问题:农村居民各种不同类型的收入对消费支出影响(2006年)农村居民收入(Y)主要来源于4项:即农业经营收入(X1)、工资性收入(X2)、财产性收入(X3)及转移性收入(X4)。
(1)利用线性模型或双对数模型进行分析。
(2)回归模型中存在多重共线性吗?三、实验数据:由老师提供(本实验报告截取从北京到新疆共31组数据)四、实验步骤:1、建立新的工作文件,输入数据,分别保存为Y(农村居民收入),X1(农业经营收入)、X2(工资性收入)、X3(财产性收入)、及X4(转移性收入)。
2、建立线性模型:Y = a1*X1 + a2*X2 +a3*X3 + a4*X4 + u得到方程:Y = 0.6268809567*X1 + 0.481134931*X2 - 0.255544644*X3 + 2.683018467*X4 + 479.30109493、分析由图中数据可以看出,在最小二乘法下,模型的R平方和F值较大,表明模型中各解释变量对Y的联合线性作用显著;但是X3(财产性收入)的系数是负的,这不符合经济学意义,财产性收入应当与消费支出正相关,故怀疑模型存在多重共线性。
4、检验:计算解释变量之间的简单相关系数:在“quick”菜单中选“group statistics”项中的“correlation”命令。
在出现“serieslist”对话框时,直接输入X1,X2,X3,X4出现如下结果从表中可以看出,解释变量X1、X3、X4之间存在高度线性相关。
4、修正第一步:运用OLS方法逐一求Y对各个解释变量的回归。
(1)Y = 0.8997862236*X1 + 1541.033294t值 15.32947 12.29913prob.值 0.0000 0.0000R2=0.890148 F=234.9925(2)Y = 0.2487123305*X2 + 2505.747921t值 0.527219 2.676297prob.值 0.6021 0.0121R2= 0.009494 F=0.277960(3)Y = 8.049228785*X3 + 1943.170851t值 9.28666 11.56389prob.值 0.0000 0.0000R2=0.748356 F= 86.24206(4)Y = 5.928884198*X4 + 1631.299987t值 9.212266 8.434353prob.值 0.0000 0.0000R2= 0.745314 F=84.86584结合经济意义和统计检验结果分析,在4个一元回归模型中消费支出Y对X1工资性收入线性关系最强,拟合程度较好,与经验相符,因此选(1)为初始的回归模型。

eviews计量经济学实验报告EViews计量经济学实验报告引言计量经济学是经济学领域中的一个重要分支,它运用数学、统计学和计量学的方法来分析经济现象。
EViews是一个常用的计量经济学软件,它提供了丰富的数据分析和模型建立工具,被广泛应用于学术研究和实际经济分析中。
本实验报告将利用EViews软件进行计量经济学实验,以探讨经济现象并得出相关结论。
实验目的本实验旨在利用EViews软件对某一经济现象进行实证分析,通过建立相应的计量经济模型,对经济现象进行量化分析,并得出相关结论。
实验步骤1. 数据收集:首先,我们需要收集与所研究经济现象相关的数据,包括时间序列数据和横截面数据等。
这些数据可以来自于官方统计机构、学术研究机构或者自行收集整理。
2. 数据预处理:接下来,我们需要对收集到的数据进行预处理,包括数据清洗、缺失值处理、异常值处理等,以确保数据的质量和完整性。
3. 模型建立:在数据预处理完成后,我们可以利用EViews软件建立计量经济模型,包括回归分析、时间序列分析、面板数据分析等,以探讨经济现象的内在规律和影响因素。
4. 模型估计:建立模型后,我们需要对模型进行参数估计,得到模型的具体参数估计值,并进行显著性检验和模型拟合度检验,以验证模型的可靠性和有效性。
5. 结果分析:最后,我们将对模型估计结果进行分析,得出与经济现象相关的结论,并对实证分析结果进行解释和讨论。
实验结论通过以上实验步骤,我们得出了关于某一经济现象的实证分析结果,并得出了相关的结论。
这些结论对于理解经济现象的内在规律和制定经济政策具有重要的参考价值。
总结EViews计量经济学实验报告通过利用EViews软件进行实证分析,对经济现象进行了深入探讨,并得出了相关结论。
这些结论对于经济学研究和实际经济分析具有重要的理论和实践意义,为我们深入理解经济现象和推动经济发展提供了重要的参考依据。
EViews软件的应用为我们提供了一个强大的工具,帮助我们更好地理解和分析经济现象,为经济学领域的研究和实践提供了重要的支持和帮助。

西南科技大学Southwest University of Science and Technology 经济管理学院计量经济学实验报告——多元线性回归的检验专业班级:国贸0903姓名:王鑫学号: 20092438任课教师:龙林成绩:简单线性回归模型的处理实验目的:掌握多元回归参数的估计和检验的处理方法。
实验要求:学会建立模型,估计模型中的未知参数等。
试验用软件:Eviews实验原理:线性回归模型的最小二乘估计、回归系数的估计和检验。
实验内容:1、实验用样本数据:运用Eviews软件,建立1990—2001年中国国内生产总值X和深圳市收入Y的回归模型,做简单线性回归分析,并对回归结果进行检验。
以研究我国国内生产总值对深圳市收入的影响。
年份地方预算内财政收入Y(亿元)国内生产总值(GDP)X(亿元)1990 21.7037 171.6665 1991 27.3291 236.6630 1992 42.9599 317.3194 1993 67.2507 449.2889 1994 74.3992 615.1933 1995 88.0174 795.6950 1996 131.7490 950.0446 1997 144.7709 1130.0133 1998 164.9067 1289.0190 1999 184.7908 1436.0267 2000 225.0212 1665.4652 2001 265.6532 1954.6539经过简单的回归分析后得出表EQ1:Dependent Variable: YMethod: Least SquaresDate: 11/28/11 Time: 18:31Sample: 1990 2001Included observations: 12Variable CoefficientStd. Error t-Statistic Prob.C -3.611151 4.161790 -0.867692 0.4059X 0.134582 0.003867 34.80013 0.0000 R-squared 0.991810 Mean dependent var 119.8793 Adjusted R-squared 0.990991 S.D. dependent var 79.36124S.E. of regression 7.532484 Akaike infocriterion 7.027338Sum squared resid 567.3831 Schwarz criterion 7.108156Log likelihood -40.16403 F-statistic 1211.049Durbin-Watson stat 2.051640 Prob(F-statistic) 0.00000其中拟合优度为:0.991810有很强的线性关系。
计量经济学实验报告(多元线性回归分析)实验2:多元线性回归分析实验目的:学习利用Eviews建立多元线性回归模型,研究64国家婴儿死亡率与妇女文盲率之间的关系。
一、实验内容:1、先验的预期CM和各个变量之间的关系.2、做CM对FLR的回归,得到回归结果。
3、做CM对FLR和PGNP的回归,得到回归结果。
4、做CM对FLR,PGNP和TFR的回归结果,并给出ANOVA。
5、根据各种回归结果,选择哪个模型?为什么?6、如果回归模型(4)是正确的模型,但却估计了(2)或(3),会有什么后果?7、假定做了(2)的回归,如何决定增加变量PGNP和TFR?使用了哪种检验?给出必要的计算结果。
二、实验报告———-多元线性回归分析1、问题提出婴儿死亡率(CM)是指婴儿出生后不满周岁死亡人数同出生人数的比率.一般以年度为计算单位,以千分比表示。
婴儿死亡率是反映一个国家和民族的居民健康水平和社会经济发展水平的重要指标,特别是妇幼保健工作水平的重要指标。
婴儿死亡率(CM)的高低是一个国家或地区社会经济多方面因素协调发展的结果。
由于世界各国婴儿死亡率差别很大,所以就64个国家社会综合发展状况,针对性的研究婴儿死亡率(CM)与女性识字率(FLR)、人均GNP(PGNP)、总生育率(TFR)之间的关系2.指标选择本次实验研究婴儿死亡率与妇女文盲率之间的关系,故应采用婴儿死亡率(CM)和女性识字率(FLR)作为指标。
但影响婴儿死亡率的因素较复杂,尤其是经济发展状况、总生育率等也会对其产生重要影响,考虑到实验的准确性,故引入人均GNP(PGNP)和总生育率(TFR)相关数据。
3。
数据来源数据来源:教师提供4。
数据处理此次实验可直接使用数据,无需进行数据处理。
5。
先验的预期CM 和各个变量之间的关系 【题1】 5-1预期CM 与FLR 存在负相关关系。
一方面,女性受教育程度越高,其知识越丰富,自我保护意识和能力就越强,则更善于保护自己和婴儿;另一方面,女性教育程度越高,其就业机会与收入获得途径就越多,可以更好的保障自己和婴儿的生活.因此,我们预期FLR 的提高会导致CM 降低。
Eviews多重共线性实验报告(1)Eviews多重共线性实验报告1. 实验背景多重共线性是指在回归分析中,自变量之间存在高度相关,导致回归系数的不稳定性和误差方差的增大。
在实践中,多重共线性是经济预测分析的重要问题,如何诊断和处理多重共线性是经济学研究中的重要课题。
2. 实验目的通过Eviews软件进行多重共线性诊断,掌握运用Eviews软件解决多重共线性问题的技巧,提高经济预测和分析的准确度和可靠性。
3. 实验流程(1)收集所需要进行回归分析的数据。
(2)在Eviews中建立回归模型,运行回归分析。
(3)通过Eviews的诊断功能,检验回归模型中自变量之间的线性相关。
(4)运用Eviews的多重共线性处理方法,解决自变量之间的多重共线性问题。
4. 实验结果(1)通过Eviews的诊断功能,我们可以得到多重共线性诊断报告,其中显示了变量之间的相关系数矩阵、方差膨胀因子(VIF)、条件指数(CI)、特征值(eigenvalue)、特征向量(eigenvector)等诊断指标。
通过观察相关系数矩阵和VIF,我们可以发现是否存在高度相关的自变量。
当VIF大于10时,就表明存在多重共线性。
(2)如果诊断报告中存在多重共线性问题,我们可以通过Eviews中的多重共线性处理方法解决。
其中包括删除相关系数较高的变量、采用主成分回归法、采用岭回归等方法,具体方法应根据实际情况来选择。
5. 实验结论通过Eviews的多重共线性诊断和处理,我们可以更加准确地进行回归分析,避免了多重共线性所带来的偏误和不稳定性。
在实际应用中,我们应根据具体情况选择适当的处理方法,以得到更加可靠的预测结果。
《计量经济学》实验报告四开课实验室:财经科学实验室年月日班级:学号:姓名:实验项目名称:多重共线性的检验与修正成绩:实验性质:验证性□综合性□设计性指导教师签字:【实验目的】掌握多重共线性的检验与修正方法并能运用Eviews软件进行实现【实验要求】能根据OLS的估计结果判断是否存在多重共线性,熟悉逐步回归法修正模型的基本操作步骤,读懂各项上机榆出结果的含义并能进行分析【实验软件】 Eviews 软件【实验内容】根据给定的案例数据按实验要求进行操作【实验方案与进度】实验:设蔬菜销售量Y与人口(X1)、价格(X2)、粮食(X3)、收入(X4)、副食(X5)Dependent Variable: Y Method: Least Squares Date: 06/03/13 Time: 16:48 Sample: 1978 1996 Included observations: 19Variable Coefficient Std. Error t-Statistic Prob. C -1.530260 6.006901 -0.254750 0.8032 X1 0.014649 0.002923 5.012107 0.0003 X2 -0.702775 0.254521 -2.761169 0.0172 X3 0.060321 0.027575 2.187545 0.0492 X4 0.119825 0.036991 3.239290 0.0071 X5 0.018081 0.026022 0.694816 0.5004 X60.0922660.0542651.7003020.1148 R-squared0.986169 Mean dependent var 9.091579 Adjusted R-squared 0.979254 S.D. dependent var 1.717935 S.E. of regression 0.247442 Akaike info criterion 0.322027 Sum squared resid 0.734730 Schwarz criterion 0.669979 Log likelihood 3.940740 F-statistic 142.6067 Durbin-Watson stat2.292164 Prob(F-statistic)0.000000123456-1.5300.0150.7030.0600.120.0180.092t t t t t t t t Y X X X X X X u =+-+++++(2)方程线性显著性检验由(1)表中的数据可知F 统计量的值为142.6067,查表得0.05(6,12)F =3,显然142.6067>0.05(6,12)F =3,说明方程具有线性显著性。
多重共线性实验报告武颖经济统计学一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。
二、实验要求:应用教材第119页案例做多元线性回归模型,并识别和修正多重共线性。
三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。
四、预备知识:最小二乘法估计的原理、t 检验、F 检验、2R 值。
五、实验步骤1.假定模型:设定并估计多元线性回归模型tt t t t t t u X X X X X Y ++++++=66554433221ββββββ2.录入数据:国内旅游收入为Y ,国内旅游人数为X2,城镇居民人均旅游支出为X3,农村居民人均旅游费用为X4,公路里程为X5,铁路里程为X6.3.回归结果:在Eview行输入LS Y C XX3 X4 X5 X6,得到回归结果2模型估计结果为:Yt=-274.3773+0.013088X2+5.438193X3+3.271773X4-563.1077X5+12.98624X6(1316.690) (0.012692) (1.380395) (0.944215) (4.177929) (321.2830)t=(-0.208384)(1.031172)(3.939591)(3.465073)(3.108296)(-1.752685)R2=0.995406 F=173.35254.模型检验:该模型R2=0.995406,R2=0.989664,可决系数很高,F检验值为173.3525,明显显著。
假设显著性水平α=0.05,X2>0.05,X6>0.05,接受原假设,可能存在严重的多重共线性六.多重共线性的识别(1)得到解释变量的相关系数矩阵将解释变量x2、x3、x4、x5、x6选中,双击选择Open Group(或点击右键,选择Open/as Group),然后再点击View/covariance analysis/Correlation/Common Sample,即可得出相关系数再点击表顶部的Freeze,可得一个Table类型独立的object.由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,特别是x2和x3之间高度相关,证实解释变量之间存在多重共线性。
多重共线性的检验和解决的实验报告1
实验三报告
⼀、实验⽬的:
1.掌握多重共线性的识别⽅法
2.能针对具体问题提出解决多重共线性问题的措施
⼆、实验步骤:
1 相关系数法检验多重共线性
( 1 )点击Eviews6.reg注册然后点击Eviews6.exe
(2) 在file —new —workfile 在start date 和end date 输⼊1960、1982点击确定
(3) 在proc中找到import输⼊Excel 表并在弹出的对话框中输⼊Y X2 X3 X4
X5 X6 检查数据输⼊是否正确
(4)在Eviews 编辑框中输⼊ls Y C X1 X2 X3 X4 进⾏回归,结果如下t值
检验不符合。
说明解释变量之间很可能存在多重共线性。
2 画图法检验是否存在多重共线性:
在quick 中点击Graph在弹出的对话框中输⼊X1 Y 、X2 Y、X3 Y X4 Y点击确定,分别选择scatter 选择带回归线,分别可以看出各⾃变量与Y之间的线性关系,也说明解释变量之间可能存在多重共线性。
综合以上两种检验说明解释变量之间存在多重共线性。
3多重共线性的补救措施(逐步回归法):
(1)分别对四个⾃变量进⾏回归,选拟合优度最⼤的X1作为基本⽅程即Y=-12.45554+0.117845X1,采⽤逐步回归法分别对其进⾏回归
通过以上实验得到i i i x x x 321i 1856.38818.11036.05926.127y
+-+-= Y-X1-X2(留,可决系数升⾼,符号正确)-X3(留,可决系数升⾼,符号正确)
-X4(删,可决系数升⾼,X4的系数不显著)。
数学与统计学院实验报告院(系):数学与统计学学院 学号: 姓名: 实验课程: 计量经济学 指导教师:实验类型(验证性、演示性、综合性、设计性): 综合性 实验时间:2017年 4 月 5 日 一、实验课题多重共线性的诊断及处理 二、实验目的和意义第8周练习 多重共线性右表是某城市财政收入rev 、第一、第二、第三产业gdp1、gdp2、gdp3的有关数据。
1).建立rev 对gdp1,gdp2,gdp3的多元线性回归,并从经济和数理统计上简要说明模型存在着哪些不足。
2).写出rev ,gdp1,gdp2,gdp3的相关系数矩阵。
3).利用判别系数法判断模型是否存在着多重共线性。
4).用逐步回归的方法排除引起共线性的变量,重新建立多元回归。
5).如果不想排除变量,通过经验,假设:gdp1对财政收入的贡献是 gdp3的三倍,而且gdp2与财政收入是对数线性关系。
那么请建立ln (rev )对(3gdp1+gdp3)及ln (gdp2)的半对数线性回归模型,看看模型在经济和数学上是否合理,并从中你得到了什么启示(自己随意发挥)。
三、解题思路(eviews6)1、建立多元线性回归:quick —estimate equation —(rev c gdp1 gdp2 gdp3)年份 rev gdp1 gdp2 gdp3 1983 6604 27235 26781 7106 1984 6634 26680 28567 10240 1985 6710 26762 31766 11912 1986 6823 33595 40062 14160 1987 8103 38510 52935 16960 1988 8578 41529 61337 18777 1989 8469 47994 67848 30498 1990 11118 65138 98946 39700 1991 16053 86983 112531 66960 1992 20221 105825 143545 92231 1993 27076 129136 223697 117031 1994 31888 138619 216161 151334 1995 35139 146637 305940 193573 1996 42436 149788 371066 227561 1997 56204 161800 426925 256684 1998 93828 162960 614341 372177 1999 130532 199519 821302 524562 200017906324664811210586885672、建立相关系数矩阵:quick--group statistic--correlation--rev gdp1 gdp2 gdp3)3、判定系数法:利用一解释变量由其他解释变量变出模型一::quick—estimate equation—(gdp1 c gdp2 gdp3)模型二::quick—estimate equation—(gdp2 c gdp1 gdp3)模型三::quick—estimate equation—(gdp3 c gdp1gdp2)4、逐步回归:quick—estimate equation—method:stepwise—rev c- gdp1 gdp2 gdp35、建立对数线性关系:quick—estimate equation—LOG(REV) C3*GDP1+GDP3 LOG(GDP2)四、实验过程记录与结果1、建立多元回归方程:模型:REV = 7726.69598122 - 0.180508326923*GDP1 + 0.0759120320555*GDP2 + 0.185205459439*GDP3通过多元回归模型可见,该模型通过假设检验,但是两个解释变量的效果并不好(p>0.05);第二点是GDP1表示第一产业,不存在负值,所以不满足经济条件2、相关系数矩阵:(3、判定系数法:(利用一解释变量由其他解释变量变出,检验拟合优度)由系数判定法,可以看出三个模型都显著性成立,即任意一个解释变量都能由其他解释变量线性变出,所以可以得出该模型存在多重共线性。
计量经济学Eviews多重共线性实验报告记录
————————————————————————————————作者:————————————————————————————————日期:
实验报告
课程名称计量经济学
实验项目名称多重共线性
班级与班级代码
专业
任课教师
学号:
姓名:
实验日期:2014 年05 月11日
广东商学院教务处制
姓名实验报告成绩
评语:
指导教师(签名)
年月日
说明:指导教师评分后,实验报告交院(系)办公室保存。
计量经济学实验报告
一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。
二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。
三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。
四、预备知识:最小二乘法估计的原理、t检验、F检验、2
R值。
五、实验步骤
1、选择数据
理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。
为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。
本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。
主要数据如下:
1985~2007年统计数据
年份
能源消费
国民
总收入
国内生
产总值
工业
增加值
建筑业
增加值
交通运输邮电
增加值
人均生活
电力消费
能源加工
转换效率
y X1 X2 X3 X4 X5 X6 X7 1985766829040.7 9016 3448.7 417.9 406.9 21.3 68.29 198680850 10274.4 10275.2 3967 525.7 475.6 23.2 68.32 198786632 12050.6 12058.6 4585.8 665.8 544.9 26.4 67.48 198892997 15036.8 15042.8 5777.2 810 661 31.2 66.54 198996934 17000.9 16992.3 6484 794 786 35.3 66.51 199098703 18718.3 18667.8 6858 859.4 1147.5 42.4 67.2 1991103783 21826.2 21781.5 8087.1 1015.1 1409.7 46.9 65.9 1992109170 26937.3 26923.5 10284.5 1415 1681.8 54.6 66.00 1993115993 35260 35333.9 14188 2266.5 2205.6 61.2 67.32 1994122737 48108.5 48197.9 19480.7 2964.7 2898.3 72.7 65.2 1995131176 59810.5 60793.7 24950.6 3728.8 3424.1 83.5 71.05 1996138948 70142.5 71176.6 29447.6 4387.4 4068.5 93.1 71.5 1997137798 77653.1 78973 32921.4 4621.6 4593 101.8 69.23 1998132214 83024.3 84402.3 34018.4 4985.8 5178.4 106.6 69.44 1999133831 88189 89677.1 35861.5 5172.1 5821.8 118.2 69.19 2000138553 98000.5 99214.6 40033.6 5522.3 7333.4 132.4 69.04 2001143199 108068.2 109655.2 43580.6 5931.7 8406.1 144.6 69.03 2002151797 119095.7 120332.7 47431.3 6465.5 9393.4 156.3 69.04 2003174990 135174 135822.8 54945.5 7490.8 10098.4 173.7 69.4 2004203227 159586.7 159878.3 65210 8694.3 12147.6 190.2 70.71 2005223319 183956.1 183084.8 76912.9 10133.8 10526.1 216.7 71.08 2006 246270 213131.7 211923.5 91310.9 11851.1 12481.1 249.4 71.24
2007 265583 251483.2 249529.9 107367.2 14014.1 14604.1 274.9 71.25
资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。
为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图:
能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98至02年开始缓慢回升,02年到06年开始快速增长。
国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。
工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。
建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。
2、设定并估计多元线性回归模型
t t t t t t t u X X X X X Y ++++++=66554433221ββββββ (2.1)
2.1录入数据,得到图。
2.2.1)采用OLS 估计参数
在主界面命令框栏中输入
ls y c x1 x2 x3 x4 x5 x6 x7回车,即可得到参数的估计结果。
1234567
ˆ28023.7310.68888512.430670.26564322.600710.874955909.01611444.437(94945.12)(3.034175)(3.675319)(0.190824)10.19131)
(2.953978)(345.5062)
(1382.319)
(0.295157)(3.522820)( 3.382i Y X X X X X X X t =-+-+++++=--22201)(1.392080)
(2.217646)
(0.296195)
(2.630969)
(1.044938)
0.989801
0.985041207.96
14
R R F df ====
由此可见,该模型的可决系数为0.989801,修正的可决系数为0.985041,模型拟和很好,F统计量为386.2196,回归方程整体上显著。
可是其中的lnX3、lnX4、lnX6对lnY影响不显著,不仅如此,lnX2、lnX5的参数为负值,在经济意义上不合理。
所以这样的回归结果并不理想。
3、多重共线性模型的识别
点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x1、x2、x3、x4、x5、x6、x7,点击OK,即可得出相关系数矩阵(同图2.2.3)。
从相关系数矩阵可以看出,解释变量x1、x2、x3、x4、x5、x6、x7相互之间的相关系数较高,解释变量之间存在多重共线性。
4、多重共线性模型的修正
3.多重共线性模型的修正
使用逐步回归法进行修正。
第一步:运用OLS方法分别求Y对各解释变量进行一元回归,分别求Y对各解释变量x1、x2、x3、x4、x5、x6、x7进行一元回归。
回归结果详下图。
再结合经济意义和统计检验选出拟合效果最好的一元线性回归方程。
通过上面7个图进行对比分析,依据调整后可决系数2R最大原则,选取x1
(2R=0.969514)作为进入回归模型的第一个解释变量,形成一元回归模型。
第二步:逐步回归。
将剩余解释变量分别加入模型,结果如下:
经比较,可以发现加入X2、X5、X6、X7后参数的符号与预期相反,不符合经济意义,且t 检验部显著。
而加入X4后变化并不显著,只有加入X3后修正的可决系数有所提高,而且参数符号的经济意义合理, 而且参数的t检验,在α=0.1,t(0.05,15)=1.753时显著,所以保留X3。
再加入其他新变量逐步回归。
当加入X2时,虽然R-^2有所增加,但其系数的符号与预期相反且参数的t检验不显著;加入X4后,各参数的t检验不显著;加入X5后,虽然R-^2有所增加,但是但其系数的符号与预期相反且参数的t检验不显著;加入X6、X7后,其系数的符号与预期相反且参数的t检验不显著,这说明主要是X2、X4、X5、X6、X7引起了多重共线性,应予以剔除。
Y^=80927.77+0.5512X1+0.4349X3
t=(28.6903) (5.3587) (1.8308)
2
R=0.9751 2R= 0.9726 F= 391.2352 DW= 0.6938
这说明,在其他因素不变的情况下,当国民总收入X1每增加1亿元,工业增加值X3每增加1亿元时,平均说来能源消费标准煤总量将分别增加0.5512万吨、0.4349万吨。
这说明,国民总收入对能源消费标准煤总量的影响,比工业增加值对能源消费标准煤总量的影
响要大。