计量经济学第四章 多元线性回归模型
- 格式:ppt
- 大小:673.01 KB
- 文档页数:104


多元线性回归的计算模型多元线性回归模型的数学表示可以表示为:Y=β0+β1X1+β2X2+...+βkXk+ε,其中Y表示因变量,Xi表示第i个自变量,βi表示第i个自变量的回归系数(即自变量对因变量的影响),ε表示误差项。
1.每个自变量与因变量之间是线性关系。
2.自变量之间相互独立,即不存在多重共线性。
3.误差项ε服从正态分布。
4.误差项ε具有同方差性,即方差相等。
5.误差项ε之间相互独立。
为了估计多元线性回归模型的回归系数,常常使用最小二乘法。
最小二乘法的目标是使得由回归方程预测的值与实际值之间的残差平方和最小化。
具体步骤如下:1.收集数据。
需要收集因变量和多个自变量的数据,并确保数据之间的正确对应关系。
2.建立模型。
根据实际问题和理论知识,确定多元线性回归模型的形式。
3.估计回归系数。
利用最小二乘法估计回归系数,使得预测值与实际值之间的残差平方和最小化。
4.假设检验。
对模型的回归系数进行假设检验,判断自变量对因变量是否显著。
5. 模型评价。
使用统计指标如决定系数(R2)、调整决定系数(adjusted R2)、标准误差(standard error)等对模型进行评价。
6.模型应用与预测。
通过多元线性回归模型,可以对新的自变量值进行预测,并进行决策和提出建议。
多元线性回归模型的计算可以利用统计软件进行,例如R、Python中的statsmodels库、scikit-learn库等。
这些软件包提供了多元线性回归模型的函数和方法,可以方便地进行模型的估计和评价。
在计算过程中,需要注意检验模型的假设前提是否满足,如果不满足可能会影响到模型的可靠性和解释性。
总而言之,多元线性回归模型是一种常用的预测模型,可以分析多个自变量对因变量的影响。
通过最小二乘法估计回归系数,并进行假设检验和模型评价,可以得到一个可靠的模型,并进行预测和决策。


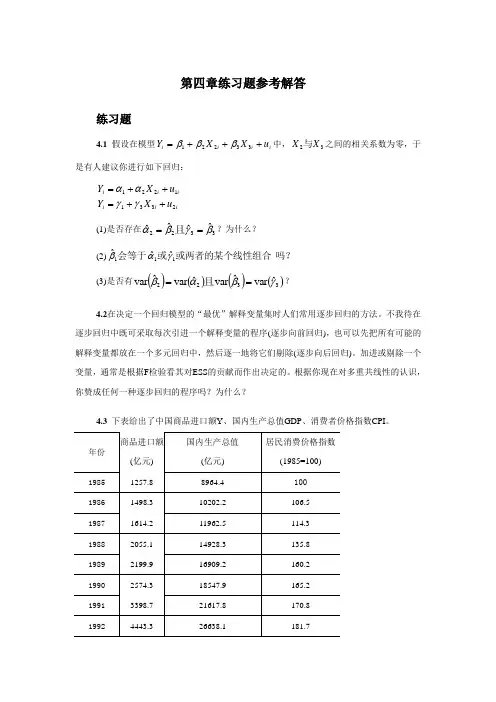
第四章练习题参考解答练习题4.1 假设在模型i i i i u X X Y +++=33221βββ中,32X X 与之间的相关系数为零,于是有人建议你进行如下回归:ii i i i i u X Y u X Y 23311221++=++=γγαα(1)是否存在3322ˆˆˆˆβγβα==且?为什么? (2)吗?或两者的某个线性组合或会等于111ˆˆˆγαβ (3)是否有()()()()3322ˆvar ˆvar ˆvar ˆvar γβαβ==且? 4.2在决定一个回归模型的“最优”解释变量集时人们常用逐步回归的方法。
不我待在逐步回归中既可采取每次引进一个解释变量的程序(逐步向前回归),也可以先把所有可能的解释变量都放在一个多元回归中,然后逐一地将它们剔除(逐步向后回归)。
加进或剔除一个变量,通常是根据F 检验看其对ESS 的贡献而作出决定的。
根据你现在对多重共线性的认识,你赞成任何一种逐步回归的程序吗?为什么?4.3 下表给出了中国商品进口额Y 、国内生产总值GDP 、消费者价格指数CPI 。
资料来源:《中国统计年鉴》,中国统计出版社2000年、20XX 年。
请考虑下列模型:i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
(2)你认为数据中有多重共线性吗? (3)进行以下回归:it t i t t i t t v CPI C C GDP v CPI B B Y v GDP A A Y 321221121ln ln ln ln ln ln ++=+=+=++根据这些回归你能对数据中多重共线性的性质说些什么?(4)假设数据有多重共线性,但32ˆˆββ和在5%水平上个别地显著,并且总的F 检验也是显著的。
对这样的情形,我们是否应考虑共线性的问题?4.4 自己找一个经济问题来建立多元线性回归模型,怎样选择变量和构造解释变量数据矩阵X 才可能避免多重共线性的出现?4.5 克莱因与戈德伯格曾用1921-1950年(1942-1944年战争期间略去)美国国内消费Y 和工资收入X1、非工资—非农业收入X2、农业收入X3的时间序列资料,利用OLSE 估计得出了下列回归方程:37.107 95.0 (1.09) (0.66) (0.17) (8.92) 3121.02452.01059.1133.8ˆ2==+++=F R X X X Y (括号中的数据为相应参数估计量的标准误)。






多元线性回归模型引言:多元线性回归模型是一种常用的统计分析方法,用于确定多个自变量与一个连续型因变量之间的线性关系。
它是简单线性回归模型的扩展,可以更准确地预测因变量的值,并分析各个自变量对因变量的影响程度。
本文旨在介绍多元线性回归模型的原理、假设条件和应用。
一、多元线性回归模型的原理多元线性回归模型基于以下假设:1)自变量与因变量之间的关系是线性的;2)自变量之间相互独立;3)残差项服从正态分布。
多元线性回归模型的数学表达式为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y代表因变量,X1,X2,...,Xn代表自变量,β0,β1,β2,...,βn为待估计的回归系数,ε为随机误差项。
二、多元线性回归模型的估计方法为了确定回归系数的最佳估计值,常采用最小二乘法进行估计。
最小二乘法的原理是使残差平方和最小化,从而得到回归系数的估计值。
具体求解过程包括对模型进行估计、解释回归系数、进行显著性检验和评价模型拟合度等步骤。
三、多元线性回归模型的假设条件为了保证多元线性回归模型的准确性和可靠性,需要满足一定的假设条件。
主要包括线性关系、多元正态分布、自变量之间的独立性、无多重共线性、残差项的独立性和同方差性等。
在实际应用中,我们需要对这些假设条件进行检验,并根据检验结果进行相应的修正。
四、多元线性回归模型的应用多元线性回归模型广泛应用于各个领域的研究和实践中。
在经济学中,可以用于预测国内生产总值和通货膨胀率等经济指标;在市场营销中,可以用于预测销售额和用户满意度等关键指标;在医学研究中,可以用于评估疾病风险因素和预测治疗效果等。
多元线性回归模型的应用可以为决策提供科学依据,并帮助解释变量对因变量的影响程度。
五、多元线性回归模型的优缺点多元线性回归模型具有以下优点:1)能够解释各个自变量对因变量的相对影响;2)提供了一种可靠的预测方法;3)可用于控制变量的效果。
然而,多元线性回归模型也存在一些缺点:1)对于非线性关系无法准确预测;2)对异常值和离群点敏感;3)要求满足一定的假设条件。
4.31)建立经济模型:i t t t CPI GDP Y μβββ+++=ln ln ln 321其中 Y 表示为商品进口额,GDP 表示为国内生产总值,CPI 表示为居民消费价格指数。
模型参数估计结果:t t t CPI GDP Y ln 057053.1ln 656674.1060149.3ln -+-=(0.337427)(0.092206) (0.214647)t= (-9.069059) (17.96703) (-4.924618)992218.02=R 991440.02=RF=1275.093(2)居民消费价格指数的回归系数的符号不能进行合理的经济意义解释,且CPI 与进口之间的简单相关系数呈现正向变动。
可能数据中有多重共线性。
计算相关系数:从上图可知, GDP 与CPI 之间存在较高的线性相关。
3)已知:i t t GDP A A Y 121ln ln μ++= i t t CPI B B Y 221ln ln μ++= i t t CPI C C GDP 321ln ln μ++=对以上三个模型分别进行回归,结果如下:t t GDP Y ln 218573.1090667.4ln +-=(0.384252) (0.035196)t= (-10.64579) (34.62222)982783.02=R 981963.02=R F=1198.698t t CPI Y ln 253662.1442420.5ln +-=(1.253662) (0.228046)t= (-4.341218) (11.68091)866619.02=R 860268.02=R F=136.4437t t CPI GDP 245971.2437984.1ln +-=(0.734328) (0.133577)t= (-1.958231) (16.81400)930855.02=R 927563.02=R F=282.7107单方程拟合效果都很好,回归系数显著,可决系数较高,GDP 和CPI 对进口分别有显著的单一影响,在这两个变量同时引入模型时影响方向发生了改变,这只有通过相关系数的分析才能发现。
计量经济学复习笔记(四):多元线性回归⼀元线性回归的解释变量只有⼀个,但是实际的模型往往没有这么简单,影响⼀个变量的因素可能有成百上千个。
我们会希望线性回归模型中能够考虑到这些所有的因素,⾃然就不能再⽤⼀元线性回归,⽽应该将其升级为多元线性回归。
但是,有了⼀元线性回归的基础,讨论多元线性回归可以说是轻⽽易举。
另外我们没必要分别讨论⼆元、三元等具体个数变量的回归问题,因为在线性代数的帮助下,我们能够统⼀讨论对任何解释变量个数的回归问题。
1、多元线性回归模型的系数求解多元线性回归模型是⽤k 个解释变量X 1,⋯,X k 对被解释变量Y 进⾏线性拟合的模型,每⼀个解释变量X i 之前有⼀个回归系数βi ,同时还应具有常数项β0,可以视为与常数X 0=1相乘,所以多元线性回归模型为Y =β0X 0+β1X 1+β2X 2+⋯+βk X k +µ,这⾥的µ依然是随机误差项。
从线性回归模型中抽取n 个样本构成n 个观测,排列起来就是Y 1=β0X 10+β1X 11+β2X 12+⋯+βk X 1k +µ1,Y 2=β0X 20+β1X 21+β2X 22+⋯+βk X 2k +µ2,⋮Y n =β0X n 0+β1X n 1+β2X n 2+⋯+βk X nk +µn .其中X 10=X 20=⋯=X n 0=1。
⼤型⽅程组我们会使⽤矩阵表⽰,所以引⼊如下的矩阵记号。
Y =Y 1Y 2⋮Y n,β=β0β1β2⋮βk,µ=µ1µ2⋮µn.X =X 10X 11X 12⋯X 1k X 20X 21X 22⋯X 2k ⋮⋮⋮⋮X n 0X n 1X n 2⋯X nk.在这些矩阵表⽰中注意⼏点:⾸先,Y 和µ在矩阵表⽰式中都是n 维列向量,与样本容量等长,在线性回归模型中Y ,µ是随机变量,⽽在矩阵表⽰中它们是随机向量,尽管我们不在表⽰形式上加以区分,但我们应该根据上下⽂明确它们到底是什么意义;β是k +1维列向量,其长度与Y ,µ没有关系,这是因为β是依赖于变量个数的,并且加上了对应于常数项的系数(截距项)β0;最后,X 是数据矩阵,且第⼀列都是1。
多元线性回归模型实验报告计量经济学多元线性回归模型是一种比较常见的经济学建模方法,其可用于对多个自变量和一个因变量之间的关系进行分析和预测。
在本次实验中,我们将使用一个包含多个自变量的数据集,对其进行多元线性回归分析,并对分析结果进行解释。
数据集介绍本次实验使用的数据集来自于UCI Machine Learning Repository,数据集包含有关汽车试验的多个自变量和一个连续因变量。
数据集中包含了204条记录,其中每条记录包含了一辆汽车的14个属性,分别是:MPG(燃油效率),气缸数(Cylinders)、排量(Displacement)、马力(Horsepower)、重量(Weight)、加速度(Acceleration)、模型年(Model Year)、产地(Origin)等。
模型建立在进行多元线性回归分析之前,我们首先需要对数据进行预处理。
为了确保数据的可用性,我们需要先检查数据是否存在缺失值和异常值。
如果有,需要进行相应的处理,以确保因变量和自变量之间的关系受到了正确地分析。
在对数据进行预处理之后,我们可以使用Python中的statsmodels包来对数据进行多元线性回归分析。
具体建模过程如下:```import statsmodels.api as sm# 准备自变量和因变量数据X = data[['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']]y = data['MPG']# 添加常数项X = sm.add_constant(X)# 拟合线性回归模型model = sm.OLS(y, X).fit()# 输出模型摘要print(model.summary())```在上述代码中,我们首先通过data[['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']]选择了所有自变量列,用于进行多元线性回归分析;然后,我们又通过`sm.add_constant(X)`,向自变量数据中添加了一列全为1的常数项,用于对截距进行建模;最后,我们使用`sm.OLS(y, X).fit()`来拟合线性回归模型,并使用`model.summary()`输出模型摘要。