回归分析曲线拟合讲解
- 格式:ppt
- 大小:1.41 MB
- 文档页数:73

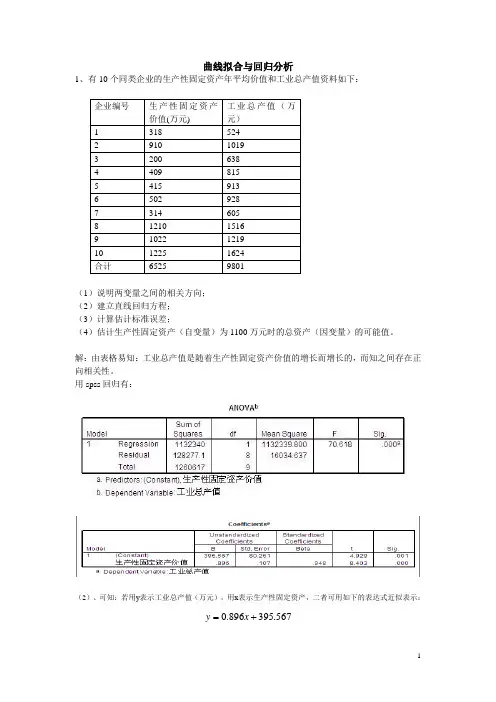
曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:=x.0+y.567395896(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。





回归拟合曲线回归拟合曲线是一种数据分析方法,用于确定数据之间的关系模式。
它可以帮助我们预测未来的趋势和变化。
本文将介绍回归拟合曲线的基本概念、常见的回归方法以及如何使用这些方法进行曲线拟合。
回归拟合曲线是通过找到最佳拟合线来描述两个或多个变量之间的关系。
拟合曲线可以是线性的,也可以是非线性的。
线性回归使用一条直线来拟合数据,而非线性回归使用其他类型的函数来拟合数据。
回归分析通常用于预测一个变量的值,基于已知的自变量值。
在回归拟合曲线中,有两个主要的变量:自变量和因变量。
自变量是我们用来预测因变量的变量,而因变量是我们想要预测的变量。
我们假设自变量能够解释因变量的变化。
回归分析的目标是找到自变量和因变量之间的关系,并使用这种关系来预测未来的因变量。
回归分析有很多不同的方法,包括线性回归、多项式回归、指数回归等。
线性回归是最简单的回归方法之一,它使用一条直线来拟合数据。
线性回归的基本原理是找到一条直线,使得这条直线与数据点的距离最小。
这种方法被广泛应用于各种领域,例如经济学、统计学和工程学等。
多项式回归是一种非线性回归方法,它使用多项式函数来拟合数据。
它可以适应各种曲线形态,并能更好地拟合非线性数据。
多项式回归的原理是在数据中添加多项式项,使得拟合曲线能够更好地适应数据点。
通过选择合适的多项式次数,我们可以调整曲线的形状和适应性。
指数回归是一种应用较广泛的非线性回归方法,它使用指数函数来拟合数据。
指数回归在研究生长速度、衰变速度等方面非常有用。
指数回归的原理是将因变量和自变量取对数,使拟合曲线变为线性形式。
然后使用线性回归分析来获得最佳拟合直线。
在进行回归拟合曲线之前,我们需要明确两个事项:回归分析的目标和回归模型的选择。
回归分析的目标是什么,决定了我们要解决什么问题。
回归模型的选择取决于我们的数据类型和问题需求。
回归分析在实际应用中非常有价值。
例如,在销售预测中,我们可以使用历史销售数据来预测未来销售额。
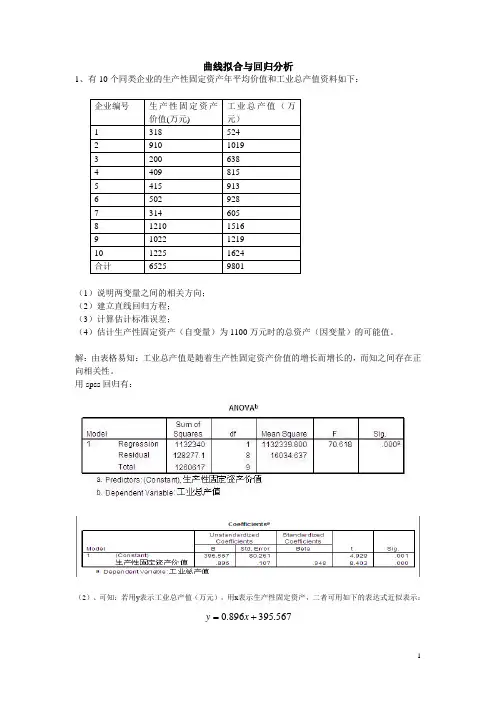
曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:=x.0+y.567395896(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。

曲线拟合的一般步骤曲线拟合是数学中的一个重要概念,可以用于回归分析、模拟计算、数据预测等领域。
本文将简单介绍曲线拟合的一般步骤,帮助读者了解如何应用曲线拟合进行数据分析。
一、确定曲线类型在进行曲线拟合之前,首先需要确定所拟合的曲线类型。
曲线类型的选择取决于数据的特性和预测的目标。
例如,如果数据呈现出周期性变化的趋势,可以选择对数周期函数或三角函数进行拟合;如果数据呈现出指数增长的趋势,可以选择指数函数进行拟合。
选择合适的曲线类型有助于提高拟合的准确度和预测的精度。
二、收集数据收集数据是进行曲线拟合的前提。
数据的收集需要考虑采样的频率、样本量的大小等因素。
通常情况下,数据的样本量越大、采样的频率越高,得到的拟合曲线越精确。
在进行数据收集时,还需要考虑数据的可信度和数据的质量。
三、对数据进行处理在收集完数据之后,需要对数据进行处理。
数据处理的主要目的是为了减少数据存在的噪声,并消除异常数据对拟合的影响。
数据处理方法可以采用平滑处理、滤波处理、插值法等方法。
同时,还需要进行数据标准化,将不同尺度的数据进行标准化处理,以便进行合理的拟合。
四、选择拟合算法选择合适的拟合算法对于拟合的准确度和模型的复杂度有重要影响。
拟合算法通常分为参数拟合和非参数拟合两种。
其中,参数拟合根据已有数据,估计模型中的参数,并针对参数进行优化;非参数拟合则不需要对模型参数进行预先确定。
常用的参数拟合算法包括最小二乘法、梯度下降法、牛顿迭代法等;非参数拟合算法包括局部加权线性回归、核函数回归等。
五、拟合模型评估进行拟合之后,需要对拟合模型进行评估。
评估的目的是为了验证拟合模型的有效性、准确性和稳定性。
评估方法可以采用拟合优度、均方误差、残差分布等指标。
根据评估结果,进行参数调整和算法选择,逐步提高拟合的精度和模型的可行性。
总结曲线拟合是一项基础而重要的数据处理技术。
选择合适的曲线类型、收集准确的数据、对数据进行处理、选择合适的拟合算法、评估拟合模型,这是曲线拟合的一般步骤。

第十章:多元线性回归与曲线拟合――Regression菜单详解(上)(医学统计之星:张文彤)上次更新日期:10.1 Linear过程10.1.1 简单操作入门10.1.1.1 界面详解10.1.1.2 输出结果解释10.1.2 复杂实例操作10.1.2.1 分析实例10.1.2.2 结果解释10.2 Curve Estimation过程10.2.1 界面详解10.2.2 实例操作10.3 Binary Logistic过程10.3.1 界面详解与实例10.3.2 结果解释10.3.3 模型的进一步优化与简单诊断10.3.3.1 模型的进一步优化10.3.3.2 模型的简单诊断回归分析是处理两个及两个以上变量间线性依存关系的统计方法。
在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。
回归分析就是用于说明这种依存变化的数学关系。
§10.1Linear过程10.1.1 简单操作入门调用此过程可完成二元或多元的线性回归分析。
在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。
例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响?显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。
但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。
回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。
这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。
10.1.1.1 界面详解在菜单中选择Regression==>liner,系统弹出线性回归对话框如下:除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。

曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:企业编号生产性固定资产价值(万元) 工业总产值(万元)1 318 5242 910 10193 200 6384 409 8155 415 9136 502 9287 314 6058 1210 15169 1022 121910 1225 1624合计6525 9801(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:567.395896.0+=xy(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。
7.3 曲线估计曲线估计即曲线拟合,恰当的曲线拟合方法可以准确而快速地反映出实际情况。
在曲线估计中,一般首先绘制自变量和因变量间的散点图,然后通过数据在散点图中的分布特点选择所要进行回归分析的类型。
确定函数关系后再进一步确定函数关系中的未知参数,并进行显著性检验。
曲线估计可以拟合许多常用的曲线关系,当变量之间存在可以使用这些曲线描述的关系时,我们便可以使用曲线回归分析进行拟合。
(一)曲线回归分析的基本原理曲线回归分析的基本任务是通过两个相关变量x 与y 的实际观测数据建立曲线回归方程,以揭示x 与y 间的曲线联系的形式。
曲线回归分析最困难和首要的工作是确定因变量y 与自变量x 之间曲线关系的类型。
通常通过两个途径来确定:(1)利用有关专业知识,根据已知的理论规律和实践经验。
例如,幂函数的形式能较好地表现生产函数;多项式方程能够较好地反映总成本与总产量之间的关系等;(2)若没有已知的理论规律和经验可利用,可在直角坐标系作散点图,观察实测点的分布趋势与哪一类已知函数曲线最接近,然后再选用该函数关系式来拟合数据。
对于可直线化的曲线函数类型,曲线回归分析的基本过程是:先将x 和(或)y 进行变量转换,然后对新变量进行直线回归分析——建立直线回归方程并进行显著性检验,最后将新变量还原为原变量,由新变量的直线回归方程得出原变量的曲线回归方程。
还有一情况是找不到已知的函数曲线较接近数据的分布趋势,这时可利用多项式回归,通过逐渐增加多项式的高次项来拟合,直到满意为止。
在实际问题中,用户往往不能确定究竟该选择何种函数模型更接近样本数据,这时可以采用曲线估计的方法,其步骤如下:1.根据实际问题本身特点,同时选择几种模型;2.SPSS 自动完成模型的参数估计,并显示R2、F 检验值、相伴概率值等统计量;3.选择具有R2统计量值最大的模型作为此问题的回归模型,并作一些预测。
(二)曲线回归模型SPSS 中的本质线性模型有: 模型回归方程变换后的线性方程一元曲线(linear ) 01y x ββ=+二次曲线(Quadratic ) 2012y x x βββ=++ ()201211y x x x x βββ=++=复合曲线(Compound ) 01x y ββ= ()()()01ln ln ln y x ββ=+增长曲线(Growth ) 01xy eββ+=()01ln y x ββ=+对数曲线(Logarithmic ) ()01ln y x ββ=+ ()()01ln y x xx ββ=+=三次曲线(Cubic )230123y x x x ββββ=+++()2301231212,x x x xy x x x ββββ=++==+S 曲线(S )10xy eββ+=()01111ln y x x x ββ==⎛⎫+ ⎪⎝⎭指数曲线(Exponential ) 01x y e ββ= ()()01ln ln y x ββ=+逆函数(Inverse )10y xββ=+01111y x x x ββ=+=⎛⎫ ⎪⎝⎭幂函数(Power ) ()10x y ββ=()()()0111ln ln ln y x x x ββ==+逻辑函数(Logistic )0111xy u ββ=+ ()()0111ln ln ln x y u ββ⎛⎫-=+ ⎪⎝⎭SPSS 曲线估计中,首先,在不能明确究竟哪种模型更接近样本数据时,可在以上多种可选择的模型中,选择几种模型;然后由SPSS 自动完成模型的参数估计,并输出回归方程的显著性检验F 值和P 值(Sig ),判定系数等统计量。