实时数据库系统解决方案-Read
- 格式:ppt
- 大小:3.16 MB
- 文档页数:48


db2解决死锁的方法DB2是一种常见的关系型数据库管理系统,它被广泛应用于企业级应用程序中。
然而,随着应用程序的复杂性增加和并发访问的增加,死锁问题也变得越来越常见。
在本文中,我们将探讨一些使用DB2解决死锁问题的方法。
1. 死锁的定义和原因死锁是指两个或多个事务彼此等待对方持有的资源,从而导致所有事务无法继续执行的状态。
死锁通常发生在并发访问数据库时,其中一个事务正在使用某个资源,而另一个事务需要访问相同的资源。
死锁的发生原因可以归结为四个条件:互斥(资源只能被一个事务使用)、持有并等待(一个事务持有资源并等待另一个事务的资源)、不可剥夺(资源不能被其他事务抢占)、循环等待(多个事务形成循环等待资源)。
2. 使用锁机制避免死锁在DB2中,可以使用锁机制来避免死锁的发生。
锁是一种机制,用于协调并发事务对共享资源的访问。
DB2提供了两种类型的锁:共享锁和排他锁。
共享锁允许多个事务同时读取资源,但不允许写入资源;排他锁只允许一个事务同时读取或写入资源。
为了避免死锁,可以采取以下策略:- 在事务开始时,尽量将锁的范围缩小到最小,只锁定必要的资源。
- 在事务执行期间,尽量减少锁的持有时间,执行完操作后尽快释放锁。
- 避免循环等待,即事务在请求资源时按照统一的顺序进行,避免形成死锁的循环等待。
3. 设置适当的隔离级别DB2提供了多种隔离级别,用于控制事务之间的相互影响。
不同的隔离级别对并发访问的控制程度不同。
在选择隔离级别时,需要权衡事务的一致性和性能。
在避免死锁的角度考虑,可以选择较低的隔离级别,如读取已提交(Read Committed)。
较低的隔离级别可以减少锁的竞争,从而降低死锁的风险。
但同时,较低的隔离级别也可能导致数据不一致的问题,需要根据具体业务需求进行权衡。
4. 监控和诊断死锁DB2提供了一些工具和功能,用于监控和诊断死锁问题。
可以通过以下方式来实现:- 使用DB2的系统监控工具,如db2pd命令和db2top工具,可以实时查看数据库的锁和死锁情况。

主题:db file scattered read 消耗分析一、db file scattered read概述1.1 db file scattered read是Oracle数据库中的一种I/O操作,用于读取数据块到内存中。
1.2 db file scattered read操作会在访问表或索引时发生,通常是由于全表扫描或索引扫描导致。
1.3 db file scattered read操作的消耗对系统性能和数据库响应时间有着重要影响。
二、db file scattered read消耗的原因分析2.1 大量的I/O操作:当数据库需要执行大量的db file scattered read操作时,会增加I/O负载,导致系统性能下降。
2.2 大量的全表扫描:如果数据库中存在大量的全表扫描操作,可能会导致大量的db file scattered read操作,进而影响数据库性能。
2.3 磁盘读取速度慢:当磁盘读取速度较慢时,会导致db file scattered read操作消耗增加。
三、优化db file scattered read消耗的方法3.1 增加内存缓存:通过增加内存缓存,可以减少db file scattered read操作对磁盘的依赖,提高数据库性能。
3.2 优化SQL查询:尽量避免全表扫描,使用合适的索引和优化SQL查询语句,减少db file scattered read操作的消耗。
3.3 磁盘性能优化:优化磁盘的读取速度,使用高速磁盘或者采用磁盘阵列等技术来提高磁盘读取速度,减少db file scattered read操作的消耗。
四、db file scattered read消耗影响的解决方案4.1 增加数据库服务器的内存:通过增加数据库服务器的内存,可以提升内存缓存效果,减少db file scattered read操作的消耗对磁盘的依赖。
4.2 使用SSD硬盘:采用SSD硬盘可以显著提高磁盘的读取速度,减少db file scattered read操作的消耗,并提高数据库性能。

数据库连接池内存泄漏问题的分析和解决⽅案⼀、问题描述上周五晚上主营出现部分设备掉线,经过查看⽇志发现是由于缓存系统出现长时间gc导致的。
这⾥的gc⽇志的特点是:1.gc时间都在2s以上,部分节点甚⾄出现12s超长时间gc。
2.同⼀个节点距离上次gc时间间隔为普遍为13~15天。
然后紧急把剩余未gc的⼀个节点内存dump下来,使⽤mat⼯具打开发现,com.mysql.jdbc.NonRegisteringDriver 对象占了堆内存的⼤部分空间。
查看对象数量,发现com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference 这个对象堆积了10140 个。
初步判断长时间gc的问题应该是由于 com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference 这个对象⼤量堆积引起的。
⼆、问题分析⽬前正式环境使⽤数据库相关依赖如下:依赖版本mysql 5.1.47hikari 2.7.9Sharding-jdbc3.1.0根据以上描述,提出以下问题:1、com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference 到底是个什么对象呢?2、这种对象为什么会⼤量堆积,JVM回收不过来了?NonRegisteringDriver$ConnectionPhantomReference 到底是个什么对象呢?简单来说,NonRegisteringDriver类有个虚引⽤集合connectionPhantomRefs⽤于存储所有的数据库连接,NonRegisteringDriver.trackConnection⽅法负责把新创建的连接放⼊connectionPhantomRefs集合。
源码如下:1.public class NonRegisteringDriver implements java.sql.Driver {2. protected static final ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference> connectionPhantomRefs = new ConcurrentHashMap<ConnectionPhantomReference,3. protected static final ReferenceQueue<ConnectionImpl> refQueue = new ReferenceQueue<ConnectionImpl>();4.5. ....6.7. protected static void trackConnection(Connection newConn) {8.9. ConnectionPhantomReference phantomRef = new ConnectionPhantomReference((ConnectionImpl) newConn, refQueue);10. connectionPhantomRefs.put(phantomRef, phantomRef);11. }12. ....13. }我们追踪创建数据库连接的过程源码,发现其中会调到com.mysql.jdbc.ConnectionImpl的构造函数,该⽅法会调⽤createNewIO⽅法创建⼀个新的数据库连接MysqlIO对象,然后调⽤我们上⾯提到的NonRegisteringDriver.trackConnection⽅法,把该对象放⼊NonRegisteringDriver.connectionPhantomRefs集合。
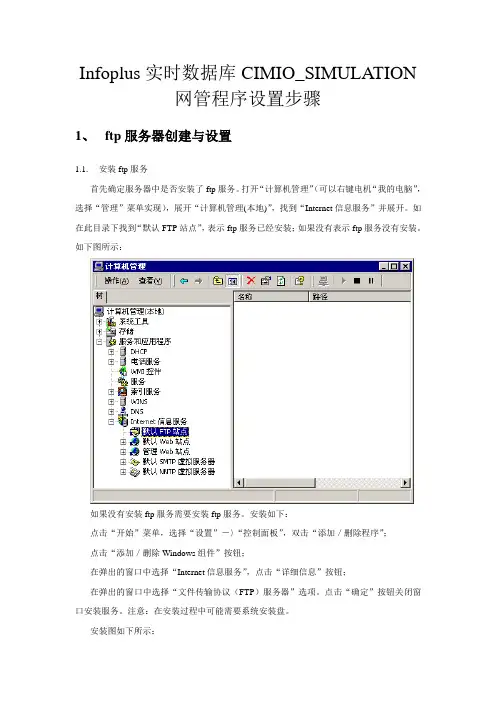
Infoplus实时数据库CIMIO_SIMULATION网管程序设置步骤1、ftp服务器创建与设置1.1.安装ftp服务首先确定服务器中是否安装了ftp服务。
打开“计算机管理”(可以右键电机“我的电脑”,选择“管理”菜单实现),展开“计算机管理(本地)”,找到“Internet信息服务”并展开。
如在此目录下找到“默认FTP站点”,表示ftp服务已经安装;如果没有表示ftp服务没有安装。
如下图所示:如果没有安装ftp服务需要安装ftp服务。
安装如下:点击“开始”菜单,选择“设置”-〉“控制面板”,双击“添加/删除程序”;点击“添加/删除Windows组件”按钮;在弹出的窗口中选择“Internet信息服务”,点击“详细信息”按钮;在弹出的窗口中选择“文件传输协议(FTP)服务器”选项。
点击“确定”按钮关闭窗口安装服务。
注意:在安装过程中可能需要系统安装盘。
安装图如下所示:1.2.ftp服务器的设置新建一个用户“eastxy”,用户密码为“eastxy1234”。
打开“计算机管理”(可以右键电机“我的电脑”,选择“管理”菜单实现),展开“计算机管理(本地)”,找到“Internet信息服务”并展开,右键点击“默认FTP站点”,选择“帐号安全”页签,勾选“允许匿名连接”,用户选择“eastxy”,密码“eastxy1234”。
如下图所示:然后再资源管理器中找到“C:\Inetpub\ftproot\”目录,然后再改目录下建一个新的的“CIM_IO”目录。
2、逻辑设备创建2.1.复制程序解压cimio_SIMULATION.rar文件,拷贝其中的文件到“C:\WINNT\system32”(Windows2000系统)或者“C:\windows\system32”(WindowsXP系统)目录下。
2.2.设置服务打开“C:\WINNT\system32\drivers\etc”(Windows2000系统)或者“C:\windows \system32\drivers\etc”(WindowsXP系统)目录。