怎么查找一个基因的启动子序列
- 格式:doc
- 大小:791.50 KB
- 文档页数:17


确定启动子位置的方法(一)确定启动子位置引言启动子是指基因的一个特殊区域,它在基因转录过程中起着重要的作用。
确定启动子位置是基因组学研究中的一项重要任务,对于深入理解基因的调控机制有着非常重要的意义。
本文将介绍几种常见的方法来确定启动子位置。
1.实验方法5’ RACE5’ RACE (Rapid Amplification of cDNA Ends) 是一种常用的实验方法,用于确定基因的启动子位置。
该方法通过引物扩增方法,在未知启动子区域的5’端合成一条cDNA链,并通过PCR扩增获得启动子序列。
5’ RACE在启动子区域进行测序,可获得启动子的精确位置。
Chromatin Immunoprecipitation (ChIP)ChIP是一种通过抗体和染色质上的特定蛋白结合来确定启动子位置的方法。
该方法首先通过交联和剪切处理来固定染色质上的蛋白质-DNA复合物,然后使用特定的抗体来免疫沉淀(IP)所要分析的蛋白质,最后通过PCR或测序来检测与启动子相关的DNA序列。
2.计算方法基于序列保守性的方法基于序列保守性的方法通过比对物种间的基因组序列来确定启动子位置。
这种方法假设启动子处的序列在不同物种间具有高度的保守性,因此可以通过比对序列中的保守区域来确定启动子的位置。
基于转录因子结合位点的方法许多转录因子结合在启动子区域,因此基于转录因子结合位点的方法可以帮助确定启动子位置。
通过分析转录因子结合位点的分布情况,并结合表观遗传学修饰等信息,可以预测启动子的位置。
基于表达谱和转录本结构的方法基于表达谱和转录本结构的方法可以通过分析基因的表达谱和转录本结构来确定启动子位置。
这种方法假设在基因的表达谱和转录本结构中存在着与启动子相关的特征,通过分析这些特征可以推断出启动子的位置。
总结确定启动子位置是基因组学研究中的一项重要任务。
本文介绍了几种常见的方法,包括实验方法和计算方法。
实验方法包括5’ RACE 和ChIP等,而计算方法则包括基于序列保守性、转录因子结合位点和表达谱转录本结构等方法。

干货7个步骤教你找到启动子
作者:解螺旋·子非鱼
如需转载请注明来源:解螺旋·医生科研助手
导语
看到一大串密码一样的序列,要怎么找出启动子呢?其实很简单,也就7步,跟着小鱼做就行。
师弟对着电脑上的一大串序列发呆,小鱼问道,“师弟,你这是在格物致知吗?”
“没有啦,我在想怎么把这个基因启动子找出来。
”
“试试用Map viewer吧!”
下面小鱼就以人的K-RAS基因为例讲述一下找基因启动子序列的具体操作步骤:
1.打开NCBI的Map viewer页面,
/mapview/index.html
2.点击“GO”出现如下页面:
3.出现下图,RAS参考序列给出了两个,序列有微小的差异,但总体来说基本相同。
现在普遍采用的是“reference”那个序列。
4.点击上述两条序列第一条序列(即12 reference)对应的“Genes seq”,出现新的页面,点击下图出现的“Download/ViewSequence/Evidence ”,即可下载查看序列等功能。
5.出现的页面提示K-ras基因在染色体上的位置:
6.因为启动子一般在-2000~+200区域,把页面中的参数修改一下:
7.那么就得到K-ras的启动子区域,如下图:。


基因的启动⼦序列,你是怎么找到的?启动⼦(promoter)是与RNA聚合酶结合并能起始mRNA合成的序列。
UTR(Untranslated Regions):即⾮翻译区,是信使RNA(mRNA)分⼦两端的⾮编码⽚段。
5'UTR从mRNA起点的甲基化鸟嘌呤核苷酸帽延伸⾄AUG起始密码⼦,3'UTR从编码区末端的终⽌密码⼦延伸⾄多聚A尾巴(Poly-A)的末端。
那今天我们就和⼤家说说如何⽤万能的PubMed来查找出基因的启动⼦序列~
然后我们可以直接在搜索栏进⾏查找⾃⼰想要的基因
以IL17A为例进⾏搜索
我们点开第⼆天进⾏查看说明
结果中⾸先说明了这个基因的主要内容
在这,我们可以看见这个基因的⼀些基本信息
我们在这选择Tools中的Sequence Text View
可以看见,这是基因的⼀些信息,同时,我们还能查找到相应的区域
选择FASTA
在这,我们就能看见promoter的相关区域,还能查找到不同位置区域的基因。
找到之后,复制出来,就是我们需要的启动⼦序列了~。

如何找一个基因的启动子序列呢一个基因的启动子序列是一个基因组区域,位于基因的上游,并能够识别和结合转录因子,调控基因的转录活性。
寻找一个基因的启动子序列可以通过多种方法和技术来进行。
1. 基因组数据挖掘:最简单的方法是使用公开的基因组数据库,例如Ensembl、NCBI等,使用基因名或序列信息目标基因,并获取其序列信息。
这些数据库通常会提供基因的起始位置和上游区域的信息。
2.序列比对和多序列比较:如果基因组数据库中没有目标基因的启动子序列信息,可以通过对已知相关物种的基因组进行序列比对来获取启动子序列。
过去研究或其他相关文献中可能已经报道了该基因位点的启动子信息,可以通过多序列比较来找到高度保守的区域进行分析。
3.实验方法:寻找基因的启动子序列也可以通过实验方法来进行。
以下是几个常用的实验方法:-基因克隆:通过PCR扩增目标基因的上游区域,然后将PCR产物克隆到适当的载体中进行测序。
从测序结果中截取相应的序列作为启动子序列。
- 5' RACE(Rapid Amplification of cDNA Ends):通过5' RACE技术,可以找到目标基因的转录起始位点,从而确定启动子序列。
这种方法从mRNA上游端引导逆转录聚合酶链式反应(RT-PCR),然后再通过测序获取启动子序列。
-转录组学方法:RNA测序和转录组学方法可以检测到基因的转录产物,从而很大程度上能够帮助确定启动子序列。
RNA测序可以生成从基因的5'端到3'端的转录产物的序列信息,因此可以利用这些数据来识别基因的启动子区域。
4. 计算方法:计算方法可以利用一些生物学特征或机器学习算法来预测基因的启动子序列。
例如,启动子序列通常富含一些特定的DNA序列模式,如TATA box、CAAT box和GC box等。
利用这些DNA序列模式的分布和相互作用关系,可以预测和确定基因的启动子区域。
在寻找基因的启动子序列时,需要根据研究目的选择适当的方法。
在讲述某个基因的启动子查询之间,我们有必要对基础知识进行一下复习和总结。
先看一下中心法则:启动子是在DNA转录为RNA这一步过程中发挥作用的,在此要与顺序数为负(-1,-2,……),向下游(3’端)数的碱基为正(+2,+3,……)区域:启动子的范围非常大,可以包含转录起始位点上游2000bp,有些特定基因的转录区内部也存在着转录因子的结合位点,因此也属于为/。
进入项Genome Browser,进入基因组浏览器入口,如下图在Organism的下拉菜单中选择Rat,在assembly的下拉菜单中选择最新日期Nov. 2004可,如下图所示:然后点击Submit,返回的页面如下:结果显示该基因的已知序列和相关mRNA序列,点击Known Gene中的第一个序列,出现包含这序列的图解概要。
为了获得这个区域更清晰的图像,可以点击紧靠zoom out的1.5X按钮,如下图:对于Known Genes(已知基因)和预测的基因路径来说,一般的惯例是以一个高的垂直线或块状表示每个编码外显子,以短的垂直线或块状表示5′端和3′端非翻译区。
起连接作用的内含子以非常细的线条表示。
翻译的方向由沿着细线的箭头指示。
本例的搜寻目的来说,默认设置不是理想的设置。
按照视图利用页面底部的Track Controls按钮,将一些路径设置为hide模式(即不显示),其他设置为dense模式(所有资料密集在一条直线上);另一些路径设置为full模式(每个特征有一个分开的线条,最多达300)。
在考虑这些路径内究竟存在那些资料之前,对这些路径的内容和表现做一个简要的讨论是必要的,许多这些讨论是由外界提供给UCSC的。
Ensembl Gene Predictions路径由Ensembl提供。
Ensembl基因通过许多方法来预测,包括与已知mRNA和蛋白质进行同源性比较。
若查询启动子区域,我们需要将Ensembl Genes选择为dense 或full模式,点击Refresh,即刷新,出现下图:图中多出了Ensembl Genes的预测路径,我们在红框中圈出。
问题:NCBI中怎样查找编码区/非编码区、起始密码子、启动子、外显子/内含子。
启动子
一般定义启动子,都是upstream 1000bp,downstream1000bp的那段序列。
或者根据你的实验。
你去ensemble,输入基因,找到exon,点开,在configuration里面选好flank多少bp 的序列,选好之后自动刷新,就出来了。
在序列里面,ensemble用不同的颜色标出来不同区域,5‘UTR之类的,还有exon,intron,转录起始位点等等,flank的区域就是你选的promoter 了。
开放阅读框
在分子生物学中,开放阅读框(Open Reading Frame, ORF)从起始密码子开始,是DNA序列中具有编码蛋白质潜能,一段无终止密码子打断的碱基序列。

应用UCSC/Ensembl查找基因启动子(promoter)、内含子、外显子序列启动子的甲基化,转录因子与启动子的结合调控基因的表达等研究领域一直较为热门。
本文图文形式讲解了启动子的概念,利用UCSC如何查找一个基因的启动子序列,以及外显子和内含子序列的显示。
有很多关于此方面的文章由于写作在早期,近年来查询数据库网站的改版使得这些文章有些落伍,使用起来也不方便。
本文是最新的关于查询启动子方法的文章,创作于2009/10/14,大家可以完全按此操作。
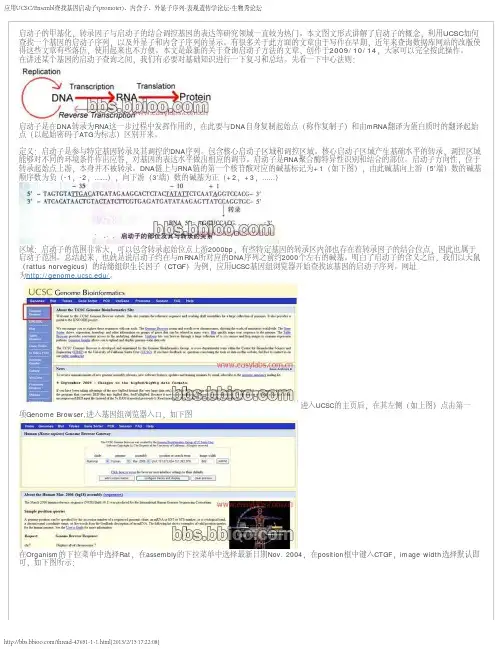
在讲述某个基因的启动子查询之间,我们有必要对基础知识进行一下复习和总结。
先看一下中心法则:启动子是在DNA转录为RNA这一步过程中发挥作用的,在此要与DNA自身复制起始点(称作复制子)和由mRNA翻译为蛋白质时的翻译起始点(以起始密码子ATG为标志)区别开来。
定义:启动子是参与特定基因转录及其调控的DNA序列。
包含核心启动子区域和调控区域。
核心启动子区域产生基础水平的转录,调控区域能够对不同的环境条件作出应答,对基因的表达水平做出相应的调节。
启动子是RNA聚合酶特异性识别和结合的部位。
启动子方向性,位于转录起始点上游,本身并不被转录。
DNA链上与RNA链的第一个核苷酸对应的碱基标记为+1(如下图),由此碱基向上游(5’端)数的碱基顺序数为负(-1,-2,……),向下游(3’端)数的碱基为正(+2,+3,……)区域:启动子的范围非常大,可以包含转录起始位点上游2000bp,有些特定基因的转录区内部也存在着转录因子的结合位点,因此也属于启动子范围。
总结起来,也就是说启动子约在与mRNA所对应的DNA序列之前约2000个左右的碱基。
明白了启动子的含义之后,我们以大鼠(rattus norvegicus)的结缔组织生长因子(CTGF)为例,应用UCSC基因组浏览器开始查找该基因的启动子序列。
网址为/。
进入UCSC的主页后,在其左侧(如上图)点击第一项GenomeBrowser,进入基因组浏览器入口,如下图在Organism的下拉菜单中选择Rat,在assembly的下拉菜单中选择最新日期Nov. 2004,在position框中键入CTGF,image width 选择默认即可,如下图所示:然后点击Submit,返回的页面如下:结果显示该基因的已知序列和相关mRNA序列,点击Known Gene 中的第一个序列,出现包含这序列的图解概要。

基因启动子分析基本流程”1. 数据获取:首先需要获取所研究基因的启动子序列。
可以通过数据库查询或测序技术获取,数据库比如NCBI、Ensembl等,或者利用PCR、随机引物法等技术从DNA中扩增得到。
2. 启动子预测:将获取到的DNA序列输入到启动子预测软件中进行预测,以确定是否存在启动子元件。
启动子元件一般包括TATA-box、CAAT-box、GC-box等保守序列,以及增强子和抑制子。
3.序列比对和进化保守性分析:通过多序列比对,将同一基因在不同物种中的启动子序列进行比对,以确定其中的保守序列。
保守序列通常表示该序列的功能在进化过程中具有重要作用。
4.功能元件鉴定:通过启动子序列中的保守序列和已知的转录调控因子结合位点进行分析,找出可能的功能元件。
可以使用在线工具或软件来预测可能的调控因子结合位点。
5.转录因子分析:对启动子中找到的调控因子结合位点,进一步验证其与转录调控因子的结合关系。
可以使用DNA酶切、染色质免疫沉淀等技术验证。
6.功能验证:通过转录因子与启动子结合部位上下游引入突变或上调/下调转录因子表达等方式,验证启动子的调控功能。
可以通过克隆启动子片段构建报告基因体系,如荧光素酶报告基因体系。
7.体外与体内实验:进行体外和体内实验验证启动子的功能。
体外实验可以通过细胞培养和转染技术,体内实验可以通过转基因动物模型。
8.数据分析和结果展示:对实验结果进行数据分析和统计,并进行可视化展示。
可以使用各种数据分析软件和绘图工具来展示实验结果。
总结:基因启动子分析是一项复杂而重要的研究工作,通过获取基因启动子序列、预测和鉴定功能元件,进一步验证其调控机制,最终得到基因在不同环境下的调控模式。
这项工作对深入理解基因调控机制、疾病研究和基因工程具有重要意义。
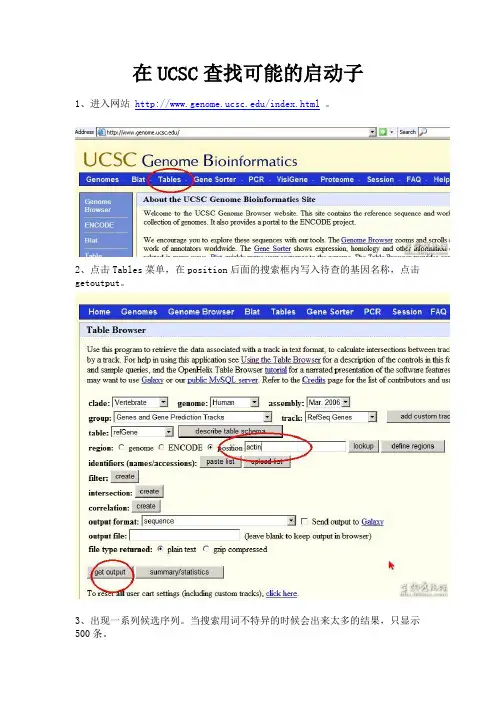
在UCSC查找可能的启动子1、进入网站/index.html。
2、点击Tables菜单,在position后面的搜索框内写入待查的基因名称,点击getoutput。
3、出现一系列候选序列。
当搜索用词不特异的时候会出来太多的结果,只显示500条。
4、点击自己目的基因的结果链接,会出现该基因在染色体上的位置 (有时候会直接跳到选择genome,protein,mRNA那一页面,可能是在搜索词比较特异的情况写),继续getoutput。
5、选择genome这一项。
6、promoter/up stream前面的框中打勾,一般的启动子长度大约为2kb左右,这个数字可以修改。
为便于观察,可继续修改下面的几个选项。
这里选择CDS大写。
7、点击get sequence即可得到结果。
UTR和upstream是分开的,CDS是大写的,可以看到起始码。
copyATG以前的序列进行启动子分析。
pcr以genome为模板。
在Ensembl查找可能的启动子1、进入网站/index.html,选择物种,填入搜索的基因名称。
2、出来2个结果。
本例中貌似是同一个。
点击相应链接进入新页面。
3、貌似有2个不同的转录本。
点击Exon Info。
4、新页面中即可看到5' upstreamsequence。
可以在Flanking sequence at either end oftranscript后面的框中修改期望显示的序列长度。
一般启动子最好选>2kb。
然后copy所显示的上游序列进行分析。
1、UCSC(1)网址:http://genome.ucsc。
edu/cgi-bin/hgNear在Genome里选择物种,比如human,search里输入你的基因名PTEN,点击Go(2)出现新的页面,看到“Known Gene Names”下面的PTEN了吧,点它(3)又回到了和(1)类似的页面,此时,点击sequence(4)出现一个新的页面,选中promoter,同时可以输入数值修改具体的序列区域,比如Promoter including 2000 bases upstream and 100 downstream,即表示启动子—2000~+100区域(5)点击“get sequence”,出现页面中最上面的序列“〉uc001kfb.1 (promoter 2000 100) PTEN —phosphatase and tensin homolog”就是你要的人PTEN启动子—2000~+100区域的序列了2、Ensembl(1)网址:http://www。
/index.html在“Search Ensembl“标题下search后的下拉框中选中物种名homo sapiens(人),for框中输入基因名PTEN,点击Go(2)出现的新页面中比较乱,但不要管它,直接寻找“Ensembl protein coding gene ”字样的,对,也就是第二个,点击它(3)新出现的页面也很乱,不过依然不用管它,看到左侧有点肉色(实在不知道怎么描述了)的那些选项了吗,对,就是“Your Ensembl"下面那一堆,在里面找“Genomic sequence",点它(4)现在的界面就一目了然了,在“5’ Flanking sequence”中输入数值确定启动子长度(默认为600),比如1000,点击update;(5)出现的序列中,标为红色的就是基因的外显子,红色之间黑色的序列就是内含子,而第一个红色自然就是第一外显子了,那么从开始的碱基一直到第一个红色的碱基间自然就是启动子-1000~+1的序列啦这样,你不仅查到了启动子,连它的外显子、内含子序列也全部搞定了3、SIB-EPD(1)网址:http://www。
如何查找基因的启动子区基因的启动子区是基因的调控区域,其位于基因的上游区域。
启动子区域的特点是具有包括启动子、增强子、转录因子结合位点等在内的一系列调控元件,这些元件共同参与了基因的转录调控。
找到一个基因的启动子区,可以帮助我们理解基因的调控机制,进而揭示基因功能和可能的突变带来的影响。
下面将介绍几种常用的方法来查找基因的启动子区。
1.基于生物信息学的预测方法:在基因组学研究中,有很多基于生物信息学的预测方法可以用来查找启动子区域。
这些方法的基本原理是通过分析DNA序列中的一些保守模体和序列特征来预测潜在的启动子区域。
常用的生物信息学工具有TSSGuru、PromoterInspector、Softberry和PromoterScan等,这些工具常常依赖于一些已知的和保守的启动子模体来进行预测。
2.实验室方法:实验室方法一般用于鉴定启动子区域的转录起始位点(TSS)。
这些方法包括实验室测定的转录起始位点显示法(5'-RACE)和转录起始位点定位法(TSS mapping)。
5'-RACE利用了RNA反转录和PCR扩增的原理,可以将对应于转录起始位点的RNA序列扩增出来,并通过测序鉴定转录起始位点。
TSS mapping是一种高通量测定转录起始位点的方法,它可以通过酶切或测序技术鉴定转录起始位点。
3.基于转录因子结合的方法:转录因子是调控基因表达的关键分子,它们结合到基因的启动子区域上,并激活或抑制基因的转录。
通过研究转录因子的结合位点可以找到潜在的启动子区域。
常用的方法有DNA亲和层析法(DNA affinitychromatography)、ChIP-Seq和DNase-seq等。
其中,ChIP-Seq是一种高通量的方法,可以通过将转录因子与其结合DNA片段一起进行测序,从而确定转录因子结合位点和相关启动子区域。
4.跨物种比较法:在物种间比较的基础上查找启动子区域是一种常用的方法。
如何查找基因的启动子及预测转录因子?最近长链非编码RNA(lncRNA)很火热,好不容易找到了一个心仪的lncRNA(关于怎么找,我们之前也聊过:自己做测序、芯片;从别人的数据里挖据;或移植研究从其他疾病里扯一个过来验证),那么问题来了:分子有了,机制部分我该往哪个方向扯呢?很多人可能都会仔细寻找下游靶分子,以证明该lncRNA参与了xx调控,具有某个功能,表明该lncRNA分子在疾病发生发展过程中起到了很重要的作用。
其实,我们还可以往上游做,以丰富机制研究的深度。
今天我们就聊一聊,预测一下参与调控lncRNA表达转录因子的方法。
今天我们通过2个方式进行预测:方法1、需要用到UCSC、PROMO数据库首先,我们需要找到lncRNA的启动子序列。
打开UCSC数据库:举例:HOTAIR输入:HOTAIR点击GO点击红色的那个序列得到这么一个图,点击红色框,继续点击,得到这个界面,我们需要修改一些参数:转录起始位点上游2000nt和下游100nt区域为我们所选的启动子区。
SubmitOK,启动子序列有了。
拷贝下来。
接下来,我们打开PROMO数据库:在SelectSpecies进行部分设置,Submit另外,如果对转录因子有选择的话,也可以在SelectFactors中进行设置。
最后,我们点击SearchSites将刚刚得到的启动子序列粘贴进行。
另外,默认容错率15%,如果得到的转录因子过多,我们可以进行调整,设置成5%或0%。
Submit/cgi-bin/promo_v3/promo/promo.cgi?dirDB=TF_8.3&idCon=148645 228400&getFile=resumSearchRes.html我最终设置了容错率为15,一共得到了80个预测的转录因子。
那么这些转录因子都有可能与HOTAIR的表达相关,可能存在正向或负向的调控关系。
<可结合另两篇博文找相关系数:1.Oncomine: 一个肿瘤相关基因研究的数据库;2.CRN:肿瘤表型转录组数据库 >方法2、直接通过GeneCards数据库查找相关基因的转录因子选择第一个HOTAIR,得到这个界面,往下拉:点击:See All at QIAGEN得到了很多很多的预测转录因子。
如何查找一个基因的启动子序列- UCSC GenomeBioinformatics Site来源:shumingky 发布时间:2009-09-13 查看次数:1712本篇文章写于早期,随着UCSC网站的改版,本文部分内容与网站不一致,读者操作起来可能不方便。
为此,站长原创了一篇文章:“应用UCSC/Ensembl查找基因启动子(promoter)、内含子、外显子序列”,大家可按该文章讲述的方法进行查询基因的启动子,这篇文章之所以没删除,原因是其中有些原理性的内容是一致的,读者可将这两篇文章结合起来阅读。
关键词:基因,启动子序列,软件定义:启动子是参与特定基因转录及其调控的DNA序列。
包含核心启动子区域和调控区域。
核心启动子区域产生基础水平的转录,调控区域能够对不同的环境条件作出应答,对基因的表达水平做出相应的调节。
区域:启动子的范围非常大,可以包含转录起始位点上游2000bp,有些特定基因的转录区内部也存在着转录因子的结合位点,因此也属于启动子范围。
这项搜寻要从UCSC基因组浏览器开始,网址为/。
以编码pendrin (PDS)的基因为例来说明上述问题。
PDS与耳蜗的异常发育、感觉神经性听力下降以及弥散性甲状腺增大(甲状腺肿)有关。
进入UCSC的主页后,在Organism的下拉菜单中选择Human,然后点击B rowser。
使用者现在到了人类基因组浏览器入口。
本例的搜寻很简单:在assemb ly的下拉菜单中选择Dec. 2001,在position框中键入pendrin,然后点击Submi t。
返回的页面结果显示一个已知的基因和两个mRNA序列。
继续点击mRNA序列的登录号AF030880,出现包含这个mRNA区域的图解概要。
为了获得这个区域更清晰的图像,点击紧靠zoom out的1.5X按钮。
最后点击页面中部的reset all按钮,使各个路径的设置恢复默认状态。
然而,对于本例的搜寻目的来说,默认设置不是理想的设置。
定义:启动子是参与特定基因转录及其调控的DNA序列。
包含核心启动子区域和调控区域。
核心启动子区域产生基础水平的转录,调控区域能够对不同的环境条件作出应答,对基因的表达水平做出相应的调节。
区域:启动子的范围非常大,可以包含转录起始位点上游2000bp,有些特定基因的转录区内部也存在着转录因子的结合位点,因此也属于启动子范围。
8票票数Do One Thing, And Do It Well. mybbff edited on 2005-07-22 08:41 举报∙超级细菌耐药性基因多重PCR检测∙【原创】ensembl 改版后如何查找启动子∙【原创】使用UCSC查找一个基因的启动子序列(终)∙【共享】如何查找基因启动子,外显子,内含子序列-最新的资料Revelation 2005-05-07 11:23 消息引用收藏分享分享到哪里?∙复制网址∙新浪微博∙34积分∙12得票∙246丁当加关注∙豆瓣社区∙腾讯微博∙开心网∙人人网下面以BCL-2基因为例,查找查找该基因的启动子区域,首先要找到该基因的基因组序列。
去NCBI吧,在Search的下拉菜单里找到Gene,在检索项里输入Bcl-2,检索第一项就是bcl-2 for human,点进去看看啥样。
0票票数Do One Thing, And Do It Well. 举报∙• 【消息】ACEI + ARB,你给血透患者用这样的组合吗?Revelation∙34积分∙12得票∙246丁当加关注2005-05-07 11:29 消息引用收藏分享分享到哪里?∙复制网址∙新浪微博∙豆瓣社区∙腾讯微博∙开心网∙人人网首先你可以看到该基因的参考序列(reference sequence),然后看到bcl-2的位置和基因组背景。
bcl-2上游是PHLPP,下游是FVT1基因。
在这个长长的网页的最后是已经注册的Bcl-2基因的信息。
0票票数Do One Thing, And Do It Well. Revelation edited on 2005-05-07 11:59 举报∙基因过表达Revelation 2005-05-07 11:35 消息引用收藏分享分享到哪里?∙复制网址∙新浪微博∙34积分∙12得票∙246丁当加关注∙豆瓣社区∙腾讯微博∙开心网∙人人网看到基因组序列了么,点进去,根据序列信息自己就能定位转录起始位点,上游就是promoter了,简单吧。
不!我觉得麻烦。
有更简单的方法么?有!注意到在网页的开头有这么个链接么?HGNC:9900票票数Do One Thing, And Do It Well. 举报∙• 【消息】ACEI + ARB,你给血透患者用这样的组合吗?Revelation 2005-05-07 11:38 消息引用收藏分享∙34积分∙12得票∙246丁当加关注分享到哪里?∙复制网址∙新浪微博∙豆瓣社区∙腾讯微博∙开心网∙人人网点进去,看看吧。
原来是BCL-2的symbol report,各种各样的连接。
注意到左下角的Ensembl GeneView 了么,很有用的,点击。
0票票数Do One Thing, And Do It Well. 举报∙jetPEI DNA transfection reagentRevelation∙34积分∙12得票∙246丁当加关注2005-05-07 11:42 消息引用收藏分享分享到哪里?∙复制网址∙新浪微博∙豆瓣社区∙腾讯微博∙开心网∙人人网呵呵,原来到了Ensemble了,是Ensemble的report。
列出了一堆令人兴奋的信息,太全了,只要是和这个基因相关的信息都能找到,包括SNP,Isoforms,等等等。
我们感兴趣的是,这个连接“View genomic sequence for this gene with exons highlighted”票数Do One Thing, And Do It Well. 举报∙• 【读片】产科疑难超声病例(299):十指连心,水深请谨慎Revelation 2005-05-07 11:48 消息引用收藏分享分享到哪里?∙复制网址∙新浪微博∙豆瓣社区∙34积分∙12得票∙246丁当加关注∙腾讯微博∙开心网∙人人网点击,看看,原来是bcl-2的基因组结构,红底色碱基是exon,绿底色碱基是SNP,太牛了。
别光高兴,忘了找promoter,默认的这个report只是显示bcl-2,上游600bp,下游600bp。
想想,短了一点。
怎么样让5'端多显示几百个碱基呢?秘密在这里。
0票票数Do One Thing, And Do It Well. 举报∙罗氏NimbleGen比较基因组杂交4x72K芯片服务Revelation∙34积分∙12得票∙246丁当加关注2005-05-07 11:55 消息引用收藏分享分享到哪里?∙复制网址∙新浪微博∙豆瓣社区∙腾讯微博∙开心网∙人人网把“5' Flanking sequence”的值改成5000bp,哼!小样!!不行?10000,20000,。
,靠,上一个基因的exon都露出来,算了吧(最大值99999)。
如果保守估计可以做起始位点上游2000bp内的区域,如果最大化估计,可以用起始位点上游至上有基因的最后一个exon结尾处,算你狠!!!0票票数Do One Thing, And Do It Well. 举报∙• 【期刊导读】PM(北医):塞来昔考用于鼻内镜术后疼痛的治疗Revelation∙34积分∙12得票∙246丁当加关注2005-05-07 11:57 消息引用收藏分享分享到哪里?∙复制网址∙新浪微博∙豆瓣社区∙腾讯微博∙开心网∙人人网然后就分析吧,先到MATCH分析一下转录因子结合位点/pub/programs.html#match 然后,然后。
,不管我的事了。
对方有大狙,撤!!!!1票票数Do One Thing, And Do It Well. 举报∙• 【求职】要么不当医生,要么就当庸医lsgggg ∙ 2积分∙ 1得票∙ 67丁当加关注2005-05-07 15:07 消息 引用 收藏 分享分享到哪里?∙复制网址∙ 新浪微博 ∙ 豆瓣社区 ∙ 腾讯微博 ∙ 开心网 ∙ 人人网 不错,顶! 0票 票数 举报 ∙ • 【原创】我在深圳某公立医院的杯具求职经历akanggg2005-05-07 15:16 消息 引用 收藏 分享 分享到哪里? ∙ 复制网址 ∙ 新浪微博∙ 豆瓣社区∙ 腾讯微博∙16积分∙ 2得票∙118丁当加关注∙开心网∙人人网好文!不过CXCR4的基因点了ensamble后怎么没有结果呢??0票票数举报∙microRNA及靶基因荧光素酶报告基因技术Revelation∙34积分∙12得票2005-05-07 22:14 消息引用收藏分享分享到哪里?∙复制网址∙新浪微博∙豆瓣社区∙腾讯微博∙开心网∙人人网这个我check了一下,主要的问题出在NCBI数据库和Ensemble数据库之间的融合性上,也就是说目前二者之间的统一性与一致性还有一些小小的运转不灵。
解决方案:246丁当加关注1,我说过你可以看到四项:1)Ensembl GeneView 2)GENATLAS 3)GeneCards 4)GeneClinics/GeneTests第一项不行,其他的试试,当看到第三项GeneCards的时候就会发现CXCR4的蛋白的Ensemble注册号:ENSP000002413932,点击进去会看到相应的核酸序列的Ensemble注册号:ENSG00000121966。
点击去就回看到你要找的东西了。
3,这时候你会注意到Ensemble给的ID是CXCR4_HUMAN ,而NCBI给的ID是CXCR4,用CXCR4检索Ensemble数据库确实不能检索到任何东西,而用CXCR4_HUMAN 作关键词就可以。
所以,问题出在这两大数据库之间命名的一致性上,偌大的两个数据库,肯定大量存在这种问题,所以,我上门查找启动子的根本思路就是找到Ensemble注册号,不要局限于一种方法,get it!!Good Luck!!Sadas Dasd AsdAsd asd Asd ad aAsd ad。