informatica开发学习
- 格式:doc
- 大小:2.74 MB
- 文档页数:53
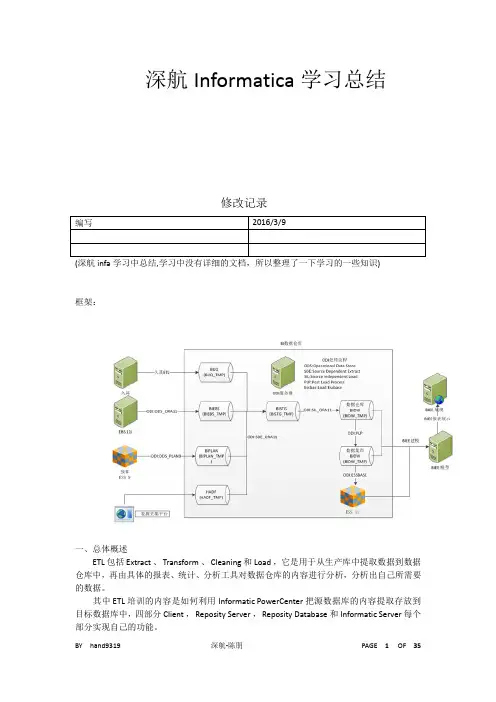
深航Informatica学习总结修改记录框架:一、总体概述ETL 包括 Extract 、 Transform 、 Cleaning 和 Load ,它是用于从生产库中提取数据到数据仓库中,再由具体的报表、统计、分析工具对数据仓库的内容进行分析,分析出自己所需要的数据。
其中 ETL 培训的内容是如何利用 Informatic PowerCenter 把源数据库的内容提取存放到目标数据库中,四部分 Client , Reposity Server , Reposity Database 和 Informatic Server 每个部分实现自己的功能。
二、系统体系结构此部分介绍了 Informatic ETL 工具包括的主要内容。
1.ClientInformatic Client 主要有五个部分。
Client 可以和 Reposity 分离,通过 TCP/IP 连接,连接到远程的 Reposity Server 。
2. Reposity Manager主要用于进行一个 Reposity 库的管理,当用户使用 Client 工具登录一个 Reposity 服务器之后,进行文件夹权限的创建,用户权限、密码的管理等。
3. Designer主要是进行数据抽取的转换工具的设计,主要是 mapping 的设计、设计源数据库的结构,目标数据库的结构,然后设计把源数据导入到目标数据库中,所需要进行的转换操作( Transformation )。
同一个 Reposity 的 folder 之间可以建立 shortcut 方式,多个 reposity 的 folder 之间只能做拷贝。
4. Workflow Manager主要用于流程任务( workflow Task )的设计。
进行任务流程的设计、每一个 Tast 针对一个 Session ,一个 session 针对一个 mapping ,其中 workflow 中的 Folder 和 Designer 中的 folder 相对应的关系。

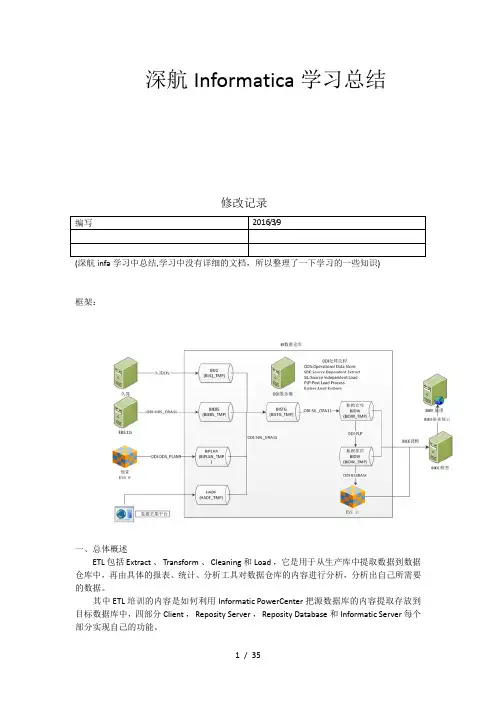
深航Informatica学习总结修改记录编写2016/3/9框架:一、总体概述ETL 包括 Extract 、 Transform 、 Cleaning 和 Load ,它是用于从生产库中提取数据到数据仓库中,再由具体的报表、统计、分析工具对数据仓库的内容进行分析,分析出自己所需要的数据。
其中 ETL 培训的内容是如何利用 Informatic PowerCenter 把源数据库的内容提取存放到目标数据库中,四部分 Client , Reposity Server , Reposity Database 和 Informatic Server 每个部分实现自己的功能。
二、系统体系结构此部分介绍了 Informatic ETL 工具包括的主要内容。
1.ClientInformatic Client 主要有五个部分。
Client 可以和 Reposity 分离,通过 TCP/IP 连接,连接到远程的 Reposity Server 。
2. Reposity Manager主要用于进行一个 Reposity 库的管理,当用户使用 Client 工具登录一个 Reposity 服务器之后,进行文件夹权限的创建,用户权限、密码的管理等。
3. Designer主要是进行数据抽取的转换工具的设计,主要是 mapping 的设计、设计源数据库的结构,目标数据库的结构,然后设计把源数据导入到目标数据库中,所需要进行的转换操作( Transformation )。
同一个 Reposity 的 folder 之间可以建立 shortcut 方式,多个 reposity 的 folder 之间只能做拷贝。
4. Workflow Manager主要用于流程任务( workflow Task )的设计。
进行任务流程的设计、每一个 Tast 针对一个 Session ,一个 session 针对一个 mapping ,其中 workflow 中的 Folder 和 Designer 中的 folder 相对应的关系。

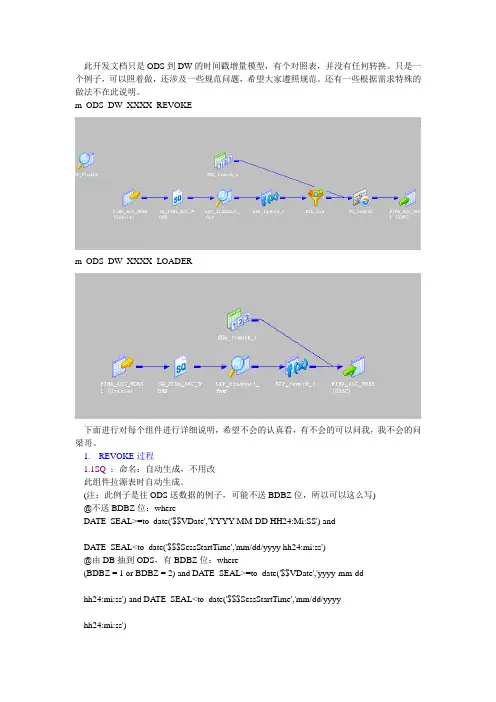
此开发文档只是ODS到DW的时间戳增量模型,有个对照表,并没有任何转换。
只是一个例子,可以照着做,还涉及一些规范问题,希望大家遵照规范。
还有一些根据需求特殊的做法不在此说明。
m_ODS_DW_XXXX_REVOKEm_ODS_DW_XXXX_LOADER下面进行对每个组件进行详细说明,希望不会的认真看,有不会的可以问我,我不会的问梁哥。
1.REVOKE过程1.1SQ :命名:自动生成,不用改此组件拉源表时自动生成。
(注:此例子是往ODS送数据的例子,可能不送BDBZ位,所以可以这么写)@不送BDBZ位:whereDA TE_SEAL>=to_date('$$VDate','YYYY-MM-DD HH24:Mi:SS') andDA TE_SEAL<to_date('$$$SessStartTime','mm/dd/yyyy hh24:mi:ss')@由DB抽到ODS,有BDBZ位:where(BDBZ = 1 or BDBZ = 2) and DATE_SEAL>=to_date('$$VDate','yyyy-mm-ddhh24:mi:ss') and DA TE_SEAL<to_date('$$$SessStartTime','mm/dd/yyyyhh24:mi:ss')LOOKUP(找对照表的UNICODE):命名:LKP_F(X): 命名:EXP_新增3个字段:ID,BDBZ,DA TE_V(名字自己定义)ID: :LKP.LKP_FINDID(UNIT_CODE,ZT_CODE,SUB_CODE,SUB_YEAR,ACCOUNTS_MARK_DATE,0)(查找的字段是原来定义的主键+BDBZ位[0])BDBZ: 2BDBZ: SETV ARIABLE($$VDate,to_char(SESSSTARTTIME,'yyyy-mm-dd HH24:MI:SS'))(是为了给变量赋值)FILTER:命名:FIL_作用:过滤掉ID为空的值。

Informatica元数据库2009-07-12 14:00Informatica所有的元数据信息均以数据库表的方式存到了元数据库中。
当然Infa本身工具提供了很多的人性化的功能,使我们在开发时可以很方便的进行操作,但人们的需求总是万变的,需要方便的取到自己需要的信息,那就需要我们对他的元数据库有很深的了解。
Informatica通过表和视图给我们提供着所有的信息,在此将通过一个系列的帖子,将大部分常见的,且非常有用的表及视图介绍一下。
基于这些东西,我们即可以根据不同的需求查出自己需要的数据,也可以开发一些辅助的Infa应用程序。
OPB_ATTR:INFORMATICA(Designer,Workflow等)设计时及服务器设置的所有属性项的名称,当前值及该属性项的简要说明例如:ATTR_NAME:Tracing LevelATTR_VALUE:2ATTR_COMMENT:Amount of detail in the session log用途:可以通过该表快速查看到设计或设置时碰到的一些属性项的用途与说明OPB_ATTR_CATEGORY:INFORMATICA各属性项的分类及说明例如:CATEGORY_NAME:Files and DirectoriesDESCRIPTION:Attributes related to file names and directory locations 用途:查看上表所提的属性项的几种分类及说明OPB_CFG_ATTR:WORKFLOW MANAGER中的各个Folder下的Session Configuration的配置数据,每个配置对应表中一组Config_Id相同的数据,一组配置数据共23条例如:ATTR_ID:221ATTR_VALUE:$PMBadFileDir用途:查看所有的SessionConfiguration的配置项及值,并方便的进行各个不同Folder间的配置异同比较OPB_CNX:WORKFLOW MANAGER中关于源、目标数据库连接的定义,包括Relational Connection,Queue Connection,Loader Connection等例如:OBJECT_NAME:Orace_SourceUSER_NAME:oralUSER_PASSWORD:`?53S{$+*$*[X]CONNECT_STRING:Oratest用途:查看在WorkFlow Manager中进行配置的所有连接及其配置数据OPB_CNX_ATTR:上表所记录的所有数据库连接的一些相关属性值,一种属性值一条数据。

Informatica 学习整理rmatica 产品介绍:• PowerCenter :Informatica PowerCenter 是世界级的企业数据集成平台,它在ETL 领域中无论是执行能力还是战略远见方面都是佼佼者,是Informatica 的核心产品 。
2.ETL 环节中最重要的:• 大家可能大部分会认为转换才是最重要的环节,但事实上是加载环节。
大家可能大部分会认为转换才是最重要的环节,但事实上是加载环节。
• 按重要程度递减排序,分别是load (装载)、clean (清洗)、transfer (转换)、extract (抽取)(抽取)3.具有2个server:• InformaticaRepository Server:资料库server,管理ETL 过程产生的元数据,用来管理对资料库中元数据的请求和操作;• Informatica server:实际的ETL 引擎;4.具有5个client:• PowerCenter Designer :设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL 映射• Workflow Manager :合理地实现复杂的ETL 工作流,基于时间、事件的作业调度 • Workflow Monitor :监控Workflow 和Session 运行情况,生成日志和报告 • Repository Manager :资料库管理,包括安全性管理等,元数据维护和安全操作,如:元数据查找,用户、组、权限管理等。
如:元数据查找,用户、组、权限管理等。
• Repository Server Administrator Console :对知识库的操作,如:知识库的创建、备份、恢复等。
创建、备份、恢复等。
5.基本的ETL 任务设计和部署的大致步骤:• 使用Designer 客户端,获取源数据表的元数据。
客户端,获取源数据表的元数据。
• 使用Designer 客户端,获取目标数据表的元数据。
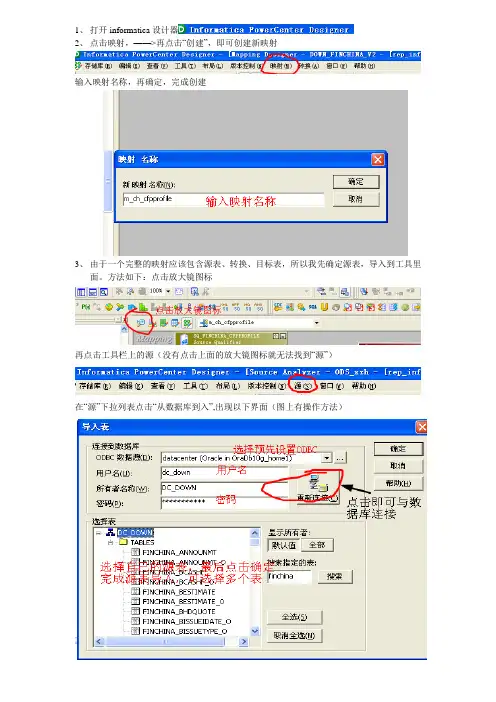
1、打开informatica设计器2、点击映射,——>再点击“创建”,即可创建新映射输入映射名称,再确定,完成创建3、由于一个完整的映射应该包含源表、转换、目标表,所以我先确定源表,导入到工具里面。
方法如下:点击放大镜图标再点击工具栏上的源(没有点击上面的放大镜图标就无法找到“源”)在“源”下拉列表点击“从数据库到入”,出现以下界面(图上有操作方法)导入目标表,先点击三角形图标,如下图再点击“目标”,在“目标”下拉列表点击“从数据库到入”,出现以下界面(操作方法同导入源表)4、点击下面红色框内的小图标,加入映射编辑对话拖入源表和目标表拖入表入下,(其中源表表结构不可编辑,转换组件可从工具栏中拖入)5、双击上述源表取数组建加入SQL语句,双击后,点击属性找到“SQL Query”行如下加入SQL语句注意:如的sql语句字段的顺序一点要与组件数据流入的的字段顺序一直,字段名也要一致编辑目标表的,方法:双击目标表,点击属性,就行编辑,如下6、保存,完成映射编辑7、点击,“W”图标,打开工作流编辑器8、找到上述映射所在的文件夹,右击——>打开(或双击)9新建会话,点击下列红框内的图标再点击“任务”在任务下拉框中,选择“创建”,出现以下对话框,输入任务名称,再点击创建选择映射最后点击完成10、编辑会话双击进入会话编辑界面,在点击“映射”编辑完成后,保存即完成编辑。
11、创建工作流,点击下列红框内图标,点击,“工作流”,再选择“工作流”下拉列表中的“创建”出现下列对话框,就行编辑或配置相关属性点击确定,有选择会话,拖入到编辑框中,如下示,拖入后如下,完成连接保存,即完成整个工作流12,运行右击编辑界面,或选择工作流右击,点击“启动工作流”。
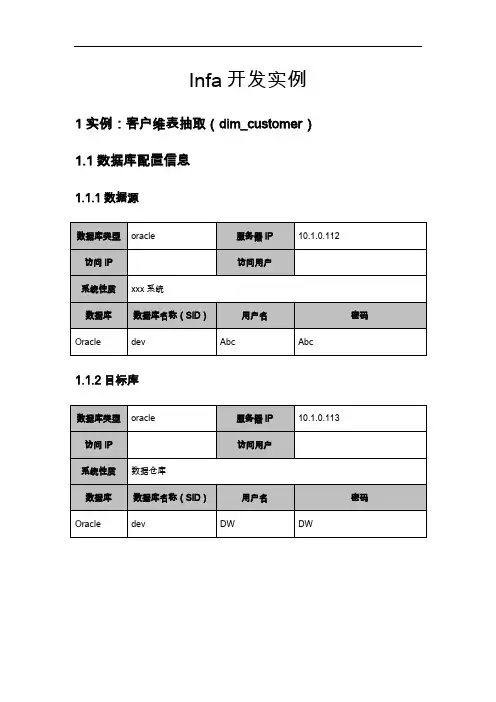
Infa开发实例1实例:客户维表抽取(dim_customer)1.1数据库配置信息1.1.1数据源1.1.2目标库1.2详细设计1.2.1基础信息1.2.2口径说明1.3抽取步骤1.3.1定义源1.打开Designer,选择“源->从数据库导入”,导入源表结构2.选择“源->从数据库导入”后出现如下提示框,若未配置源数据库的odbc,则需要先配置,可点击如下图的“…”进行配置3.在弹出的ODBC中,选择系统DSN,添加按钮,选择想为其安装数据源的驱动程序4.这里我们选择oracle in oraclient10g_home1,弹出如下框,进行配置,tns service name为本机配置的tns连接,这里不再详述5.配置完我们可以点击测试,看是否能连通数据库6.配置完odbc,我们选择相应的odbc连接,输入用户名密码连接erp数据库,也可以在搜索栏填入指定的表,然后选择导入7.用同样的方式,我们将Hz_Parties表导入designer1.3.2定义目标1.导入目标表的方式与导入源的方式基本一致,首先选择“目标->从数据库导入”2.选择我们配置好的odbc,输入目标库的用户名,密码1.3.3创建映射1.选择“映射->创建”,输入映射的名称,映射命名建议以“M_目标表名_Inc”方式来创建2.创建完映射,将刚才导入的两张源表拖入映射工作区中3.将我们需要的字段拖入join组件中,并join组件设置两张表的关联条件4.双击source qualifier组件,在“属性”的sql query中点击“生成sql”,这样在任务抽取的时候,直接根据sql获取源表相应字段的数据,而不是将整张表的所有字段全部加载的informatica中4.生成的sql或者开发人员修改了sql后,可以点击“验证”,看sql的语法是否正确5.将序列号组件和目标表拖入到工作区中,并将我们通过join组件关联后需要的字段与目标表关联,序列号组件中的序列也与目标表中的rowid字段关联,与目标表关联后,整个映射工作也就完成了1.3.4定义任务1.打开workflow工具,选择“工作流->创建”,输入工作流名称,工作流命名建议以“WF_目标表名_Inc”的方式2.点击确定后,工作流创建成功,如下图所示1.3.5创建会话任务1.点击工具栏上的“session”组件按钮进行创建会话任务2.弹出如下选框,选择我们刚刚做好的映射,点击确定3.点击工具栏的“链接”组件,将“启动”与会话任务进行连接4.点击“连接->关系”进行数据库连接的配置5.点击“新建”,选择oracle然后选择确定6.在弹出的如下框中进行配置,连接字符串中的oracle_crp为服务器上对应的tns连接串7.双击会话任务,在映射选项中进行数据源和目标的配置8.在连接类型中选择我们配置好的数据源,源和目标的数据源都要一一配置,如下图9.目标表配置中,target load type属性中我们一般选择normal选项,bulk有时候会报错,对于维表的抽取,我们一般采用全量的方式抽取,所以勾选truncate target table属性1.3.6监控工作流1.工作流及会话任务创建完成后,在工作流空白工作区右键->启动工作流2.启动workflow monitor,可以监控工作流的执行情况2实例:收入分析事实表抽取(ft_income_structure)2.1数据库配置信息2.1.1数据源2.1.2目标库2.2详细设计2.2.1基础信息2.2.2口径说明HZ_CUST_ACCOUNTS RAC,gl_code_combinations gcc,FND_FLEX_VALUE_SETS FFS,FND_FLEX_VALUES_VL FFV,mtl_system_items_b msiwhere ct.customer_trx_id = ctl.customer_trx_idand gd.customer_trx_id = ct.customer_trx_idand gd.customer_trx_line_id = ctl.customer_trx_line_idand hp.party_id = rac.party_idand ct.bill_to_customer_id = rac.cust_account_idand gd.account_class = 'REV'and gd.amount isnotnulland gd.amount <>0and gcc.code_combination_id = gd.code_combination_idAND gcc.chart_of_accounts_id = 50368and FFS.FLEX_VALUE_SET_ID = 1014869and FFV.FLEX_VALUE_SET_ID = FFS.FLEX_VALUE_SET_ID and FFV.Flex_Value = gcc.segment3and substr(ffv.FLEX_VALUE, 1, 1) = '6'and anization_id = 81and msi.inventory_item_id = ctl.inventory_item_idgroupby rac.account_number,2.3抽取步骤2.3.1定义源1.由于抽取任务涉及源表过多,关联关系复杂,并且已经写出数据的sql口径,我们直接获取sql语句生成的数据即可,点击“源->创建”,输入创建表的名称2.双击我们创建出来的表,添加表字段2.3.2定义目标参照1.3.2,导入后如图所示2.3.3创建映射1.参照1.3.3的方式创建映射2.在source qualifier中的写入我们写好的sql口径2.3.4定义任务参照1.3.42.3.5创建会话任务参照1.3.52.3.6监控工作流参照1.3.6。

Informatica 9安装手册项目号xxxx文档编号xxxx版本号 1.0保密级别一般内部公开秘密机密修订记录日期作者版本修订原因主要修订内容目录一、文档说明 (4)二、安装前系统环境准备 (4)1.确认系统需求 (4)2.检查Informatica环境变量 (5)3.确定端口 (5)4.创建Informatica用户 (5)三、安装介质准备 (6)四、安装Informatica 服务端 (6)1.创建informatica安装用户并设置安装目录 (6)2.表空间及数据库用户准备 (6)3.准备安装介质 (7)4.运行install.sh,开始安装 (7)5.选择图形化方式进行全新安装 (8)6.选择安装类型 (8)7.系统环境检查 (9)8.指定license,设定安装目录 (9)9.安装概要 (10)10.安装过程 (10)11.创建Domain并启用HTTPS安全管理 (11)12.设置配置Domain的数据库连接信息 (11)13.配置Domain和Node信息 (12)14.安装结束 (12)五、安装informaitca客户端 (13)六、安装之后的设置 (18)1.配置环境变量 (18)2.安装/配置数据库客户端 (19)七、Informatica服务端创建服务 (20)八、验证安装结果 (22)一、文档说明二、安装前系统环境准备1.确认系统需求Domain和应用服务的系统需求可以在同一机器配置Informatica Domain和一个node,所有application服务运行在同一node。
如果创建包括多个node的domain,可以将application服务运行不同的node上。
Informatica node支持以下Unix或Linux安装平台:✓Sun Solaris✓HP-UX✓IBM AIX✓Red Hat Linux✓SUSE Linux下表中列出了Informatica Domain包括不同node配置的最小系统需求:安装组件处理器需求内存需求磁盘需求4 CPU 8GB 20GB Domain with all Data Quality,Data Services andPowerCenter services running on one node2 CPU 4GB 4GB Domain with all PowerCenter services running onone node1CPU 2GB 3GB Domain with all PownerCenter services running onone node except Metadata Manager Service andReporting Service2CPU 2GB 3GB Metadata Manager Service running on a separatenodeReporting Sevice running on a separate node 1CPU 512MB 3GB Orchestration Server running on a separate node 1CPU 512MB 3GB安装过程中临时磁盘空间需求在安装过程中会产生大量的临时文件,确保有足够的可用临时空间。

informatica 学习日记informatica学习日记1.使用informatic client 1.1使用repository manager 1.1.1创建存储库。
前提:a.在odbc数据源管理器中新建一个数据源连接至你要创建repository的数据库(例:jzjxdev)b.要在你要连接的数据库中新建一个用户(例:name:etlpassword:etl)现在可以创建存储库了。
选择repository create repository,输入存储库名称(例如:jzjx)和数据库username(例:etl),databasepassword(例:etl),odbcdatasource(例:jzjxdev),nativeconnectstring(数据库所在IP(示例:141.20.52.108)1.1.2中添加存储库。
通过这一步你可以添加别人已经建好的repository。
选择repository add repository,输入存储库名称(例如jzjx)、用户名(例如ETL),然后单击OK查看名为jzjx的文件repository在左边的浏览器中,但是此时还看不到它的内容,要看到它的内容或者对它进行操作必须先连接它。
1.1.3添加文件夹选择folderccreate,输入文件夹名称即可。
1.2designer的使用首先,连接到存储库,您可以在存储库管理器中看到存储库创建的文件夹。
1.2.1资源sources文件夹下的表是抽取的来源表。
导入方法:在“工具”菜单下选择“源分析器”,然后在“源”菜单下选择“导入”fromdatabase,连接想要连接的数据库,连接上后选择你要抽取的表点击ok你所选择的表就会出现在sources文件夹下。
注意:上述导入过程仅导入表结构。
也可以创建自己的源表,只要创建的表的结构与实际表的结构一致。
1.2.2目标targets文件夹下的表是抽取的目标表,也就是抽取结果的存放表.导入方法:在“工具”菜单下选择“仓库设计器”,然后在“目标”菜单下选择“从数据库导入”,以连接要连接的用户数据库,连接上后选择你要抽取的表点击ok你所选择的表就会出现在targets文件夹下。
Informatica总结一、安装过程及其连接1、安装前准备*本机的oracle服务实例为orcl/cognos*将360或其它系统软件的拦截程序退出*Informatica安装前的准备工作及注意事项:创建表空间,用于存放数据库数据create tablespace BI_ETL datafile'C:\oracle\product\10.2.0\oradata\BI\BI_ETL.dbf'size1000M reuse autoextend on next100M;--这里,保存位置,空间大小需要按照实际情况灵活应变. 创建域用户并分配权限,用来管理域create user bi_domain identified by bi_domaindefault tablespace bi_etl temporary tablespacetempprofile default account unlock;grant connect to bi_domain;grant dba to bi_domain;grant resource to bi_domain;grant unlimited tablespace to bi_domain;grant select any table to bi_domain;alter user bi_domain default role all;创建资源用户并分配权限create user bi_resource identified bybi_resourcedefault tablespace bi_etl temporary tablespacetempprofile default account unlock;grant connect to bi_resource;grant dba to bi_resource;grant resource to bi_resource;grant unlimited tablespace to bi_resource;grant select any table to bi_resource;alter user bi_resource default role all;2、安装服务端*打开910HF6_Server_Installer_win32-x86/Server/install.exe 双击安装-->下一步--->修改安装地址-->直到完成-->将informatic 主页地址复制粘贴到IE浏览器地址栏中--回车--继续浏览此网页(不推荐)--用户名(Administrtor)、密码(admin)--登陆*创建存储库服务器:域导航器右边--操作--创建--存储库服务--命名、许可证、节点都选择最下面的--下一步--数据库类型(oracle)、(用户名和密码:准备时新创建的用户名和密码)、数据库服务实例名(orcl/cognos)、代码页选择GB2312-80--选择第二个按钮和其第一个选项--完成---提示可用--将操作模式改为普通(右边编辑--修改)*创建集成服务:域导航器右边--操作--创建--集成服务--命名、许可证、节点都选择最下面的--下一步--存储库服务选择前面新建的、用户名(Administrtor)、密码(admin)数据移动模式选择unicode--完成--代码页改为GB2312-80--确定--提示可用(若禁用--右边启动按钮启动即可)3、安装客户端双击910HF6_Client_Installer_win32-x86/client/install.exe--下一步--改变安装位置--直到完成*启动客户端程序连接服务器:打开客户端PCRM--存储库---配置域--添加按钮--域名(自起)、网关主机:计算机主机名(在计算机属性中粘贴复制)、网关端口:6005--确定--右边窗口已选定---表名成功二、组件过程A、B、聚合和行级转换*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入;若有多个,也得导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*映射:映射--创建---命名(mapping)--拖入源表--点击SQ按钮--双击表头--端口--选择(删除、添加)需要字段和是否输入、输出--属性--user defined join后面添加关联条件--确定--点击聚合按钮--添加聚合字段--填写聚合函数表达式---点击行级转换按钮f(x)--拖拽字段--添加行级转换字段(比如:2倍)--填写行级转换表达式---确定---拖入目标表--连接目标表和行级转换器、聚合器对应序列字段--保存*任务:任务--创建--命名据库--加载项改为normal--确定--保存*启动:(工作流--启动工作流)/(右键单击任务--启动任务)C、过滤器(查找deptno=30的员工)*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定3、目标--生成执行sql语句--连接--odbc_oracle--目标表所属用户名、密码(Scott2、tiger)---生成并执行sql语句---到Scott2中查看是否已创建表头4、*映射:映射--创建---命名(mapping)--拖入源表--点击过滤器按钮--双击表头--属性--过滤条件(filter condition:deptno=30)--端口--选择(删除、添加)需要字段和是否输入、输出---确定--连接源表和过滤器对应字段--拖入目标表--连接目标表和过滤器对应字段--保存5、任务:任务--创建--命名数据库--加载项改为normal--确定--保存7、启动:(工作流--启动工作流)/(右键单击任务--启动任务)D、存储过程及序列(统计每个部门下的员工个数)*在Scott用户下创建存储过程,用来统计每个部门下的员工个数*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表2、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*映射:映射--创建---命名(mapping)--拖入源表--点击聚合按钮--双击表头--端口--选择(删除、添加)需要字段和是否输入、输出--分组字段选择分组按钮--确定--点击存储过程按钮--登陆存储过程所属用户--连接--选择存储过程--确定--双击存储过程--属性--connection连接--选择源source --确定--连接目标表和存储器对应返回值字段--点击序列按钮--拖入目标表--连接目标表和过滤器对应序列字段--保存*任务:任务--创建--命名据库--加载项改为normal--确定--保存*启动:(工作流--启动工作流)/(右键单击任务--启动任务)E、排序(按SAL排序)*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*目标--生成执行sql语句--连接--odbc_oracle--目标表所属用户名、密码(Scott2、tiger)---生成并执行sql语句---到Scott2中查看是否已创建表头*映射:映射--创建---命名(mapping)--拖入源表--点击排序按钮--双击表头--端口--选择(删除、添加)需要字段和是否输入、输出(排序字段选择键-选择升序/降序)---确定--连接源表和排序器对应字段--拖入目标表--连接目标表和过滤器对应字段--保存8、任务:任务--创建--命名9、工作流:工作流--创建--命名--双击--映射--选择源数据库/目标数据库--加载项改为normal--确定--保存10、启动:(工作流--启动工作流)/(右键单击任务--启动任务)F、分发器(分别查询10、20、30部门下的员工)*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*映射:映射--创建---命名(mapping)--拖入源表--点击路由器转换按钮--双击表头--分组--添加分组按钮--true处修改条件(如:deptno=10/deptno=20/deptno=30)--确定---拖入目标表--连接目标表和路由器器对应字段--保存*任务:任务--创建--命名*工作流:工作流--创建--命名--双击--映射--选择源数据库/目标数据库--加载项改为normal--确定--保存*启动:(工作流--启动工作流)/(右键单击任务--启动任务)G、增量抽取*源:源--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)*目标表1、方法一(目标--从数据库导入--连接--odbc_oracle--连接--选择取数据的表--确定(若源列表中有表,则不用再导入)--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定2、方法二、直接在源中拖拽过来--双击表头--重命名--端口--选择(删除、添加)需要字段和是否输入、输出---确定*映射:映射--创建---命名(mapping)--拖入源表--点击查询转换器按钮--查询目标表--确定--将组合主键字段连接--双击表头--条件--添加对应相同字段(year=year1...)--确定--点击更新按钮--将目标表中查询的字段连接(更新和查询转换之间)--双击表头--属性--转换属性--值(填写iif(isnull(YEAR),dd_insert,iif(YEAR=YEAR1 and MONTH=MONTH1 and SCORE=SCORE1,dd_reject,dd_update)))-将源表中字段与更新中连接--确定---拖入目标表--连接目标表和更新中从目标表查询的字段对应字段--保存*任务:任务--创建--命名*工作流:工作流--创建--命名--双击--映射--选择源数据库/目标数据库--加载项改为normal--确定--保存*启动:(工作流--启动工作流)/(右键单击任务--启动任务)。
1Informatica概述 (3)2安装Informatica8.6.1 (3)2.1服务端安装 (3)2.2客户端安装 (7)3配置管理服务器 (9)3.1创建知识库和集成服务 (9)3.2客户端到集成服务端的连接 (11)4PowerCenter Designer学习 (13)4.1概念和基本定义 (13)4.2Mapping设计和组件的使用 (15)4.2.1实例一:聚合抽取 (15)4.2.2实例二:取TOP前三条记录 (16)4.2.3实例三:抽取XML源 (19)4.3WorkFlow的设计和使用 (20)4.3.1创建Session (20)4.3.2设计WorkFlow (22)4.4Repository Manager (23)1 Informatica概述Informatica一直致力于为客户提供具有强大的元数据管理、数据集成和个性化分析递送功能的世界通行标准的统一数据服务平台。
Informatica的基础设施产品以可伸缩的、可扩展的企业级数据集成平台为特点,并广泛支持来自Informatica和其他的领先商务智能提供商的数据仓库基础设施和分析型应用软件的开发和管理,提供元数据管理解决方案,帮助企业集成、优化、审核信息资产以提高运营效率,增加客户收益,取得竞争优势。
详见文档:2 安装Informatica8.6.1这里以Informatica8.6.1为例:2.1 服务端安装找到安装目录pc861_win32_x86.zip\Server\Windows\Disk1\InstData\VM下点击安装选择安装语言,这里以中文版为例点击下一步,并选择安装PowerCenter8.6.1必须选择事先准备好的安装密匙选择安装路径HTTPS配置,配置管理控制台与配置管理器的安全通信(如果没有使用该端口就采用默认)配置好Informatica域并进行下一步,取掉为特定用户启动Informatica Services,点击完成安装2.2 客户端安装选择安装设置安装路径安装完成后可以看到包含的所有工具3 配置管理服务器3.1 创建知识库和集成服务接下来我们主要是配置知识库管理服务器,PowerCenter数据整合引擎是基于元数据驱动的,提供了基于元数据驱动的元数据知识库(Repository),知识库是PowerCenter 的核心。
部门集市以及客服集市Informatica开发手册更新历史:目录部门集市以及客服集市Informatica开发手册 (1)一、Mapping开发 (3)1.源表(文件)结构导入 (3)2.目标表(文件)结构导入 (6)3.Mapping开发 (8)3.1.命名规则 (8)3.2.源表 (8)3.3.目标表 (8)3.4.参数定义 (8)3.5.表达式转换器(客服) (9)3.6.调度存储过程(客服) (10)二、Workflow/Session开发 (11)1.Workflow/Seesion命名规则 (11)2.Workflow参数设定 (11)3.Session源文件设置 (12)3.1.源文件名称设置 (12)3.2.源文件路径设置 (12)3.3.核实源文件分隔符、语言环境设置 (12)4.Session目标表设置 (14)4.1.目标表名称 (14)4.2.目标表数据装载方式设置 (14)4.3.拒绝文件名设置 (14)4.4.目标文件名以及下发路径设置(客服) (15)5.存储过程设置(客服) (15)6.Lookup组件设置 (15)7.Session日志存储数量设置 (15)8.Session一次提交的数据量的设置 (16)三、Workflow导出/导入 (17)一、Mapping开发1.源表(文件)结构导入1.1.常用的数据源类型介绍目前在传统行业中,使用Informatica进行ETL作业的源有两种,一种是数据库中的表,一种是指定分隔符存储的平面文件。
源数据类型可以在创建源表的时候,可以进行选择,包括DB2/ORACL/File等,如下图:DB2数据库文件1.2.常用的创建源表方式路径>>Designer->工具->Source Analyzer->源1)手工创建:在没有现成测试文件、数据库表的情况下,进行手工创建,设置字段名称,字段类型,源数据类型。
控件名称Repository Manager 资料库Designer 设计器Workflow Manager 物理设计Workflow Monitor 监控Repository Manager--资料库:informatica的知识存储。
Designer 设计器:设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL映射。
Workflow Manager--物理设计:合理地实现复杂的ETL工作流,基于时间、事件的作业调度。
Workflow Monitor--监控:监控Workflow和Session运行情况,生成日志和报告。
注:查看帮助Fn+F1Repository Manager添加文件夹在Repository Manager 文件夹选项添加新建完成一个文件夹,在Designer中相应的文件夹会有业务组件、源、目标、多维数据集、维度、转换、Mapplet、映射、用户自定义的函数几个内容。
导入对象在Repository Manager 中导入XML对象选择存储库—导入对象如下:选择导入的XML文件选择导入对象。
选择导入目标文件夹。
如有冲突,会提示解决。
开始导入。
导入完成。
Designer添加源在PowerCenter Designer添加源选择要添加的文件夹点击,这个为源设计的一个控件。
菜单栏将如下:再选择源,然后可以选择导入源,或者创建源。
创建源在菜单的源,选择创建。
输入源的名称和数据库类型创建,生产如下:双击刚刚生产的控件,进入编辑表:表为表级信息编辑,列可以添加列信息。
导入数据库源在菜单的源,选择从数据库导入。
输入用户名和密码,连接完成好选择所需要的表。
也可以根据需要搜索所需要的表。
导入源和创建源的比较,导入源表结构都已经生成完成,不需要一个一个字段再输入那么麻烦。
当导入一张已存在的表,如果表存在字段变更,有提示是否替换,重命名等。
比较:可以查看表发生了哪些变更。
添加目标在PowerCenter Designer添加目标目标控件,选择目标控件后,菜单栏如下:选择菜单列的目标可以创建目标或者导入目标,创建目标目标 创建输入目标名并选择数据库类型创建。
点击进入编辑目标表,从数据库源导入在菜单的目标,选择从数据库导入。
输入用户名和密码,连接完成好选择所需要的表。
也可以根据需要搜索所需要的表。
若导入一张已存在的表,同样提示是否替换等。
添加转换在PowerCenter Designer添加转换转换控件点击后,菜单列如下:可以选择导入或者创建。
转换是为映射所用,在转换工作区添加的转换是可以重复使用。
也可以在设计映射的时候直接添加转换,此时的转换不能重复使用。
一般都是在设计映射的时候使用转换。
转换的类型有:创建转换选择转换类型,输入转换的名称创建。
点击进去可以编辑转换。
也可以直接拖控件到工作区Source QualifierSource Qualifier的作用:可以过滤数据。
可以连接同数据源的不同数据。
命名规范:一般是以SQ_开头。
数据过滤条件。
也就是SQL里面的where条件。
点击生成SQL将自动生成where条件。
在Mapping中:用Update Strategy Transformation标识行为Insert,Update,Delete或者Reject;命名规范:一般是以UPD_开头,插入UPD_INS,更新UPD_UPD,删除UPD_DEL,拒绝UPD_REJ。
Forward Rejected Rows:勾选时被Rejected的行会存入对应Target配置的Reject文件中去,不选时,可能会写入Session Log中去,根椐当前Transformation的Tracing Level 的属性来决定;如果在会话属性中配置了出错行日志属性,则不会生成Reject文件。
DD_INSERT:更新策略为插入数据。
DD_UPDATE:更新策略为更新数据,必须要有主键,主键应该等于update语句的where条件。
DD_DELETE:删除数据。
DD_REJECT:更新策略为拒绝。
用来执行单行计算,在计算表达式中,可以使用输入端口,输入/输出端口,可以使用函数,但数据源只能是一个。
命名规范:一般是以EXP_开头。
当为只是输出内容时,可编辑表达式来表达输出内容,可以使用函数等等。
可以通过验证来检查表达式是否有错误。
汇总器转换Aggregator可用于聚合统计。
命名规范:一般是以AGG_开头。
只允许聚合表达式出现在Aggregator Transformation 组件中只允许聚合表达式出现在Aggregator Transformation 组件中聚合函数:AVG,COUNT,FIRST,LAST,MAX,MEDIAN,MIN,PERCENTILE,STDDEV,SUM,VARIANCE表达式转换中也能使用函数,但是使用聚合函数会提示只能在Aggregator Transformation 组件中使用。
它只有一个输入组,一个输出组。
筛选器转换Filter用来过滤数据,只有Filter Condition评估为真的数据才能通过;将Filter尽可能地靠近Source可以提升性能;Filter只能接受来自单个Transformation的数据流;Filter只有一种输入/输出端口,默认值无效。
命名规范:一般是以FIL_开头。
Filter Condition就是一个判断条件,判断成功了的数据才能通过。
查找转换Lookup分为连接型和非连接型的,连接型的可以传送多个返回值给其它的Transformation,非连接型的只能有一个返回端口,在表达式中用Lookup函数(:LKP())来调用。
命名规范:一般是以LKP_开头。
当使用查找转换控件时,它会提示你要查找源或者是目标:Lookup的端口除了I,O之外,还有L和R;L 查找(lookup)R返回值(return)连接型:非连接型:非连接型的只能有一个返回端口,在表达式中用Lookup函数(:LKP())来调用。
如::LKP.LKPTRANS(EMPNO),LKPTRANS为查找转换控件的名称。
多匹配行处理策略:返回第一行,返回最一行,报错,返回任一值。
序列生成器生成序列数值。
可以使用它创建唯一的主键值、替代缺失的主键或在一定有序数字范围内循环。
命名规范:一般是以SEQ_开头。
它有两个字段,下一个值和当前值。
可以设定它的开始值,间隔值,最大值,当前值,是否循环等。
连接转换器Joiner可以用来连接两个相关的不同来源的数据源。
命名规范:一般是以JNR_开头。
连接方式有,内连接,左外连接,右外连接,全外连接。
条件为两个表的关联的条件。
规范器转换在关系型数据库处理中,Normalizer用来从一行变成多行,行列转换。
命名规范:一般是以NRM_开头。
如:本来是输出一行,有个10个字段。
经过规范转换可以顺一列有10行数据。
列名:为输出多少个列出现次数:该列输入字段个数Reset和Restart属性:会话结束时重置GK值到上次的值或者到1;如果两个都没有选,则下次回话GK会在上次的值+1开始。
Generated Key,自动产生不能删除的端口,命名为GK_XXX,由这个端口产生一个序列号值,在需要时可以作为主键,运行成功后会在知识库中保存下一个值,可以在Mapping中看到下一个值,可以修改这个值;路由转换Router转换为:一个输入组,可以有多个输出组。
每个输出组可以条件输出条件,满足条件的就在一个组输出。
命名规范:一般是以RTR_开头。
UNION转换UNION转换相当于UNION ALL语句,可以有多个输入组,但是只能有一个输出组。
命名规范:一般是以UN_开头。
首先要建输入组。
在添加组端口字段。
输出结果像UNION ALL 一样。
SQL转换SQL转换有查询模式和脚本模式。
命名规范:一般是以SQL_开头。
查询模式:输入查询语句,返回查询结果脚本模式:执行脚本查询模式:(1)静态连接选择查询模式。
数据库连接模式:静态连接就是在工作流的映射里指定,动态连接就是转换控件中传入参数。
编辑转换控件,SQL端口可以编辑输入、输出的内容。
要注意字段的长度要足够。
默认有SQLError字段输出,这是执行语句失败输出的内容。
还是可以添加SQL语句执行返回的输出。
SQL查询要指定查询语句,不然报错没有查询语句。
SQL查询返回字段多少个,SQL输出必须添加多少个端口名称。
多少个字段,按查询的字段顺序输出。
这里映射就是指定静态连接。
控件会比静态的自动多一个字段LogicalConnectionObject,这就是连接的目标,但是映射配置主要有效的参数设置。
添加Mapplet在PowerCenter Designer添加Mapplet菜单如下:添加映射在PowerCenter Designer添加映射命名规范:一般是以m_开头+数据流向+表名+增全量。
如:m_eas_ods_t_ea_person_inc 映射:相当于是一个方法,可以供工作流或者是工作集来调用。
菜单如下:在映射菜单下创建或者导入:创建映射:输入映射名称确定。
保存时候会解析是否有明显错误。
引用参数和变量:当需要引用参数和变量时,可以在映射 参数和变量下声明参数和变量,然后参数和参数的值可以写在一个参数文件中,在工作流中指定参数文件就可以进行读取参数了。
参数名称规则:以$$开头。
增量操作:时间增量:有时间条件,可以根据时间条件来限制增量抽取。
没有时间的:可以使用目标表和源表关联,可以判断哪些是新增的,哪些是删除的,再通过字段的HASH值或者MD5值来判断字段是否有变化,有变化就是更新的。
to_number(nvl(dbms_utility.get_hash_value($$T_BC_DailyLoanBillEntry,0,power(2, 30)),0))as L_HASHVALUE 用来计算HASH值,$$T_BC_DailyLoanBillEntry是一个变量,为需要关注是否发生变化的值,多个值用||来分隔。
或者使用MD5值,MD5(字段1||字段2||字段3||…)PowerCenter Workflow Manager在PowerCenter Workflow Manager中可以添加会话,工作集,工作流。
添加会话在PowerCenter Workflow Manager添加会话。
添加会话菜单将如下:要填会话,必须在Designer中有可用映射。
选择任务创建:选项映射添加工作集在PowerCenter Workflow Manager添加工作集。
菜单如下:可用创建工作集生产如下可用添加工作集内容可用添加会话,然后直接指定映射。
添加工作流在PowerCenter Workflow Manager添加工作流。