sql分组后二次汇总(处理表重复记录查询和删除)的实现方法
- 格式:doc
- 大小:11.50 KB
- 文档页数:1

SQL重复记录查询1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from peoplewhere peopleId in(select peopleId from people group by peopleId having count(peopleId) >1)2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录delete from people where peopleId in(select peopleId from people group by peopleId havingcount(peopleId) > 1) and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)3、查找表中多余的重复记录(多个字段)select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录delete from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)(二)比方说在A表中存在一个字段“name”,而且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;Select Name,Count(*) From A Group By Name Having Count(*) > 1如果还查性别也相同大则如下:Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1(三)方法一declare @max integer,@id integerdeclare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1open cur_rowsfetch cur_rows into @id,@maxwhile @@fetch_status=0beginselect @max = @max -1set rowcount @maxdelete from 表名 where 主字段 = @idfetch cur_rows into @id,@maxendclose cur_rowsset rowcount 0方法二有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
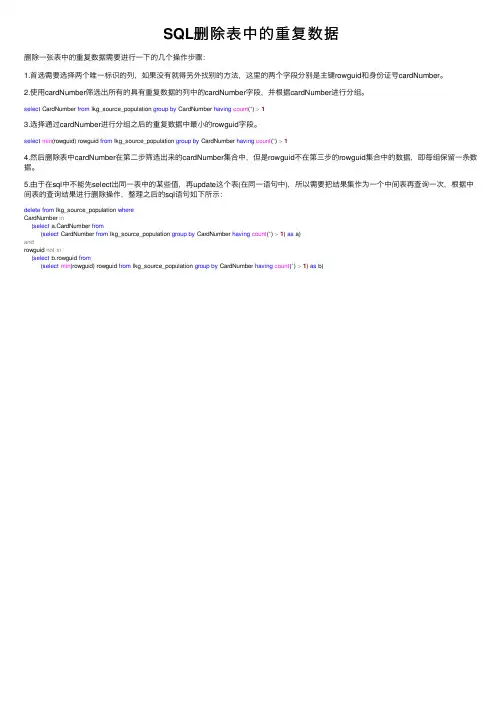
SQL删除表中的重复数据删除⼀张表中的重复数据需要进⾏⼀下的⼏个操作步骤:1.⾸选需要选择两个唯⼀标识的列,如果没有就得另外找别的⽅法,这⾥的两个字段分别是主键rowguid和⾝份证号cardNumber。
2.使⽤cardNumber筛选出所有的具有重复数据的列中的cardNumber字段,并根据cardNumber进⾏分组。
select CardNumber from lkg_source_population group by CardNumber having count(*) >13.选择通过cardNumber进⾏分组之后的重复数据中最⼩的rowguid字段。
select min(rowguid) rowguid from lkg_source_population group by CardNumber having count(*) >14.然后删除表中cardNumber在第⼆步筛选出来的cardNumber集合中,但是rowguid不在第三步的rowguid集合中的数据,即每组保留⼀条数据。
5.由于在sql中不能先select出同⼀表中的某些值,再update这个表(在同⼀语句中),所以需要把结果集作为⼀个中间表再查询⼀次,根据中间表的查询结果进⾏删除操作,整理之后的sql语句如下所⽰:delete from lkg_source_population whereCardNumber in(select a.CardNumber from(select CardNumber from lkg_source_population group by CardNumber having count(*) >1) as a)androwguid not in(select b.rowguid from(select min(rowguid) rowguid from lkg_source_population group by CardNumber having count(*) >1) as b)。

查询和删除同一表内一个或多个字段重复记录的SQL语句比如此刻有一人员表(表名:peosons)假假想将姓名、身份证号、住址这三个字段完全相同的记录查询出来select p1.* from persons p1,persons p2 where <> and = and = and =能够实现上述成效.几个删除重复记录的SQL语句1.用rowid方式2.用group by方式3.用distinct方式1。
用rowid方式据据oracle带的rowid属性,进行判定,是不是存在重复,语句如下:查数据:select * from table1 a where rowid !=(select max(rowid)from table1 b where = and =......)删数据:delete from table1 a where rowid !=(select max(rowid)from table1 b where = and =......)by方式查数据:select count(num), max(name) from student --列出重复的记录数,并列出他的name属性group by numhaving count(num) >1 --按num分组后找出表中num列重复,即显现次数大于一次删数据:delete from studentgroup by numhaving count(num) >1如此的话就把所有重复的都删除。
3.用distinct方式-关于小的表比较有效create table table_new as select distinct * from table1 minuxtruncate table table1;insert into table1 select * from table_new;查询及删除重复记录的方式大全1、查找表中多余的重复记录,重复记录是依照单个字段(peopleId)来判定select * from peoplewhere peopleId in(select peopleId from people group by peopleId having count(peopleId) > 1)2、删除表中多余的重复记录,重复记录是依照单个字段(peopleId)来判定,只留有rowid 最小的记录delete from peoplewhere peopleId in (select peopleId frompeople group by peopleId having count(peopleId) > 1)and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)3、查找表中多余的重复记录(多个字段)select * from vitae awhere , in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录delete from vitae awhere , in (select peopleId,seq from vitae group by peopleId,seq having count(*) >1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)5、查找表中多余的重复记录(多个字段),不包括rowid最小的记录select * from vitae awhere , in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)(二)例如说在A表中存在一个字段“name”,而且不同记录之间的“name”值有可能会相同,此刻确实是需要查询出在该表中的各记录之间,“name”值存在重复的项;Select Name,Count(*) From A Group By Name Having Count(*) > 1若是还查性别也相同大那么如下:Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1(三)方式一declare @max integer,@id integerdeclare cur_rows cursor local for select 主字段,count(*) from 表名group by 主字段having count(*) >;1open cur_rowsfetch cur_rows into @id,@maxwhile @@fetch_status=0beginselect @max = @max -1set rowcount @maxdelete from 表名where 主字段= @idfetch cur_rows into @id,@maxendclose cur_rowsset rowcount 0方式二"重复记录"有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部份关键字段重复的记录,比如Name字段重复,而其他字段不必然重复或都重复能够忽略。

sql数据查重复方法
在SQL中,如果你想查找重复的数据,你可以使用 `GROUP BY` 和
`HAVING` 子句。
以下是一个基本的例子,演示如何查找重复的记录:
假设我们有一个名为`students` 的表,其中包含`id`, `name`, 和`age` 列。
```sql
SELECT name, age
FROM students
GROUP BY name, age
HAVING COUNT() > 1;
```
这个查询将返回所有名字和年龄的组合,这些组合在表中出现超过一次。
解释:
1. `GROUP BY name, age`: 这将数据按照名字和年龄进行分组。
2. `HAVING COUNT() > 1`: 这将只选择那些出现超过一次的组。
注意:这个查询只会返回重复的名字和年龄的组合,不会告诉你具体的重复记录是什么。
如果你需要知道具体的重复记录,你需要使用更复杂的查询或者在应用程序中进行处理。

SQL去重的三种方法汇总SQL去重是指在查询结果中去掉重复的记录。
在实际应用中,我们经常需要对数据库中的数据进行去重操作,以便得到准确且唯一的结果。
本文将介绍三种常用的SQL去重方法:使用DISTINCT关键字、使用GROUPBY子句、使用窗口函数以及使用临时表。
一、使用DISTINCT关键字DISTINCT关键字用于查询结果去除重复的行。
它可用于SELECT语句中,对特定的字段进行去重操作。
示例:SELECT DISTINCT column1, column2 FROM table_name;这条SQL语句将返回去除了重复行的column1和column2字段的结果集。
使用DISTINCT关键字的优点是简单易用,适用于简单的去重需求。
但它的缺点是性能较低,对于大数据量的查询,可能会导致查询时间过长。
二、使用GROUPBY子句GROUPBY子句用于将查询结果按照一些或多个字段进行分组,然后可以对每个分组进行聚合操作。
在使用GROUPBY子句时,需要使用聚合函数(如COUNT、SUM等),以便对每个分组进行统计。
示例:SELECT column1, column2 FROM table_name GROUP BY column1, column2;这条SQL语句将返回对column1和column2字段进行分组后的结果集,每组中只包含一个唯一的值。
使用GROUPBY子句的优点是性能较好,适用于对复杂的查询结果进行去重。
但它的缺点是需要对查询结果进行聚合操作,可能会导致查询结果的失真。
三、使用窗口函数窗口函数是一种高级的SQL技术,可以对查询结果进行排序、分组和聚合操作。
在去重操作中,我们可以使用窗口函数的ROW_NUMBER(函数来为每一行分配一个唯一的行号,然后根据行号进行筛选。
示例:SELECT column1, column2 FROMSELECT column1, column2, ROW_NUMBER( OVER(PARTITION BYcolumn1, column2 ORDER BY column1) AS rnFROM table_nameAStWHERE rn = 1;这条SQL语句将返回根据column1和column2字段去重后的结果集。

sql去重用法在SQL中,你可以使用各种方法去除重复的记录。
以下是一些常见的方法:1. 使用DISTINCT关键字:这是最简单的方法,它返回唯一的行。
```sqlSELECT DISTINCT column1, column2, ...FROM table_name;```2. 使用ROW_NUMBER()窗口函数:如果你想基于某些条件去重,可以使用ROW_NUMBER()。
例如,假设你有一个包含重复姓名的表,并且你想保留每个姓名的最新记录。
```sqlWITH CTE AS (SELECT ,ROW_NUMBER() OVER(PARTITION BY name ORDER BY date_column DESC) as rnFROM table_name)SELECT FROM CTE WHERE rn = 1;```3. 使用GROUP BY:当你想要根据某个列的值聚合其他列的值时,可以使用GROUP BY。
但请注意,这不会返回原始表中的所有列,只会返回聚合的列和选择的列。
```sqlSELECT column1, MAX(column2), ...FROM table_nameGROUP BY column1;```4. 使用临时表或JOIN:有时,你可以使用临时表或JOIN来达到去重的效果。
这取决于你的具体需求和数据结构。
5. 使用窗口函数与DELETE:如果你想从表中删除重复的行并保留一个,你可以结合使用窗口函数和DELETE语句。
例如:```sqlDELETE t1FROM table_name t1JOIN table_name t2ON < AND _column = _columnWHERE > ;```在上面的例子中,我们基于`duplicate_column`列删除重复的行,只保留一个。
6. 使用子查询与NOT EXISTS:这是一个稍微复杂的方法,但有时很有用:```sqlSELECT column1, column2, ...FROM table_name t1WHERE NOT EXISTS (SELECT 1 FROM table_name t2 WHERE _column = _column AND > );```在这个例子中,我们基于`key_column`列删除重复的行,只保留一个。

sql删除重复数据的详细⽅法完全重复的数据,通常是由于没有设置主键/唯⼀键约束导致的。
测试数据:复制代码代码如下:if OBJECT_ID('duplicate_all') is not nulldrop table duplicate_allGOcreate table duplicate_all(c1 int,c2 int,c3 varchar(100))GOinsert into duplicate_allselect 1,100,'aaa' union allselect 1,100,'aaa' union allselect 1,100,'aaa' union allselect 1,100,'aaa' union allselect 1,100,'aaa' union allselect 2,200,'bbb' union allselect 3,300,'ccc' union allselect 4,400,'ddd' union allselect 5,500,'eee'GO(1) 借助临时表利⽤DISTINCT得到单条记录,删除源数据,然后导回不重复记录。
如果表不⼤的话,可以把所有记录导出⼀次,然后truncate表后再导回,这样可以避免delete的⽇志操作。
复制代码代码如下:if OBJECT_ID('tempdb..#tmp') is not nulldrop table #tmpGOselect distinct * into #tmpfrom duplicate_allwhere c1 = 1GOdelete duplicate_all where c1 = 1GOinsert into duplicate_allselect * from #tmp(2) 使⽤ROW_NUMBER复制代码代码如下:with tmpas(select *,ROW_NUMBER() OVER(PARTITION BY c1,c2,c3 ORDER BY(getdate())) as numfrom duplicate_allwhere c1 = 1)delete tmp where num > 1如果多个表有完全重复的⾏,可以考虑通过UNION将多个表联合,插到⼀个新的同结构的表,SQL Server会帮助去掉表和表之间的重复⾏。

⽤SQL语句删除重复记录
今天⼀同学在QQ上问我"⽤SQL语句删除重复记录,如何把具有相同字段的记录删除,只留下⼀条。
"
平时懒得想的我就在百度查了⼀下,发现很多都很⿇烦,都要得⽤临时表,把重复数据复制到临时表再做处理.相当⿇烦.
于是还是⾃⼰写SQL语句吧.
例如表frmZHProductResult⾥有id,zhproductid字段,如果有zhproductid相同的记录只留下⼀条,其余的删除。
zhproductid的内容不定,相同的记录数不定。
那么只要我把重复数据列出来,不就可以了?于是为了不马上删除数据.我先把想要删除的数据列出来,看是否有错:
代码
1SELECT*FROM frmZHProductResult where id<>(select max(id) from frmZHProductResult d where frmZHProductResult.zhproductid =d.zhproductid ) 2AND zhproductid in (select zhproductid from frmZHProductResult b GROUP BY ZhproductId HAVING COUNT(ZhproductId)>1)
3
结果,的确是我所想要的数据.
呵呵,那么直接删除了.把select * from 换成 Delete.。

查询和删除表中重复数据sql语句1、查询表中重复数据。
select * from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最⼩的记录delete from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)3、查找表中多余的重复记录(多个字段)select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)4、删除表中多余的重复记录(多个字段),只留有rowid最⼩的记录delete from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)5、查找表中多余的重复记录(多个字段),不包含rowid最⼩的记录select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)(⼆)⽐⽅说在A表中存在⼀个字段“name”,⽽且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;Select Name,Count(*) From A Group By Name Having Count(*) > 1如果还查性别也相同⼤则如下:Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1(三)⽅法⼀declare @max integer,@id integerdeclare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1open cur_rowsfetch cur_rows into @id,@maxwhile @@fetch_status=0beginselect @max = @max -1set rowcount @maxdelete from 表名 where 主字段 = @idfetch cur_rows into @id,@maxendclose cur_rowsset rowcount 0⽅法⼆"重复记录"有两个意义上的重复记录,⼀是完全重复的记录,也即所有字段均重复的记录,⼆是部分关键字段重复的记录,⽐如Name字段重复,⽽其他字段不⼀定重复或都重复可以忽略。

删除数据库中重复数据的几个方法1.使用DISTINCT关键字查询重复数据:DISTINCT关键字可以用于从查询结果中去除重复的数据。
例如,可以使用以下SQL语句查询数据库中的重复数据,并删除重复的数据:```sqlDELETE FROM your_tableWHERE id NOT INSELECT MIN(id)FROM your_tableGROUP BY column_name```这个SQL语句将删除你的表中除了具有最小id的记录之外的所有重复记录。
2.使用临时表删除重复数据:另一种常用的方法是使用临时表将重复数据存储起来,然后再根据需要删除重复数据。
以下是一个示例:```sqlCREATE TABLE temp_table LIKE your_table;INSERT INTO temp_tableSELECTDISTINCT*FROM your_table;DELETE FROM your_table;INSERT INTO your_tableSELECT*FROM temp_table;DROP TABLE temp_table;```这个方法首先创建一个与你的表相同结构的临时表,然后使用DISTINCT关键字将去除重复的数据插入到临时表中。
接下来,删除你的表中的所有数据,并将临时表中的数据重新插入到你的表中。
最后,删除临时表。
3.使用GROUPBY和HAVING子句删除重复数据:GROUPBY和HAVING子句可以用于根据指定的列对数据进行分组,并删除重复分组。
以下是一个示例:```sqlDELETE FROM your_tableWHERE id NOT INSELECT MIN(id)FROM your_tableGROUP BY column_nameHAVINGCOUNT(*)>1```这个SQL语句将删除你的表中重复分组的记录,只保留每个分组中具有最小id的记录。

sql删除重复数据方法在SQL中,可以使用多种方法删除重复数据。
以下是一些常见的方法:1.使用DISTINCT关键字:DISTINCT关键字用于从结果集中仅选择唯一的值。
可以将DISTINCT用于SELECT语句,以选择指定列中的唯一值。
例如,如果要删除表中name列中的重复数据,可以使用以下语句:```DELETE FROM table_name WHERE id NOT IN (SELECT MIN(id) FROM table_name GROUP BY name);```这将删除除具有最小ID值的记录外,表中所有name列的重复记录。
2.使用临时表:可以使用临时表来删除重复数据。
首先,创建一个临时表,将表中的数据插入到临时表中。
然后,从临时表中删除重复数据。
最后,将临时表中的数据重新插入到原始表中。
以下是一个使用临时表删除重复数据的例子:```--创建临时表CREATE TABLE temp_table AS SELECT DISTINCT * FROMoriginal_table;--清空原始表TRUNCATE TABLE original_table;--从临时表中重新插入数据到原始表INSERT INTO original_table SELECT * FROM temp_table;```请注意,上述示例省略了保持表结构的细节。
3.使用ROW_NUMBER(函数:ROW_NUMBER(函数为每个行分配一个唯一的数字。
可以使用该函数删除重复数据。
以下是一个使用ROW_NUMBER(函数删除重复数据的例子:```DELETEFROMSELECT column1, column2, column3, ROW_NUMBER( OVER (PARTITION BY column1, column2, column3 ORDER BY (SELECT 0)) AS rnFROM table_nametWHERE t.rn > 1;```上述示例按列column1、column2和column3进行分组,并按指定的顺序为每个组分配唯一的行号。
SQL查询重复数据和清除重复数据分类:SQL 2008-05-20 11:03 34086人阅读评论(1) 收藏举报sqlsqlserversunjoin选择重复,消除重复和选择出序列有例表:empemp_no name age001 Tom 17002 Sun 14003 Tom 15004 Tom 16要求:列出所有名字重复的人的记录(1)最直观的思路:要知道所有名字有重复人资料,首先必须知道哪个名字重复了:select name from emp group by name having count(*)>1所有名字重复人的记录是:select * from empwhere name in (select name from emp group by name having count(*)>1)(2)稍微再聪明一点,就会想到,如果对每个名字都和原表进行比较,大于2个人名字与这条记录相同的就是合格的,就有select * from emp where (select count(*) from emp e where =) >1注意一下这个>1,想下如果是=1,如果是=2 如果是>2 如果 e 是另外一张表而且是=0那结果就更好玩了:)这个过程是在判断工号为001的人的时候先取得001的名字()然后和原表的名字进行比较注意e是emp的一个别名。
再稍微想得多一点,就会想到,如果有另外一个名字相同的人工号不与她他相同那么这条记录符合要求:select * from empwhere exists(select * from emp e where = and e.emp_no<>emp.emp_no)此思路的join写法:select emp.* from emp,emp ewhere = and emp.emp_no<>e.emp_no/* 这个语句较规范的join 写法是select emp.* from emp inner join emp e on = and emp.emp_no<>e.emp_no但个人比较倾向于前一种写法,关键是更清晰*/b、有例表:empname ageTom 16Sun 14Tom 16Tom 16清除重复过滤掉所有多余的重复记录(1)我们知道distinct、group by 可以过滤重复,于是就有最直观的select distinct * from emp 或select name,age from emp group by name,age获得需要的数据,如果可以使用临时表就有解法:select distinct * into #tmp from empdelete from empinsert into emp select * from #tmp(2)但是如果不可以使用临时表,那该怎么办?我们观察到我们没办法区分数据(物理位置不一样,对SQL Server来说没有任何区别),思路自然是想办法把数据区分出来了,既然现在的所有的列都没办法区分数据,唯一的办法就是再加个列让它区分出来,加什么列好?最佳选择是identity列:alter table emp add chk int identity(1,1)表示例:name age chkTom 16 1Sun 14 2Tom 16 3Tom 16 4重复记录可以表示为:select * from emp where (select count(*) from emp e where =)>1要删除的是:delete from empwhere (select count(*) from emp e where = and e.chk>=emp.chk)>1再把添加的列删掉,出现结果。
sql去除重复的⼏种⽅法
所以⽤这样⼀句SQL就可以去掉重复项了:
select * from msg group by terminal_id;
SQL中distinct的⽤法(四种⽰例分析)
⽰例1
select distinct name from A
执⾏后结果如下:
⽰例2
select distinct name, id from A
执⾏后结果如下:
实际上是根据“name+id”来去重,distinct同时作⽤在了name和id上,这种⽅式Access和SQL Server同时⽀持。
⽰例3:统计
select count(distinct name) from A; --表中name去重后的数⽬, SQL Server⽀持,⽽Access不⽀持
select count(distinct name, id) from A; --SQL Server和Access都不⽀持
⽰例4
select id, distinct name from A; --会提⽰错误,因为distinct必须放在开头
其他
distinct语句中select显⽰的字段只能是distinct指定的字段,其他字段是不可能出现的。
例如,假如表A有“备注”列,如果想获取distinc name,以及对应的“备注”字段,想直接通过distinct是不可能实现的。
SQL删除重复数据方法例如:id name value1 a pp2 a pp3 b iii4 b pp5 b pp6 c pp7 c pp8 c iiiid是主键要求得到这样的结果id name value1 a pp3 b iii4 b pp6 c pp8 c iii方法1delete YourTablewhere [id] not in (select max([id]) from YourTablegroup by (name + value))方法2delete afrom 表 a left join(select id=min(id) from 表group by name,value)b on a.id=b.idwhere b.id is null查询及删除重复记录的SQL语句查询及删除重复记录的SQL语句1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from peoplewhere peopleId in (select peopleId from people group by peopleId havingcount(peopleId) > 1)2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录delete from peoplewhere peopleId in (select peopleId from people group by peopleId havingcount(peopleId) > 1)and rowid not in (select min(rowid) from people group by peopleId havingcount(peopleId )>1)3、查找表中多余的重复记录(多个字段)select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录delete from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1) 5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1) (二)比方说在A表中存在一个字段“name”,而且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;Select Name,Count(*) From A Group By Name Having Count(*) > 1如果还查性别也相同大则如下:Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1(三)方法一declare @max integer,@id integerdeclare cur_rows cursor local for select 主字段,count(*) from 表名group by 主字段having count(*) >;1open cur_rowsfetch cur_rows into @id,@maxwhile @@fetch_status=0beginselect @max = @max -1set rowcount @maxdelete from 表名where 主字段= @idfetch cur_rows into @id,@maxendclose cur_rowsset rowcount 0方法二"重复记录"有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
sql分组后⼆次汇总(处理表重复记录查询和删除)的实现⽅法--处理表重复记录(查询和删除)/******************************************************************************************************************************************************1、Num、Name相同的重复值记录,没有⼤⼩关系只保留⼀条2、Name相同,ID有⼤⼩关系时,保留⼤或⼩其中⼀个记录整理⼈:中国风(Roy)⽇期:2008.06.06******************************************************************************************************************************************************/ --1、⽤于查询重复处理记录(如果列没有⼤⼩关系时2000⽤⽣成⾃增列和临时表处理,SQL2005⽤row_number函数处理)--> --> (Roy)⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table #TGoCreate table #T([ID] int,[Name] nvarchar(1),[Memo] nvarchar(2))Insert #Tselect 1,N'A',N'A1' union allselect 2,N'A',N'A2' union allselect 3,N'A',N'A3' union allselect 4,N'B',N'B1' union allselect 5,N'B',N'B2'Go--I、Name相同ID最⼩的记录(推荐⽤1,2,3),⽅法3在SQl05时,效率⾼于1、2⽅法1:Select * from #T a where not exists(select 1 from #T where Name= and ID<a.ID)⽅法2:select a.* from #T a join (select min(ID)ID,Name from #T group by Name) b on = and a.ID=b.ID⽅法3:select * from #T a where ID=(select min(ID) from #T where Name=)⽅法4:select a.* from #T a join #T b on = and a.ID>=b.ID group by a.ID,,a.Memo having count(1)=1⽅法5:select * from #T a group by ID,Name,Memo having ID=(select min(ID)from #T where Name=)⽅法6:select * from #T a where (select count(1) from #T where Name= and ID<a.ID)=0⽅法7:select * from #T a where ID=(select top 1 ID from #T where Name= order by ID)⽅法8:select * from #T a where ID!>all(select ID from #T where Name=)⽅法9(注:ID为唯⼀时可⽤):select * from #T a where ID in(select min(ID) from #T group by Name)--SQL2005:⽅法10:select ID,Name,Memo from (select *,min(ID)over(partition by Name) as MinID from #T a)T where ID=MinID⽅法11:select ID,Name,Memo from (select *,row_number()over(partition by Name order by ID) as MinID from #T a)T where MinID=1/*ID Name Memo----------- ---- ----1 A A14 B B1(2 ⾏受影响)*/--II、Name相同ID最⼤的记录,与min相反:⽅法1:Select * from #T a where not exists(select 1 from #T where Name= and ID>a.ID)⽅法2:select a.* from #T a join (select max(ID)ID,Name from #T group by Name) b on = and a.ID=b.ID order by ID ⽅法3:select * from #T a where ID=(select max(ID) from #T where Name=) order by ID⽅法4:select a.* from #T a join #T b on = and a.ID<=b.ID group by a.ID,,a.Memo having count(1)=1⽅法5:select * from #T a group by ID,Name,Memo having ID=(select max(ID)from #T where Name=)⽅法6:select * from #T a where (select count(1) from #T where Name= and ID>a.ID)=0⽅法7:select * from #T a where ID=(select top 1 ID from #T where Name= order by ID desc)⽅法8:select * from #T a where ID!<all(select ID from #T where Name=)⽅法9(注:ID为唯⼀时可⽤):select * from #T a where ID in(select max(ID) from #T group by Name)--SQL2005:⽅法10:select ID,Name,Memo from (select *,max(ID)over(partition by Name) as MinID from #T a)T where ID=MinID⽅法11:select ID,Name,Memo from (select *,row_number()over(partition by Name order by ID desc) as MinID from #T a)T where MinID=1⽣成结果2:/*ID Name Memo----------- ---- ----3 A A35 B B2(2 ⾏受影响)*/--2、删除重复记录有⼤⼩关系时,保留⼤或⼩其中⼀个记录--> --> (Roy)⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table #TGoCreate table #T([ID] int,[Name] nvarchar(1),[Memo] nvarchar(2))select 1,N'A',N'A1' union allselect 2,N'A',N'A2' union allselect 3,N'A',N'A3' union allselect 4,N'B',N'B1' union allselect 5,N'B',N'B2'Go--I、Name相同ID最⼩的记录(推荐⽤1,2,3),保留最⼩⼀条⽅法1:delete a from #T a where exists(select 1 from #T where Name= and ID<a.ID)⽅法2:delete a from #T a left join (select min(ID)ID,Name from #T group by Name) b on = and a.ID=b.ID where b.Id is null⽅法3:delete a from #T a where ID not in (select min(ID) from #T where Name=)⽅法4(注:ID为唯⼀时可⽤):delete a from #T a where ID not in(select min(ID)from #T group by Name)⽅法5:delete a from #T a where (select count(1) from #T where Name= and ID<a.ID)>0⽅法6:delete a from #T a where ID<>(select top 1 ID from #T where Name= order by ID)⽅法7:delete a from #T a where ID>any(select ID from #T where Name=)select * from #T⽣成结果:/*ID Name Memo----------- ---- ----1 A A14 B B1(2 ⾏受影响)*/--II、Name相同ID保留最⼤的⼀条记录:⽅法1:delete a from #T a where exists(select 1 from #T where Name= and ID>a.ID)⽅法2:delete a from #T a left join (select max(ID)ID,Name from #T group by Name) b on = and a.ID=b.ID where b.Id is null⽅法3:delete a from #T a where ID not in (select max(ID) from #T where Name=)⽅法4(注:ID为唯⼀时可⽤):delete a from #T a where ID not in(select max(ID)from #T group by Name)⽅法5:delete a from #T a where (select count(1) from #T where Name= and ID>a.ID)>0⽅法6:delete a from #T a where ID<>(select top 1 ID from #T where Name= order by ID desc)⽅法7:delete a from #T a where ID<any(select ID from #T where Name=)select * from #T/*ID Name Memo----------- ---- ----3 A A35 B B2(2 ⾏受影响)*/--3、删除重复记录没有⼤⼩关系时,处理重复值--> --> (Roy)⽣成測試數據if not object_id('Tempdb..#T') is nulldrop table #TGoCreate table #T([Num] int,[Name] nvarchar(1))Insert #Tselect 1,N'A' union allselect 1,N'A' union allselect 1,N'A' union allselect 2,N'B' union allselect 2,N'B'Go⽅法1:if object_id('Tempdb..#') is not nulldrop table #Select distinct * into # from #T--排除重复记录结果集⽣成临时表#truncate table #T--清空表insert #T select * from # --把临时表#插⼊到表#T中--查看结果select * from #T/*Num Name----------- ----1 A2 B(2 ⾏受影响)*/--重新执⾏测试数据后⽤⽅法2⽅法2:alter table #T add ID int identity--新增标识列godelete a from #T a where exists(select 1 from #T where Num=a.Num and Name= and ID>a.ID)--只保留⼀条记录goalter table #T drop column ID--删除标识列--查看结果select * from #T/*Num Name----------- ----1 A2 B(2 ⾏受影响)*/--重新执⾏测试数据后⽤⽅法3⽅法3:declare Roy_Cursor cursor local forselect count(1)-1,Num,Name from #T group by Num,Name having count(1)>1 declare @con int,@Num int,@Name nvarchar(1)open Roy_Cursorfetch next from Roy_Cursor into @con,@Num,@Namewhile @@Fetch_status=0beginset rowcount @con;delete #T where Num=@Num and Name=@Nameset rowcount 0;fetch next from Roy_Cursor into @con,@Num,@Nameendclose Roy_Cursordeallocate Roy_Cursor--查看结果select * from #T/*Num Name----------- ----1 A2 B(2 ⾏受影响)。
查询和删除表中重复数据sql语句1、查询表中重复数据。
select * from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最⼩的记录delete from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)3、查找表中多余的重复记录(多个字段)select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)4、删除表中多余的重复记录(多个字段),只留有rowid最⼩的记录delete from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)5、查找表中多余的重复记录(多个字段),不包含rowid最⼩的记录select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)(⼆)⽐⽅说在A表中存在⼀个字段“name”,⽽且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;Select Name,Count(*) From A Group By Name Having Count(*) > 1如果还查性别也相同⼤则如下:Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1(三)⽅法⼀declare @max integer,@id integerdeclare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1open cur_rowsfetch cur_rows into @id,@maxwhile @@fetch_status=0beginselect @max = @max -1set rowcount @maxdelete from 表名 where 主字段 = @idfetch cur_rows into @id,@maxendclose cur_rowsset rowcount 0⽅法⼆"重复记录"有两个意义上的重复记录,⼀是完全重复的记录,也即所有字段均重复的记录,⼆是部分关键字段重复的记录,⽐如Name字段重复,⽽其他字段不⼀定重复或都重复可以忽略。
SQL删除重复数据⽅法例如:id name value1 a pp2 a pp3 b iii4 b pp5 b pp6 c pp7 c pp8 c iiiid是主键要求得到这样的结果id name value1 a pp3 b iii4 b pp6 c pp8 c iii⽅法1delete YourTablewhere [id] not in (select max([id]) from YourTablegroup by (name + value))⽅法2delete afrom 表 a left join(select id=min(id) from 表 group by name,value)b on a.id=b.idwhere b.id is null查询及删除重复记录的SQL语句查询及删除重复记录的SQL语句1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最⼩的记录delete from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)3、查找表中多余的重复记录(多个字段)select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) 4、删除表中多余的重复记录(多个字段),只留有rowid最⼩的记录delete from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)5、查找表中多余的重复记录(多个字段),不包含rowid最⼩的记录select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)(⼆)⽐⽅说在A表中存在⼀个字段“name”,⽽且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;Select Name,Count(*) From A Group By Name Having Count(*) > 1如果还查性别也相同⼤则如下:Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1(三)⽅法⼀declare @max integer,@id integerdeclare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1open cur_rowsfetch cur_rows into @id,@maxwhile @@fetch_status=0beginselect @max = @max -1set rowcount @maxdelete from 表名 where 主字段 = @idfetch cur_rows into @id,@maxendclose cur_rowsset rowcount 0⽅法⼆"重复记录"有两个意义上的重复记录,⼀是完全重复的记录,也即所有字段均重复的记录,⼆是部分关键字段重复的记录,⽐如Name字段重复,⽽其他字段不⼀定重复或都重复可以忽略。