SPSS18.0教程中文完整版学习
- 格式:pdf
- 大小:2.12 MB
- 文档页数:128

保姆级操作教程 | 手把手教你SPSS分析数据实战这也太方便了吧数据分析是现代社会研究中不可或缺的一部分。
而SPSS作为一款功能强大且易于使用的统计分析软件,受到了许多研究人员和学生的青睐。
本文将手把手教你如何使用SPSS进行数据分析,让你的研究工作更加高效和准确。
步骤1:导入数据首先,打开SPSS软件并点击菜单栏上的“文件”选项。
然后选择“打开”并浏览你存储数据集的位置。
选择相应的数据文件,并点击“打开”。
现在,你的数据集就已经成功导入。
步骤2:查看数据在导入数据后,你可以通过点击菜单栏上的“数据视图”选项来查看数据。
在数据视图中,你可以浏览和编辑数据。
如果你想查看数据的统计摘要信息,可以点击菜单栏上的“变量视图”选项。
步骤3:数据清理在进行数据分析之前,你需要对数据进行清理。
这包括处理缺失值、异常值和离群值等。
SPSS提供了一系列用于数据清理的功能,例如删除无效数据、替换缺失值等。
你可以使用菜单栏上的“转换”选项来执行这些操作。
步骤4:选择统计分析方法在进行数据清理后,接下来需要选择合适的统计分析方法。
SPSS提供了多种常用的统计分析方法,例如描述统计、相关分析、回归分析、t检验等。
你可以根据自己的研究目的和数据类型选择相应的方法。
步骤5:进行统计分析一旦你选择了合适的统计分析方法,你可以点击菜单栏上的“分析”选项,并选择相应的分析方法。
然后,你需要选择要分析的变量,并设置相应的参数。
点击“确定”后,SPSS将自动进行统计分析,并生成相应的结果。
步骤6:解读结果进行完统计分析后,你需要对分析结果进行解读。
SPSS会生成各种统计指标和图表,用于帮助你理解数据。
你可以查看参数估计值、置信区间、显著性水平等信息,并根据这些结果进行推断和判断。
步骤7:报告和呈现结果最后,你需要将分析结果进行报告和呈现。
SPSS提供了生成报告和图表的功能,你可以根据需要选择相应的样式和格式。
在报告中,你可以总结分析结果、提出结论,并展示相关的图表和图形。

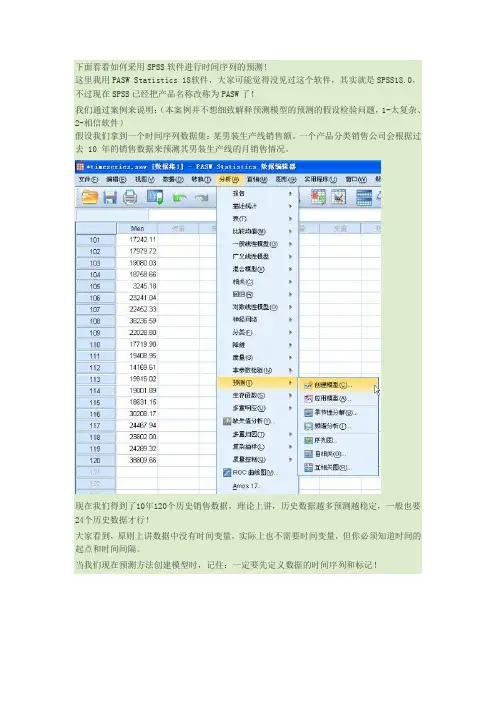
下面看看如何采用SPSS软件进行时间序列的预测!这里我用PASW Statistics 18软件,大家可能觉得没见过这个软件,其实就是SPSS18.0,不过现在SPSS已经把产品名称改称为PASW了!我们通过案例来说明:(本案例并不想细致解释预测模型的预测的假设检验问题,1-太复杂、2-相信软件)假设我们拿到一个时间序列数据集:某男装生产线销售额。
一个产品分类销售公司会根据过去 10 年的销售数据来预测其男装生产线的月销售情况。
现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行!大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH和DATE(时间标签)。
接下来:为了帮我们找到适当的模型,最好先绘制时间序列。
时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。
另外,我们需要弄清以下几点:• 此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?• 此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?这时候我们就可以看到时间序列图了!我们看到:此序列显示整体上升趋势,即序列值随时间而增加。
上升趋势似乎将持续,即为线性趋势。
此序列还有一个明显的季节特征,即年度高点在十二月。
季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。
时间序列预测模型的建立是一个不断尝试和选择的过程。

SPSS教程(完整)第⼆章 SPSS统计应⽤第⼀节 SPSS基础SPSS(Statistical Package for the Social Sciences)即社会科学统计软件包,是当今世界上公认的最流⾏、最强⼤的三⼤统计分析软件(SPSS、SAS和BMDP)之⼀。
SPSS从10.0版本开始就基于Microsoft Windows 95操作系统上运⾏,具有Windows软件的共同特征。
由于SPSS具有统计、绘图功能强、使⽤简单⽅便等优点。
受到⼴⼤科研⼯作者的青睐。
在这⾥主要以12.0版为基础,介绍SPSS的基本使⽤⽅法。
⼀、SPSS安装和运⾏1 SPSS v12.0 安装打开计算机,启动Windows XP操作系统。
1) 将课程配备的光碟放⼊光盘驱动器中。
2) 启动Windows资源管理器,双击光盘驱动器图标,在⽬录窗⼝中找到“SPSS12 install”⽂件夹,双击进⼊该⽂件夹;找到“setup”应⽤程序,双击后就启动安装。
显⽰欢迎安装SPSS 12.0版以及版权声明(图2-1),浏览后单击“Next”按钮进⼊下⼀个画⾯。
图2-1 SPSS12.0欢迎窗⼝3)同意SPSS12.0软件协议⽤户阅读“协议”,同意协议,单击“I accept the terms in license agreement”选项。
否则单击“Cancel”退出安装,如图2-2。
图2-2 软件协议窗⼝4)阅读SPSS 12.0 ⾃述⽂件后,单击“Next”按钮,进⼊下⼀个界⾯。
5)填写⽤户信息。
例如:在⽤户名“Name:”栏填写: Student在单位名称“Organization:”栏填写: SWU如图2-3。
单击“Next”按钮,进⼊下⼀个界⾯。
图2-3填写⽤户信息5)指定SPSS12.0系统的安装⽬录(图2-4)图2-4 指定安装⽬录同意安装程序⾃动安装到“C:\Program file\spss”,单击“Next”后进⼊下⼀个画⾯继续安装。

本章学习目标:掌握SPSS数据预处理的可视离散化方法;了解SPSS缺失值的填补方法;掌握SPSS的数据校验方法;如何标识重复个案;如何标识异常个案;学习如何从数据集中选择符合条件的个案。
随着计算机系统能力的提高,对信息的需要成比例增长,导致收集的数据越来越多。
随之而来的问题是出现更多的个案、更多的变量以及更多的数据输入错误。
这些错误会损害作为数据仓储最终目标的预测模型的预测能力,因此必须使数据保持“干净”。
不过,数据仓储中数据量的增长已经大大超出了手动验证个案的能力,因而实现自动化的数据验证过程变得十分关键。
数据预处理即当录入或读取数据后,对数据进行必要的清理(包括查错纠错、标识数据中的异常个案和无效个案、变量和数据值等)、转换、填补缺失值等,为后续统计分析应用(如均值比较、方差分析、回归分析等)打下良好基础。
如果把整个统计分析过程比作大厨烧菜,那么种菜或去菜场买菜等获取食材就相当于录入或读取数据,而扔掉坏的菜叶、切菜等准备工作就相当于数据预处理,而在锅里烧菜烹饪就相当于后续具体统计分析应用(如均值比较、方差分析、相关性分析、回归分析等)。
可见,数据预处理虽不产生最终的分析结果,但作为最终分析的准备,是数据分析必不可少的一环,它在完整的数据分析项目过程中的位置如图3-1所示。
在本章中,3.1节讨论尺度数据(即连续型数据)转换到分类数据的可视离散化方法;3.2节讨论SPSS中数据缺失值的填补方法;3.3节讨论SPSS中数据校验的方法;3.4节学习如何标识重复个案和异常个案;3.5节学习如何从数据集中选择满足条件的个案。
图3-1 统计分析项目过程图3.1 可视离散化可视离散化(可视化分段)(Visual Binning)用于为定量变量(或尺度变量)创建分类变量(或定性变量),从而实现连续变量的离散化。
在统计分析中,有时候需要了解总体的大致分布状况,而不需要了解属性的具体信息。
例如,调查居民的收入水平,实际得到的是以“元”计数的具体收入值。






spss使用教程SPSS使用教程SPSS(Statistical Package for the Social Sciences)是一款常用的统计分析软件。
它提供了丰富的数据分析功能,可以帮助我们进行数据清洗、统计描述、假设检验、回归分析、因子分析等各种统计分析任务。
下面是一个简单的SPSS使用教程,帮助你快速上手SPSS。
1. 新建数据集打开SPSS软件,点击"File"-"New"-"Data"来新建一个数据集。
可以选择手动输入数据,也可以将已有的数据文件导入。
2. 数据清洗在数据集中,经常会遇到缺失值、异常值等问题,需要进行数据清洗。
在SPSS中,可以使用"Transform"-"Recode"命令来处理缺失值,使用"Analyze"-"Descriptive Statistics"命令来识别和处理异常值。
3. 数据分析SPSS提供了丰富的数据分析功能。
以下是一些常用的数据分析任务及对应的SPSS命令:- 统计描述:使用"Analyze"-"Descriptive Statistics"命令来计算变量的均值、标准差、最小值、最大值等统计指标。
- 假设检验:使用"Analyze"-"Compare Means"命令来进行独立样本t检验、配对样本t检验等假设检验。
- 回归分析:使用"Analyze"-"Regression"命令来进行线性回归分析,探索变量之间的关系。
- 因子分析:使用"Analyze"-"Dimension Reduction"-"Factor"命令来进行因子分析,提取出潜在的因子结构。