第9章 因子分析
- 格式:pdf
- 大小:4.45 MB
- 文档页数:36


《基础生态学》(第三版)名词解释绪论1)生态学(ecology):是研究有机体及其周围环境-包括非生物环境和生物环境相互关系的科学。
2)尺度(Scale):某一现象或过程在空间、时间上所涉及到的范围和发生频率。
3)生物圈(biosphere):地球上的全部生物和一切适合于生物栖息的场所。
包括岩石圈的上层、全部水圈和大气圈的下层。
4)景观生态学(landscape ecology):研究景观单元的类型组成,空间格局及其与生态学过程相互作用的科学。
(景观是由不同生态系统组成的异质性区域,生态系统在景观中形成斑块(patch))5)全球生态学(global ecology):研究全球性的环境问题与全球变化。
其主要理论为:地球表面温度和化学组成受地球所有生物总体的生命活动所主动调节,并保持动态平衡。
第一章生物与环境6)环境(environment):某一特定生物体或生物群体以外的空间,以及直接或间接影响该生物体或生物群体生存的一切事物的总和。
7)生境或栖息地(habitat):指特定生物体或群体所处的物理环境。
8)生态因子(ecological factor):环境中对生物的生长、发育、生殖、行为和分布有直接或间接影响的环境要素。
9相互作用或交互作用(interaction):生物与生物之间的相互关系。
10)反作用(counteraction):生物对环境的影响,一般称为反作用。
表现在生物的影响改变了环境因子的状况。
11)利比希最小因子定律(Liebig’s law of the minimum):植物的生长取决于处于最小量状况的营养物质的量。
即:每一种植物都需要一定种类和数量的营养物,如果其中有一种营养物完全缺失,植物就不能生存。
如果该种营养物数量极微,就会对植物的生长产生不良影响。
12)限制因子(Limiting factor):在众多的环境因素中,任何接近或超过某种生物的耐受性极限而阻止其生存、生长、繁殖或扩散的因素,叫限制因子。
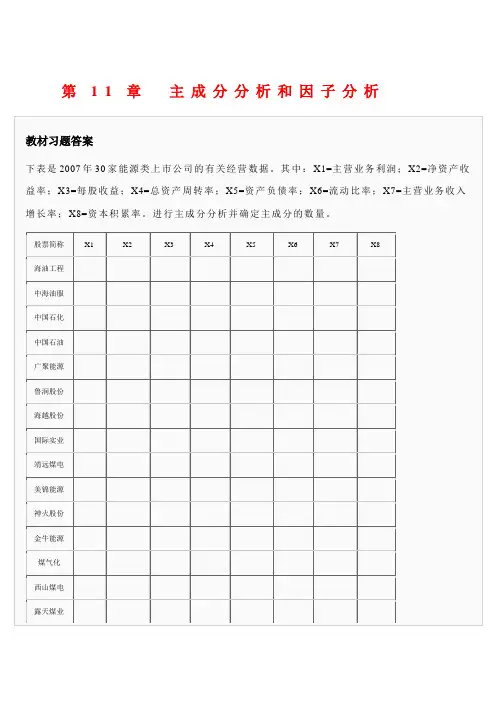


第九章 对应分析§9.1 什么是对应分析及基本思想对应分析又称为相应分析,于1970年由法国统计学家J.P.Beozecri 提出来的。
它是在R 型和Q 型因子分析基础上发展起来的一种多元统计方法。
由前一章我们知道应用因子分析的方法,可以用较少的几个公共因子去提取研究对象的绝大部分信息,即可减少因子的数目,又把握住了研究对象之间的相互关系。
但是因子分析根据研究对象的不同又分为R 型因子分析和Q 型因子分析,即对指标(变量)作因子分析和对样品作因子分析是分开进行的,这样做往往会漏掉一些指标与样品之间有关的一些信息,另外在处理实际问题中,样品的个数远远地大于变量个数。
比如有100个样品,每个样品测10项指标,要作Q 型因子分析,就要计算(100×100)阶相似系数阵的特征根和特征向量,这对于一般小型计算机的容量和速度都是难以胜任的。
对应分析是将R 型因子分析与Q 型分子分析结合起来进行统计分析,它是从R 型因子分析出发,而直接获得Q 型因子分析的结果。
克服了由样品容量大,作Q 型分析所带来的计算上的困难。
另外根据R 型和Q 型分析的内在联系,可将指标(变量)和样品同时反映到相同坐标轴(因子轴)的一张图形上,便于对问题的分析。
比如在图形上邻近的一些样品则表示它们的关系密切归为一类,同样邻近的一些变量点则表示它们的关系密切归为一类,而且属地同一类型的样品点,可用邻近的变量点来表征。
因此,对应分析,概括起来可提供如下三方面的信息即指标之间的关系,样品之间的关系,以及指标与样品之间的关系。
基本思想:由于R 型因子分析和Q 型因子分析都是反映一个整体的不同侧面,因此它们之间一定存在内在的联系。
对应分析就是通过一个过渡矩阵Z 将二者有机地结合起来,具体地说,首先给出变量点的协差阵Z Z A '=和样品点的协差阵Z Z B '=,由于Z Z '和Z Z '有相同的非零特征根记为),m i n(0,21n p m m ≤<≥≥≥λλλ ,如果A 的特征根i λ对应的特征向量为i U ,则B 的特征根i λ对应的特征向量就是i i V ZU ∆,根据这个结论(后面有证明)就可以很方便的借助R 型因子分析而得到Q 型因子分析的结果。


医学统计学第3版课程设计1. 课程概述本课程是医学统计学第3版课程设计,是为了帮助医学生掌握医学统计学的基本概念、方法和技能,以及其在临床、流行病学和健康科研中的应用。
该课程通过课堂讲授、案例分析和实践练习等方式,授予学生医学统计学的知识和技能,是医学生必修课程之一。
2. 课程目标•掌握医学统计学的基本知识和方法;•学会应用医学统计学进行数据分析和推断;•了解医学统计学在临床、流行病学和健康科研中的应用;•能够运用医学统计学方法分析和评估临床研究和公共卫生问题;•能够熟练运用SPSS等统计软件进行数据管理和分析。
3. 课程内容和教学方法3.1 课程内容本课程内容包括基本概念、计量方法、推断方法、回归分析、实验设计、临床试验、流行病学和生存分析等方面的内容。
具体包括以下章节:•第一章:绪论•第二章:描述性统计学•第三章:概率理论和分布•第四章:参数估计•第五章:假设检验•第六章:回归分析•第七章:方差分析•第八章:因子分析•第九章:生存分析•第十章:实验设计•第十一章:临床试验•第十二章:流行病学3.2 教学方法本课程采用面授讲解、案例分析和实践练习相结合的方式,教师将采用多媒体辅助教学和互动式教学方法,引导学生积极思考和参与,培养学生的分析思维和解决实际问题的能力。
具体教学方法包括:•面授讲解•小组案例分析•课堂讨论•实践练习•课程作业4. 评估方法本课程评估分为平时成绩和期末考试两部分。
平时成绩包括:•课堂出席率•作业完成情况•小组案例分析报告期末考试为闭卷考试,考试题型包括选择题、计算题和应用题。
5. 参考教材本课程参考教材为《医学统计学》第3版,作者为雷公达、叶志明、王立平。
此外,教师还会补充相关的学术论文和国际标准等资料。
6. 总结医学统计学是医学生必修课程之一,是医学生进行临床医学和公共卫生研究的重要工具。
本课程将通过多种教学方法,为学生提供全面的医学统计学知识和技能,为学生未来的学习和研究奠定坚实基础。


第八章_因子分析因子分析是一种常用的多元统计分析方法,它通过对观测变量之间的关系进行综合考虑,将它们归纳为较少数量的共同因子,并解释这些因子与观测变量之间的关系。
因子分析可以用来发现数据背后的隐藏结构和模式,从而提高数据的解释力和预测能力。
1.因子分析的主要应用领域因子分析在许多领域中都有广泛应用。
在社会科学领域,因子分析常用于对人的主观评价和态度的研究,例如对消费者满意度、领导能力等方面的研究。
在市场研究中,因子分析可以将众多的市场指标归纳为几个关键的影响因素,从而更好地了解市场的特点和消费者的需求。
在心理学领域,因子分析可以用来研究人的智力、性格、态度等方面的因素。
在生物医学领域,因子分析可以用来研究疾病的病因,如心脏病的发病机制等。
2.因子分析的基本原理因子分析的基本原理是通过对观测变量之间的协方差矩阵进行特征值分解,找出最能解释观测变量之间关系的共同因子。
首先,将原始数据标准化,然后计算变量之间的协方差矩阵。
接下来,对协方差矩阵进行特征值分解,得到一组特征值和特征向量。
根据特征值的大小,选择前k个最大的特征值对应的特征向量,作为共同因子的估计。
最后,通过因子载荷矩阵和因子得分矩阵,将观测变量映射到共同因子上进行解释。
3.因子分析的步骤因子分析的步骤主要包括:确定研究对象和目标、准备数据、选择因子提取方法、确定因子数目、因子旋转和解释因子。
(1)确定研究对象和目标:确定要进行因子分析的变量和要研究的问题,例如对消费者满意度进行因子分析,研究消费者满意度的主要影响因素。
(2)准备数据:收集数据并进行预处理,包括缺失值处理、异常值处理和变量标准化。
(3)选择因子提取方法:根据数据的特点和研究目标选择适合的因子提取方法,常见的方法包括主成分分析、主因子分析和最大似然估计。
(4)确定因子数目:根据特征值和方差贡献率等指标,确定最优的因子数目。
(5)因子旋转:对提取的因子进行旋转,使得每个因子上的变量载荷更加清晰和有意义。

第13章因子分析因子分析始于1904年Chars Spearman对学生成绩的分析,在经济领域有着极为广泛的用途。
在多个变量的变化过程中,除了一些特定因素之外,还受到一些共同因素的影响。
因此,每个变量可以拆分成两部分,一是共同因素,二是特殊因素。
这些共同因素称为公因子,特殊因素称为特殊因子。
因子分析即是提出多个变量的公共影响因子的一种多元统计方法,它是主成分分析的推广。
因子分析主要解决两类问题:一是寻求基本结构,简化观察系统。
给定一组变量或观察数据,是否存在一个子集,特别是一个加权子集,来解释整个问题,即将为数众多的变量减少为几个新的因子,以再现它们之间的内在联系。
二是用于分类,将变量或样本进行分类,根据因子得分值,在因子轴所构成的空间中进行分类处理。
p个变量X的因子模型表达式为:f称为公因子,Λ称为因子载荷。
X的相关系数矩阵分解为:对于未旋转的因子,1Φ。
ψ称为特殊度,即每个变量中不属于共性的部=分。
13.1 因子估计Stata可以通过变量进行因子分析,也可以通过矩阵进行。
命令为factor 或factormat。
webuse bg2,cleardescribefactor bg2cost1-bg2cost6factor bg2cost1-bg2cost6, factors(2)* pf 主因子方法,用复相关系数的平方作为因子载荷的估计量(默认选项)factor bg2cost1-bg2cost6, factors(2) pcf* pcf 主成分因子,假定共同度=1factor bg2cost1-bg2cost6, factors(2) ipf* ipf 迭代主因子,重复估计共同度factor bg2cost1-bg2cost6, factors(2) ml* ml 极大似然因子,假定变量(至少3个)服从多元正态分布,对偏相关矩阵的行列式进行最优化求解,等价于Rao的典型因子方法13.2 预测Stata可以通过predict预测变量得分、拟合值和残差等。
第9章因子分析与主成份分析因子分析与因子分析进程因子分析是将多个实测变量转换为少数几个不相关的综合指标的多元统计分析方式。
线性综合指标往往是不能直接观测到的,但它更能反映事物的本质。
因子分析概念在各个领域的科学研究中往往需要对反映事物的多个变量进行大量的观测,搜集大量数据以便进行分析寻觅规律。
多变量大样本无疑会为科学研究提供丰硕的信息,但也在必然程度上增加了数据收集的工作量,更重要的是在大多数情形下,许多变量之间可能存在相关性而增加了问题分析的复杂性。
由于各变量之间存在必然的相关关系,因此有可能用较少的综合指标别离综合存在于各变量中的各类信息,而综合指标之间彼此不相关,即各指标代表的信息不重叠。
如此就可以够对综合指标按照专业知识和指标所反映的独特含义给予命名。
这种分析方式成为因子分析,代表各类信息的综合指标就称为因子或主成份。
按照因子分析的目的咱们明白,综合指标应该比原始变量少,但包括的信息量应该相对损失较少。
原始变量:X一、X二、X3、X4……Xm主成份:Z一、Z二、Z3、Z4……Zn则各因子与原始变量之间的关系能够表示成:X1=b11Z1+b12Z2+b13Z3……+b1n Z n+e1X2=b21Z1+b22Z2+b23Z3……+b2n Z n+e2X3=b31Z1+b32Z2+b33Z3……+b3n Z n+e3……X m=b m1Z1+b m2Z2+b m3Z3……+b mn Z n+en写成矩阵形式为:X=BZ+E。
其值X为原始变量向量,B为公因子负荷系数矩阵,Z为公因子向量,E为残差向量。
公因子Z一、Z二、Z3…Zn之间彼此不相关,称为正交模型。
因子分析的任务就是求出公因子负荷系数和残差。
若是残差E的影响很小能够忽略不计,数学模型变成X=BZ。
若是Z中各分量之间彼此不相关,形成特殊形式的因子分析,称为主成份分析。
主成份分析的数学模型能够写成:Z1=a11X 1+a12X2+a13X 3……+a1m X mZ2=a21X 1+a22X2+a23X 3……+a2m X mZ3=a31X 1+a32X2+a33X 3……+a3m X m……Z n=an1X 1+an2X2+an3X 3……+anm X m写成矩阵形式为:Z=AX。
第9章 因子分析及R使用
Ø了解因子分析的目的和实际意义
Ø熟悉因子分析建模的条件和因子的实际意义
Ø掌握因子载荷的推导步骤,以及性质
Ø能用R语言解决实际因子分析问题,给出分析报告
Ø因子分析模型的基本思想,与主成分分析的区别Ø因子分析的数学模型,假定,因子载荷估计方法Ø因子旋转和因子得分的实际意义和数学表达式ØR语言计算程序中有关因子分析的算法基础
Ø主成分分析通过线性组合将原变量综合成几个主成分Ø因子分析通过构筑若干意义较为明确的公因子
Ø主成分分析是“变异数”导向的方法,
Ø因子分析是“共变异数”导向的方法。
因子分析是主成分分析的推广
ü因子变量数远少于原变量数
ü因子变量是一种新的综合
ü因子变量之间没有相关关系
ü因子变量具有明确的解释性
ü减少分析变量个数;
ü通过对变量间关系探测,将原变量进行分类。
ü将相关性较高的分在同一类中,每一类代表了一个基本结构,即公因子。
ü用少数不可测的公共因子的线性函数来描述原观测的每一分量。
ü样品间的因子分析称为Q型因子分析,
ü变量间的因子分析称为R型因子分析。
R型因子模型
X = AF + ε
A = (a ij)为因子载荷阵,F为公因子,ε为特殊因子
【例9.1】水泥行业上市公司经营业绩因子模型实证分析
【例9.1】水泥行业上市公司经营业绩因子模型实证分析
极大似然估计因子估计方法
主因子估计
9.3.1 极大似然估计法
9.3.1 极大似然估计法
因子载荷loadings
是x i 与F j 的相关系数
表示x i 依赖F j 的程度
9.3.2 主因子估计法
9.3.2 主因子估计法
9.3.2 主因子估计法
9.3.3 因子载荷的意义
方差贡献
共同度
因子载荷a ij表示x i依赖F j的程度,
其值越大,依赖程度越大。
9.3.3 方差贡献及共同度
ü寻找每个主因子的实际意义
ü如果各主因子的典型代表变量不突出,就需要进行旋转ü使因子载荷矩阵中载荷的绝对值向0和1两个方向分化
9.3.2 主因子估计法
正交旋转斜交旋转Varimax(最大方差正交旋转法)Promax
因子旋转方法
如何进行旋转
求B 的载荷系数方差达到最大的θ即可获得正交矩阵Γ
回归估计法
Bartlett 估计法因子得分
计算方法
X =AF + ε
Var (ε)=σ2I Var (ε)=Ω
回归法因子得分
因子得分信息图
综合得分及排名
【例9.4】 (续例3.1、例7.2和例8.2) 对我国居民消费数据进行因子分析
因子分析的核心问题
一是如何构造因子变量二是如何解释因子变量
一、确认数据是否适合作因子分析
二、构造因子变量
三、旋转因子使其更具可解释性
四、计算因子得分并做因子图一般运用KMO 与Bartlett's 进行验证> 0.9非常适合0.8~0.9适合0.7~0.8一般0.6~0.7不太适合0.5~0.6不适合< 0.5极不适合
R语言因子分析过程
一、因子计算
(1)是否适合做因子分析:KMO
(2)计算因子分析的对象:factanal, msa.fa (3)按方差贡献定因子数:>80%
(4)获得因子载荷并解释:$loadings
(5)是否需进行因子旋转:'varimax'二、因子评价
(6)因子得分:$scores (7)因子信息图:biplot (8)综合得分:加权得分(9)得分排序:$ranks
1
问题的定义2因子分析的适应性3确定因子数目4
因子旋转5
因子解释6
因子得分7因子分析的意义
一个完整的因子分析过程应当包含如下方面:。