层次分析法指标矩阵构建
- 格式:docx
- 大小:14.28 KB
- 文档页数:1
层次分析法的具体步骤(1)建立层次结构模型如上所述,家纺纺织产业实施循环经济评价指标体系可被分为四层,最上层为最高层(目标层),即纺织企业循环经济各个方面的综合水平;第二层为准则层,即相互独立、分别隶属于总系统层的子系统;第三层为指数层,是对准则层的进一步细分和阐述;最底层为指标层,该层隶属于准则层,是对纺织企、Ek循环经济各个方面具体的评价指标。
在层次分析法巾多采用三层分析,即目标层、准则层和指标层。
(2)构造比较判断矩阵根据层次结构模型,通过对某层次中各元素的相对重要性做出比较判断,即对于上一层次某一推则而言,在其下一层次中所有与之相关的元素中依次两两比较,从而得出逐层进行判断评分,进而构成两两判断矩阵,如表6—2所示。
如A1,A2,…,久,在考虑相对上一层准则H:前提下构造判断矩阵H‘—A。
具体的做法是:先将矩阵左侧的指标A1依次与矩阵上边一排所列的指标Al—A。
相对于目标Hf做两两比较,比较结果按AHP法设计的范围标度(表6—3)对它的重要性给予量化,并相应填入矩阵第一行;接着依次用左列指标A2,A3,…,A4重复进行上述比较,以完成矩阵的第二行至第n行。
对于每个准则层以及每个准则下的指标群,进行同样过程,这样也就形成了多级比较判断矩阵。
AHP采用这种标度方法,不仅能克服一些指标和指标子系统无标度情况下无法测量、统计等困难,而且这种标度法有特定的科学依据,这主要表现为:第一。
实验心理学有关研究表明,人们对不同程度刺激的感觉区别,最佳的区别个数为7土2,若取其最大的极限,恰好是9个。
也就是说,人们对某个事物的属性同时进行比较,要使其前后的判断基本保持一致,最多只能对9个不向事物向时进行比较判断。
按照人们惯用的相邻标度差为1的离散标度值确定法,对1—9种事物进行比较判别时,其比例标度恰好为[1,9]间的整数。
第二,人们在估计事物问区别时,习惯采用五种判断表述:相等、较强、强、4硼、绝对强。
若需要更高精度,还可在这五种相邻判断之间做出比较,这样共有9个等级。

中国健康教育2225年3月第37卷第3期•论著•层次分析法在建立网络健康信息评价指标体系权重中的应用许燕,徐锦杭,赵玉遂,吴青青,徐水洋【摘要】目的研究确定网络健康信息评价指标权重。
方法采用层次分析法确定网络健康信息评价指标权重。
结果咨询专家平均(48.55±6.47)岁,91.67%的专家具有高级职称,平均工作年限(23.64±9.63)年;3项二级指标信息特性、媒体特性及发布特性的归一化权重分别为0.d.0.22、0.55;三级评价指标总权重中,“信息准确性”所占权重最高,为0.21;其次为“作者的权威性”,占0.13。
结论初步确定了网络健康信息评价指标体系及指标权重,对我国的网络健康信息评价有一定的指导作用。
【关键词】层次分析法;互联网;健康信息;权重【中图分类号】R193【文献标识码】A【文章编号】1002-9982(2021)03-0213-04DOI:1516168/j.cda in/1002-9982.202043.005AppUchUon of anCyhc hierorchy process in determining weighs of eveluahon inden system foe internes health information XE Yan,XE Jin-Tang,ZHAO Yu-sui,WE Qing-qing,XE Shui-qang3Zhejiaag Prninca Centefoe Disease Control and Prevention,Hngzhn315451,Chiua【Abshoct】Objective To determiuc the weight oS evaluation index system fos interuct health informatio/Methodi The weight oS evaluation index system oS interuct health ii/ormation was determiued by mD/analytic hierarchy process and Delphi methoks.Resalts The mean ano oS experts was48.55(39-64)years old,and91.67%oS the experts hat high professional titles and the mean worUin/years in their owu areas were23.64(15-46)years.The uormalized weights oS information characterisPcs,media characteristics and pubPshD/characterisPcs in the second-level indicators were0.60,0.22and0.D,respectivep.Weight of information accaracy was the highest in the thirU-levoi evaluation index(which wasaroped0.01),then followed bs amhor amhontanve(accop/D/fos0.53).Conclusion Evapation index system oS Dtefl vet health information and its weights were ini/ally identified which wopld plby a certain auidin/role in interuct health infofl mation evapation in Chiun[Ken woresi Aualytiv hierarchy process;Internet;Health iDormation;Weight随着我国网民规模的扩大及互联网普及率的不断提升,互联网凭借其海量信息、便利性和时效性的优点[1],成为网民深入了解健康相关信息的重要窗口。




为困难。
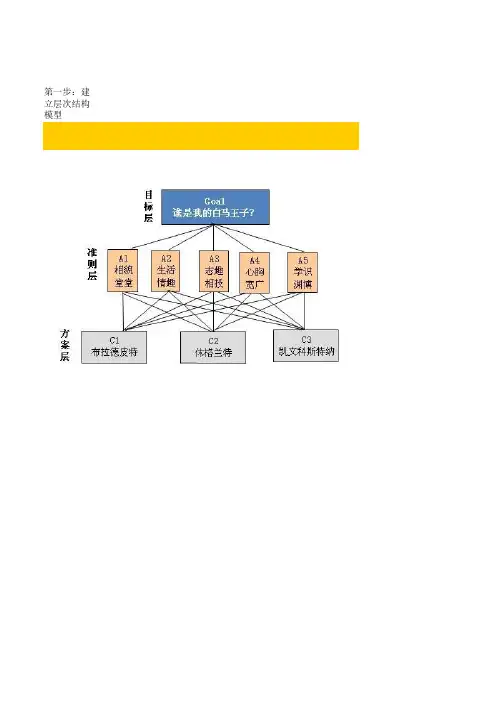
本文根据层次分析法(AHP),根据城市灾害应急内容的特点做相应的转换处理,在众多参考因子中选取了能较综合反映城市灾害应急能力且没有重复内容的6个一级评价指标(城市灾害监测与预警能力;城市灾害防御能力;城市居民的应急反应能力;政府部门的快速反应能力;应急救援能力;资源保障能力)和多个二级评价指标(图2)。
图2 城市灾害应急能力评价指标体系的层次模型(二)评价指标的构建根据评价质保体系设置的原则和指标选取的方法,结合城市灾害管理的相关特点,运用系统理论中的曾测分析法对城市灾害应急能力评价指标体系进行构建。
(如表1)表1 城市灾害应急能力的评价指标体系城市灾害应急响应能力(A)灾害监测预报能力(B1)政府部门快速反应能力(B4)灾害防御能力(B2)应急救援能力(B5)城市居民应急能力(B3)应急资源保障能力(B6)已有灾害的监测预报能力(C1)预报精度的高低(C4)公共防灾意识的普及程度(C7)有无编制灾害应急预案(C10)灾害损失评估能力(C13)医疗救助能力(C16)救灾物资供应能力(C19)灾民安置能力(C22)对可能存在灾害的监测预报能力(C2)城市建筑抗灾能力的大小(C5)公共参与防灾演习情况(C8)指挥部门到达现场的速度(C11)灾害信息的发布能力(C14)救援队伍的人力投入(C17)通讯能力(C20)灾害立法的情况(C23)预警设备的完善情况(C3)防御措施的情况(C6)公众对防灾计划了解情况(C9)现场指挥救灾能力(C12)居民的自救能力(C15)救灾资金的储备情况(C18)运输能力(C21)三、城市灾害应急能力评价指标权重计算(一)评价指标判断矩阵的构建1、矩阵的建立信息是系统分析最基础的数据,任何系统分析都要掌握一定的信息才能进行,层次分析法也需要有相应的信息作为分析的基础,其信息的主要来源于人们对不同层次中各个元素之间的相对重要性作出的判断。
通过引入适当的判断标度将这些判断用数值的形式表示出来,构成判断矩阵,以便比较本层次的各因素与某一因素之间的相对重要程度。


[收稿时间]2020-08-19[作者简介]刘久伟(1990—),男,内蒙古人,本科,研究方向:高等教育学。
李佳旭(1994—),男,吉林人,硕士研究生,研究方向:教育经济与管理。
[摘要]公共管理类专业的专业性较弱而综合性较强,因而其学生的职业能力一直受到关注却缺乏完备的评价体系,同时高校对于本领域专业学生的职业能力培养也缺乏整体性和针对性。
文章基于当代大学生职业能力评价体系的构建原则,结合公共管理类专业的特点,采用AHP 层次分析法构建大学生的职业能力评价体系,并使用模糊综合评价进行了实证研究,得出并检验了公共管理专业学生最应该发展的职业能力,为高校对公共管理类专业的课程改革提供理论支持。
[关键词]职业能力;评价指标体系;层次分析法;模糊综合评价[中图分类号]G640[文献标识码]A [文章编号]2095-3437(2022)03-0234-032022年3University Education一、背景为了推动我国社会主义建设和经济发展,教育部决定从1999年开始支持全国普通高校持续扩大招生规模,我国的高等教育逐渐从精英教育转变为大众教育,由此造成的教育过度使得人才市场的总供给大于总需求[1-2]。
据统计,2019年我国普通高校应届毕业生达到834万人,2020年更是再创新高,达到874万人,就业形势不容乐观。
在新冠肺炎疫情的影响下,“就业难”问题愈加凸显,然而学生自身的职业能力是否符合经济社会和岗位需要也值得深思[3]。
职业能力是学生通过目前高等教育培养所获得的从事某种职业所应该具备的能力的总和[4]。
由于缺乏对大学生职业能力的评价标准,目前部分高校的人才培养体系和培养目标存在过于理想化和理论化的问题。
本文以公共管理专业为例,以市场需要为导向,以大学生职业能力为核心,通过构造评价指标体系,为提升公共管理专业学生的职业能力提供人才培养模式和方向的理论依据。
二、大学生职业能力评价指标体系的设计原则(一)科学性原则在本研究中,科学性原则是建立评价指标体系的首要原则,同时也是所有科研设计的第一原则,只有建立在科学性基础上的研究才具有可信度和现实意义。

基于德尔菲法和层次分析法的现代医院门诊医疗质控指标体系构建与应用①中国医学科学院北京协和医院,100730 北京市东城区帅府园1号■ 张宇斐① 柴建军① 胡冰水① 申 思① 胡英莉① 赵玉芳① 王 治①马玉芬① 洪成伟① 柳昭羽①【摘 要】目的:构建一套科学、规范且能适用于门诊医疗服务质控指标体系,以期为门诊质控管理提供科学依据。
方法:运用德尔菲法确立门诊医疗质控指标体系,采用层次分析法确定指标权重。
结果:构建了门诊质控指标体系,包括3个一级指标、7个二级指标和19个三级指标, 专家积极系数、权威程度和意见协调程度均较好。
结论:初步构建了一套现代医院门诊医疗质控指标体系,指标针对性强,结构合理,具有较强的科学性和实用性。
【关键词】德尔菲法 层次分析法 门诊医疗质控 指标体系中图分类号 R197.3 文献标识码 A DOI 10.19660/j.issn.1671-0592.2021.3.11Study on the construction and application of evaluation index system of outpatient medical quality control based on Delphi method and AHP/ ZHANG Yufei, CHAI Jianjun, HU Bingshui, SHEN Si, HU Yingli, ZHAO Yufang, WANG Zhi, MA Yufen, HONG Chengwei, LIU Zhaoyu// Chinese Hospitals. -2021,25(3):36-39【Abstract】Objective: To develop a scientific, standardized, and practical index system of outpatient medical quality control, and to provide a scientific basis for quality evaluation and comprehensive quality management. Methods: Delphi method was used to select the index and establish an evaluation index system. AHP was used to determine the weights of the index. Results: The system of outpatient medical quality control, including3 primary indexes, 7 secondary indexes and 19 third indexes, was finally established. Experts' positive coefficient, authority and opinions were well coordinated. Conclusion: Being scientific and practical, the index system was relevant to the point and had a reasonable structure.【Key words】delphi method ,analytic hierarchy process ,outpatient medical quality control ,index system Author's address:Peking Union Medical College Hospital, Chinese Academy of Medical Sciences, No. 1,Shuaifuyuan, Dongcheng District, Beijing, 100730, PRC医疗质量直接关系到人民群众的健康权益和对医疗服务的切身感受,抓好质量管理,对促进当前现代医院形成可持续发展的管理模式和监督机制具有重要意义。
层次分析法(AHP )评价模型1.层次分析法简介层次分析法简称AHP (The analytic hierarchy process),由美国的运筹学家T.L.Saaty 提出。
层次分析法要求明确项目的总目标,将其分解为各层子目标、准则层、指标层甚 至指标,构建一种递阶层次结构;构造两两判断矩阵,求解判断矩阵的特征向量,得到 每层的元素相对于上一层次的权重;采用加权的方法确定方案层各指标对总F1标的权 重,反映不同指标的相对重要性。
层次分析法通过制定标准,对难以量化的定性指标标 准化数学运算处理,转化为可以量化的数据,是一个定性和定量结合的方法。
2.层次分析法的一般步骤(1)确定评价目标和范围,构造递阶层次结构。
(2) 构造两两比较矩阵(判断矩阵)对于同一层次的各因素关于上一层中对应准则(目标)的重要性进行两两比较,构造出两两比较的判断矩阵。
用标度法表示比较结果。
如表所示:判断矩阵标注及其含义注:ij C ={2,4,6,8,1/2,1/4,1/6,1/8}表示重要性等级介于 ij C ={l,3,5,7,9,l/3,l/5,l/7,l/9}。
根据此表可以得到对于同一层次指标的判断矩阵mm A ,mm ij m a a a a A )(},...,,{21==A 的性质如下: ①0>ij a ②ijij a a 1=③1==ij a j i 时, (3)由比较矩阵计算被比较因素对上一层对应准则的相对权重(归一化特征向量),并进行判断矩阵的一致性检验。
(4)计算指标层对总目标的组合权重和组合一致性检验,得出各指标对总目标的影响权重。
3.一致性检验由于指标采用的两两比较,有可能出现甲的重要性大于乙、乙的重要性大于两、丙 的重要性却大于甲的情况,因此,确定计算相对权重后要进行組阵一致性判断,矩阵一 致性指标记为CI1max --=n nCI λRICI CR =RI 是平均随机一致性指标,判断矩阵的阶数不同,RI 的取值也不同,RI 的取值见表平均随机一致性指标的取值当时,判断矩阵通过一致性检验,得到的权重具有可信性。
95技术·工具基于熵值法和层次分析法的绩效管理指标体系构建与优化余书俏(景德镇陶瓷大学)摘要:绩效管理是现代企业管理中的重要环节,其目的是通过对企业的各项业务进行全面、科学的管理,实现企业的长期发展目标。
绩效管理需要建立科学合理的指标体系,以评估企业的各项业务表现,及时发现并解决相关问题,然而传统的绩效管理指标体系往往以财务指标为主,会忽视非财务因素的影响,导致指标体系存在单一性和不全面性,影响了绩效管理的效果。
因此,构建和优化适用于企业绩效管理的指标体系是非常有必要的。
关键词:熵值法;层次分析法;绩效管理;指标体系绩效管理在现代企业管理中起着至关重要的作用,其不仅能够帮助企业监控和评估绩效,还能促进企业的持续发展。
本文引入熵值法和层次分析法来构建和优化绩效管理指标体系,熵值法是一种基于信息熵的评估方法,可以帮助企业确定指标的权重,确保指标在绩效管理中的重要性得到充分体现。
层次分析法则可以帮助建立指标之间的层次结构,并确定它们的重要性,从而确保指标体系的合理性和可操作性。
绩效管理评价概述绩效管理是企业管理中至关重要的一环,它可以帮助企业提高员工和团队的工作效率,实现企业发展和目标的持续增长,而绩效管理评价则是绩效管理的核心部分,它是对员工和团队绩效进行评估和分析的过程。
绩效管理评价主要包括目标设定、绩效评估和反馈三个方面。
在目标设定阶段,企业需要明确制定员工和团队的工作目标,并将其与企业的总体战略和目标进行对接,确保员工和团队的工作与企业的发展方向一致,更好地促进企业实现发展目标。
在绩效评估阶段,企业需要根据员工和团队的工作目标和表现,对其工作绩效进行评估和分析,如360度评估、绩效考核、关键绩效指标(KPI)评估等。
通过这些评估,企业可以更全面、更客观地了解员工和团队的工作状态,并为进一步提高绩效提供有力支持和指导。
构建绩效管理指标体系的方法一、熵值法熵值法是一种评价指标重要程度的方法,它通过计算指标在总体中的相对重要性来辅助绩效管理决策。
旅游业发展水平评价问题摘要为了研究比较两个旅游城市Q、Y的旅游业发展水平,建立层次分析法]3[数学模型,对两个旅游城市Q、Y的旅游业发展水平进行了评价.首先,通过对题目中的图1、表1进行了分析与讨论,根据层次分析法,建立了目标层A、准则层B和子准则层C、方案层D四个层次,通过同一层目标之间的重要性的两两比较,得出判断矩阵,利用]1[MATLAB编程对每个判断矩阵进行求解.其次,用MATLAB软件算出决策组合向量,再比较决策组合向量的大小,由“决策组合向量最大”为目标,得出城市Y的决策组合向量为0.4325,城市Q组合向量为0.5675.最后,通过城市Q旅游业发展水平与旅游城市Y旅游业发展水平的决策组合向量比较,得出城市Q的旅游业发展水平较高.关键词层次分析法MATLAB旅游业发展水平决策组合向量1.问题重述本文要求分析QY,两个旅游城市旅游业发展水平,并且给出了两个城市各方面因素的对比,如城市规模与密度,经济条件,交通条件,生态环境条件,宣传与监督,旅游规格,空气质量,城市规模,人口密度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP,外贸依存度,市内外交通,人均拥有绿地面积,污水集中处理率,环境噪音,国内外旅游人数,理赔金额,立案数量,A级景点数量,旅行社数量,星级饭店数量.建立数学模型进行求解.2.问题分析本文要求分析QY,两个城市的分析Y,两个旅游城市旅游业发展水平,在对Q中,发现需要考虑因素较多,第一、城市规模与密度,包括城市规模与人口密度.第二、经济条件,包括外贸依存度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP.第三、交通条件,包括市内外交通.第四,生态环境条件包括空气质量,人均绿地面积,污水处理能力,环境噪音.第五、宣传与监督,包括国内外旅游人数,游客投诉立案件数.第六、旅游规格,包括A级景点个数,旅行社个数,星级饭店个数,这就涉及到层次分析法来估算各个指标的权重,评出最优方案.具体内容如下:(1)本文选择了对QY,两个旅游城市旅游业发展水平有影响的19个指标作为评价要素,指标规定如下:城市规模:城市的人口数量.人口密度:单位面积土地上居住的人口数.是反映某一地区范围内人口疏密程度的指标.人口影响城市规模.人口密度越大城市规模也就越大.人均GDP:即人均国内生产总值.人均城建资金:即用于城市建设的资金总投入.第三产业增加值:增加值率指在一定时期内单位产值的增加值.即第三产业增加值越高越能带动城市经济的发展.税收GDP:税收是国家为实现其职能,凭借政治权力,按照法律规定,通过税收工具强制地、无偿地征收参与国民收入和社会产品的分配和再分配取得财政收入的一种形式.外贸依存度:即城市对于外贸交易的依赖程度.市内交通:即城市市区交通情况.市外交通:即城市郊区交通情况.市内交通与市外交通对于城市交通条件具有同等的重要性.空气质量:即城市总体空气质量情况.空气质量越好对于城市生态环境就越好.人均绿地面积:即反应城市绿化面积以及人口密度的比值关系.污水处理能力:城市污水处理水平.环境噪音:城市环境噪音情况.国内外旅客人数:国内外来旅客一年总人数.人数越多说明宣传与监督就越好.理赔金额:即立案后需要赔付的资金数.立案件数:即在旅游时发生违法事件后公安部立案的件数.A 级景点数量:即A 级景点的个数.A 级景点越多,越能带动旅行社数量以及星级饭店数量,则旅游规格越大.旅行社数量:即旅行社的个数.星级饭店数量:即星级饭店在旅游景点的个数.(2)用层次分析法建立模型,根据判断矩阵,利用MATLAB 软件,算出每个判断矩阵的特征向量W 、最大特征根c 、一次性指标CI ,再结合随机一次性指标,得出每个指标的特征向量.(3)用(2)得出的数据,运用MATLAB 软件算出两个城市的决策组合向量,做比较.3.模型假设1.假设两个城市Q 、Y 的人口流动不大.2.假设两个城市Q 、Y 的各项指标短期内不会发生太大的改变.4.符号说明A : 表示目标层;j B : 表示准则层第j 个指标的名称)6,,2,1( =j ;i C : 表示子准则层第i 个指标的名称()19,,2,1 =i ; q D : 表示方案层第q 个指标的名称()2,1=q ;1w : 表示准则层对目标层的特征向量组成的矩阵; 2w : 表示子准则层对准则层的特征向量组成的矩阵; 3w : 表示方案层对子准则层的特征向量组成的矩阵;CI : 表示一次性指标;CR : 表示随机一次性指标; Z : 表示决策组合向量.5.模型建立与求解5.1 根据层次分析法分析以及题目中的图1可以建立如下表5-1的层次分析结构,并构造两两比较判断矩阵在递阶层次结构中,设上一层元素B 为准则层,所支配的下一层元素为1C ……19C ,要确定元素1C ……n C 对于准则层B 相对的重要性即权重,可分为两种情况:(1)如果1C 2C ……n C 对B 的重要性可定量,其权重可直接确定; (2)如果问题复杂,1C 2C ……n C 对B 的重要性无法直接定量,而是一些定性的,确定权重用两两比较方法.(3)其方法是,对于准则层C ,元素i C 和j C 哪一个更重要,重要多少,按1-9比例标度对重要性程度赋值.表5-2中列出了1-9标度的含义.对于准则B ,n 个元素之间相对重要性的比较得到一个两两比较判断矩阵P =()mxn ij P ,表示其中ij P 表示i P 和j P 对B 的影响之比,显然ij P >0,ij P =ijP 1,ij P =1,由ij P 的特点,P 称为正互反矩阵.通过两两判断矩阵用方根法求出他们的最大特征根和特征向量,求法如下: 1. 判断矩阵每一行元素的乘积,其中ij n1j 1p m =∏=,i =1,2…,n .2. 计算i m 的n 次方根_i w ,_i w =n i m .3. 对向量Tn w w w ⎪⎭⎫ ⎝⎛=__1,...,归一化,即∑==n j ji w 1__i w w ,则Tn w w w ⎪⎭⎫⎝⎛=__1,...,为所求的特征向量.4. 计算判断矩阵的最大特征跟m ax λ,()∑==n1max i iinw pw λ,式中()i pw 表示pw 的第i 个元素.5. 定义⎪⎭⎫ ⎝⎛--=1max n n CI CI λ为矩阵A 的一致性指标,为了确定A 的不一致性程度的容许范围,需要找出衡量A 的一致性指标CI 的标准.引入随机一致性指标RI .平均随机一致性指标RI 是这样得到的;对于固定的n ,随机构造正互反矩阵A ,其中ij a 是从1,2,……9,91......31,21中随机抽取的,这样的A 是最不一致的,取充分大的样子(500个样本)得到A 的最大特征跟的平均值m ax λ,定义⎪⎭⎫ ⎝⎛--=1max n n RI λ,对于不同的n 得出随机一致性指标RI 的数值如下表5-3表中n =1,2时RI =0,是因为1,2阶的正互反矩阵总是一致阵.令RICICR =,称CR 为一致性比率,当CR <0.1时,本文认为判断矩阵具有满意的一致性,否则就需要调整判断矩阵,使之具有满意的一致性.最后通过计算得出下表5-4(其中n B 表示准则层的特征向量中的第n 个数值,in C 表示指标层的特征向量第n 个准则对第j 个指标的数值)层次总排序一致性检验的方法j n1CI c CI j j ∑==j n 1c RI RI j j ∑==RICI CR =若1.0CR时,所以认为判断矩阵具有满意的一致性,否则就需要调整判断.矩阵,使之具有满意的一致性.5.2根据层次分析法求出各个指标的权重依据题目中的表1分析,对本题做出其中一种假设:(1)经济条件和交通条件重要性相当,生态环境条件最重要,旅游规格、宣传与监督、城市规模与密度依次次之.(2)在城市规模与密度中,城市人口比人口密度重要一点.(3)在经济条件中,第三产业增加值GDP第一重要,其次是人均GDP,税收GDP、外贸依存度、人均城建资金依次次之.(4)在交通条件中,市内交通和市外交通的重要性相当.(5)在生态环境条件中,空气质量第一重要,其次是人均绿地面积,污水处理能力、环境噪音依次次之.(6)在宣传与监督中,国内外旅游人数第一重要,理赔金额、游客投诉立案件数重要性相当.(7)在旅游规格中,A级景点个数第一重要,星级饭店个数、旅行社个数依次次之.(8)对于城市规模,城市Q比城市Y的重要性小一些;对于人口密度,城市Y比城市Q的重要性明显重要;对于人均GDP,城市Q比城市Y的重要性稍重要;对于人均城建资金,城市Q比城市Y的重要性稍微重要;对于第三产业增加值GDP,城市Q比城市Y的重要性小一些;对于税收GDP,城市Q比城市Y的重要性稍小一点;对于外贸依存度,城市Q比城市Y的重要性稍重要;对于市内交通,城市Y比城市Q的重要性稍重要一点;对于市外交通,城市Y比城市Q的重要性比稍重要小一点;归于空气质量,城市Q比城市Y的重要性相当;对于人均绿地面积,城市Y比城市Q的重要性稍重要;对于污水处理能力,城市Y比城市Q的重要性稍重要一些;对于环境噪音,城市Q比城市Y的重要性相当;对于国内外旅游人数,城市Q比城市Y的重要性稍重要;对于理赔金额,城市Q比城市Y的重要性稍重要一些;对于游客投诉立案件数,城市Q比城市Y的重要性稍重要;对于A级景点个数,城市Y比城市Q的重要性稍重要小一些;对于旅行社个数,城市Y比城市Q的重要性稍重要小一些;对于星级饭店个数,城市Q比城市Y的重要性相当.根据上述分析,按1-9比例标度对准则层对目标层、子准层对准则层、目标层对子准则层的重要程度进行赋值,构造准则层对目标层的判断矩阵、子准则层对准则层的判断矩阵、方案层对子准则层的判断矩阵.准则层()6,,2,1 =j B j 对目标层A 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=12312121321141313123412252321114232111431215141411A 利用MATLAB 软件(附录1)求得 最大特征值0719.6max =λ特征向量⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=1219.00753.03422.02057.02057.00492.01w一致性检验比率1.00116.0<=CR所以矩阵满足一致性检验.子准则层21,C C 对准则层1B 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=131311B利用MATLAB 软件(附录2)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层76543,,,,C C C C C 对准则层2B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=121412312131321431522131511413221412B 利用MATLAB 软件(附录3)求得 最大特征值0681.5max =λ特征向量⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=0973.01599.04185.00618.02625.0w一致性检验比率1.00152.0<=CR所以矩阵满足一致性检验.子准则层98,C C 对准则层3B 的判断矩阵⎥⎦⎤⎢⎣⎡=11113B 利用MATLAB 软件(附录4)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层13121110,,,C C C C 对准则层4B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎣⎡=1121311121312212133214B 利用MATLAB 软件(附录5)求得最大特征值0104.4max =λ特征向量⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=1409.01409.02628.04554.0w 一致性检验比率1.00038.0<=CR所以矩阵满足一致性检验.子准则层161514,,C C C 对准则层5B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211212215B 利用MATLAB 软件(附录6)求得最大特征值0536.3max =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=3108.01958.04934.0w 一致性检验比率1.00462.0<=CR所以矩阵满足一致性检验.子准则层191817,,C C C 对准则层6B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211312316B 利用MATLAB 软件(附录7)求得最大特征值0092.3max =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=2970.01634.05396.0w 一致性检验比率1.00079.0<=CR所以矩阵满足一致性检验.方案层对子准则层的判断矩阵 方案层21,D D 对子准则层1C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层2C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155112C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=1667.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层3C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133113C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层4C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=144114C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层5C 的判断矩阵:⎥⎥⎦⎤⎢⎢⎣⎡=122115C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎢⎣=3333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层6C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层7C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=141417C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层8C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155118C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=8333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层9C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122119C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层10C 的判断矩阵⎥⎦⎤⎢⎣⎡=111110C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层11C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1313111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=7500.02500.0w因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层12C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1414112C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2000.08000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层13C 的判断矩阵⎥⎦⎤⎢⎣⎡=111113C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层14C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331114C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2115⎥⎥⎦⎤⎢⎢⎣⎡=1441115C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层16C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层17C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331117C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2118⎥⎥⎦⎤⎢⎢⎣⎡=1221118C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层19C 的判断矩阵:⎥⎦⎤⎢⎣⎡=111119C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 通过准则层()6,,2,1 =j B j 对目标层A 的判断矩阵、子准则层()19,,2,1 =i C i 对准则层()6,,2,1 =j B j 的判断矩阵得出特征向量,建立层次总表5-5层次总排序一致性检验如下:0073.061==∑=j j j CI B CI65274.0j 61j j ==∑=RI B RI0111.065274.00073.0===RI CI CR 由于1.00111.0<=CR ,所以认为层次总排序的结果具有满意的一致性,因此不需要重新调整判断矩阵的元素取值.5.3 利用MATLAB 进行决策组合向量的运算(附录9)⋅⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=⋅⋅=Tw w w Z 2970.0001634.0000005396.00000003108.0000001958.0000004934.00000001409.0000001409.0000002628.0000004554.00000005000.0000005000.00000000973.000001599.0000004185.0000000618.0000002625.00000002500.0000007500.0132⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡5000.05000.06667.03333.06667.03333.02500.07500.08000.02000.02500.07500.05000.05000.02000.08000.07500.02500.05000.05000.06667.03333.01667.08333.08000.02000.02500.07500.06667.03333.02000.08000.02500.07500.08333.01667.03333.06667.0⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡⋅1219.00753.03422.02057.02057.00492.0 Z ⎥⎦⎤⎢⎣⎡=5675.04325.0 比较Z 值大小可知,12Z Z >,表明城市Q 的旅游发展也水平最高,城市Y 的旅游业发展水平次之,所以城市Q 的旅游发展也水平高.6模型的评价优点:(1) 本文选择了计算比较简单的层次分析法,经过计算得到了相应的综合发展旅游业的估计值,为城市旅游业的发展提供了依据.(2) 使用了MATLAB 软件,减少了计算工作量,大大降低了运算的困难.缺点:判断的结果具有一定的主观性,不能比较切实的结合当地的具体情况,做出科学的决策方案.7参考文献[1] 姜启源等,数学建模(第四版)北京:高等教育出版社.2011年[2] 马莉,数学实验与建模,北京:清华大学出版2010年[3] 王莲芬,层次分析法引论,北京:中国人民大学出版社,1990年附录:附录1x=[1 1/4 1/4 1/5 1/2 1/3;4 1 1 1/2 3 2;4 1 1 1/2 3 2;5 2 2 1 4 3;2 1/3 1/3 1/4 1 1/2;3 1/2 1/2 1/3 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-6)/5 %一致性指标CR=CI/1.24 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =6.0719W =0.04920.20570.20570.34220.07530.1219B =0.04670.21410.21410.29180.08810.1452CI =0.0144CR =0.0116C =0.2146附录2:>> x=[1 3;1/3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250附录3:x=[1 4 1/2 2 3;1/4 1 1/5 1/3 1/2;2 5 1 3 4;1/2 3 1/3 1 2;1/3 2 1/4 1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-5)/4 %一致性指标CR=CI/1.12 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =5.0681W =0.26250.06180.41850.15990.0973B =0.27340.05940.36640.18730.1135CI =0.0170CR =0.0152C =0.2698附录4:x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录5:x=[1 2 3 3;1/2 1 2 2;1/3 1/2 1 1;1/3 1/2 1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-4)/3 %一致性指标CR=CI/0.90 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =4.0104W =0.45540.26280.14090.1409B =0.43950.27870.14090.1409CI =0.0035CR =0.0038C =0.3131附录6:x=[1 2 2;1/2 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0536W =0.49340.19580.3108B =0.46060.18790.3515CI =0.0268CR =0.0462C =0.3733附录7:x=[1 3 2;1/3 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0092W =0.53960.16340.2970B =0.51990.16200.3181CI =0.0046CR =0.0079C =0.4015附录8:% 目标层Q,Y对子准则层C1的赋值>> x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C2的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.83330.1667B =0.83330.1667CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C3的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C4的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C5的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.66670.3333B =0.66670.3333CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C6的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C7的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C8的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.16670.8333B =0.16670.8333CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C9的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C10的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =NaNC =0.5000% 目标层Q,Y对子准则层C11的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.25000.7500B =0.25000.7500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C12的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C13的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000% 目标层Q,Y对子准则层C14的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C15的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C16的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C17的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C18的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C19的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录9:% 最终组合权向量:x=[0.75 0 0 0 0 0;0.25 0 0 0 0 0;0 0.2625 0 0 0 0;0 0.0618 0 0 0 0;0 0.4185 0 0 0 0;0 0.1599 0 0 0 0;0 0.0973 0 0 0 0;0 0 0.5 0 0 0;0 0 0.5 0 0 0;0 0 0 0.4554 0 0;0 0 0 0.2628 0 0;0 0 0 0.1409 0 0;0 0 0 0.1409 0 0;0 0 0 0 0.4934 0;0 0 0 0 0.1958 0;0 0 0 0 0.3108 0;0 0 0 0 0 0.5396;0 0 0 0 0 0.1634;0 0 0 0 0 0.2970]x =0.7500 0 0 0 0 00.2500 0 0 0 0 00 0.2625 0 0 0 00 0.0618 0 0 0 00 0.4185 0 0 0 00 0.1599 0 0 0 00 0.0973 0 0 0 00 0 0.5000 0 0 00 0 0.5000 0 0 00 0 0 0.4554 0 00 0 0 0.2628 0 00 0 0 0.1409 0 00 0 0 0.1409 0 00 0 0 0 0.4934 00 0 0 0 0.1958 00 0 0 0 0.3108 00 0 0 0 0 0.53960 0 0 0 0 0.16340 0 0 0 0 0.2970y=[0.0492;0.2057;0.2057;0.3422;0.0753;0.1219]y =0.04920.20570.20570.34220.07530.1219z=x*y运算结果:z =0.03690.01230.05400.01270.08610.03290.02000.10290.10290.15580.08990.04820.04820.03720.01470.02340.06580.01990.0362a=[0.3333 0.8333 0.75 0.2 0.3333 0.75 0.2 0.1667 0.3333 0.5 0.25 0.8 0.5 0.75 0.2 0.75 0.3333 0.3333 0.5;0.6667 0.1667 0.25 0.8 0.6667 0.250.8 0.8333 0.6667 0.5 0.75 0.2 0.5 0.25 0.8 0.25 0.6667 0.6667 0.5]a =Columns 1 through 70.3333 0.8333 0.7500 0.2000 0.3333 0.7500 0.20000.6667 0.1667 0.2500 0.8000 0.6667 0.2500 0.8000Columns 8 through 140.1667 0.3333 0.5000 0.2500 0.8000 0.5000 0.75000.8333 0.6667 0.5000 0.7500 0.2000 0.5000 0.2500Columns 15 through 190.2000 0.7500 0.3333 0.3333 0.50000.8000 0.2500 0.6667 0.6667 0.5000c=a*z运算结果:c =0.43250.5675。