第十一章多元线性回归与logistic回归
- 格式:doc
- 大小:376.00 KB
- 文档页数:9

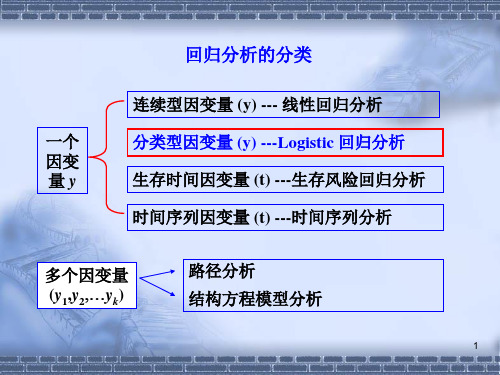
logistic回归和线性回归1.输出:线性回归输出是连续的、具体的值(如具体房价123万元)回归逻辑回归的输出是0~1之间的概率,但可以把它理解成回答“是”或者“否”(即离散的⼆分类)的问题分类2.假设函数线性回归:θ数量与x的维度相同。
x是向量,表⽰⼀条训练数据逻辑回归:增加了sigmoid函数逻辑斯蒂回归是针对线性可分问题的⼀种易于实现⽽且性能优异的分类模型,是使⽤最为⼴泛的分类模型之⼀。
sigmoid函数来由假设某件事发⽣的概率为p,那么这件事不发⽣的概率为(1-p),我们称p/(1-p)为这件事情发⽣的⼏率。
取这件事情发⽣⼏率的对数,定义为logit(p),所以logit(p)为因为logit函数的输⼊取值范围为[0,1](因为p为某件事情发⽣的概率),所以通过logit函数可以将输⼊区间为[0,1]转换到整个实数范围内的输出,log函数图像如下将对数⼏率记为输⼊特征值的线性表达式如下:其中,p(y=1|x)为,当输⼊为x时,它被分为1类的概率为hθ(x),也属于1类别的条件概率。
⽽实际上我们需要的是给定⼀个样本的特征输⼊x,⽽输出是⼀个该样本属于某类别的概率。
所以,我们取logit函数的反函数,也被称为logistic函数也就是sigmoid函数ϕ(z)中的z为样本特征与权重的线性组合(即前⾯的ΘT x)。
通过函数图像可以发现sigmoid函数的⼏个特点,当z趋于正⽆穷⼤的时候,ϕ(z)趋近于1,因为当z趋于⽆穷⼤的时候,e^(-z)趋于零,所以分母会趋于1,当z趋于负⽆穷⼤的时候,e^(-z)会趋于正⽆穷⼤,所以ϕ(z)会趋于0。
如在预测天⽓的时候,我们需要预测出明天属于晴天和⾬天的概率,已知根天⽓相关的特征和权重,定义y=1为晴天,y=-1为⾬天,根据天⽓的相关特征和权重可以获得z,然后再通过sigmoid函数可以获取到明天属于晴天的概率ϕ(z)=P(y=1|x),如果属于晴天的概率为80%,属于⾬天的概率为20%,那么当ϕ(z)>=0.8时,就属于⾬天,⼩于0.8时就属于晴天。




logistic回归与多元线性回归区别及若干问题讨论logistic回归与多元线性回归区别及若干问题讨论1多重线性回归(MultipleLinearRegression)Logistic回归(LogisticRegression)概念多重线性回归模型可视为简单直线模型的直接推广,具有两个及两个以上自变量的线性模型即为多重线性回归模型。
属于概率型非线性回归,是研究二分类(可扩展到多分类)观察结果与一些影响因素之间关系的一种多变量分析方法。
变量的特点应变量:1个;数值变量(正态分布)自变量:2个及2个以上;最好是数值变量,也可以是无序分类变量、有序变量。
应变量:1个;二分类变量(二项分布)、无序/有序多分类变量自变量:2个及2个以上;数值变量、二分类变量、无序/有序多分类变量总体回归模型LogitP=(样本)偏回归系数含义表示在控制其它因素或说扣除其它因素的作用后(其它所有自变量固定不变的情况下),某一个自变量变化一个单位时引起因变量Y变化的平均大小。
表示在控制其它因素或说扣除其它因素的作用后(其它所有自变量固定不变的情况下),某一因素改变一个单位时,效应指标发生与不发生事件的概率之比的对数变化值(logitP的平均变化量),即lnOR。
适用条件LINE:1、L:线性——自变量X与应变量Y之间存在线性关系;2、I:独立性——Y 值相互独立,在模型中则要求残差相互独立,不存在自相关;3、N:正态性——随机误差(即残差)e服从均值为零,方差为2的正态分布;4、E:等方差——对于所有的自变量X,残差e的方差齐。
观察对象(case)之间相互独立;若有数值变量,应接近正态分布(不能严重偏离正态分布);二分类变量服从二项分布;要有足够的样本量;LogitP与自变量呈线性关系。
11 Logistic回归分析在中医药科研中,经常遇到因变量是分类变量(包括二分类和多分类)的资料,如治 愈与未治愈,生存与死亡,发病与未发病,疗效评价分显效、好转、无效等级等。
这类资 料,由于因变量是分类变量不具有连续性和正态性,直接用一般多元线性回归分析是不妥 的,需用Logistic 回归分析。
Logistic 回归分析是一种适用于因变量为分类变量的回归分析, 近年来在许多研究领域得到了广泛的应用。
Logistic 回归属于概率型非线性回归, 它分为非条件Logistic 回归和条件Logistic 回归(又 称配比Logistic 回归),二者根本的差别在于构造 Logistic 模型时是前者未使用条件概率, 后 者使用了条件概率。
11.1二分类资料的Logistic 回归分析如果因变量Y 是二分类变量,其取值只有两种,如阳性(编码为1)和阴性(编码为0), 这时要说明的问题是阳性率p 二P (Y =1)与自变量X 间的关系,可进行因变量为二分类资料的Logistic 回归。
二分类Logistic 回归对自变量没有特殊要求,自变量可以是分类变量和 连续变量。
11.1.1一个两分类自变量的二分类 Logistic 回归1操作步骤(1)指定频数变量:选择菜单Data T Weight cases,在弹出的Weight cases 对话框中,将频数变量 f 送入Frequency 框中;单击 OK 。
(2)进行二分类 Logistic 回归分析。
选择菜单 AnalyzeT Regression T Binary Logistic (二分类 Logistic ),弹出 Logistic Regression 对话框,如图 11-2;将因变量 lx 送入 Dependent (因变量)框内,将自变量 fz 送入Covariates (协变量)框内;单击 Options (选项)按钮,一个自变量的二分类 Logistic 回归要拟合的 Logistic 回归方程为:log it ( p )二 ln (~^) = b o bX1 -P例11-1 《实用中医药杂志》2006年1月 第22卷1期,复方血栓通胶囊配合肌苷片治疗 青少年近视,数据见表11-1。
第十一章 多元线性回归与logistic 回归一、教学大纲要求(一)掌握内容1.多元线性回归分析的概念:多元线性回归、偏回归系数、残差。
2.多元线性回归的分析步骤:多元线性回归中偏回归系数及常数项的求法、多元线性回归的应用。
3.多元线性回归分析中的假设检验:建立假设、计算检验统计量、确定P 值下结论。
4.logistic 回归模型结构:模型结构、发病概率比数、比数比。
5.logistic 回归参数估计方法。
6.logistic 回归筛选自变量:似然比检验统计量的计算公式;筛选自变量的方法。
(二)熟悉内容常用统计软件(SPSS 及SAS )多元线性回归分析方法:数据准备、操作步骤与结果输出。
(三)了解内容标准化偏回归系数的解释意义。
二、教学内容精要(一) 多元线性回归分析的概念将直线回归分析方法加以推广,用回归方程定量地刻画一个应变量Y 与多个自变量X 间的线形依存关系,称为多元线形回归(multiple linear regression ),简称多元回归(multiple regression )基本形式:01122ˆk kY b b X b X b X =+++⋅⋅⋅+ 式中Y ˆ为各自变量取某定值条件下应变量均数的估计值,1X ,2X ,…,k X 为自变量,k 为自变量个数,0b 为回归方程常数项,也称为截距,其意义同直线回归,1b ,2b ,…, k b 称为偏回归系数(partial regression coefficient ),j b 表示在除j X 以外的自变量固定条件下,j X 每改变一个单位后Y 的平均改变量。
(二) 多元线性回归的分析步骤Y ˆ是与一组自变量1X ,2X ,…,k X 相对应的变量Y 的平均估计值。
多元回归方程中的回归系数1b ,2b ,…, k b 可用最小二乘法求得,也就是求出能使估计值Y ˆ和实际观察值Y 的残差平方和22)ˆ(∑∑-=Y Y e i 为最小值的一组回归系数1b ,2b ,…,k b 值。
第十一章 多元线性回归与logistic 回归一、教学大纲要求(一)掌握内容1.多元线性回归分析的概念:多元线性回归、偏回归系数、残差。
2.多元线性回归的分析步骤:多元线性回归中偏回归系数及常数项的求法、多元线性回归的应用。
3.多元线性回归分析中的假设检验:建立假设、计算检验统计量、确定P 值下结论。
4.logistic 回归模型结构:模型结构、发病概率比数、比数比。
5.logistic 回归参数估计方法。
6.logistic 回归筛选自变量:似然比检验统计量的计算公式;筛选自变量的方法。
(二)熟悉内容常用统计软件(SPSS 及SAS )多元线性回归分析方法:数据准备、操作步骤与结果输出。
(三)了解内容标准化偏回归系数的解释意义。
二、教学内容精要(一) 多元线性回归分析的概念将直线回归分析方法加以推广,用回归方程定量地刻画一个应变量Y 与多个自变量X 间的线形依存关系,称为多元线形回归(multiple linear regression ),简称多元回归(multiple regression )基本形式:01122ˆk kY b b X b X b X =+++⋅⋅⋅+ 式中Y ˆ为各自变量取某定值条件下应变量均数的估计值,1X ,2X ,…,kX 为自变量,k 为自变量个数,0b 为回归方程常数项,也称为截距,其意义同直线回归,1b ,2b ,…, k b 称为偏回归系数(partial regression coefficient ),j b 表示在除j X 以外的自变量固定条件下,j X 每改变一个单位后Y 的平均改变量。
(二) 多元线性回归的分析步骤Y ˆ是与一组自变量1X ,2X ,…,kX 相对应的变量Y 的平均估计值。
多元回归方程中的回归系数1b ,2b ,…, k b 可用最小二乘法求得,也就是求出能使估计值Y ˆ和实际观察值Y 的残差平方和22)ˆ(∑∑-=Y Y e i 为最小值的一组回归系数1b ,2b ,…,k b 值。
根据以上要求,用数学方法可以得出求回归系数1b ,2b ,…, k b 的下列正规方程组(normal equation ):⎪⎪⎩⎪⎪⎨⎧=+++=+++=+++ky kk k k k yk k y k k l l b l b l b l l b l b l b l l b l b l b 22112222221111122111式中()()()()i j ij ji i i j j i j X X l l X X X X X X n==--=-∑∑∑∑∑∑∑∑-=--=nY X Y X Y Y X Xl i i i iiy ))(())((常数项0b 可用下式求出:k k X b X b X b Y b ----= 22110(三)多元线性回归分析中的假设检验在算得各回归系数并建立回归方程后,还应对此多元回归方程作假设检验,判断自变量1X ,2X ,…,k X 是否与Y 真有线性依存关系,也就是检验无效假设0H (1230k ββββ===== ), 备选假设1H 为各j β值不全等于0或全不等于0。
检验时常用统计量F)1(--==k n l k l MS MS F 误差回归误差回归式中n 为个体数,k 为自变量的个数。
式中 ky k y y l b l b l b l +++= 2211回归回归总误差l l l -=()∑=-=yy l Y Y l 2总(四) logistic 回归模型结构设k X X X ,,,21 为一组自变量,Y 为应变量。
当Y 是阳性反应时,记为Y =1;当Y 是阴性反应时,记为Y =0。
用P 表示发生阳性反应的概率;用Q 表示发生阴性反应的概率,显然P +Q =1。
Logistic 回归模型为:kk kk X X X X X X e e P ββββββββ+++++++++=22110221101同时可以写成:kk X X X e Q ββββ+++++=2211011式中0β是常数项;(12)j j k β= ,,,是与研究因素j X 有关的参数,称为偏回归系数。
事件发生的概率P 与x β之间呈曲线关系,当x β在()∞∞-,之间变化时, P 或Q 在(0,1)之间变化。
若有n 例观察对象,第i 名观察对象在自变量ik i i X X X ,,,21 作用下的应变量为i Y ,阳性反应记为i Y =1,否则i Y =0。
相应地用i P 表示其发生阳性反应的概率;用i Q 表示其发生阴性反应的概率,仍然有i P +i Q =1。
i P 和i Q 的计算如下:01122011221i i k iki i k ikX X X X X X P i e e ββββββββ++++++++=+0112211i i k iki X X X Q e ββββ++++=+这样,第i 个观察对象的发病概率比数(odds )为i i Q P ,第l 个观察对象的发病概率比数为l l Q P ,而这两个观察对象的发病概率比数之比值便称为比数比OR (odds ratio )。
对比数比取自然对数得到关系式:ln )()()(222111lk ik k l i l i l l i i X X X X X X Q P Q P -++-+-=⎪⎪⎭⎫⎝⎛βββ 等式左边是比数比的自然对数,等式右边的()ljij X X -()k j ,,, 21=是同一因素iX的不同暴露水平ij X 与lj X 之差。
j β的流行病学意义是在其它自变量固定不变的情况下,自变量j X 的暴露水平每改变一个测量单位时所引起的比数比的自然对数改变量。
或者说,在其他自变量固定不变的情况下,当自变量j X 的水平每增加一个测量单位时所引起的比数比为增加前的jeβ倍。
同多元线性回归一样,在比较暴露因素对反应变量相对贡献的大小时,由于各自变量的取值单位不同,也不能用偏回归系数的大小作比较,而须用标准化偏回归系数来做比较。
标准化偏回归系数值的大小,直接反映了其相应的暴露因素对应变量的相对贡献的大小。
标准化偏回归系数的计算,可利用有关统计软件在计算机上解决。
(五)logistic 回归参数估计由于logistic 回归是一种概率模型,通常用最大似然估计法(maximum likelihood estimate )求解模型中参数j β的估计值(12)j b j k = ,,,。
Y 为在k X X X ,,,21 作用下的阳性事件(或疾病)发生的指示变量。
其赋值为:⎩⎨⎧=应个观察对象出现阴性反,第应个观察对象出现阳性反,第i i Y i 01第i 个观察对象对似然函数的贡献量为:1i iY Y i i il P Q -= 当各事件是独立发生时,则n 个观察对象所构成的似然函数L 是每个观察对象的似然函数贡献量的乘积,即∏∏==-==n i ni Y i Y i i i i Q P l L 111式中∏为i 从1到n 的连乘积。
依最大似然估计法的原理,使得L 达到最大时的参数值即为所求的参数估计值,计算时通常是将该似然函数取自然对数(称为对数似然函数)后,用Newton —Raphson 迭代算法求解参数估计值)21(k j bj,,, =。
(六)logistic 回归筛选自变量在logistic 回归中,筛选自变量的方法有似然比检验(likelihood ratiotest )、计分检验(score test)、Wald 检验(Wald test)三种。
其中似然比检验较为常用,用Λ表示似然比检验统计量,计算公式为:())ln (ln 2ln 2''L L L L -==Λ式中ln 为自然对数的符号,L 为方程中包含)(k m m <个自变量的似然函数值,'L 为在方程中包含原m 个自变量的基础上再加入1个新自变量j X 后的似然函数值。
在无效假设0H 条件下,统计量Λ服从自由度为1的2χ分布。
当2)1(αχ≥Λ时,则在α水平上拒绝无效假设,即认为j X 对回归方程的贡献具有统计学意义,应将j X 引入到回归方程中;否则,不应加入。
逆向进行即可剔除自变量。
三、典型试题分析(一)单项选择题1.多元线性回归分析中,反映回归平方和在应变量Y 的总离均差平方和中所占比重的统计量是( )。
A . 复相关系数B . 偏相关系数C . 偏回归系数D . 确定系数 答案:D[评析] 本题考点:多元线性回归中的几个概念的理解。
多元线性回归中的偏回归系数(multiple linear regression )表示在其它自变量固定不变的情况下,自变量j X 每改变一个单位时,单独引起应变量Y 的平均改变量。
确定系数(coefficient of determination )表示回归平方和回归SS 占总离均差平方和总SS 的比例,简记为2R 。
即总回归SS SS R =2。
确定系数的平方根即R 称为复相关系数(multiple correlation coefficient ),它表示p 个自变量共同对应变量线性相关的密切程度,它不取负值, 即0≤R ≤1。
2.Logistic 回归分析适用于应变量为( )。
A .分类值的资料B .连续型的计量资料C .正态分布资料D .一般资料答案:A[评析] 本题考点:logistic 回归的概念。
logistic 回归属于概率型回归,可用来分析某类事件发生的概率与自变量之间的关系。
适用于应变量为分类值的资料,特别适用于应变量为二项分类的情形。
模型中的自变量可以是定性离散值,也可以是计量观测值。
(二)计算题根据表11-2数据,分别用SPSS 统计软件、SAS 统计软件写出多元线性回归的统计分析步骤及其简要结果。
表11-1 某学校20名一年级女大学生肺活量及有关变量测量结果编号 体重1X /kg 胸围2X /cm 肩宽3X /cm 肺活量Y /L1 50.8 73.2 36.3 2.96 2 49.0 84.1 34.5 3.13 3 42.8 78.3 31.0 1.914 55.0 77.1 31.0 2.635 45.3 81.7 30.0 2.86 6 45.3 74.8 32.0 1.917 51.4 73.7 36.5 2.98 8 53.8 79.4 37.0 3.289 49.0 72.6 30.1 2.52 10 53.9 79.5 37.1 3.27 11 48.8 83.8 33.9 3.10 12 52.6 88.4 38.0 3.28 13 42.7 78.2 30.9 1.92 14 52.5 88.3 38.1 3.27 15 55.1 77.2 31.1 2.64 16 45.2 81.6 30.2 2.85 17 51.4 78.3 36.5 3.16 18 48.7 72.5 30.0 2.51 19 51.3 78.2 36.4 3.15 20 45.8 75.0 32.5 1.94 答案:SPSS :数据文件:“EXAP11—2.sav ”。