数据库范式分解例题及解析
- 格式:docx
- 大小:15.36 KB
- 文档页数:2

分解为第三范式例题
理解你的要求,我将以一个例子来解释第三范式。
假设我们有一个包含以下信息的数据库表:
学生表 (Student)。
学生ID (StudentID)。
学生姓名 (StudentName)。
学生年级 (StudentGrade)。
学生地址 (StudentAddress)。
学生成绩 (StudentScore)。
学生成绩科目 (StudentSubject)。
在这个例子中,我们可以看到学生成绩和学生成绩科目与学生的其他信息关联在一起。
但是,如果一个学生有多个成绩科目,那
么在这个表中就会出现重复的学生信息。
这违反了第三范式的要求,即消除传递依赖。
为了符合第三范式,我们可以将学生成绩和学生
成绩科目从学生表中分离出来,创建一个新的表:
学生成绩表 (StudentScore)。
学生ID (StudentID)。
学生成绩 (StudentScore)。
学生成绩科目 (StudentSubject)。
通过这种方式,我们消除了学生成绩和学生成绩科目对学生信
息的重复依赖。
现在,每个表都只包含特定类型的信息,而且不会
出现数据冗余。
这样设计的数据库结构更加规范化,易于维护和查询。
总之,第三范式要求数据库表中的每一列都与主键直接相关,
而不是间接相关。
通过将相关的数据分解到多个表中,我们可以确
保数据库的结构更加健壮和高效。

设有关系模式R(运动员编号,比赛项目,成绩,比赛类别,比赛主管),如果规定:每个运动员每参加一个比赛项目,只有一个成绩;每个比赛项目只属于一个比赛类别;每个比赛类别只有一个比赛主管。
试回答下列问题:
⑴根据上述规定,写出模式R的基本FD和关键码;
⑵说明R不是2NF的理由,并把R分解成2NF模式集;
⑶进而分解成3NF模式集。
解:⑴基本的FD有3个:
(运动员编号,比赛项目)→成绩
比赛项目→比赛类别
比赛类别→比赛主管
R的关键码为(运动员编号,比赛项目)。
⑵ R有两个这样的FD:
(运动员编号,比赛项目)→(比赛类别,比赛主管)
比赛项目→(比赛类别,比赛主管)
可见,前一个FD是部分(局部)函数依赖,所以R不是2NF模式。
如果把R分解成R1(比赛项目,比赛类别,比赛主管)
R2(运动员编号,比赛项目,成绩)
这里,R1和R2都是2NF模式。
⑶ R2已是3NF模式。
在R1中,存在两个FD:比赛项目→比赛类别
比赛类别→比赛主管
因此,“比赛项目→比赛主管”是一个传递依赖,R1不是3NF模式。
R1应分解为R11(比赛项目,比赛类别)
R12(比赛类别,比赛主管)
这样,ρ={R11,R12,R2}是一个3NF模式集。

补充讲义一、范式举例BCNF.如:课程号与学号)例4:R(X,Y,Z),F={XY->Z},R为几范式?BCNF。
例5:R(X,Y,Z),F={Y->Z,XZ->Y},R为几范式?3NF。
R的候选码为{XZ,XY},(R中所有属性都是主属性,无传递依赖)二、求闭包数据库设计人员在对实际应用问题调查中,得到的结论往往是零散的、不规范的(直观问题好办,复杂问题难办了),所以,这对分析数据模型,达到规范化设计要求,还有差距,为此,从规范数据依赖集合的角度入手,找到正确分析数据模型的方法,以确定关系模式的规范化程度。
例1.已知关系模式R(U、F),其中,U={A,B,C,D,E}; F={AB→ C, B→ D, EC → B , AC→B} ,求(AB)+F.解:设X(0)=AB○1计算X(1),在F中找出左边为AB子集的FD,其结果是:AB→C,B→D∴X(1)=X(0)UB=ABUCD=ABCD 显然,X(1)≠X(0)○2计算X(2),在F中找出左边为ABCD子集的FD,其结果是:C→E,AC→B∴X(2)=X(1)UB=ABCDUBE=ABCDE 显然,X(2)=U所以,(AB)+ F=ABCDE.(等于U,所以AB是唯一候选关键字)例2.设有关系模式R(U、F),其中U={A,B,C,D,E,I};F={A→D,AB→E,B→E,CD→I,E→C},计算(AE)+解:令X={AE},X(0)=AE○1在F中找出左边是AE子集的FD,其结果是:A→D,E→C∴X(1)=X(0)UB=X(0)UDC=ACDE 显然,X(1)≠X(0)○2在F中找出左边是ACDE子集的FD,其结果是:CD→I∴X(2)=X(1)UI=ACDEI显然,X(2)≠X(1),但F中未用过的函数依赖的左边属性已含有X(2)的子集,所以不必再计算下去,即(AE)+=ACDEI.因为,X(3)=X(2),所以,算法结束。

第三范式例题
第三范式(3NF)是数据库规范化的一种形式,它是为了消除数据冗余和改善数据完整性而进行的。
在第三范式中,每个非主属性都完全函数依赖于整个候选键。
以下是一个第三范式的例题:
考虑一个公司,该公司的员工有以下信息:员工编号、员工姓名、部门、工资。
现在的问题是,这些信息应该如何存储以避免数据冗余并保持数据的完整性?
首先,我们可以将员工的信息分为三个表:员工表、部门表和工资表。
1. 员工表:员工编号、员工姓名、部门编号
2. 部门表:部门编号、部门名称
3. 工资表:员工编号、工资
现在,让我们看看这些表是否满足第三范式的要求:
在员工表中,员工编号是主键,非主属性是员工姓名和部门编号。
因为部门编号完全依赖于员工编号(每个员工的部门编号都是唯一的),所以这个表满足第三范式的要求。
在部门表中,部门编号是主键,非主属性是部门名称。
因为部门名称完全依赖于部门编号(每个部门的名称都是唯一的),所以这个表也满足第三范式的要求。
在工资表中,员工编号是主键,非主属性是工资。
因为工资完全依赖于员工编号(每个员工的工资都是唯一的),所以这个表也满足第三范式的要求。
因此,通过将数据分为三个表并确保每个非主属性都完全依赖于整个候选键,我们实现了第三范式,从而避免了数据冗余并保持了数据的完整性。

1、请简述满足1NF、2NF和3NF的基本条件。
并完成下题:某信息一览表如下,其是否满足3NF,若不满足请将其化为符合3NF的关系。
(本小题第一范式的关系应满足的基本条件是元组中的每一个分量都必须是不可分割的数据项。
第二范式,指的是这种关系不仅满足第一范式,而且所有非主属性完全依赖于其主码。
第三范式,指的是这种关系不仅满足第二范式,而且它的任何一个非主属性都不传递依赖于任何主关键字。
考生情况(考生编号,姓名,性别,考生学校)考场情况(考场号,考场地点)考场分配(考生编号,考场号)成绩(考生编号,考试成绩,学分)2、某信息一览表如下,其是否满足3NF,若不满足请将其化为符合3NF的配件关系:(配件编号,配件名称,型号规格)供应商关系(供应商名称,供应商地址)配件库存关系(配件编号,供应商名称,单价,库存量)3、简述满足1NF、2NF和3NF的基本条件。
并完成下题:已知教学关系,教学(学号,姓名,年龄,性别,系名,系主任,课程名,成绩),试问该关系的主键是什么,属于第几范式,为什么?如果它不属于3NF,请把它规范到3NF。
4、请确定下列关系的关键字、范式等级;若不属于3NF,则将其化为3NF 。
例1.仓库(仓库号,面积,电话号码,零件号,零件名称,规格,库存数量)例1答案:仓库号+零件号;1NF;仓库(仓库号,面积,电话号码)零件(零件号,零件名称,规格)保存(仓库号,零件号,库存数量)例2. 报名(学员编号,学员姓名,培训编号,培训名称,培训费,报名日期),每项培训有多个学员报名,每位学员可参加多项培训。
例2答案:学员编号+培训编号;1NF;学员(学员编号,学员姓名)培训(培训编号,培训名称,培训费)报名(学员编号,培训编号,报名日期)5、请确定下列关系的关键字、范式等级;若不属于3NF,则将其化为3NF,要求每个关系写一条记录。
(部门编号,部门名称,所在城市,员工编号,员工姓名,项目编号,项目名称,预算,职务,加入项目的日期)[注]职务指某员工在某项目中的职务。
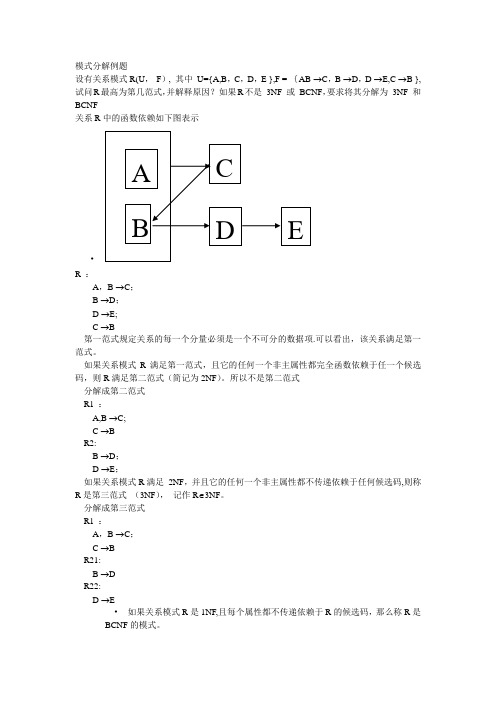
模式分解例题设有关系模式R(U,F), 其中U={A,B,C,D,E },F = {AB →C,B →D,D →E,C →B },试问R最高为第几范式,并解释原因?如果R不是3NF 或BCNF,要求将其分解为3NF 和BCNF关系R中的函数依赖如下图表示•R :A,B →C;B →D;D →E;C →B第一范式规定关系的每一个分量必须是一个不可分的数据项.可以看出,该关系满足第一范式。
如果关系模式R满足第一范式,且它的任何一个非主属性都完全函数依赖于任一个候选码,则R满足第二范式(简记为2NF)。
所以不是第二范式分解成第二范式R1 :A,B →C;C →BR2:B →D;D →E;如果关系模式R满足2NF,并且它的任何一个非主属性都不传递依赖于任何候选码,则称R是第三范式(3NF),记作R∈3NF。
分解成第三范式R1 :A,B →C;C →BR21:B →DR22:D →E•如果关系模式R是1NF,且每个属性都不传递依赖于R的候选码,那么称R是BCNF的模式。
R1 :A,B →C;C →BR21:B →DR22:D →ER1中属性B传递依赖于R的候选码AB,故R1不是BCNF范式关系模式R∈1NF,若X→Y,且Y⊆X 时,X必含有候选码,则R∈BCNF。
R1中C→ B,且B⊆C ,但B不含有任何候选码,故R1不是BCNF范式分解成BCNF范式R11 :A,BR12 :C →BR21:B →DR22:D →E候选码是什么?能够唯一标识一个元组的某一属性或属性组.候选码:(A,B)和(A,C)假设有一个名为参加的关系,该关系有属性:职工(职工名)、工程(工程名)、时数(花费在工程上的小时数)和工资(职工的工资);一个参加记录描述一个职工花费在一个工程上的总时数和他的工资;另外,一个职工可以参加多个工程,多个职工可以参加同一个工程(用A、B、C、D分别代表属性职工、工程、时数和工资)。
请回答如下各问题:1) 确定这个关系的关键字;AB2) 找出这个关系中的所有函数依赖;AB—>C , A—〉D3)指出这个关系上的哪些函数依赖会带来操作异常现象;D对关键字AB的部分函数依赖可能会带来如下问题:数据冗余:一个职工参加多个工程,则职工的工资值会重复;更新异常:当改变职工的工资时,可能会只修改了一部分,从而造成数据不一致;插入异常:当一个职工尚未承担工程,但要插入职工信息(如工资)则不允许(因为没有完整的关键字);删除异常:当某个工程结束,删除工程信息时,可能会将职工信息(如工资)一同删除(如果职工只参加了一项工程)。
实用数据库真题及答案解析数据库是现代信息系统中的核心组成部分,它的重要性在各行各业中都得到了广泛的认可。
对于数据库的理解与应用能力的考察,成为了许多招聘面试中的重要环节之一。
为了帮助大家更好地备考数据库相关的考试,下面将介绍一些实用的数据库真题及答案解析。
1. 数据库的三范式是什么?它们有什么作用?答案解析:数据库的三范式分别为第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。
它们是数据结构设计中的规范,旨在消除冗余数据,提高数据库的数据存储效率。
- 第一范式(1NF)要求数据库中的每个列都是原子性的,不可再拆分。
即每个属性不允许包含多个值。
- 第二范式(2NF)要求数据库中的非主键属性必须完全依赖于主键属性。
- 第三范式(3NF)要求数据库中的非主键属性之间不能存在传递依赖关系。
通过遵循三范式,可以有效地解决数据冗余问题,确保数据库存储的数据一致性和完整性。
2. 简述数据库的ACID特性。
答案解析:ACID是指数据库事务的四个特性,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
- 原子性:事务是一个不可分割的工作单位,要么全部执行,要么全部不执行。
- 一致性:事务执行前后,数据库从一个一致性状态变为另一个一致性状态。
- 隔离性:并发执行的事务之间应该相互隔离,互不影响。
- 持久性:事务一旦提交,对数据库的修改是永久性的,即使系统故障也能够保证数据的持久性。
ACID特性保证了数据库事务的可靠性和数据的完整性。
3. 什么是数据库索引?请简述其作用和使用场景。
答案解析:数据库索引是一种特殊的数据结构,用于加快对数据库表中数据的查找和访问速度。
索引可以根据指定的列或列组合,快速定位到符合条件的数据行,从而提高查询效率。
索引的主要作用有:- 提高数据检索效率:通过索引可以快速定位到满足查询条件的数据,减少了全表扫描的时间。
数据库范式例题范式是一种关系型数据库设计的规范,它是通过对表结构进行优化来消除冗余数据、提高数据存储和操作的效率的。
常见的数据库范式有1NF、2NF、3NF等。
以下是一个例题:假设我们有一个学生信息表,包含以下字段:- 学生编号(Student_ID)- 姓名(Name)- 性别(Gender)- 年龄(Age)- 班级编号(Class_ID)- 班级名称(Class_Name)- 班主任姓名(Teacher_Name)这个表中存在冗余数据,比如班级编号、班级名称和班主任姓名都与班级相关,而不是与学生本身相关。
因此,可以使用范式将这个表优化为更好的结构。
首先,我们可以使用第一范式(1NF)来消除重复的数据,把表分成两个表:学生表和班级表。
学生表包含以下字段:- 学生编号(Student_ID)- 姓名(Name)- 性别(Gender)- 年龄(Age)- 班级编号(Class_ID)班级表包含以下字段:- 班级编号(Class_ID)- 班级名称(Class_Name)- 班主任姓名(Teacher_Name)接下来,我们可以使用第二范式(2NF)来消除部分依赖,即确保每个非主键字段完全依赖于主键。
在学生表中,班级名称和班主任姓名都只与班级相关,因此我们可以把它们从学生表中移除,放到班级表中。
最后,我们使用第三范式(3NF)来消除传递依赖,即确保每个非主键字段都不依赖于其他非主键字段。
在班级表中,班主任姓名只与班级编号相关,而不是与班级名称相关,因此我们可以把班主任姓名从班级表中移到另一个表中。
最终,我们将这个结构优化为三个表:学生表包含以下字段:- 学生编号(Student_ID)- 姓名(Name)- 性别(Gender)- 年龄(Age)- 班级编号(Class_ID)班级表包含以下字段:- 班级编号(Class_ID)- 班级名称(Class_Name)教师表包含以下字段:- 班级编号(Class_ID)- 班主任姓名(Teacher_Name)通过以上的优化,我们消除了冗余数据、提高了存储和操作的效率,并且让数据库结构更加清晰和规范。
数据库范式例题1. 介绍数据库范式是一种规范,用于设计和组织关系型数据库中的表结构。
它定义了关系型数据库中各个属性之间的关系和依赖。
范式分为一至五个等级,每个等级都有其独特的规则和要求。
范式的目标是最大程度地减少冗余和数据插入、更新和删除的异常。
在本文中,我们将通过一个例题来说明数据库范式的概念、规则和应用。
我们将讨论如何将一个未经范式化的数据库转化为符合第三范式的数据库。
2. 范例数据库设计假设我们有一个关系型数据库,用于存储学生和课程的相关信息。
该数据库包含以下表格:Students(学生)学生编号姓名课程编号课程成绩1 张三 1 851 张三2 902 李四 2 953 王五 1 80Courses(课程)课程编号课程名称1 数学2 英语3 物理3. 第一范式(1NF)根据第一范式的要求,每个属性的值都应该是原子性的,不可再分的。
在我们的范例数据库中,符合第一范式的要求,因为每个表格中的每个属性都是原子性的。
4. 第二范式(2NF)根据第二范式的要求,非键属性必须完全依赖于键属性。
在我们的范例数据库中,如果我们将学生表拆分成学生表和学生成绩表,可以更好地满足第二范式的要求。
学生表学生编号姓名1 张三2 李四3 王五学生成绩表学生编号课程编号课程成绩1 1 851 2 902 2 953 1 805. 第三范式(3NF)根据第三范式的要求,非键属性不应该存在传递依赖关系。
在我们的范例数据库中,学生表和学生成绩表已经符合第三范式的要求,因为它们没有属性之间的传递依赖关系。
6. 总结通过以上示范,我们了解了数据库范式的概念和应用。
范式化的数据库设计可以提高数据的一致性、完整性和可维护性。
在实际应用中,根据数据的特点和需求,我们可以选择适当的范式等级来设计和优化数据库结构。
范式化并不是唯一的选择,有时候为了提高数据库的查询性能,我们需要进行冗余设计,但也需要权衡冗余带来的数据更新复杂度。
在设计数据库时,我们需要根据实际情况综合考虑各种因素,以达到最佳的数据库设计方案。
怎么判断一二三范式例题在关系型数据库设计中,范式是指对关系模式进行规范化的过程。
通过范式化可以消除数据冗余,提高数据的有效性和可靠性。
常见的范式有三种:第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。
二、如何判断一二三范式1. 第一范式第一范式是指所有的属性都是原子性的,即属性不可再分。
例如,一个学生的姓名和年龄应分成两个属性,而不是一个属性。
2. 第二范式第二范式是指每个非主属性都完全依赖于主键,而不是部分依赖。
例如,如果一个订单编号与订单日期、客户编号、客户姓名、产品编号、产品名称都有关系,那么应将订单编号作为主键,将客户编号和产品编号作为外键,分别与客户和产品表关联。
3. 第三范式第三范式是指每个非主属性都不依赖于其他非主属性。
例如,如果一个员工表中包含员工号、员工姓名、部门号、部门名称、工资等属性,那么应该将部门号和部门名称作为单独的部门表,避免数据冗余。
三、例题1. 判断是否符合第一范式一个订单表包含订单号、客户姓名、客户电话、产品名称、产品单价、购买数量、订单总价。
该表是否符合第一范式?答:该表不符合第一范式,因为客户姓名和客户电话应该分成两个属性。
2. 判断是否符合第二范式一个员工表包含员工号、员工姓名、部门名称、部门地址、工资等属性。
该表是否符合第二范式?答:该表不符合第二范式,因为部门名称和部门地址与部门号有关系,应该将部门名称和部门地址分成一个单独的部门表。
3. 判断是否符合第三范式一个订单表包含订单号、客户姓名、产品名称、产品单价、购买数量、订单总价、客户地址等属性。
该表是否符合第三范式?答:该表不符合第三范式,因为订单表中的客户地址与客户姓名有关系,应该将客户地址分离成一个单独的客户表。
数据库范式分解例题及解析
数据库范式是一种设计数据库表结构的理论,旨在减少数据冗
余并确保数据的一致性和完整性。
数据库范式分解是指将一个不符
合范式要求的关系模式分解成若干个符合范式要求的关系模式的过程。
下面我将以一个简单的例题来解析数据库范式分解的过程。
假设有一个学生信息管理系统,其中有一个包含学生姓名、年龄、性别和所在班级的关系模式(表)StuInfo。
现在我们来分解这
个关系模式,使其符合第三范式(3NF)的要求。
首先,我们观察到StuInfo表中存在部分数据冗余。
比如,一
个班级内可能有多个学生,如果将班级信息也包含在StuInfo表中,就会导致班级信息的重复。
因此,我们需要将班级信息从StuInfo
表中分离出来,创建一个新的班级信息表ClassInfo,包含班级ID
和班级名称两个字段。
接下来,我们需要考虑学生信息之间的函数依赖关系。
假设学
生姓名和年龄之间存在函数依赖关系,即一个学生的姓名唯一确定
其年龄,那么我们需要将这部分数据分离出来,创建一个新的学生
信息表Student,包含学生ID、姓名和年龄三个字段。
最后,我们再来看性别字段。
由于性别是一个固定的取值范围(男或女),不会因为其他属性的变化而改变,因此性别并不依赖于其他属性。
所以,性别字段可以留在StuInfo表中,不需要再进行分解。
通过以上分解过程,我们将原来的StuInfo表分解为了三个符合3NF的表,Student表、ClassInfo表和经过部分分解的StuInfo 表。
这样的设计能够减少数据冗余,确保数据的一致性和完整性,提高数据库的性能和可维护性。
总的来说,数据库范式分解是一个重要的数据库设计过程,通过合理的分解可以使数据库表结构更加规范化,减少数据冗余,确保数据的一致性和完整性。
在实际应用中,需要根据具体的业务需求和数据特点来进行范式分解,以达到最佳的数据库设计效果。