spss曲线拟合与回归分析
- 格式:doc
- 大小:161.00 KB
- 文档页数:10
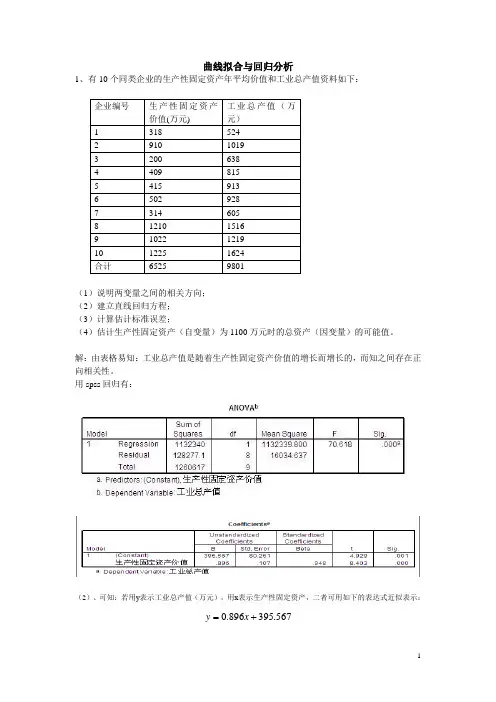
曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:=x.0+y.567395896(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。

SPSS 10.0高级教程十二:多元线性回归与曲线拟合回归分析是处理两个及两个以上变量间线性依存关系的统计方法。
在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。
回归分析就是用于说明这种依存变化的数学关系。
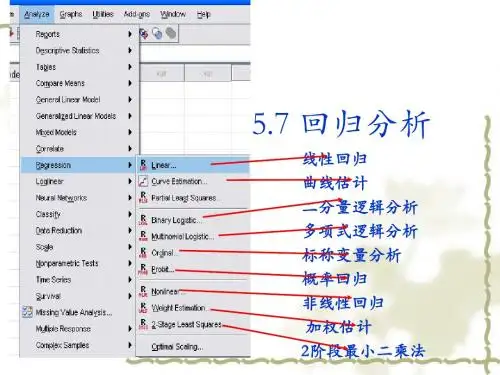
§10.1Linear过程10.1.1 简单操作入门调用此过程可完成二元或多元的线性回归分析。
在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。
例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响?显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。
但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。
回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。
这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。
10.1.1.1 界面详解在菜单中选择Regression==>liner,系统弹出线性回归对话框如下:除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。
【Dependent框】用于选入回归分析的应变量。
【Block按钮组】由Previous和Next两个按钮组成,用于将下面Independent框中选入的自变量分组。
由于多元回归分析中自变量的选入方式有前进、后退、逐步等方法,如果对不同的自变量选入的方法不同,则用该按钮组将自变量分组选入即可。
下面的例子会讲解其用法。
【Independent框】用于选入回归分析的自变量。
【Method下拉列表】用于选择对自变量的选入方法,有Enter(强行进入法)、Stepwise(逐步法)、Remove(强制剔除法)、Backward(向后法)、Forward(向前法)五种。


数据统计分析软件SPSS的应用(五)——相关分析与回归分析数据统计分析软件SPSS的应用(五)——相关分析与回归分析数据统计分析软件SPSS是目前应用广泛且非常强大的数据分析工具之一。
在前几篇文章中,我们介绍了SPSS的基本操作和一些常用的统计方法。
本篇文章将继续介绍SPSS中的相关分析与回归分析,这些方法是数据分析中非常重要且常用的。
一、相关分析相关分析是一种用于确定变量之间关系的统计方法。
SPSS提供了多种相关分析方法,如皮尔逊相关、斯皮尔曼相关等。
在进行相关分析之前,我们首先需要收集相应的数据,并确保数据符合正态分布的假设。
下面以皮尔逊相关为例,介绍SPSS 中的相关分析的步骤。
1. 打开SPSS软件并导入数据。
可以通过菜单栏中的“File”选项来导入数据文件,或者使用快捷键“Ctrl + O”。
2. 准备相关分析的变量。
选择菜单栏中的“Analyze”选项,然后选择“Correlate”子菜单中的“Bivariate”。
在弹出的对话框中,选择要进行相关分析的变量,并将它们添加到相应的框中。
3. 进行相关分析。
点击“OK”按钮后,SPSS会自动计算所选变量之间的相关系数,并将结果输出到分析结果窗口。
4. 解读相关分析结果。
SPSS会给出相关系数的值以及显著性水平。
相关系数的取值范围为-1到1,其中-1表示完全负相关,1表示完全正相关,0表示没有相关关系。
显著性水平一般取0.05,如果相关系数的显著性水平低于设定的显著性水平,则可以认为两个变量之间存在相关关系。
二、回归分析回归分析是一种用于探索因果关系的统计方法,广泛应用于预测和解释变量之间的关系。
SPSS提供了多种回归分析方法,如简单线性回归、多元线性回归等。
下面以简单线性回归为例,介绍SPSS中的回归分析的步骤。
1. 打开SPSS软件并导入数据。
同样可以通过菜单栏中的“File”选项来导入数据文件,或者使用快捷键“Ctrl + O”。
2. 准备回归分析的变量。

SPSS-回归分析回归分析(⼀元线性回归分析、多元线性回归分析、⾮线性回归分析、曲线估计、时间序列的曲线估计、含虚拟⾃变量的回归分析以及逻辑回归分析)回归分析中,⼀般⾸先绘制⾃变量和因变量间的散点图,然后通过数据在散点图中的分布特点选择所要进⾏回归分析的类型,是使⽤线性回归分析还是某种⾮线性的回归分析。
回归分析与相关分析对⽐:在回归分析中,变量y称为因变量,处于被解释的特殊地位;;⽽在相关分析中,变量y与变量x处于平等的地位。
在回归分析中,因变量y是随机变量,⾃变量x可以是随机变量,也可以是⾮随机的确定变量;⽽在相关分析中,变量x和变量y都是随机变量。
相关分析是测定变量之间的关系密切程度,所使⽤的⼯具是相关系数;⽽回归分析则是侧重于考察变量之间的数量变化规律。
统计检验概念:为了确定从样本(sample)统计结果推论⾄总体时所犯错的概率。
F值和t值就是这些统计检定值,与它们相对应的概率分布,就是F分布和t分布。
统计显著性(sig)就是出现⽬前样本这结果的机率。
标准差表⽰数据的离散程度,标准误表⽰抽样误差的⼤⼩。
统计检验的分类:拟合优度检验:检验样本数据聚集在样本回归直线周围的密集程度,从⽽判断回归⽅程对样本数据的代表程度。
回归⽅程的拟合优度检验⼀般⽤判定系数R2实现。
回归⽅程的显著性检验(F检验):是对因变量与所有⾃变量之间的线性关系是否显著的⼀种假设检验。
回归⽅程的显著性检验⼀般采⽤F 检验。
回归系数的显著性检验(t检验): 根据样本估计的结果对总体回归系数的有关假设进⾏检验。
1.⼀元线性回归分析定义:在排除其他影响因素或假定其他影响因素确定的条件下,分析某⼀个因素(⾃变量)是如何影响另⼀事物(因变量)的过程。
SPSS操作2.多元线性回归分析定义:研究在线性相关条件下,两个或两个以上⾃变量对⼀个因变量的数量变化关系。
表现这⼀数量关系的数学公式,称为多元线性回归模型。
SPSS操作3.⾮线性回归分析定义:研究在⾮线性相关条件下,⾃变量对因变量的数量变化关系⾮线性回归问题⼤多数可以化为线性回归问题来求解,也就是通过对⾮线性回归模型进⾏适当的变量变换,使其化为线性模型来求解。
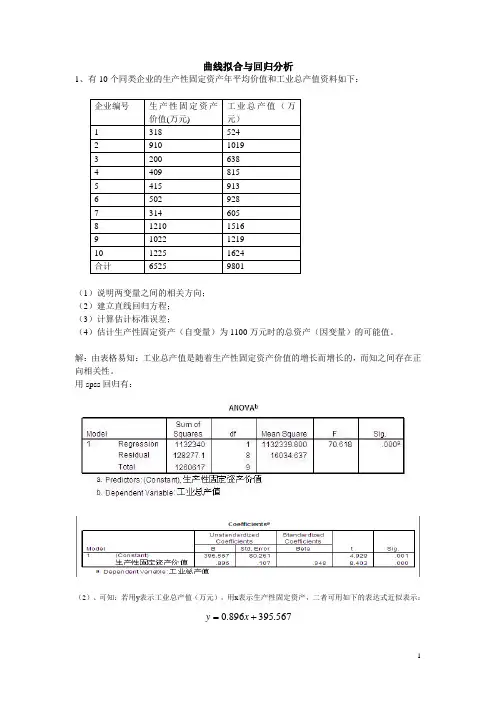
曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:=x.0+y.567395896(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。




线性回归的首要满足条件是因变量与自变量之间呈线性关系,之后的拟合算法也是基于此,但是如果碰到因变量与自变量呈非线性关系的话,就需要使用非线性回归进行分析。
SPSS中的非线性回归有两个过程可以调用,一个是分析—回归—曲线估计,另一个是分析—回归—非线性,两种过程的思路不同,这也是非线性回归的两种分析方法,前者是通过变量转换,将曲线线性化,再使用线性回归进行拟合;后者则是直接按照非线性模型进行拟合。
我们按照两种方法分别拟合同一组数据,将结果进行比较。
分析—回归—曲线估计
变量转换的方法简单易行,在某些情况下是首选,但是只能拟合比较简单的(选项中有的)非线性关系,并且该方法存在一定的缺陷,例如
1.通过变量转换使用最小二乘法拟合的结果,再变换回原值之后不一定是最优解,并且变量转换也可能会改变残差的分布和独立性等性质。
2.曲线关系复杂时,无法通过变量转换进行直线化
3.曲线直线化之后,只能通过最小二乘法进行拟合,其他拟合方法无法实现
基于以上问题,非线性回归模型可以很好的解决,它和线性回归模型一样,也提出一个基本模型框架,所不同的是模型中的期望函数可以为任意形式,甚至没有表达式,在参数估计上,由于是曲线,无法直接使用最小二乘法进行估计,需要使用高斯-牛顿法进行估计,这一方法比较依赖于初始值的设定。
下面我们来直接按照非线性模型进行拟合,看看结果如何
分析—回归—非线性
以上用了两种方差进行拟合,从决定系数来看似乎非线性回归更好一点,但是要注意的是,曲线回归计算出的决定系数是变量转换之后的,并不一定能代表变换之前的变异解释程度,这也说明二者的决定系数不一定可比。
我们可以通过两种方法计算出的预测值与残差图进行比较来判断优劣,首先将相关结果保存为变量,再做图。
SPSS回归分析SPSS(Statistical Package for the Social Sciences)是一种用来进行统计分析的软件,其中包括回归分析。
回归分析是一种用来找出因变量与自变量之间关系的统计方法。
在回归分析中,我们可以通过控制自变量,预测因变量的值。
SPSS中的回归分析提供了多种模型,其中最常用的是线性回归分析。
线性回归分析模型假设因变量与自变量之间存在线性关系。
在执行回归分析前,需要明确因变量和自变量的选择。
通常,因变量是我们要预测或解释的变量,而自变量是用来解释或预测因变量的变量。
首先,我们需要导入数据到SPSS。
在导入数据前,要确保数据的结构合适,缺失值得到正确处理。
然后,在SPSS中打开回归分析对话框,选择线性回归模型。
接下来,我们需要指定因变量和自变量。
在指定因变量和自变量后,SPSS会自动计算回归模型的系数和统计指标。
其中,回归系数表示自变量的影响程度,统计指标(如R方)可以衡量模型的拟合程度。
在执行回归分析后,我们可以进一步分析回归模型的显著性。
一种常用的方法是检查回归系数的显著性。
SPSS会为每个回归系数提供一个t检验和相应的p值。
p值小于其中一显著性水平(通常是0.05)可以认为回归系数是显著的,即自变量对因变量的影响是有意义的。
此外,我们还可以通过分析残差来检查模型的适当性。
残差是观测值与回归模型预测值之间的差异。
如果残差分布服从正态分布,并且没有明显的模式(如异方差性、非线性),则我们可以认为模型是适当的。
最后,我们可以使用SPSS的图表功能来可视化回归模型。
比如,我们可以绘制散点图来展示自变量和因变量之间的关系,或者绘制残差图来检查模型的适当性。
总之,SPSS提供了强大的回归分析功能,可以帮助我们探索变量之间的关系并预测因变量的值。
通过进行回归分析,我们可以得到有关自变量对因变量的影响的信息,并评估模型的拟合程度和适用性。
数据统计分析软件SPSS的应用相关分析与回归分析一、本文概述随着信息技术的快速发展和大数据时代的来临,数据统计分析在各个领域的应用越来越广泛。
SPSS作为一款功能强大的数据统计分析软件,其在社会科学、商业分析、医学统计等多个领域具有广泛的应用。
本文将深入探讨SPSS在相关分析与回归分析中的应用,帮助读者更好地理解和应用这一强大的工具。
本文将简要介绍SPSS软件的基本功能和特点,使读者对其有一个初步的了解。
随后,文章将重点介绍相关分析的概念、类型及其在SPSS中的实现方法,包括皮尔逊相关系数、斯皮尔曼秩相关系数等。
文章还将详细阐述回归分析的基本原理、类型及其在SPSS中的操作步骤,如线性回归分析、逻辑回归分析等。
通过本文的学习,读者将能够掌握SPSS在相关分析与回归分析中的基本应用,提高数据处理和分析的能力,为实际工作和研究提供有力支持。
文章还将提供一些实际案例,以帮助读者更好地理解和应用所学知识,提高实际操作能力。
二、SPSS软件基础SPSS,全称为Statistical Package for the Social Sciences,即“社会科学统计软件包”,是一款广泛应用于社会科学领域的数据统计分析软件。
它提供了丰富的数据分析工具,包括描述性统计、推论性统计、探索性数据分析、回归分析、因子分析、聚类分析等,能够帮助研究者轻松处理和分析数据,挖掘数据背后的深层次信息。
在使用SPSS之前,用户需要对其基本界面和常用功能有所了解。
SPSS界面友好,主要分为菜单栏、工具栏、数据视图和变量视图等部分。
菜单栏包含了大多数统计分析功能的命令,如“分析”“描述统计”“因子分析”等。
工具栏则提供了一些常用的统计分析工具的快捷方式。
数据视图是用户输入和编辑数据的地方,而变量视图则用于定义变量的属性,如变量名、变量类型、宽度、小数位数等。
在SPSS中,数据分析的核心步骤通常包括数据准备、数据分析、结果解释和报告生成。
曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:企业编号生产性固定资产价值(万元) 工业总产值(万元)1 318 5242 910 10193 200 6384 409 8155 415 9136 502 9287 314 6058 1210 15169 1022 121910 1225 1624合计6525 9801(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:567.395896.0+=xy(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。
解:用spss 进行回归分析:若用21,,x x y 分别表示销售利润率、职工平均销售额和流通费用水平,则通过以上的分析结果可知21985.0909.2769.6x x y ++-=;并且由显著性水平可知:流通费用水平对销售利润率影响不大(0.131大于0.05),而职工平均销售额的显著性水平为0,说明它对销售利润率的影响很大。
第五章 方差分析与假设检验1、(P75)为比较5种品牌的合成木板的耐久性,对每个品牌取4个样品作摩擦实验测量磨损量,得以下数据:(1)、它们的耐久性有无明显差异? (2)、有选择的作两品牌的比较,能得出什么结果? 解:(1)、用spss 进行方差分析有:A、B、C、D四种品牌的标准差相近,它们的耐久性没有明显的差异。
用MA TLAP分析有:function anova_1fm1 = [2.2 2.1 2.4 2.5;2.2 2.3 2.4 2.6;2.2 2.0 1.9 2.1;2.4 2.7 2.6 2.7;2.3 2.5 2.3 2.4;];p=anova1(fm1);display(p);得到:p= 0.5737>0.05,也能得到相同的结论。
(2)、从五种品牌的平均值可以判断这种品牌的总体耐久性的好坏,其方差和标准差可以说明它的各个样本之间耐久性的差异。
例如A、B两种品牌,B的总体水平要稍高,而且它的各个样品间差异较小。
2、将土质基本相同的一块耕地分成5块,每块又均等分成4小块。
在每块地内把4个品种的小麦分种在4小块内,每小块的播种量相等,册的收获量如下:A1 A2 A3 A4 A5B1 32.3 34.0 34.7 36.0 35.5B2 33.2 33.6 36.8 34.3 36.1B3 30.8 34.4 32.3 35.8 32.8B4 29.5 26.2 28.1 28.5 29.4考察地块和品种对小麦的收获量有无显著影响?并在必要时做进一步比较。
解:利用MATLAP进行分析:function anova_2fm1 = [32.3 34.0 34.7 36.0 35.5;33.2 33.6 36.8 34.3 36.1;30.8 34.4 32.3 35.8 32.8;29.5 26.2 28.1 28.5 29.4;];p=anova2(fm1,2);display(p);得到:p =0.7770 0.0121 0.9393由于05.07770.01>=p ,所以地块对小麦的收获量没有影响; 由于05.00121.001.02<=<p ,所以品种对其收获量有显著影响; 由于05.09393.03>=p ,所以地块和品种的交互作用对收获量也没有影响。
进一步比较:把种在B2中的小麦品种放在A3这块地中种植可得到最高产量。
第六章 计算机模拟1、你到海边度假,听到当地气象台的天气预报每天下雨的机会是40%,用蒙特卡罗方法模拟你的假期中有4天连续下雨的概率。
解:可以假设该地方的天气情况为一个半径为5的大圆,然后下雨这种情况是它内部半径是10的同心圆,利用蒲丰投针的方法,就可以知道“连续四次投到小圆”这种情况发生的概率就是连续4天下雨的概率。
其MA TLAP 程序如下所示: function rain_value l = 5;d = sqrt(10); m = 0;b=0; n = 10000; for i = 1:(n-4)a = unifrnd(0,d,n,1); y = unifrnd(0,l,n,1); for j= 1:4if pi*a(i+j)*a(i+j) <= pi*y(i+j)*y(i+j) b = b + 1 ; end endif b == 10 m = m+1; elseif n<10 b = 0; end endp = 4*m/n; display(p)运行结果: p =4.0000e-003由此可知:连续4天都下雨的概率为:0.4*0.4*0.4*0.4=0.02562、一个带有船只卸货的岗楼,任何时间仅能为一艘船只卸货。
船只进港是为了卸货,相邻两艘船只到达的时间间隔在15分钟到145分钟之间变化。
一艘船只卸货的时间由所卸货物类型决定,在45分钟到90分钟之间变化,请回答以下问题:(1)、每艘船只在港口的平均时间和最长时间是多少?(2)、若一艘船只的等待时间是从到达到开始卸货的时间,每艘船只的平均等待时间和最长等待时间是多少?(3)、卸货设备空闲时间的百分比是多少?(4)、船只排队最长的长度是多少?解:这个问题可以看做是一个排队的例子,用MATLAP求解程序如下所示:function timeWaiting = simu3_ship(n)n = input('n=');m=0;x = zeros(1,n);y = zeros(1,n);D = zeros(1,n);leng = zeros(1,n);t = unifrnd(65,130,1,n)+15; %两艘船到达的时间间隔s = unifrnd(22.5,45,1,n)+45; %一艘船只的卸货时间x(1) = t(1); %第一艘船到达的时间for i = 2:ny(i) = x(i-1) + t(i); %第2~n搜船到达的时间j = i - 1;c(j) = x(j) + s(j)+ D(j); %计算第一艘船离开的时间if c(j) < y(i) %比较相邻两艘船离开、到达时刻的大小D(i) = 0;D3(i) = y(i)-c(j); %D3用来计算空闲的时间elseD(i) = c(j) - y(i);D3(i) = 0;endx(i) = y(i);D1(i) = D(i)+s(i);D2(i) = D(i);for k = 2:nif c(j) > y(k)m = m+1;endleng(j) = m; %计算每艘船在卸货的时候,等待的船只个数endm = 0;endaverageWaiting1 = mean(D1);maxWaiting1 = max(D1);averageWaiting2 = mean(D2);maxWaiting2 = max(D2);maxLength = max(leng);freerate3 = sum(D3(i))/(sum(D3(i))+sum(s(i-1)));display(averageWaiting1);display(maxWaiting1);display(averageWaiting2);display(maxWaiting2);display(freerate3);display(maxLength);在命令窗口输入:n=10运行结果:averageWaiting1 =72.5714maxWaiting1 =72.5714averageWaiting2 =0.7345maxWaiting2 =7.3453freerate3 =0.2007maxLength =8可知:(1)、每艘船只在港口的平均时间和最长时间是72.5714和72.5714分种。
(2)、若一艘船只的等待时间是从到达到开始卸货的时间,每艘船只的平均等待时间和最长等待时间是0.7345和7.3453分种。