应用重力模型进行交通分布的详细步骤
- 格式:doc
- 大小:1.86 MB
- 文档页数:8

无约束重力模式根据无约束重力模型公式:γβαij jit UTkjiX ∙=),(两边取对数得Ln(Tij)=lnk+αlnGi+βlnAj-γlntijTij─交通区i到交通区j的出行分布量:Gi─交通区i的出行产生总量:Aj─交通区j的出行吸引总量:K,α,β,γ─模型参数;公式转换为:Y=K+αx1+βx2-γx3参数的确定是通过拟合现状OD调查资料,用最小二乘法确定。
现有一规划区域,共划分为5个交通区,经调查其现状OD分布见表1,各交通区间的出行时间见表2,通过对各交通区的交通生成进行预测,得到各交通区未来交通产生、吸引量见表3,分析计算得到未来各交通区间的交通出行时间见表4。
表A1(现状OD分布)表B2(各交通区间的出行时间)表C2(各交通区未来交通产生,吸引量)表D1(未来各交通区间的交通出行时间)解:选用出行时间的函数形式,将无约束重力模型变为:Ln(Tij)=lnk+αlnGi+βlnAj-γlntij格式LN(number):number是用于计算其自然对数的正实数。
Ln是exp函数的反函数计算步骤:打开数据文件,在定下的单元格中输入公式 Ln(number),按下number之后选择要计算的数字,然后按下Entre键后公式将返回计算结果如下表:Y=K+αx1+βx2-γx3此方程为线性回归方程,k, α,β,γ是用最小二乘法标定。
计算步骤:[c¹·c]¯¹c¹·y=β^c=(1 x):将C=( 1 x)转置的步骤是:按矩阵c选择行列数,在单元格中输入:=TRANSPOSE(B2:E26),然后按Cntrl+Shift+Enter组合键最后得出的结果是如下表(C¹):下一步的步骤是[C¹.c];依据C4×25·C25×4=C4×4 选择单元格区域的行列数,在单元格区域中输入为=MMULT(A28:Y31,B2:E26),然后然后按Cntrl+Shift+Enter组合键最后得出的结果是如下表[C¹.c]:下一步是算[C¹.c] ¯¹;先选择单元格区域的行列数,在单元格区域中输入:=MINVERSE(B34:E37)然后按Cntrl+Shift+Enter组合键。




9、简述交通分布的重力模型的基本原理及其计算过程:重力分布模型仿效牛顿万有引力定律,认为交通小区间的交通量与交通小区各自的交通发生量和吸引量成广义的正比关系,而与交通小区间的交通阻抗(距离、时间、费用)成广义的反比。
重力分布模型是一个非常有用的交通分布模型,它适用于运输网络出现较大变化时的未来交通出行分布预测。
但该模型应用时,需要标定模型的参数。
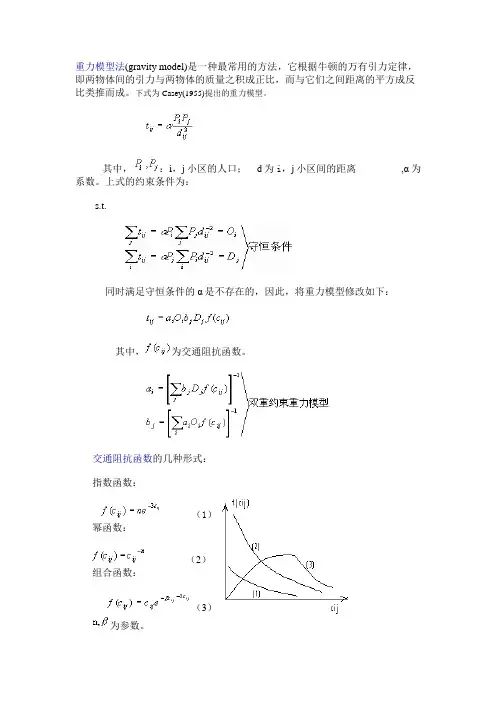
重力模型(gravity model)是一种最常用的方法,它根据牛顿的万有引力定律,即两物体间的引力与两物体的质量之积成正比,而与它们之间距离的平方成反比类推而成。
重力模型考虑了两交通小区间的吸引强度与吸引阻力,认为两交通小区之间的出行吸引与两交通小区的出行发生、吸引量成正比,与交通小区间的交通阻抗成反比。
重力模型直观上容易理解,预测考虑的因素比较全面,尤其是强调了局部与整体之间的相互作用,比较切合实际,即没有完整的O-D表,也能用O-D矩阵(只要能标定a)预测。
重力模型的一个致命缺点是短程O-D分布偏大,尤其是区内出行,在预测时必须给予注意。
下式为Casey(1955)提出的重力模型。
其中,:i,j小区的人口; d为i,j小区间的距离,α为系数。
上式的约束条件为:s.t.同时满足守恒条件的α是不存在的,因此,将重力模型修改如下:其中,为交通阻抗函数。
交通阻抗函数的几种形式:指数函数:(1)幂函数:(2)组合函数:(3)为参数。
单约束型B.P.R.模型其中,调整系数。
发生侧得到保证,即:以下以幂指数交通阻抗函数为例介绍其计算方法:第1步令m=0,m为计算次数。
第2步给出n(可以用最小二乘法求出)。
第3步令第4步求出第5步收敛判定。
若下式满足,则结束计算;反之,令m+1=m,返回第2步重复计算。
,作业:按上次作业给出的现状OD表和将来生成、发生与吸引交通量,利用下式重力模型和弗拉塔算法,求出将来OD表。
收敛标准。
重力模型:其中,,,。
读者也可以利用以前给出的现状分布交通量和表4-1示现状行驶时间,估计出这3个参数。

重力模型法(gravity model)是一种最常用的方法,它根据牛顿的万有引力定律,即两物体间的引力与两物体的质量之积成正比,而与它们之间距离的平方成反比类推而成。
下式为Casey(1955)提出的重力模型。
其中,:i,j小区的人口; d为i,j小区间的距离,α为系数。
上式的约束条件为:s.t.同时满足守恒条件的α是不存在的,因此,将重力模型修改如下:其中,为交通阻抗函数。
交通阻抗函数的几种形式:指数函数:(1)幂函数:(2)组合函数:(3)为参数。
单约束型B.P.R.模型其中,调整系数。
发生侧得到保证,即:以下以幂指数交通阻抗函数为例介绍其计算方法:第1步令m=0,m为计算次数。
第2步给出n(可以用最小二乘法求出)。
第3步令第4步求出第5步收敛判定。
若下式满足,则结束计算;反之,令m+1=m,返回第2步重复计算。
,作业:按上次作业给出的现状OD表和将来生成、发生与吸引交通量,利用下式重力模型和弗拉塔算法,求出将来OD表。
收敛标准。
重力模型:其中,,,。
读者也可以利用以前给出的现状分布交通量和表4-1示现状行驶时间,估计出这3个参数。
表4-1 现状行驶时间表4-2将来行驶时间解:利用重力模型求解分布交通量如下:同理,可以计算出其它各交通小区之间的交通量如下表所示。
重力模型的优点:a.直观上容易理解;b.能考虑路网的变化和土地利用对人们的出行产生的影响;c.特定交通小区之间的OD交通量为零时,也能预测;d.能比较敏感地反映交通小区之间行驶时间变化的情况。
重力模型的缺点:a.重力模型仅仅是将物理法则简单直观上容易理解;b.能考虑路网的变化和土地利用对地应用到社会现象,尽管有类似性,需要更加贴合人们出行的方法;c.一般,人们的出行距离分布在全区域并非为定值,而重力模型将其视为定值;d.交通小区之间的行驶时间因交通方式和时间段的不同而异,而重力模型使用了同一时间;e.求内内交通量时的行驶时间难以给出;f.交通小区之间的距离小时,有夸大预测的可能性;g.利用重力模型计算出的分布交通量必须借助于其它方法进行收敛计算。
TransCAD 运用重力模型进行预测详细步骤一、将CAD 创建的DXF 文件导入到TransCAD用TransCAD 软件打开.dxf 文件会弹出窗口,按照下图所示操作即可,Road 层和Area 层需要分两次导入。
导入路网层:点击OK ,命名为Road 并保存(Save )。
导入小区层:点击点击OK ,命名为Area 并保存(Save )。
Road 层和Area 层叠加:右键选择Layers 重命名图层:点击点击检查路段连接性:tools-map editing-check line layerconnectivity无问题,则显示为黑色点儿,继续下一步;有问题则显示为其他颜色点儿,需要进行调整。
二、分别给Road 层和Area 层建立相应字段并填充数据切换到Road 层,点击Dataview ,选择Modify Table ,弹出如下窗口,建立luming 、danxiangchedaoshu 、daoludengji 、danchedaonengli 、AB-T 、BA-T 、AB-V 、BA-V 、AB-C 、BA-C 和reallength字段。
切换到Endpoints 层,点击Dataview ,选择Modify Table ,弹出如下窗口,建立xiaoqu字段。
点击填充Road层数据表:其中luming 、danxiangchedaoshu 、daoludengji 根据调查结果进行填充,本例快速路AB-V 和BA-V 取60km/h ,主干路AB-V 和BA-V 取40km/h ,次干路AB-V 和BA-V 取30km/h ,支路AB-V 和BA-V 取20km/h ,不同等级道路单车道通行能力视隔离情况(机非隔离、中央隔离)进行取值,本例中快速路取值1100pcu/h ;主干路无隔离,则取950pcu/h ,有一种隔离措施,则取1000pcu/h ,有两种隔离措施,则取1050pcu/h ;次干路则依次取值为800pcu/h 、850pcu/h 、900pcu/h ;支路无机非隔离带则取450pcu/h ,有机非隔离带则取650pcu/h 。

论述交通量预测的增长率法和重力模型法0、引言所谓的交通量分布就是区与区之间的交通流,现状的区与区之间的交通分布已经从OD表中体现出来了。
交通量分布预算的目的就是根据现状OD分布量及各区因经济增长、土地开发等形成的交通量增长来推算各区之间将来的交通分布。
交通量预测主要有增长率法和重力模型法两种方法。
1、增长率法预测分布交通量增长率法是从已知的现有OD调查表和发生、吸引交通量的增长率求出OD 分布交通量的近似值,其次对、就、进行收敛计算,从而求得将来的分布交通量。
增长率法包括平均增长率法、底特律法和弗雷特法。
1.1平均增长率法1.1.1平均增长率法计算步骤①根据计算公式计算将来出行量式中:—区到区的将来出行量;—区到区的现在出行量;—区出行发生的增长系数;—区出行吸引的增长系数②检验吸引量和发生量是否与推算的交通量相符合,是否满足(为判定值),如符合计算完成;如不符合需要在第一轮的基础上重新计算增长系数,并重复步骤①,直到满足上述要求为止。
1.1.2平均增长率法算例【例1】已知1、2、3区的出行、增长系数及现状分布,如表2.1-1所示,求将来的出行分布。
(取)表1.1-1 出行、增长系数及现状分布解:求间的交通量于是有,,,,,,,,得到第一轮计算结果,如表1.1-2所示。
表1.1-2 第一轮计算结果因第一轮计算结果中新的调整系数不能满足的要求,因此需要进行第二轮计算,直到满足要求为止。
本例共需要进行四轮计算,才可得到最终结果。
1.2底特律法此方法假定区到区间的交通量同和成比例增加。
1.2.1底特律法计算步骤①根据计算公式计算将来出行量式中:其中—未来发生量合计;—未来吸引量合计②检验吸引量和发生量是否与推算的交通量相符合,是否满足(为判定值),如符合计算完成;如不符合需要在第一轮的基础上重新计算增长系数,并重复步骤①,直到满足上述要求为止。
1.3弗雷特法该方法假设,小区之间OD交通量的增长系数不仅与小区的发生增长系数和小区的吸引增长系数有关,还与整个规划区域的其他交通小区的增长系数有关。


交通与汽车工程学院实验报告课程名称: 交通运输系统规划课程代码: 6011029 年级/专业/班学生姓名:学号:实验总成绩: 任课教师:开课学院: 交通与汽车工程学院实验中心名称: 汽车交通实验中心西华大学实验报告开课学院及实验室:交通与汽车工程学院实验时间:2013年12月19日2、实验设备、仪器及材料3、实验内容3.1 一般实验(非上机实验):3.2 上机实验:,程序调试过程中出现的问题及解决方法3.2.4 程序运行的结果注解:理工科实验需记录实验过程中的数据、图表、计算、现象观察等,实验过程中出现的问题;其它如在计算机上进行的编程、仿真性或模拟性实验需记录程序核心代码以及程序在调式过程中出现的问题及解决方法;记录程序执行的结果。
4、实验总结4.1实验结果分析及问题讨论4.2实验总结心得体会注解:实验总结的内容根据不同学科和类型实验要求不一样,一般理工科类的实验需要对实验结果进行分析,并且对实验过程中问题进行讨论;在计算机上进行的编程、仿真性或模拟性实验需要对上机实践结果进行分析,上机的心得体会及改进意见。
其它实验应总结实验过程写出心得体会及改进意见。
说明:各门实验课程实验报告的格式及内容要求,请按照实验指导书的要求手工书写。
实验一用简单引力模型预测运输需求分布一、实验目的和任务能够运用简单引力模型预测未来年交通运输需求分布。
二、实验仪器、设备及材料计算机三、实验内容表1是只有三个小区的现状OD矩阵,表2是未来目标年各交通小区的出行产生量、吸引量,表3是交通小区之间的阻抗,用简单引力模型预测未来年运输需求分布矩阵。
表3 小区间交通阻抗(1)根据已知,把数据输入到Excel中,如图1所示:图1 (2)用简单引力模型:qij = k OiDj/ Rijγ1-1(3)两边取对数,得:log qij – log OiDj= log k –γlog Rij1-2(4)参数标定:令Y = log q ij– log O i D j , a = log k , b = - γ, X = log R ij(5)公式1-2可以转换成:Y = a + b X 1-3 (6)公式1-3为二元一次线性回归方程,a,b为待定系数。
重庆交通大学学生实验报告实验课程名称专业综合实验Ⅰ开课实验室交通运输工程实验教学中心学院交通运输年级2010 专业班交规一班学生姓名王菊学号********开课时间2013 至2014 学年第一学期实验结果分析(含数据、图表整理): 吸引发生量=700(1)建立的交通小区和路网如图所示:图1 建立的交通小区与路网(2)设置的小区参数与路网参数如图所示:图2 交通小区及路网参数表图3 交通小区参数图4 各节点的属性(3)单击【create】建立路网文件后, 选择multiple paths计算小区之间的最短路矩阵, 即阻抗, 如下图所示:图5 最短路矩阵(4)由于此处交通发生量与吸引量均为700, 因此无需再平衡, 交通生成量即为700。
由于上面得到的最短路的编号为点的ID, 需要把它变成小区的ID, 单击右键, 选择【Indices】, 为最短路矩阵建立一个小区编号, 如图所示:图6 最短路矩阵(5)单击【gravity application】,应用重力模型进行交通分布, 设置各参数如图:图7 重力模型各参数得到的各小区交通分布如下图:图8 小区间OD矩阵(6)选择【tools】下的【desire line】, 各小区交通分布图如下:图9 期望线图(7)为了确保计算结果的准确性, 因此采用行和与列和校核OD计算结果。
如图:图10 各选项值图11 行和与列和校核结果图12 各点间OD(8)建立交通流分配的路网文件, 单击【traffic assignment】,设置各选项如图:图13 各选项值得到各路段的交通流量, 如图所示:图14 各路段交通流量表单击【planning utilities】下的【create flow map】生成各路段流量图, 如下:图15 路段流量图(9)单击【intersection diagram】得到各交叉口的流量图, 如下:图16 交叉口1流量图17 交叉口2流量图18 交叉口3流量图19 交叉口4流量图20 交叉口5流量图21 交叉口6流量实验收获、心得及建议:通过应用transcad软件进行交通需求预测, 我对交通预测的四个基本阶段有了更深的理解, 在这个过程中, 必须设置好每一步的参数, 才能进行下一步操作, 最后才能得出正确的实验结果。
应用重力模型进行交通分布的详细步骤
第一步:求阻抗矩阵Rij(Impedance Matrix)
交通阻抗可表示为:出行距离和行程时间的长短,以及出行费用的大小等。
为真实地反映交通阻抗,依托工程道路网规划采用通常使用的平均行程时间表示。
小区之间的阻抗——平均行程时间越小表示小区之间阻抗越小,越大表示小区之间阻抗越大,因此以平均行程时间为道路权值求各小区之间的最短路径(Shortest Path),其值即为小区之间的阻抗R ij。
1、数据准备
(1)创建路网
图1表示的是TransCAD创建路网的界面。
(2)做选择集。
在Endpoints层,于dataview中选择质心点,将其作为一个选择集。
(3)各路段平均行程时间(Travel time)
其中,平均行程时间=Length/平均车速*60
2、操作过程
Networks/Paths—Multiple paths调出其对话框如图2所示。
3、运行结果(即为阻抗矩阵),如图3所示。
第二步:重力模型标定(校准)(Gravity Mode Calibration)1、数据准备
(1)基础OD矩阵。
(2)阻抗矩阵(Shortest Paths),如图3所示。
重力模型标定(校准)(Gravity Mode Calibration)数据准备:
基年OD矩阵的索引(质心层质心ID)与最短路径矩阵的索引(路网节点层质心ID)不匹配,并且因为下面将在路网节点层上操作,因此必须使基年OD索引与最短路径矩阵的索引相一致,以使两表数据相对应(转换为“质心ID”)。
操作方法:按其对话框4示意操作。
2、操作过程
按对话框(如图5)操作即可。
3、运行结果
(1)标定参数结果(这里选用伽马函数):a=2.6288,b=0.2361,c=0.0,如图6所示,不过大看show report 里面参数更准确。
(2)K-Factor Flow:如图7所示。
第三步:创建综合阻抗因子f (Rij) (Synthetic Friction Factors)
1、数据准备
(1)创建空矩阵“Friction Factor shell”;
(2)已标定的a、b、c值;
(3)阻抗(最短路径)矩阵,如图8所示。
2、操作过程
详见图9对话框所示。
3、运行结果
如图10所示。
第四步:应用重力模型(得2010年OD分布矩阵)
1、数据准备
(1)已标定的a,b,c值;
(2)综合阻抗因子矩阵;
(3)阻抗(最短路径)矩阵。
(4)K-Factor矩阵
因为采用重力模型分布时要用到规划年交通出行量,所以必须在小区层上操作,因此综合阻抗因子矩阵、阻抗(最短路径)矩阵、K-Factor矩阵(索引值与2010PCU_P、
2010PCU_A的ID相匹配)。
即要将这三个矩阵的ID转换回来。
ID转换后的数据见图11。
2、操作过程
详见图12所示。
3、运行结果
规划年(2010年)OD矩阵(ID转换为实际小区号),详见图13。
操作结束,希望对大家有用!老拳。