Informatica _组件使用介绍及优化
- 格式:ppt
- 大小:1.50 MB
- 文档页数:25

常用组件使用方法表1中列出的是informatica中的所有组件。
不会在本文档中出现的会在组件名后标出。
表1Lookup概要描述获得一个关联的值。
例如:源里包含employee ID,但你还需要employee name。
用于计算的值。
例如:只是汇率或者个人所得税之类的固定数值,不是计算得出来的数据。
Update slowly changing dimension tables。
主要是根据条件查出原表,若查出了,就把自己添加的标志位设为真,否则就设置为假。
Connected or unconnectedConnected 和unconnected 的transformations的输入和输出是不同的,不同点如表2列出的。
表2Connected下面是Integration Service处理connected Lookup transformation的过程:1.一个connected Lookup transformation通过pipeline从其他的transformation获得输入值。
2.为每个输入行,Integration Service会通过lookup ports 和condition从源或者缓存中查询。
3.如果组件没有使用缓存或者使用的静态缓存,Integration Service会使用lookupquery来返回值。
4.如果组件使用的动态缓存,当Integration Service在缓存找不到这行,它会把这行插入到缓存中。
当Integration Service找到这行,它会修改这行在缓存中或者什么都不做。
它标记这行是插入、修改或者是不做变动。
5.Integration Service从查询中返回值到下一个transformation。
如果transformation使用动态缓存,你可以把这行通过Filter 或者Router transformation来过滤后在到目标中。


目录未找到目录项。
Informatica 数据整合分为三类数据集成,即下游集成、中游集成和上游集成下游集成:指数据仓库,显著特点是,从数据流的角度看,数据仓库的主体功能是所有应用系统的下游,所有数据都会流向数据仓库中游集成:指数据交换平台,特点是,任何平台和它的关系都是对等的,它是这个数据枢纽hub的中心点,用来支持所有系统之间数据的数据交换,用于解决数据集成毛团问题。
上游集成:指主数据平台,而且是交易型主数据平台。
用于管理企业核心数据的黄金记录,作为企业核心记录的黄金数据的标准平台。
Informatica 的四个客户端及作用:1,Repository Manager:用于管理Repository本身,如创建文件夹,导入/导出Mapping、Worlkfolw,版本管理,部署,Repository的清除。
2,Designer:用于导入ETL元数据,开发ETL程序。
在Power Center中ETL程序被叫做Mapping,即源到目标的映射。
3,Workflow Manager:用于对Mapping的进行数据源、数据目标、使用的字符集、调优及参数配置等,使Mapping能够运行。
此外,还提供了基本的调度和排程的能力。
4,Workflow Monitor:用于监控运行时的Workflow和session,监控ETL运行是否正常、执行效率及异常时的错误信息。
Power Center的开发过程:0,使用PowerCenter客户端连接域(Domian)和数据库服务器Repository Service;建立一个文件夹(Folder),用于开发学习;1,在客户端PowerCenter Designer中导入源表和目标表的结构定义;注:在Power Center Designer中导入的仅仅是表结构,与执行过程的表名无强相关2,在Designer中,创建Mapping(ETL流程)3,在Designer中,拖动源和目标,以及相应组件进入Mapping4,在Designer中,建立源和目标,以及相应组件之间的映射5,在Workflow Manager中提供相应的配置信息及参数6,通过Workflow Monitor客户端进行监控7,预览执行结果重要概念:Mapping:是一个程序,但它不直接可以执行Session:是一个Mapping的实例,指定相关的配置信息后,可以执行;Workflow:可以执行一个或者多个Session,对Session或者其他Task组件进行排程基础组件:1,Source:源文件数据源可以是数据库表,文本文件,XML文件,SAP等,应用系统、Hadoop,MQ等源文件常用方法:手工创建,通过数据库、文本文件、样例文件导入注意:理论上,源表结构定义继承了数据库中表的定义,但是实践中有可能导入后的数据类型发生变化,如表中varchar2,而导入后变为nvarchar2,从而引起Session执行异常。

Transaction Control组件Active输入输出行数不同Connected连接组件组件概述PowerCenter可以根据流经过Transaction Control组件的一组数据来控制事务的操作类型:提交或者回滚。
事务包含受限于提交或者回滚的数据行。
可以通过输入行中一个变化的数值来定义一个事务,也可以通过一组已经排序了的数据来定义一个事务,比如员工id、日期。
在PowerCenter中,可以应用Transaction Control组件在mapping或者session 中:Mapping:在mapping中,通过Transaction Control组件定义一个事务。
在组件中根据一个表达式定义一个事务。
根据表达式的返回值,可以选择commit、roll back 或者continue不做任何变化。
Session:在配置session的时候可以自己定义事务。
在Integration Service向目标中写数据失败时,可以选择提交或者回滚。
在执行session的时候,Integration Service判断组件输入的每一行,当输入行事务类型为commit时,Integration Service提交所有行至目标。
当输入行事务类型为回滚时,Integration Service从目标中回滚该事务的所有行。
如果mapping的目标为文件时,Integration Service每开始一个新的事务时生成一个新的动态命名的输出文件。
Note:也可以通过其他的组件属性来定义事务。
组件属性使用Transaction Control组件定义事务目标的提交、回滚条件。
事务目标包含:relational, XML, and dynamic MQSeries。
在Properties tab中控制表达式中定义以下参数,事务是一行或者一组数据,受限于提交或者回滚行。
每个事务的行数是变化的。
Transformation tab:在这个tab中可以重命名组件名称和增加组件说明Ports tab:增加输入输出端口Properties tab:定义事务控制表达式,标志出:commit, roll back, or no actionMetadata Extensions tab:You can extend the metadata stored in the repository by associating information with the Transaction Control transformation.Properties Tab通过该tab可以定义以下两个属性:Transaction control expressionTracing level事务控制表达式使用IIF函数来检查每一行是否满足条件。
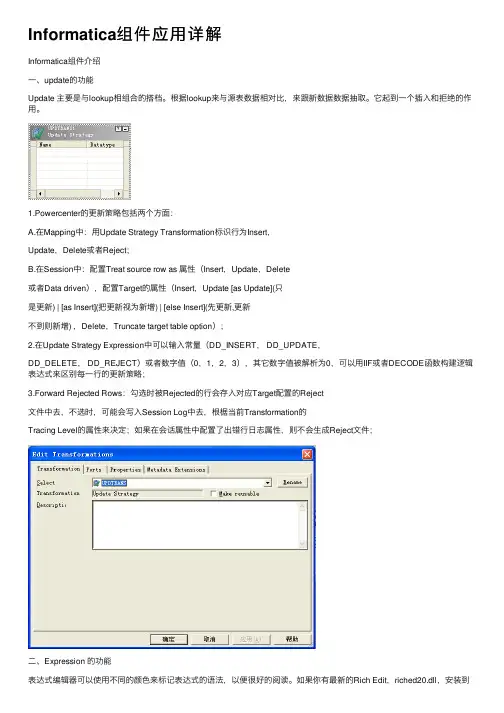
Informatica组件应⽤详解Informatica组件介绍⼀、update的功能Update 主要是与lookup相组合的搭档。
根据lookup来与源表数据相对⽐,来跟新数据数据抽取。
它起到⼀个插⼊和拒绝的作⽤。
1.Powercenter的更新策略包括两个⽅⾯:A.在Mapping中:⽤Update Strategy Transformation标识⾏为Insert,Update,Delete或者Reject;B.在Session中:配置Treat source row as 属性(Insert,Update,Delete或者Data driven),配置Target的属性(Insert,Update [as Update](只是更新) | [as Insert](把更新视为新增) | [else Insert](先更新,更新不到则新增) ,Delete,Truncate target table option);2.在Update Strategy Expression中可以输⼊常量(DD_INSERT, DD_UPDATE,DD_DELETE, DD_REJECT)或者数字值(0,1,2,3),其它数字值被解析为0,可以⽤IIF或者DECODE函数构建逻辑表达式来区别每⼀⾏的更新策略;3.Forward Rejected Rows:勾选时被Rejected的⾏会存⼊对应Target配置的Reject⽂件中去,不选时,可能会写⼊Session Log中去,根椐当前Transformation的Tracing Level的属性来决定;如果在会话属性中配置了出错⾏⽇志属性,则不会⽣成Reject⽂件;⼆、Expression 的功能表达式编辑器可以使⽤不同的颜⾊来标记表达式的语法,以便很好的阅读。
如果你有最新的Rich Edit,riched20.dll,安装到了系统,表达式显⽰表达式函数为兰⾊,注释式灰⾊,引⽤的字符串式绿⾊。

一、Suorce调优1.文本文件:-调优Line Sequential Buffer Length(1024)2.关系型数据库:-在Source Qualify优化SQL-在源数据增加索引-增加Database Network Packet size-当DB与informatica在同一台机器上使用IPC协议二、Target调优1.目标为文本文件:-调优Line Sequential Buffer Length(1024)2.目标位关系型数据库-删除目标索引和约束-增加checkpoit interval-使用Bulk Loading和External loading-增加Database networkPacketsize三、Mapping调优>最少化转化组件>减少不必要的link>对Aggregator、Joiner、Rank、Lookup等组件,减少连接的input/output和output字段>Single Pass:读一次数据,多处使用>减少数据类型转换:数值的比较比字符串要快>减少转换错误:使用session tracing terse>组件调优:Lookup组件、Filter组件、Aggregator组件、Joiner组件调优、调优Sequence Generator>调优表达式>增加Partition>调优Session参数四、System调优>增加network speed:本地速度一般是网络的5-20倍;文件拷贝到本地>使用informatica Grid>当只处理7-bit ASCII或EBCDIC数据时,选用ASCII data movement mode :只是用一个字节存储数据。
>减少Paging(虚拟内存):在Unix系统下,使用processor binding将资源分配给informatica。


接下来的这些条目是INFOR MATICA 的高级调优建议。
请极其谨慎地处理,每次试用一条建议。
在没有试着使用初级和中级建议来提高INFORMATICA 的性能以前,不要尝试使用如下的高级建议。
这些建议的实施可能需要系统管理员(SA)、数据库管理员(DBA)以及网络管理员之类的专家级人物的配合才可以,所以要细心。
高级调优最重要的方面就是能够精确的查明瓶颈是什么,并且有能力定位这些瓶颈是如何引起的。
根据常理,这些高级建议放在最后,并且是在系统级上的建议。
还有其他的适用于数据仓库调优的高级建议,可以依据你的软硬件资源存在的问题去寻找相应的帮助。
1、将MAPPING 分解。
保留一个数据目标。
如果必要每个数据目标保留一个数据源。
为什么要这么做呢?在一个MAPPING 中减少数据目标的个数会大幅度的提高运行的速度。
基本的情况是这样的:每个MAPPING/TARGET 对应一个SESSION。
每个SESSION 都会建立它自己的数据库连接。
因为对每个目标表建立一个单独的数据库连接,数据库管理器(DBMS)能将插入、更新和删除等操作需求并行地处理。
在一个SESSION 中进行一个特定目的的操作也是很有帮助的(例如不在把以数据驱动地操作和直接插入操作混合地插入到同一个数据目标中)。
如果实际情况运行,每个SESSION 可以被放置到标记为“CONCURRENT”的BATCH(译者注:旧版本的术语)中。
如果能够这样做,MAPPING和SESSION 的并行执行的情况就很显而易见了。
关于并行处理的研究一再地表明:与直接将原本的操作单元简单地顺序执行相比,同一时刻开始的并行执行有时只需花费一半的时间。
当一个MAPPING 中包含多个数据目标时,就会使得每个数据库连接去处理多个不同地数据库操作语句,有时会影响这个数据目标的性能,有时又是那个。
请想一下,在这情况下,INFORMATICA (包括其他的任何工具)都很难进行BULK(并行)操作,即使在SESSION中已经设定了BULK 属性。

Infa性能调优大多我们运用的工具都会提到一个共同的问题------性能调优。
什么是性能调优,每个人都有自己的一个定义,我比较喜欢的一个定义就是:性能调优就是尽力去消除系统中存在的性能瓶颈。
这是一个循环往复的过程,首先找到性能瓶颈,然后采取各种方法尽力消除它,然后寻找下一个性能瓶颈,然后消除它,循环往复,直到性能达到预期目的为止。
比较喜欢这个定义在于它告诉我们,性能调优没有一个最终的答案,每一次优化只要达到我们的期待的结果即是优化完成。
大多我们运用的工具都会提到一个共同的问题------性能调优。
什么是性能调优,每个人都有自己的一个定义,我比较喜欢的一个定义就是:性能调优就是尽力去消除系统中存在的性能瓶颈。
这是一个循环往复的过程,首先找到性能瓶颈,然后采取各种方法尽力消除它,然后寻找下一个性能瓶颈,然后消除它,循环往复,直到性能达到预期目的为止。
比较喜欢这个定义在于它告诉我们,性能调优没有一个最终的答案,每一次优化只要达到我们的期待的结果即是优化完成。
性能优化应该从整个系统上去规划,使系统能有一个理想的性能平衡。
换句话说就是使系统中的各个部分:应用软件、数据库、硬件资源共同达到一个性能的最优化,让各部分资源能用自己最擅长的一面最大程度的提升系统性能,最终达到一个系统级的性能平衡。
在此我们将对Informatica性能优化做一个系统的介绍,而其中也在一定程度上运用系统性能平衡的规则进行调优指导。
在此我们将按调优的一个通用的顺序进行介绍,或者说是一个调优Guideline, 即首先定位性能瓶颈,其次进行性能调优,最后介绍一些调优经验。
一、性能瓶颈性能调优时,首要的任务即是确定性能的瓶颈所在。
在对Informatica进行瓶颈确定时,我们应首先排除是否特殊情况,即从当时网络、数据库、服务器是否运行正常、是否忙等情况排除,当确认是普通情况后,我们便可以按以下步骤进行性能瓶颈确定。
1.Target确定瓶颈是否发生在ETL中的L上。

Informatica使用说明(图解)唾沫星冲锋枪 2013-4-22目录前言 (3)第一篇环境搭建 (3)服务器 (3)准备 (3)安装 (3)配置 (17)客户端 (23)准备 (23)安装 (24)介绍 (28)第二篇开发应用 (28)Repository Manager (28)环境介绍 (28)配置目录 (31)Designer (33)环境介绍 (33)配数据源 (34)引入数据源 (36)引入数据目标表 (38)制作Mapping (40)WorkFlow Manager (43)制作session (43)配置服务器数据源 (44)配置session源 (46)配置session目标 (47)制作workflow (48)执行workflow (50)WorkFlow Monitor (50)第三篇监控维护 (51)基本信息查看 (51)运行时间查看 (51)Session日志查看 (52)Workflow日志查看 (52)结束语 (53)前言个人从事ETL方面工作多年,各种工具都有一定了解,POWERCENTER是较为优秀的产品之一。
POWERCENTER是C/S模式,客户端开发服务器运行,本文主要介绍POWERCENTER 基本使用部分,详细的各个组件使用可以查阅相关帮助文档。
第一篇环境搭建服务器准备因为INFORMATICA把配置信息和开发的ETL过程信息都保存在资料库里,所以要预先准备一个数据库资料库。
本文采用oracle做资料库,名称INFO用户INFO密码INFO,配置好数据库的监听。
安装找到软件SERVER目录下的install.bat运行。
POWERCENTER的授权文件是按数据库接口出售的,支持数据库越多价格越高。
这里请注意配置,之前准备好的数据库资料库。
安装完成后可以查看一下服务项里面是否正常。
安装补丁。
因机器不同选择相应的补丁版本,如64位server系统需要补丁。

Informatica_(3)组件⼀、Informatica介绍Informatica PowerCenter 是Informatica公司开发的世界级的企业数据集成平台,也是业界领先的ETL⼯具。
Informatica PowerCenter使⽤户能够⽅便地从异构的已有系统和数据源中抽取数据,⽤来建⽴、部署、管理企业的数据仓库,从⽽帮助企业做出快速、正确的决策。
此产品为满⾜企业级要求⽽设计,可以提供企业部门的数据和电⼦商务数据源之间的集成,如XML,⽹站⽇志,关系型数据,主机和遗留系统等数据源。
此平台性能可以满⾜企业分析最严格的要求。
Informatica PowerCenter已被全球多家著名企业⽤来建设BI/DW系统,它可集成和分析企业的关键商务信息,优化整个商务价值链的表现和响应速度。
Informatica PowerCenter拥有⼀个功能强⼤的数据整合引擎,所有的数据抽取、转换、装载的功能都是在内存中执⾏的,不需要开发者⼿⼯编写这些过程的代码。
Informatica PowerCenter 数据整合引擎是元数据驱动的,通过知识库和引擎的配对管理,可以保证数据整合过程能够最优化执⾏,并且使数据仓库管理员⽐较容易对系统进⾏分析管理,从⽽适应⽇益增加的数据装载和⽤户群。
⼆、informatica开发步骤:定义源: Desinger定义⽬标: Desinger创建映射: 源--》转换组件--》⽬标Mapping都是由源表、转换组件和⽬标表组成,⽤于描述数据抽取的过程。
源表和⽬标表可以从源和⽬标⽂件夹拖拽到⼯作区,转换组件需要⼿动创建。
Mapping设计的关键就是转换组件的使⽤,这关系到数据抽取的正确性和效率。
定义任务: Workflow Manager创建⼯作流: Workflow Manager⼯作流调度监控 : Workflow Monitor三、转换组件1. 组件列表Source Qualifier 从数据源读取数据Expression ⾏级转换Filter 数据过滤Sorter 数据排序Router 条件分发joiner 异构数据关联连接Lookup 查询连接Aggregator 聚合Update Strategy 对⽬标编辑(insert\update\delete\reject)Union 数据合并Sequence Generator 序列号⽣成器Normalizer 记录规范化Rank 对记录进⾏TOPxTransaction Control 对装载数据按条件进⾏事物控制Stored Procedure 存储过程组件Custom ⽤户⾃定义组件HTTP WWW组件Java Java⾃编程组件其它应⽤组件2. 组件类型Passive类型:流⼊流出组件的⾏数不发⽣变化,如:Expression、Lookup、HTTP组件。
Informatica主要功能特性介绍1.Pre-Session和Post-Session调用数据库SQL以及存储过程。
2.列/行转换:一行记录转换为多条记录,使用Normalizer组件(见:Normalizer)。
3.行/列转换+条件汇总功能:多条记录合并为一条记录,使用Aggregator组件(结合其条件汇总功能) (见:ReversibleNormalizer)。
关于条件汇总的两种写法,注意它们的不同,如下:1) sum(iif(COMMITMONTH=$$v_yearmonth,PREMIUM,0))2) sum(PREMIUM, COMMITMONTH=$$v_yearmonth)4.增量汇总:将上次汇总的结果保存在Informatica系统目录下,以后对于增量的数据再做汇总的结果跟上次汇总的结果合并,大大提高汇总效率。
要结合Aggregator组件和Session的增量汇总属性(见:IncrementalAggregation)。
最新汇总数据的集合文件,会在Informatica Server的Cache子目录下生成,文件名如:PMAGG493_4.idx,PMAGG493_4.dat。
5.Mapping的参数(Parameter)和变量(Variable):参数和变量的值可以在参数文件中指定;变量的值可以在Session运行结束后动态更改(用法举例:动态生成抽取源表的Where语句,来实现对增量数据的抽取(见:ParameterAndVariable)。
可以使用的Variable函数:SetCountVariable SetMaxVariable SetMinVariable SetVariable。
参数文件的格式举例:[tdbu.s_m_ParameterAndVariable]$$PID=12$$VID=8$InputFile1=sales.txt$DBConnection_target=sales$PMSessionLogFile=D:/session logs/firstrun.txt6.读文件列表(FileList):针对多个结构相同,但是文件名不同的文件数据源,采用该方式可以大大提高ETL设计的灵活性,减少不必要的重复性操作。
六步法:Informatica数据质量控制方法第一篇:六步法:Informatica 数据质量控制方法Informatica 数据质量控制方法一个战略性和系统性的方法能帮助企业正确研究企业的数据质量项目,业务部门与IT 部门的相关人员将各自具有明确角色和责任,配备正确的技术和工具,以应对数据质量控制的挑战。
Informatica 的六步法为帮助指导数据质量控制而设计,从初始的数据探查到持续监测以及持续进行的数据优化。
业务部门与IT 部门的数据使用者—业务分析师、数据管理员、IT 开发人员和管理员,能够在六个步骤的每一步中协同使用Informatica 数据质量解决方案;并在整个扩展型企业的所有数据领域和应用程序中嵌入数据质量控制。
步骤一:探查数据内容、结构和异常第一步是探查数据以发现和评估数据的内容、结构和异常。
通过探查,可以识别数据的优势和弱势,帮助企业确定项目计划。
一个关键目标就是明确指出数据错误和问题,例如将会给业务流程带来威胁的不一致和冗余。
步骤二:建立数据质量度量并明确目标Informatica的数据质量解决方案为业务人员和IT人员提供了一个共同的平台建立和完善度量标准,用户可以在数据质量记分卡中跟踪度量标准的达标情况,并通过电子邮件发送URL来与相关人员随时进行共享。
步骤三:设计和实施数据质量业务规则明确企业的数据质量规则,即,可重复使用的业务逻辑,管理如何清洗数据和解析用于支持目标应用字段和数据。
业务部门和IT部门通过使用基于角色的功能,一同设计、测试、完善和实施数据质量业务规则,以达成最好的结果。
步骤四:将数据质量规则构建到数据集成过程中Informatica Data Quality支持普遍深入的数据质量控制,使用户可以从扩展型企业中的任何位置跨任何数量的应用程序、在一个基于服务的架构中作为一项服务来执行业务规则。
数据质量服务由可集中管理、独立于应用程序并可重复使用的业务规则构成,可用来执行探查、清洗、标准化、名称与地址匹配以及监测。
InformaticaV7性能调优简介1. 宗旨:定义性能标准(合理的期望值),找到最大的bottleneck,消除它;重复,直到无法调整为止。
2. 瓶颈类型:Target, Source,Mapping,Session,System查找瓶颈的方法:Target:写到本地文件Source:i. 每个Source Qualifer后跟Filter组件,Filter Condition设为Falseii. 移走所有的转换组件,将数据写到文件中。
iii. 将SQL Query在Database 中执行。
Mapping:i. 每个Target前面跟Filter组件,Filter Condition设为Falseii. 查看Peformance Details:3. Target调优:删除目标索引和约束增加checkpoint interval使用Bulk loading和External Loading增加Database network Packet sizeOracle调优数据库:i. Large intial and next value(storage clause)ii. Rollbacksegmentsiii. 最优化redo log,见:init.oraiv. 当Oracle跟Informatica在同一机器上,使用IPC协议。
4. Source调优:针对文件:调优Line Sequential Buffer Length(1024)调优Query:添加索引;优化SQL语句使用tempdb,关联Sybase和SQL Server的表增加Database network Packet size当Oracle跟Informatica在同一机器上,使用IPC协议,见listener.ora和 tnsnames.ora 文件。
5. Mapping调优:最少化转换组件减少不必要的link对Aggregator, Joiner, Rank, Lookup 等组件,减少连接的input/output和output字段。
ETL流程中Informatica的使用什么是ETL流程ETL(Extraction-Transformation-Loading)是一种数据处理过程,用于从多个数据源中提取数据,并将其转换为可用于分析和存储的目标数据库或数据仓库。
这是一种重要的数据集成方法,可用于整理、转换和处理大量的数据。
Informatica简介Informatica是一种用于数据集成和管理的强大软件平台。
它提供了一个统一的环境,使用户能够从各种源系统中提取数据,并将其转换、清洗和加载到目标系统中。
Informatica具有灵活的架构和丰富的功能,可以轻松处理各种ETL任务。
Informatica的主要组件Informatica由几个主要组件组成,每个组件都具有不同的功能和用途。
以下是Informatica的主要组件:1.源系统连接器:Informatica提供了许多连接器,用于连接不同类型的源系统,如关系型数据库、文件、Web服务等。
2.转换器:Informatica提供各种转换器,用于对数据进行各种转换和操作,如清洗、过滤、合并、拆分等。
3.加载器:Informatica的加载器组件用于将转换后的数据加载到目标系统中,如数据仓库、数据湖等。
4.目标系统连接器:Informatica支持将数据加载到不同类型的目标系统中,包括关系型数据库、文件等。
5.管理控制台:Informatica的管理控制台用于管理和监视ETL流程,包括任务调度、错误处理等。
ETL流程中使用Informatica的步骤在进行ETL流程中使用Informatica时,通常需要按照以下步骤进行操作:1.需求分析:首先,需要明确ETL流程的需求和目标,包括数据来源、目标系统、数据转换规则等。
2.数据提取:使用Informatica的源系统连接器,从源系统中提取数据。
可以选择适合的连接器,如关系型数据库连接器、文件连接器等。
3.数据转换:使用Informatica的转换器组件对提取的数据进行必要的转换和操作。