计量经济学案例作业
- 格式:doc
- 大小:237.50 KB
- 文档页数:9


计量经济学期中教学案例分析作业第五章案例分析班级:电子商务15-2 班姓名:郑瑞璇学号:2015213720一、问题的提出与模型的建立根据本章引子提出的问题,为了给制定医疗机构的规划提供依据,分析比较医疗机构与人口数量的关系,建立卫生医疗机构数与人口数的回归模型。
假定医疗机构数与人口数之间满足线性约束,则理论模型设定为Yi= 31+ 化Xi+uiYi表示医疗机构数;Xi表示人口数。
由2001年《四川统计年鉴》得到如表1所示数据。
表1 四川省2000年各地医疗机构数与人口数地区人口数(万人)X医疗机构数(个)Y地区人口数(万人)X医疗机构数(个)Y成都1013.36304眉山339.9827自贡315911宜宾508.51530攀枝花103934广安438.61589泸州463.71297达州620.12403德阳379.31085雅安149.8866绵阳518.41616巴中346.71223广元302.61021资阳488.41361遂宁3711375阿坝82.9536内江419.91212甘孜88.9594乐山345.91132凉山402.41471南充709.24064二、参数估计进入EViews软件包,确定样本范围,编辑输入数据,选择估计方程菜单,得到图一的估计结果。
[=]Equatron: UNTITLED Workfile: UNTITLED::Untitled\ ■巴翁Dependent Variable: YMethod: Least SquaresDate: 12/19/16 Time: 21:39Sample: 1 21 induced observations: 21Variable Coefficient Std. Error t-Statistic ProbC -562.9074 291.5642 -1.930646 0.06B5X5372028 0.644239 8339811 00Q00R-squared 0.78543& Mean dependentvar 1508143Adjusted R-squared 0.774145 S.D. dependent var 1310.975S.E. of regression 5230301 Akaike info criterion 15 79746Sum squared resid 7375164 Schwarz criterion 15.89694Log likelihood -16X8733 Hann自n-Ouinn criter 15.31905F-statistic 69.55245 Durbin-Watson stat 1 947198ProbfF-stati stic) 0000000图一回归结果估计结果Yi = -562.9074 + 5.3728Xit= (-1.9306)(8.3398)2R =0.7854 F=69.55三、检验模型的异方差本例用的是四川省2000年各州市的医疗机构数和人口数,由于各地区人口数不同,对医疗机构设置数量有不同的需求,这种差异使得模型很容易产生异方差,从而影响模型的估计与使用。
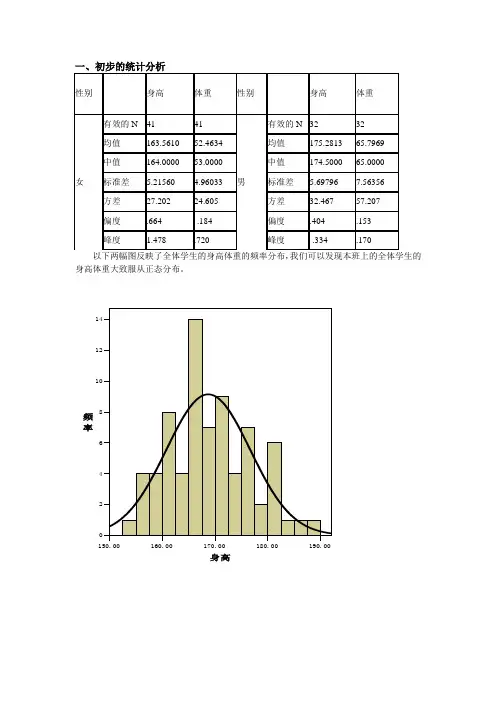
二、均值分析1、分性别对身高进行的比较假设男女身高相等,否定假设可认为男生身高明显高于女生。
2、分南北地区进行比较(1)身高假设两者均值相等,检验结果不能否定原假设,因而不能认为南北方身高有显著差异。
(2)体重通过假设两者均值相等,检验结果无法否定原假设,因而认为南北方体重没有明显差异。
3、分出生年份月份进行比较年份性别身高体重84 男均值172.00 56.00N 1 1总计均值172.00 56.00N 1 185 男均值180.33 70.67N 3 3女均值161.00 51.00N 2 2总计均值172.60 62.80N 5 586 男均值174.20 65.40N 20 20女均值162.11 52.28N 18 18总计均值168.47 59.1887 男均值178.50 66.58N 6 6女均值164.83 52.83N 18 18总计均值168.25 56.27N 24 2488 男均值170.50 65.00N 2 2女均值167.00 53.50N 2 2总计均值168.75 59.25N 4 489 女均值165.00 50.00N 1 1总计均值165.00 50.00N 1 1总计男均值175.28 65.80N 32 32女均值163.56 52.46N 41 41总计均值168.70 58.31N 73 73ANOVA 表由表可看出,各年份出生的人身高体重无显著性差异。
总计均值171.00 64.00N 6 6 3 男均值174.50 69.50N 4 4 女均值160.25 50.75N 4 4 总计均值167.38 60.13N 8 8 4 男均值181.25 68.50N 4 4 女均值162.25 52.00N 4 4 总计均值171.75 60.25N 8 8 5 男均值169.50 65.25N 2 2 女均值156.00 43.00N 1 1 总计均值165.00 57.83N 3 3 6 男均值175.00 63.00N 1 1 女均值171.50 57.50N 4 4 总计均值172.20 58.60N 5 5 7 男均值171.00 64.33N 3 3 女均值167.00 50.50N 2 2 总计均值169.40 58.80N 5 5 8 男均值179.20 64.90N 5 5 女均值161.50 52.50N 2 2 总计均值174.14 61.36N 7 7 9 男均值171.67 58.00N 3 3 女均值163.33 54.33N 3 3 总计均值167.50 56.1710 男均值174.67 61.83N 3 3总计均值174.67 61.83N 3 311 女均值162.50 51.67N 12 12总计均值162.50 51.67N 12 1212 男均值171.00 66.50N 2 2女均值167.00 57.00N 1 1总计均值169.67 63.33N 3 3总计男均值175.28 65.80N 32 32女均值163.56 52.46N 41 41总计均值168.70 58.31N 73 73ANOVA 表由表同样可得出,各月出生的人身高体重无显著性差异。
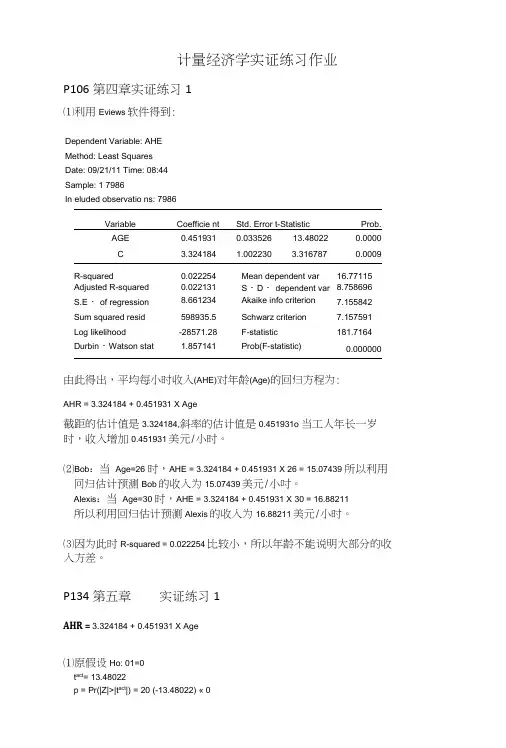
计量经济学实证练习作业P106第四章实证练习1⑴利用Eviews软件得到:Dependent Variable: AHEMethod: Least SquaresDate: 09/21/11 Time: 08:44Sample: 1 7986In eluded observatio ns: 7986Variable Coefficie nt Std. Error t-Statistic Prob.AGE 0.451931 0.033526 13.48022 0.0000C 3.324184 1.002230 3.316787 0.0009R-squared 0.022254 Mean dependent var 16.77115 Adjusted R-squared 0.022131 S・D・ dependent var 8.758696 S.E・ of regression 8.661234 Akaike info criterion 7.155842 Sum squared resid 598935.5 Schwarz criterion 7.157591 Log likelihood -28571.28 F-statistic 181.7164 Durbin・Watson stat 1.857141 Prob(F-statistic) 0.000000由此得出,平均每小时收入(AHE)对年龄(Age)的回归方程为:AHR = 3.324184 + 0.451931 X Age截距的估计值是3.324184,斜率的估计值是0.451931o 当工人年长一岁时,收入增加0.451931美元/小时。
⑵Bob:当Age=26 时,AHE = 3.324184 + 0.451931 X 26 = 15.07439 所以利用冋归估计预测Bob的收入为15.07439美元/小吋。
Alexis:当Age=30 时,AHE = 3.324184 + 0.451931 X 30 = 16.88211所以利用回归估计预测Alexis的收入为16.88211美元/小时。

计量案例分析学院:国际贸易学院班级:贸易经济2班姓名:___________学号:_______2013年12月16日□ Equati on: UNTITLED Workfile: UNTITLED::Untitled、View | Proc | Object | Print〔Name〔Freeze] Estimate | Forecast | Stats | Resids |Dependent Variable: YMethod: Least SquaresDate: 12/21/13 Time: 19:06Sample: 1994 2007Included observations: 14VariableCoefficientStd.Errort-Statistic Prob.C•1471.9561137.046-1.294544 0.2316X2 0.042510.0046139.216082 0.0000X3 4.4324781.0633414.168445 0.0031X4 2.9222731.0936652.6720010.0283X5 1.4267861.4175551.006512 0.3436X6 -354.9821244.8486-1.449802 0.1852R-squared0.997311Mean dependent var3527.783Adjusted R-squared 0.995630 S.D. dependent var 1927.495S.E. of regression 127.4135 Akaike info criterion 12.83028Sum squared resid 129873.5 Schwarz criterion 13.10416Log likelihood -83.81195 Hannan-Quinn criter. 12.80493F-statistic 593.4168 Durbin-Watson stat 1.558415Prob(F-statistic) 0.0000019941997年中国旅游收入及相关数据¥=-1471.96+0.0425X2+4.432X3+2.922X4+1.427X5-354.98X6R2 =0.997 -R=0.996经济意义:说明假定其他变量不变的情况下,各每增加1万人次的国内旅游人数、1元的城镇居民人均旅游花费、1元的农村居民人均旅游花费、1万公里的公路里程和1万公里的铁路里程,国内旅游收入就会相应的增加0. 0425亿元、4. 432亿元、2.922亿元、1.427亿元和减少354. 98亿元。

计量经济学建模案例计量经济学是一种运用数学和统计方法对经济现象进行定量分析的方法,可以帮助经济学家解释和预测经济现象,并制定相应的政策。
下面是一种计量经济学建模案例:假设我们要研究某个城市的房价与房屋面积之间的关系。
我们可以使用多元线性回归模型来建模,其中自变量是房屋面积,因变量是房价。
为了使模型更加准确,我们还可以引入其他可能影响房价的变量,如地理位置、房屋年龄、房屋类型等。
首先,我们需要收集相关的数据。
我们可以通过调查和市场价格来获得房屋面积、房价以及其他相关变量的数据。
假设我们收集了100个样本数据来建立模型。
接下来,我们需要进行数据的预处理。
这包括数据清洗、缺失值处理、异常值处理等。
我们可以使用统计软件进行数据处理和分析。
然后,我们可以使用多元线性回归模型来建立房价与房屋面积以及其他相关变量之间的关系。
模型的形式可以表示为:房价= β0 + β1 × 房屋面积+ β2 × 地理位置+ β3 × 房屋年龄 +β4 × 房屋类型+ ε其中,β0、β1、β2、β3、β4是模型的回归系数,表示不同变量对房价的影响程度。
ε是误差项,表示模型无法解释的部分。
接着,我们可以使用最小二乘法估计回归系数,并进行统计显著性检验和模型拟合度检验。
这可以帮助我们判断模型的准确性和可解释性。
最后,我们可以使用估计的回归模型来进行预测和分析。
通过对模型的解释和系数的分析,我们可以得出不同变量对房价的影响程度,并制定相应的政策措施。
总之,计量经济学建模能够帮助我们理解和预测经济现象,对于研究者和政策制定者具有重要意义。
以上是一个简单的计量经济学建模案例,实际的建模过程可能更加复杂,需要根据具体问题进行相应的分析和处理。

计量经济学作业第二章为了初步分析城镇居民家庭平均每百户计算机用户有量(Y)与城镇居民平均每人全年家庭总收入(X)的关系,可以作以X为横坐所估计的参数,总收入每增加1元,平均说来城镇居民每百户计算机拥有量将增加0.002873台,这与预期的经济意义相符。
拟合优度和统计检验拟合优度的度量:本例中可决系数为0.8320,说明所建模型整体上对样本数据拟合较好,即解释变量“各地区城镇居民家庭人均总收入”对被解释变量“各地区城镇居民每百户计算机拥有量”的绝大部分差异做出了解释。
对回归系数的t检验:针对和,估计的回归系数的标准误差和t值分别为:,;的标准误差和t值分别为:,。
因为,绝;因,所以应拒绝。
城镇居民人均总收入对城镇居民每百取,平均置信度已经得到、、、n=31,可计算出。
当时,将相关数据代入计算得到83.7846 3.1627,即是说当地区城镇居民人均总收入达到25000元时,城镇居民每百户计算机拥有量平均值置信度95%的预测区间为(80.6219,86.9473)台。
个别置信度95%的预测区间为当时,将相关数据代入计算得到83.784616.7190是说,当地区城镇居民人均总收入达到元时,城镇居民每百户计算机拥有量化,选择“教育支出在地方财政支出中的比重”作为其代表。
探索将模型设定为线性回归模型形式:根据图中的数据,模型估计的结果写为(935.8816)(0.0018)(0.0080)(0.0517)(9.0867)(470.3214)t=(-2.5820)(6.3167)(4.9643)(2.8267)(2.5109)(1.8422)=0.9732F=181.7539n=31模型检验1.经济意义检验模型估计结果说明,在嘉定齐天然变量不变的情况下,地区生产12中数据可以得到:=0.9732可决系数为=0.9679:,性水平,在分布表中查出自由度为k-1=5何n-k=25界值.由表3.4得到F=181.7539,由于F=181.7539>,应拒绝原假设:,说明回归方程显著,即“地区生产总值”,“年末人口数”,“居民平均每人教育现金消费”,“居民教育消费价格指数”,“教育支出在地方财政支出中的比重”等变量联合起来确实对“地方财政教育支出”有显著影响。

计量经济学第五,六章作业(总13页) -本页仅作为预览文档封面,使用时请删除本页-各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据(单位:元)(1)试根据上述数据建立2007年我国农村居民家庭人均消费支出对人均纯收入的线性回归模型。
(2)选用适当方法检验模型是否在异方差,并说明存在异方差的理由。
(3)如果存在异方差,用适当方法加以修正。
答:散点图线性回归分析图由图建立样本回归函数=+= F=由图形法可看出残差平方随的变动呈增大趋势,但还需进一步检验.White检验由上述结果可知,该模型存在异方差,理由是从数据可看出一是截面数据,看出各省市经济发展不平衡3)用加权最小二乘法修正,选用权数w1=,w2=,w3=.则散点图回归结果Goldfield-quanadt检验F==所以模型存在异方差t检验,F检验显著=+t=()()=,DW= ,F=剔除价格变动因素后的回归结果如下下表是北京市连续19年城镇居民家庭人均收入与人均支出的数据。
表略(1)建立居民收入—消费函数;残差图2ˆ79.9300.690(6.38)(12.399)(0.013)(6.446)(53.621)0.9940.575t t Y X Se t R DW =+====(2)检验模型中存在的问题,并采取适当的补救措施预以处理;(2)DW =,取%5=α,查DW 上下界18.1,40.1,18.1<==DW d d U L ,说明误差项存在正自相关(3)对模型结果进行经济解释。
采用科克伦奥科特迭代法广义差分因此,原回归模型应为t t X Y 669.0985.104+=其经济意义为:北京市人均实际收入增加1元时,平均说来人均实际生活消费支出将增加元。
.为了探讨股票市场繁荣程度与宏观经济运行情况之间的关系,取股票价格指数与GDP 开展探讨,表为美国1981-2006年股票价格指数(y )和国内生产总值GDP (x )的数据。
估计回归模型y_t=β_1+β_2 X_t+µ_t检验(1)中模型是否存在自相关,若存在,用广义差分法消除自相关最小二乘法估计回归模型为=3002527+ Se=t== F= DW=(2)LM=T=26*= P值为 t检验和F检验不可信。

计量经济学大作业计量经济学作为一门将经济理论、数学和统计学相结合的学科,在当今社会经济领域中发挥着重要作用。
它通过建立数学模型和运用统计方法,对经济现象进行定量分析和预测,为政策制定、企业决策等提供科学依据。
在本次大作业中,我将通过一个具体的案例来展示计量经济学的应用和分析过程。
假设我们要研究某地区的居民消费水平与收入水平之间的关系。
首先,我们需要收集相关的数据。
通过问卷调查、统计部门公布的数据等渠道,我们获取了该地区一定数量居民的收入和消费支出数据。
接下来,我们对数据进行初步的处理和分析。
观察数据的分布情况,检查是否存在异常值或缺失值。
对于异常值,需要判断其是由于数据录入错误还是真实的特殊情况。
如果是录入错误,进行修正;如果是特殊情况,则需要在后续的分析中加以考虑。
对于缺失值,可以采用适当的方法进行填补,如均值填补、回归填补等。
在确定数据质量良好后,我们建立计量经济模型。
根据经济理论和前人的研究成果,我们假设居民消费水平(Y)与收入水平(X)之间存在线性关系,模型可以表示为:Y =β0 +β1X +ε ,其中β0 是截距项,β1 是斜率,表示收入对消费的边际影响,ε 是随机误差项。
为了估计模型中的参数β0 和β1 ,我们使用最小二乘法(OLS)。
最小二乘法的基本思想是使得观测值与模型预测值之间的误差平方和最小。
通过计算,我们得到了参数的估计值。
然后,我们对模型进行检验。
首先是经济意义检验,即参数估计值的符号和大小是否符合经济理论和实际情况。
例如,在我们的模型中,β1 应该为正,因为通常情况下收入增加会导致消费增加。
其次是统计检验,包括拟合优度检验(R²)、变量的显著性检验(t 检验)和方程的显著性检验(F 检验)。
R²衡量了模型对数据的拟合程度,其值越接近 1 表示拟合越好。
t 检验用于判断每个自变量对因变量的影响是否显著,F 检验用于判断整个方程是否显著。
假设我们得到的估计结果为:Y = 1000 + 08X ,R²= 08 ,t 检验和 F 检验均显著。
计量经济学综合案例练习题综合练习一在中国某一城市的甲公司经营一幢写字楼的出租经营业务,虽然所处地段、楼宇均不错,但出租状况不理想。
公司决策层想寻找出租经营的突破口,需要研究影响写字楼出租率的各类因素,其中价格是一个重要影响因素。
为研究价格对出租率的影响,收集了如下17个写现需要解决如下几个问题:1.绘制空闲率与租金水平关系的散点图。
(使用EVIEWS软件的散点图功能)。
2.建立合适的回归模型,并估计模型参数。
3.对模型进行综合检验。
4.对回归模型进行综合评价。
5.解释模型中参数的意义,说明价格政策对写字楼出租率的影响。
综合练习二为了研究汽车需求量模型,调查了某国1971~1986年的汽车需求数据如下表所示,其中,Y=汽车出售量,X2=汽车价格指数,X3=消费价格指数,X4=个人可支配收入(亿元),X5=利1.制定适当的线性或对数线性模型,并估计汽车需求函数。
2.检验回归模型。
3.模型中是否存在多重共线。
4.用恰当的方法处理回归模型。
5.解释所得到的最终模型。
综合练习三为了研究中国城镇居民家庭交通和通讯支出与可支配收入的关系,收集了中国1998年各地区的数据如下表所示。
家庭可支配收入与交通和通讯支出单位:元通过城镇居民家庭交通和通讯支出与可支配收入的关系的分析可以预测随着人们收入的增加对交通通讯的需求。
要求:1.绘制两变量关系散点图,并就两变量依存关系给出基本分析。
2.设定回归分析模型并检验回归模型。
3.该样本为截面数据,检验回归模型的异方差性。
4.如模型中存在异方差,应如何处理。
5.解释最终模型的经济含义。
综合练习四为了研究地区经济总量与财政收入的关系,收集了某地区生产总值与财政收入的数据如下表所示。
要求:1. 建立恰当的回归模型研究财政收入对地区生产总值的依赖关系。
2. 检验所得的回归模型。
3. 用恰当的方法处理回归模型中存在的问题。
4. 解释所得到的最终回归模型。
综合练习五考虑如下模型t t *t u X Y ++=βα其中,*t Y =理想的或长期的厂房设备投资,t X =销售量。
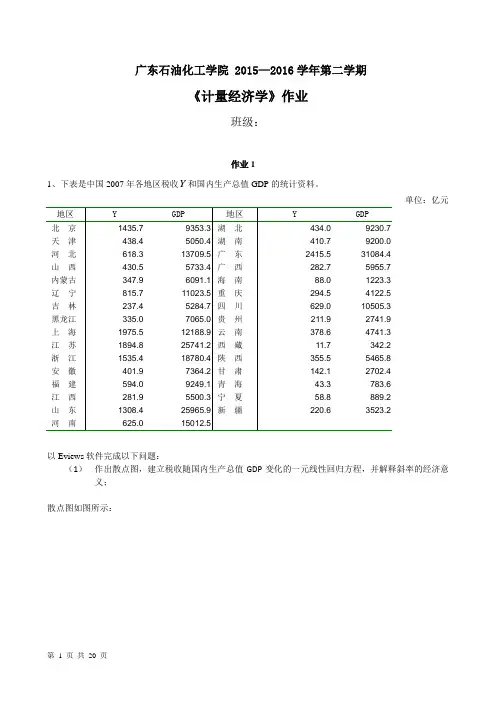
广东石油化工学院 2015—2016学年第二学期《计量经济学》作业班级:作业11、下表是中国2007年各地区税收Y和国内生产总值GDP的统计资料。
单位:亿元以Eviews软件完成以下问题:(1)作出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义;散点图如图所示:建立如下的回归模型根据Eviews软件对表中数据进行回归分析的计算结果知:R^2 = 0.760315 F=91.99198斜率的经济意义:国内生产总值GDP每增加1亿元,国内税收增加0.071亿元。
(2)对所建立的方程进行检验;从回归估计的结果看,模型拟合较好。
可决系数R2=0.760315,表明国内税收变化的76.03%可由国内生产总值GDP的变化来解释。
从斜率项的t检验值看,大于10%显著性水平下自由度为n-2=29的临界值t0.05(29)=1.699,且该斜率值满足0<0.071<1,符合经济理论中税收乘数在0与1之间的说法,表明2007年,国内生产总值GDP每增加1亿元,国内税收增加0.071亿元。
(3)若2008年某地区国内生产总值为8500亿元,求该地区税收收入的预测值和预测区间。
由上图可得知该地区国内生产总值的预测值:Y i= -10.63+0.071*8500=592.87(亿元)下面给出国内生产总值90%置信度的预测区间E(GDP)=8891.126Var(GDP)=57823127.64在90%的置信度下,某地区E(Y0)的预测区间为(60.3,1125.5)。
2、已知某市货物运输总量Y(万吨),国内生产总值GDP(亿元,1980不变价)1985年-1998年的样本观测值见下表。
年份Y GDP 年份Y GDP1985 18249 161.69 1992 17522 246.921986 18525 171.07 1993 21640 276.81987 18400 184.07 1994 23783 316.381988 16693 194.75 1995 24040 363.521989 15543 197.86 1996 24133 415.511990 15929 208.55 1997 25090 465.781991 18308 221.06 1998 24505 509.1资料来源:《天津统计年鉴》,1999年。
2.6计量经济学一元回归案例分析(课堂例题)一保险公司希望确定居民住宅区火灾造成的损失数量与该住户到最近的消防站的距离之间的关系,以便准确地定出保险金额。
下表列出火灾事故的损失及火灾发生地与最近的消防站的距离。
序号火灾损失Y 距消防站距离X1 28.1 4.32 19.8 1.83 31.3 7.64 23.5 3.85 27.5 5.16 36.2 9.57 24.1 3.78 22.3 2.59 17.5 1.610 31.3 6.311 22.4 3.112 35.3 9.513 45.2 14.414 35.4 9.315 35.1 7.5合计435 90均值29 6请:1)建立线性回归模型并进行相关的计算;2)用最小二乘法估计参数β1与β2;3)给出样本回归方程;4)进行方差分析5)进行回归方程的显著性检验[F0.05(1,13)=4.67;F0.01(1,13)=9.07]];6)计算相关系数并进行相关系数检验[r0.05(13)=0.514;r0.01(13)=0.64]7)计算样本的决定系数;8)计算总体方差的估计值;9)计算参数β1与β2的标准差的估计值;10)给出参数β1与β2的95%的置信区间[t0.025(13)=2.16];11)当X0=4.5公里时给出总体)(YE与个别值Y的点预测值;12)计算))(ˆ(00Y E Y Var -与)ˆ(00Y Y Var -估计值; 13)给出总体)(0Y E 与个别值0Y 的95%的区间预测。
解:X 、Y 散点图如下:火灾损失Y51015202530354045505101520火灾损失Y以下计算保留3位小数1)一元线性回归模型为:Y t =β1+β2X t +εt (t=12,……,n )列表计算如下序号 火灾损失Y 距消防站 距离X Y 的平方 X 的平方 XY Lyy —y 2Lxx —x 2 Lxy--xy1 28.1 4.3 789.61 18.49 120.83 0.81 2.89 1.532 19.8 1.8 392.04 3.24 35.64 84.64 17.64 38.643 31.3 7.6 979.69 57.76 237.88 5.29 2.56 3.684 23.5 3.8 552.25 14.44 89.3 30.25 4.84 12.1 5 27.5 5.1 756.25 26.01 140.25 2.25 0.81 1.356 36.2 9.5 1310.44 90.25 343.9 51.84 12.25 25.27 24.1 3.7 580.81 13.69 89.17 24.01 5.29 11.278 22.3 2.5 497.29 6.25 55.75 44.89 12.25 23.45 9 17.5 1.6 306.25 2.56 28 132.25 19.36 50.6 10 31.3 6.3 979.69 39.69 197.19 5.29 0.09 0.69 11 22.4 3.1 501.76 9.61 69.44 43.56 8.41 19.14 12 35.3 9.5 1246.09 90.25 335.35 39.69 12.25 22.05 13 45.2 14.4 2043.04 207.36 650.88 262.44 70.56 136.08 14 35.4 9.3 1253.16 86.49 329.22 40.96 10.89 21.12 15 35.1 7.5 1232.01 56.25 263.2537.212.259.15 合计 435 90 13420.38 722.34 2986.05 805.38 182.34 376.05 均值296894.69248.156199.07 53.692 12.15625.07由上表知:n=15i X ∑=90,X =6, 2i X ∑=722.34,xx L =2i x ∑=2)(X X i -∑=2i X ∑ -n(X )2=182.34i Y ∑=435,Y =29, 2i Y ∑=13420.38,yy L =2i y ∑=2)(Y Y i -∑=2i Y ∑-n(Y )2=805.38…………………………………………………………………………………………….i i Y X ∑=2986.05,xy L =i i y x ∑=))((Y Y X X i i --∑=i i Y X ∑ -n X Y =376.052)用最小二乘法进行参数估计2ˆβ=xy L /xx L =i i y x ∑/2i x ∑=))((Y Y X X i i --∑/2)(X X i -∑ =376.05/182.34=2.0621ˆβ=Y -2ˆβX =29-2.062×6=16.628 3)样本回归方程tY ˆ=1ˆβ+2ˆβt X =16.628+2.062t X (t=1,2,……,n ) 或 Y ˆ=1ˆβ+2ˆβX =16.628+2.062X 4)方差分析2)(Y Y i -∑ = 2)ˆ(i i Y Y -∑ + 2)ˆ(Y Y i-∑ TSS(总离差平方和) = RSS(残差平方和) + ESS(回归平方和) TSS=2)(Y Y i -∑=yy L =805.38ESS=2)ˆ(Y Y i-∑=2ˆβxy L =2.062×376.05=775.415 RSS=2)ˆ(i i Y Y -∑= TSS- ESS=yy L -2ˆβxy L =805.38-775.415=29.965 方差来源 平方和 自由度均方 F-统计量回归 775.415 1 MESS=ESS/1=775.415 F=MESS/MRSS=336.406 残差 29.965 13 MRSS=RSS/13=2.305 总离差 805.38 145)回归方程的显著性检验(1)α=0.05 F 0.05(1,13)=4.67(2)α=0.01 F 0.01(1,13)=9.07由方差分析表知:F=336.406> F 0.01(1,13)=9.07> F 0.05(1,13)=4.67 拒绝原假设H 0,认为解释变量与被解释变量间有显著的线性关系。
实验项目一Eviews使用1实验一 An Overview of Regression Analysis【实验目的】了解回归分析概述【实验原理】按步骤学会使用基本回归分析方法【实验内容】1. A simple example of regression analysis:1)Creating an EViews workfile2)Entering data into an EViews workfile3)Creating a group in EViews4)Graphing with EViews5)Generating new variables in EViews2. Exercises【实验步骤】详细步骤见附录1:Chapter 1: An Overview of Regression Analysis。
【实验结果分析】1、Exercises10:P171)实验结果Variable Coefficient Std. Error t-Statistic Prob.C 12927.98 2196.546 5.885596 0.0000GDP 17.08593 0.315860 54.09330 0.0000 R-squared 0.987846 Mean dependent var 113268.4Adjusted R-squared 0.987509 S.D. dependent var 64886.29S.E. of regression 7251.954 Akaike info criterion 20.66713Sum squared resid 1.89E+09 Schwarz criterion 20.75331Log likelihood -390.6754 Hannan-Quinn criter. 20.69779F-statistic 2926.085 Durbin-Watson stat 0.334658Prob(F-statistic) 0.000000PRICE = 12927.9811421 + 17.0859280802*GDP 单位:10亿美元2)实验结果分析A、详细说明估计参数的经济意义17.08表示美国的GDP每增加10亿美元,一栋独立住宅的名义中间价格就会平均上涨17.08美元。
【精品】计量经济学案例【案例一:经济增长与劳动力市场】计量经济学在劳动经济学中有着广泛的应用。
为了评估经济增长与劳动力市场之间的关系,可以使用生产函数模型,这一模型包括了劳动和资本等投入变量,以及一个因变量,即经济产出。
假设我们有一份涵盖了各个国家历年的GDP和劳动力人口的数据集,我们可以将数据设定为面板数据,并进行固定效应模型估计。
首先,我们需要对数据进行平稳性检验以避免伪回归。
我们可以用单位根检验,如ADF检验或IPS检验等来进行检查。
如果数据是平稳的,我们可以进行下一步,也就是估计生产函数模型。
如果我们发现劳动力和经济增长之间存在正相关关系,那么我们可能会得出结论:增加劳动力可以促进经济增长。
另一方面,如果资本和经济增长之间存在更强的关系,那么我们可能会建议政策制定者通过增加投资来刺激经济增长。
【案例二:价格与需求】计量经济学也被广泛应用于研究价格与需求之间的关系。
例如,在商品市场中,价格和需求之间存在负相关关系。
为了验证这一点,我们可以使用OLS估计法进行回归分析。
假设我们有一份包含各种商品价格和销售量的数据集。
我们可以将价格作为自变量,销售量作为因变量进行回归。
如果回归结果的斜率是负的,说明价格和销售量之间存在负相关关系,即当价格上升时,销售量会下降。
如果回归结果的斜率是正的,那么我们可能需要进一步检查数据是否存在异常值或者是否存在其他因素影响了结果。
通过这种分析,我们可以更好地理解价格和需求之间的关系,从而帮助政策制定者做出更好的决策。
例如,如果一个公司想要提高其产品的销售量,它可能需要考虑降低价格或者提供其他形式的促销活动。
【案例三:教育投资与经济增长】计量经济学也被广泛应用于研究教育投资与经济增长之间的关系。
一些研究表明,教育投资可以促进经济增长。
为了验证这一点,我们可以使用时间序列数据集进行回归分析。
假设我们有一份包含了各个国家历年的教育投资和GDP数据的时间序列数据集。
我们可以将教育投资作为自变量,GDP作为因变量进行回归。
计量经济学模型案例
最近进行的一项研究是使用计量经济学模型分析了我国交通拥堵问题。
交通拥堵不仅是城市发展的障碍,还对环境和居民的日常生活造成了很大的影响,因此对其进行研究具有重要的意义。
为了分析交通拥堵对出行时间的影响,我们使用了一个多元回归模型。
我们选择的解释变量包括交通流量、交通设施和经济指标,而被解释变量为行程时间。
我们收集了一年的数据,涵盖了多个城市和交通路段。
通过对数据的分析,我们发现交通流量对行程时间的影响是显著的。
当交通流量增加时,行程时间也相应增加。
这表明交通拥堵对出行时间有负面影响。
同时,我们还发现交通设施的改善可以减少行程时间。
例如,增加道路宽度和改善交叉口信号灯可以提高交通效率,缩短行程时间。
此外,我们还发现城市的经济指标与交通拥堵有关。
城市人口数量、经济发展水平和就业率都与交通流量和行程时间呈正相关关系。
这说明城市的人口和经济增长会导致交通拥堵问题的加剧。
根据我们的研究结果,我们提出了一些建议来缓解交通拥堵问题。
首先,可以采取交通管理措施来减少交通流量。
例如,限制车辆进入市区、完善公共交通和建设停车场等。
其次,应该加强对交通设施的投入,提高交通效率。
这包括改善道路、建设高速公路和提升交叉口的信号灯系统。
最后,还应该积极推
动城市的可持续发展和城市规划,促进经济的均衡发展,避免交通拥堵问题的进一步加剧。
综上所述,我们的计量经济学模型分析了我国交通拥堵问题,并提出了一些缓解措施。
这些研究结果对政府和城市规划者在解决交通拥堵问题上提供了有价值的参考。
案例适用:就业与失业案例内容:自从1978年我国改革开放以来,我国经济实现30年的持续稳定增长,1978—2006年的GDP年均增长率为9.7%,最近的四年GDP年增长率接近或超过10%。
2006年GDP的总量位居世界第四,仅次于德国,成绩令世界瞩目。
但经济运行中也出现了一些问题,如贫富差距、环境污染、贸易顺差等,而就业问题尤其突出,主要表现在以下几个方面:1.农村就业问题突出,转移农村劳动力的任务十分艰巨农村就业问题对农民的生活水平提高起到至关重要的作用,但是由于农村劳动力数额庞大,农村就业矛盾相当突出。
改革开放以来,发生农村劳动力大量向城镇转移,农业就业比重有所下降,1990—2006年,我国乡村从业人员所占比重由73.7%下降到62.9%,平均每年下降0.68个百分点。
但农业就业比重依然偏高,人口基数庞大,造成我国农村剩余劳动力规模仍维持在1.5亿左右。
农村劳动力转移任务十分艰巨。
2.城镇失业率趋于上升,实际失业率更高随着社会经济转型,我国城镇也面临着日益严峻的就业形势。
劳动年龄人口数量快速增长,农村劳动力向城市转移速度的加快以及城镇下岗职工再就业难度的加大,使得城镇失业现象日益严重。
1994年底,全国城镇登记失业人数为470.4万人,登记失业率达2.8%。
而到2006年底,城镇登记失业人数达到847.0万人,登记失业率达4.1%。
据国内有关研究机构和世界银行专家估计,中国城市实际失业率大约在8%~10%之间。
3.结构性就业矛盾突出在经济结构调整和深化企业改革中,我国出现下岗失业增加和用人需求萎缩同时存在的现象,结构性就业矛盾突出。
高素质、低年龄的劳动力在就业竞争中占据一定的优势,而低素质、高年龄的劳动者在劳动力市场竞争中越来越没有竞争能力,呈现出就业困难群体数量急剧增加的趋势。
2006年,全国普通高校毕业生人数从2005年的338万增加到390万左右,这个数字已经是2001年104万的近4倍。
2013级统计学专业《计量经济学》案例作业学号: 130702060 姓名:叶豪特1.下表是消费Y 与收入X 的数据,试根据所给数据资料完成以下问题:(1)估计回归模型u X Y ++=21ββ中的未知参数1β和2β,并写出样本回归模型的书写格式;(2)试用Goldfeld-Quandt 法和White 法检验模型的异方差性; (3)选用合适的方法修正异方差。
(1)eview 结果Method: Least SquaresDate: 06/08/15 Time: 10:20Sample: 1 60Included observations: 60Variable Coefficient Std. Error t-Statistic Prob. C 9.347522 3.638437 2.569104 0.0128 X 0.637069 0.019903 32.00881 0.0000 R-squared 0.946423 Mean dependent var 119.6667 Adjusted R-squared 0.945500 S.D. dependent var 38.68984 S.E. of regression 9.032255 Akaike info criterion 7.272246 Sum squared resid 4731.735 Schwarz criterion 7.342058 Log likelihood -216.1674 Hannan-Quinn criter. 7.299553 F-statistic 1024.564 Durbin-Watson stat 1.790431 Prob(F-statistic) 0.0000001β=9.35,2=0.64β,样本回归模型书写格式:01e=9.35+0.64XY X ββ=++(2)首先,用Goldfeld-Quandt 法进行检验。
a.将样本按递增顺序排序,去掉1/4,再分为两个部分的样本,即1222n n ==。
b.分别对两个部分的样本求最小二乘估计,得到两个部分的残差平方和,即2122603.01482495.840e e==∑∑求F 统计量为22212495.844.1390603.0148e F e===∑∑给定0.05α=,查F 分布表,得临界值为0.05(20,20) 2.12F =。
c.比较临界值与F 统计量值,有F =4.1390>0.05(20,20) 2.12F =,说明该模型的随机误差项存在异方差。
用White 法进行检验F-statistic6.301373 Probability 0.003370Test Equation:Dependent Variable: RESID^2 Method: Least SquaresDate: 06/08/15 Time: 12:25 Sample: 1 60C -10.03614 131.1424 -0.076529 0.9393 X 0.165977 1.619856 0.102464 0.9187 R-squared0.181067 Mean dependent var 78.86225 Adjusted R-squared 0.152332 S.D. dependent var 111.1375 S.E. of regression 102.3231 Akaike info criterion 12.14285 Sum squared resid 596790.5 Schwarz criterion 12.24757 Log likelihood -361.2856 F-statistic6.3013730.05α=,在自由度为2下查卡方分布表,得25.9915χ=。
比较临界值与卡方统计量值,即2210.8640 5.9915nR χ=>=,说明模型中的随机误差项存在异方差。
(2)用加权最小二乘估计,得如下结果Dependent Variable: Y Method: Least SquaresDate: 06/08/15 Time: 13:10 Sample: 1 60Included observations: 60 C 10.37051 2.629716 3.943587 0.0002 R-squared0.211441 Mean dependent var 106.2101 Adjusted R-squared 0.197845 S.D. dependent var 8.685376 S.E. of regression 7.778892 Akaike info criterion 6.973470 Sum squared resid 3509.647 Schwarz criterion 7.043282 Log likelihood -207.2041 F-statistic1159.176 R-squared0.946335 Mean dependent var 119.6667 Adjusted R-squared 0.945410 S.D. dependent var 38.68984 S.E. of regression 9.039689 Sum squared resid 4739.526其估计的书写形式为2ˆ10.37050.63100.2114,..7.7789,1159.18YX R s e F =+===2. 下表给出了日本工薪家庭实际消费支出与可支配收入数据日本工薪家庭实际消费支出与实际可支配收入单位:1000日元要求:(1)建立日本工薪家庭的收入—消费函数; (2)检验模型中存在的问题,并采取适当的补救措施预以处理;(3)对模型结果进行经济解释。
要求:(1)检测进口需求模型t t t u X Y ++=21ββ的自相关性;(2)采用科克伦-奥克特迭代法处理模型中的自相关问题。
(1)由eviews 一元线性回归结果可得:Dependent Variable: Y Method: Least Squares Date: 06/09/15 Time: 20:20 Sample: 1970 1994 Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.C -68.16026 15.26513 -4.465096 0.0002 X1.5297120.05097630.008460.0000R-squared0.975095 Mean dependent var 388.0000 Adjusted R-squared 0.974012 S.D. dependent var 43.33397 S.E. of regression 6.985763 Akaike info criterion 6.802244 Sum squared resid 1122.420 Schwarz criterion 6.899754 Log likelihood -83.02805 Hannan-Quinn criter. 6.829289 F-statistic 900.5078 Durbin-Watson stat 0.348288Prob(F-statistic)0.000000Y=-68.16+1.53X(1)220.975,0.974,900.5078,..0.348R R F DW ====(2)Dependent Variable: Y Method: Least Squares Date: 06/09/15 Time: 20:58 Sample: 1970 1994 Included observations: 25VariableCoefficientStd. Errort-StatisticProb.C 18.33144 29.51518 0.621085 0.5409 X 1.202239 0.109382 10.99121 0.0000 TIME^20.0505020.0155223.2536110.0036R-squared 0.983186 Mean dependent var 388.0000 Adjusted R-squared 0.981657 S.D. dependent var 43.33397 S.E. of regression 5.868976 Akaike info criterion 6.489404 Sum squared resid 757.7875 Schwarz criterion 6.635669 Log likelihood -78.11755 Hannan-Quinn criter. 6.529972 F-statistic 643.2046 Durbin-Watson stat 0.403640 Prob(F-statistic)0.000000D.W.检验结果表明,在5%显著性水平下,n=25,k=2(包含常数项),查表得1.29, 1.45,L U d d ==,由于D.W.=0.35<L d ,故(1)存在正自相关。
引入时间变量T (T=1,2,……,25)以平方的形式出现,回归函数变化为:2ˆY=18.33+1.20X+0.05T (2)22R 0.983,R 0.982,643.205,..0.404F DW ====,这里,D.W.值仍然比较低,没有通过5%显著性水平下的D.W.检验,因此判断(2)式仍然存在正自相关性。
再对(2)式进行序列相关性的拉格朗日乘数检验。
含一阶滞后残差项的辅助回归为:2t t-12e =50.81-0.19X+0.03T 0.75e 0.75R +=%%于是,LM=240.75⨯=18,该值大于显著性水平为5%,自由度为1的2χ分布的临界值20.05=3.84χ(1),由此判断原模型存在1阶序列相关性。
含2阶滞后残差项的辅助回归为: Dependent Variable: A Method: Least Squares Date: 06/09/15 Time: 22:00 Sample: 1970 1994Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.C -0.620166 19.49328 -0.031814 0.9749 X 0.001895 0.072225 0.026239 0.9793 TIME^2 0.001447 0.010240 0.141311 0.8890 RE 0.9176810.2108534.352228 0.0003 RE2-0.197403 0.213975-0.9225500.3672R-squared 0.604654 Mean dependent var 1.98E-14 Adjusted R-squared 0.525585 S.D. dependent var 5.619117 S.E. of regression 3.870322 Akaike info criterion 5.721409 Sum squared resid 299.5879Schwarz criterion5.965184 Log likelihood -66.51761 Hannan-Quinn criter. 5.789022 F-statistic7.647165 Durbin-Watson stat 1.826752 Prob(F-statistic)0.000657(RE2为2e t -%)2t t-1t-22e -0.620.00190.001440.924e -0.197e 0.605X time R =+++=%%%采用科克伦-奥克特两步法处理模型中的自相关问题 根据01111t t t Y X ββρμε-=+++,eviews 运行结果如下:112167.00 1.130.980.99t t Y X R μ-=++=最终的消费模型为 Y t = 93.7518+0.5351 X t(3)模型说明日本工薪居民的边际消费倾向为0.5351,即收入每增加1元,平均说来消费增加0.54元。