分类资料统计分析
- 格式:ppt
- 大小:11.05 MB
- 文档页数:49

分类资料的统计分析一、概念分类资料是指观测对象按照其中一种特征进行分类或分组的数据。
常见的分类资料有性别(男、女)、学历(小学、初中、高中、大学)、职业(医生、教师、律师等)。
分类资料中每个分类称为一类或一组,根据组别统计频数或百分比可以揭示不同分类间的差异和关系。
二、方法1.频数与频率分析:通过统计每个类别的个数,得到各类别的频数和频率(频次比),并绘制柱状图、饼图等图表,直观地展示不同类别的占比情况。
2.极差分析:对于有序分类资料,比如学历,可以计算最高和最低值的差距,该差距称为极差。
极差分析衡量了不同类别之间的距离,有助于比较不同类别在一些变量上的差异。
3.交叉分析:用于分析两个或多个分类资料之间的关系。
通过交叉表格(列联表)和卡方检验,可以计算出各类别之间的关联度,判断不同分类是否相互关联。
4.分类资料的描述性统计分析:主要包括计算百分比、计算平均数、计算方差等统计指标。
通过这些指标,可以对不同类别的分布情况进行综合分析。
三、实践应用1.人口统计学:年龄、性别、婚姻状况等是人口统计学中常见的分类资料。
通过对这些资料的统计分析,可以了解人口结构、人口变动趋势等,为制定人口政策提供参考。
2.市场调研:对于市场调研中收集到的消费者分类资料,可以通过频数分析和交叉分析揭示不同人群的消费偏好和购买行为,帮助企业制定更加精准的销售策略。
3.教育评估:对学生的学历、家庭背景等进行统计分析,可以了解学生群体的整体素质水平、教育资源配置情况等,为教育政策制定和学校招生计划提供依据。
4.健康管理:对医疗数据中患者的病种、治疗效果等分类资料进行统计分析,可以评估不同病种的流行趋势、治疗效果、药物副作用等,为医疗决策提供参考。
总之,分类资料的统计分析是统计学中的重要内容,通过对分类资料的频数、频率、交叉分析等方法进行利用,可以揭示分类之间的差异、关系和趋势,为各个领域的决策者和研究者提供参考依据。



分类资料组间比较的统计方法选择与应用在统计学中,分类资料组间比较是指对不同分类资料组之间的差异进行统计分析。
分类资料是指将个体按其中一种特征分组,而分类资料组是指这些不同特征组成的组。
此时,为了确定不同组之间的差异,我们需要选择适当的统计方法进行比较。
下面介绍几种常用的分类资料组间比较的统计方法选择与应用。
1.基本原则:在选择分类资料组间比较的统计方法时,需要根据变量的测定水平来确定,通常可以根据资料的测定水平来进行分类资料分析的方法选择。
对于分类资料,我们可以采用卡方检验分析,对于有序分类资料,我们可以采用秩和检验分析。
2.卡方检验:卡方检验适用于分类资料的比较,其基本思想是比较实际观测频数与理论频数之间的差异。
卡方检验有两种形式:独立性检验和拟合优度检验。
独立性检验用于检验两个或多个分类变量之间是否存在关联;拟合优度检验用于检验观测频数与理论频数之间的差异是否显著。
3.秩和检验:对于有序分类资料,我们可以采用秩和检验进行比较。
秩和检验的基本思想是将不同组之间的观测值按顺序排列,并将其转化为秩次,然后将秩次相加得到秩和,通过比较秩和的大小来判断不同组之间的差异是否显著。
4.t检验:当分类资料分为两个组进行比较时,可以采用t检验。
t检验的基本思想是通过比较两个组的均值差异来判断两个组之间的差异是否显著。
但是需要注意的是,t检验要求数据满足正态分布的假设,所以在进行t检验之前需要进行正态分布检验。
5.方差分析:当分类资料包含多个组时,可以使用方差分析进行比较。
方差分析的基本思想是比较组间方差与组内方差之间的差异,通过计算F值来判断不同组之间的差异是否显著。
方差分析也需要满足正态分布的假设。
6.非参数检验:如果数据不满足正态分布假设,或者样本量较小,可以使用非参数检验。
非参数检验不依赖于总体分布形式的假设,比如Mann-Whitney U检验适用于两个独立样本的比较,Kruskal-Wallis H检验适用于多个独立样本的比较。

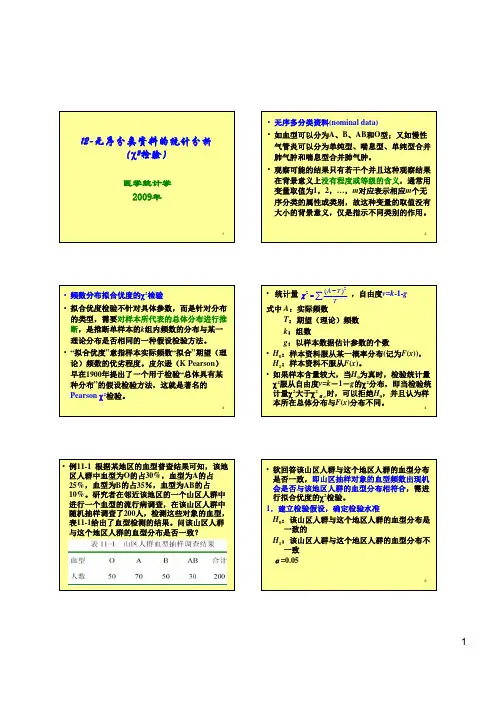
与这个地区人群的血型分布是否一致?53.计算χ统计量及自由度22()20.38A T Tχ−==∑10与消咳喘治疗慢性支气管炎的疗效是否相同?11数据,其余数据均由此派生。
13•一般地,R 行C 列的理论频数n :总频数n R :第R 行频数合计n C :第C 列频数合计•两个独立样本率的比较可用基本公式•亦可用上述基本公式的展开式n n n T CR =∑−=TT A 22)(χ)1(22−=∑CR n n A n χ14•四格表专用公式•在此,式(11-1)、(11-3)及(11-4)等价。
•由于受到“行频数合计等于n ,且列频数合计等于n ”条件的约束,自由度为•对于两独立样本四格表资料,自由度22()()()()()ad bc na b c d a c b d χ−=++++)(列数)行数11(−×−=ν11212(=−×−=)()ν151.建立检验假设,确定检验水准H 0:π1=π2,即两种药物治疗慢性支气管炎的疗效相同H 1:π1≠π2,即两种药物治疗慢性支气管炎的疗效不同α=0.05162.求检验统计量χ2值和自由度v•首先,计算a 、b 、c 、d 对应的理论频数。
•当然,在计算T 11基础上,其余三个理论数也可以按以下方式计算。
253.100237/19812011=×=T 747.19237/3912012=×=T 747.97237/19811721=×=T 253.19237/3911722=×=T 747.19253.10012012=−=T 747.97253.10019821=−=T 253.19747.9711722=−=T 17然后,计算检验统计量χ2值和自由度v•四个表专用公式:45.30 253.19)253.1935(747.97)747.9782(747.19)747.194(253.100)253.100116( )(222222=−+−+−+−=−=∑TT A χ1ν=×(2-1)(2-1)=222()()()()()(11635482)23730.44631(1164)(8235)(11682)(435)ad bc na b c d a c b d −=++++×−××==+×+×+×+χ183.确定P 值,下结论•查附表8,χ20.05,1=3.84,χ2=30.45>χ20.05,1,P<0.05,按α=0.05水准拒绝H 0,差别有统计学意义,可认为慢支口服液II 号治疗慢性支气管炎有效率高于消咳喘。

分类变量资料的统计分析详细讲解资料的统计分析通常包括描述统计和推断统计两个方面。
描述统计主要是对变量的单个特征进行分析,常用的统计指标包括频数、比例、均值、中位数、众数、标准差等;推断统计则是在样本数据的基础上推断总体数据的特征,常用的方法包括假设检验、方差分析、回归分析等。
本文将以分类变量为例,详细介绍分类变量资料的统计分析方法和步骤。
首先,分类变量是一种相互独立、不可顺序比较的变量,常见的示例包括性别、职业、学历等。
对于分类变量资料的统计分析,首先需要进行数据的整理和描述。
数据整理包括去除缺失值、异常值和重复值等处理。
应根据实际情况选择合适的处理方法,常用的方法有均值填充、删除等。
同时,需要将数据进行编码或离散化处理,便于后续的分析。
数据描述主要包括频数及比例的统计,可以用来描述分类变量的分布情况。
通过计算每个类别的频数和比例,可以获得分类变量的基本特征。
同时,可以使用图表来展示分类变量的分布情况,如饼图、柱状图等。
接下来,可以对分类变量与其他变量之间的关系进行分析。
常用的方法有卡方检验和列联表分析。
卡方检验适用于两个分类变量之间的关系检验,可以用来判断两个分类变量是否相关;列联表分析则可以用来描述两个分类变量之间的关系程度。
通过分析发现两个或多个分类变量之间的关联关系,可以更好地理解数据。
此外,对于分类变量的统计分析还可以进行组内和组间的比较。
组内比较主要是对同一分类变量的不同类别进行比较,常用的方法有t检验和方差分析;组间比较则是对不同分类变量之间的差异进行比较,可以使用相关分析和回归分析等方法。
最后,需要进行结果的解释和报告。
对分类变量资料的统计分析得出的结果进行解读,并进行相关性讨论。
通过各种统计方法对变量进行分析,报告结果可以提供决策者一个更全面的了解。
总结起来,分类变量资料的统计分析主要包括数据整理和描述、关联分析、比较分析和结果解释等步骤。
通过这些步骤可以更好地分析分类变量的特征、关系和差异,为实际问题的解决提供有力的支持和参考。


STATA软件操作(四)分类与等级资料的统计分析STATA软件操作(四)分类与等级资料的统计分析在统计学中,数据可分为分类数据和等级数据。
分类数据是指事物被划分为不同的类别或类型,每个类别之间没有顺序或大小的关系。
而等级数据则是指事物按照某种特定的顺序或大小排列。
STATA是一款功能强大的统计分析软件,它提供了丰富的工具和函数,可以进行分类数据和等级数据的统计分析。
本文将介绍如何使用STATA软件进行分类与等级资料的统计分析。
一、分类数据的统计分析分类数据的统计分析主要包括频数和比例统计、列联表分析和卡方检验等。
下面以一个简单的示例说明如何用STATA软件进行分类数据的分析。
假设我们有一份调查问卷数据,其中包含了100个受访者的性别(男、女)和喜好的水果(苹果、香蕉、橙子)信息。
我们想要了解男女受访者喜好的水果分布是否存在差异。
首先,我们需要将数据导入STATA软件。
在STATA命令窗口中输入以下命令:```use "文件路径/文件名.dta"```接着,我们可以使用`tab`命令来计算频数和比例。
输入以下命令:```tab sex fruit```这样,STATA会输出一个包含性别和水果的频数表和比例表。
通过观察这些表,我们可以得到男女受访者对不同水果的喜好情况。
如果我们还想了解性别和喜好水果的关系是否显著,可以进行列联表分析和卡方检验。
输入以下命令:```tab sex fruit, chi2```STATA会输出一个包含列联表和卡方检验结果的表格。
通过观察卡方检验的p值,我们可以判断性别和喜好水果之间是否存在显著差异。
二、等级数据的统计分析等级数据的统计分析主要包括描述统计分析和推断统计分析。
下面以一个实例介绍如何使用STATA软件进行等级数据的分析。
假设我们有一份学生数学考试成绩数据,其中包含了100个学生的分数信息。
我们想要了解这些学生成绩的分布情况。
首先,我们需要将数据导入STATA软件。

分类变量资料的统计分析分类变量是一种在研究或分析中常见的类型数据,它描述了被观察个体或对象之间的不同特征,可以将其分为不同的类别或组。
在统计学中,对分类变量的分析可以帮助我们了解不同类别的分布情况、比较不同类别之间的差异、探索不同类别与其他变量之间的关系等。
本文将介绍分类变量资料统计分析的一些常用方法。
首先,我们可以通过计算频数和频率来描述分类变量的分布情况。
频数是指每个类别中观察到的个体或对象的数量,频率则是频数除以总数后的比例。
通过绘制条形图或饼图,可以直观地展示分类变量不同类别的频数或频率分布,帮助我们了解变量的整体情况。
其次,我们可以对不同类别之间的差异进行比较。
其中一种常用的方法是卡方检验,它用于检验两个或多个分类变量之间是否存在显著性差异。
卡方检验的原理是通过比较观察到的频数与期望频数之间的差异来判断差异是否显著。
比如,我们可以用卡方检验来确定两个不同群体之间的分布是否存在显著差异。
此外,分类变量的统计分析还可以探索其与其他变量之间的关系。
当我们有一个分类变量和一个或多个连续变量时,可以使用方差分析(ANOVA)来检验分类变量对连续变量的影响是否显著。
方差分析通过比较不同类别下的连续变量的均值来判断差异是否显著。
另外,我们还可以使用列联表分析来研究两个或多个分类变量之间的关联关系,例如,我们可以通过计算卡方值来确定两个分类变量之间的关联程度。
此外,还有一些其他常用的分类变量分析方法。
比如,在研究中,我们经常遇到多个分类变量之间的关联关系,可以使用多项Logistic回归模型来分析这些多分类变量之间的依赖关系。
另外,如果我们想预测或分类新的个体或对象所属的类别,可以使用分类树或逻辑回归等方法进行建模和预测。
综上所述,分类变量的统计分析是一种有价值的工具,可以帮助我们理解和揭示数据背后的模式和关联关系。
通过对分类变量的分布和差异进行描述分析,我们可以更好地理解数据,并从中提取有用的信息。

有序多分类数据的统计分析有序多分类数据是指数据集中的变量具有多个有序类别的情况。
在统计分析中,对于这种类型的数据,我们需要采取相应的方法来进行分析和解释。
本文将介绍有序多分类数据的统计分析方法,包括描述性统计、推断统计和可视化分析等内容,帮助读者更好地理解和处理这类数据。
一、描述性统计分析描述性统计是对数据进行总体描述和概括的统计方法,可以帮助我们了解数据的基本特征。
对于有序多分类数据,我们可以通过计算频数、频率、众数、中位数、四分位数等指标来描述数据的分布情况。
此外,还可以计算累积频数和累积频率,以便更直观地展示数据的分布情况。
例如,假设我们有一组有序多分类数据,包括“低”、“中”、“高”三个类别,我们可以计算每个类别的频数和频率,然后绘制频数分布直方图或频率分布柱状图,以便直观地展示数据的分布情况。
二、推断统计分析推断统计是通过样本数据对总体进行推断的统计方法,可以帮助我们从样本数据中获取总体的信息。
对于有序多分类数据,我们可以进行卡方检验、秩和检验等方法来检验不同类别之间的关联性和差异性。
以卡方检验为例,假设我们想要检验两个有序多分类变量之间是否存在相关性,可以利用卡方检验来进行检验。
首先建立原假设和备择假设,然后计算卡方统计量,并根据显著性水平进行假设检验,从而判断两个变量之间是否存在显著相关性。
三、可视化分析可视化分析是通过图表、图形等可视化手段来展示数据的分布和关系,可以帮助我们更直观地理解数据。
对于有序多分类数据,我们可以利用条形图、箱线图、热力图等图表来展示数据的分布和关系。
例如,我们可以通过绘制箱线图来比较不同类别之间的中位数和四分位数,从而直观地展示数据的差异性。
此外,还可以利用热力图来展示不同类别之间的相关性,帮助我们发现变量之间的潜在关系。
综上所述,有序多分类数据的统计分析涉及描述性统计、推断统计和可视化分析等多个方面,通过综合运用这些方法,可以更全面地理解和解释这类数据。