正态分布、区间估计
- 格式:ppt
- 大小:255.00 KB
- 文档页数:29



统计学中的区间估计方法及其应用统计学是一门研究数据收集、分析和解释的学科。
在统计学中,区间估计是一种常用的方法,用于估计总体参数的范围。
本文将介绍区间估计的基本概念和常见方法,并探讨其在实际应用中的意义。
一、区间估计的基本概念区间估计是通过样本数据对总体参数进行估计,并给出一个范围,使得该范围内有一定的置信水平包含真实的总体参数值。
常见的区间估计方法有点估计法、区间估计法和极大似然估计法等。
点估计法是通过样本数据计算得到一个点估计值,作为总体参数的估计值。
例如,通过样本均值估计总体均值,通过样本方差估计总体方差等。
区间估计法是在点估计的基础上,给出一个置信区间,该区间包含了总体参数的真实值。
置信区间的计算依赖于样本数据的分布和样本容量等因素。
极大似然估计法是通过最大化似然函数,寻找最有可能生成观测数据的参数值。
该方法常用于对总体分布的参数进行估计。
二、常见的区间估计方法1. 正态分布的区间估计在正态分布的区间估计中,常用的方法有Z检验和T检验。
Z检验适用于大样本,T检验适用于小样本。
这两种方法都是基于正态分布的性质,通过计算样本均值与总体均值之间的差异,得出置信区间。
2. 二项分布的区间估计对于二项分布的区间估计,常用的方法是Wald区间估计和Wilson区间估计。
Wald区间估计是基于正态近似的方法,适用于大样本。
Wilson区间估计是一种修正的方法,适用于小样本。
3. 指数分布的区间估计对于指数分布的区间估计,常用的方法是对数似然比法和置信上限法。
对数似然比法是通过最大化似然函数,得到参数的估计值,并计算置信区间。
置信上限法是寻找参数的最大值,使得观测值在该上限下的概率达到一定的置信水平。
三、区间估计的应用意义区间估计在实际应用中具有重要的意义。
首先,区间估计提供了对总体参数范围的估计,使得我们能够更准确地了解总体的特征。
其次,区间估计能够帮助我们进行决策和预测。
例如,在市场调研中,我们可以通过区间估计来估计产品的需求量,从而制定合理的生产计划。

区间估计的习题和答案区间估计的习题和答案区间估计是统计学中一种常用的方法,用于估计总体参数的范围。
通过样本数据,我们可以根据一定的置信水平构建一个区间,该区间包含了总体参数的真实值的概率。
本文将介绍一些区间估计的习题,并提供相应的答案。
1. 问题:某电商平台声称其平均每日订单数超过10000,现从该平台随机抽取了100个订单进行统计,得到平均每日订单数为9800,标准差为2000。
请构建一个95%的置信区间。
解答:根据中心极限定理,样本均值服从正态分布,当样本容量大于30时,可以使用正态分布进行区间估计。
根据题目信息,样本容量为100,标准差为2000,所以我们可以使用正态分布进行估计。
置信水平为95%,对应的α为0.05。
查找标准正态分布表得到α/2对应的临界值为1.96。
计算得到置信区间为:9800 ± 1.96 * (2000 / √100) = 9800 ± 392因此,95%的置信区间为[9408, 10192]。
2. 问题:某服装品牌声称其销售额的年增长率不低于10%。
现从该品牌的10个门店中随机抽取了销售额的年增长率数据,得到样本均值为8%,样本标准差为2%。
请构建一个90%的置信区间。
解答:根据题目信息,样本容量为10,样本标准差为2%,样本均值为8%。
由于样本容量较小,无法使用正态分布进行区间估计,需要使用t分布。
置信水平为90%,对应的α为0.1。
查找t分布表得到自由度为9时,α/2对应的临界值为1.83。
计算得到置信区间为:8% ± 1.83 * (2% / √10) = 8% ± 1.16因此,90%的置信区间为[6.84%, 9.16%]。
3. 问题:某医院声称其糖尿病患者的平均住院天数不超过7天。
现从该医院随机选取了50名糖尿病患者,得到平均住院天数为8天,样本标准差为2天。
请构建一个99%的置信区间。
解答:根据题目信息,样本容量为50,样本标准差为2天,样本均值为8天。


总体参数的区间估计公式在进行区间估计时,我们首先需要收集到一个样本,并根据样本对总体参数进行估计。
然后根据样本的统计量,结合分布的性质和抽样方法,建立置信区间。
设总体参数为θ,我们希望得到它的置信水平为1-α的置信区间。
置信水平表示我们对总体参数的估计的可信程度,一般常用的置信水平有90%、95%和99%等。
参数估计的方法有很多,具体的方法选择取决于总体参数的性质、样本的大小以及其他假设条件。
常见的参数估计方法有:1.总体均值的区间估计:假设总体呈正态分布,样本大小为n,则总体均值的区间估计公式为:[样本均值-Z值(α/2)*总体标准差/√(n),样本均值+Z值(α/2)*总体标准差/√(n)]其中Z值(α/2)为标准正态分布的分位数,可以从标准正态分布表中查得。
2.总体比例的区间估计:假设总体为二项分布,样本大小为n,成功的次数为x,则总体比例的区间估计公式为:[样本比例-Z值(α/2)*√(样本比例*(1-样本比例)/n),样本比例+Z值(α/2)*√(样本比例*(1-样本比例)/n)]其中Z值(α/2)为标准正态分布的分位数,可以从标准正态分布表中查得。
3.总体方差的区间估计:假设总体呈正态分布,样本大小为n,则总体方差的区间估计公式为:[(n-1)*样本方差/卡方分布(α/2),(n-1)*样本方差/卡方分布(1-α/2])]其中卡方分布是用于描述自由度为n-1的卡方随机变量的概率分布,可以从卡方分布表中查得。
以上是常见的总体参数区间估计公式,这些公式是根据统计学理论推导而来的,适用于不同情况下的参数估计。
在实际应用中,我们根据具体问题和假设条件选择适当的参数估计方法,计算置信水平的区间估计,从而对总体参数进行估计和推断。

区间估计的发展历程区间估计是统计学中的一个重要方法,用于估计总体参数的取值范围。
其发展历程可以追溯到20世纪初,随着统计学的发展,区间估计方法也不断演变和完善。
20世纪初,统计学的先驱者在面对大量数据时,常常只能通过样本均值或样本比例来估计总体均值或总体比例,并且无法对估计结果的可信度进行评估。
在这种情况下,区间估计的概念开始浮现。
最早的区间估计方法是基于正态分布的,如对总体均值的区间估计常使用的Z分布。
到了20世纪30年代,统计学家们通过研究样本统计量的抽样分布发现,当样本容量较大时,样本均值的抽样分布近似服从正态分布。
于是,他们开始使用标准正态分布进行区间估计,该方法被称为大样本法。
随后,统计学家们发现在很多实际情况下,样本容量并不总是很大,并且样本均值的抽样分布并不一定服从正态分布。
为解决这个问题,20世纪40年代,学者们提出了小样本法。
这种方法利用t分布进行区间估计,不仅适用于小样本,而且当样本容量大时,也能产生与Z分布相似的结果。
随着计算机的发展和计算方法的改进,20世纪50年代出现了蒙特卡洛方法,从而使区间估计更加准确和高效。
蒙特卡洛方法是通过模拟抽样分布来进行区间估计,其原理类似于抛硬币的过程。
通过大量的模拟实验,可以得到参数的估计值以及其取值范围。
20世纪70年代,贝叶斯统计学的兴起使得区间估计的思想得到了进一步的发展。
贝叶斯统计学使用贝叶斯公式来计算参数的后验概率,并通过后验概率的分布进行区间估计。
相比于传统的频率学派,贝叶斯统计学更加灵活,可以直接对参数的不确定性进行建模。
此外,以非参数统计学为代表的现代统计学方法也为区间估计提供了新的思路。
非参数统计学不需要对总体的分布进行假设,可以在较小的样本容量下进行区间估计。
随着统计学的不断发展和应用领域的扩大,区间估计的方法也在不断完善和丰富。
目前已经出现了各种各样的区间估计方法,如bootstrap方法、Jackknife方法等。

常用的参数估计方法参数估计是统计分析中的一个重要概念,指的是通过已有的样本数据来估计未知的参数。
常见的参数估计方法包括点估计和区间估计两种。
下面将分别介绍这两种方法及其常见的应用。
一、点估计点估计是通过样本数据来估计总体参数的方法之一,通常用样本的统计量(如样本均值、样本方差等)作为总体参数的估计值。
点估计的特点是简单直观,易于计算。
但是点估计的精度不高,误差较大,因此一般用在总体分布已知的情况下,用于快速估计总体参数。
常见的点估计方法包括最大似然估计、矩估计和贝叶斯估计。
1.最大似然估计最大似然估计是目前最常用的点估计方法之一。
其基本思想是在已知的样本信息下,寻找一个未知参数的最大似然估计值,使得这个样本出现的概率最大。
最大似然估计的优点是可以利用样本数据来估计参数,估计量具有一定的无偏性和效率,并且通常具有渐进正常性。
常见的应用包括二项分布、正态分布、泊松分布等。
2.矩估计矩估计是另一种常用的点估计方法,其基本思想是利用样本矩(如一阶矩、二阶矩等)与相应的总体矩之间的关系,来进行未知参数的估计。
矩估计的优点是计算简单,适用范围广泛,并且具有一定的无偏性。
常见的应用包括指数分布、伽马分布、weibull分布等。
3.贝叶斯估计贝叶斯估计是另一种常用的点估计方法,其基本思想是先对未知参数进行一个先验分布假设,然后基于样本数据对先验分布进行修正,得到一个后验分布,再用后验分布来作为估计值。
贝叶斯估计的优点是能够有效处理小样本和先验信息问题,并且可以将先验偏好考虑进去。
常见的应用包括正态分布、伽马分布等。
二、区间估计区间估计是通过样本数据来构造总体参数的置信区间,从而给出总体参数的不确定性范围。
区间估计的特点是精度高,抗扰动性强,但是计算复杂度高,需要计算和估计的样本量都很大。
常见的区间估计方法包括正态分布区间估计、t分布区间估计、置信区间估计等。
1.正态分布区间估计正态分布区间估计是一种用于总体均值和总体方差的区间估计方法,其基本思想是在已知样本数据的均值和标准差的情况下,根据正态分布的性质得到总体均值和总体方差的置信区间。

正态分布是概率论和统计学中最重要的概率分布之一,它在自然界和社会科学中都有广泛的应用。
在很多实际问题中,我们需要对正态分布的均值进行估计,从而对总体均值进行推断。
本文将围绕着正态分布均值的区间估计展开讨论。
1. 正态分布的概念正态分布又称为高斯分布,是以数学家高斯命名的一种连续概率分布。
正态分布的概率密度函数呈钟形曲线,中间高、两边低,左右对称,因此也被称为钟形曲线。
正态分布的特点在于其均值和标准差能完全描述其分布,因此在统计学中有着重要的地位。
2. 区间估计的重要性区间估计是统计推断的重要方法之一,它可以帮助我们对总体参数进行推断。
在现实问题中,很少有机会能够获得总体所有数据,只能通过样本来做出总体的推断。
而区间估计可以帮助我们根据样本数据估计出参数的范围,从而更加准确地进行推断和决策。
3. 正态分布均值的区间估计方法对于正态分布的均值来说,我们可以使用样本均值和标准差来对总体均值进行估计。
常用的区间估计方法有置信区间法和贝叶斯区间估计法。
3.1 置信区间法在置信区间法中,我们根据样本数据来计算均值的置信区间,通常是指在统计学上确定的一个包含总体参数的区间。
置信区间的确定需要指定置信水平,通常使用95和99置信水平。
置信区间的计算可参考t分布或者标准正态分布的分位数。
3.2 贝叶斯区间估计法贝叶斯区间估计法是基于贝叶斯统计学的方法,它将参数看作随机变量,并给出参数的概率分布。
通过贝叶斯定理和样本数据,可以得到参数的后验概率分布,进而得到参数的区间估计。
4. 区间估计的应用正态分布均值的区间估计方法在实际问题中有着广泛的应用。
比如在质量控制中,我们可以通过对正态分布均值的区间估计来判断产品的质量是否符合标准;在市场调查中,我们可以通过对正态分布均值的区间估计来对市场需求进行预测等等。
5. 区间估计的注意事项在进行正态分布均值的区间估计时,需要注意一些细节问题。
首先是样本容量的选择,样本容量的大小对区间估计的精度有着重要的影响;其次是置信水平的选择,不同的置信水平会得到不同的置信区间;最后是对总体分布是否服从正态分布的检验,如果总体分布不服从正态分布,需要进行修正或者使用其他方法来进行估计。
正态分布在医学统计学区间估计的应用
正态分布在医学统计学区间估计中有着重要的作用,下面来看看它具体在医学统计学中的应用:
一、正态分布在病人总死亡评估中的应用
1、采用正态分布加以拟合,以此为基础进行参数的估计,来评估患病的总死亡率;
2、正态分布用于估计患者每一种病的能力,以及每个患者的健康状况,对有效的病人总死亡率的有效性的评估;
3、采用正态分布加以建模,以评估人群特定疾病的潜在病死率。
二、正态分布在病人康复情况评估中的应用
1、用正态分布拟合以此来评价患者在疾病入院状态以及出院状态,以便记录每一个患者的康复情况;
2、用正态分布拟合对比康复情况和病人体重、血压等参数,以便来评估疾病康复速度及相关变量;
3、采用正态分布估计病人疾病康复时间,以及评估病人康复率。
三、正态分布在医療安全性评估中的应用
1、用正态分布运算识别医疗机构中的安全缺陷及其准确性;
2、采用正态分布估计对医疗安全性的危害概率;
3、用正态分布拟合以此来评估医疗安全事件的频率和比例,以此来发现有关的风险因素。
四、正态分布在药物毒性监测中的应用
1、用正态分布评估药物毒副作用出现的概率,评估药物在不同患者身上的作用效果;
2、运用正态分布来收集药物实验结果,以检测出不同的药物的毒性;
3、采用正态分布来评估药物的安全程度及其有效性。
总而言之,正态分布在医学统计学区间估计中有着重要的应用,可以在病人总死亡评估、病人康复情况评估、医療安全性评估以及药物毒性监测中使用,在这些医学领域中都能发挥作用。
正态分布N (μ,σ)参数区间估计允许μ为任意的实数,σ为任意的正实数。
基于Wolfram Mathematica ,给出了正态分布N (μ,σ)抽样定理,从而得到参数μ,σ2,σ的区间估计。
在σ已知和未知情形下,通过均值分布、中位值分布、卡方分布三种方法估计总体均值μ,区间长度均值分布最短,卡方分布次之,中位值分布最长,但当样本量n 较大时,区间长度趋于接近。
在μ已知和未知情形下,通过卡方分布可以估计总体方差的置信区间,通过卡分布、卡方分布可以估计总体标准差的置信区间。
最后给出不同情形下不同方法的MMA 程序及运行结果。
◼抽样分布定理引理1:X Ν(μ,σ)⇔X -μσΝ 0,1 .转换分布TransformedDistributionX -μσ,X 正态分布NormalDistribution [μ,σ]NormalDistribution [0,1]转换分布TransformedDistribution [μ+X σ,X 正态分布NormalDistribution [],假设Assumptions →σ>0]NormalDistribution [μ,σ]引理2:X χ(ν)⇔X 2 χ2(ν).转换分布TransformedDistribution X 2,X 卡分布ChiDistribution [ν]ChiSquareDistribution [ν]转换分布TransformedDistribution X ,X 卡方分布ChiSquareDistribution [ν]ChiDistribution [ν]引理3:X Ν 0,1 ,Y χ2(n )⇒Xt (n ).=转换分布TransformedDistributionX,{X 正态分布NormalDistribution [],Y 卡方分布ChiSquareDistribution [n ]} ;概率密度函数PDF [ ,x ]==⋯PDF [学生t 分布StudentTDistribution [n ],x ]//幂展开PowerExpand //完全简化FullSimplify [#,n >0&&x ≠0]&True定理1:X i Ν(μ,σ)⇒X -Νμ,σn⇔X --μσnΝ 0,1 .CharacteristicFunction NormalDistribution [μ,σ],t nn;特征函数CharacteristicFunction 正态分布NormalDistribution μ,σn,t ;%⩵%%//完全简化FullSimplify [#,n >0&&n ∈整数域Integers ]&True定理2:X i Ν(μ,σ)⇒ i =1nX i -μσ2=∑i =1n (X i -μ)2σ2χ2(n )⇔σχ(n ).转换分布TransformedDistributionX [i ]-μσ,X [i ] 正态分布NormalDistribution [μ,σ]NormalDistribution [0,1]n =7;=转换分布TransformedDistribution i =1nY [i ]2,数组Array [Y,n ] 联合分布ProductDistribution [{正态分布NormalDistribution [],n }]ChiSquareDistribution [7]定理3:X i Ν(μ,σ)⇒(n -1)S 2σ2χ2 n -1⇔σχ n -1 .令Y i =X i -μσ,则(n -1)S 2σ2=i =1n2=i =1n-= i =1nY i -Y 2= i =1nY i 2-2Y Y i +Y 2= i =1nY i 2-2Y i =1nY i +n Y 2= i =1nY i 2-n Y 2χ2n -1 ⇒σχ n -1 .2 正态分布\\正态分布统计分析\\正态分布参数区间估计.nbn =n0=35;=转换分布TransformedDistribution i =1nY [i ]2-1ni =1nY [i ]2,数组Array [Y,n ] 联合分布ProductDistribution [{正态分布NormalDistribution [],n }] ;Block {n =n0},显示Show 直方图Histogram 伪随机变数RandomVariate ,2×106 ,500,"概率密度函数PDF" ,绘图Plot [⋯PDF [卡方分布ChiSquareDistribution [n -1],x ],{x,5,65},绘图样式PlotStyle →粗Thick ]定理4:X i Ν(μ,σ)⇒X --μSnt n -1 .根据定理1,得X iΝ(μ,σ)⇒X --μσnΝ 0,1 ,根据定理3,得(n -1)S 2σ2χ2 n -1 ,根据引理3,X --μσn=X --μSnt n -1 .定理5:F Xn +12=正则化的不完全贝塔函数BetaRegularized12补余误差函数Erfc-x +μ2σ ,1+n2,1+n 2,n =2k +1.次序分布OrderDistribution {正态分布NormalDistribution [μ,σ],n },n +12;累积分布函数CDF [%,x ]//完全简化FullSimplifyBetaRegularized 12Erfc ,1+n 2,1+n 2推论:μ=x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized q,1+n 2,1+n 2.In[2]:=解方程Solve 正则化的不完全贝塔函数BetaRegularized12补余误差函数Erfc-x +μ2σ ,1+n 2,1+n 2⩵q,μOut[2]=μ→x +2σInverseErfc 2InverseBetaRegularized q,1+n 2,1+n 2定理6:-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σχ2 2n .正态分布\\正态分布统计分析\\正态分布参数区间估计.nb3In[5]:=转换分布TransformedDistribution -2对数Log12补余误差函数Erfc-X +μ2σ,X 正态分布NormalDistribution [μ,σ] ;概率密度函数PDF [%,x ]⩵⋯PDF [卡方分布ChiSquareDistribution [2],x ]//完全简化FullSimplify [#,x >0]&Out[6]=True**参数区间估计**In[7]:=需要Needs ["HypothesisTesting`"]μ0=20;σ0=3;X =伪随机变数RandomVariate [正态分布NormalDistribution [μ0,σ0],10001];n =长度Length [X ];S =标准偏差StandardDeviation [X ];α=0.01;"参数的极大似然估计:"清除Clear [μ,σ]{μ1,σ1}={μ,σ}/.求分布参数FindDistributionParameters [X,正态分布NormalDistribution [μ,σ]]"一、总体均值μ的区间估计""(一)均值分布U =X --μσnN(0,1)——σ已知"σ=σ0;Sw =σn ;m =平均值Mean [X ];"1.计算法"Q =分位数Quantile 正态分布NormalDistribution [0,1],1-α 2 ;{m -Sw Q,m +Sw Q }"2.MeanCI"MeanCI X,KnownVariance →σ2,置信级别ConfidenceLevel →1-α"3.NormalCI"NormalCI [m,Sw ,置信级别ConfidenceLevel →1-α]"区间长度:"L =2Sw Q"相对区间长度:"r =L /m "(二)均值分布T =X -μSnt (n -1)——σ未知""1.计算法"Sw =S n ;m =平均值Mean [X ];Q =分位数Quantile 学生t 分布StudentTDistribution [n -1],1-α 2 ;{m -Sw Q,m +Sw Q }4 正态分布\\正态分布统计分析\\正态分布参数区间估计.nb"2.MeanCI"MeanCI [X,KnownVariance →无None,置信级别ConfidenceLevel →1-α]"3.StudentTCI"StudentTCI [m ,Sw ,n -2,置信级别ConfidenceLevel →1-α]"区间长度:"L =2Sw Q"相对区间长度:"r =L /m"(三)均值近似分布U =X --μσn~N[0,1]——σ未知""1.计算法"σ=σ1;Sw =σn ;m =平均值Mean [X ];Q =分位数Quantile 正态分布NormalDistribution [0,1],1-α 2 ;{m -Sw Q,m +Sw Q }"2.MeanCI"MeanCI X,KnownVariance →σ12,置信级别ConfidenceLevel →1-α"3.NormalCI"NormalCI [m,Sw ,置信级别ConfidenceLevel →1-α]"区间长度:"L =2Sw Q"相对区间长度:"r =L /m"(四)中位值分布F Xn +12=正则化的不完全贝⋯BetaRegularized [12补余误差函数Erfc [-x +μ2σ],1+n 2,1+n2],n =2k +1——σ已知""1.等尾区间:"σ=σ0;x =中位数Median [X ];μL =x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized 1-α 2,1+n 2,1+n 2;μU =x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized α 2,1+n 2,1+n 2;{μL,μU }"等尾区间长度:"L =μU -μL"相对区间长度:"r =2L μU +μL "(五)中位值分布F Xn +12=正则化的不完全贝⋯BetaRegularized [12补余误差函数Erfc [-x +μ2σ ],1+n 2,1+n2],n =2k +1——σ未知""1.等尾区间:"σ=σ1;x =中位数Median [X ];正态分布\\正态分布统计分析\\正态分布参数区间估计.nb5中位数μL =x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized 1-α 2,1+n 2,1+n 2;μU =x +2σ反互补误差函数InverseErfc 2正规化不完全贝塔函数的逆InverseBetaRegularized α 2,1+n 2,1+n 2;{μL,μU }"等尾区间长度:"L =μU -μL"相对区间长度:"r =2L μU +μL"(六)卡方分布-2 i =1n对数Log [12补余误差函数Erfc [-X i +μ2σ]] χ2(2n )——σ已知"清除Clear [μ]σ=σ0;x =-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σ;F =卡方分布ChiSquareDistribution [2n ];μL =μ/.求根FindRoot 累积分布函数CDF [F,x ]==α2,{μ,μ1} ;μU =μ/.求根FindRoot 累积分布函数CDF [F,x ]⩵1-α2,{μ,μ1} ;{μL,μU }"等尾区间长度:"L =μU -μL"相对区间长度:"r =2L μU +μL"(七)卡方分布-2 i =1n对数Log [12补余误差函数Erfc [-X i +μ2σ ]]~χ2(2n )——σ未知"清除Clear [μ]σ=σ0;x =-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σ;F =卡方分布ChiSquareDistribution [2n ];μL =μ/.求根FindRoot 累积分布函数CDF [F,x ]==α2,{μ,μ1} ;μU =μ/.求根FindRoot 累积分布函数CDF [F,x ]⩵1-α2,{μ,μ1} ;{μL,μU }"等尾区间长度:"L =μU -μL"相对区间长度:"6 正态分布\\正态分布统计分析\\正态分布参数区间估计.nbr =2L μU +μL"二、总体方差σ2的区间估计""(一)卡方分布χ2=∑i =1n (X i -μ)2σ2χ2(n )——μ已知"μ=μ0;T =n 平均值Mean (X -μ)2 ;F =卡方分布ChiSquareDistribution [n ];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;VL =T QL;VU =T QU;{VL,VU }"等尾区间长度:"L =VU -VL"相对区间长度:"r =2L VL +VU "(二)卡方分布χ2=(n -1)S 2σ2χ2(n -1)——μ未知"T = n -1 S 2;F =卡方分布ChiSquareDistribution [n -1];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;VL =T QL;VU =T QU;{VL,VU }"等尾区间长度:"L =VU -VL"相对区间长度:"r =2L VL +VU "(三)卡方分布χ2=∑i =1n (X i -μ )2σ2~χ2(n )——μ未知"μ=μ1;T =n 平均值Mean (X -μ)2 ;F =卡方分布ChiSquareDistribution [n ];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;VL =T QL;VU =T QU;{VL,VU }"等尾区间长度:"L =VU -VL"相对区间长度:"r =2L VL +VU"三、总体标准差σ的区间估计""(一)卡分布χ(n )——μ已知"μ=μ0;T =n Mean (X -μ)2 ;F =卡分布ChiDistribution [n ];"1.等尾区间:"正态分布\\正态分布统计分析\\正态分布参数区间估计.nb7QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;σL =T QL;σU =T QU;{σL,σU }"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σU "(二)卡分布χ(n -1)——μ未知"T =n -1S;F =卡分布ChiDistribution [n -1];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;σL =T QL;σU =T QU;{σL,σU }"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σU "(三)卡分布χχ(n )——μ未知"μ=μ1;T =n Mean (X -μ)2 ;F =卡分布ChiDistribution [n ];"1.等尾区间:"QL =分位数Quantile F,1-α 2 ;QU =分位数Quantile F,α 2 ;σL =T QL;σU =T QU;{σL,σU }"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σU "(四)卡方分布-2 i =1n对数Log [12补余误差函数Erfc [-X i +μ2σ]] χ2(2n )——μ已知"清除Clear [σ]μ=μ0;x =-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σ;F =卡方分布ChiSquareDistribution [2n ];σL =σ/.求根FindRoot 累积分布函数CDF [F,x ]⩵1-α2,{σ,σ1} ;σU =σ/.求根FindRoot 累积分布函数CDF [F,x ]⩵α2,{σ,σ1} ;{σL,σU }8 正态分布\\正态分布统计分析\\正态分布参数区间估计.nb"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σU"(五)卡方分布-2 i =1n对数Log [12补余误差函数Erfc [-X i +μ2σ]] χ2(2n )——μ未知"清除Clear [σ]μ=μ1;x =-2 i =1n对数Log12补余误差函数Erfc-X i +μ2σ;F =卡方分布ChiSquareDistribution [2n ];σL =σ/.求根FindRoot 累积分布函数CDF [F,x ]⩵1-α2,{σ,σ1} ;σU =σ/.求根FindRoot 累积分布函数CDF [F,x ]⩵α2,{σ,σ1} ;{σL,σU }"等尾区间长度:"L =σU -σL"相对区间长度:"r =2L σL +σUOut[11]=参数的极大似然估计:Out[13]={19.9803,3.00134}Out[14]=一、总体均值μ的区间估计Out[15]=(一)均值分布U =X --μσnN(0,1)——σ已知Out[17]=1.计算法Out[19]={19.9031,20.0576}Out[20]=2.MeanCIOut[21]={19.9031,20.0576}Out[22]=3.NormalCIOut[23]={19.9031,20.0576}Out[24]=区间长度:Out[25]=0.154542Out[26]=相对区间长度:Out[27]=0.00773471Out[28]=(二)均值分布T =X -μSn t (n -1)——σ未知正态分布\\正态分布统计分析\\正态分布参数区间估计.nb9Out[29]= 1.计算法Out[32]={19.903,20.0577} Out[33]= 2.MeanCIOut[34]={19.903,20.0577} Out[35]= 3.StudentTCIOut[36]={19.903,20.0577} Out[37]=区间长度:Out[38]=0.154648Out[39]=相对区间长度:Out[40]=0.00774003Out[41]=(三)均值近似分布U=X--μσ n~N[0,1]——σ未知Out[42]= 1.计算法Out[45]={19.903,20.0576} Out[46]= 2.MeanCIOut[47]={19.903,20.0576} Out[48]= 3.NormalCIOut[49]={19.903,20.0576} Out[50]=区间长度:Out[51]=0.154611Out[52]=相对区间长度:Out[53]=0.00773817Out[54]=(四)中位值分布F X n+12=BetaRegularized[12Erfc,1+n2,1+n2],n=2k+1——σ已知Out[55]= 1.等尾区间:Out[59]={19.8529,20.0466} Out[60]=等尾区间长度:Out[61]=0.193686Out[62]=相对区间长度:Out[63]=0.00970872Out[64]=(五)中位值分布F X n+12=BetaRegularized[12Erfc,1+n2,1+n2],n=2k+1——σ未知Out[65]= 1.等尾区间:Out[69]={19.8529,20.0466}Out[70]=等尾区间长度:10正态分布\\正态分布统计分析\\正态分布参数区间估计.nbOut[71]=0.193773Out[72]=相对区间长度:Out[73]=0.00971306Out[74]=(六)卡方分布-2 i =1n Log [12Erfcχ2(2n )——σ已知Out[78]={19.9015,20.0722}Out[79]=等尾区间长度:Out[80]=0.170753Out[81]=相对区间长度:Out[82]=0.00854324Out[83]=(七)卡方分布-2 i =1n Log [12Erfcχ2(2n )——σ未知Out[87]={19.9015,20.0722}Out[88]=等尾区间长度:Out[89]=0.170753Out[90]=相对区间长度:Out[91]=0.00854324Out[92]=二、总体方差σ2的区间估计Out[93]=(一)卡方分布χ2=∑i =1n (X i -μ)2σ2 χ2(n )——μ已知Out[95]= 1.等尾区间:Out[98]={8.68869,9.34535}Out[99]=等尾区间长度:Out[100]=0.656658Out[101]=相对区间长度:Out[102]=0.0728243Out[103]=(二)卡方分布χ2=(n -1)S 2σ2 χ2(n -1)——μ未知Out[105]= 1.等尾区间:Out[108]={8.68917,9.3459}Out[109]=等尾区间长度:Out[110]=0.656728Out[111]=相对区间长度:Out[112]=0.0728279Out[113]=(三)卡方分布χ2=∑i =1n (X i -μ )2σ2~χ2(n )——μ未知正态分布\\正态分布统计分析\\正态分布参数区间估计.nb 11Out[115]= 1.等尾区间:Out[118]={8.68832,9.34495}Out[119]=等尾区间长度:Out[120]=0.65663Out[121]=相对区间长度:Out[122]=0.0728243Out[123]=三、总体标准差σ的区间估计Out[124]=(一)卡分布χ(n )——μ已知Out[126]= 1.等尾区间:Out[129]={2.94766,3.05702}Out[130]=等尾区间长度:Out[131]=0.109358Out[132]=相对区间长度:Out[133]=0.0364242Out[134]=(二)卡分布χ(n -1)——μ未知Out[136]= 1.等尾区间:Out[139]={2.94774,3.05711}Out[140]=等尾区间长度:Out[141]=0.109366Out[142]=相对区间长度:Out[143]=0.0364261Out[144]=(三)卡分布χχ(n )——μ未知Out[146]= 1.等尾区间:Out[149]={2.9476,3.05695}Out[150]=等尾区间长度:Out[151]=0.109355Out[152]=相对区间长度:Out[153]=0.0364242Out[154]=(四)卡方分布-2 i =1n Log [12Erfcχ2(2n )——μ已知Out[158]={2.89486,3.15965}Out[159]=等尾区间长度:12 正态分布\\正态分布统计分析\\正态分布参数区间估计.nbOut[160]=0.264793Out[161]=相对区间长度:Out[162]=0.0874698Out[163]=(五)卡方分布-2 i =1n Log [12Erfcχ2(2n )——μ未知Out[167]={2.86679,3.12718}Out[168]=等尾区间长度:Out[169]=0.260386Out[170]=相对区间长度:Out[171]=0.0868828正态分布\\正态分布统计分析\\正态分布参数区间估计.nb 13。
区间估计的原理引言:在统计学中,区间估计是一种估计参数未知的总体的方法,它提供了一个范围,称为置信区间,该范围内有一定概率包含了真实的参数值。
区间估计的原理是基于抽样理论和概率统计的基础上,通过样本数据来对总体进行估计。
一、区间估计的基本思想区间估计的基本思想是通过样本数据来估计总体的参数值,并给出一个置信区间,使得这个区间内的参数值有一定的概率包含真实的参数值。
通常情况下,我们希望这个置信区间尽可能地窄,以提高估计的精度。
二、置信水平的选择在进行区间估计时,我们需要选择一个置信水平来决定置信区间的范围。
置信水平是指在重复抽样的情况下,包含真实参数值的置信区间的概率。
常见的置信水平有90%、95%和99%等,一般情况下,我们会选择较高的置信水平,以增加估计的可靠性。
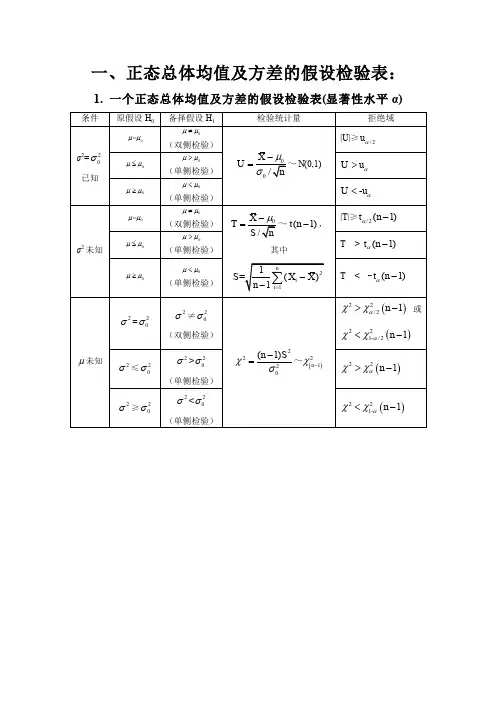
三、区间估计方法1. 正态分布情况下的区间估计:当总体服从正态分布时,可以使用样本均值和标准差来进行区间估计。
常用的方法有Z分布方法和t 分布方法,其中Z分布方法适用于大样本情况,t分布方法适用于小样本情况。
2. 非正态分布情况下的区间估计:当总体不服从正态分布时,可以使用样本中位数和四分位数来进行区间估计。
这种方法被称为非参数估计方法,它不依赖于总体的分布情况。
四、区间估计的应用区间估计在实际问题中具有广泛的应用,下面以两个例子来说明:1. 信赖度评估:在工程领域中,我们经常需要评估某个产品或系统的可靠性和信赖度。
通过对样本数据进行区间估计,我们可以对产品或系统的平均寿命进行估计,并给出一个置信区间,以评估其可靠性。
2. 市场调研:在市场调研中,我们经常需要对某个产品或服务的市场需求进行预测。
通过对样本数据进行区间估计,我们可以估计总体的平均需求量,并给出一个置信区间,以评估市场需求的波动范围。
结论:区间估计是统计学中一种重要的估计方法,它通过样本数据来对总体进行估计,并给出一个置信区间。
区间估计的原理是基于抽样理论和概率统计的基础上,通过选择置信水平和合适的估计方法来进行估计。
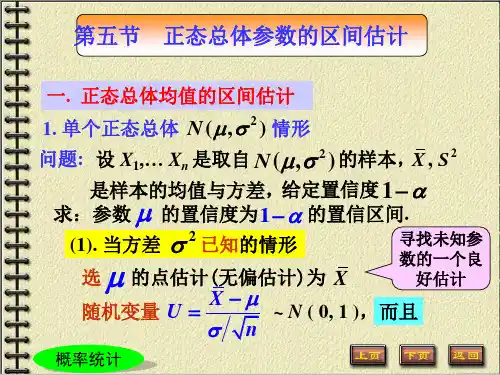
第19讲 正态总体参数的区间估计教学目的:理解区间估计的概念,掌握各种条件下对一个正态总体的均值和方差进行区间估计的方法。
教学重点:置信区间的确定。
教学难点:对置信区间的理解。
教学时数: 2学时。
教学过程:第六章 参数估计§6.3正态总体参数的区间估计1. 区间估计的概念我们已经讨论了参数的点估计,但是对于一个估计量,人们在测量或计算时,常不以得到近似值为满足,还需估计误差,即要求知道近似值的精确程度。
因此,对于未知参数θ,除了求出它的点估计ˆθ外,我们还希望估计出一个范围,并希望知道这个范围包含参数θ真值的可信程度。
设ˆθ为未知参数θ的估计量,其误差小于某个正数ε的概率为1(01)αα-<<,即ˆ{||}1P θθεα-<=-或αεθθεθ-=+<<-1)ˆˆ(P这表明,随机区间)ˆ,ˆ(εθεθ+-包含参数θ真值的概率(可信程度)为1α-,则这个区间)ˆ,ˆ(εθεθ+-就称为置信区间,1α-称为置信水平。
定义 设总体X 的分布中含有一个未知参数θ。
若对于给定的概率1(01)αα-<<,存在两个统计量1112(,,,)n X X X θθ= 与2212(,,,)n X X X θθ= ,使得12{}1P θθθα<<=-则随机区间12(,)θθ称为参数θ的置信水平为1α-的置信区间,1θ称为置信下限,2θ称为置信上限,1α-称为置信水平。
注(1)置信区间的含义:若反复抽样多次(各次的样本容量相等,均为n ),每一组样本值确定一个区间12(,)θθ,每个这样的区间要么包含θ的真值,要么不包含θ的真值。
按伯努利大数定理,在这么多的区间中,包含θ真值的约占100(1)%α-,不包含θ真值的约仅占100%α。
例如:若0.01α=,反复抽样1000次,则得到的1000个区间中,不包含θ真值的约为10个。
(2)置信区间的长度表示估计结果的精确性,而置信水平表示估计结果的可靠性。