Informatica学习笔记
- 格式:doc
- 大小:57.50 KB
- 文档页数:14
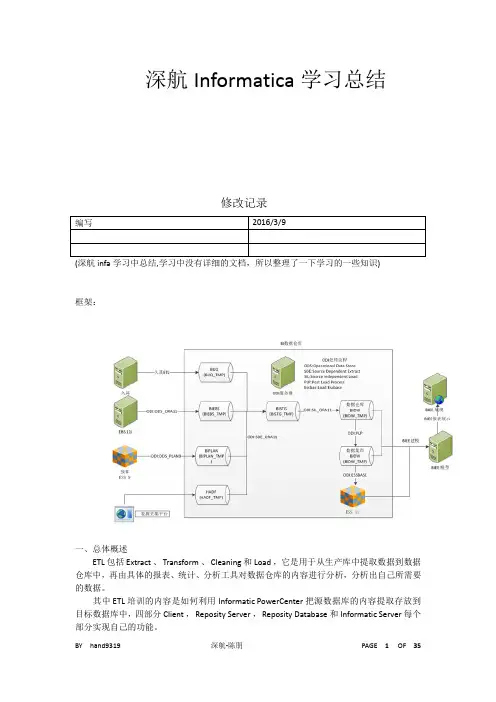
深航Informatica学习总结修改记录框架:一、总体概述ETL 包括 Extract 、 Transform 、 Cleaning 和 Load ,它是用于从生产库中提取数据到数据仓库中,再由具体的报表、统计、分析工具对数据仓库的内容进行分析,分析出自己所需要的数据。
其中 ETL 培训的内容是如何利用 Informatic PowerCenter 把源数据库的内容提取存放到目标数据库中,四部分 Client , Reposity Server , Reposity Database 和 Informatic Server 每个部分实现自己的功能。
二、系统体系结构此部分介绍了 Informatic ETL 工具包括的主要内容。
1.ClientInformatic Client 主要有五个部分。
Client 可以和 Reposity 分离,通过 TCP/IP 连接,连接到远程的 Reposity Server 。
2. Reposity Manager主要用于进行一个 Reposity 库的管理,当用户使用 Client 工具登录一个 Reposity 服务器之后,进行文件夹权限的创建,用户权限、密码的管理等。
3. Designer主要是进行数据抽取的转换工具的设计,主要是 mapping 的设计、设计源数据库的结构,目标数据库的结构,然后设计把源数据导入到目标数据库中,所需要进行的转换操作( Transformation )。
同一个 Reposity 的 folder 之间可以建立 shortcut 方式,多个 reposity 的 folder 之间只能做拷贝。
4. Workflow Manager主要用于流程任务( workflow Task )的设计。
进行任务流程的设计、每一个 Tast 针对一个 Session ,一个 session 针对一个 mapping ,其中 workflow 中的 Folder 和 Designer 中的 folder 相对应的关系。

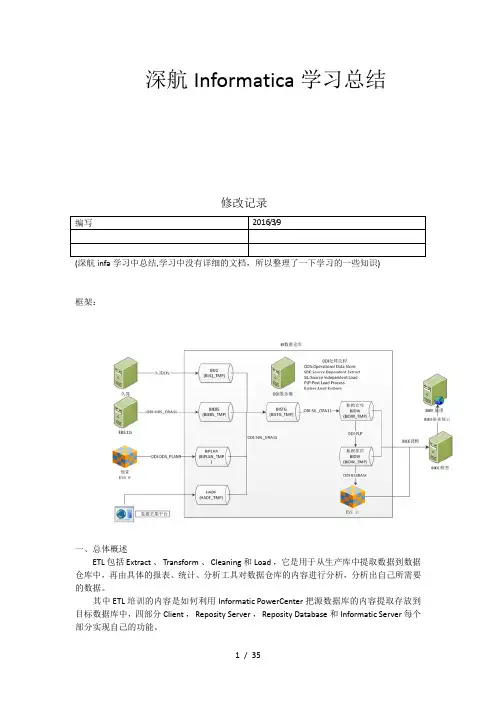
深航Informatica学习总结修改记录编写2016/3/9框架:一、总体概述ETL 包括 Extract 、 Transform 、 Cleaning 和 Load ,它是用于从生产库中提取数据到数据仓库中,再由具体的报表、统计、分析工具对数据仓库的内容进行分析,分析出自己所需要的数据。
其中 ETL 培训的内容是如何利用 Informatic PowerCenter 把源数据库的内容提取存放到目标数据库中,四部分 Client , Reposity Server , Reposity Database 和 Informatic Server 每个部分实现自己的功能。
二、系统体系结构此部分介绍了 Informatic ETL 工具包括的主要内容。
1.ClientInformatic Client 主要有五个部分。
Client 可以和 Reposity 分离,通过 TCP/IP 连接,连接到远程的 Reposity Server 。
2. Reposity Manager主要用于进行一个 Reposity 库的管理,当用户使用 Client 工具登录一个 Reposity 服务器之后,进行文件夹权限的创建,用户权限、密码的管理等。
3. Designer主要是进行数据抽取的转换工具的设计,主要是 mapping 的设计、设计源数据库的结构,目标数据库的结构,然后设计把源数据导入到目标数据库中,所需要进行的转换操作( Transformation )。
同一个 Reposity 的 folder 之间可以建立 shortcut 方式,多个 reposity 的 folder 之间只能做拷贝。
4. Workflow Manager主要用于流程任务( workflow Task )的设计。
进行任务流程的设计、每一个 Tast 针对一个 Session ,一个 session 针对一个 mapping ,其中 workflow 中的 Folder 和 Designer 中的 folder 相对应的关系。

informatica 学习日记1. INFORMATICA CLIENT的使用1.1 Repository Manager 的使用1.1.1 创建Repository。
前提:a. 在ODBC数据源管理器中新建一个数据源连接至你要创建Repository的数据库(例:jzjxdev)b. 要在你要连接的数据库中新建一个用户(例:name: ETL password: ETL)现在你可以创建一个Repository了。
选择Repository – Create Repository,输入Repository Name(例:JZJX),DatabaseUsername(例:etl),Database Password(例:etl),ODBC Data Source(例:jzjxdev),Native Connect String(数据库所在ip例:141.20.52.108)1.1.2 添加Repository。
通过这一步你可以添加别人已经建好的Repository。
选择Repository – Add Repository,输入Repository Name(例:JZJX),Username(例:etl),点击ok就可以看到名为JZJX的Repository在左边的浏览器中,但是此时还看不到它的内容,要看到它的内容或者对它进行操作必须先连接它。
1.1.3 添加Folder选择Folder – Create,输入文件夹名称即可。
1.2 Designer 的使用首先连接Repository,可以看到该Repository在Repository Manager中创建的文件夹。
1.2.1 SourcesSources文件夹下的表是抽取的来源表。
导入方法:选择Tools菜单下的Source Analyzer,然后选择Sources菜单下的Importfrom database,连接想要连接的数据库,连接上后选择你要抽取的表点击ok你所选择的表就会出现在Sources文件夹下。

、中与的理解:类似于局域网,就是局域网中的节点或者计算机。
应与在数据库中存储在不同的中,此处指操作的内容。
、中与:工作引擎;:管理引擎,管理;与工作流程为:客户端发请求到,调用完成各种操作,其中,工作过程中会访问进行元数据信息、规则等访问,并将,的结果状态等存储到。
一般一个对应一个,当一个一个要对应多个时,涉及,将多个放在一个下,一个对应一个。
、与端配置一般配置时,尽可能选择,的性能高于,但是的兼容性和适用性高。
端:用于过程中实际存取读写数据;端:用于导入表,即元数据。
、中数据处理方式为并行处理,即管道式处理。
、分区分区使处理方式由单线程变成多线程,一个连接变成多个连接。
分区后,当使用汇总、关联等组件时可自动保证数据结果的正确性。
在汇总、关联之前,若数据已进行排序,且组件中已排序属性已勾选,则数据为流式通过;否则,需数据全量到达然后进行处理。
、集群:既可支持单机,也可建立集群环境。
而且,集群环境可以异构,即不限定等;在集群环境中,任务可通过以下三种方式分发:第一种:轮询;第二种:动态控制,需在文件中进行配置;第三种:建立与的映射表(,然后在文件中进行配置该映射表?)。
无论采取哪种方式,都可以保证的执行顺序,因为的执行顺序是由中表(表名貌似是)存储。
、增值服务组件:,可自动接管坏点启用方式为:运行时以方式运行;要求:需在磁盘中建立共享存储,并配置主从节点。
、规则文档映射中可导出成文件,并包含各种。
使用方式:在客户端组件中,选择要导出的,右键菜单。
、批量开发利用组件,可实现批量过程开发,尤其适用于平推。
(具体转化方式不详)、增量采集主要适用于可做增量的,如。
先,然后。
(具体抓取方式需查询相关文档)、下推优化:指导方针:平衡与的负载。
原理:将下推部分转化成,在中实现。
可实现下推和下推。
使用方法:中菜单下有选项。
、数据校验插件可创建,代替手工校验。
、前瞻监控、调优:、减少、减少过程中数据量,尽早、避免不必要排序,、中符号比表达式性能高中有变量端口,可生成中间量,重复使用中尽量少嵌套,可用高级函数代替、尽量避免类型转换、、的统计信息除了在中,中也有、中各参数:占用的全部内存(内存块个数):内存块大小(中所有的数据量的整数倍):当源是文件时,文件记录长度:最大内存块数、调优:尽量关闭日志;目标加载前利用删除索引约束,加载完成后利用重建索引约束;提交间隔可稍微设置大一些;关闭统计信息收集;设置各种参数;数据装载方式尽量选择、文件与文件的区别:具体参见各组件使用的文件夹配置名称,如组件使用文件夹,组件使用文件夹。


informaticapowercenter学习笔记(LookUp使⽤)LOOKUP TRANSFORMATION的使⽤点评:LOOKUP基本⽤法不熟的话请参考下附属信息。
⽤法感受:1 LOOKUP的作⽤跟我们以前在EXCEL的函数功能类似,就是隔表取值。
优点就是⽤ETL⼯具可以设置CACHE,⼤量的数据也可以实现这个功能。
数据量⼤的话要设置CACHE ENABLE并调⾼CACHE SIZE的值。
2 LOOKUP 有CONNECTED 和UNCONNECTED的两种,根据需要⽽⽤,如果很多字段要取对应的这个值的话,就⽤UNCONNECTED.在具体项⽬中要⼩⼼LOOKUP来处理维度列的情况,我⽬前项⽬中就发现,在LOOKUP中根据⼏列来取出主键,结果数据并不完全能唯⼀区别,最后要做数据清理或引⼊代理键。
3 关于缓慢变化维处理,⽤LOOKUP加UPDATESTRATERY组件就可实现缓慢变化维的更新或插⼊,这是数据仓库项⽬中处理缓慢变化维⽐较经典的⽤法,我认为。
顺带粘贴些关于LOOKUP的参考信息,了解的,请忽略以下信息,呵呵:Lookup概要描述 获得⼀个关联的值。
例如:源⾥包含employee ID,但你还需要employee name。
⽤于计算的植。
例如:只是汇率或者个⼈所得税之类的固定数值,不是计算得出来的数据。
Update slowly changing dimension tables。
主要是根据条件查出原表,若查出了,就把⾃⼰添加的标志位设为真,否则就设置为假。
Connected or unconnected Connected 和 unconnected 的transformations的输⼊和输出是不同的,不同点如表2列出的。
表2Connected Lookup Unconnected Lookup从 pipeline获得输⼊。
从另⼀个transformation的:LKP的表达式获得输⼊。

Informatica总结rmatica中关键词:(一)源表:即源表来自于数据库的表,例如在job100下面的源表是一些PRPCmain、CD码表、ODS表等一些表主要是来自于核心生产库中的表;job200下面的源表是些CD、ODS、MID表;job300下面的源表主要是CD、ODS、MID、olap表。
(二)元数据:元数据就是来自于数据库的基本表,起初的表(三)目标表:在执行完一个job后最终将数据存储在的表即目标表。
(四)映射:简单来讲将源表的数据导入目标表的过程就是一个映射。
(五)工作集:在一个job中执行的转化其中的每一个过程就相当于一个工作集。
(六)工作流:相当于在kettle中执行一个job的过程。
2.designer界面主要是定义源表和目标表生成映射的过程。
3.workflow界面编辑工作集执行工作流的过程。
4.monitor界面主要是为了执行完工作流之后查看工作日志的过程。
关于数据库方面(1).在Informatica中创建源和目标表的时候:在designer中创建源:来自于核心生产库在本地的配置文件中进行配置创建目标表:来自MIS生产库或者是测试库在本地的配置文件中进行配置根据这个路径E:\oracle\product\10.2.0\db_1\network\admin\tnsnames.ora找出.ora文件(2)创建工作流和工作集的时候:在workflow中,在进行启动的时候:在进行刷数参数配置在C:\Windows\System32\drivers\etc添加88.22.34.188 zj-misetl路径:/home/info_param data_param_test.txt文件是在windows32相对应的文件夹的下面在启动工作流的时候:配置数据库的文件不在本地文件中而是在Linux系统下面所以需要和Linux系统相连,通过xftp连接Linux系统,找到配置数据库的时候需要的文件。
Informatica PowerCenter8.1学习笔记一、软件的安装及配置安装前的注意事项:首先要确定密匙文件:Licnese.key内写明的授权日期范围及授权内容,如已过期,则将系统时间调整至未过期之前的时间,否则安装过程中极易出现问题!1、安装篇在安装之前我们先来进行一些准备工作,首先如果需要连接MSSQL2000,则应该先升级SP4补丁。
首先进入安装文件夹点击,然后会打开如下界面:(图1-1)点击要安装的组件。
(1)安装服务端组件首先点击,等待安装准备工作完成后自动跳转至如下界面:(图1-2)点击,至下一步:(图1-3)在这里需选择密匙文件,点击后在出现的选择界面内:(图1-4)选中密匙文件点击即可。
然后会回到图1-3 的界面,点击进行下一步。
可能出现错误:(图1-5)这个错误是由于密匙文件过期造成的,只需将系统时间调整至过期日期之前即可。
密匙文件验证完毕后会出现如下界面:(图1-6)点击即可进入下一步。
(图1-7)如果想要完全安装,则直接点击即可,如需定制安装,刚选中即可,这里我们只需安装PowerCenterServices,对于完全安装就不再详述。
点击进行跳转:(图1-8)在这里我们只选Services组件,然后点击进入下一步:(图1-9)在这里我们可以选择安装还是升级,我们选择第一项,点击进入下一步:(图1-10)选择安装目录,然后点击(图1-11)在图1-11 中所示的界面内检查安装信息是否正确,如正确点击安装完成后进入如下域设定界面:(图1-12)第一项为建立新的域,第二项为导入现有域,可根据实际情况进行选择,这里我们只介绍新建域的操作。
选中第一项后点击,会出现配置服务器数据库信息界面:(图1-13)几个需要填写的内容分别为:Database type(数据库类型)Database URL(数据库连接URL字符串)Database userID(数据库登陆用户名)Database user password(数据库登陆密码)Database service name(数据库名)在填写完毕后点击进行链接测试,如通过则会出现:(图1-14)然后点击,进入服务器信息配置界面:(图1-15)几个需要填写的内容分别为:Domain name(域名称)Domain host name(映射地址名称)Node name(节点名称)Domain port no(域对应端口号) Domain user name(管理员帐号) Domain password(管理员密码)Confirm password(确认密码)Create Repository Service点击会出现(图1-16)可以配置Minimum port no(最小端口号)及Maximum port no(最大端口号),配置完毕后点击开始进行域的创建。


控件名称Repository Manager 资料库Designer 设计器Workflow Manager 物理设计Workflow Monitor 监控Repository Manager—-资料库:informatica的知识存储。
Designer 设计器:设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL映射。
Workflow Manager--物理设计:合理地实现复杂的ETL工作流,基于时间、事件的作业调度。
Workflow Monitor——监控:监控Workflow和Session运行情况,生成日志和报告。
注:查看帮助Fn+F1Repository Manager添加文件夹在Repository Manager 文件夹选项添加新建完成一个文件夹,在Designer中相应的文件夹会有业务组件、源、目标、多维数据集、维度、转换、Mapplet、映射、用户自定义的函数几个内容。
导入对象在Repository Manager 中导入XML对象选择存储库—导入对象如下:选择导入的XML文件选择导入对象。
选择导入目标文件夹.如有冲突,会提示解决. 开始导入。
导入完成。
Designer添加源在PowerCenter Designer添加源选择要添加的文件夹点击,这个为源设计的一个控件。
菜单栏将如下:再选择源,然后可以选择导入源,或者创建源. 创建源在菜单的源,选择创建.输入源的名称和数据库类型创建,生产如下:双击刚刚生产的控件,进入编辑表:表为表级信息编辑,列可以添加列信息。
导入数据库源在菜单的源,选择从数据库导入。
输入用户名和密码,连接完成好选择所需要的表。
也可以根据需要搜索所需要的表。
导入源和创建源的比较,导入源表结构都已经生成完成,不需要一个一个字段再输入那么麻烦。
当导入一张已存在的表,如果表存在字段变更,有提示是否替换,重命名等.比较:可以查看表发生了哪些变更。
添加目标在PowerCenter Designer添加目标目标控件,选择目标控件后,菜单栏如下:选择菜单列的目标可以创建目标或者导入目标, 创建目标目标 创建输入目标名并选择数据库类型创建.点击进入编辑目标表,从数据库源导入在菜单的目标,选择从数据库导入。
Informatica总结一、安装过程及其连接1、安装前准备*本机的oracle服务实例为orcl/cognos*将360或其它系统软件的拦截程序退出*Informatica安装前的准备工作及注意事项:创建表空间,用于存放数据库数据create tablespace BI_ETL datafile'C:\oracle\product\10.2.0\oradata\BI\BI_ETL.dbf'size1000M reuse autoextend on next100M;--这里,保存位置,空间大小需要按照实际情况灵活应变. 创建域用户并分配权限,用来管理域create user bi_domain identified by bi_domaindefault tablespace bi_etl temporary tablespacetempprofile default account unlock;grant connect to bi_domain;grant dba to bi_domain;grant resource to bi_domain;grant unlimited tablespace to bi_domain;grant select any table to bi_domain;alter user bi_domain default role all;创建资源用户并分配权限create user bi_resource identified bybi_resourcedefault tablespace bi_etl temporary tablespacetempprofile default account unlock;grant connect to bi_resource;grant dba to bi_resource;grant resource to bi_resource;grant unlimited tablespace to bi_resource;grant select any table to bi_resource;alter user bi_resource default role all;2、安装服务端*打开910HF6_Server_Installer_win32-x86/Server/install.exe 双击安装-->下一步--->修改安装地址-->直到完成-->将informatic 主页地址复制粘贴到IE浏览器地址栏中--回车--继续浏览此网页(不推荐)--用户名(Administrtor)、密码(admin)--登陆*创建存储库服务器:域导航器右边--操作--创建--存储库服务--命名、许可证、节点都选择最下面的--下一步--数据库类型(oracle)、(用户名和密码:准备时新创建的用户名和密码)、数据库服务实例名(orcl/cognos)、代码页选择GB2312-80--选择第二个按钮和其第一个选项--完成---提示可用--将操作模式改为普通(右边编辑--修改)*创建集成服务:域导航器右边--操作--创建--集成服务--命名、许可证、节点都选择最下面的--下一步--存储库服务选择前面新建的、用户名(Administrtor)、密码(admin)数据移动模式选择unicode--完成--代码页改为GB2312-80--确定--提示可用(若禁用--右边启动按钮启动即可)3、安装客户端双击910HF6_Client_Installer_win32-x86/client/install.exe--下一步--改变安装位置--直到完成*启动客户端程序连接服务器:打开客户端PCRM--存储库---配置域--添加按钮--域名(自起)、网关主机:计算机主机名(在计算机属性中粘贴复制)、网关端口:6005--确定--右边窗口已选定---表名成功二、组件过程A、B、聚合和行级转换*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入;若有多个,也得导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*映射:映射--创建---命名(mapping)--拖入源表--点击SQ按钮--双击表头--端口--选择(删除、添加)需要字段和是否输入、输出--属性--user defined join后面添加关联条件--确定--点击聚合按钮--添加聚合字段--填写聚合函数表达式---点击行级转换按钮f(x)--拖拽字段--添加行级转换字段(比如:2倍)--填写行级转换表达式---确定---拖入目标表--连接目标表和行级转换器、聚合器对应序列字段--保存*任务:任务--创建--命名据库--加载项改为normal--确定--保存*启动:(工作流--启动工作流)/(右键单击任务--启动任务)C、过滤器(查找deptno=30的员工)*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定3、目标--生成执行sql语句--连接--odbc_oracle--目标表所属用户名、密码(Scott2、tiger)---生成并执行sql语句---到Scott2中查看是否已创建表头4、*映射:映射--创建---命名(mapping)--拖入源表--点击过滤器按钮--双击表头--属性--过滤条件(filter condition:deptno=30)--端口--选择(删除、添加)需要字段和是否输入、输出---确定--连接源表和过滤器对应字段--拖入目标表--连接目标表和过滤器对应字段--保存5、任务:任务--创建--命名数据库--加载项改为normal--确定--保存7、启动:(工作流--启动工作流)/(右键单击任务--启动任务)D、存储过程及序列(统计每个部门下的员工个数)*在Scott用户下创建存储过程,用来统计每个部门下的员工个数*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表2、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*映射:映射--创建---命名(mapping)--拖入源表--点击聚合按钮--双击表头--端口--选择(删除、添加)需要字段和是否输入、输出--分组字段选择分组按钮--确定--点击存储过程按钮--登陆存储过程所属用户--连接--选择存储过程--确定--双击存储过程--属性--connection连接--选择源source --确定--连接目标表和存储器对应返回值字段--点击序列按钮--拖入目标表--连接目标表和过滤器对应序列字段--保存*任务:任务--创建--命名据库--加载项改为normal--确定--保存*启动:(工作流--启动工作流)/(右键单击任务--启动任务)E、排序(按SAL排序)*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*目标--生成执行sql语句--连接--odbc_oracle--目标表所属用户名、密码(Scott2、tiger)---生成并执行sql语句---到Scott2中查看是否已创建表头*映射:映射--创建---命名(mapping)--拖入源表--点击排序按钮--双击表头--端口--选择(删除、添加)需要字段和是否输入、输出(排序字段选择键-选择升序/降序)---确定--连接源表和排序器对应字段--拖入目标表--连接目标表和过滤器对应字段--保存8、任务:任务--创建--命名9、工作流:工作流--创建--命名--双击--映射--选择源数据库/目标数据库--加载项改为normal--确定--保存10、启动:(工作流--启动工作流)/(右键单击任务--启动任务)F、分发器(分别查询10、20、30部门下的员工)*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*映射:映射--创建---命名(mapping)--拖入源表--点击路由器转换按钮--双击表头--分组--添加分组按钮--true处修改条件(如:deptno=10/deptno=20/deptno=30)--确定---拖入目标表--连接目标表和路由器器对应字段--保存*任务:任务--创建--命名*工作流:工作流--创建--命名--双击--映射--选择源数据库/目标数据库--加载项改为normal--确定--保存*启动:(工作流--启动工作流)/(右键单击任务--启动任务)G、增量抽取*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*映射:映射--创建---命名(mapping)--拖入源表--点击查询转换器按钮--查询目标表--确定--将组合主键字段连接--双击表头--条件--添加对应相同字段(year=year1...)--确定--点击更新按钮--将目标表中查询的字段连接(更新和查询转换之间)--双击表头--属性--转换属性--值(填写iif(isnull(YEAR),dd_insert,iif(YEAR=YEAR1 and MONTH=MONTH1 and SCORE=SCORE1,dd_reject,dd_update)))-将源表中字段与更新中连接--确定---拖入目标表--连接目标表和更新中从目标表查询的字段对应字段--保存*任务:任务--创建--命名*工作流:工作流--创建--命名--双击--映射--选择源数据库/目标数据库--加载项改为normal--确定--保存*启动:(工作流--启动工作流)/(右键单击任务--启动任务)。
六步法:Informatica数据质量控制方法第一篇:六步法:Informatica 数据质量控制方法Informatica 数据质量控制方法一个战略性和系统性的方法能帮助企业正确研究企业的数据质量项目,业务部门与IT 部门的相关人员将各自具有明确角色和责任,配备正确的技术和工具,以应对数据质量控制的挑战。
Informatica 的六步法为帮助指导数据质量控制而设计,从初始的数据探查到持续监测以及持续进行的数据优化。
业务部门与IT 部门的数据使用者—业务分析师、数据管理员、IT 开发人员和管理员,能够在六个步骤的每一步中协同使用Informatica 数据质量解决方案;并在整个扩展型企业的所有数据领域和应用程序中嵌入数据质量控制。
步骤一:探查数据内容、结构和异常第一步是探查数据以发现和评估数据的内容、结构和异常。
通过探查,可以识别数据的优势和弱势,帮助企业确定项目计划。
一个关键目标就是明确指出数据错误和问题,例如将会给业务流程带来威胁的不一致和冗余。
步骤二:建立数据质量度量并明确目标Informatica的数据质量解决方案为业务人员和IT人员提供了一个共同的平台建立和完善度量标准,用户可以在数据质量记分卡中跟踪度量标准的达标情况,并通过电子邮件发送URL来与相关人员随时进行共享。
步骤三:设计和实施数据质量业务规则明确企业的数据质量规则,即,可重复使用的业务逻辑,管理如何清洗数据和解析用于支持目标应用字段和数据。
业务部门和IT部门通过使用基于角色的功能,一同设计、测试、完善和实施数据质量业务规则,以达成最好的结果。
步骤四:将数据质量规则构建到数据集成过程中Informatica Data Quality支持普遍深入的数据质量控制,使用户可以从扩展型企业中的任何位置跨任何数量的应用程序、在一个基于服务的架构中作为一项服务来执行业务规则。
数据质量服务由可集中管理、独立于应用程序并可重复使用的业务规则构成,可用来执行探查、清洗、标准化、名称与地址匹配以及监测。
1Informatica概述 (3)2安装Informatica8.6.1 (3)2.1服务端安装 (3)2.2客户端安装 (7)3配置管理服务器 (9)3.1创建知识库和集成服务 (9)3.2客户端到集成服务端的连接 (11)4PowerCenter Designer学习 (13)4.1概念和基本定义 (13)4.2Mapping设计和组件的使用 (15)4.2.1实例一:聚合抽取 (15)4.2.2实例二:取TOP前三条记录 (16)4.2.3实例三:抽取XML源 (19)4.3WorkFlow的设计和使用 (20)4.3.1创建Session (20)4.3.2设计WorkFlow (22)4.4Repository Manager (23)1 Informatica概述Informatica一直致力于为客户提供具有强大的元数据管理、数据集成和个性化分析递送功能的世界通行标准的统一数据服务平台。
Informatica的基础设施产品以可伸缩的、可扩展的企业级数据集成平台为特点,并广泛支持来自Informatica和其他的领先商务智能提供商的数据仓库基础设施和分析型应用软件的开发和管理,提供元数据管理解决方案,帮助企业集成、优化、审核信息资产以提高运营效率,增加客户收益,取得竞争优势。
详见文档:2 安装Informatica8.6.1这里以Informatica8.6.1为例:2.1 服务端安装找到安装目录pc861_win32_x86.zip\Server\Windows\Disk1\InstData\VM下点击安装选择安装语言,这里以中文版为例点击下一步,并选择安装PowerCenter8.6.1必须选择事先准备好的安装密匙选择安装路径HTTPS配置,配置管理控制台与配置管理器的安全通信(如果没有使用该端口就采用默认)配置好Informatica域并进行下一步,取掉为特定用户启动Informatica Services,点击完成安装2.2 客户端安装选择安装设置安装路径安装完成后可以看到包含的所有工具3 配置管理服务器3.1 创建知识库和集成服务接下来我们主要是配置知识库管理服务器,PowerCenter数据整合引擎是基于元数据驱动的,提供了基于元数据驱动的元数据知识库(Repository),知识库是PowerCenter 的核心。
Informatica®10.4.0剖析入门指南Informatica 剖析入门指南10.4.02019年12 月© 版权所有 Informatica LLC 2010, 2020本软件和文档仅根据包含使用与披露限制的单独许可协议提供。
未事先征得 Informatica LLC 同意,不得以任何形式、通过任何手段(电子、影印、录制或其他手段)复制或传播本文档的任何部分。
Informatica 和 Informatica 标志是 Informatica LLC 在美国和世界其他许多司法管辖区的商标或注册商标。
欲获得 Informatica 商标的最新列表,请访问 https:// /trademarks.html。
其他公司和产品名称可能是其各自所有者的商业名称或商标。
美国政府权利交付给美国政府客户的程序、软件、数据库及相关文档和技术数据是指适用的联邦采购条例和政府机构特定补充条例中定义的"商业计算机软件"或"商业技术数据"。
因此,使用、复制、披露、修改和改编应遵循适用的政府合同中规定的限制和许可条款、政府合同条款的适用范围以及 FAR 52.227-19 商用计算机软件许可中规定的额外权利。
本软件和/或文档中的若干部分受第三方版权约束。
所需的第三方声明随产品一起提供。
本文档中的信息如有更改,恕不另行通知。
如发现本文档中有什么问题,请通过以下电子邮件地址向我们报告:**********************************。
Informatica 产品根据对应协议的条款和条件进行担保。
INFORMATICA 按"原样"提供本文档中的信息,无任何明示或暗示的担保,包括但不限于任何适销性和特定用途适用性担保,也没有任何非侵权担保或条件。
发布日期: 2020-02-04目录前言 (6)Informatica 资源 (6)Informatica Network (6)Informatica 知识库 (6)Informatica 文档 (6)Informatica 产品可用性矩阵 (7)Informatica Velocity (7)Informatica Marketplace (7)Informatica 全球客户支持部门 (7)第 1章: 入门概览 (8)剖析概览 (8)介绍 Informatica Analyst (9)Informatica Analyst 用户界面 (9)Informatica Developer 用户界面 (11)Informatica Developer 欢迎页 (12)备忘单 (12)Informatica Developer 任务 (13)教程讲解 (13)教程结构 (13)教程先决条件 (14)Informatica Analyst 教程 (14)Informatica Developer 教程 (15)第 I部分: Informatica Analyst 入门 (16)第 2章: 课程 1。
Informatica学习笔记摘要:Informatica学习笔记1:UPDATE AS INSERTInformatica学习笔记2:客户端连接服务器的问题 Informatica学习笔记3:workflow的问题 Informatica学习笔记4:Folder权限的问题 Informatica学习笔记6:建立workflow的问题 Informatica学习笔记7:workflow执行报错Informatica学习笔记8:提示joiner输入字段没有排序 Informatica学习笔记9:import一系列mapping Informatica学习笔记10:复制数据库的问题Informatica学习笔记11:informatica services不能启动 Informatica学习笔记12:从mysql抽取数据的字符集问题 Informatica学习笔记13:没有Lincense导致的问题 Informatica学习笔记14:lookup中自定义sql有问题 Informatica学习笔记15:infopower如何实现增量抽取? Informatica学习笔记16:informatica 8.1 安装问题Informatica学习笔记17:如何在PowerCenter中实现累加SUM Informatica学习笔记18:PC8.1运行出错 Informatica学习笔记19:多行记录合并问题――――――――――――――――――――――――――― Informatica学习笔记1:UPDATE AS INSERT问:要求实现每天抽取数据,而且是如果有改变才抽取更新,没有就不更新,因为源表中有最后修改时间的字段,我让它和SESSION上次运行时间比较来解决是否抽取,但问题是有的表中没有主键,我该怎么实现更新呢?有主键的我在WORKFLOW的MAPPING里面勾上了UPDATE ELSE INSERT 那没主键的用UPDATE AS INSERT 行么?还有UPDATE AS INSERT 什么意思啊,能解释的形象点么?答:UPDATE AS INSERT 就是语句一: update tab_name set c1= value1 ,c2 = value2 where c_prikey =value_pri语句二: insert into tab_name values(******)当在 tab_name的c_prikey找到有等于value_pri的,就执行语句一把所有对应的记录update。
摘要:Informatica学习笔记1:UPDATE AS INSERTInformatica学习笔记2:客户端连接服务器的问题Informatica学习笔记3:workflow的问题Informatica学习笔记4:Folder权限的问题Informatica学习笔记6:建立workflow的问题Informatica学习笔记7:workflow执行报错Informatica学习笔记8:提示joiner输入字段没有排序Informatica学习笔记9:import一系列mappingInformatica学习笔记10:复制数据库的问题Informatica学习笔记11:informatica services不能启动Informatica学习笔记12:从mysql抽取数据的字符集问题Informatica学习笔记13:没有Lincense导致的问题Informatica学习笔记14:lookup中自定义sql有问题Informatica学习笔记15:infopower如何实现增量抽取?Informatica学习笔记16:informatica 8.1 安装问题Informatica学习笔记17:如何在PowerCenter中实现累加SUMInformatica学习笔记18:PC8.1运行出错Informatica学习笔记19:多行记录合并问题———————————————————————————Informatica学习笔记1:UPDATE AS INSERT问:要求实现每天抽取数据,而且是如果有改变才抽取更新,没有就不更新,因为源表中有最后修改时间的字段,我让它和SESSION上次运行时间比较来解决是否抽取,但问题是有的表中没有主键,我该怎么实现更新呢?有主键的我在WORKFLOW的MAPPING里面勾上了UPDATE ELSE INSERT那没主键的用 UPDATE AS INSERT 行么?还有UPDATE AS INSERT 什么意思啊,能解释的形象点么?答:UPDATE AS INSERT 就是语句一: update tab_name set c1= value1 ,c2 = value2 where c_prikey = val ue_pri语句二: insert into tab_name values(******)当在 tab_name的c_prikey找到有等于value_pri的,就执行语句一把所有对应的记录update。
当没有匹配的,就执行语句二。
你可以powercenter的 source defination中的自己定义主键,也可以直接 override update sql,可以不用理会真实表结构中是否有主键Informatica学习笔记2:客户端连接服务器问:我通过客户端连接到服务器,做了一个workflow,运行的时候出现错误,说是服务器连接不上repository server和infomatic server他俩的port是不是要一样还是不需要?答:看看server 的配置..我想可能是没有配置好.问:Repository server服务起来了,就是informatica server起不来了,在配置的时候,是informatica server的ip解析不出来,怎么才能把那个地址和主机对应起来答:1.直接写IP2.编辑客户端的%WINDOWS%/SYSTEM32/DRIVERS/ETC/HOSTS文件,把ip与名字的对应关系加进去,客户端这台机器就可以自己解析了3.找DNS或者什么解析服务器搞定。
问:informatica server装在unix操作系统下,能不能找到配置informatica server的配置文件对应的是那一个文件.答:unix下缺省是pmserver.cfg,可以用pmconfig这个命令行工具修改配置文件,也可以直接打开编辑。
如果不是缺省的配置文件名可以通过, ps -efl|grep pmserver看看是哪个文件名。
问:谢谢,pmserver.cfg这个文件中的配置信息我看过了,里面设置的都是repository server ip:192.168.0.1和port:6001,怎么找不到配置的informatica server的ip:192.168.0.1和port:4001我是想知道这个信息在配置文件中能找到吗?答:这个是在workflow manager里面注册的。
双击server名字就看得到了。
问:是的,我在workflow manager里看到过,只要在那里注册好了就行了吗,我想它应该存放在什么位置所以想搞清楚,还是谢谢你.答:他存放在策略库的opb_server_info表里面,呵呵。
你也可以试试看直接改数据库。
不过直接改数据库这种事情要悄悄的干,被david知道了要打pp的。
Informatica学习笔记3:workflow问题问:创建一个工作流从一个txt文件到目标表,是不是要定义.par参数文件有没有谁有这方面的资料教程,给我发一份,非常感谢!~我创建了一个,运行的时候出错了:(Server10) Start workflow: Request acknowledged(Server10) Start workflow: ERROR: Error in starting execution of work flow [id = 8] [wf_s_m_test]. Please check the server log for more inf ormation.答:没必要非得定义参数文件,直接在session 中,指定路径和文件名就行..如果是同结构批量的文件,可以用file list 功能..参数文件也能作,相对来说是在外部控制路径和文件名,比较动态了.那个错,不是让你去看 server log 吗.. 去看看了.window 平台,default 去看事件管理器Informatica学习笔记4:Folder权限的问题问:Informatica用不同的用户创建的不同的folder,互相看不见是什么原因那?答:保护机制的作用,建folder的时候,在安全选项里可以设置!~把read权限赋给 repository user就可以了也有可能是启用了 version control 的原因Informatica学习笔记5:建立Repositories的时候出错问:我的Infromatica是安装在英文版的Windows环境下的,Matadata要放在Oracle9i中,可是当我在建立Repository的时候怎么也连接不上我的Oracle9i 数据库,而我用其他方式连接数据库是畅通的,在Windows的事件查看中看到如下信息:(368|752) Failure in running command-line request type[100401] [pmrep agent create -r "TCS" -t "Oracle" -u informatica -c Oradb -d "MS1252" -h tcs-china.db -o 9999 -H "tcs-china.db" -O 5001 -K 2082340862]. Er ror is [An error occurred while creating the repository.].答:建repository在"Repository Server Administration Console"里面可以找到Active Log的,可以看看出错信息,出错多的好像都是插入一个LONG的值,通常建策略库出问题都是字符集捣的鬼,几个地方要注意数据库的字符集,系统NLS_LANG环境变量,操作系统的缺省字符集(windows在地区设置里面看,还有缺省输入法也可能影响),理论上不同的字符集只要是可转换的,都是可以的,不过弄成一样的比较简单了。
问:谢谢guruhao的提示和帮助,我决定将Oracle和Informatica重新安装一下再来测试一次,我的操作系统的缺省字符集(windows在地区设置里面)是china系统NLS_LANG环境变量是N/A答:这一段都是正常的,drop table不成功,属于建库之前清理表的动作,还要往后,大约在中间的位置。
有个真正的插入数据的错,你最好设置一下NLS_LANG使之与oracle server的字符集相匹配。
it should be Oracle characterset is not same in Oracle Server and cli ent.Informatica学习笔记6:建立workflow的问题问:我用powercenter8建立一个mapping后,在workflow manager中建立了workflow,但是运行这个workflow时却提示以下错误信息:Could not start execution of this workflow because the current run on this Integration Service has not completed yet我检查了一下:server中的各服务已经正常启动了,但是就是运行时出现这种情况,请问是什么原因导致的??以及怎样解决呢???各位知道的就请说一下吧。
答:该错误应该是说你建的这个workflow正在运行,且还没有结束,因而你不可以再次启动该工作流。
你可以通过Monitor观察一下。
问:该错误应该是说你建的这个workflow正在运行,且还没有结束,因而你不可以再次启动该工作流。
你可以通过Monitor观察一下。
但是我在monitor中又看不到任何的session在运行啊~答:将你的informatica server在service里重新启动后再运行看看(问:过一阵子之后再运行就正常了。
不知道为什么?怪怪的~~~)Informatica学习笔记7:workflow执行报错问:我在执行某个workflow 的时候报了如下错误:FATAL ERROR : Unexpected Condition in file [/u05/bld65_64/pm713n/serv er/dmapper/widget/wjoiner.cpp] line [3176]. Contact Informatica Technical Support for assistance. Aborting this DTM process due to an unex pected condition.请问各位这是什么原因?我看了一下日志文件,好像是初始化的过程都还没有结束就报错了。