第五节正态总体参数的区间估计汇总
- 格式:ppt
- 大小:2.34 MB
- 文档页数:14




正态总体参数的区间估计实验结论正态总体参数的区间估计是统计学中一种常用的方法,可以帮助我们估计未知正态总体参数的取值范围。
通过构建置信区间,我们可以在一定的置信水平下对总体参数的取值范围进行估计。
以下是一个关于正态总体参数的区间估计实验结论。
在本实验中,我们以某个地区的成年人男性身高为研究对象,采集了一组样本数据。
通过对样本数据的分析和计算,得出了平均身高和标准差的估计值,并以此构建了置信区间。
首先,我们计算出了样本数据的均值为175cm,并且样本的标准差为5cm。
接下来,我们选择了一个置信水平为95%的置信区间进行计算。
根据正态分布的性质,我们可以使用标准正态分布表来确定置信区间的边界。
通过查表,我们找到了置信水平为95%对应的临界值,记为z。
在本实验中,z的取值为1.96。
然后,我们可以根据样本的均值、标准差和样本容量来计算置信区间的上限和下限。
置信区间的上限计算公式为:上限 = 均值 + z * (标准差/ √样本容量);置信区间的下限计算公式为:下限 = 均值 - z * (标准差/ √样本容量)。
根据实验数据的计算,最终得出了置信区间为(172.04cm,177.96cm)。
这意味着在95%的置信水平下,我们可以合理地推断该地区成年男性的平均身高位于该区间内。
这个实验结论具有以下几个指导意义。
首先,通过正态总体参数的区间估计,我们可以更准确地估计未知总体参数的取值范围,有助于我们了解总体的特征。
其次,通过选择合适的置信水平,我们可以控制估计结果的可靠性和精确度。
在本实验中,我们选择了95%的置信水平,意味着我们有95%的把握让估计结果覆盖真实总体参数。
最后,置信区间的上下限提供了关于总体参数范围的重要信息,可以用来支持决策和制定策略。
总之,正态总体参数的区间估计是一种重要的统计方法,可以为我们提供对未知总体参数取值范围的估计。
通过该方法,我们可以在一定的置信水平下对总体参数进行准确的估计,从而为实际问题的分析和决策提供科学依据。

总体参数的区间估计公式在进行区间估计时,我们首先需要收集到一个样本,并根据样本对总体参数进行估计。
然后根据样本的统计量,结合分布的性质和抽样方法,建立置信区间。
设总体参数为θ,我们希望得到它的置信水平为1-α的置信区间。
置信水平表示我们对总体参数的估计的可信程度,一般常用的置信水平有90%、95%和99%等。
参数估计的方法有很多,具体的方法选择取决于总体参数的性质、样本的大小以及其他假设条件。
常见的参数估计方法有:1.总体均值的区间估计:假设总体呈正态分布,样本大小为n,则总体均值的区间估计公式为:[样本均值-Z值(α/2)*总体标准差/√(n),样本均值+Z值(α/2)*总体标准差/√(n)]其中Z值(α/2)为标准正态分布的分位数,可以从标准正态分布表中查得。
2.总体比例的区间估计:假设总体为二项分布,样本大小为n,成功的次数为x,则总体比例的区间估计公式为:[样本比例-Z值(α/2)*√(样本比例*(1-样本比例)/n),样本比例+Z值(α/2)*√(样本比例*(1-样本比例)/n)]其中Z值(α/2)为标准正态分布的分位数,可以从标准正态分布表中查得。
3.总体方差的区间估计:假设总体呈正态分布,样本大小为n,则总体方差的区间估计公式为:[(n-1)*样本方差/卡方分布(α/2),(n-1)*样本方差/卡方分布(1-α/2])]其中卡方分布是用于描述自由度为n-1的卡方随机变量的概率分布,可以从卡方分布表中查得。
以上是常见的总体参数区间估计公式,这些公式是根据统计学理论推导而来的,适用于不同情况下的参数估计。
在实际应用中,我们根据具体问题和假设条件选择适当的参数估计方法,计算置信水平的区间估计,从而对总体参数进行估计和推断。

正态总体参数的区间估计实验结论在统计学中,正态分布是一种非常重要的分布,许多自然现象和实验数据都可以用正态分布来描述。
而在实际应用中,我们常常需要估计正态总体的参数,比如均值和标准差。
在这篇文章中,我将介绍如何利用区间估计的方法来估计正态总体的参数,并给出一个实验结论。
让我们来回顾一下区间估计的基本原理。
区间估计是通过样本数据来估计总体参数的一种方法,其核心思想是利用样本数据给出一个参数的估计区间,该区间包含真实参数的概率较高。
在正态总体参数的区间估计中,我们通常使用样本均值和样本标准差来进行估计。
接下来,我将介绍一个实际的例子来说明正态总体参数的区间估计方法。
假设我们有一批产品的重量数据,我们想要估计这批产品的平均重量。
我们随机抽取了一部分产品进行称重,得到了样本均值和样本标准差。
根据中心极限定理,我们知道样本均值的分布是正态分布的,可以利用这一性质来构建参数的置信区间。
假设我们得到的样本均值为100,样本标准差为5,样本量为30。
我们可以利用正态分布的性质来构建样本均值的置信区间,假设置信水平为95%,那么我们可以计算出置信区间为(98, 102)。
这意味着在95%的置信水平下,真实的总体平均重量落在98到102之间。
通过这个简单的例子,我们可以看到区间估计的重要性和实际应用。
在实际问题中,我们往往无法得知总体参数的真实值,只能通过样本数据来进行估计。
区间估计可以帮助我们对参数的估计进行更准确的评估,同时也可以给出参数估计的不确定性范围。
总的来说,正态总体参数的区间估计是统计学中一种常用的方法,通过构建置信区间来估计总体参数的真实值。
在实际应用中,我们可以根据样本数据来进行参数的估计,同时也可以评估参数估计的置信水平。
通过区间估计的方法,我们可以更准确地了解总体参数的情况,为决策提供更可靠的依据。
希望本文能帮助读者更好地理解正态总体参数的区间估计方法,并在实际问题中应用到实践中。


总体参数的区间估计公式(原创版)目录1.引言2.总体参数的区间估计公式概述3.区间估计的种类4.区间估计的步骤5.区间估计的性质6.应用实例7.结论正文一、引言在统计学中,总体参数的区间估计是推断统计的一个重要方法。
区间估计是指根据样本数据来估计总体的某个未知参数的范围,从而得到该参数真值的可信度区间。
总体参数的区间估计公式是进行区间估计的具体工具,它能够帮助我们更好地理解总体参数的真实值可能落在哪个范围内。
二、总体参数的区间估计公式概述总体参数的区间估计公式,通常包括两个边界值,一个上界和一个下界。
这两个边界值构成了一个区间,这个区间通常表示为:参数的真实值有(1-α)的概率落在 [L,U] 的范围内,其中α是显著性水平,L 和 U 分别是区间的下界和上界。
三、区间估计的种类区间估计分为单侧区间估计和双侧区间估计。
单侧区间估计只给出参数的一个方向的边界,如上界或下界,而双侧区间估计则同时给出参数的上界和下界。
四、区间估计的步骤进行区间估计的步骤通常包括:1.确定要估计的总体参数。
2.确定显著性水平α。
3.选择适当的统计方法,根据样本数据计算出区间估计的边界值。
4.根据边界值构建区间,并给出估计结果。
五、区间估计的性质区间估计具有以下性质:1.区间估计的结果是一个区间,该区间包含了参数真实值的可能性。
2.区间估计的宽度随着样本量的增加而减小,随着显著性水平的减小而减小。
3.区间估计的结果是基于样本数据的,因此具有一定的随机性。
六、应用实例假设我们想要估计一个正态分布总体的均值,我们已经收集了 n 个样本数据,我们可以使用正态分布的总体均值的区间估计公式来进行估计。
假设我们设定显著性水平为 0.05,那么我们可以根据 t 分布表,选取 t 值为 2,然后根据样本均值和标准差,计算出区间估计的下界和上界,从而得到均值的可信度区间。
七、结论总体参数的区间估计公式是进行区间估计的具体工具,它能够帮助我们更好地理解总体参数的真实值可能落在哪个范围内。


总体参数的区间估计公式摘要:1.总体参数的区间估计概述2.区间估计公式的推导3.区间估计在统计学中的应用正文:一、总体参数的区间估计概述总体参数的区间估计是统计学中一种重要的参数估计方法。
在实际问题中,我们通常需要对总体的某个未知参数进行估计,例如均值、方差等。
由于样本数据的随机性,我们需要通过一定的方法来估计总体参数的真实值,区间估计就是其中一种常用的方法。
区间估计的核心思想是利用样本数据计算出一个区间,该区间内包含总体参数真实值的概率在一定范围内。
这个概率范围通常用置信水平来表示,置信水平越高,所估计的区间范围就越宽,包含总体参数真实值的可能性就越大。
二、区间估计公式的推导设总体X 的概率密度函数为f(x),样本容量为n,样本均值为x,样本标准差为s,我们要估计总体均值μ。
根据中心极限定理,当n 充分大时,样本均值的分布近似于正态分布,即:x ~ N(μ, σ/n)其中,σ为总体方差。
为了估计总体均值μ,我们可以构造一个置信区间。
设α为置信水平,对应的Z 值为Zα,那么:μ的置信区间为:x ± Zα * s / √n其中,s / √n 为样本标准差除以√n,它实际上是总体标准差σ的估计。
三、区间估计在统计学中的应用区间估计在统计学中有广泛的应用,主要包括以下几个方面:1.对总体参数的单个估计:通过构造置信区间,我们可以估计总体参数的单个值,如均值、方差等。
2.对总体参数的统计推断:通过比较不同置信水平下的置信区间,我们可以对总体参数进行统计推断,如判断总体参数是否等于某个值等。
3.对样本容量的估计:在实际问题中,我们通常需要根据样本数据来估计总体参数,而样本容量的大小直接影响到估计的准确性。
通过构造置信区间,我们可以估计合适的样本容量。
总体参数的区间估计公式总体参数的区间估计是统计学中一种重要的方法,它可以用来对总体的未知参数进行估计并给出其估计的不确定性范围。
本文将介绍总体参数的区间估计公式,并解释其含义及应用。
首先,我们需要了解什么是总体参数。
在统计学中,总体是要研究的对象的全体,而总体参数则是总体的某个特征的度量。
例如,我们想要研究一座城市的平均年龄,那么平均年龄就是总体参数。
那么如何利用样本数据来估计总体参数呢?这就需要用到区间估计公式。
区间估计公式是一种基于样本数据的统计方法,它可以给出一个区间,该区间有一定的概率包含真实的总体参数值。
一般来说,我们希望该区间的概率值足够高,通常取95%或99%。
这就是我们常说的置信水平。
下面介绍总体均值的区间估计公式。
假设我们有一个样本,样本的大小为n,样本的均值为x̄,总体的标准差为σ。
当总体的分布近似服从正态分布时,总体均值的区间估计公式为:x̄± Z * (σ / √n)其中,x̄表示样本均值,Z是正态分布的一个分位数,可以从标准正态分布表中查找对应的值。
σ是总体的标准差,√n表示样本大小的平方根。
这个公式的意义是,以95%的置信水平,样本均值x̄加减一个与样本大小、总体标准差和置信水平相关的倍数,得到的区间就是总体均值的估计区间。
换句话说,这个区间内的值有95%的概率包含总体均值。
除了总体均值的区间估计,我们还可以估计其他总体参数,比如总体比例、总体方差等。
不同的总体参数有不同的区间估计公式,但原理类似。
区间估计的应用非常广泛。
例如,市场调研公司想要估计某个产品在全国范围内的市场份额,可以采集一部分样本进行调查,通过区间估计公式估计产品市场份额的范围。
又如,政府部门想要估计某个城市的平均收入水平,可以抽取一部分居民进行调查,应用区间估计公式计算平均收入的估计区间。
总的来说,总体参数的区间估计公式可以帮助我们通过样本数据对总体参数进行估计,并给出估计的不确定性范围。
正态分布N (μ,σ)参数区间估计允许μ为任意的实数,σ为任意的正实数。
基于Wolfram Mathematica ,给出了正态分布N (μ,σ)抽样定理,从而得到参数μ,σ2,σ的区间估计。
在σ已知和未知情形下,通过均值分布、中位值分布、卡方分布三种方法估计总体均值μ,区间长度均值分布最短,卡方分布次之,中位值分布最长,但当样本量n 较大时,区间长度趋于接近。
在μ已知和未知情形下,通过卡方分布可以估计总体方差的置信区间,通过卡分布、卡方分布可以估计总体标准差的置信区间。
最后给出不同情形下不同方法的MMA 程序及运行结果。
◼抽样分布定理引理1:X Ν(μ,σ)⇔X -μσΝ 0,1 .转换分布TransformedDistributionX -μσ,X 正态分布NormalDistribution [μ,σ]NormalDistribution [0,1]转换分布TransformedDistribution [μ+X σ,X 正态分布NormalDistribution [],假设Assumptions →σ>0]NormalDistribution [μ,σ]引理2:X χ(ν)⇔X 2 χ2(ν).转换分布TransformedDistribution X 2,X 卡分布ChiDistribution [ν]ChiSquareDistribution [ν]转换分布TransformedDistribution X ,X 卡方分布ChiSquareDistribution [ν]ChiDistribution [ν]引理3:X Ν 0,1 ,Y χ2(n )⇒Xt (n ).=转换分布TransformedDistributionX,{X 正态分布NormalDistribution [],Y 卡方分布ChiSquareDistribution [n ]} ;概率密度函数PDF [ ,x ]==⋯PDF [学生t 分布StudentTDistribution [n ],x ]//幂展开PowerExpand //完全简化FullSimplify [#,n >0&&x ≠0]&True定理1:X i Ν(μ,σ)⇒X -Νμ,σn⇔X --μσnΝ 0,1 .CharacteristicFunction NormalDistribution [μ,σ],t nn;特征函数CharacteristicFunction 正态分布NormalDistribution μ,σn,t ;%⩵%%//完全简化FullSimplify [#,n >0&&n ∈整数域Integers ]&True定理2:X i Ν(μ,σ)⇒ i =1nX i -μσ2=∑i =1n (X i -μ)2σ2χ2(n )⇔σχ(n ).转换分布TransformedDistributionX [i ]-μσ,X [i ] 正态分布NormalDistribution [μ,σ]NormalDistribution [0,1]n =7;=转换分布TransformedDistribution i =1nY [i ]2,数组Array [Y,n ] 联合分布ProductDistribution [{正态分布NormalDistribution [],n }]ChiSquareDistribution [7]定理3:X i Ν(μ,σ)⇒(n -1)S 2σ2χ2 n -1⇔σχ n -1 .令Y i =X i -μσ,则(n -1)S 2σ2=i =1n2=i =1n-= i =1nY i -Y 2= i =1nY i 2-2Y Y i +Y 2= i =1nY i 2-2Y i =1nY i +n Y 2= i =1nY i 2-n Y 2χ2n -1 ⇒σχ n -1 .2 正态分布\\正态分布统计分析\\正态分布参数区间估计.nbn =n0=35;=转换分布TransformedDistribution i =1nY [i ]2-1ni =1nY [i ]2,数组Array [Y,n ] 联合分布ProductDistribution [{正态分布NormalDistribution [],n }] ;Block {n =n0},显示Show 直方图Histogram 伪随机变数RandomVariate ,2×106 ,500,"概率密度函数PDF" ,绘图Plot [⋯PDF [卡方分布ChiSquareDistribution [n -1],x ],{x,5,65},绘图样式PlotStyle →粗Thick ]定理4:X i Ν(μ,σ)⇒X --μSnt n -1 .根据定理1,得X iΝ(μ,σ)⇒X --μσnΝ 0,1 ,根据定理3,得(n -1)S 2σ2χ2 n -1 ,根据引理3,X --μσn=X --μSnt n -1 .定理5:F Xn +12=正则化的不完全贝塔函数BetaRegularized12补余误差函数Erfc-x +μ2σ ,1+n2,1+n 2,n =2k +1.次序分布OrderDistribution {正态分布NormalDistribution [μ,σ],n },n +12;累积分布函数CDF [%,x ]//完全简化FullSimplifyBetaRegularized 12Erfc ,1+n 2,1+n 2推论:μ=x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized q,1+n 2,1+n 2.In[2]:=解方程Solve 正则化的不完全贝塔函数BetaRegularized12补余误差函数Erfc-x +μ2σ ,1+n 2,1+n 2⩵q,μOut[2]=μ→x +2σInverseErfc 2InverseBetaRegularized q,1+n 2,1+n 2定理6:-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σχ2 2n .正态分布\\正态分布统计分析\\正态分布参数区间估计.nb3In[5]:=转换分布TransformedDistribution -2对数Log12补余误差函数Erfc-X +μ2σ,X 正态分布NormalDistribution [μ,σ] ;概率密度函数PDF [%,x ]⩵⋯PDF [卡方分布ChiSquareDistribution [2],x ]//完全简化FullSimplify [#,x >0]&Out[6]=True**参数区间估计**In[7]:=需要Needs ["HypothesisTesting`"]μ0=20;σ0=3;X =伪随机变数RandomVariate [正态分布NormalDistribution [μ0,σ0],10001];n =长度Length [X ];S =标准偏差StandardDeviation [X ];α=0.01;"参数的极大似然估计:"清除Clear [μ,σ]{μ1,σ1}={μ,σ}/.求分布参数FindDistributionParameters [X,正态分布NormalDistribution [μ,σ]]"一、总体均值μ的区间估计""(一)均值分布U =X --μσnN(0,1)——σ已知"σ=σ0;Sw =σn ;m =平均值Mean [X ];"1.计算法"Q =分位数Quantile 正态分布NormalDistribution [0,1],1-α 2 ;{m -Sw Q,m +Sw Q }"2.MeanCI"MeanCI X,KnownVariance →σ2,置信级别ConfidenceLevel →1-α"3.NormalCI"NormalCI [m,Sw ,置信级别ConfidenceLevel →1-α]"区间长度:"L =2Sw Q"相对区间长度:"r =L /m "(二)均值分布T =X -μSnt (n -1)——σ未知""1.计算法"Sw =S n ;m =平均值Mean [X ];Q =分位数Quantile 学生t 分布StudentTDistribution [n -1],1-α 2 ;{m -Sw Q,m +Sw Q }4 正态分布\\正态分布统计分析\\正态分布参数区间估计.nb"2.MeanCI"MeanCI [X,KnownVariance →无None,置信级别ConfidenceLevel →1-α]"3.StudentTCI"StudentTCI [m ,Sw ,n -2,置信级别ConfidenceLevel →1-α]"区间长度:"L =2Sw Q"相对区间长度:"r =L /m"(三)均值近似分布U =X --μσn~N[0,1]——σ未知""1.计算法"σ=σ1;Sw =σn ;m =平均值Mean [X ];Q =分位数Quantile 正态分布NormalDistribution [0,1],1-α 2 ;{m -Sw Q,m +Sw Q }"2.MeanCI"MeanCI X,KnownVariance →σ12,置信级别ConfidenceLevel →1-α"3.NormalCI"NormalCI [m,Sw ,置信级别ConfidenceLevel →1-α]"区间长度:"L =2Sw Q"相对区间长度:"r =L /m"(四)中位值分布F Xn +12=正则化的不完全贝⋯BetaRegularized [12补余误差函数Erfc [-x +μ2σ],1+n 2,1+n2],n =2k +1——σ已知""1.等尾区间:"σ=σ0;x =中位数Median [X ];μL =x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized 1-α 2,1+n 2,1+n 2;μU =x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized α 2,1+n 2,1+n 2;{μL,μU }"等尾区间长度:"L =μU -μL"相对区间长度:"r =2L μU +μL "(五)中位值分布F Xn +12=正则化的不完全贝⋯BetaRegularized [12补余误差函数Erfc [-x +μ2σ ],1+n 2,1+n2],n =2k +1——σ未知""1.等尾区间:"σ=σ1;x =中位数Median [X ];正态分布\\正态分布统计分析\\正态分布参数区间估计.nb5中位数μL =x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized 1-α 2,1+n 2,1+n 2;μU =x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized α 2,1+n 2,1+n 2;{μL,μU }"等尾区间长度:"L =μU -μL"相对区间长度:"r =2L μU +μL"(六)卡方分布-2 i =1n对数Log [12补余误差函数Erfc [-X i +μ2σ]] χ2(2n )——σ已知"清除Clear [μ]σ=σ0;x =-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σ;F =卡方分布ChiSquareDistribution [2n ];μL =μ/.求根FindRoot 累积分布函数CDF [F,x ]==α2,{μ,μ1} ;μU =μ/.求根FindRoot 累积分布函数CDF [F,x ]⩵1-α2,{μ,μ1} ;{μL,μU }"等尾区间长度:"L =μU -μL"相对区间长度:"r =2L μU +μL"(七)卡方分布-2 i =1n对数Log [12补余误差函数Erfc [-X i +μ2σ ]]~χ2(2n )——σ未知"清除Clear [μ]σ=σ0;x =-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σ;F =卡方分布ChiSquareDistribution [2n ];μL =μ/.求根FindRoot 累积分布函数CDF [F,x ]==α2,{μ,μ1} ;μU =μ/.求根FindRoot 累积分布函数CDF [F,x ]⩵1-α2,{μ,μ1} ;{μL,μU }"等尾区间长度:"L =μU -μL"相对区间长度:"6 正态分布\\正态分布统计分析\\正态分布参数区间估计.nbr =2L μU +μL"二、总体方差σ2的区间估计""(一)卡方分布χ2=∑i =1n (X i -μ)2σ2χ2(n )——μ已知"μ=μ0;T =n 平均值Mean (X -μ)2 ;F =卡方分布ChiSquareDistribution [n ];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;VL =T QL;VU =T QU;{VL,VU }"等尾区间长度:"L =VU -VL"相对区间长度:"r =2L VL +VU "(二)卡方分布χ2=(n -1)S 2σ2χ2(n -1)——μ未知"T = n -1 S 2;F =卡方分布ChiSquareDistribution [n -1];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;VL =T QL;VU =T QU;{VL,VU }"等尾区间长度:"L =VU -VL"相对区间长度:"r =2L VL +VU "(三)卡方分布χ2=∑i =1n (X i -μ )2σ2~χ2(n )——μ未知"μ=μ1;T =n 平均值Mean (X -μ)2 ;F =卡方分布ChiSquareDistribution [n ];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;VL =T QL;VU =T QU;{VL,VU }"等尾区间长度:"L =VU -VL"相对区间长度:"r =2L VL +VU"三、总体标准差σ的区间估计""(一)卡分布χ(n )——μ已知"μ=μ0;T =n Mean (X -μ)2 ;F =卡分布ChiDistribution [n ];"1.等尾区间:"正态分布\\正态分布统计分析\\正态分布参数区间估计.nb7QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;σL =T QL;σU =T QU;{σL,σU }"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σU "(二)卡分布χ(n -1)——μ未知"T =n -1S;F =卡分布ChiDistribution [n -1];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;σL =T QL;σU =T QU;{σL,σU }"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σU "(三)卡分布χχ(n )——μ未知"μ=μ1;T =n Mean (X -μ)2 ;F =卡分布ChiDistribution [n ];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;σL =T QL;σU =T QU;{σL,σU }"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σU "(四)卡方分布-2 i =1n对数Log [12补余误差函数Erfc [-X i +μ2σ]] χ2(2n )——μ已知"清除Clear [σ]μ=μ0;x =-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σ;F =卡方分布ChiSquareDistribution [2n ];σL =σ/.求根FindRoot 累积分布函数CDF [F,x ]⩵1-α2,{σ,σ1} ;σU =σ/.求根FindRoot 累积分布函数CDF [F,x ]⩵α2,{σ,σ1} ;{σL,σU }8 正态分布\\正态分布统计分析\\正态分布参数区间估计.nb"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σU"(五)卡方分布-2 i =1n对数Log [12补余误差函数Erfc [-X i +μ2σ]] χ2(2n )——μ未知"清除Clear [σ]μ=μ1;x =-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σ;F =卡方分布ChiSquareDistribution [2n ];σL =σ/.求根FindRoot 累积分布函数CDF [F,x ]⩵1-α2,{σ,σ1} ;σU =σ/.求根FindRoot 累积分布函数CDF [F,x ]⩵α2,{σ,σ1} ;{σL,σU }"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σUOut[11]=参数的极大似然估计:Out[13]={19.9803,3.00134}Out[14]=一、总体均值μ的区间估计Out[15]=(一)均值分布U =X --μσnN(0,1)——σ已知Out[17]=1.计算法Out[19]={19.9031,20.0576}Out[20]=2.MeanCIOut[21]={19.9031,20.0576}Out[22]=3.NormalCIOut[23]={19.9031,20.0576}Out[24]=区间长度:Out[25]=0.154542Out[26]=相对区间长度:Out[27]=0.00773471Out[28]=(二)均值分布T =X -μSn t (n -1)——σ未知正态分布\\正态分布统计分析\\正态分布参数区间估计.nb9Out[29]= 1.计算法Out[32]={19.903,20.0577} Out[33]= 2.MeanCIOut[34]={19.903,20.0577} Out[35]= 3.StudentTCIOut[36]={19.903,20.0577} Out[37]=区间长度:Out[38]=0.154648Out[39]=相对区间长度:Out[40]=0.00774003Out[41]=(三)均值近似分布U=X--μσ n~N[0,1]——σ未知Out[42]= 1.计算法Out[45]={19.903,20.0576} Out[46]= 2.MeanCIOut[47]={19.903,20.0576} Out[48]= 3.NormalCIOut[49]={19.903,20.0576} Out[50]=区间长度:Out[51]=0.154611Out[52]=相对区间长度:Out[53]=0.00773817Out[54]=(四)中位值分布F X n+12=BetaRegularized[12Erfc,1+n2,1+n2],n=2k+1——σ已知Out[55]= 1.等尾区间:Out[59]={19.8529,20.0466} Out[60]=等尾区间长度:Out[61]=0.193686Out[62]=相对区间长度:Out[63]=0.00970872Out[64]=(五)中位值分布F X n+12=BetaRegularized[12Erfc,1+n2,1+n2],n=2k+1——σ未知Out[65]= 1.等尾区间:Out[69]={19.8529,20.0466}Out[70]=等尾区间长度:10正态分布\\正态分布统计分析\\正态分布参数区间估计.nbOut[71]=0.193773Out[72]=相对区间长度:Out[73]=0.00971306Out[74]=(六)卡方分布-2 i =1n Log [12Erfcχ2(2n )——σ已知Out[78]={19.9015,20.0722}Out[79]=等尾区间长度:Out[80]=0.170753Out[81]=相对区间长度:Out[82]=0.00854324Out[83]=(七)卡方分布-2 i =1n Log [12Erfcχ2(2n )——σ未知Out[87]={19.9015,20.0722}Out[88]=等尾区间长度:Out[89]=0.170753Out[90]=相对区间长度:Out[91]=0.00854324Out[92]=二、总体方差σ2的区间估计Out[93]=(一)卡方分布χ2=∑i =1n (X i -μ)2σ2 χ2(n )——μ已知Out[95]= 1.等尾区间:Out[98]={8.68869,9.34535}Out[99]=等尾区间长度:Out[100]=0.656658Out[101]=相对区间长度:Out[102]=0.0728243Out[103]=(二)卡方分布χ2=(n -1)S 2σ2 χ2(n -1)——μ未知Out[105]= 1.等尾区间:Out[108]={8.68917,9.3459}Out[109]=等尾区间长度:Out[110]=0.656728Out[111]=相对区间长度:Out[112]=0.0728279Out[113]=(三)卡方分布χ2=∑i =1n (X i -μ )2σ2~χ2(n )——μ未知正态分布\\正态分布统计分析\\正态分布参数区间估计.nb 11Out[115]= 1.等尾区间:Out[118]={8.68832,9.34495}Out[119]=等尾区间长度:Out[120]=0.65663Out[121]=相对区间长度:Out[122]=0.0728243Out[123]=三、总体标准差σ的区间估计Out[124]=(一)卡分布χ(n )——μ已知Out[126]= 1.等尾区间:Out[129]={2.94766,3.05702}Out[130]=等尾区间长度:Out[131]=0.109358Out[132]=相对区间长度:Out[133]=0.0364242Out[134]=(二)卡分布χ(n -1)——μ未知Out[136]= 1.等尾区间:Out[139]={2.94774,3.05711}Out[140]=等尾区间长度:Out[141]=0.109366Out[142]=相对区间长度:Out[143]=0.0364261Out[144]=(三)卡分布χχ(n )——μ未知Out[146]= 1.等尾区间:Out[149]={2.9476,3.05695}Out[150]=等尾区间长度:Out[151]=0.109355Out[152]=相对区间长度:Out[153]=0.0364242Out[154]=(四)卡方分布-2 i =1n Log [12Erfcχ2(2n )——μ已知Out[158]={2.89486,3.15965}Out[159]=等尾区间长度:12 正态分布\\正态分布统计分析\\正态分布参数区间估计.nbOut[160]=0.264793Out[161]=相对区间长度:Out[162]=0.0874698Out[163]=(五)卡方分布-2 i =1n Log [12Erfcχ2(2n )——μ未知Out[167]={2.86679,3.12718}Out[168]=等尾区间长度:Out[169]=0.260386Out[170]=相对区间长度:Out[171]=0.0868828正态分布\\正态分布统计分析\\正态分布参数区间估计.nb 13。
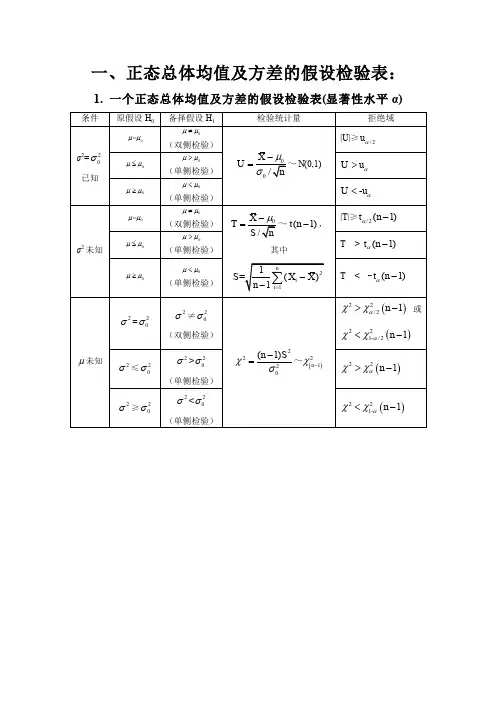
授课题目:第七章参数估计教学目的、要求(分掌握、熟悉、了解三个层次):1、理解参数的点估计、估计量与估计值的概念;2、掌握矩估计法(一阶、二阶)和最大似然估计法;3、了解估计量的无偏性,有效性(最小方差性)和一致性(相合性)的概念,并会验证估计量的无偏性;4、了解区间估计的概念,会求单正态总体的均值与方差的置信区间。
教学重点及难点:矩法估计,极大似然估计;估计量的评价准则;正态总体参数的区间估计课时安排:7课时授课方式:理论课教学基本内容:7.3 区间估计1. 区间估计的一般步骤我们在讨论抽样分布时曾提到过区间估计。
与点估计不同的是,它给出的不是参数空间的某一个点,而是一个区间(域)。
按照一般的观念,似乎我们总是希望能得到参数的一个具体值,也就是说用点估计就够了,为什么还要引入区间估计呢?这是因为在使用点估计时,我们对估计量θˆ是否能“接近”真正的参数θ的考察是通过建立种种评价标准,然后依照这些标准进行评价,这些标准一般都是由数学特征来描绘大量重复试验时的平均效果,而对于估值的可靠度与精度却没有回答。
即是说,对于类似这样的问题:“估计量θˆ在参数θ的λ邻域的概率是多大?”点估计并没有给出明确结论,但在某些应用问题中,这恰恰是人们所感兴趣的,如例7.12某工厂欲对出厂的一批电子器件的平均寿命进行估计,随机地抽取n件产品进行试验,通过对试验的数据的加工得出该批产品是否合格的结论?并要求此结论的可信程度为95%,应该如何来加工这些数据?对于“可信程度”如何定义,我们下面再说,但从常识可以知道,通常对于电子元器件的寿命指标往往是一个范围,而不必是一个很准确的数。
因此,在对这批电子元器件的平均寿命估计时,寿命的准确值并不是最重要的,重要的是所估计的寿命是否能以很高的可信程度处在合格产品的指标范围内,这里可信程度是很重要的,它涉及到使用这些电子元器件的可靠性。
因此,若采用点估计,不一定能达到应用的目的,这就需要引人区间估计。