第3-4章平稳时间序列分析-模型检验.
- 格式:ppt
- 大小:428.50 KB
- 文档页数:48



注:图中,S号代表序列的观察值;连续曲线代表拟合序列曲线;虚线代表拟合序列的95%上下置信限。
所谓预测就是要利用序列以观察到的样本值对序列在未来某个时刻的取值进行估计。
目前对平稳序列最常用的预测方法是线性最小方差预测。
线性是指预测值为观察值序列的线性函数,最小方差是指预测方差达到最小。
在预测图上可以看到,数据围绕一个范围内波动,即说明未来的数值变化时平稳的。
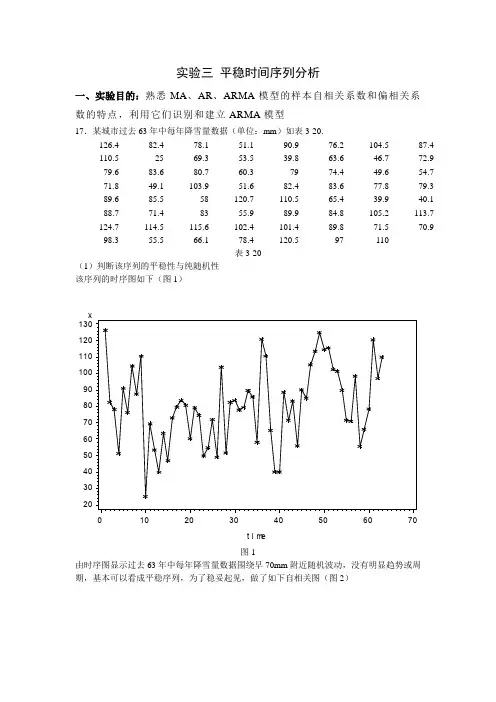
二、课后习题第十七题:根据某城市过去63年中每年降雪量数据(单位:mm)得:(书本P94)程序:data example17_1;input x@@;time=_n_;cards;2579588397 110;proc gplot data=example17_1;plot x*time=1;symbol c=red i=join v=star;run;proc arima data=example17_1;identify var=x nlag=15minic p= (0:5) q=(0:5);run;estimate p=1;run;estimate p=1 noin;run;forecast lead=5id=time out=results;run;proc gplot data=results;plot x*time=1 forecast*time=2 l95*time=3 u95*time=3/overlay;symbol1c=black i=none v=start;symbol2c=red i=join v=none;symbol3c=green i=join v=none l=32;run;(1)判断该序列的平稳性与纯随机性该序列的时序图如下(图a)图a由时序图显示过去63年中每年降雪量数据围绕早70mm附近随机波动,没有明显趋势或周期,基本可以看成平稳序列,为了稳妥起见,做了如下自相关图(图b)图b时序图就是一个平面二维坐标图,通常横轴表示时间,纵轴表示序列取值。




欢迎共阅t P p t tt t t x B x x B x Bx x ===---221第3章 平稳时间序列分析一个序列经过预处理被识别为平稳非白噪声序列,那就说明该序列是一个蕴含着相关信息的平稳序列。
3.1 方法性工具 3.1.1 差分运算 一、p 阶差分记t x ∇为t x 的1阶差分:1--=∇t t t x x x记t x 2∇为t x 的2阶差分:21122---+-=∇-∇=∇t t t t t t x x x x x x 以此类推:记t p x ∇为t x 的p 阶差分:111---∇-∇=∇t p t p t p x x x 二、k 步差分记t k x ∇为t x 的k 步差分:k t t t k x x x --=∇3.1.2 延迟算子 一、定义延迟算子相当与一个时间指针,当前序列值乘以一个延迟算子,就相当于把当前序列值的时间向过去拨了一个时刻。
记B 为延迟算子,有延迟算子的性质:1.10=B2.若c 为任一常数,有1)()(-⋅=⋅=⋅t t t x c x B c x c B3.对任意俩个序列{t x }和{t y },有11)(--±=±t t t t y x y x B4.n t t n x x B -=5.)!(!!,)1()1(0i n i n C B C B in i i nni i n-=-=-∑=其中二、用延迟算子表示差分运算 1、p 阶差分 2、k 步差分3.2 ARMA 模型的性质 3.2.1 AR 模型定义 具有如下结构的模型称为p 阶自回归模型,简记为AR(p):ts Ex t s E Var E x x x x t s t s t t p tp t p t t t ∀=≠===≠+++++=---,0,0)(,)(,0)(,0222110εεεσεεφεφφφφε(3.4)AR(p)模型有三个限制条件:条件一:0≠p φ。
这个限制条件保证了模型的最高阶数为p 。



平稳时间序列分析平稳时间序列分析是一种常用的时间序列分析方法,它旨在研究时间序列在均值和方差上的稳定性,并将其用于预测未来的数据走势。
本文将详细介绍平稳时间序列分析的基本概念、建模方法和预测技术。
首先,让我们来了解什么是时间序列。
时间序列是按照一定的时间间隔收集到的一系列数据点的有序集合,它可以是连续的或离散的。
时间序列分析的目的是通过对过去的数据进行统计分析,揭示出时间序列中的内在规律和趋势,并预测未来的数据走势。
平稳时间序列是指在统计意义上具有稳定性的时间序列,即其均值和方差保持恒定不变。
平稳时间序列具有以下特点:1)均值是常数,不随时间变化;2)方差是常数,不随时间变化;3)协方差只与时间间隔有关,与具体的时间点无关。
为了实现平稳时间序列分析,我们需要进行以下几个步骤:1. 数据准备:收集所需的时间序列数据,并将其整理成适合分析的格式。
通常,我们会绘制时间序列图以直观地查看数据的趋势和模式。
2. 时间序列分解:时间序列通常包含趋势、季节性和随机成分。
我们需要对时间序列进行分解,将其分解为这些组成部分。
常用的分解方法有经典的加性模型和乘性模型。
3. 平稳性检验:对于时间序列分析,我们需要确保数据是平稳的。
平稳性检验的目的是判断时间序列的均值和方差是否是稳定的。
常用的平稳性检验方法有ADF检验、KPSS检验等。
4. 模型建立:如果时间序列被证实是平稳的,我们可以根据数据的模式和趋势选择适当的模型。
常用的模型包括自回归滑动平均模型(ARMA模型)、自回归积分滑动平均模型(ARIMA模型)等。
5. 模型识别与估计:在模型建立的基础上,我们需要对模型进行识别和估计。
模型识别的目的是选择最适合数据的模型阶数,常用的方法有自相关函数(ACF)和偏自相关函数(PACF)的分析。
模型的估计通常使用最大似然估计方法。
6. 模型检验:建立模型后,我们需要对模型进行检验,验证其拟合程度和预测准确度。
常用的模型检验方法有残差分析、DW检验、Ljung-Box检验等。
时序数据分析中的平稳性检验与模型拟合方法时序数据分析是一种重要的数据分析方法,它用于研究随时间变化的数据。
在时序数据分析中,平稳性检验和模型拟合是两个关键的步骤。
本文将介绍平稳性检验和模型拟合的基本概念、方法和应用。
一、平稳性检验平稳性是指时间序列数据的统计特性在不同时间段内保持不变。
平稳性检验是为了确定时间序列数据是否满足平稳性的要求。
常用的平稳性检验方法有ADF检验(Augmented Dickey-Fuller test)和KPSS检验(Kwiatkowski-Phillips-Schmidt-Shin test)。
ADF检验是一种常用的平稳性检验方法,它基于Dickey-Fuller单位根检验。
ADF检验的原假设是时间序列数据存在单位根,即非平稳性。
如果通过ADF检验,可以拒绝原假设,认为时间序列数据是平稳的。
KPSS检验是另一种常用的平稳性检验方法,它基于Kwiatkowski-Phillips-Schmidt-Shin统计量。
KPSS检验的原假设是时间序列数据是平稳的。
如果通过KPSS检验,可以拒绝原假设,认为时间序列数据是非平稳的。
平稳性检验的目的是为了确定时间序列数据是否适合进行模型拟合。
如果时间序列数据不满足平稳性要求,就需要进行差分处理或其他预处理方法来使其平稳化。
二、模型拟合方法模型拟合是时序数据分析的核心步骤之一,它用于建立时间序列数据的数学模型,以便对未来的数据进行预测和分析。
常用的模型拟合方法有ARIMA模型(自回归移动平均模型)、GARCH模型(广义自回归条件异方差模型)和VAR模型(向量自回归模型)。
ARIMA模型是一种常用的线性模型,它包括自回归部分、差分部分和移动平均部分。
ARIMA模型适用于平稳时间序列数据的建模和预测。
GARCH模型是一种用于建模条件异方差的模型,它能够捕捉时间序列数据中的波动性。
GARCH模型适用于金融领域的波动性建模和预测。
VAR模型是一种多变量时间序列模型,它能够捕捉不同变量之间的相互关系。