图的深度优先搜索,广度优先搜索,代码
- 格式:wps
- 大小:29.50 KB
- 文档页数:5

一、实验目的1.掌握图的各种存储结构,特别要熟练掌握邻接矩阵和邻接表存储结构;2.遍历是图各种应用的算法的基础,要熟练掌握图的深度优先遍历和宽度优先遍历算法,复习栈和队列的应用;3.掌握图的各种应用的算法:图的连通性、连通分量和最小生成树、拓扑排序、关键路径。
二、实验内容实验内容1**图的遍历[问题描述]许多涉及图上操作的算法都是以图的遍历为基础的。
写一个程序,演示在连通无向图上遍历全部顶点。
[基本要求]建立图的邻接表的存储结构,实现无向图的深度优先遍历和广度优先遍历。
以用户指定的顶点为起点,分别输出每种遍历下的顶点访问序列。
[实现提示]设图的顶点不超过30个,每个顶点用一个编号表示(如果一个图有N个顶点,则它们的编号分别为1,2,…,N)。
通过输入图的全部边输入一个图,每条边是两个顶点编号对,可以对边依附顶点编号的输入顺序作出限制(例如从小到大)。
[编程思路]首先图的创建,采用邻接表建立,逆向插入到单链表中,特别注意无向是对称插入结点,且要把输入的字符在顶点数组中定位(LocateVex(Graph G,char *name),以便后来的遍历操作,深度遍历算法采用递归调用,其中最主要的是NextAdjVex(Graph G, int v, int w);FirstAdjVex ()函数的书写,依次递归下去,广度遍历用队列的辅助。
[程序代码]头文件:#include<stdio.h>#include<stdlib.h>#define MAX_VERTEX_NUM 30#define MAX_QUEUE_NUMBER 30#define OK 1#define ERROR 0#define INFEASIBLE -1#define OVERFLOW -2#define TRUE 1#define FALSE 0typedef int Status;typedef int InfoType;typedef int Status;/* 定义弧的结构*/typedef struct ArcNode{int adjvex; /*该边所指向的顶点的位置*/ struct ArcNode *nextarc; /*指向下一条边的指针*/ InfoType info; /*该弧相关信息的指针*/}ArcNode;/*定义顶点的结构*/typedef struct VNode{char data[40]; /*顶点信息*/ArcNode *firstarc; /*指向第一条依附该顶点的弧的指针*/}VNode,AdjList[MAX_VERTEX_NUM];/*定义图的结构*/typedef struct {AdjList vertices;int vexnum,arcnum; /*图的当前顶点数和弧数*/int kind; /*图的类型标志*/}Graph;/*定义队列的结构*/typedef struct{int *elem;int front, rear;}Queue;/*功能选择*/void MenuSelect(int w);/*顶点定位*/int LocateVex(Graph G,char *name);/*创建无向图*/void CreateGraph(Graph &G);/*求第一个顶点*/int FirstAdjVex(Graph G, int v);/*求下一个顶点*/int NextAdjVex(Graph G, int v, int w);/*深度递归*/void DFS(Graph G, int v) ;/*深度遍历*/void DFSTravel(Graph G,int v);/*广度遍历*/void BFSTraverse(Graph G,char *name);/*初始化队列*/Status InitQueue(Queue &Q);/*判空*/Status EmptyQueue(Queue Q);/*进队*/Status EnQueue(Queue &Q, int e);/*出队*/Status DeQueue(Queue &Q, int &e);实现文件:#include <stdio.h>#include"malloc.h"#include "tuhead.h"#include "stdlib.h"#include "string.h"bool visited[MAX_VERTEX_NUM];/************************************************************ 顶点定位************************************************************/int LocateVex(Graph G,char *name){int i;for(i=1;i<=G.vexnum;i++) //从1号位置开始存储if(strcmp(name,G.vertices[i].data)==0) //相等则找到,返回位序return i;return -1;}/************************************************************ 创建无向图************************************************************/void CreateGraph(Graph &G){ArcNode *p;char name1[10],name2[10];int i,j,k;printf(" 请输入顶点数,按回车键结束:");scanf("%d",&G.vexnum);printf(" 请输入弧数,按回车键结束:");scanf("%d",&G.arcnum);printf(" 请依次输入顶点名(用空格分开且字符小于10),按回车键结束:\n");printf(" ");for(i=1;i<=G.vexnum;i++) //从1号位置开始存储{scanf("%s",G.vertices[i].data); //从一号位置开始初始化G.vertices[i].firstarc=NULL;}printf("\n\n\n\n");printf(" ………………………………………输入小提示………………………………………\n");printf(" &&&&1 为避免输入遗漏,最好从选择任意一点,输入所有相邻边\n");printf(" &&&&2 输入边时格式(用空格分开,即格式为顶点(空格)顶点(空格))\n");printf(" ………………………………………输入小提示………………………………………\n\n\n\n");for(k=0;k<G.arcnum;k++){printf("请输入相邻的两个顶点,按回车键结束:");scanf("%s%s",name1,name2);i=LocateVex(G,name1); //返回位序j=LocateVex(G,name2);p=(ArcNode *)malloc(sizeof(ArcNode)); //申请边节点p->adjvex=j; //插入到邻接表中,注意此处为逆向插入到单链表中p->nextarc=G.vertices[i].firstarc;G.vertices[i].firstarc=p;//无向图,注意是对称插入结点p=(ArcNode *)malloc(sizeof(ArcNode));p->adjvex=i;p->nextarc=G.vertices[j].firstarc;G.vertices[j].firstarc=p;}}/************************************************************ 求第一个顶点************************************************************/int FirstAdjVex(Graph G, int v){ArcNode *p;if(v>=1 && v<=G.vexnum){p=G.vertices[v].firstarc;if(p->nextarc==NULL)return 0;elsereturn (p->nextarc->adjvex); //返回第一个顶点字符}return -1;}/************************************************************ 求下一个顶点************************************************************/int NextAdjVex(Graph G, int v, int w){ //在图G中寻找第v个顶点的相对于w的下一个邻接顶点ArcNode *p;if(v>=1 && v<=G.vexnum && w>=1 && w<=G.vexnum){p=G.vertices[v].firstarc;while(p->adjvex!=w)p=p->nextarc; //在顶点v的弧链中找到顶点wif(p->nextarc!=NULL)return 0; //若已是最后一个顶点,返回0 elsereturn(p->nextarc->adjvex); //返回下一个邻接顶点的序号}return -1;}/************************************************************ 深度递归************************************************************/void DFS(Graph G, int v){int w;ArcNode *p;visited[v]=1;printf("%s ",G.vertices[v].data); //访问第v个顶点p=G.vertices[v].firstarc; //p为依附顶点的第一条边while (p!=NULL){w=p->adjvex;if(visited[w]==0)DFS(G,w);p=p->nextarc; //下移指针}}/************************************************************ 深度遍历************************************************************/void DFSTravel(Graph G,int v){for(int i=1;i<=G.vexnum;i++)visited[i]=0;int w;ArcNode *p;visited[v]=1;printf("%s ",G.vertices[v].data); //访问第v个顶点p=G.vertices[v].firstarc;while (p!=NULL){w=p->adjvex;if(visited[w]==0)DFS(G,w);p=p->nextarc;}}/************************************************************ 初始化队列************************************************************/Status InitQueue(Queue &Q){Q.elem = new int[MAX_QUEUE_NUMBER];Q.front = Q.rear = 0;return OK;}Status EmptyQueue(Queue Q){if(Q.front==Q.rear)return 0;elsereturn 1;}/*********************************************************** * 进队列* ***********************************************************/ Status EnQueue(Queue &Q, int e){if((Q.rear + 1)%MAX_QUEUE_NUMBER != Q.front)Q.elem[Q.rear ] = e;else ;Q.rear = (Q.rear + 1)%MAX_QUEUE_NUMBER;return OK;}/*********************************************************** * 出队列* ***********************************************************/ Status DeQueue(Queue &Q, int &e){if(Q.rear != Q.front)e = Q.elem[Q.front];else ;Q.front = (Q.front+1)%MAX_QUEUE_NUMBER;return OK;}/*********************************************************** * 广度遍历************************************************************/void BFSTraverse(Graph G,char *name){ArcNode *p;int v,w,u,k=0;Queue Q;int visited[20];for(v=1;v<=G.vexnum;v++) //初始化visited[v]=0;InitQueue(Q);for(v=LocateVex(G,name);k!=2;v=(v+1)%(G.vexnum-1)) //v为输入的字符转化的位序{if(v+1==LocateVex(G,name)) //从v开始走完图的所有顶点k++;if(visited[v]==0){visited[v]=1;printf("%s ",G.vertices[v].data); //访问第v个顶点EnQueue(Q,v); // 进队while(EmptyQueue(Q)!=0){DeQueue(Q,u); //出队p=G.vertices[u].firstarc;while(p!=NULL){w=p->adjvex; //p边的下一个顶点if(visited[w]==0){printf("%s ",G.vertices[w].data);visited[w]=1;EnQueue(Q,w);}p=p->nextarc; //下移指针}}}}}主文件:#include <stdio.h>#include"malloc.h"#include "tuhead.h"#include "stdlib.h"#include "string.h"/************************************************************ 界面控制************************************************************/void main(){printf("\n################################# 图的遍历#################################\n");printf("\n $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n");printf("\n");printf(" 1 ------- 图的创建\n");printf(" 2 ------- 图的深度优先遍历\n");printf(" 3 ------- 图的广度优先遍历\n");printf(" 0 ------- 退出\n");printf("\n $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n");printf("\n");printf("请输入选择的操作代码(0-3)按回车键结束\n");MenuSelect(1);}/************************************************************ 功能选择************************************************************/void MenuSelect(int w){int select,done;int v;Graph G; char name[10];while (done) {printf("input the operating code : ");scanf("%d",&select);switch(select){case 1: printf("根据要求创建图:\n ");CreateGraph(G);break;case 2: printf("请输入深度优先遍历开始点的名:");scanf("%s",name);v=LocateVex(G,name); //将输入字符找到在顶点数组name对应的序号Vprintf("深度优先遍历:");DFSTravel(G,v);printf("\n");break;case 3: printf("请输入广度优先遍历开始点的名:");scanf("%s",name);printf("广度优先遍历:");BFSTraverse(G,name);printf("\n");break;case 0: done=0; break;default: printf(" ERROR\n");}printf("\n");}}[实验数据与结果]测试数据:实验结果。

深度优先搜索示例代码深度优先搜索(Depth First Search,DFS)是一种用于遍历或搜索树或图的算法。
它通过从根节点或某个指定节点开始,尽可能深地探索每个分支,直到找到目标节点或到达叶子节点为止。
本文将给出一个深度优先搜索的示例代码,帮助读者理解算法的实现过程。
示例代码如下:```class Graph:def __init__(self):self.graph = {}def add_edge(self, vertex, edge):if vertex in self.graph:self.graph[vertex].append(edge)else:self.graph[vertex] = [edge]def dfs(self, start):visited = set()self.dfs_helper(start, visited)def dfs_helper(self, vertex, visited):visited.add(vertex)print(vertex)if vertex in self.graph:for neighbor in self.graph[vertex]:if neighbor not in visited:self.dfs_helper(neighbor, visited)```在示例代码中,首先定义了一个`Graph`类,用于表示图结构。
`Graph`类包含了两个方法:`add_edge`用于添加边,`dfs`用于执行深度优先搜索。
`add_edge`方法用于向图中添加边,其中`vertex`表示起始节点,`edge`表示目标节点。
`dfs`方法用于执行深度优先搜索,其中`start`表示搜索的起始节点。
在深度优先搜索的实现中,我们使用了一个`visited`集合来记录已经访问过的节点,避免重复访问。
`dfs_helper`方法用于递归地进行深度优先搜索,其中`vertex`表示当前访问的节点,`visited`表示已访问节点的集合。

dfs和bfs算法代码深度优先搜索(DFS)和广度优先搜索(BFS)是常用的图遍历算法,它们可以帮助我们解决很多实际问题。
本文将详细介绍这两种算法的实现原理和应用场景。
一、深度优先搜索(DFS)深度优先搜索是一种递归的搜索算法,它从图的某个顶点开始,沿着一条路径尽可能深地搜索,直到无法继续为止,然后回溯到上一级节点,继续搜索其他路径。
DFS一般使用栈来实现。
DFS的代码实现如下:```def dfs(graph, start):visited = set() # 用一个集合来记录已访问的节点stack = [start] # 使用栈来实现DFSwhile stack:node = stack.pop() # 取出栈顶元素if node not in visited:visited.add(node) # 将节点标记为已访问neighbors = graph[node] # 获取当前节点的邻居节点stack.extend(neighbors) # 将邻居节点入栈return visited```DFS的应用场景很多,比如迷宫问题、拓扑排序、连通分量的计算等。
在迷宫问题中,我们可以使用DFS来寻找从起点到终点的路径;在拓扑排序中,DFS可以用来确定任务的执行顺序;在连通分量的计算中,DFS可以用来判断图是否连通,并将图分割成不同的连通分量。
二、广度优先搜索(BFS)广度优先搜索是一种逐层遍历的搜索算法,它从图的某个顶点开始,先访问该顶点的所有邻居节点,然后再访问邻居节点的邻居节点,依次进行,直到遍历完所有节点。
BFS一般使用队列来实现。
BFS的代码实现如下:```from collections import dequedef bfs(graph, start):visited = set() # 用一个集合来记录已访问的节点queue = deque([start]) # 使用队列来实现BFSwhile queue:node = queue.popleft() # 取出队首元素if node not in visited:visited.add(node) # 将节点标记为已访问neighbors = graph[node] # 获取当前节点的邻居节点queue.extend(neighbors) # 将邻居节点入队return visited```BFS的应用场景也很广泛,比如寻找最短路径、社交网络中的人际关系分析等。

2024年6月GESP编程能力认证C++等级考试七级真题(含答案)一、单选题(每题2分,共30分)。
1. 下列C++代码的输出结果是()。
2. 对于如下图的二叉树,说法正确的是()。
A. 先序遍历是132。
B. 中序遍历是123。
C. 后序遍历是312。
D. 先序遍历和后序遍历正好是相反的。
3. 已知两个序列s1={1,3,4,5,6,7,7,8,1}、s2={3,5,7,4,8,2,9,5,1},则它们的最长公共子序列是()。
4. 关于序列{2,7,1,5,6,4,3,8,9},以下说法错误的是()。
A. {2,5,6,8,9}是它的最长上升子序列。
B. {1,5,6,8,9}是它的最长上升子序列。
C. {7,5,4,3}是它的最长下降子序列。
D. {1,5,6,8,9}是它的唯一最长上升子序列。
5. 关于图的深度优先搜索和广度优先搜索,下列说法错误的是()。
A. 二叉树是也是一种图。
B. 二叉树的前序遍历和后序遍历都是深度优先搜索的一种。
C. 深度优先搜索可以从任意根节点开始。
D. 二叉树的后序遍历也是广度优先搜索的一种。
6. 对于如下二叉树,下面访问顺序说法错误的是()。
A. HDEBFIGCA不是它的后序遍历序列B. ABCDEFGHI是它的广度优先遍历序列C. ABDHECFGI是它的深度优先遍历序列D. ABDHECFGI是它的先序遍历序列7. 以下哪个方案不能合理解决或缓解哈希表冲突()。
A. 丢弃发生冲突的新元素。
B. 在每个哈希表项处,使用不同的哈希函数再建立一个哈希表,管理该表项的冲突元素。
C. 在每个哈希表项处,建立二叉排序树,管理该表项的冲突元素。
D. 使用不同的哈希函数建立额外的哈希表,用来管理所有发生冲突的元素。
8. 在C++中,关于运算符&,下面说法正确的是()。
9. 下面关于图的说法正确的是()。
A. 在无向图中,环是指至少包含三个不同顶点,并且第一个顶点和最后一个顶点是相同的路径。

深度优先搜索和⼴度优先搜索 深度优先搜索和⼴度优先搜索都是图的遍历算法。
⼀、深度优先搜索(Depth First Search) 1、介绍 深度优先搜索(DFS),顾名思义,在进⾏遍历或者说搜索的时候,选择⼀个没有被搜过的结点(⼀般选择顶点),按照深度优先,⼀直往该结点的后续路径结点进⾏访问,直到该路径的最后⼀个结点,然后再从未被访问的邻结点进⾏深度优先搜索,重复以上过程,直⾄所有点都被访问,遍历结束。
⼀般步骤:(1)访问顶点v;(2)依次从v的未被访问的邻接点出发,对图进⾏深度优先遍历;直⾄图中和v有路径相通的顶点都被访问;(3)若此时图中尚有顶点未被访问,则从⼀个未被访问的顶点出发,重新进⾏深度优先遍历,直到图中所有顶点均被访问过为⽌。
可以看出,深度优先算法使⽤递归即可实现。
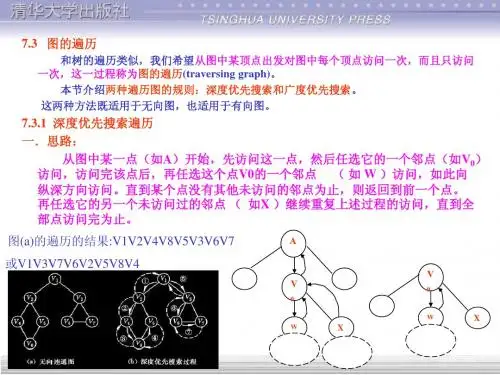
2、⽆向图的深度优先搜索 下⾯以⽆向图为例,进⾏深度优先搜索遍历: 遍历过程: 所以遍历结果是:A→C→B→D→F→G→E。
3、有向图的深度优先搜索 下⾯以有向图为例,进⾏深度优先遍历: 遍历过程: 所以遍历结果为:A→B→C→E→D→F→G。
⼆、⼴度优先搜索(Breadth First Search) 1、介绍 ⼴度优先搜索(BFS)是图的另⼀种遍历⽅式,与DFS相对,是以⼴度优先进⾏搜索。
简⾔之就是先访问图的顶点,然后⼴度优先访问其邻接点,然后再依次进⾏被访问点的邻接点,⼀层⼀层访问,直⾄访问完所有点,遍历结束。
2、⽆向图的⼴度优先搜索 下⾯是⽆向图的⼴度优先搜索过程: 所以遍历结果为:A→C→D→F→B→G→E。
3、有向图的⼴度优先搜索 下⾯是有向图的⼴度优先搜索过程: 所以遍历结果为:A→B→C→E→F→D→G。
三、两者实现⽅式对⽐ 深度优先搜索⽤栈(stack)来实现,整个过程可以想象成⼀个倒⽴的树形:把根节点压⼊栈中。
每次从栈中弹出⼀个元素,搜索所有在它下⼀级的元素,把这些元素压⼊栈中。
并把这个元素记为它下⼀级元素的前驱。

广度优先和深度优先的例子广度优先搜索(BFS)和深度优先搜索(DFS)是图遍历中常用的两种算法。
它们在解决许多问题时都能提供有效的解决方案。
本文将分别介绍广度优先搜索和深度优先搜索,并给出各自的应用例子。
一、广度优先搜索(BFS)广度优先搜索是一种遍历或搜索图的算法,它从起始节点开始,逐层扩展,先访问起始节点的所有邻居节点,再依次访问其邻居节点的邻居节点,直到遍历完所有节点或找到目标节点。
例子1:迷宫问题假设有一个迷宫,迷宫中有多个房间,每个房间有四个相邻的房间:上、下、左、右。
现在我们需要找到从起始房间到目标房间的最短路径。
可以使用广度优先搜索算法来解决这个问题。
例子2:社交网络中的好友推荐在社交网络中,我们希望给用户推荐可能认识的新朋友。
可以使用广度优先搜索算法从用户的好友列表开始,逐层扩展,找到可能认识的新朋友。
例子3:网页爬虫网页爬虫是搜索引擎抓取网页的重要工具。
爬虫可以使用广度优先搜索算法从一个网页开始,逐层扩展,找到所有相关的网页并进行抓取。
例子4:图的最短路径在图中,我们希望找到两个节点之间的最短路径。
可以使用广度优先搜索算法从起始节点开始,逐层扩展,直到找到目标节点。
例子5:推荐系统在推荐系统中,我们希望给用户推荐可能感兴趣的物品。
可以使用广度优先搜索算法从用户喜欢的物品开始,逐层扩展,找到可能感兴趣的其他物品。
二、深度优先搜索(DFS)深度优先搜索是一种遍历或搜索图的算法,它从起始节点开始,沿着一条路径一直走到底,直到不能再继续下去为止,然后回溯到上一个节点,继续探索其他路径。
例子1:二叉树的遍历在二叉树中,深度优先搜索算法可以用来实现前序遍历、中序遍历和后序遍历。
通过深度优先搜索算法,我们可以按照不同的遍历顺序找到二叉树中所有节点。
例子2:回溯算法回溯算法是一种通过深度优先搜索的方式,在问题的解空间中搜索所有可能的解的算法。
回溯算法常用于解决组合问题、排列问题和子集问题。
例子3:拓扑排序拓扑排序是一种对有向无环图(DAG)进行排序的算法。

哈尔滨工业大学计算机科学与技术学院实验报告课程名称:数据结构与算法课程类型:必修实验项目名称:图的搜索与应用实验题目:图的深度和广度搜索与拓扑排序设计成绩报告成绩指导老师一、实验目的1.掌握图的邻接表的存储形式。
2.熟练掌握图的搜索策略,包括深度优先搜索与广度优先搜索算法。
3.掌握有向图的拓扑排序的方法。
二、实验要求及实验环境实验要求:1.以邻接表的形式存储图。
2.给出图的深度优先搜索算法与广度优先搜索算法。
3.应用搜索算法求出有向图的拓扑排序。
实验环境:寝室+机房+编程软件(NetBeans IDE 6.9.1)。
三、设计思想(本程序中的用到的所有数据类型的定义,主程序的流程图及各程序模块之间的调用关系)数据类型定义:template <class T>class Node {//定义边public:int adjvex;//定义顶点所对应的序号Node *next;//指向下一顶点的指针int weight;//边的权重};template <class T>class Vnode {public:T vertex;Node<T> *firstedge;};template <class T>class Algraph {public:Vnode<T> adjlist[Max];int n;int e;int mark[Max];int Indegree[Max];};template<class T>class Function {public://创建有向图邻接表void CreatNalgraph(Algraph<T>*G);//创建无向图邻接表void CreatAlgraph(Algraph<T> *G);//深度优先递归搜索void DFSM(Algraph<T>*G, int i);void DFS(Algraph<T>* G);//广度优先搜索void BFS(Algraph<T>* G);void BFSM(Algraph<T>* G, int i);//有向图的拓扑排序void Topsort(Algraph<T>*G);/得到某个顶点内容所对应的数组序号int Judge(Algraph<T>* G, T name); };主程序流程图:程序开始调用关系:主函数调用五个函数 CreatNalgraph(G)//创建有向图 DFS(G) //深度优先搜索 BFS(G) //广度优先搜索 Topsort(G) //有向图拓扑排序 CreatAlgraph(G) //创建无向图其中 CreatNalgraph(G) 调用Judge(Algraph<T>* G, T name)函数;DFS(G)调用DFSM(Algraph<T>* G , int i)函数;BFS(G) 调用BFSM(Algraph<T>* G, int k)函数;CreatAlgraph(G) 调选择图的类型无向图有向图深 度 优 先 搜 索广度优先搜索 深 度 优 先 搜 索 广度优先搜索拓 扑 排 序程序结束用Judge(Algraph<T>* G, T name)函数。
数据结构课设——有向图的深度、⼴度优先遍历及拓扑排序任务:给定⼀个有向图,实现图的深度优先, ⼴度优先遍历算法,拓扑有序序列,并输出相关结果。
功能要求:输⼊图的基本信息,并建⽴图存储结构(有相应提⽰),输出遍历序列,然后进⾏拓扑排序,并测试该图是否为有向⽆环图,并输出拓扑序列。
按照惯例,先上代码,注释超详细:#include<stdio.h>#include<stdlib.h>#include<malloc.h>#pragma warning(disable:4996)#define Max 20//定义数组元素最⼤个数(顶点最⼤个数)typedef struct node//边表结点{int adjvex;//该边所指向结点对应的下标struct node* next;//该边所指向下⼀个结点的指针}eNode;typedef struct headnode//顶点表结点{int in;//顶点⼊度char vertex;//顶点数据eNode* firstedge;//指向第⼀条边的指针,边表头指针}hNode;typedef struct//邻接表(图){hNode adjlist[Max];//以数组的形式存储int n, e;//顶点数,边数}linkG;//以邻接表的存储结构创建图linkG* creat(linkG* g){int i, k;eNode* s;//边表结点int n1, e1;char ch;g = (linkG*)malloc(sizeof(linkG));//申请结点空间printf("请输⼊顶点数和边数:");scanf("%d%d", &n1, &e1);g->n = n1;g->e = e1;printf("顶点数:%d 边数:%d\n", g->n, g->e);printf("请输⼊顶点信息(字母):");getchar();//因为接下来要输⼊字符串,所以getchar⽤于承接上⼀条命令的结束符for (i = 0; i < n1; i++){scanf("%c", &ch);g->adjlist[i].vertex = ch;//获得该顶点数据g->adjlist[i].firstedge = NULL;//第⼀条边设为空}printf("\n打印顶点下标及顶点数据:\n");for (i = 0; i < g->n; i++)//循环打印顶点下标及顶点数据{printf("顶点下标:%d 顶点数据:%c\n", i, g->adjlist[i].vertex);}getchar();int i1, j1;//相连接的两个顶点序号for (k = 0; k < e1; k++)//建⽴边表{printf("请输⼊对<i,j>(空格分隔):");scanf("%d%d", &i1, &j1);s = (eNode*)malloc(sizeof(eNode));//申请边结点空间s->adjvex = j1;//边所指向结点的位置,下标为j1s->next = g->adjlist[i1].firstedge;//将当前s的指针指向当前顶点上指向的结点g->adjlist[i1].firstedge = s;//将当前顶点的指针指向s}return g;//返回指针g}int visited[Max];//标记是否访问void DFS(linkG* g, int i)//深度优先遍历{eNode* p;printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已访问过的顶点visited值改为1p = g->adjlist[i].firstedge;//p指向顶点i的第⼀条边while (p)//p不为NULL时(边存在){if (visited[p->adjvex] != 1)//如果没有被访问DFS(g, p->adjvex);//递归}p = p->next;//p指向下⼀个结点}}void DFSTravel(linkG* g)//遍历⾮连通图{int i;printf("深度优先遍历;\n");//printf("%d\n",g->n);for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问{DFS(g, i);//调⽤DFS函数}}}void BFS(linkG* g, int i)//⼴度优先遍历{int j;eNode* p;int q[Max], front = 0, rear = 0;//建⽴顺序队列⽤来存储,并初始化printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已经访问过的改成1rear = (rear + 1) % Max;//普通顺序队列的话,这⾥是rear++q[rear] = i;//当前顶点(下标)队尾进队while (front != rear)//队列⾮空{front = (front + 1) % Max;//循环队列,顶点出队j = q[front];p = g->adjlist[j].firstedge;//p指向出队顶点j的第⼀条边while (p != NULL){if (visited[p->adjvex] == 0)//如果未被访问{printf("%c ", g->adjlist[p->adjvex].vertex);visited[p->adjvex] = 1;//将该顶点标记数组值改为1rear = (rear + 1) % Max;//循环队列q[rear] = p->adjvex;//该顶点进队}p = p->next;//指向下⼀个结点}}}void BFSTravel(linkG* g)//遍历⾮连通图{int i;printf("⼴度优先遍历:\n");for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问过{BFS(g, i);//调⽤BFS函数}}}//因为拓扑排序要求⼊度为0,所以需要先求出每个顶点的⼊度void inDegree(linkG* g)//求图顶点⼊度{eNode* p;int i;for (i = 0; i < g->n; i++)//循环将顶点⼊度初始化为0{g->adjlist[i].in = 0;}for (i = 0; i < g->n; i++)//循环每个顶点{p = g->adjlist[i].firstedge;//获取第i个链表第1个边结点指针while (p != NULL)///当p不为空(边存在){g->adjlist[p->adjvex].in++;//该边终点结点⼊度+1p = p->next;//p指向下⼀个边结点}printf("顶点%c的⼊度为:%d\n", g->adjlist[i].vertex, g->adjlist[i].in);}void topo_sort(linkG *g)//拓扑排序{eNode* p;int i, k, gettop;int top = 0;//⽤于栈指针的下标索引int count = 0;//⽤于统计输出顶点的个数int* stack=(int *)malloc(g->n*sizeof(int));//⽤于存储⼊度为0的顶点for (i=0;i<g->n;i++)//第⼀次搜索⼊度为0的顶点{if (g->adjlist[i].in==0){stack[++top] = i;//将⼊度为0的顶点进栈}}while (top!=0)//当栈不为空时{gettop = stack[top--];//出栈,并保存栈顶元素(下标)printf("%c ",g->adjlist[gettop].vertex);count++;//统计顶点//接下来是将邻接点的⼊度减⼀,并判断该点⼊度是否为0p = g->adjlist[gettop].firstedge;//p指向该顶点的第⼀条边的指针while (p)//当p不为空时{k = p->adjvex;//相连接的顶点(下标)g->adjlist[k].in--;//该顶点⼊度减⼀if (g->adjlist[k].in==0){stack[++top] = k;//如果⼊度为0,则进栈}p = p->next;//指向下⼀条边}}if (count<g->n)//如果输出的顶点数少于总顶点数,则表⽰有环{printf("\n有回路!\n");}free(stack);//释放空间}void menu()//菜单{system("cls");//清屏函数printf("************************************************\n");printf("* 1.建⽴图 *\n");printf("* 2.深度优先遍历 *\n");printf("* 3.⼴度优先遍历 *\n");printf("* 4.求出顶点⼊度 *\n");printf("* 5.拓扑排序 *\n");printf("* 6.退出 *\n");printf("************************************************\n");}int main(){linkG* g = NULL;int c;while (1){menu();printf("请选择:");scanf("%d", &c);switch (c){case1:g = creat(g); system("pause");break;case2:DFSTravel(g); system("pause");break;case3:BFSTravel(g); system("pause");break;case4:inDegree(g); system("pause");break;case5:topo_sort(g); system("pause");break;case6:exit(0);break;}}return0;}实验⽤图:运⾏结果:关于深度优先遍历 a.从图中某个顶点v 出发,访问v 。

深度优先搜索算法详解及代码实现深度优先搜索(Depth-First Search,DFS)是一种常见的图遍历算法,用于遍历或搜索图或树的所有节点。
它的核心思想是从起始节点开始,沿着一条路径尽可能深入地访问其他节点,直到无法继续深入为止,然后回退到上一个节点,继续搜索未访问过的节点,直到所有节点都被访问为止。
一、算法原理深度优先搜索算法是通过递归或使用栈(Stack)的数据结构来实现的。
下面是深度优先搜索算法的详细步骤:1. 选择起始节点,并标记该节点为已访问。
2. 从起始节点出发,依次访问与当前节点相邻且未被访问的节点。
3. 若当前节点有未被访问的邻居节点,则选择其中一个节点,将其标记为已访问,并将当前节点入栈。
4. 重复步骤2和3,直到当前节点没有未被访问的邻居节点。
5. 若当前节点没有未被访问的邻居节点,则从栈中弹出一个节点作为当前节点。
6. 重复步骤2至5,直到栈为空。
深度优先搜索算法会不断地深入到图或树的某一分支直到底部,然后再回退到上层节点继续搜索其他分支。
因此,它的搜索路径类似于一条深入的迷宫路径,直到没有其他路径可走后,再原路返回。
二、代码实现以下是使用递归方式实现深度优先搜索算法的代码:```pythondef dfs(graph, start, visited):visited.add(start)print(start, end=" ")for neighbor in graph[start]:if neighbor not in visited:dfs(graph, neighbor, visited)# 示例数据graph = {'A': ['B', 'C'],'B': ['A', 'D', 'E'],'C': ['A', 'F'],'D': ['B'],'E': ['B', 'F'],'F': ['C', 'E']}start_node = 'A'visited = set()dfs(graph, start_node, visited)```上述代码首先定义了一个用于实现深度优先搜索的辅助函数`dfs`。
有两种常用的方法可用来搜索图:即深度优先搜索和广度优先搜索。
它们最终都会到达所有连通的顶点。
深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现。
深度优先搜索:深度优先搜索就是在搜索树的每一层始终先只扩展一个子节点,不断地向纵深前进直到不能再前进(到达叶子节点或受到深度限制)时,才从当前节点返回到上一级节点,沿另一方向又继续前进。
这种方法的搜索树是从树根开始一枝一枝逐渐形成的。
下面图中的数字显示了深度优先搜索顶点被访问的顺序。
为了实现深度优先搜索,首先选择一个起始顶点并需要遵守三个规则:(1) 如果可能,访问一个邻接的未访问顶点,标记它,并把它放入栈中。
(2) 当不能执行规则1时,如果栈不空,就从栈中弹出一个顶点。
(3) 如果不能执行规则1和规则2,就完成了整个搜索过程。
广度优先搜索:在深度优先搜索算法中,是深度越大的结点越先得到扩展。
如果在搜索中把算法改为按结点的层次进行搜索,本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
在深度优先搜索中,算法表现得好像要尽快地远离起始点似的。
相反,在广度优先搜索中,算法好像要尽可能地靠近起始点。
它首先访问起始顶点的所有邻接点,然后再访问较远的区域。
它是用队列来实现的。
下面图中的数字显示了广度优先搜索顶点被访问的顺序。
实现广度优先搜索,也要遵守三个规则:(1) 访问下一个未来访问的邻接点,这个顶点必须是当前顶点的邻接点,标记它,并把它插入到队列中。
(2) 如果因为已经没有未访问顶点而不能执行规则1时,那么从队列头取一个顶点,并使其成为当前顶点。
(3) 如果因为队列为空而不能执行规则2,则搜索结束。
BFS是一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。
换句话说,它并不考虑结果的可能位址,彻底地搜索整张图,直到找到结果为止。
BFS并不使用经验法则算法。
浅析深度优先和⼴度优先遍历实现过程、区别及使⽤场景⼀、什么是深度/⼴度优先遍历? 深度优先遍历简称DFS(Depth First Search),⼴度优先遍历简称BFS(Breadth First Search),它们是遍历图当中所有顶点的两种⽅式。
这两种遍历⽅式有什么不同呢?我们来举个栗⼦: 我们来到⼀个游乐场,游乐场⾥有11个景点。
我们从景点0开始,要玩遍游乐场的所有景点,可以有什么样的游玩次序呢?1、深度优先遍历 第⼀种是⼀头扎到底的玩法。
我们选择⼀条⽀路,尽可能不断地深⼊,如果遇到死路就往回退,回退过程中如果遇到没探索过的⽀路,就进⼊该⽀路继续深⼊。
在图中,我们⾸先选择景点1的这条路,继续深⼊到景点7、景点8,终于发现⾛不动了: 于是,我们退回到景点7,然后探索景点10,⼜⾛到了死胡同。
于是,退回到景点1,探索景点9: 按照这个思路,我们再退回到景点0,后续依次探索景点2、3、5、4、发现相邻的都玩过了,再回退到3,再接着玩6,终于玩遍了整个游乐场: 具体次序如下图,景点旁边的数字代表探索次序。
当然还可以有别的排法。
像这样先深⼊探索,⾛到头再回退寻找其他出路的遍历⽅式,就叫做深度优先遍历(DFS)。
这⽅式看起来很像⼆叉树的前序遍历。
没错,其实⼆叉树的前序、中序、后序遍历,本质上也可以认为是深度优先遍历。
2、⼴度优先遍历 除了像深度优先遍历这样⼀头扎到底的玩法以外,我们还有另⼀种玩法:⾸先把起点相邻的⼏个景点玩遍,然后去玩距离起点稍远⼀些(隔⼀层)的景点,然后再去玩距离起点更远⼀些(隔两层)的景点… 在图中,我们⾸先探索景点0的相邻景点1、2、3、4: 接着,我们探索与景点0相隔⼀层的景点7、9、5、6: 最后,我们探索与景点0相隔两层的景点8、10: 像这样⼀层⼀层由内⽽外的遍历⽅式,就叫做⼴度优先遍历(BFS)。
这⽅式看起来很像⼆叉树的层序遍历。
没错,其实⼆叉树的层序遍历,本质上也可以认为是⼴度优先遍历。
深度优先搜索算法利用深度优先搜索解决迷宫问题深度优先搜索算法(Depth-First Search, DFS)是一种常用的图遍历算法,它通过优先遍历图中的深层节点来搜索目标节点。
在解决迷宫问题时,深度优先搜索算法可以帮助我们找到从起点到终点的路径。
一、深度优先搜索算法的实现原理深度优先搜索算法的实现原理相当简单直观。
它遵循以下步骤:1. 选择一个起始节点,并标记为已访问。
2. 递归地访问其相邻节点,若相邻节点未被访问,则标记为已访问,并继续访问其相邻节点。
3. 重复步骤2直到无法继续递归访问,则返回上一级节点,查找其他未被访问的相邻节点。
4. 重复步骤2和3,直到找到目标节点或者已经遍历所有节点。
二、利用深度优先搜索算法解决迷宫问题迷宫问题是一个经典的寻找路径问题,在一个二维的迷宫中,我们需要找到从起点到终点的路径。
利用深度优先搜索算法可以很好地解决这个问题。
以下是一种可能的解决方案:```1. 定义一个二维数组作为迷宫地图,其中0代表通路,1代表墙壁。
2. 定义一个和迷宫地图大小相同的二维数组visited,用于记录节点是否已经被访问过。
3. 定义一个存储路径的栈path,用于记录从起点到终点的路径。
4. 定义一个递归函数dfs,参数为当前节点的坐标(x, y)。
5. 在dfs函数中,首先判断当前节点是否为终点,如果是则返回True,表示找到了一条路径。
6. 然后判断当前节点是否越界或者已经访问过,如果是则返回False,表示该路径不可行。
7. 否则,将当前节点标记为已访问,并将其坐标添加到path路径中。
8. 依次递归访问当前节点的上、下、左、右四个相邻节点,如果其中任意一个节点返回True,则返回True。
9. 如果所有相邻节点都返回False,则将当前节点从path路径中删除,并返回False。
10. 最后,在主函数中调用dfs函数,并判断是否找到了一条路径。
```三、示例代码```pythondef dfs(x, y):if maze[x][y] == 1 or visited[x][y] == 1:return Falseif (x, y) == (end_x, end_y):return Truevisited[x][y] = 1path.append((x, y))if dfs(x+1, y) or dfs(x-1, y) or dfs(x, y+1) or dfs(x, y-1): return Truepath.pop()return Falseif __name__ == '__main__':maze = [[0, 1, 1, 0, 0],[0, 0, 0, 1, 0],[1, 1, 0, 0, 0],[1, 1, 1, 1, 0],[0, 0, 0, 1, 0]]visited = [[0] * 5 for _ in range(5)]path = []start_x, start_y = 0, 0end_x, end_y = 4, 4if dfs(start_x, start_y):print("Found path:")for x, y in path:print(f"({x}, {y}) ", end="")print(f"\nStart: ({start_x}, {start_y}), End: ({end_x}, {end_y})") else:print("No path found.")```四、总结深度优先搜索算法是一种有效解决迷宫问题的算法。
c++深搜与宽搜的解题思路当我们面对一些需要在大量数据中搜索特定信息的问题时,深度优先搜索(DFS)和广度优先搜索(BFS)成为了两种常用的搜索算法,它们在不同场景下都有着独特的优势。
在 C++ 中,DFS 和 BFS 都有着非常易于实现的解决方案。
首先,DFS 从根节点开始,遍历图或树的深度并回溯到上一个节点,直到找到需要的信息。
在使用 DFS 时,为避免陷入死循环,需要标记已经访问过的节点,常使用 bool 数组或枚举类型进行标记。
DFS 的使用场景是在一些树结构或迷宫中需要寻找路径、判断连通性等问题中。
C++ 实现 DFS 的代码如下:```c++void dfs(int u) {vis[u] = true; // 标记节点已经访问// 对 u 进行相应处理for (int v = 0; v < Adj[u].size(); ++v) { // 遍历 u 的所有出边if (!vis[Adj[u][v]]) { // 如果 v 没有访问过dfs(Adj[u][v]); // 继续深度优先搜索}}}```接着,我们来了解一下 BFS,它从广度开始,遍历图或树的每一层,一层一层地向前推进,直到找到需要的信息。
在使用 BFS 时,需要借助队列先进先出的特性,将每一层的节点都存入队列中,当队列为空时,说明已经遍历完整个图或树。
BFS 的使用场景是在一些求最短路径、寻找最优解等问题中。
C++ 实现 BFS 的代码如下:```c++void bfs(int s) {queue<int> q;q.push(s); // 将起点加入队列vis[s] = true; // 标记节点已经访问while (!q.empty()) { // 队列不为空int u = q.front(); // 取出队首元素q.pop(); // 弹出队首元素// 对 u 进行相应处理for (int v = 0; v < Adj[u].size(); ++v) { // 遍历 u的所有出边if (!vis[Adj[u][v]]) { // 如果 v 没有访问过q.push(Adj[u][v]); // 将 v 加入队列vis[Adj[u][v]] = true; // 标记已经访问过}}}}```无论是 DFS 还是 BFS,它们都在特定的场景中有着非常广泛的应用。
MATLAB⼴度优先搜索BFS、深度优先搜索DFS如此经典的算法竟⼀直没有单独的实现过,真是遗憾啊。
⼴度优先搜索在过去实现的⼆值图像连通区域标记和prim最⼩⽣成树算法时已经⽆意识的⽤到了,深度优先搜索倒是没⽤过。
这次单独的将两个算法实现出来,因为算法本⾝和图像没什么关系,所以更纯粹些。
⼴度优先搜索是从某⼀节点开始,搜索与其线连接的所有节点,按照⼴度⽅向像外扩展,直到不重复遍历所有节点。
深度优先搜索是从某⼀节点开始,沿着其搜索到的第⼀个节点不断深⼊下去,当⽆法再深⼊的时候,回溯节点,然后再在回溯中的某⼀节点开始沿另⼀个⽅向深度搜索,直到不重复的遍历所有节点。
⼴度优先搜索⽤的是队列作为临时节点存放处;深度优先搜索可以递归实现(算法导论就是⽤递归实现的伪代码),不过我这⾥是⽤栈作为临时节点存放处。
感觉也没什么好介绍的了,抄算法导论上的介绍也没什么意思,所有的内容都是书上的,真正学东西还是要看书。
下⾯是运⾏结果:原连通图:⼴度优先搜索:深度优先搜索:matlab代码如下,其中的画图函数netplot.m。
BFS.m1 clear all;close all;clc2 %初始化邻接压缩表3 b=[12;13;14;24;425;36;46;47];56 m=max(b(:)); %压缩表中最⼤值就是邻接矩阵的宽与⾼7 A=compresstable2matrix(b); %从邻接压缩表构造图的矩阵表⽰8 netplot(A,1) %形象表⽰910 head=1; %队列头11 tail=1; %队列尾,开始队列为空,tail==head12 queue(head)=1; %向头中加⼊图第⼀个节点13 head=head+1; %队列扩展1415 flag=1; %标记某个节点是否访问过了16 re=[]; %最终结果17while tail~=head %判断队列是否为空18 i=queue(tail); %取队尾节点19for j=1:m20if A(i,j)==1 && isempty(find(flag==j,1)) %如果节点相连并且没有访问过21 queue(head)=j; %新节点⼊列22 head=head+1; %扩展队列23 flag=[flag j]; %对新节点进⾏标记24 re=[re;i j]; %将边存⼊结果25 end26 end27 tail=tail+1;28 end2930 A=compresstable2matrix(re);31 figure;32 netplot(A,1)DFS.m1 clear all;close all;clc2 %初始化邻接压缩表3 b=[12;13;14;24;425;36;46;47];56 m=max(b(:)); %压缩表中最⼤值就是邻接矩阵的宽与⾼7 A=compresstable2matrix(b); %从邻接压缩表构造图的矩阵表⽰8 netplot(A,1) %形象表⽰910 top=1; %堆栈顶11 stack(top)=1; %将第⼀个节点⼊栈1213 flag=1; %标记某个节点是否访问过了14 re=[]; %最终结果15while top~=0 %判断堆栈是否为空16 pre_len=length(stack); %搜寻下⼀个节点前的堆栈长度17 i=stack(top); %取堆栈顶节点18for j=1:m19if A(i,j)==1 && isempty(find(flag==j,1)) %如果节点相连并且没有访问过20 top=top+1; %扩展堆栈21 stack(top)=j; %新节点⼊栈22 flag=[flag j]; %对新节点进⾏标记23 re=[re;i j]; %将边存⼊结果24break;25 end26 end27if length(stack)==pre_len %如果堆栈长度没有增加,则节点开始出栈28 stack(top)=[];29 top=top-1;30 end31 end3233 A=compresstable2matrix(re);34 figure;35 netplot(A,1)compresstable2matrix.m1 function A=compresstable2matrix(b)2 [n ~]=size(b);3 m=max(b(:));4 A=zeros(m,m);56for i=1:n7 A(b(i,1),b(i,2))=1;8 A(b(i,2),b(i,1))=1;9 end1011 end。
天津理工大学实验报告学院(系)名称:计算机与通信工程学院姓名学号专业计算机科学与技术班级2009级1班实验项目实验四图的深度优先与广度优先遍历课程名称数据结构与算法课程代码实验时间2011年5月12日第5-8节实验地点7号楼215 批改意见成绩教师签字:实验四图的深度优先与广度优先遍历实验时间:2011年5月12日,12:50 -15:50(地点:7-215)实验目的:理解图的逻辑特点;掌握理解图的两种主要存储结构(邻接矩阵和邻接表),掌握图的构造、深度优先遍历、广度优先遍历算法。
具体实验题目:(任课教师根据实验大纲自己指定)每位同学按下述要求实现相应算法:根据从键盘输入的数据创建图(图的存储结构可采用邻接矩阵或邻接表),并对图进行深度优先搜索和广度优先搜索1)问题描述:在主程序中提供下列菜单:1…图的建立2…深度优先遍历图3…广度优先遍历图0…结束2)实验要求:图的存储可采用邻接表或邻接矩阵;定义下列过程:CreateGraph(): 按从键盘的数据建立图DFSGrahp():深度优先遍历图BFSGrahp():广度优先遍历图实验报告格式及要求:按学校印刷的实验报告模版书写。
(具体要求见四)实验思路:首先,定义邻接矩阵和图的类型,定义循环队列来存储,本程序中只给出了有向图的两种遍历,定义深度优先搜索和广度优先搜索的函数,和一些必要的函数,下面的程序中会有说明,然后是函数及运行结果!#include<iostream>#include<cstdlib>using namespace std;#define MAX_VERTEX_NUM 20//最大顶点数#define MaxSize 100bool visited[MAX_VERTEX_NUM];enum GraphKind{AG,AN,DG,DN};//图的种类,无向图,无向网络,有向图,有向网络struct ArcNode{int adjvex;ArcNode * nextarc;};struct VNode{int data;ArcNode * firstarc;};struct Graph{VNode vertex[MAX_VERTEX_NUM];int vexnum,arcnum;//顶点数,弧数GraphKind kind;//图的类型};struct SeqQueue{int *base;int front,rear;SeqQueue InitQueue(){//循环队列初始化SeqQueue Q;Q.base = new int;Q.front=0;Q.rear=0;return Q;}void DeQueue(SeqQueue &Q,int &u){//出队操作u = *(Q.base+Q.front);Q.front = (Q.front+1)%MaxSize;}int QueueFull(SeqQueue Q){//判断循环队列是否满return (Q.front==(Q.rear+1)%MaxSize)?1:0;}void EnQueue(SeqQueue &Q,int x){//入队操作if(QueueFull(Q)){cout<<"队满,入队操作失败!"<<endl;exit(0);}*(Q.base+Q.rear) = x;Q.rear = (Q.rear+1)%MaxSize;void CreateDG(Graph & G,int n,int e){//初始化邻接表头结点int j;for(int i=0;i<n;++i){G.vertex[i].data=i;G.vertex[i].firstarc=NULL;}for(i=0;i<e;++i){cin>>i>>j;//输入边的信息ArcNode* s;s= new ArcNode;s->adjvex = j;s->nextarc = G.vertex[i].firstarc;G.vertex[i].firstarc = s;}}void Visit(Graph G,int u){cout<<G.vertex[u].data<<" ";}int FirstAdjVex(Graph G,int v){if(G.vertex[v].firstarc)return G.vertex[v].firstarc->adjvex;elsereturn -1;}int NextAdjVex(Graph G,int v,int w){ArcNode* p = G.vertex[v].firstarc;while(p->adjvex!=w)p = p->nextarc;if(p->nextarc)return p->nextarc->adjvex;elsereturn -1;}void DFSGrahp(Graph G,int v){visited[v]=true;Visit(G,v);//访问顶点V,对从未访问过的邻接点w递归调用DFS for(int w=FirstAdjVex(G,v);w!=0;w=NextAdjVex(G,v,w))if(!visited[w]) DFSGrahp(G,w);}void DFSTraverse(Graph G){//对图G做深度优先搜索for(int v=0;v<G.vexnum;++v)visited[v]=false;//初始化访问标志数组visitedfor(v=0;v<G.vexnum;++v)if(!visited[v]) DFSGrahp(G,v);//对尚未访问的顶点v调用DFS }void BFSGrahp(Graph G){//图的广度优先搜索SeqQueue Q;Q=InitQueue();int u;for(int v=0;v<G.vexnum;++v)if(!visited[G,v]){EnQueue(Q,v);//v入队列while(!((Q.front==Q.rear)?1:0)){DeQueue(Q,u);//对首元素出队,赋给uvisited[u]=true;Visit(G,u);for(int w=FirstAdjVex(G,u);w!=0;w=NextAdjVex(G,u,w)) //u的未访问过的邻接点w入队列if(!visited[w])EnQueue(Q,w);}}}int main(){Graph p;int n,e;cout<<"输入图的顶点及边数:"<<endl;cin>>n>>e;cout<<"创建图:"<<endl;CreateDG(p,n,e);cout<<"图的优先深度结果为:"<<endl;DFSTraverse(p);cout<<"图的广度优先结果为:"<<endl;BFSGrahp(p);printf("结果如上所示!\n");return 0;}。
四色定理是一个经典的图论问题,可以使用深度优先搜索(DFS)或广度优先搜索(BFS)算法来解决。
以下是使用DFS算法的C++代码实现:c复制代码#include<iostream>#include<vector>#include<queue>using namespace std;const int MAXN = 100; // 最大顶点数vector<int> G[MAXN]; // 邻接表存储图int color[MAXN]; // 记录每个顶点的颜色bool vis[MAXN]; // 记录每个顶点是否被访问过bool dfs(int u) {vis[u] = true; // 标记顶点u为已访问for (int i = 0; i < G[u].size(); i++) {int v = G[u][i];if (!vis[v]) { // 如果顶点v未被访问过,则继续递归访问vif (color[v] == -1 || dfs(color[v])) { // 如果顶点v未染色或染色后可以与顶点u相邻,则将v染色为与u不同的颜色,并返回truecolor[v] = color[u];return true;}} else if (color[v] == color[u]) { // 如果顶点v已被染色且与顶点u颜色相同,则说明存在环,返回falsereturn false;}}return true; // 无法染色,返回true}bool check(int n) { // 检查是否可以通过n种颜色染色for (int i = 0; i < n; i++) {memset(color, -1, sizeof(color)); // 初始化染色数组为-1memset(vis, false, sizeof(vis)); // 初始化访问数组为falseif (!dfs(i)) { // 从第i个顶点开始进行DFS染色,如果无法染色,则说明需要更多颜色,返回falsereturn false;}}return true; // 所有顶点都可以通过n种颜色染色,返回true}int main() {int n, m; // n为顶点数,m为边数cin >> n >> m;for (int i = 0; i < m; i++) {int u, v; // u和v之间有一条有向边cin >> u >> v;G[u].push_back(v); // 将v加入u的邻接表中}if (check(4)) { // 检查是否可以通过4种颜色染色,如果是,则输出“四色定理成立”,否则输出“四色定理不成立”cout << "四色定理成立" << endl;} else {cout << "四色定理不成立" << endl;}return0;}这段代码首先通过输入顶点和边的数量,构造一个有向图。
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#define MAX_VERTEX_NUM 50
typedef struct Arcnode
{
int adjvex;
struct Arcnode *nextarc;
} Arcnode;
typedef struct VNode
{
int data;
Arcnode *firstarc;
} VNode, AdjList[MAX_VERTEX_NUM];
typedef struct
{
AdjList vertice;
int vexnum, arcnum;
int kind;
} Graph;
int visit[100];//用来标记每个定点是否被访问过
void changeV_G(int v[], Graph &G, int n);//将邻接矩阵转换成邻接表int FirstAdjVex(Graph G, int v);
int NextAdjVex(Graph G, int v, int w);
void DFS(Graph G, int v);
void DFSTraverse(Graph G, int v[]);
void changeV_G(int v[], Graph &G, int n)
{
for(int i=0; i<n; i++)
{
G.vertice[i].data=i;
G.vertice[i].firstarc=NULL;
}
G.vexnum=n;//图的顶点数
for(int i=0; i<n; i++)
for(int j=0; j<n; j++)
{
int x=n*i+j;
if(v[x]==1)
{
if(G.vertice[i].firstarc==NULL)
{
G.vertice[i].firstarc=new Arcnode;
G.vertice[i].firstarc->adjvex=j;
G.vertice[i].firstarc->nextarc=NULL;
}
else
{
Arcnode *p=G.vertice[i].firstarc;
for(; p->nextarc!=NULL; p=p->nextarc)
{
}
p->nextarc=new Arcnode;
p=p->nextarc;
p->adjvex=j;
p->nextarc=NULL;
}
}
}
}
void DFSTraverse(Graph G, int visit[], int n)
{
for(int i=0; i<n; i++)
{
for(int v=0; v<G.vexnum; v++) visit[v] = 0;
for(int v=i; v<G.vexnum; v++)
if(!visit[v]) DFS(G,v);
printf("\n");
}
}
void DFS(Graph G, int v)
{
visit[v]=1;
printf("%d ",G.vertice[v].data );
int w;
for( w = FirstAdjVex(G, v); w>= 0; w = NextAdjVex(G, v, w)) {
if(!visit[w])
DFS(G, w);
}
}
int FirstAdjVex(Graph G, int v)//G.vertice[v].data
{
if(G.vertice[v].firstarc!=NULL)
return G.vertice[v].firstarc->adjvex;
else
return -1;
}
int NextAdjVex(Graph G, int v, int w)
{
Arcnode *p;
for(p = G.vertice[v].firstarc;;)
{
if(p->adjvex==w)
break;
p=p->nextarc;
}
if(p->nextarc==NULL) return -1;
else return p->nextarc->adjvex;
}
typedef struct QNode
{
int data;
struct QNode *next;
} QNode, *QueuePtr;
typedef struct
{
QueuePtr ffront;
QueuePtr rear;
} LinkQueue;
int InitQueue(LinkQueue &Q)
{
Q.ffront=(QueuePtr)malloc(sizeof(QNode));
Q.rear=Q.ffront;
if(!Q.ffront) exit(1);
Q.ffront->next = NULL;
return 1;
}
int EnQueue(LinkQueue &Q, int e)
{
QueuePtr p;
p=(QueuePtr)malloc(sizeof(QNode));
if(!p) exit(1);
p->data = e;
p->next = NULL;
Q.rear->next = p;
Q.rear = p;
return 1;
}
int Dequeue(LinkQueue &Q, int &e)
{
if(Q.ffront == Q.rear) return 0;
QueuePtr p;
p = Q.ffront->next;
e = p ->data;
Q.ffront->next = p->next;
if(Q.rear==p) Q.rear = Q.ffront;
free(p);
return 1;
}
int QueueEmpty(LinkQueue Q)
{
if(Q.ffront==Q.rear)
return 1;
else return 0;
}
void BFSTraverse(Graph G, int visit[], int n)
{
int v;
for(int i=0; i<n; i++)
{
for(v=0; v<G.vexnum; v++)
visit[v]=0;
LinkQueue Q;
InitQueue(Q);
int w, u;
for(v=i; v<G.vexnum; v++)
if(!visit[v])
{
visit[v] = 1;
printf("%d ", G.vertice[v].data);
EnQueue(Q, v);//v入队列
while(!QueueEmpty(Q))
{
Dequeue(Q, u);//队头元素出队并置为u
for(w=FirstAdjVex(G, u); w >= 0; w = NextAdjVex(G, u, w))
if(! visit[w])
{
visit[w] = 1;
printf("%d ", G.vertice[w].data);
EnQueue(Q, w);//w入队列
}//if
}//while
}//if
printf("\n");
}
}
int main()
{
int n;
int *v;//图的邻接矩阵
Graph G;
scanf("%d", &n);
v =(int *) malloc(sizeof(int)*n*n);
for(int i=0; i<n*n; i++)
scanf("%d", &v[i]);
changeV_G(v, G, n);//将邻接矩阵转换成邻接表
printf("DFS\n");
DFSTraverse(G, visit, n);
printf("WFS\n");
BFSTraverse(G, visit, n);
return 0;
}。