相关分析和一元线性回归分析SPSS报告
- 格式:doc
- 大小:586.00 KB
- 文档页数:14




相关分析和回归分析SPSS实现SPSS(统计包统计分析软件)是一种广泛使用的数据分析工具,在相关分析和回归分析方面具有强大的功能。
本文将介绍如何使用SPSS进行相关分析和回归分析。
相关分析(Correlation Analysis)用于探索两个或多个变量之间的关系。
在SPSS中,可以通过如下步骤进行相关分析:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单,然后选择“相关”子菜单。
3.在“相关”对话框中,选择将要分析的变量,然后单击“箭头”将其添加到“变量”框中。
4.选择相关系数的计算方法(如皮尔逊相关系数、斯皮尔曼等级相关系数)。
5.单击“确定”按钮,SPSS将计算相关系数并将结果显示在输出窗口中。
回归分析(Regression Analysis)用于建立一个预测模型,来预测因变量在自变量影响下的变化。
在SPSS中,可以通过如下步骤进行回归分析:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单,然后选择“回归”子菜单。
3.在“回归”对话框中,选择要分析的因变量和自变量,然后单击“箭头”将其添加到“因变量”和“自变量”框中。
4.选择回归模型的方法(如线性回归、多项式回归等)。
5.单击“统计”按钮,选择要计算的统计量(如参数估计、拟合优度等)。
6.单击“确定”按钮,SPSS将计算回归模型并将结果显示在输出窗口中。
在分析结果中,相关分析会显示相关系数的数值和统计显著性水平,以评估变量之间的关系强度和统计显著性。
回归分析会显示回归系数的数值和显著性水平,以评估自变量对因变量的影响。
值得注意的是,相关分析和回归分析在使用前需要考虑数据的要求和前提条件。
例如,相关分析要求变量间的关系是线性的,回归分析要求自变量与因变量之间存在一定的关联关系。
总结起来,SPSS提供了强大的功能和工具,便于进行相关分析和回归分析。
通过上述步骤,用户可以轻松地完成数据分析和结果呈现。
然而,分析结果的解释和应用需要结合具体的研究背景和目的进行综合考虑。

实验报告四.spss一元线性相关回归分析预测
本实验使用spss 17.0软件,针对50个被试者,使用一元线性相关回归分析预测变
量X和Y的关系。
一、实验目的
通过一元线性相关回归分析,预测50个被试者的被试变量X(会计实操次数)和被试变量Y(综合评价分)之间的关系,来检验变量X是否能够预测变量Y的值。
二、实验流程
(2)数据收集:通过收集50个被试者的实际实操次数与综合评价分,建立反映这两
者之间关系的一元线性回归方程。
(3)数据分析:通过SPSS软件的一元线性相关回归分析预测变量X和Y的关系,使
用R方值进行检验研究结果的显著性。
以分析变量X对于变量Y的影响程度。
三、实验结果及分析
1.回归分析结果如下所示:变量X的系数b = 0.6755,t = 7.561,p = 0.000,说
明变量X和被试变量Y之间存在着显著的相关关系;R方值为0.941,说明变量X可以较
好地预测变量Y。
2.可以得出一元线性回归方程为:Y=0.67×X+5.293,其中,b为系数,X是自变量,Y是因变量。
四、结论
(1)50个被试者实际实操次数与综合评价分之间存在着显著的相关性;
(2)变量X可以较好地预测变量Y,R方值较高;。

相关分析与回归分析一、试验目标与要求本试验项目的目的是学习并使用SPSS 软件进展相关分析和回归分析,具体包括:(1) 皮尔逊pearson 简单相关系数的计算与分析(2) 学会在SPSS 上实现一元与多元回归模型的计算与检验。
(3) 学会回归模型的散点图与样本方程图形。
(4) 学会对所计算结果进展统计分析说明。
(5) 要求试验前,了解回归分析的如下内容。
♦ 参数α、β的估计♦ 回归模型的检验方法:回归系数β的显著性检验〔t -检验〕;回归方程显著性检验〔F -检验〕。
二、试验原理1.相关分析的统计学原理相关分析使用某个指标来明确现象之间相互依存关系的密切程度。
用来测度简单线性相关关系的系数是Pearson 简单相关系数。
2.回归分析的统计学原理相关关系不等于因果关系,要明确因果关系必须借助于回归分析。
回归分析是研究两个变量或多个变量之间因果关系的统计方法。
其根本思想是,在相关分析的根底上,对具有相关关系的两个或多个变量之间数量变化的一般关系进展测定,确立一个适宜的数据模型,以便从一个量推断另一个未知量。
回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数和模型进展检验和判断,并进展预测等。
线性回归数学模型如下:i ik k i i i x x x y εββββ+++++= 22110在模型中,回归系数是未知的,可以在已有样本的根底上,使用最小二乘法对回归系数进展估计,得到如下的样本回归函数:iik k i i i e x x x y +++++=ββββˆˆˆˆ22110 回归模型中的参数估计出来之后,还必须对其进展检验。
如果通过检验发现模型有缺陷,如此必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量和解释变量与其函数形式,或者对数据进展加工整理之后再次估计参数。
回归模型的检验包括一级检验和二级检验。
一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟和优度评价和显著性检验;二级检验又称为经济计量学检验,它是对线性回归模型的假定条件能否得到满足进展检验,具体包括序列相关检验、异方差检验等。
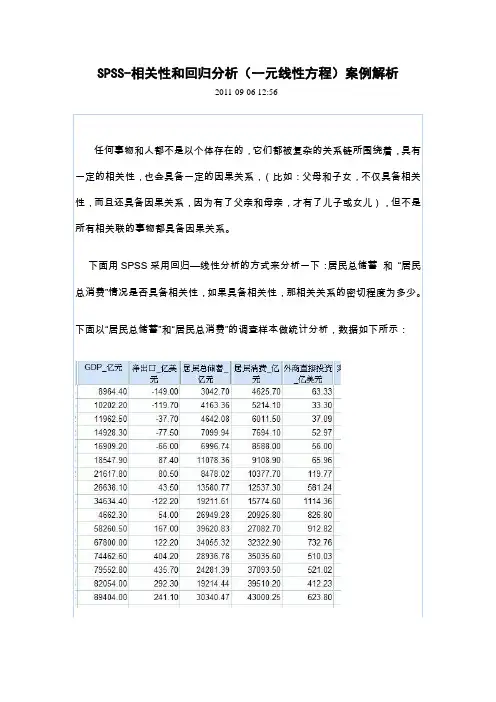
用下面的数据做相关分析和一元线性回归分析:选用普通高等学校毕业生数和高等学校发表科技论文数量做相关分析和一元线性回归分析。
一、相关分析1.作散点图普通高等学校毕业生数和高等学校发表科技论文数量的相关图从散点图可以看出:普通高等学校毕业生数和高等学校发表科技论文数量的相关性很大。
2.求普通高等学校毕业生数和高等学校发表科技论文数量的相关系数把要求的两个相关变量移至变量中,因为都是定距数据,选择相关系数中的Pearson,点击确定,可以得到下面的结果:关;相关系数检验对应的概率P值=0.000,小于显著性水平0.05,应拒绝原假设(两变量之间不具有相关性),即毕业生人数好发表科技论文数之间的相关性显著。
3.求两变量之间的相关性选择相关系数中的全部,点击确定:Correlations(万人) (篇)Kendall's tau_b (万人)CorrelationCoefficient1.000 1.000** Sig. (2-tailed) . .N 14 14 (篇) CorrelationCoefficient1.000**1.000Sig. (2-tailed) . .N 14 14Spearma n's rho (万人)CorrelationCoefficient1.000 1.000**Kendall相关系数=1.000,呈正相关;无相关系数检验对应的概率P 值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显著。
两相关变量(毕业生数和发表论文数)的Spearman 相关系数=1.000,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显著。
4.普通高等学校毕业生数和高等学校发表科技论文数量的相关系数将所求变量移至变量,将控制变量移至控制中,选中显示实际显著性水平,点击确定:Correlations相关系数=0.998,呈正相关;对应的偏相关系数双侧检验p 值0,小于显著性水平0.05,应拒绝原假设(两变量之间不具有相关性),即普通高校毕业生数与发表论文数之间相关性显著。
SPSS相关分析实验报告篇一:spss对数据进行相关性分析实验报告实验一一.实验目的掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。
二.实验原理相关性分析是考察两个变量之间线性关系的一种统计分析方法。
更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。
P值是针对原假设H0:假设两变量无线性相关而言的。
一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。
越小,则相关程度越低。
而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。
三、实验内容掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。
(1)检验人均食品支出与粮价和人均收入之间的相关关系。
a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。
C.在对话窗口中点击ok,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间显著相关。
人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间也显著相关。
(2)研究人均食品支出与人均收入之间的偏相关关系。
读入数据后:A.点击系统弹出一个对话窗口。
B.点击OK,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.000<0.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.8665<0.921,说明它们之间的显著性关系稍有减弱。
用下面的数据做相关分析和一元线性回归分析:
选用普通高等学校毕业生数和高等学校发表科技论文数量做相关分析和一元线性回归分析。
一、相关分析
1.作散点图
普通高等学校毕业生数和高等学校发表科技论文数量的相关图
从散点图可以看出:普通高等学校毕业生数和高等学校发表科技论文数量的相关性很大。
2.求普通高等学校毕业生数和高等学校发表科技论文数量的相关系
数
把要求的两个相关变量移至变量中,因为都是定距数据,选择相关系数中的Pearson,点击确定,可以得到下面的结果:
Correlations
普通高等学校毕业生数(万人)高等学校发表科技论文数量(篇)
普通高等学校毕业生数(万人)Pearson Correlation1.998**
Sig. (2-tailed).000
N1414
高等学校发表科技论文数量(篇)Pearson Correlation.998**1 Sig. (2-tailed).000
N1414
**. Correlation is significant at the 0.01 level (2-tailed).
两相关变量的Pearson相关系数=0.0998,表示呈高度正相关;相关系数检验对应的概率P值=0.000,小于显著性水平0.05,应拒绝原假设(两变量之间不具有相关性),即毕业生人数好发表科技论文数之间的相关性显著。
3.求两变量之间的相关性
选择相关系数中的全部,点击确定:
Correlations
(万人)(篇)
Kendall's tau_b(万人)Correlation Coefficient 1.000 1.000**
Sig. (2-tailed)..
N1414
(篇)Correlation Coefficient 1.000** 1.000
Sig. (2-tailed)..
N1414
Spearman's rho(万人)Correlation Coefficient 1.000 1.000**
Sig. (2-tailed)..
N1414
(篇)Correlation Coefficient 1.000** 1.000
Sig. (2-tailed)..
N1414
**. Correlation is significant at the 0.01 level (2-tailed).
注解:两相关变量(毕业生数和发表论文数)的Kendall相关系数=1.000,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显著。
两相关变量(毕业生数和发表论文数)的Spearman相关系数=1.000,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显著。
4.普通高等学校毕业生数和高等学校发表科技论文数量的相关系数
将所求变量移至变量,将控制变量移至控制中,选中显示实际显著性水平,点击确定:
Correlations
普通高等学校毕业生数(万人)高等学校发表科技论文数量(篇)
注解: 两相关变量(普通高校毕业生数和发表论文数)的偏相关系数=0.998,呈正相关;对应的偏相关系数双侧检验p值0,小于显著性水平0.05,应拒绝原假设(两变量之间不具有相关性),即普通高校毕业生数与发表论文数之间相关性显著。
二、一元线性回归
从前面的相关分析可以看出普通高等学校毕业生数和高等学校发表科技论文数量呈高度正相关关系,所以,下面对这两个变量做一元线性回归分析。
1.建立回归方程
Variables Entered/Removed b
Model Variables
Entered
Variables
Removed Method
1(篇)a.Enter
a. All requested variables entered.
b. Dependent Variable: (万人)
此图显示的是回归分析方法引入变量的方式。
Model Summary
Model R R Square Adjusted R
Square
Std. Error of the
Estimate
1.998a.996.99611.707
a. Predictors: (Constant), (篇)
此图是回归方程的拟合优度检验。
注解:上图是回归方程的拟合优度检验。
第二列:两变量(被解释变量和解释变量)的相关系数R=0.998.
第三列:被解释变量(毕业人数)和解释变量(发表科技论文数)的判定系数=0.996是一元线性回归方程拟合优度检验的统计量;判定系数越接近1,说明回归方程对样本数据的拟合优度越高,被解释变量可以被模型解释的部分越
多。
第四列:被解释变量(毕业人数)和解释变量(发表科技论文数)的调整判定系数=0.996。
这主要适用于多个解释变量的时候。
第五列:回归方程的估计标准误差=11.707.
ANOVA b
Model Sum of Squares df Mean Square F Sig.
1Regression448318.6641448318.6643271.335.000a Residual1644.53512137.045
Total449963.19913
a. Predictors: (Constant), (篇)
b. Dependent Variable: (万人)
第二列:被解释变量(毕业人数)的总离差平方和=449963.199,被分解为两部分:回归平方和=448318.664;剩余平方和=1644.535.
F检验统计量的值=3271.335,对应概率的P值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验的原假设(回归系数与0不存在显著性差异),结论:回归系数不为0,被解释变量(毕业人数)与解释变量(发表科技论文数)的线
Coefficients a
Model Unstandardized Coefficients
Standardized
Coefficients
t Sig.
B Std. Error Beta
1(Constant)-316.25914.029-22.543.000 (篇).001.000.99857.196.000 a. Dependent Variable: (万人)
注解:回归方程的回归系数和常数项的估计值,以及回归系数的显著性检验。
第二列:常数项估计值=-316.259;回归系数估计值=0.001.
第三列:回归系数的标准误差=0.000
第四列:标准化回归系数=0.998.
第五、六列:回归系数T检验的t统计量值=57.196,对应的概率P 值=0.000,小于显著性水平0.05,拒绝原假设(回归系数与0不存在显著性差异),结论:回归系数不为0,被解释变量(毕业人数)与解释变量(发表科技论文数)的线性关系是显著的。
于是,回归方程为:
=-316.259+0.001x
2.回归方程的进一步分析
(1)在统计量中选中误差条图的表征,水平百分之95.
点击继续,然后点击确定,输出每个非标准化回归系数的95%置信区间:
选中统计量中的描述性,点击继续,然后确定,输出变量的均值、标准差相关系数矩阵和单侧检验概率值:
Descriptive Statistics
Mean Std. Deviation N
(万人)465.92186.04414
(篇)932780.57221459.01914
Correlations
(万人)(篇)
Pearson Correlation(万人) 1.000.998
(篇).998 1.000
Sig. (1-tailed)(万人)..000
(篇).000.
N(万人)1414
(篇)1414
(2)残差分析
选中统计量中的个案诊断,所有个案,点击继续,然后确定:
Residuals Statistics a
Minimum Maximum Mean Std. Deviation N Predicted Value137.72707.16465.92185.70414 Std. Predicted Value-1.767 1.299.000 1.00014
3.153 6.536
4.320.99514 Standard Error of Predicted
Value
Adjusted Predicted Value139.53713.78466.40185.62014 Residual-26.27619.112.00011.24714 Std. Residual-2.245 1.633.000.96114 Stud. Residual-2.511 1.696-.018 1.04814 Deleted Residual-32.89620.618-.47313.40314 Stud. Deleted Residual-3.491 1.862-.073 1.25914 Mahal. Distance.015 3.123.929.89014 Cook's Distance.000.795.100.20514 Centered Leverage Value.001.240.071.06814 a. Dependent Variable: (万人)
从上表可以看出,第8例的残差和标准化残差最大。