算法分析与设计实验五分枝—限界算法
- 格式:doc
- 大小:22.50 KB
- 文档页数:4

HUBEI UNIVERSITY OF AUTOMOTIVE TECHNOLOGY算法设计与分析实验报告实验项目实验五实验类别验证性学生姓名王龙学生学号201400797 完成日期2016-5-6指导教师刘振章实验成绩评阅日期评阅教师刘振章实验五:分枝限界法【实验目的】应用分枝限界法的算法设计思想求解单源最短路径问题。
【实验性质】验证性实验。
【实验内容与要求】采用分支限界法编程求源点0到终点6的最短路径及其路径长度。
要求完成:⑴算法描述⑵写出程序代码⑶完成调试⑷进行过程与结果分析。
【算法思想及处理过程】由于要找的是从源到各顶点的最短路径,所以选用一个数组存起来.Fenzhi函数: 由于先前赋值时, 用一个二维数组将结点的有向图标记存起来了( 有边为1, 无边为0 ),并且又用另外一个二维数组将其权重存起来了; 首先, 通过双重for循环, 通过if语句判断, 如果标记为1, 并且相加的权重小于先前最优权重( 在初始化的时候, 对最优权重赋上一个最大值 ), 则求得最优权重, 并且用一维数组将权重存起来, 而且用一维数组将前驱结点存起来.你然后, 一直循环下去, 直到循环到目的结点.【程序代码】for (z=0; z<k; z++){scanf ("%d %d %d", &i, &j, &m);t[i][j] = m;ti[i][j] = 1;}for (i = 0; i < n; i++) //初始化数组{d[i] = 99; // 赋个最大值s[i] = -1;}}void fenzhi (int d[], int s[],int t[][MAX], int ti[][MAX], int n, int k) {int i, j, zi;d[0]=0; s[0]=-1;for (i=0; i<n; i++){printf ("当前扩展节点:%d,权重:%d : \n", i, d[i]);for (j=0; j<n; j++){if (ti[i][j] == 1 ){if ( d[j]>t[i][j]+d[i]){d[j]=t[i][j]+d[i]; //最短长度s[j]=i; //前驱结点}if (j != n /* && j != 6 */ )printf ("入队结点:%d ,最优权重:%d \n", j, d[j]);}}printf ("\n");}}void output (int d[], int s[], int n){int i, j=0, zi[MAX];printf ("从源点到各个结点的最短路径: \n");for (i=0; i<n; i++)printf ("dist[%d] = %d \n", i, d[i]);printf ("\n");printf ("从源点到终点的最短路径长度为: %d \n", d[n-1]);printf ("其路径为: %d ", n-1);zi[j] = s[n-1];printf ("----> %d ", zi[j]);while (zi[j] != 0){j++;zi[j] = s[zi[j-1]];printf ("----> %d ", zi[j]);}printf ("\n");}【运行结果】图1 输入数据图2 输出扩展结点图3 最终结果【算法分析】本程序的主要函数ShorestPaths的时间复杂度为: O ( n * (n-1) ), 最坏时间复杂度为: O ( n*n )【实验总结】。

算法分析与设计分支限界法分支限界法是一种常用的优化算法,它通过剪枝和分支的方式在空间中找到最优解。
在算法设计与分析中,分支限界法在求解组合优化问题和图论问题中有广泛应用。
分支限界法的基本思想是将问题划分为一个个子问题,并对每个子问题进行求解,同时通过剪枝操作减少空间。
算法从一个初始状态开始,通过扩展子节点来生成树。
在每个节点上,先判断该节点是否需要剪枝操作。
如果需要剪枝,则舍弃该节点及其子节点;如果不需要剪枝,则继续扩展该节点为新的可能解。
通过不断扩展和剪枝操作,最终找到最优解。
分支限界法的核心是选择一个合适的策略来确定节点的扩展顺序。
常用的策略包括优先级队列、最小堆、最大堆等。
这些策略可以根据问题的性质和特点来选择,以保证效率。
同时,剪枝操作也是分支限界法中关键的一环。
剪枝操作有多种方式,如上界和下界剪枝、可行剪枝、标杆剪枝等。
通过剪枝操作,可以减少空间,提高算法的效率。
分支限界法的时间复杂度通常是指数级别的,因为每个节点需要根据策略进行扩展,并进行剪枝操作。
然而,通过合理选择策略和剪枝操作,可以显著减少空间,降低时间复杂度。
此外,分支限界法还可以通过并行计算等技术进一步提高效率。
分支限界法在求解组合优化问题中有广泛应用。
组合优化问题是在有限的资源条件下,通过组合和选择来达到最优解的问题。
例如,旅行商问题、背包问题等都是经典的组合优化问题,而分支限界法可以在有限的时间内找到最优解。
在图论问题中,分支限界法也有重要的应用。
例如,最短路径问题、图着色问题等都可以通过分支限界法求解。
总之,分支限界法是一种基于和剪枝的优化算法,通过合理选择策略和剪枝操作,在有限的时间内找到最优解。
该算法在组合优化问题和图论问题中有广泛应用,可以有效提高问题求解的效率。
在实际应用中,可以根据问题性质和特点选择合适的策略和剪枝操作,以达到最佳的求解效果。



五大常用算法之五:分支限界法五大常用算法之五:分支限界法分支限界法一、基本描述类似于回溯法,也是一种在问题的解空间树T上搜索问题解的算法。
但在一般情况下,分支限界法与回溯法的求解目标不同。
回溯法的求解目标是找出T中满足约束条件的所有解,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。
(1)分支搜索算法所谓“分支”就是采用广度优先的策略,依次搜索E-结点的所有分支,也就是所有相邻结点,抛弃不满足约束条件的结点,其余结点加入活结点表。
然后从表中选择一个结点作为下一个E-结点,继续搜索。
选择下一个E-结点的方式不同,则会有几种不同的分支搜索方式。
1)FIFO搜索2)LIFO搜索3)优先队列式搜索(2)分支限界搜索算法二、分支限界法的一般过程由于求解目标不同,导致分支限界法与回溯法在解空间树T上的搜索方式也不相同。
回溯法以深度优先的方式搜索解空间树T,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树T。
分支限界法的搜索策略是:在扩展结点处,先生成其所有的儿子结点(分支),然后再从当前的活结点表中选择下一个扩展对点。
为了有效地选择下一扩展结点,以加速搜索的进程,在每一活结点处,计算一个函数值(限界),并根据这些已计算出的函数值,从当前活结点表中选择一个最有利的结点作为扩展结点,使搜索朝着解空间树上有最优解的分支推进,以便尽快地找出一个最优解。
分支限界法常以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。
问题的解空间树是表示问题解空间的一棵有序树,常见的有子集树和排列树。
在搜索问题的解空间树时,分支限界法与回溯法对当前扩展结点所使用的扩展方式不同。
在分支限界法中,每一个活结点只有一次机会成为扩展结点。
活结点一旦成为扩展结点,就一次性产生其所有儿子结点。
在这些儿子结点中,那些导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被子加入活结点表中。


第八章分枝-限界法§1 算法基本思想本章叙述中为了区别图中的顶点和解空间树中的顶点,凡是在解空间树中出现的“顶点”一律称为“结点”。
分枝限界法同回溯法类似,它也是在解空间中搜索问题的可行解或最优解,但搜索的方式不同。
回溯法采用深度优先的方式,朝纵深方向搜索,直至达到问题的一个可行解,或经判断沿此路径不会达到问题的可行解或最优解时,停止向前搜索,并沿原路返回到该路径上最后一个还可扩展的结点。
从该结点出发朝新的方向纵深搜索。
分枝限界法则采用宽度优先的方式搜索解空间树,它将活结点存放在一个特殊的表中。
其策略是:在扩展结点处,首先生成其所有的儿子结点,将那些导致不可行解或导致非最优解的儿子舍弃,其余儿子加入活结点表中。
然后,从活结点表中取出一个结点作为当前扩展结点。
重复上述结点扩展过程。
所以,分枝限界法与回溯法的本质区别在于搜索方式的不同。
回溯法更适于处理那些求所有可行解的问题,而分枝限界法更适于处理那些只确定一个可行解,特别是最优解的问题。
从活结点表中选择下一扩展结点的不同方式导致不同的分枝限界法。
最常见的有以下两种方式:1).队列式(FIFO)分枝限界法:将活结点表组织成一个队列,并按队列的先进先出原则选取下一个结点作为当前扩展结点。
2).优先队列式分枝限界法:将活结点表组织成一个优先队列,并按优先队列给结点规定的优先级选取优先级最高的下一个结点作为当前扩展结点。
队列式分枝限界法搜索解空间树的方式类似于解空间树的宽度优先搜索,不同的是队列式分枝限界法不搜索不可行结点(已经被判定不能导致可行解或不能导致最优解的结点)为根的子树。
这是因为,按照规则,这样的结点未被列入活结点表。
优先队列式分枝限界法的搜索方式是根据活结点的优先级确定下一个扩展结点。
结点的优先级常用一个与该结点有关的数值p来表示。
最大优先队列规定p值较大的结点的优先级较高。
在算法实现时通常用一个最大堆来实现最大优先队列,用最大堆的Deletemax运算抽取堆中的下一个结点作为当前扩展结点,体现最大效益优先的原则。

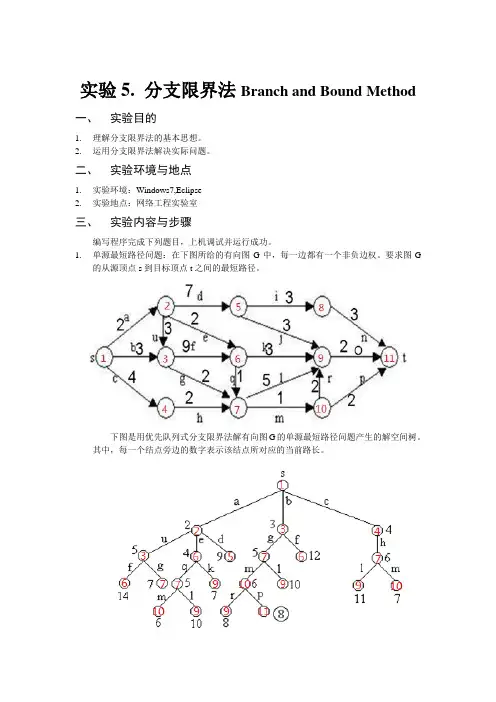
实验5. 分支限界法Branch and Bound Method一、实验目的1.理解分支限界法的基本思想。
2.运用分支限界法解决实际问题。
二、实验环境与地点1.实验环境:Windows7,Eclipse2.实验地点:网络工程实验室三、实验内容与步骤编写程序完成下列题目,上机调试并运行成功。
1.单源最短路径问题:在下图所给的有向图G中,每一边都有一个非负边权。
要求图G的从源顶点s到目标顶点t之间的最短路径。
下图是用优先队列式分支限界法解有向图G的单源最短路径问题产生的解空间树。
其中,每一个结点旁边的数字表示该结点所对应的当前路长。
算法思想:解单源最短路径问题的优先队列式分支限界法用一极小堆来存储活结点表。
其优先级是结点所对应的当前路长。
算法从图G的源顶点s和空优先队列开始。
结点s被扩展后,它的儿子结点被依次插入堆中。
此后,算法从堆中取出具有最小当前路长的结点作为当前扩展结点,并依次检查与当前扩展结点相邻的所有顶点。
如果从当前扩展结点i到顶点j有边可达,且从源出发,途经顶点i再到顶点j的所相应的路径的长度小于当前最优路径长度,则将该顶点作为活结点插入到活结点优先队列中。
这个结点的扩展过程一直继续到活结点优先队列为空时为止。
算法结束后,数组dist返回从源到各顶点的最短距离。
相应的最短路径容易从前驱顶点数组记录的信息构造出。
算法:public class BBShortest {static final float M=Float.MAX_VALUE;static class HeapNode implements Comparable {int i; // 顶点编号float length; // 当前路长HeapNode(int ii, float ll) {i = ii;length = ll;}public int compareTo(Object x) {float xl = ((HeapNode) x).length;if (length < xl)return -1;if (length == xl)return 0;return 1;}}// 1,2,3,4,5,6,7,8,9,10,11static float[][] a={{0,0,0,0,0,0,0,0,0,0,0,0,},{0,0,2,3,4,M,M,M,M,M,M,M,},//1{0,M,0,3,M,7,2,M,M,M,M,M,},//2{0,M,M,0,M,M,9,2,M,M,M,M,},//3{0,M,M,M,0,M,M,2,M,M,M,M,},//4{0,M,M,M,M,0,M,M,3,3,M,M,},//5{0,M,M,M,M,M,0,1,M,3,M,M,},//6{0,M,M,M,M,M,M,0,M,5,1,M,},//7{0,M,M,M,M,M,M,M,0,M,M,3,},//8{0,M,M,M,M,M,M,M,M,0,M,2,},//9{0,M,M,M,M,M,M,M,M,2,0,2,},//10{0,M,M,M,M,M,M,M,M,M,M,0,},//11}; // 图G的邻接矩阵static float[] dist=new float[a.length];static int[] p=new int[dist.length];public static void shortest(int v, float[] dist, int[] p) {int n = p.length - 1;MinHeap heap = new MinHeap();// 定义源为初始扩展结点HeapNode enode = new HeapNode(v, 0);for (int j = 1; j <= n; j++)dist[j] = Float.MAX_VALUE;dist[v] = 0;while (true) { // 搜索问题的解空间for (int j = 1; j <= n; j++)if (a[enode.i][j] < Float.MAX_VALUE && enode.length + a[enode.i][j] < dist[j]) {// 顶点i到顶点j可达,且满足控制约束dist[j] = enode.length + a[enode.i][j];p[j] = enode.i;HeapNode node = new HeapNode(j, dist[j]);heap.put(node); // 加入活结点优先队列}// 取下一扩展结点if (heap.isEmpty())break;elseenode = (HeapNode) heap.removeMin();}}}注意:实现算法时,MinHeap直接用PriorityQueue创建优先级队列。

第1篇一、实验目的1. 理解并掌握分枝限界法的基本原理和实现方法。
2. 通过实际编程,运用分枝限界法解决实际问题。
3. 比较分析分枝限界法与其他搜索算法(如回溯法)的优缺点。
4. 增强算法设计能力和编程实践能力。
二、实验内容本次实验主要涉及以下内容:1. 分支限界法的基本概念和原理。
2. 分支限界法在单源最短路径问题中的应用。
3. 分支限界法的实现步骤和代码编写。
4. 分支限界法与其他搜索算法的对比分析。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发环境:PyCharm四、实验步骤1. 算法描述:分支限界法是一种用于解决组合优化问题的算法,其基本思想是在问题的解空间树中,按照一定的搜索策略,优先选择有潜力的节点进行扩展,从而减少搜索空间,提高搜索效率。
2. 程序代码:下面是使用Python实现的分支限界法解决单源最短路径问题的代码示例:```pythonimport heapqclass Node:def __init__(self, vertex, distance, parent): self.vertex = vertexself.distance = distanceself.parent = parentdef __lt__(self, other):return self.distance < other.distancedef branch_and_bound(graph, source):初始化优先队列和已访问节点集合open_set = []closed_set = set()添加源节点到优先队列heapq.heappush(open_set, Node(source, 0, None))主循环,直到找到最短路径while open_set:弹出优先队列中最小距离的节点current_node = heapq.heappop(open_set)检查是否已访问过该节点if current_node.vertex in closed_set:continue标记节点为已访问closed_set.add(current_node.vertex)如果当前节点为目标节点,则找到最短路径if current_node.vertex == target:path = []while current_node:path.append(current_node.vertex)current_node = current_node.parentreturn path[::-1]遍历当前节点的邻居节点for neighbor, weight in graph[current_node.vertex].items():if neighbor not in closed_set:计算新节点的距离distance = current_node.distance + weight添加新节点到优先队列heapq.heappush(open_set, Node(neighbor, distance, current_node))没有找到最短路径return None图的表示graph = {0: {1: 2, 2: 3},1: {2: 1, 3: 2},2: {3: 2},3: {1: 3}}源节点和目标节点source = 0target = 3执行分支限界法path = branch_and_bound(graph, source)print("最短路径为:", path)```3. 调试与测试:在编写代码过程中,注意检查数据结构的使用和算法逻辑的正确性。
![算法分析与设计[分枝限界法]](https://uimg.taocdn.com/adbaad7f01f69e31433294ce.webp)
实验五分支限界算法的应用一、实验目的1.掌握分支限界算法的基本思想、技巧和效率分析方法。
2.熟练掌握用分支限界算法的基本步骤和算法框架,FIFO搜索,LIFO搜索,优先队列式搜索的思想。
3.学会利用分支限界算法解决实际问题。
二、算法问题描述批处理作业调度问题:n个作业{1, 2, …, n}要在两台机器上处理,每个作业必须先由机器1处理,然后再由机器2处理,机器1处理作业i所需时间为ai,机器2处理作业i所需时间为bi(1≤i≤n),批处理作业调度问题(batch-job scheduling problem)要求确定这n个作业的最优处理顺序,使得从第1个作业在机器1上处理开始,到最后一个作业在机器2上处理结束所需时间最少。
注意:由于要从n个作业的所有排列中找出具有最早完成时间的作业调度,所以,批处理作业调度问题的解空间是一棵排列树,并且要搜索整个解空间树才能确定最优解,因此,其时间性能是O(n!)。
在搜索过程中利用已得到的最短完成时间进行剪枝,才能够提高搜索速度。
三、算法设计批处理作业调度问题要从n个作业的所有排列中找出具有最小完成时间和的作业调度,所以如图,批处理作业调度问题的解空间是一颗排列树。
在作业调度问相应的排列空间树中,每一个节点E都对应于一个已安排的作业集。
以该节点为根的子树中所含叶节点的完成时间和可表示为:设|M|=r,且L是以节点E为根的子树中的叶节点,相应的作业调度为{pk,k=1,2,……n},其中pk是第k个安排的作业。
如果从节点E到叶节点L的路上,每一个作业pk在机器1上完成处理后都能立即在机器2上开始处理,即从pr+1开始,机器1没有空闲时间,则对于该叶节点L有:注:(n-k+1)t1pk,因为是完成时间和,所以,后续的(n-k+1)个作业完成时间和都得算上t1pk。
如果不能做到上面这一点,则s1只会增加,从而有:。
类似地,如果从节点E开始到节点L的路上,从作业pr+1开始,机器2没有空闲时间,则:同理可知,s2是的下界。
基本思想:分枝定界法是一个用途十分广泛的算法,运用这种算法的技巧性很强,不同类型的问题解法也各不相同。
分支定界法的基本思想是对有约束条件的最优化问题的所有可行解(数目有限)空间进行搜索。
该算法在具体执行时,把全部可行的解空间不断分割为越来越小的子集(称为分支),并为每个子集内的解的值计算一个下界或上界(称为定界)。
在每次分支后,对凡是界限超出已知可行解值那些子集不再做进一步分支。
这样,解的许多子集(即搜索树上的许多结点)就可以不予考虑了,从而缩小了搜索范围。
这一过程一直进行到找出可行解为止,该可行解的值不大于任何子集的界限。
因此这种算法一般可以求得最优解。
将问题分枝为子问题并对这些子问题定界的步骤称为分枝定界法。
分枝节点的选择:对搜索树上的某些点必须作出分枝决策,即凡是界限小于迄今为止所有可行解最小下界的任何子集(节点),都有可能作为分枝的选择对象(对求最小值问题而言)。
怎样选择搜索树上的节点作为下次分枝的节点呢?有两个原则:1)从最小下界分枝(优先队列式分枝限界法):每次算完界限后,把搜索树上当前所有叶节点的界限进行比较。
找出限界最小的节点,此结点即为下次分枝的结点。
·优点:检查子问题较少,能较快地求得最佳解;·缺点:要存储很多叶节点的界限及对应的耗费矩阵,花费很多内存空间。
2)从最新产生的最小下界分枝(队列式(FIFO)分枝限界法):从最新产生的各子集中按顺序选择各结点进行分枝,对于下届比上届还大的节点不进行分枝。
优点:节省了空间;缺点:需要较多的分枝运算,耗费的时间较多。
这两个原则更进一步说明了,在算法设计中的时空转换概念。
分枝定界法已经成功地应用于求解整数规划问题、生产进度表问题、货郎担问题、选址问题、背包问题以及可行解的数目为有限的许多其它问题。
对于不同的问题,分枝与界限的步骤和内容可能不同,但基本原理是一样的。
分枝界限法是组合优化问题的有效求解方法,其步骤如下所述:步骤一:如果问题的目标为最小化,则设定目前最优解的值Z=∞步骤二:根据分枝法则(Branching rule),从尚未被洞悉(Fathomed)节点(局部解)中选择一个节点,并在此节点的下一阶层中分为几个新的节点。
算法分析与设计实验五分枝―限界算法1、实现0/1背包问题的lc分枝―限界算法,要求使用大小固定的元组表示动态状态空间树,与0/1背包问题回溯算法做复杂性比较。
2、实现货郎担问题的分枝―限界算法并与货郎担问题的动态规划算法做复杂性比较比较。
3.实现了带截止期作业排序的分枝定界算法,并与带截止期作业排序的贪心算法进行了复杂度比较。
(选择一项完成)实验六分枝―限界算法实验目的1.掌握分枝―限界的基本思想方法;2.了解适合用分枝定界法求解的问题类型,并能设计相应的动态规划算法;3.掌握分枝定界算法的复杂性分析方法,分析问题的复杂性。
预习与实验要求1.预习实验教学和教材的相关内容,掌握分支定界的基本思想;2.严格按照实验内容进行实验,养成良好的算法设计和编程习惯;3.认真听,服从安排,独立思考,完成实验。
实验设备与器材硬件:PC软件:c++或java等编程环境实验原理分枝―限界算法类似于回溯法,也是一种在问题的解空间树上搜索问题解的算法。
但两者求解方法有两点不同:第一,回溯法只通过约束条件剪去非可行解,而分枝―限界法不仅通过约束条件,而且通过目标函数的限界来减少无效搜索,也就是剪掉了某些不包含最优解的可行解;第二,在解空间树上,回溯法以深度优先搜索,而分枝―限界法则以广度优先或最小耗费优先的方式搜索。
分枝―限界的搜索策略是,在扩展节点处,首先生成其所有的儿子结点(分支),然后再从当前的活结点表中选择下一个扩展结点。
为了有效地选择下一扩展结点,以加速搜索进程,在每一活结点处,计算一个函数值(限界),并根据这些已计算出的函数值从当前活结点表中选择一个最有利的结点做为扩展,使搜索朝着解空间树上最优解的分支推进,以便尽快找出一个最优解。
分枝定界法通常以广度优先或最小代价优先的方式搜索问题的解空间树(问题的解空间树是表示问题所有空间的有序树,常见的是子集树和排序树)。
在搜索问题的解空间树时,分枝定界法的每个活动节点只有一次机会成为扩展节点。
《算法设计与分析》实验报告实验5 分支限界算法姓名学号班级网络131实验日期2016.11.29 实验地点学院305一、实验目的:掌握分支限界算法的设计思想与设计方法。
二、实验环境1、硬件环境CPU:2.0GHz内存:4GB硬盘:100GB2、软件环境操作系统:win7编程环境:devc++编程语言:c三、实验内容1、问题有一个背包,最大限重为C,有n个物品,重量分别为W=<w1, w2, …, wn>,价值分别为V=<v1, v2, …, vn>要求使用分支限界算法找出一个装载方案,使得放入背包物品的价值之和最大。
输出装载方案和该方案下的背包所装物品总重量及总价值。
2、数据结构(1)解的结构typedef struct treenode(2)搜索空间的结构int bbfifoknap(int w[],int v[],int n,int c,int* bestValue)3、算法伪代码PackSolu(G, n, C)输入: G[]存储物品的数据结构,n表示物品个数,C表示背包容量输出:一个用来存储各个物品装入数目的数组1. Sort(G) // 将物品从大到小排序2. v<-0; w<-0; i<-0; // v表示装入背包的总值,w表示装入背包的总重,i表示物品的索引3. while i < n do4. if 背包可装下j个第i种物品5. then v<-(v+G[i].v);w<-(w+G[i].w);solu[i] = 1;6. else solu[i] = 0;7. if v >界的值best_v then 更新最优解8. while solu[i] = 0 and i > 0 do i--; // 回溯到上一个装入的物品9. if solu[i] > 0 then solu[i] = 0;w<-(w-G[i].w);v<-(v-G[i].v);i++10. if i > 0 then goto 34、算法分析时间复杂度:O(2^n)空间复杂度:O(n)5、关键代码(含注释)#include<iostream>#include<queue>using namespace std;typedef struct treenode{int weight;int value;int level;int flag;}treenode;queue<struct treenode> que;int enQueue(int w,int v,int level,int flag,int n,int* bestvalue) {treenode node;node.weight = w;node.value = v;node.level = level;node.flag = flag;if (level == n){if (node.value > *bestvalue){*bestvalue = node.value;}return 0;}else{que.push(node);}}//w为重量数组,v为价值数组,n为物品个数,c为背包容量,bestValue为全局最大价值int bbfifoknap(int w[],int v[],int n,int c,int* bestValue){//初始化结点int i=1;treenode tag, livenode;livenode.weight = 0;livenode.value = 0;livenode.level = 1;livenode.flag = 0;//初始为0tag.weight = -1;tag.value = 0;tag.level = 0;tag.flag = 0;//初始为0que.push(tag);while (1){if (livenode.weight + w[i - 1] <= c){enQueue(livenode.weight + w[i - 1], livenode.value + v[i - 1], i, 1,n,bestValue);}enQueue(livenode.weight,livenode.value, i, 0,n,bestValue);livenode = que.front();que.pop();if (livenode.weight == -1){if (que.empty() == 1){break;}livenode = que.front();que.pop();que.push(tag);i++;}}return 0;}6、实验结果(1)输入:C=10,n=4,W=<7, 4, 3, 2>,V=<9, 5, 3, 1>输出:12(2)输入:C=10,n=5,V=<10, 32, 12, 20, 18>,W=<1, 4, 2, 4, 6>输出:64四、实验总结(心得体会、需要注意的问题等)这次学习的是分支界限算法。
1、实现0/1背包问题的LC分枝—限界算法,要求使用大小固定的元组表示动态状态空间树,与0/1背包问题回溯算法做复杂性比较。
2、实现货郎担问题的分枝—限界算法并与货郎担问
题的动态规划算法做复杂性比较比较。
3、实现带有期限的作业排序的分枝—限界算法并与
带有期限的作业排序贪心算法做复杂性比较。
(任选一个完成)
实验六分枝—限界算法
实验目的
1.掌握分枝—限界的基本思想方法;
2.了解适用于用分枝—限界方法求解的问题类型,并能设计相应动态规划算法;
3.掌握分枝—限界算法复杂性分析方法,分析问题复杂性。
预习与实验要求
1.预习实验指导书及教材的有关内容,掌握分枝—限界的基本思想;
2.严格按照实验内容进行实验,培养良好的算法设计和编程的习惯;
3.认真听讲,服从安排,独立思考并完成实验。
实验设备与器材
硬件:PC机
软件:C++或Java等编程环境
实验原理
分枝—限界算法类似于回溯法,也是一种在问题的解空间树上搜索问题解的算法。
但两者求解方法有两点不同:第一,回溯法只通过约束条件剪去非可行解,而分枝—限界法不仅通过约束条件,而且通过目标函数的限界来减少无效搜索,也就是剪掉了某些不包含最优解的可行解;第二,在解空间树上,回溯法以深度优先搜索,而分枝—限界法则以广度优先或最小耗费优先的方式搜索。
分枝—限界的搜索策略是,在扩展节点处,首先生成其所有的儿子结点(分支),然后再从当前的活结点表中选择下一个扩展结点。
为了有效地选择下一扩展结点,以加速搜索进程,在每一活结点处,计算一个函数值(限界),并根据这些已计算出的函数值从当前活结点表中选择一个最有利的结点做为扩展,使搜索朝着解空间树上最优解的分支推进,以便尽快找出一个最优解。
分枝—限界法常以广度优先或以最小耗费优先的方式搜索问题的解空间树(问题的解空间树是表示问题皆空间的一颗有序树,常见的有子集树和排序树)。
在搜索问题的解空间树时,分枝—限界法的每一个活结点只有一次机会成为扩展结点。
活结点一旦成为扩展结点,就一次性产生其所有儿子结点。
在这些儿子结点中,那些导致不可行解或非最优解的儿子结点将被舍弃,其余儿子结点被加入活结点表中。
此后,从活结点表取出下一结点成为当前扩展结点,并重复上述扩展过程,直到找到最优解或活结点表为空时停止。
实验内容
以下三个问题选做一项:
1.实现0-1背包问题的分枝—限界算法。
(1)选择合适的数据结构来表示问题,其中要求使用大小固定的元组表示动态状态空间树;
(2)确定限界函数;
(3)根据分枝—限界法的基本原理,写出求解0-1背包问题的伪码算法;
(4)编制C++或JA V A等高级语言程序实现伪码算法;
(5)上机运行程序,验证算法的正确性;
(6)作时空复杂性分析,并与用回溯法解0-1背包问题作比较。
2.实现货郎担问题的分枝—限界算法。
(1)选择合适的数据结构来表示问题;
(2)确定限界函数;
(3)根据分枝—限界法的基本原理,写出求解货郎担问题的伪码算法;
(4)编制C++或JA V A等高级语言程序实现伪码算法;
(5)上机运行程序,验证算法的正确性;
(6)作时空复杂性分析,并与用动态规划法解货郎担问题作比较。
3.实现带有期限的作业排序问题的分枝—限界算法。
(1)选择合适的数据结构来表示问题;
(2)确定限界函数;
(3)根据分枝—限界法的基本原理,写出求解带有期限的作业排序问题的伪码算法;
(4)编制C++或JA V A等高级语言程序实现伪码算法;
(5)上机运行程序,验证算法的正确性;
(6)作时空复杂性分析,并与用贪心法解带有期限的作业排序问题作比较。
实验报告
1.描述分枝—限界法的基本原理;
2.写出用分枝—限界法实现0-1背包问题、货郎担问题或带有期限的作业排序问题的
伪码算法,写出算法所用到的主要数据结构,简要画出各问题的解空间树以及搜索
过程,写出限界函数;
3.得出结果,并写出算法的时间复杂性和空间复杂性,并与其他算法解题作比较。
4.详细填写完成实验的收获和得失,实验过程中遇到的问题、解决的办法、实验心得
以及对该实验的建议和意见。
思考题
1.分枝—限界法适合解决哪些问题?
2.怎样确定限界函数?限界函数是固定不变的吗?。