验证码识别技术PPT课件
- 格式:ppt
- 大小:417.00 KB
- 文档页数:14


验证码识别原理及实现方法验证码的作用:有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试。
其实现代的验证码一般是防止机器批量注册的,防止机器批量发帖回复。
目前,不少网站为了防止用户利用机器人自动注册、登录、灌水,都采用了验证码技术。
所谓验证码,就是将一串随机产生的数字或符号,生成一幅图片,图片里加上一些干扰象素(防止OCR),由用户肉眼识别其中的验证码信息,输入表单提交网站验证,验证成功后才能使用某项功能。
我们最常见的验证码1,四位数字,随机的一数字字符串,最原始的验证码,验证作用几乎为零。
2,随机数字图片验证码。
图片上的字符比较中规中矩,有的可能加入一些随机干扰素,还有一些是随机字符颜色,验证作用比上一个好。
没有基本图形图像学知识的人,不可破!3,各种图片格式的随机数字+随机大写英文字母+随机干扰像素+随机位置。
4,汉字是注册目前最新的验证码,随机生成,打起来更难了,影响用户体验,所以,一般应用的比较少。
简单起见,我们这次说明的主要对象是第2种类型的,我们先看几种网上比较常见的这种验证码的图片.这四种样式,基本上能代表2中所提到的验证码类型,初步看起来第一个图片最容易破解,第二个次之,第三个更难,第四个最难。
真实情况那?其实这三种图片破解难度相同。
第一个图片,最容易,图片背景和数字都使用相同的颜色,字符规整,字符位置统一。
第二个图片,看似不容易,其实仔细研究会发现其规则,背景色和干扰素无论怎么变化,验证字符字符规整,颜色相同,所以排除干扰素非常容易,只要是非字符色素全部排除即可。
第三个图片,看似更复杂,处理上面提到背景色和干扰素一直变化外,验证字符的颜色也在变化,并且各个字符的颜色也各不相同。
看似无法突破这个验证码,本篇文章,就一这种类型验证码为例说明,第四个图片,同学们自己搞。
第四个图片,除了第三个图片上提到的特征外,又在文字上加了两条直线干扰率,看似困难其实,很容易去掉。



验证码识别技术研究与应用随着互联网技术的不断发展,验证码逐渐成为了一个保护网站或应用的重要手段。
很多网站都会在用户登录、注册、重置密码等操作时添加验证码。
验证码一般由数字、英文字母或汉字随机组合成,以防止机器人恶意攻击和大规模注册。
但是,由于验证码图像难以识别,人工识别成本过高,因此验证码识别技术成为了必须探索的课题之一。
一、验证码识别技术验证码识别技术是指通过计算机程序自动识别验证码。
通常,验证码识别技术可以分为两种方法:基于图像处理的验证码识别和基于模型的验证码识别。
基于图像处理的验证码识别是指对验证码图像进行预处理和特征提取,然后采用分类器进行识别。
基于模型的验证码识别是指采用机器学习的方法,通过模型训练来实现验证码的识别。
1. 基于图像处理的验证码识别基于图像处理的验证码识别一般包括以下几个步骤:1)去噪处理:为了清除验证码图像中的噪点,可以采用中值滤波、均值滤波等算法进行去噪。
2)验证码分割:由于验证码图像中的字符之间没有分隔符,需要对每个字符进行分割。
分割方法有垂直投影法、水平投影法、基于联通性的字符分割等。
3)验证码特征提取:为了将验证码图像转化为计算机可识别的数字,需要对验证码图像进行特征提取。
常用的特征提取方法有灰度矩、Zernike矩、Gabor滤波器等。
4)验证码分类:最后采用分类器对验证码进行分类,常用的分类器有KNN、SVM、随机森林等。
2. 基于模型的验证码识别基于模型的验证码识别通常采用机器学习的方法,主要包括以下几个步骤:1)数据采集:从互联网上采集大量的验证码图像数据。
2)特征提取:对采集到的验证码数据进行特征提取,常用的方法有HOG特征、SIFT特征等。
3)模型训练:对提取到的特征进行模型训练,采用SVM、随机森林等分类器进行分类模型的训练。
4)模型评估:对训练好的模型进行评估,以确定模型的精度和正确率。
5)应用部署:将训练好的模型应用于实际验证码的识别。
二、验证码识别技术的应用验证码识别技术在互联网领域的应用非常广泛,主要包括以下几个方面:1. 自动注册:很多网站为了防止恶意注册,设置了各种各样的验证码,但是验证码难以防范机器人注册。
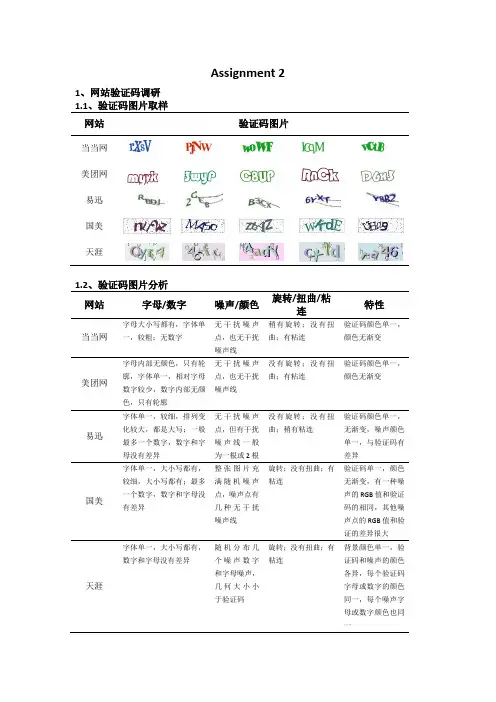
Assignment 2 1、网站验证码调研1.1、验证码图片取样网站验证码图片当当网美团网易迅国美天涯1.2、验证码图片分析网站字母/数字噪声/颜色旋转/扭曲/粘连特性当当网字母大小写都有,字体单一,较粗;无数字无干扰噪声点,也无干扰噪声线稍有旋转;没有扭曲;有粘连验证码颜色单一,颜色无渐变美团网字母内部无颜色,只有轮廓,字体单一,相对字母数字较少,数字内部无颜色,只有轮廓无干扰噪声点,也无干扰噪声线没有旋转;没有扭曲;有粘连验证码颜色单一,颜色无渐变易迅字体单一,较细,排列变化较大,都是大写;一般最多一个数字,数字和字母没有差异无干扰噪声点,但有干扰噪声线一般为一根或2根没有旋转;没有扭曲;稍有粘连验证码颜色单一,无渐变,噪声颜色单一,与验证码有差异国美字体单一,大小写都有,较细,大小写都有;最多一个数字,数字和字母没有差异整张图片充满随机噪声点,噪声点有几种无干扰噪声线旋转;没有扭曲;有粘连验证码单一,颜色无渐变,有一种噪声的RGB值和验证码的相同,其他噪声点的RGB值和验证的差异很大天涯字体单一,大小写都有,数字和字母没有差异随机分布几个噪声数字和字母噪声,几何大小小于验证码旋转;没有扭曲;有粘连背景颜色单一,验证码和噪声的颜色各异,每个验证码字母或数字的颜色同一,每个噪声字母或数字颜色也同一2.易迅网的验证码自动识别系统主要针对易迅网的验证码制作识别系统,其中易迅网的验证码和验证码特点如下:易迅网站字母/数字噪声/颜色旋转/扭曲/粘连特性易迅字体单一,较细,排列变化较大,都是大写;一般最多一个数字,数字和字母没有差异无干扰噪声点,但有干扰噪声线一般为一根或2根没有旋转;没有扭曲;稍有粘连验证码颜色单一,无渐变,噪声颜色单一,与验证码有差异2.1、识别系统的组成模块一般验证码识别需要完成以下图2.1的识别过程(图2.1)其中本识别系统包含了上述所有识别步骤,并总结为以下几大组成模块:1.预处理模块,包括了对验证码原图的灰度化、二值化、去噪;2.字符分割模块;3.字符识别模块;4.结果显示模块。




数字验证码的识别数字验证码很多地方都会用到,我前段时间也写过一篇有关于生成验证码的文章,那是随机生成大小不一,颜色不一,形状不一的数字图片,本文主要是针对那些比较规范的验证码的识别,何谓规范?规范就是数字的大小几乎一致,颜色对比度挺高,没什么干扰线.识别的依据就是最最最基础的办法,比对,先取样,保存成字模,再用字模去和将要识别的图片进行比较,取最接近的那个结果.不过在比较之前必须得到图片里面的数据提取出来并适当地去除一些干扰.下面就是识别部份的代码:/** ImageCode.java** Created on 2007年1月18日, 下午10:00** To change this template, choose Tools | Template Manager* and open the template in the editor.*/package net.bccn.hadeslee.programfan;import java.awt.image.BufferedImage;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.io.StreamTokenizer;import .URL;import javax.imageio.ImageIO;/*** 验证码识别程序* @author hadeslee*/public class ImageCode {private BufferedImage bi;private static int[][][] model=new int[5][10][208];//静态初始化块static{initNumModel();}/*** Creates a new instance of ImageCode*/public ImageCode() {initNumModel();}public String getNumber(InputStream is){try{bi= ImageIO.read( is );final StringBuffer sb=new StringBuffer();for(int i=0;i<4;i++){int[] data=this.getData(i);sb.append(this.doCheck(data));}return sb.toString();} catch(Exception exe){exe.printStackTrace();return "";}}/*** 重载的方法,根据传进来的参数得到返回的字符串 * @param bi* @return结果*/public String getNumber(BufferedImage bi){try{this.bi= bi;StringBuffer sb=new StringBuffer();for(int i=0;i<4;i++){int[] data=this.getData(i);sb.append(this.doCheck(data));}//System.out.println(sb.toString());return sb.toString();} catch(Exception exe){exe.printStackTrace();return "";}/*** 静态初始化方法,* 用于初始化字模*/private static void initNumModel(){try{//System.out.println("初始化model");for(int i=0;i<10;i++){StreamTokenizer st=new StreamTokenizer(new InputStreamReader(ImageCode.class.getRes ourceAsStream("/net/bccn/hadeslee/model/programfan_"+i+".mod")));st.whitespaceChars('#','#');st.whitespaceChars(',',',');st.eolIsSignificant(false);out:while(true){int token=st.nextToken();if(token==StreamTokenizer.TT_WORD){int who=0;int index=0;if(st.sval.equals("center")){who=0;}else if(st.sval.equals("left")){who=1;}else if(st.sval.equals("right")){who=2;}else if(st.sval.equals("up")){who=3;}else if(st.sval.equals("down")){who=4;}while(st.nextToken()==StreamTokenizer.TT_NUMBER){model[who][i][index++]=(int)st.nval;}st.pushBack();}else if(token==StreamTokenizer.TT_EOF){break out;}}}} catch(Exception exe){exe.printStackTrace();}//System.out.println("初始化结束model");}//通过传进来的字符串得到BufferedImage对象private BufferedImage getBI(String url){try {return ImageIO.read(new URL(url));} catch (IOException ex) {ex.printStackTrace();return null;}}/**根据索引得到*某一块的图像转为数组*的文件*/private int[] getData(int index){BufferedImage sub=bi.getSubimage(index*16,0,16,13);int iw=sub.getWidth();int ih=sub.getHeight();int[] demo=new int[iw*ih];for(int i=0;i<ih;i++){for(int j=0;j<iw;j++){demo[i*iw+j]=(sub.getRGB(j,i)==-1?0:1);}}return demo;}//根据传进来的数组,得到五个位置当中和差别最小的那个private int getMin(int who,int[] demo){int temp=208;for(int i=0;i<5;i++){int x=0;for(int j=0;j<demo.length;j++){x+=(model[i][who][j]==demo[j]?0:1);}if(x<temp){temp=x;}}//System.out.println("比对"+who+"最小值是"+temp);return temp;}//分析689或者0的方法,以免这几个数字混淆private int get689(int[] demo,int origin){boolean isLeft=false,isRight=false;int temp=-1;if((demo[75]==1&&demo[90]==1)||(demo[76]==1&&demo[91]==1)||(demo[58]==1&&demo[74]==1&&demo[90]==1)||(demo[59]==1&&demo[75]==1&&demo [91]==1)||(demo[60]==1&&demo[76]==1&&demo[92]==1)||(demo[28]==1&&demo[44]==1&&demo [60]==1)||(demo[27]==1&&demo[43]==1&&demo[59]==1)){isRight=true;}if((demo[131]==1&&demo[147]==1)||(demo[132]==1&&demo[148]==1)||(demo[133]==1&&de mo[149]==1)){isLeft=true;}if(isLeft&&isRight){temp=8;}else if(isLeft){temp=6;}else if(isRight){temp=9;}else{temp=origin;}if(temp==8&&(!((demo[103]==1&&demo[104]==1&&demo[105]==1&&demo[106]==1)||(demo[87]==1&&demo[88]==1&&demo[89]==1&&demo[90]==1)||(demo[103]+demo[104]+demo[105]+demo[106]+demo[87]+demo[88]+demo[89]+demo[90]>3)))){return temp=0;}return temp;}//比较传入的数据,返回最接近的值private int doCheck(int[] demo){int number=-1;int temp=208;for(int i=0;i<10;i++){int x=this.getMin(i,demo);if(x<temp){temp=x;number=i;}}//System.out.println("===========================================");if(number==6||number==8||number==9){number=this.get689(demo,number);}return number;}}下面是一些字模的内容,把它保存成相应的文件,并能让程序找到就可以了.比如这是0的字模,它在不同位字模,以此类推.这些字模都是先取到样本,然后再分类的#center0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,#left0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0, 0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0, 0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0, 0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0, #right0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0, 0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0, 0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0, 0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0, 0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0, 0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0, 0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0, 0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0, 0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0, 0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0, 0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0, 0,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0, #up0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0, 0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0, 0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0, 0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, #down0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,在此算法的实现中主要是针对比较规范的验证码,然后还要针对外形比较相似的6890进行分辨,实现识别的方式有很多种,大家仁者见仁,智者见智吧.不过,说句题外话,MOTO的识别就很牛,它对手写字体的支持都能达到很高的识别率,更不要说是正体了,这就是另外一个领域了.不是一两句代码就能搞得定的:)。

验证码识别技术模拟精灵是首个公开最有效的验证码识别技术的软件,使用模拟精灵制作了大量的免费、商用群发软件,对很多复杂BT的验证码都能成功的识别。
但是验证码仍然需要精湛的技术与足够的耐心。
请牢记这一点。
验证码识别不适合浮躁的人去做。
验证码识别是一项特殊的技术,任何一个公开的验证码识别代码都会很快的失效。
因为代码的公开后相关网站都会很快的更改验证码。
所以下面我只会介绍其原理。
在这里讨论验证码识别技术纯粹基于技术研究目的。
公开此技术也是为了让更多的网站采取更有效的防范措施。
禁止任何人利用这里介绍的验证码识别技术滥发垃圾信息。
本文介绍的验证码识别适用于比较复杂的图片验证码,也是大多数网站采用的方法。
有一些网站的验证码极简单,例如在网页中直接显示验证码字符而不是图片,或者图片的文件名直接就是验证码上的字符。
或者有其他规律可循,或者有其他明显的漏洞可以利用(例如通过改写访问验证码页面的源代码使验证码不刷新)。
这一类的验证码识别极其简单,只要熟练掌握web库、element库的函数即可,不需要使用下面介绍的方法。
一、下载验证码样本打开c:\test文件夹,选“查看缩略图”,然后重复运行下面的LAScript脚本,每运行一次,就查看c:\test下自动生成的图片,把图片上的字符改为文件名.例如图片上面显示5,就把文件名改为5.jpg.如果变化比较复杂的验证码,可以对每个字符多用几个样本,第一个字符为验证码字符,第二个字符可以为任意字符。
例如:5a.jpg , 5b.jpg , 5c.jpg ...........等等。
样本多就会识别能力就越强。
img = image.new();--下载图像,没有后缀名要显示指定*.bmp格式img:getURL("http://www.***.com/test.asp","*.png");assert(img:ok(),"下载验证码失败");img:Crop(4 ,3 , 56 ,18 )img:save("c:\\test\\test.jpg") --保存到硬盘--折分图片,指定一行四列img2,img3,img4,img5 = img:split(1,4);img2:save("c:\\test\\0001.jpg")img3:save("c:\\test\\0002.jpg")img4:save("c:\\test\\0003.jpg")img5:save("c:\\test\\0004.jpg")image.del(img);如何确定图片后缀名在整个验证码识别过程中,格式与后缀名一定不能搞错,否则就会失败。
验证码识别步骤---完美ESALES系统验证码识别过程(含图
片)
验证码识别步骤---完美ESALES系统验证码识别过程
(含图片)
由于本人最近工作较忙,因此零散的给出一些常用验证码的
识别算法,写的不是很详细,需要的请QQ跟我联系详谈
完美ESALES系统的验证码步骤
1、灰度滤色(将图片的色彩转化为黑白图片,即灰度化,
然后根据灰度值分辨出有效的颜色和无效的颜色,譬如说我
们这里采用的是:L(0-148),即表示是将灰度值为0-148的规整出来作为有效值1,其他的都为无效值0)
2、连点去噪(将图片根据字符下限和字符上限的值进行分
割,譬如说这里就表示需要分割为4个字符,由于完美的验证码图片经过灰度滤色以后,就直接的消除了背景色和噪点,所以我们这里不需要再进行其他的处理,直接的进行连点去噪就可以)
3、图像分割(将图像根据01分割为4个小图片)
4、统一大小(为了方便辨认,我们这里将图像统一的变为
40 X 40的模拟图像)
5、检查(这里先从库中读取每个字符跟获取的字符信息的相似值,然后从中选取小于500的跟这个字符最相近的字符作为这个验证码识别出来的字符)。
验证码原理验证码(Verification Code)是一种用于确认用户身份或者防止恶意攻击的安全技术手段。
它通常以图形、文字、数字或者声音等形式呈现,要求用户根据提示进行输入或者操作,以验证其身份或者完成某项操作。
验证码的原理是基于人机识别的技术,通过要求用户完成特定的任务来确认用户的身份或者意图,从而提高系统的安全性。
验证码的原理主要包括以下几个方面:一、图形识别。
图形验证码是最常见的一种验证码形式,它通常以扭曲的文字、数字或者图案的形式呈现给用户,要求用户根据提示输入相应的内容。
图形验证码的原理是利用计算机生成扭曲的图形,使得机器很难识别其中的内容,但对于人类来说相对容易识别,从而实现了人机识别的差异化。
二、声音识别。
除了图形验证码,声音验证码也是一种常见的形式。
它通过播放一段语音内容,要求用户根据内容进行相应的操作,比如回答问题或者输入特定的内容。
声音验证码的原理是利用声音的特征,要求用户进行相应的识别和回应,从而确认用户的身份或者意图。
三、数字识别。
数字验证码通常以数字的形式呈现给用户,要求用户进行输入或者计算。
比如简单的加减乘除运算、数字序列填充等形式。
数字验证码的原理是利用数字的特性,要求用户进行相应的计算或者输入,从而确认用户的身份或者意图。
四、行为识别。
除了以上几种形式,还有一种行为验证码,它要求用户进行特定的操作,比如拖动滑块、点击特定区域、摇晃手机等。
行为验证码的原理是利用用户的操作行为,通过特定的操作来确认用户的身份或者意图。
总的来说,验证码的原理是利用人机识别的差异,通过要求用户进行特定的任务来确认用户的身份或者意图。
它可以有效防止恶意攻击、刷票、注册机等行为,提高系统的安全性。
随着技术的发展,验证码的形式也在不断创新和改进,以适应不同场景和需求的安全验证。
验证码技术的应用将会越来越广泛,成为网络安全的重要保障手段。