聚类分析与回归分析SPSS
- 格式:ppt
- 大小:1.21 MB
- 文档页数:27
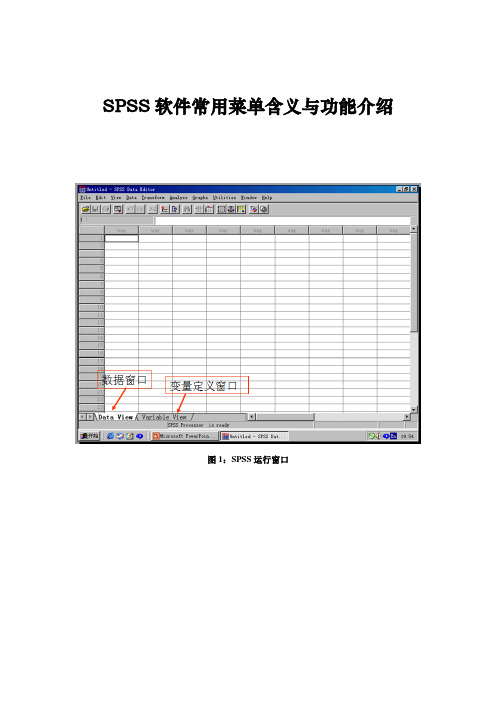
SPSS软件常用菜单含义与功能介绍图1:SPSS运行窗口1、计算产生变量根据已经存在的变量,经过函数计算后,建立新变量或替换员原量的值。
图2:计算产生变量图3:分类汇总1、描述性统计(1)频数分布分析:通过频数分布表、直方图,以及集中趋势和离散趋势的各种统计量,描述数据的分布特征。
(2)描述性统计分析:计算描述数据的集中趋势和离散趋势的各种统计量,还可以做标准化变换(变成均值为0,方差为1的数据)。
(3)探索性分析:判断数据有无离群点(outliers),极端值(extreme values);进行正态分布检验和方差齐性检验;了解数据指标之间差异的特征。
(1)双变量相关分析:分析两个变量之间是否存在相关关系。
(2)偏相关分析:剔除其他变量的影响的情况下,计算两变量之间的相关系数。
3、聚类分析与判别分析(1)系统聚类:最常用的聚类方法。
(2)判别分析:判别所研究的对象属于哪一类的统计方法。
(1)线性回归:一个因变量(dependent )与多个自变量(independents )之间存在线性数量关系。
(2)曲线拟合:可以完成11种曲线的自动拟合(根据需要进行选择),并进行参数估计与检验,绘制拟合图形等。
自变量(independent )只能选一个或者使用时间作为自变量(time: 即使用1,2,3,…,),即只能做一元函数的曲线拟合。
因变量(dependent )可以选多个,将分别做多个一元函数的拟合。
模型Models 模型名称 模型表达式Linear 线性模型 01*y b b x =+ Logarithmic对数模型01*ln y b b x =+Inverse 逆模型 01/y b b x =+ Quadratic 二次模型 2012**y b b x b x =++ Cubic 三次模型 230123***y b b x b x b x =+++Compound 复合模型 01*x y b b =Power 幂模型 10*b y b x = S S 型模型 01/b b x y e +=Growth 生长模型 01*b b x y e += Exponential 指数模型 1*0*b x y b e =LogisticLogistic 模型011/(1)b b x y e --=+一般可以先选择所有的11种模型,再根据结果选择最佳模型。

spss的综合运用——以我国城市空气质量分析为例SPSS(统计产品和服务解决方案)是一种广泛使用的统计分析软件,它可以用于数据处理、数据分析和预测建模等任务。
在我国城市空气质量分析中,可以利用SPSS进行如下几个方面的综合运用:1. 数据清洗和整理:首先需要收集城市空气质量相关的数据,包括空气质量指数(AQI)和各个监测点的相关数据。
然后,使用SPSS进行数据清洗和整理,剔除异常值和缺失值,以确保数据的准确性和完整性。
2. 描述性统计分析:利用SPSS可以计算各个城市的平均空气质量指数、标准差等统计指标,以及绘制相关统计图表,如柱状图、折线图等,以便对不同城市的空气质量进行比较和描述。
3. 相关性分析:使用SPSS可以进行相关性分析,以了解不同因素与空气质量之间的关系。
可以计算不同污染物浓度(如PM2.5、PM10、O3等)与空气质量指数的相关系数,并进行显著性检验,以确定是否存在显著的相关关系。
4. 回归分析:通过回归分析可以探究不同变量对空气质量的影响程度。
可以使用SPSS进行多元线性回归分析,建立空气质量指数与污染物浓度、气象因素等多个自变量之间的关系模型,并进行参数估计和显著性检验。
5. 聚类分析:可以使用SPSS进行聚类分析,将城市按空气质量指数和污染物浓度等因素进行分类,以便对城市进行对比和评估。
聚类分析可以帮助发现城市之间的差异,并为进一步的空气质量改善提供参考。
6. 时间序列分析:通过分析历史数据,利用SPSS进行时间序列分析,可以揭示城市空气质量的长期趋势和季节性变化,帮助预测未来的空气质量状况,以及制定相应的政策和措施。
SPSS在我国城市空气质量分析中的综合运用可以包括数据清洗和整理、描述性统计分析、相关性分析、回归分析、聚类分析和时间序列分析等方面,这些分析结果可以为了解和改善城市空气质量提供科学依据。

利用SPSS进行数据处理和分析的技巧数据是一个有用的工具,它可以帮助我们了解问题并做出更好的决策。
然而,对于大多数人来说,数据处理和分析可能会让人望而却步。
幸运的是,有一些工具可以帮助我们更轻松地处理和分析数据,其中最常用的工具之一是SPSS。
SPSS是一个广泛用于数据分析的软件包,可以轻松地进行描述性统计、假设检验、回归分析、因子分析和聚类分析等等。
在本文中,我们将探讨利用SPSS进行数据处理和分析的一些技巧。
第一步:数据的输入和清理在使用SPSS进行数据分析之前,首先需要将数据输入到SPSS 中。
数据可以来自Excel或其他电子表格程序,也可以手动输入。
在输入数据时,要注意数据类型,例如文本、数字和日期等。
要确保数据以正确的格式输入,以便进行后续的分析。
一旦数据已经输入到SPSS中,接下来需要对数据进行清理。
数据清理的目的是修复数据中的错误或缺失值,以确保数据的质量和正确性。
SPSS提供了一些工具来帮助用户对数据进行清理。
例如,可以使用SPSS Data Editor中的查找替换功能,通过查找敏感字词或错误数据,减少数据清理的负担。
SPSS还提供了插件程序,如Validate命令、Codebook等等,它们可以在清洗数据方面提供有用的支持。
第二步:描述性统计分析描述性统计分析可以帮助我们了解数据集的基本特征,例如中位数、众数、平均数、标准差和范围等等。
在SPSS中,进行描述性统计分析非常简单。
首先,选择“Analyze”菜单中的“Descriptive Statistics”选项,然后选择要分析的变量。
SPSS将生成一个报告,其中包含描述性统计信息。
在生成描述性统计报告之后,可以将其保存在SPSS的输出窗口中,以便之后参考。
此外,还可以使用SPSS的导入导出功能将描述性统计结果导出到其他程序中,例如Word或Excel。
第三步:假设检验假设检验可以帮助我们确定实际观察结果与预期结果之间是否存在显著差异。

使用SPSS软件进行因子分析和聚类分析的方法使用SPSS软件进行因子分析和聚类分析的方法随着统计分析软件的发展,SPSS(Statistical Package for the Social Sciences)软件作为一款功能强大、易于使用的统计分析工具受到广泛欢迎。
它能帮助研究人员进行各种统计分析,其中包括因子分析和聚类分析。
本文将介绍如何使用SPSS软件进行因子分析和聚类分析,并针对每个分析方法提供详细步骤和操作示例。
一、因子分析因子分析是一种常用的统计方法,在数据维度缩减和相关变量结构分析方面具有广泛的应用。
以下是使用SPSS软件进行因子分析的步骤:1. 数据准备首先,需要将原始数据导入SPSS软件中。
可以通过选择“文件”>“打开”>“数据”,然后选择合适的数据文件进行导入。
确保数据是以矩阵的形式存储,每个变量占据一列,每个观察单位占据一行。
2. 因子分析设置在SPSS软件中,选择“分析”>“数据准备”>“特殊分析”>“因子”。
在弹出的对话框中,选择需要进行因子分析的变量,将它们移动到“因子”框中。
然后,选择所需的因子提取方法(如主成分分析或因子分析),并指定所需的因子个数。
可以选择默认值,也可以根据实际需求进行调整。
3. 统计输出完成因子分析设置后,点击“确定”按钮开始分析。
SPSS软件将生成一个因子分析结果报告。
报告中将包含因子载荷矩阵、特征值、解释的方差比例等统计指标。
通过这些指标,可以对变量和因子之间的关系、每个因子的解释能力进行分析。
4. 结果解读对于因子载荷矩阵,可以根据因子载荷的大小来判断变量与因子之间的关系。
一般来说,载荷绝对值大于0.3的变量与因子之间具有显著关联。
解释的方差比例表示每个因子能够解释变量总方差的比例,一般来说,越大越好。
在解读结果时,需要综合考虑因子载荷和解释的方差比例。
二、聚类分析聚类分析是一种用于数据分类的统计方法。
它根据观测值之间的相似性将数据对象分组到不同的类别中。


SPSS基本功能及操作SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,它提供了一系列强大的数据处理和分析功能,广泛应用于社会科学、商业和医学等领域。
本文将介绍SPSS的基本功能及操作,帮助用户了解如何使用该软件进行数据分析。
一、数据输入与管理2. 数据导入:用户可以从外部文件中导入数据,如Excel文件、文本文件等,方便检索和分析。
二、数据描述与统计分析SPSS提供了丰富的数据描述和统计分析功能,帮助用户更好地理解和解释数据。
下面是一些常用的数据描述和统计分析功能:1.描述统计:SPSS可以计算变量的描述统计量,如均值、标准差、最大值、最小值等,帮助用户了解数据的基本特征。
2.频数分析:对分类变量进行频数分析,生成频数表、百分比表和列联表等,并支持绘制直方图和柱状图。
3.相关分析:计算变量之间的相关系数,帮助用户了解变量之间的相关关系,并支持绘制散点图和相关矩阵图。
4.方差分析:进行单因素或多因素方差分析,检验不同因素对因变量的影响,并进行统计显著性检验。
5.回归分析:进行线性回归或多元回归分析,建立回归模型,预测因变量的值,并进行模型评估和统计检验。
三、数据可视化与报告输出SPSS提供了丰富的数据可视化和报告输出功能,帮助用户更直观地呈现数据分析结果。
下面是一些常用的数据可视化和报告输出功能:1.图表绘制:SPSS支持绘制多种图表类型,如直方图、柱状图、散点图、线图等,帮助用户更好地展示数据分布和趋势。
2. 报告输出:用户可以将数据分析结果导出为报告格式,如Word、PDF等,方便结果的分享和演示。
3.表格制作:用户可以在SPSS中直接生成各类统计分析结果的表格,如频数表、交叉表、相关矩阵表等,便于数据的整理和查阅。
4.发布图形:用户可以将统计结果图形发布到网页或者PPT等,方便在其他软件中引用和展示。
四、数据挖掘与高级分析SPSS提供了一些高级的数据挖掘和分析功能,帮助用户发现数据中的隐藏信息和规律。
第8 章利用SPSS 进行Logistic 回归分析现实中的很多现象可以划分为两种可能,或者归结为两种状态,这两种状态分别用0和1 表示。
如果我们采用多个因素对0-1 表示的某种现象进行因果关系解释,就可能应用到logistic 回归。
Logistic 回归分为二值logistic 回归和多值logistic 回归两类。
首先用实例讲述二值logistic 回归,然后进一步说明多值logistic 回归。
在阅读这部分内容之前,最好先看看有关SPSS 软件操作技术的教科书。
§8.1 二值logistic 回归8.1.1 数据准备和选项设置我们研究2005 年影响中国各地区城市化水平的经济地理因素。
城市化水平用城镇人口比重表征,影响因素包括人均GDP、第二产业产值比重、第三产业产值比重以及地理位置。
地理位置为名义变量,中国各地区被分别划分到三大地带:东部地带、中部地带和西部地带。
我们用各地区的地带分类代表地理位置。
第一步:整理原始数据。
这些数据不妨录入Excel 中。
数据整理内容包括两个方面:一是对各地区按照三大地带的分类结果赋值,用0、1 表示,二是将城镇人口比重转换逻辑值,变量名称为“城市化”。
以各地区2005 年城镇人口比重的平均值45.41%为临界值,凡是城镇人口比重大于等于45.41%的地区,逻辑值用Yes 表示,否则用No 表示(图8-1-1)图8-1-1 原始数据(Excel 中,局部)将数据拷贝或者导入SPSS 的数据窗口(Data View)中(图8-1-2)。
图8-1-2 中国31 个地区的数据(SPSS 中,局部)第二步:打开“聚类分析”对话框。
沿着主菜单的“Analyze→Regression→Binary Logistic K”的路径(图8-1-3)打开二值Logistic 回归分析选项框(图8-1-4)。
图8-1-3 打开二值Logistic 回归分析对话框的路径对数据进行多次拟合试验,结果表明,像二产比重、三产比重等对城市化水平影响不显著。
SPSSStatistics功能介绍1. 数据导入和数据处理:SPSS Statistics能够导入各种数据格式,包括Excel、CSV、文本文件等。
用户可以对导入的数据进行清洗和处理,包括数据去重、缺失值处理、异常值处理等。
2. 描述性统计分析:SPSS Statistics提供了一系列描述性统计方法,可以计算数据的均值、标准差、中位数、最大值、最小值等。
通过这些统计指标,用户可以快速了解数据的分布和基本特征。
3. 统计推断和假设检验:SPSS Statistics提供了多种统计推断方法,包括t检验、方差分析、回归分析等。
用户可以根据样本数据对总体进行推断,并进行假设检验来判断统计结果的显著性。
4. 多元分析:SPSS Statistics支持多元回归、逐步回归、逻辑回归等多元分析方法。
用户可以通过多元分析来探究多个变量之间的关系,并进行预测建模。
5. 聚类和分类分析:SPSS Statistics提供了聚类和分类分析方法,帮助用户将数据根据特定的变量进行分组或分类。
聚类分析能够将相似样本归为一类,分类分析则可以根据已知样本对新样本进行分类。
6. 因子分析和主成分分析:SPSS Statistics支持因子分析和主成分分析方法,用于降维和变量选择。
因子分析可以提取出影响数据变化的关键因素,主成分分析则可以将多个相关变量组合成较少的不相关变量。
7. 时间序列分析:SPSS Statistics提供了时间序列分析的方法,包括移动平均、指数平滑、ARIMA模型等。
用户可以使用这些方法来分析和预测时间序列数据。
8. 数据可视化:SPSS Statistics提供了丰富的数据可视化功能,用户可以通过柱状图、折线图、散点图等方式直观地展示数据的分布和趋势。
同时,用户还可以通过自定义图表格式和样式来使图表更加美观和直观。
9. 报告生成和分享:SPSS Statistics可以生成详细的统计分析报告,并支持导出为Word、Excel、PDF等格式。
SPSS19.0实战之聚类分析这篇文章与上一篇的回归分析是一次实习作业整理出来的。
所以参考文献一并放在该文最后。
CNBlOG网页排版太困难了,又不喜欢live writer……聚类分析是将物理或者抽象对象的集合分成相似的对象类的过程。
本次实验我将对同一批数据做两种不同的类型的聚类;它们分别是系统聚类和K-mean聚类。
其中系统聚类的聚类方法也采用3种不同方法,来考察对比它们之间的优劣。
由于没有样本数据,因此不能根据其数据做判别分析。
评价标准主要是观察各聚类方法的所得到的类组间距离和组内聚类的大小。
分析数据依然采用线性回归所使用的标准化后的能源消费数据。
1.1 系统聚类本次实验的系统聚类都是凝聚系统聚类,为了控制变量,都采用平方Euclidean距离。
1.1.1 最短距离聚类法最短距离法聚类步骤如下:规定样本间的距离,计算样本两两之间的距离,得到对称矩阵。
开始每个样品自成一类。
选择对称矩阵中的最小非零元素。
将两个样品之间最小距离记为D1,将这两个样品归并成为一类,记为G1。
计算G1与其他样品距离。
重复以上过程直到所有样品合并为一类。
我们在SPSS中实现最短距离分析非常简单。
单击“”-->“” -->“”。
将弹出如图1-1所示的对话框,设置相应的参数即可。
图1-1 最短距离法我们的数据已经做过标准化,在“转化值”-->“标准化”选项上选无。
在统计量的聚类成员中选择“无”,因为这是非监督分类,不需要指定最终分出的类个数。
在绘制中选择绘制“树状图”。
单击确定,得到以下结果。
表3-1显示了数据的缺失情况:表1-1我们的数据经过预处理,所以缺失值个数为0.2. 由于相关矩阵过于庞大,无法在文档中贴出,得到的是一个非相似矩阵。
表1-2是样品聚类过程。
样品21和28在第一步合并为一类,它们之间的非相关系数最小,为0.211。
在下一次合并是第十步。
在第五步的时候,样品2、27、14组成一类,出现群集,样品个数为3。
数据分析方法大全SPSS数据分析方法详解SPSS(Statistical Package for the Social Sciences)是一种常用的数据分析软件,广泛应用于各个领域的研究和统计分析。
下面是一些常用的数据分析方法和技术,以及如何在SPSS中进行实施。
1.描述性统计分析:SPSS可以计算各种描述性统计指标,如平均数、中位数、标准差、百分位数等。
可以使用“统计”菜单下的“描述统计”选项完成。
2.相关分析:相关分析用于研究两个或多个变量之间的关系。
SPSS提供了许多方法来计算相关系数,如皮尔逊相关系数、斯皮尔曼等级相关系数等。
可以使用“分析”菜单下的“相关”选项进行分析。
3.回归分析:回归分析用于研究一个或多个自变量与因变量之间的关系。
SPSS提供了多种回归模型,如线性回归、多元回归、逐步回归等。
可以使用“分析”菜单下的“回归”选项进行分析。
4.方差分析:方差分析用于比较两个或多个组之间的平均值是否显著不同。
SPSS提供了单因素方差分析、二因素方差分析、协方差分析等多种方法。
可以使用“分析”菜单下的“方差”选项进行分析。
5.t检验和方差齐性检验:t检验用于比较两个样本平均值是否显著不同,而方差齐性检验用于检验两个样本方差是否相等。
SPSS提供了独立样本t检验、配对样本t检验、方差齐性检验等多种方法。
可以使用“分析”菜单下的“比较均值”选项进行分析。
6.散点图和箱线图:散点图用于可视化两个变量之间的关系,箱线图用于可视化不同组之间的差异。
可以使用“图表”菜单下的“散点图”和“箱线图”选项进行绘制。
7.因子分析和聚类分析:因子分析用于将多个变量归纳为较少的无关连的维度,聚类分析用于将相似的对象归为同一组。
SPSS提供了因子分析和聚类分析的功能,可以使用“分析”菜单下的“因子”和“聚类”选项进行分析。
8.生存分析:生存分析用于研究事件发生的时间和概率。
SPSS提供了生存分析的方法,如卡普兰-迈尔曲线、生存函数、风险比等。