统计学数据分布特征描述
- 格式:pptx
- 大小:806.54 KB
- 文档页数:82

统计学测量数据分布的测度描述包括以下几种常见的描述方法:
1.平均数:也称为均值,是指一组数据中所有数值的总和除以数
据个数的结果。
平均数可以用来描述一组数据的集中趋势。
2.中位数:也称为中值,是指一组数据中所有数值按大小排序后,
位于中间的那个数值,如果数据个数为偶数,则中位数为中间两个数的平均数。
中位数可以用来描述一组数据的集中趋势。
3.众数:也称为模数,是指一组数据中出现次数最多的数值。
众
数可以用来描述一组数据的集中趋势,特别是对于呈现多峰分布的数据。
4.极差:是指一组数据中最大值与最小值的差值。
极差可以用来
描述一组数据的离散程度。
5.方差:是指一组数据中每个数值与平均数的差的平方和除以数
据个数的结果。
方差可以用来描述一组数据的离散程度。
6.标准差:是指方差的正平方根。
标准差可以用来描述一组数据
的离散程度,同时也可以用来进行数据的比较。
7.百分位数:是指一组数据中某个百分比的数值。
例如,50%的百
分位数就是中位数。
百分位数可以用来描述一组数据的分布情况,比如数据的偏态和尾重程度。
这些测度描述可以帮助我们更好地理解和分析一组数据的特征和分布情况。


第3章数据分布特征的描述[引例]根据国家统计局对全国31个省(自治区、直辖市)7.4万户农村居民家庭和6.6万户城镇居民家庭的抽样调查,2011年城乡居民收入增长情况如下1:2011年全国农村居民人均纯收入6977元,比上年增加1058元,增长17.9%。
剔除价格因素影响,实际增长11.4%,增速同比提高0.5个百分点。
其中,人均工资性收入2963元,同比增加532元,增长21.9%。
工资性收入对全年农村居民增收的贡献率达50.3%。
工资性收入占农村居民纯收入的比重达42.5%,同比提高1.4个百分点。
2011年农村居民人均纯收入中位数为6194元,比上年增加995元,增长19.1%。
农村居民人均纯收入中位数比人均纯收入低783元,但增速高1.2个百分点。
2011年城镇居民人均总收入23979元,其中,人均可支配收入21810元,比上年增加2701元,增长14.1%。
剔除价格因素影响,城镇居民人均可支配收入实际增长8.4%,增速同比提高0.6个百分点。
2011年城镇居民人均可支配收入中位数为19118元,比上年增加2279元,增长13.5%。
城镇居民人均可支配收入中位数比人均可支配收入低2692元,增速低0.6个百分点。
主要是受最低工资标准、城镇居民基本养老金和离退休金以及最低生活保障标准提高影响,城镇低收入户收入增速较高;同时高收入户也保持了较快的增长速度,所以中等收入户增速相对较慢。
2011年城镇居民人均可支配收入与农村居民人均纯收入之比为3.13:1,2010年该收入比为3.23:1。
本章小结1.总量指标是说明现象总规模和总水平的数值,又称为绝对数。
绝对数的计量单位有实物单位和价值量单位。
按反映总体内容不同,总量指标可分为总体单位总量和总体标志总量;按反映的时间状况不同,总量指标可分为时期指标和时点指标。
2.将两个有联系的数值对比得到的比率称为相对数。
相对数既有无名数形式也有复名数形式。
根据研究目的和对比基础的不同,有结构相对数、比例相对数、计划完成程度相对数、比较相对数、动态相对数和强度相对数等。



第3章统计学数据分布特征的描述统计学是一门研究收集、分析和解释数据的学科。
在统计学中,数据分布特征的描述是指通过一系列统计量和图表来描述数据的集中趋势、离散程度和分布形态等特征。
数据的集中趋势描述了数据的平均水平或中心。
常用的统计量有平均值、中位数和众数。
平均值是将所有观测值相加然后除以观测值的总数,它能够反映数据的总体平均水平。
然而,当数据包含异常值时,平均值的计算结果可能会受到影响。
因此,中位数和众数在这种情况下被认为是更稳健的集中趋势度量。
中位数是将数据按大小排序,然后找出中间位置的观测值。
众数是数据中出现次数最多的观测值。
数据的离散程度描述了数据的变异程度或分散程度。
常用的统计量有方差、标准差和四分位差。
方差是观测值与均值之间差异的平方的平均值,它反映了数据的总体离散程度。
标准差是方差的平方根,用于衡量数据的波动性。
四分位差是数据的上四分位数和下四分位数之差,它描述了数据的中间50%的变异程度。
数据的分布形态描述了数据的形状和对称性。
常用的分布形态有正态分布、偏态分布和峰态分布。
正态分布是最常见的分布形态,其特点是对称、钟形曲线。
偏态分布是指数据分布不对称的情况,主要分为正偏态和负偏态。
正偏态分布意味着数据的尾部偏向右侧,负偏态分布则意味着数据的尾部偏向左侧。
峰态分布用于描述数据的峰值的尖锐程度,主要分为正态分布、高峰态和低峰态。
除了统计量,还可以使用图表来对数据分布特征进行描述。
常用的图表包括直方图、箱线图和散点图。
直方图是通过将数据分组并在坐标轴上绘制各组的频率或相对频率来展示数据的分布形态。
箱线图通过绘制数据的分位数和异常值来展示数据的中位数、四分位数和离群观测值。
散点图用于展示两个变量之间的关系,特别适用于发现变量之间的相关性和异常值。
综上所述,统计学中的数据分布特征描述是通过一系列统计量和图表来描述数据的集中趋势、离散程度和分布形态等特征。
这些描述能够帮助我们更好地理解数据,并对数据进行分析和解释。

数据分布特征的描述讲解数据分布特征描述是统计学中对一组数据进行概括和描述的过程。
我们通常使用中心趋势和离散程度来描述数据分布的特征。
中心趋势是指数据集中的一个值,代表数据的代表性,常用的中心趋势措施包括均值、中位数和众数。
离散程度则是指数据的变异程度,包括范围、方差、标准差和四分位距等。
首先,均值是一组数据的中心趋势的一个常用度量。
它是所有数据值的总和除以数据的个数。
均值具有很强的代表性,尤其对于正态分布的数据而言。
均值的计算公式为:mean = (x1 + x2 + ... + xn) / n。
其次,中位数是数据集中的一个特殊值,将数据按照大小排列后,处于中间位置的数即为中位数。
中位数不受极端值的影响,能够更好地反映数据的集中趋势。
对于偶数个数据,中位数为中间两个数的平均值;对于奇数个数据,中位数为中间一个数。
中位数的计算可以通过将数据按照大小排列,然后找到中间位置的数来得出。
此外,众数是数据集中出现频率最高的值,可以是一个或多个。
众数对于描述数据的集中趋势也具有一定的代表性。
众数的计算可以通过建立频数分布表,然后找到出现次数最多的数来得出。
除了中心趋势,离散程度也是描述数据分布特征的重要度量。
范围是测量数据分布范围的最简单方式,它是一组数据中的最大值减去最小值。
范围对于描述数据的离散程度有一定的指示作用,但它受极端值的影响较大,不能完全反映整体数据的变异程度。
方差是衡量数据分布离散程度的一种指标,它表示数据偏离均值的程度。
方差的计算公式为:variance = Σ(xi - mean)² / n,其中xi为每个数据值,mean为均值,n为数据个数。
方差越大,数据的离散程度也越大。
标准差是方差的正平方根,它具有和原始数据单位一致的度量标准,常用于度量数据的波动性。
标准差的计算公式为:standard deviation = √variance。
四分位距是一种度量数据分布离散程度的方法,它是数据按从小到大排列后,第25%分位数和第75%分位数之间的差值。
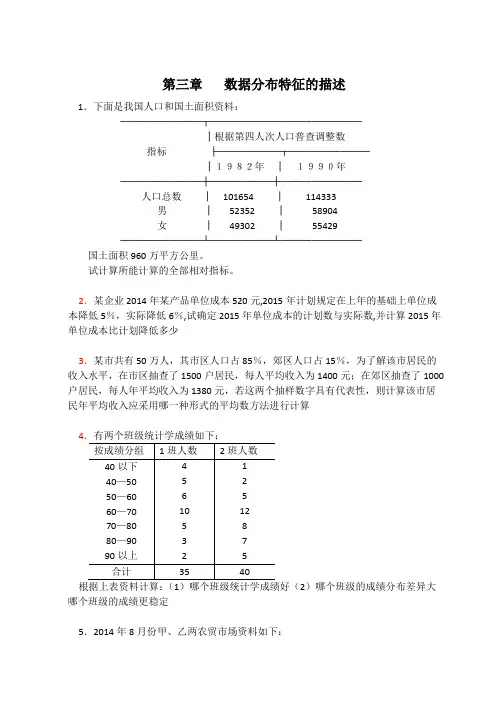
第三章数据分布特征的描述1.下面是我国人口和国土面积资料:────────┬───────────────│根据第四人次人口普查调整数指标├──────┬────────│1982年│1990年────────┼──────┼────────人口总数│101654 │114333男│52352 │58904女│49302 │55429────────┴──────┴────────国土面积960万平方公里。
试计算所能计算的全部相对指标。
2.某企业2014年某产品单位成本520元,2015年计划规定在上年的基础上单位成本降低5%,实际降低6%,试确定2015年单位成本的计划数与实际数,并计算2015年单位成本比计划降低多少3.某市共有50万人,其市区人口占85%,郊区人口占15%,为了解该市居民的收入水平,在市区抽查了1500户居民,每人平均收入为1400元;在郊区抽查了1000户居民,每人年平均收入为1380元,若这两个抽样数字具有代表性,则计算该市居民年平均收入应采用哪一种形式的平均数方法进行计算4根据上表资料计算:(1)哪个班级统计学成绩好(2)哪个班级的成绩分布差异大哪个班级的成绩更稳定5.2014年8月份甲、乙两农贸市场资料如下:────┬──────┬─────────┬─────────品种│价格(元/斤)│甲市场成交额(万元)│乙市场成交量(万斤)────┼──────┼─────────┼─────────甲│││2乙│││1丙│││1────┼──────┼─────────┼─────────合计│──││4────┴──────┴─────────┴─────────试问哪一个市场农产品的平均价格较高并说明原因。
6.某车间有甲、乙两个生产组,甲组平均每个工人的日产量36件,标准差件。
乙组工人资料如下:要求:(1)计算乙组平均每个工人的日产量和标准差。
(2)比较甲、乙两个生产小组哪个组的平均日产量更有代表性比较哪组的产量更稳定比较哪组的产量差异大第四章抽样调查检验结果如下:1.某进出口公司出口茶叶,为检查其每包规格的重量,抽取样本100包,(1)确定每包平均重量的抽样平均误差和极限误差;(2)估计这批茶叶每包平均重量的范围,确定是否达到规格要求。

数据的分布特征知识点数据的分布特征是统计学中非常重要的概念,它描述了数据集中各个数据值在整个数据集中的分布情况。
通过了解数据的分布特征,我们可以更好地理解数据的组织形式,并从中获取有关数据的相关信息。
本文将介绍数据的分布特征的几个重要知识点,包括均值、中位数、众数、标准差以及偏度和峰度。
1. 均值均值是数据集中所有数据值的平均数。
计算均值的方法是将所有数据值相加,然后除以数据的总个数。
均值可以反映数据集中数据值的集中趋势,当数据集中的数据值比较平均分布时,均值对数据的代表性较好。
2. 中位数中位数是将数据集中的所有数据值按照大小排列后的中间值。
如果数据个数为奇数,则中位数是中间的那个数;如果数据个数为偶数,则中位数是中间两个数的平均值。
中位数不受异常值的影响,更能反映数据的中心位置。
3. 众数众数是数据集中出现次数最多的数值。
一个数据集可以有一个或多个众数,或者没有众数。
众数可以用来表示数据集中的典型值,特别适用于表示分类数据。
4. 标准差标准差是用来衡量数据离均值的距离。
标准差越大,数据分布越分散;标准差越小,数据分布越集中。
标准差可以反映数据的离散程度,对于比较不同数据集之间的离散程度也非常有用。
5. 偏度和峰度偏度和峰度用来描述数据分布的形态。
偏度衡量了数据分布的对称性,正偏度表示数据分布偏向右侧,负偏度表示数据分布偏向左侧,而零偏度表示数据分布接近对称。
峰度衡量了数据分布的尖锐程度,正峰度表示数据分布较尖锐,负峰度表示数据分布较平坦,而零峰度表示数据分布接近正态分布。
总结:数据的分布特征对于理解和分析数据至关重要。
通过了解数据的均值、中位数、众数、标准差、偏度和峰度等知识点,我们可以更好地描述和解读数据。
这些分布特征可以帮助我们揭示数据背后的规律,并为数据分析和决策提供依据。
在实际应用中,我们可以根据数据的特点选择适当的描述方法,进而更好地分析和利用数据。

第三章 数据分布特征的描述(一)教学目的通过本章的学习,使同学们正确理解各种指标的概念及计算方法,学会运用相应的统计指标对数据的分布特征进行分析说明。
(二)基本要求使学生熟练掌握数据分布特征的描述方法。
(三)教学要点1、集中趋势的测度指标及其计算方法;2、离散趋势的测度指标及其计算方法;3、总体分布的偏度与峰度的测度。
(四)教学时数9——10课时(五)学习内容本章共分三节:第一节 数据分布集中趋势的测定一、定类数据集中趋势的测度——众数(Mode)(一) 概念要点众数是指一组数据中出现次数最多的变量值,用表示。
从变量分布的角度看,众数是具有明显集中趋势点的数值,一组数据分布的最高峰点所对应的数值即为众数。
当然,如果数据的分布没有明显的集中趋势或最高峰点,众数也可以不存在;如果有多个高峰点,也就有多个众数。
1.集中趋势的测度值之一2.出现次数最多的变量值3.不受极端值的影响4.可能没有众数或有几个众数5.主要用于定类数据,也可用于定序数据和数值型数据众数的不唯一性:无众数原始数据: 10 5 9 12 6 8一个众数原始数据: 6 5 9 8 5 5多于一个众数原始数据: 25 28 28 36 42 42(二)众数的计算根据未分组数据或单变量值分组数据计算众数时,我们只需找出出现次数最多的变量值即为众数。
对于组距分组数据,众数的数值与其相邻两组的频数分布有一定的关系,这种关系可作如下的理解:设众数组的频数为,众数前一组的频数为,众数后一组的频数为。
当众数相邻两组的频数相等时,即=,众数组的组中值即为众数;当众数组的前一组的频数多于众数组后一组的频数时,即>,则众数会向其前一组靠,众数小于其组中值;当众数组后一组的频数多于众数组前一组的频数时,即<,则众数会向其后一组靠,众数大于其组中值。
基于这种思路,借助于几何图形而导出的分组数据众数的计算公式如下:下限公式:(3.1)上限公式:(3.2)式中:表示众数所在组的下限;表示众数所在组的上限;表示众数所在组的组距。

第3章数据分布特征的描述数据分布特征的描述是统计学中的重要概念之一,它用来描述随机变量的概率分布或样本数据的分布情况。
通过对数据分布特征的描述,我们可以更好地理解数据的性质,为后续的数据分析和决策提供支持。
一、数据分布特征的描述方法常用的数据分布特征描述方法有:位置参数、离散程度参数、偏态参数和峰态参数。
1.位置参数:用来描述数据集的中心位置,最常用的位置参数是平均值和中位数。
平均值是所有数据值的总和除以观测次数,它具有对异常值敏感的特点,所以在存在异常值的情况下,中位数更适合作为位置参数。
2.离散程度参数:用来描述数据集的离散程度或变异程度,最常用的离散程度参数是方差和标准差。
方差是数据偏离平均值的平均平方,标准差是方差的平方根。
方差和标准差越大,代表数据的离散程度越大。
3.偏态参数:用来描述数据分布的对称性或偏斜性。
正偏态表示数据分布向右偏斜,负偏态表示数据分布向左偏斜。
常用的偏态参数是偏态系数,其表示为偏态系数=3*(平均值-中位数)/标准差,偏态系数为0时表示对称分布,大于0表示正偏态,小于0表示负偏态。
4.峰态参数:用来描述数据分布的尖度或平顶性。
正常分布的峰态参数为3,表示正态分布的峰度,大于3表示尖峰分布,小于3表示平顶分布。
二、常见的数据分布特征1. 正态分布(Normal Distribution):正态分布是最常见的概率分布之一,也是自然界中许多现象的分布形式。
正态分布的特点是对称的钟形曲线,均值和中位数相等,偏态系数为0,峰态系数为32. 偏态分布(Skewed Distribution):偏态分布是指数据分布不对称的情况,其中正偏态分布是右偏的,负偏态分布是左偏的。
正偏态分布的偏态系数大于0,负偏态分布的偏态系数小于0。
3. 峰态分布(Kurtosis Distribution):峰态分布是指数据分布的尖度或平顶性,峰态系数大于3表示尖峰分布,峰态系数小于3表示平顶分布。
第三章统计数据分布特征的描述统计数据分布特征的描述是统计学中非常重要的一个概念,它用于对数据进行系统化的描述和分析。
统计数据分布特征的描述包括位置参数、散布参数和形状参数。
位置参数描述了数据集中心位置的特征。
最常用的位置参数是均值和中位数。
均值是指所有数据值的总和除以数据个数,它能够反映数据集的平均水平。
中位数是将数据值按大小排序后的中间值,它能够反映数据集的中心位置。
均值对异常值比较敏感,中位数能够较好地排除异常值的干扰。
散布参数描述了数据集的离散程度。
最常用的散布参数是方差和标准差。
方差是指每个数据值与均值之差的平方和的平均值,它能够反映数据集的离散程度。
标准差是方差的平方根,它与数据的单位相一致,常用于衡量数据的波动性。
方差和标准差越大,表示数据的离散程度越大。
形状参数描述了数据集的分布形状。
常用的形状参数包括偏度和峰度。
偏度是指数据分布的不对称程度,大于0表示右偏,小于0表示左偏,等于0表示对称。
偏度能够反映数据集的分布形态。
峰度是指数据分布的尖锐程度,大于0表示尖锐,小于0表示平坦,等于0表示与正态分布相似。
峰度能够反映数据集的尖峰或扁平程度。
除了这些常见的参数之外,还有其他一些描述统计数据分布特征的方法,如四分位数和箱线图。
四分位数是将数据分为四等分的值,它包括上四分位数、下四分位数和中位数。
上四分位数是四分之三分位数,下四分位数是四分之一分位数。
箱线图是以箱子和线段的形式展示数据分布特征,箱子的上边界和下边界分别代表上四分位数和下四分位数,箱子的中线代表中位数,箱子的长度代表数据的离散程度。
统计数据分布特征的描述对于研究数据的特征、提取有效信息以及进行统计推断都非常重要。
了解数据的位置、散布和形状特征能够帮助研究者更好地理解数据集的性质和规律。
在实际应用中,统计数据分布特征的描述还可以帮助决策者进行决策,例如对于质量控制的判断和产品的质量评估等。
综上所述,统计数据分布特征的描述是对数据集进行系统化描述和分析的重要工具。
第三章统计数据分布特征的描述统计数据分布特征的描述是统计学中的重要概念之一、它是通过对数据进行整理、组织和分析来了解数据的分布情况,帮助我们更好地理解数据的特点和趋势。
一、数据分布特征的描述方法在统计学中,数据分布特征主要通过以下两种方法进行描述:1.图形描述法:通过绘制图表来展示数据的分布情况。
常见的图形描述方法有直方图、条形图、饼图、箱线图等。
直方图是一种用于展示数据分布的图形。
它将其中一范围内的数据分成若干个等宽的区间,并统计每个区间中数据的频数或频率,然后绘制柱状图来表示。
箱线图是一种用于展示数据分布和异常值的图形。
它将数据划分为四个部分:最大值、上四分位数、中位数、下四分位数和最小值,并通过画出盒子和须来表示数据的分布情况。
2.数值描述法:通过使用统计指标和参数来描述数据的分布情况。
常见的数值描述方法有均值、中位数、众数、标准差、方差等。
均值是指将所有数据相加后再除以数据的总个数的得到的值,代表了数据的平均水平。
中位数是指将数据按大小排序后,处于中间位置的值,代表了数据的中心位置。
众数是指数据集中出现次数最多的值,代表了数据的集中趋势。
标准差是指数据在均值附近的波动程度,代表了数据的离散程度。
方差是指数据与均值之间的平均差的平方的平均值,代表了数据的离散程度。
二、数据分布特征的描述步骤要进行数据分布特征的描述,一般需要进行以下步骤:1.数据的整理和搜集:搜集所需的数据,并将其整理成适合进行分析的形式。
2.确定描述方法:根据数据的特点和目标,选择适当的图形描述法或数值描述法。
3.进行描述分析:根据所选的描述方法,对数据进行分析和计算,得出相应的描述结果。
4.解释和应用:根据描述结果,解释数据的分布特征,并根据需要进行相应的应用。
三、数据分布特征的描述应用数据分布特征的描述在实际应用中有很多用途,以下是几个常见的应用:1.判断数据是否符合其中一种分布:通过对数据的分布特征进行描述,可以判断数据是否符合正态分布或其他特定的分布形式。
第四章 静态指标分析法(一)一、填空题1、数据分布集中趋势的测度值(指标)主要有、和。
其中和用于测度品质数据集中趋势的分布特征,用于测度数值型数据集中趋势的分布特征。
2、标准差是反映的最主要指标(测度值)。
3、几何平均数是计算和的比较适用的一种方法。
4、当两组数据的平均数不等时,要比较其数据的差异程度大小,需要计算。
5、在测定数据分布特征时,如果M M e X 0==,则认为数据呈分布。
6、当一组工人的月平均工资悬殊较大时,用他们工资的比其算术平均数更能代表全部工人工资的总体水平。
二.选择题单选题:1.反映的时间状况不同,总量指标可分为( )A 总量指标和时点总量指标B 时点总量指标和时期总量指标C 时期总量指标和时间指标D 实物量指标和价值量指标2、某厂1999年完成产值200万元,2000年计划增长10%,实际完成了231万元,超额完成( )A 5.5%B 5%C 115.5%D 15.5%3、在同一变量数列中,当标志值(变量值)比较大的次数较多时,计算出来的平均数( )A 接近标志值小的一方B 接近标志值大的一方C 接近次数少的一方D 接近哪一方无法判断4、在计算平均数时,权数的意义和作用是不变的,而权数的具体表现( )A 可变的B 总是各组单位数C 总是各组标志总量D 总是各组标志值 5、1998年某厂甲车间工人的月平均工资为520元,乙车间工人的月平均工资为540元,1999年各车间的工资水平不变,但甲车间的工人占全部工人的比重由原来的40%提高到了60%,则1999年两车间工人的总平均工资比1998年( )A 提高B 不变C 降低D 不能做结论 6、在变异指标(离散程度测度值)中,其数值越小,则( )A 说明变量值越分散,平均数代表性越低B 说明变量值越集中,平均数代表性越高C 说明变量值越分散,平均数代表性越高D 说明变量值越集中,平均数代表性越低7、有甲、乙两数列,已知甲数列:07.7,70==甲甲σX ;乙数列:41.3,7==乙乙σX 根据以上资料可直接判断( )A 甲数列的平均数代表性大B 乙数列的平均数代表性大C 两数列的平均数代表性相同D 不能直接判别8、杭州地区每百人手机拥有量为90部,这个指标是 ( )A 、比例相对指标B 、比较相对指标C 、结构相对指标D 、强度相对指标 9、某组数据呈正态分布,计算出算术平均数为5,中位数为7,则该数据分布为 ( ) A 、左偏分布 B 、右偏分布 C 、对称分布 D 、无法判断10、加权算术平均数的大小 ( )A 主要受各组标志值大小的影响,与各组次数多少无关;B 主要受各组次数多少的影响,与各组标志值大小无关;C 既与各组标志值大小无关,也与各组次数多少无关;D 既与各组标志值大小有关,也受各组次数多少的影响11、已知一分配数列,最小组限为30元,最大组限为200元,不可能是平均数的为 ( ) A 、50元 B 、80元 C 、120元 D 、210元12、比较两个单位的资料,甲的标准差小于乙的标准差,则 ( ) A 两个单位的平均数代表性相同 B 甲单位平均数代表性大于乙单位C 乙单位平均数代表性大于甲单位D 不能确定哪个单位的平均数代表性大 13、若单项数列的所有标志值都增加常数9,而次数都减少三分之一,则其算术平均数 ( ) A 、增加9 B 、增加6C 、减少三分之一 D 、增加三分之二 14、如果数据分布很不均匀,则应编制( )A 开口组B 闭口组C 等距数列D 异距数列 15、计算总量指标的基本原则是:( ) A 总体性B 全面性C 同质性D 可比性16、某企业的职工工资分为四组:800元以下;800-1000元;1000—1500元;1500以上,则1500元以上这组组中值应近似为()A1500元 B 1600元 C 1750元D 2000元 17、统计分组的首要问题是( )A 选择分组变量和确定组限B 按品质标志分组C 运用多个标志进行分组,形成一个分组体系D 善于运用复合分组18、某连续变量数列,其末组为开口组,下限为200,又知其邻组的组中值为170,则末组组中值为( )A 230B 260C 185D 215 19、分配数列中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种分布的类型是( )A 钟型分布B U 型分布C J 型分布D 倒J 型分布 20、要了解上海市居民家庭的开支情况,最合适的调查方式是:() A 普查B 抽样调查C 典型调查D 重点调查21、已知两个同类企业的职工平均工资的标准差分别为5元和6元,而平均工资分别为3000元,3500元则两企业的工资离散程度为 ( )A 甲大于乙B 乙大于甲C 一样的D 无法判断 22、加权算术平均数的大小取决于( )A 变量值B 频数C 变量值和频数D 频率23、如果所有标志值的频数都减少为原来的1/5,而标志值仍然不变.那么算术平均数( ) A 不变 B 扩大到5倍 C 减少为原来的1/5 D 不能预测其变化 24、 计算平均比率最好用 ( )A 算术平均数B 调和平均数C 几何平均数D 中位数25、若两数列的标准差相等而平均数不同,在比较两数列的离散程度大小时,应采用() A 全距 B 平均差 C 标准差 D 标准差系数26、若n=20,∑∑==2080,2002x x ,标准差为( )A 2B 4C 1.5D 327、已知某总体3215,3256==eMM,则数据的分布形态为( )A左偏分布B正态分布 C 右偏分布DU型分布28、一次小型出口商品洽谈会,所有厂商的平均成交额的方差为156.25万元,标准差系数为14.2%,则平均成交额为( )万元A11 B 177.5 C 22.19 D 8826、欲粗略了解我国钢铁生产的基本情况,调查了上钢、鞍钢等十几个大型的钢铁企业,这是()A普查B重点调查C典型调查D抽样调查多选题:1.某企业计划2000年成本降低率为8%,实际降低了10%。