统计学第4章抽样调查
- 格式:ppt
- 大小:5.60 MB
- 文档页数:73

第四章一.思考题1、一组数据的分布特征可以从哪几个方面进行测度?答:可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏态和峰态。
2、怎样理解平均数在统计学中的地位?答:平均数在统计学中具有重要的地位,它是进行统计分析和统计推断的基础。
从统计学思想上看,平均数是一组数据的重心所在,是数据误差相互抵消后的必然结果。
3、简述四分位数的计算方法。
答:四分位数是一组数据排序后处于25%和75%位子上的值。
四分位数是通过3个点将全部数据等分成4分,其中每部分包含25%的数据。
中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值和处在75%位置上的数值。
它是根据为分组数据计算四分位数时,首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数据就是四分位数。
4、对于比率数据的平均数为什么采用几何平均?答:几何平均数是适用于特殊数据的一种平均数,主要适用于计算平均比率。
当所掌握的变量值本身是比率的形式时,采用几何平均法计算平均比率更为合理。
5、简述众数、中位数、平均数的特点和应用场合。
答:众数是数据中出现次数次数最多的变量值。
主要应用于分类数据。
中位数是一组数据排序后处于中间位置的变量值,其适用于顺序数据。
平均数也称均值,它是一组数据相加后除以数据个数的结果,是集中去世的主要测量值,它适用于数值型数据。
6、简述异众比率、四分位差、方差、标准差的使用场合。
答:异众比率主要适合测度分类数据的离散程度,对于顺序数据以及数值型数据也可以计算异众比率。
四分位差主要用于测度顺序数据的离散程度。
方差和标准差适用于测度数值型数据的离散程度。
7、标准分数有哪些用途?答:首先是比较不同单位和不同质数据的位置。
其次是和正态分布结合起来,求得概率和标准分值之间的对应关系。
还有就是在假设检验和估计中应用。

统计学中的抽样与调查方法统计学是一门研究收集、整理、分析和解释数据的学科。
在统计学中,抽样与调查方法是非常重要的,它们帮助统计学家从大规模样本中获取关于总体的信息,以便进行具有代表性和可靠性的推断和预测。
本文将介绍统计学中常用的抽样与调查方法。
一、随机抽样随机抽样是最常用的抽样方法之一,它通过随机选择个体来构成样本,以确保样本具有代表性和可推广性。
一种常见的随机抽样方法是简单随机抽样,即从总体中以等可能性抽取个体。
比如,我们希望研究某城市居民的收入水平,可以使用简单随机抽样方法从人口普查数据中随机抽取一部分人作为样本。
二、分层抽样分层抽样是将总体按照特定特征分成若干层,然后从每层中随机抽取样本。
这种方法可以保证各层的代表性,并且可以对不同层次的个体进行比较和分析。
比如,我们需要对某公司员工的满意度进行调查,可以先将员工按照职位分成管理层、专业人员和基层员工三个层次,然后从每个层次中随机抽取一定数量的员工作为样本。
三、系统抽样系统抽样是按照一定的规则和顺序选择个体作为样本,通常是每隔一定间隔选择一个个体。
这种抽样方法简单易行,适用于总体有较大规模并且具有一定的周期性结构。
举个例子,我们想研究某超市一天的顾客购买行为,可以每隔半小时选择一个顾客进行观察和调查。
四、整群抽样整群抽样是将总体按照特定特征划分成若干个群体(或称簇),然后从每个群体中抽取所有个体作为样本。
这种方法适用于总体组织结构清晰、群体间差异较大的情况下。
例如,我们想研究某市区不同社区的环境意识水平,可以先将市区按照社区划分成若干个群体,然后从每个社区中抽取所有居民作为样本。
五、非随机抽样非随机抽样是指除了随机抽样以外的其他抽样方法,它们通常根据研究目的和可行性选择样本,而不是依靠随机性。
非随机抽样方法的优点是灵活性强,可以根据具体情况进行选择,但相对而言,结果的可靠性和推广性较差。
一些常见的非随机抽样方法包括方便抽样、判断抽样和专家抽样等。



第四章综合指标一.填空题:1.总量指标按其说明总体内容不同,可分为总体标志总量和总体单位总量。
2.总量指标按其反应的时间状况不同,可分为时期指标和时点指标。
3.总量指标按其采用计量单位不同,可分为实物指标. 价值指标和劳动量指标。
4.算术平均数的基本公式总体标志总量/总体单位数。
5.相对指标按其是否拥有计量单位可区分为无名数和名数。
6.某地区去年的财政总收入为250亿元。
从反映总体的时间上看,该指标是时期指标;从反映总体的内容上看,该指标是总体标志总量。
7.平均指标说明分配数列中各变量值分布的集中趋势,变异指标说明各变量值分布的离中趋势。
8. 标志变异指标是用以反映总体各单位标志值差异程度的指标。
9.强度相对指标数值大小,如果与现象的发展程度或密度成正比,则称之为正指标,反之则称为逆指标。
10.用标准差比较两个变量数列平均数的代表性的前提条件是这两个变量数列的平均数相等。
二.单项选择题:1.下列指标属于总量指标的是( D )。
A.人均粮食产量B.资金利税率C.产品合格率D.学生人数2.下列指标属于比例相对指标的是( B )。
A.工人出勤率B.农轻重的比例关系C.每百元产值利税额D.净产值占总产值的比重3.下列指标中属于时点指标的是( D )。
A.国内生产总值B.流通费用率C.人均利税额D.商店总数4.下列指标中属于时期指标的是(D )。
A.商场数量B.营业员人数C.商品价格D.商品销售量5.下列属于结构相对数的是(C )。
A.人口出生率B.产值利润率C.恩格尔系数D.人口性别比6.某地区2006年的人均粮食产量393.10公斤,人均棉花产量3.97公斤,人均国民生产总值为1558元,它们是( D )。
A.结构相对指标B.比较相对指标C、比例相对指标 D.强度相对指标7.某企业产品单位成本计划2007年比2006年降低10%,实际降低15%,则计划完成程度为( B )。
A.150%B.94.4%C.104.5%D.66.7%8.第五次全国人口普查结果,我国每10万人中具有大学程度的为3611人。

(一)填空题1.抽样推断是按照,从总体中抽取样本,然后以样本的观察结果来估计总体的数量特征。
2.抽样调查可以是抽样,也可以是抽样,但作为抽样推断基础的必须是抽样。
3.抽样调查的目的在于认识总体的。
4.抽样推断运用的方法对总体的数量特征进行估计。
5.在抽样推断中,不论是总体参数还是样本统计量,常用的指标有、和方差。
6.样本成数的方差是。
7.根据取样方式不同,抽样方法有和两种。
8.重复抽样有个可能的样本,而不重复抽样则有个可能的样本。
N为总体单位总数,n为样本容量。
9.抽样误差是由于抽样的而产生的误差,这种误差不可避免,但可以。
10.在其他条件不变的情况下,抽样误差与成正比,与成反比。
11.样本平均数的平均数等于。
12.在重复抽样下,抽样平均误差等于总体标准差的。
13.抽样极限误差与抽样平均误差之比称为。
14.总体参数估计的方法有和两种。
15.优良估计的三个标准是、和。
16.样本平均误差实质是样本平均数的。
(二) 单项选择题1、抽样推断是建立在()基础上的。
A、有意抽样B、随意抽样C、随机抽样D、任意抽样2、抽样推断的目的是()A、以样本指标推断总体指标B、取得样本指标C、以总体指标估计样本指标D、以样本的某一指标推断另一指标3、抽样推断运用()的方法对总体的数量特征进行估计。
A、数学分析法B、比例推断算法C、概率估计法D、回归估计法4、在抽样推断中,可以计算和控制的误差是()A、抽样实际误差B、抽样标准误差C、非随机误差D、系统性误差5、从总体的N个单位中抽取n个单位构成样本,共有()可能的样本。
A、1个B、N个C、n个D、很多个(但要视抽样方法而定)6、总体参数是()A、唯一且已知B、唯一但未知C、非唯一但可知D、非唯一且不可知7、样本统计量是()A、唯一且已知B、不唯一但可抽样计算而可知C、不唯一也不可知D、唯一但不可知8、 样本容量也称( )A 、样本个数B 、样本单位数C 、样本可能数目D 、样本指标数 9、 从总体的N 个单位中随机抽取n 个单位,用重复抽样方法共可抽取( )个样本。


第4章 练习题 一、单项选择题1.平均指标反映了( )①总体次数分布的集中趋势 ②总体分布的特征③总体单位的集中趋势 ④总体次数分布的离中趋势2.某单位的生产小组工人工资资料如下:90元、100元、110元、120元、128元、148元、200元,计算结果均值为128=X 元,标准差为( )①σ=33 ②σ=34 ③σ=34.23 ④σ=35 3.众数是总体中下列哪项的标志值( ) ①位置居中 ②数值最大 ③出现次数较多 ④出现次数最多4.某工厂新工人月工资400元,工资总额为200000元,老工人月工资800元,工资总额80000元,则平均工资为( )①600元 ②533.33元 ③466.67元 ④500元5.标志变异指标说明变量的( )①变动趋势 ②集中趋势 ③离中趋势 ④一般趋势 6.标准差指标数值越小,则反映变量值( )①越分散,平均数代表性越低 ②越集中,平均数代表性越高 ③越分散,平均数代表性越高 ④越集中,平均数代表性越低 7.在抽样推断中应用比较广泛的指标是( )①全距 ②平均差 ③标准差 ④标准差系数二、多项选择题1.根据标志值在总体中所处的特殊位置确定的平均指标有( ) ①算术平均数 ②调和平均数 ③几何平均数 ④众数 ⑤中位数2.影响加权算术平均数的因素有( )①总体标志总量 ②分配数列中各组标志值③各组标志值出现的次数 ④各组单位数占总体单位数比重 ⑤权数3.标志变异指标有( )①全距 ②平均差 ③标准差 ④标准差系数 ⑤相关系数 4.在组距数列的条件下,计算中位数的公式为( )①i f S fL M mm e ⋅-+=+∑12②i f S fU M m m e ⋅-=∑12--③i f S fL M mm e ⋅-+=∑12- ④i f S fU M mm e ⋅-=+∑12-⑤i f S fU M mm e ⋅-=∑12-+5.几何平均数的计算公式有( )①n n n X X X X ⋅⋅⋅121-Λ ②nX X X X nn ⋅⋅⋅121-Λ③122121-++++n X X X X nn -Λ ④∑f fIIX ⑤n IIX三、计算题1.某企业360名工人生产某种产品的资料如表1:试分别计算7、8月份平均每人日产量,并简要说明8月份平均每人日产量变化的原因。

六.计算题部分1、对一批成品按重复抽样方法抽选100件,其中废品4件,当概率为95.45%(t=2)时,可否认为这批产品的废品率不超过6%?答案:解:2%,41004,100====t p n 0196.0100)04.01(04.0)1(=-=-=n p p p μ039.00196.02=⨯==∆p p t μ p p p P p ∆+≤≤∆-039.004.0039.004.0+≤≤-P0.1%------7.9% ∴废品率不超过6%2、某乡有5000农户,按随机原则重复抽取100户调查,得平均每户年纯收入12000元,标准差2000元。
要求:(1)以95%的概率(t=1.96)估计全乡平均每户年纯收入的区间。
(2)以同样概率估计全乡农户年纯收入总额的区间范围。
答案: 解: 2001002000===n x σμ 39220096.1=⨯==∆x x t μ x x x X x ∆+≤≤∆- 3921200039212000+≤≤-X11608-----12392(元) 5000×11608------5000×12392(元)3、某企业生产一种新的电子元件,用简单随机重复抽样方法抽取100只作耐用时间试验,测试结果,平均寿命6000小时,标准差300小时,试在95.45%(t=2)概率保证下,估计这种新电子元件平均寿命区间。
答案:解:2,300,6000,100====t x n σ (小时)30100300===n x σμ (小时)60302=⨯==∆x x t μ x x x X x ∆+≤≤∆- 606000606000+≤≤-X 5940-----6060(小时)4、 从某年级学生中按简单随机抽样方式抽取50名学生,对邓小平理论课的考试成绩进行检查,得知其平均分数为75.6分,样本标准差10分,试以95.45%(99.73%t=3、68.27%t=1)的概率保证程度推断全年级学生考试成绩的区间范围。
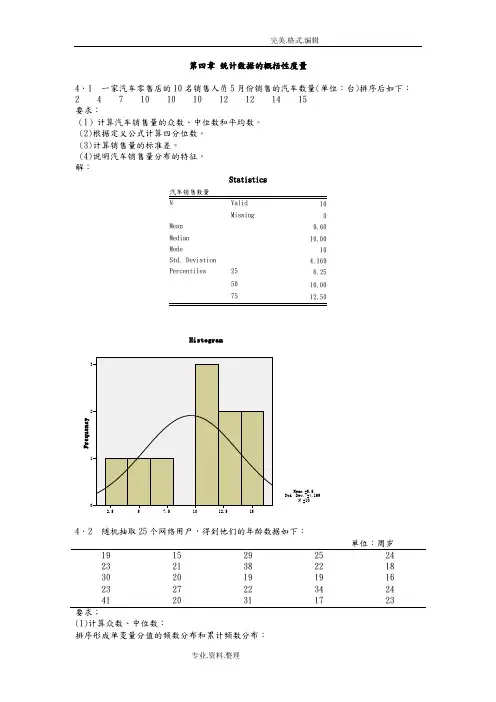
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.50单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数: ()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。

第四章抽样估计一、判断题1.抽样估计的目的是用以说明总体特征。
2.抽样分布就是样本分布。
3.既定总体在当抽样方法、抽样组织形式和样本容量确定时,样本均值的分布惟一确定。
4.样本容量就是样本个数。
5.在抽样中,样本容量是越大越好。
6.抽样的目的是判断样本估计值是否处于以总体指标为中心的某规定区域范围内。
7.当估计量有偏时,人们应该弃之不用。
8.对于一个确定的抽样分布,其方差是确定的,因而抽样标准误也是确定的。
9.抽样极限误差越大,用以包含总体参数的区间就越大,估计的把握程度也就越大,因此极限误差越大越好。
10.非抽样误差会随着样本容量的扩大而下降。
二、单项选择题1.想了解学生的眼睛视力状况,准备抽取若干学校、若干班级的学生进行测试,则()。
A.观测单位是学校B.观测单位是班级C.观测单位是学生D.观测单位可以是学校、也可班级或学生2.下列误差中属于非一致性的有()。
A.估计量偏差B.偶然性误差C.抽样标准误D.非抽样误差3.抽样估计中最常用的分布理论是()。
A.t分布理论B.二项分布理论C.正态分布理论D.超几何分布理论4.抽样标准误大小与下列哪个因素无关?()A.样本容量B.抽样方式、方法C.概率保证程度D.估计量5.下列关于抽样标准误的叙述哪个是错误的?()A.抽样标准误是抽样分布的标准差B.抽样标准误的理论值是惟一的,与所抽样本无关C.抽样标准误比抽样极限误差小D.抽样标准误只能衡量抽样中的偶然性误差的大小三、计算分析题1. 某小组5个工人的每周工资分别为520、540、560、580、600元,现从中用简单随机抽样形式(不重复抽样)随机抽取2个工人周工资构成样本。
要求:(1)计算总体平均工资的标准差;(2)列出全部可能的样本平均工资;(3)计算样本平均工资的平均数,并检验其是否等于总体平均工资;(4)计算样本平均工资的标准差;(5)用抽样平均误差的公式计算并验证是否等于(4)的结果。
2.从某大型企业中随机抽取100名职工,调查他们的工资。
统计师如何进行统计抽样与调查设计统计抽样与调查设计是统计学中非常重要的环节,它们能够帮助统计师获得准确、可靠的数据,并基于这些数据做出科学的分析和结论。
本文将介绍统计师在进行统计抽样与调查设计时应该注意的几个方面。
一、确定研究目的在进行统计抽样与调查设计之前,统计师首先需要明确研究的目的。
研究目的决定了研究的范围和要收集的数据类型。
例如,如果研究的目的是了解人们对某种产品的满意度,那么需要收集参与者的意见和评价数据。
二、选择合适的抽样方法选择合适的抽样方法是保证统计数据的准确性和可靠性的重要一步。
常用的抽样方法包括随机抽样、分层抽样和整群抽样等。
随机抽样是指每个个体都有相等的被选中的机会,可以避免抽样偏倚。
分层抽样是将总体划分为若干个层次,然后在每个层次中进行随机抽样。
整群抽样是将总体划分为若干个群体,然后仅选择其中的一部分群体进行抽样。
三、确定样本容量确定样本容量是决定研究结果的准确性和可靠性的关键因素。
样本容量过小会导致结果的可信度不足,样本容量过大则会浪费资源和时间。
样本容量的确定需要考虑到总体规模、预期误差、置信水平和统计方法等因素。
四、设计调查问卷在进行统计调查时,统计师通常会设计调查问卷来收集数据。
设计问卷时需要确保问题准确、明确,并避免引导性的问题。
同时,还需要注意问卷的结构和顺序,使被调查者能够顺利地回答问题并保持高度的关注度。
五、进行统计分析在收集到足够的数据后,统计师需要进行统计分析来获取有关总体特征和结论的信息。
常见的统计分析方法包括描述统计和推断统计。
描述统计用于总结数据的基本特征,例如平均值、标准差和频数分布等。
推断统计是基于样本数据对总体进行推断,通过计算置信区间和假设检验来进行推断。
六、解读和报告结果最后,统计师需要解读和报告统计分析的结果。
结果的解读应该结合具体的研究目的和背景来进行,避免片面解读和误导。
报告的内容应该简洁明了,同时提供足够的信息来支持结论。
图表和图像可以用于直观地展示统计结果。
抽样调查,习题答案篇一:《抽样技术》第四版习题答案第2章2.1 解:?1? 这种抽样方法是等概率的。
在每次抽取样本单元时,尚未被抽中的编号为1~64的这些单元中每一个单元被抽到的概率都是1。
100?2?这种抽样方法不是等概率的。
利用这种方法,在每次抽取样本单元时,尚未被抽中的编号为1~35以及编号为64的这36个单元中每个单元的入样概率都是抽中的编号为36~63的每个单元的入样概率都是2,而尚未被1001。
100?3?这种抽样方法是等概率的。
在每次抽取样本单元时,尚未被抽中的编号为20 000~21 000中的每个单元的入样概率都是1,所以这种抽样是等概率的。
10002.3 解:首先估计该市居民日用电量的95%的置信区间。
根据中心极限定理可知,在大间为??z?_E近似服从标准正态分布,Y的195%的置信区_z。
1而V1?f2S中总体的方差S2是未知的,用样本方差s2来代替,置信区间n为,?_2。
?由题意知道,y?9.5,s?206,而且样本量为n?300,N?50000,代入可以求得v(y)?_1?f21?50000s??206?0.6825。
将它们代入上面的式子可得该市居民n300 日用电量的95%置信区间为??7.8808,11.1192??。
下一步计算样本量。
绝对误差限d和相对误差限r的关系为d?rY。
根据置信区间的求解方法可知____PyYrY1P1_2_rY根据正态分布的分位数可以知道P。
?Z1??,所以Vz?2?_rY??11?也就是S2nnNz??2?_222_rY1?。
22Nz/2S把y?9.5,s?206,r?10%,N?50000代入上式可得,n?86以总体比例P的195%的置信区间n?1可以写为pzp?z?,将p?0.35,n?200,N?10000代入可得置信区间为??0.2844,0.4156??。
2.5 解:利用得到的样本,计算得到样本均值为?2890/20?144.5,从而估计小区的平均文化支出为144.5元。
统计学练习题及答案数据分布特征的描述1.下面是我国人口和国土面积资料:────────┬─────────────── │根据第四人次人口普查调整数├──────┬──────── │1982年│ 1990年────────┼──────┼──────── 人口总数│ __ │ __ 男│ __ │ __ 女│ __ │ __────────┴──────┴────────国土面积960万平方公里。
试计算所能计算的全部相对指标。
2.某企业2022年某产品单位成本520元,2022年计划规定在上年的基础上单位成本降低5%,实际降低6%,试确定2022年单位成本的计划数与实际数,并计算2022年降低成本计划完成程度指标。
3.某市共有50万人,其市区人口占85%,郊区人口占15%,为了解该市居民的收入水平,在市区抽查了1500户居民,每人平均收入为1400元;在郊区抽查了1000 户居民,每人年平均收入为1380元,若这两个抽样数字具有代表性,则计算该市居民年平均收入应采用哪一种形式的平均数方法进行计算?4.有两个班级统计学成绩如下:根据上表资料计算:(1)哪个班级统计学成绩好?(2)哪个班级的成绩分布差异大?5.2022年8月份甲、乙两农贸市场资料如下:────┬──────┬─────────┬─────────品种│价格(元/斤)│甲市场成交额(万元)│乙市场成交量(万斤)────┼──────┼─────────┼───────── 甲│ 1.2 │ 1.2 │ 2 乙│ 1.4 │ 2.8 │ 1 丙│ 1.5 │ 1.5 │ 1────┼──────┼─────────┼───────── 合计│ ── │ 5.5 │ 4────┴──────┴─────────┴─────────试问哪一个市场农产品的平均价格较高?并说明原因。
6.某车间有甲、乙两个生产组,甲组平均每个工人的日产量36件,标准差9.6件。
第四章 抽样分布与参数估计3.某地区粮食播种面积5000亩,按不重复抽样方法随机抽取了100亩进行实测,调查结果,平均亩产450公斤,亩产量标准差为52公斤。
试以95%的置信度估计该地区粮食平均亩产量和总产量的置信区间。
解:已知X =450公斤,n =100(大样本),n/N=1/50,11≈-Nn,不考虑抽样方式的影响,用重复抽样计算。
s =52公斤,1-α=95%,α=5%。
这时查标准正态分布表,可得临界值:96.1025.02/==z z α该地区粮食平均亩产量的置信区间是:1005296.14502⨯±=±nsz x α=[439.808,460.192] (公斤) 总产量的置信区间是:[439.808⨯5000,460.192⨯5000] (公斤) =[2199040,2300960](公斤)4.已知某种电子管使用寿命服从正态分布。
从一批电子管中随机抽取16只,检测结果,样本平均寿命为1490小时,标准差为24.77小时。
试以95%的置信度估计这批电子管的平均寿命的置信区间。
解:(1)已知X =1490小时,n =16,s =24.77小时,1-α=95%,α=5%。
这时查t 分布表,可得 2.13145)1(2/=-n t α该批电子管的平均寿命的置信区间是:1677.2413145.214902⨯±=±nst x α=[ 1476.801,1503.199](小时)因此,这批电子管的平均寿命的置信区间在1476.801小时与1503.199小时之间。
6.采用简单随机重复抽样的方法,从2 000件产品中抽查200件,其中合格品190件。
要求:(1)计算合格品率及其抽样平均误差。
(2)以95.45%的置信度,对合格品率和合格品数量进行区间估计。
(3)如果极限误差为2.31%,则其置信度是多少? 解:(1)合格品率:P=190/200⨯100%=95% 抽样平均误差:np p p )1()(-=σ=0.015(2)%3%95%100015.02%95)(22/02275.02/±=⨯⨯±=±==p Z P Z Z σαα]19601840[]2000%982000%92[(%]98%92[,,的置信区为:件合格品数量,:合格品率的置信区间为=⨯⨯)(3)%64.87)(8764.01,54.1%31.2%100015.0%31.2)(2/2/2/==-==⨯⨯==∆z F Z Z p Z ασααα查表得7.从某企业工人中随机抽选部分进行调查,所得工资分布数列如下:试求:(1)以95.45%的置信度估计该企业工人平均工资的置信区间,以及该企业工人中工资不少于800元的工人所占比重的置信区间;(2)如果要求估计平均工资的允许误差范围不超过30元,估计工资不少于800元的工人所占比重的允许误差范围不超过10%,置信度仍为95.45%,试问至少应抽多少工人? 解(1)通过EXCEL 计算可得: X =816元,n =50人,s =113.77元。