流水线与并行处理技术
- 格式:doc
- 大小:376.00 KB
- 文档页数:11


并行计算第七章并行算法常用设计技术在并行计算中,算法的设计是非常重要的,旨在提高计算速度和效率。
本章将介绍几种常用的并行算法设计技术,包括任务划分、任务调度和数据划分等。
这些技术可以帮助程序员实现高性能的并行计算。
一、任务划分任务划分是指将一个大型计算任务拆分成多个小任务,并分配给多个处理单元并行执行。
常见的任务划分策略有以下几种:1.分治法:将大问题划分成多个子问题,并分别解决。
该方法适用于问题可以被分解成一系列独立的子问题的情况。
例如,计算斐波那契数列可以使用分治法将其拆分成多个子问题,并分配给多个处理单元计算。
2.流水线:将一个长任务划分成多个子任务,并按照流水线的方式依次执行。
每个处理单元处理一个子任务,并将结果传递给下一个处理单元。
流水线技术适用于具有顺序执行步骤的应用,例如图像处理和视频编码。
3.数据并行:将输入数据划分成多个子数据集,并分配给多个处理单元并行处理。
每个处理单元只操作自己分配的子数据集,然后将结果合并。
数据并行可以提高计算速度和处理能力,适用于数据密集型应用,例如矩阵运算和图像处理。
二、任务调度任务调度是指为每个任务分配合适的处理单元,并按照一定的策略进行调度和管理。
常见的任务调度策略有以下几种:1.静态调度:在程序开始执行之前,根据预先设定的规则将任务分配给处理单元。
静态调度可以提高计算效率,但不适用于动态变化的任务。
2.动态调度:根据运行时的情况动态地调整任务的分配和调度。
动态调度可以根据负载情况来实时调整任务的分配,提高系统的整体性能。
3.动态负载平衡:将任务合理地分配给多个处理单元,使得每个处理单元的负载尽可能均衡。
动态负载平衡可以避免单个处理单元负载过重或过轻的情况,提高计算效率。
三、数据划分数据划分是指将输入数据划分成多个部分,并分配给多个处理单元。
常见的数据划分策略有以下几种:1.均匀划分:将输入数据均匀地划分成多个部分,并分配给多个处理单元。
均匀划分可以实现负载均衡,但可能导致通信开销增加。

fpu处理器原理FPU处理器原理什么是FPU处理器?FPU(浮点数处理器)是一种用于执行浮点数运算的专门硬件。
它位于主处理器(CPU)内部,负责处理复杂的浮点数计算,例如浮点加减乘除、开方和三角函数运算等。
FPU处理器的存在极大地提高了计算机对于科学计算、图形处理和大数据分析等领域的性能。
FPU的工作原理FPU处理器是根据IEEE 754标准来进行浮点数计算的。
基本的FPU工作原理如下:1.浮点数表示:FPU使用二进制科学计数法来表示浮点数。
它将浮点数分为三个部分:符号位、有效数字和指数。
符号位表示正负,有效数字表示浮点数的精度,指数表示浮点数的大小。
2.浮点数运算:FPU通过完成一系列算术运算和逻辑运算来执行浮点数运算。
它支持浮点加减乘除、取模、开方以及三角函数运算等。
3.FPU指令集:FPU通过一组专门的指令集来控制其工作。
这些指令集包括加载浮点数、存储浮点数、浮点数运算、转换浮点数格式等指令。
4.数据通路:FPU处理器通过一条独立的数据通路与CPU进行通信。
它接收CPU发送的指令和数据,执行计算后将结果返回给CPU。
FPU的性能优化技术为了提高FPU处理器的性能,设计者们采用了一系列技术来进行优化:1.流水线技术:FPU采用流水线技术将浮点数运算划分为多个阶段,每个阶段只需完成一种简单的操作。
这样可以同时进行多个浮点数计算,大大提高了运算速度。
2.缓存技术:FPU使用高速缓存来存储经常使用的浮点数数据和指令。
这样可以避免频繁地从内存中读取数据,提高了数据的访问速度。
3.指令优化:FPU设计者们针对常见的浮点数运算进行指令优化。
他们提供了一些特殊的指令,例如快速平方根指令和快速三角函数指令,以提高计算速度。
4.并行处理:一些高级FPU处理器支持同时执行多条浮点数指令。
这种并行处理技术可以加速浮点数计算,尤其是在需要处理大量数据的情况下。
FPU发展的趋势FPU处理器在过去几十年里经历了巨大的发展。

计算机组成原理中的流水线与并行处理计算机组成原理是指计算机的各个组成部分及其相互关系的原理。
其中,流水线与并行处理是计算机组成原理中的两个重要概念。
本文将从流水线和并行处理的定义、特点、应用以及优缺点等方面进行论述。
一、流水线的定义和特点流水线技术是一种将复杂的任务分解为若干个互相依赖的子任务,并通过时序控制将其分别交给不同的处理单元进行执行的技术。
它可以提高计算机的执行效率和吞吐量。
与串行处理相比,流水线处理具有以下特点:1.任务分解:将复杂的任务分解为多个子任务,每个子任务由不同的处理单元负责执行。
2.流水线寄存器:通过在流水线各个阶段之间插入流水线寄存器,实现了各个阶段之间的数据传递和暂存,确保了数据的正确性和稳定性。
3.并行操作:不同的处理单元可以并行执行不同的任务,提高了计算机的并行处理能力。
4.随机任务执行:由于流水线中的各个阶段是独立的,因此可以随机运行和停止任务,提高了计算机的灵活性。
二、并行处理的定义和特点并行处理是指同时利用多个处理器或者多个处理单元并行执行多个任务的处理方式。
它可以大幅提升计算机系统的运算速度和处理能力。
并行处理的特点如下:1.任务分配:将大任务分解为多个小任务,并分配给多个处理单元同时执行。
2.任务协调:通过合理的任务调度算法,协调各个处理单元之间的任务执行顺序和数据传递,确保整个系统的稳定性和正确性。
3.资源共享:各个处理单元之间可以共享资源,如内存、缓存等,提高资源利用率。
4.计算效率提高:通过多个处理单元同时执行任务,大幅提高了计算效率和处理速度。
三、流水线与并行处理的应用流水线和并行处理在计算机领域被广泛应用,以下是几个常见的应用示例:1.超级计算机:超级计算机通常采用并行处理的方式,利用多个处理器同时进行计算,以提高计算能力。
2.图形处理器:图形处理器(GPU)采用流水线技术,将图像处理任务分解为多个子任务,通过流水线处理实现高效的图形渲染和计算。
流水线与并行处理1. 概述流水线技术导致了关键路径的缩短,从而可以提高时钟速度或采样速度,或者可以在同样速度下降低功耗。
在并行处理中,多个输出在一个时钟周期内并行地计算。
这样,有效采样速度提高到与并行级数相当的倍数。
与流水线类似,并行处理也能够用来降低功耗。
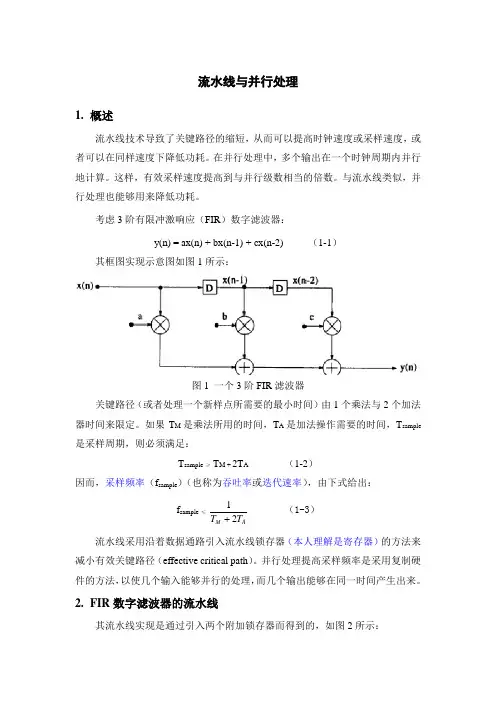
考虑3阶有限冲激响应(FIR )数字滤波器:y(n) = ax(n) + bx(n-1) + cx(n-2) (1-1)其框图实现示意图如图1所示:图1 一个3阶FIR 滤波器关键路径(或者处理一个新样点所需要的最小时间)由1个乘法与2个加法器时间来限定。
如果T M 是乘法所用的时间,T A 是加法操作需要的时间,T sample 是采样周期,则必须满足:T sample ≥ T M + 2T A (1-2)因而,采样频率(f sample )(也称为吞吐率或迭代速率),由下式给出:f sample ≤ A M T T 21 (1-3)流水线采用沿着数据通路引入流水线锁存器(本人理解是寄存器)的方法来减小有效关键路径(effective critical path )。
并行处理提高采样频率是采用复制硬件的方法,以使几个输入能够并行的处理,而几个输出能够在同一时间产生出来。
2. FIR 数字滤波器的流水线其流水线实现是通过引入两个附加锁存器而得到的,如图2所示:图2 流水线FIR滤波器,其中垂直虚线代表一个前馈割集关键路径现在由T M + 2T A减小为T M + T A。
在这种安排下,当左边的加法器启动当前迭代计算的同时,右边的加法器正在完成前次迭代结果的计算。
必须注意到,在一个M级流水线系统中,从输入到输出的任一路径上的延时原件数目是(M-1),它要大于在原始时序电路中同一路径上的延时元件数。
虽然流水线技术减小了关键路径,但是它付出了增加迟滞(latency)的代价。
迟滞实质上是流水线系统第一个输出数据的时间与原来时序系统第一个输出数据时间相比的滞后。


指令流水线的原理
指令流水线是一种基于并行处理的计算机指令执行方法,通过将指令执行过程分为若干个互相独立的阶段,使得每个阶段可以同时处理不同的指令,从而提高计算机的执行效率。
指令流水线的原理可以简单描述为以下几个步骤:
1. 指令获取阶段:从存储器中获取将要执行的指令,并将其送入指令译码阶段。
2. 指令译码阶段:对获取的指令进行译码,确定指令类型和操作数,并将其送入执行阶段。
3. 执行阶段:根据指令类型和操作数进行相应的操作,如运算、移位、存储等。
4. 访存阶段:如果指令需要访问存储器,则进行存储器操作,如读取或写入数据。
5. 写回阶段:将执行结果写回到寄存器文件或存储器中。
以上是指令流水线的基本阶段,不同的指令流水线可能还包括其他特定的阶段,如乘法器阶段、除法器阶段等。
指令流水线的关键在于将指令执行过程分解为多个互相独立的阶段,并使得各个阶段可以同时进行。
这样可以避免指令之间的冲突,提高指令的并行度和处理效率。
同时,指令流水线还
可以通过插入空泡来解决可能出现的冲突和数据依赖问题,以保证指令的正确执行。
总之,指令流水线是一种有效提高计算机处理效率的方法,通过将指令执行过程分解为多个互相独立的阶段,实现指令的并行处理,从而加快指令的执行速度。

计算机组成原理专升本试题解析指令流水线与并行处理计算机组成原理是计算机专业学生必修的一门基础课程,对于理解计算机的组成和工作原理非常重要。
在计算机组成原理的学习中,指令流水线与并行处理是一个重要的概念和技术。
本文将对指令流水线与并行处理进行详细解析。
一、指令流水线指令流水线是一种通过将处理器的执行过程划分为多个子阶段,并行执行这些子阶段来提高处理器性能的技术。
在指令流水线中,每个指令在执行的过程中经过取指令、译码、执行、访存和写回等多个阶段,不同指令在不同阶段同时执行,从而在单位时间内处理更多的指令。
指令流水线的优势在于充分利用了处理器的硬件资源,提高了指令的执行效率。
但是在实际应用中,由于指令间有数据依赖关系等问题,可能会导致流水线的阻塞和冒险,进而影响性能。
为了解决这些问题,人们提出了一系列的技术和策略,比如数据旁路、预测执行和乱序执行等,来提高指令流水线的性能。
二、并行处理并行处理是指通过同时执行多个任务来提高系统的处理能力和性能的技术。
在计算机组成原理中,主要涉及到的并行处理包括指令级并行和线程级并行。
指令级并行是通过在一个指令的执行过程中同时执行多个子指令来提高处理器性能的技术。
一种实现指令级并行的方法是超标量处理器,它能够在一个时钟周期内同时发射多条指令,并行执行这些指令。
另一种实现指令级并行的方法是超流水线处理器,它将处理器的执行流程进一步细分为多个较短的子阶段,以便更多地重叠执行。
线程级并行是通过同时处理多个线程来提高系统性能的技术。
在多核处理器和多线程处理器中,可以同时执行多个线程,从而实现线程级并行。
通过合理的线程调度和资源分配,可以充分利用处理器的硬件资源,提高系统的吞吐量和响应速度。
指令流水线和并行处理是计算机组成原理中的两个重要概念和技术,它们可以相互结合,共同提高计算机系统的性能。
指令流水线通过划分指令执行过程为多个子阶段并行执行,提高了指令的执行效率;而并行处理通过同时处理多个任务或线程,提高了系统的处理能力和性能。

流水线的工作原理
流水线的工作原理是将一个任务拆分成多个子任务,并由多个处理单元按照顺序进行并行处理,从而实现提高任务处理效率的目的。
具体来说,流水线工作原理分为以下几个步骤:
1. 任务拆分:将一个任务分解成多个子任务,每个子任务具有一定的独立性,可以并行处理。
2. 指令执行阶段划分:将每个子任务划分为不同的阶段,每个阶段需要不同类型的处理单元进行处理。
3. 并行处理:每个处理单元在每个阶段对应的子任务上进行处理,各个处理单元同时工作,形成并行处理的效果。
4. 流水线寄存器:流水线中的每个阶段之间通过流水线寄存器进行数据传输,保证各个阶段之间的数据同步。
5. 流水线冲突处理:由于流水线中各个阶段同时进行,可能会出现数据相关等冲突,需要通过添加硬件逻辑或进行优化来解决这些冲突,以保证流水线的正常工作。
6. 结果合并:当所有子任务完成处理后,将各个处理单元输出的结果合并得到最终的任务结果。
通过以上步骤,流水线能够将一个任务分解并并行处理,充分利用硬件资源,提高任务处理的效率和速度。
但是流水线也会因为流水线寄存器的引入,导致任务执行速度下降,同时需要处理冲突问题,因此需要根据具体情况进行流水线设计和优化。

FPGA(现场可编程门阵列)是一种可编程硬件,可以用于实现各种数字逻辑电路,包括带符号位加法运算。
对于超大位宽的带符号位加法运算,可以采用以下方法:
1. 使用并行处理技术:FPGA具有很高的并行处理能力,可以将带符号位加法运算划分为多个子任务,并使用多个处理单元同时进行运算,从而提高运算速度。
2. 使用流水线技术:流水线技术可以将带符号位加法运算分解为多个阶段,每个阶段只需要进行一部分运算,然后将结果传递给下一个阶段,从而加快运算速度。
3. 利用硬件乘法器:带符号位加法运算中经常需要使用到硬件乘法器,可以将乘法器与加法器相结合,以提高运算速度。
4. 使用高速接口:如果需要将运算结果传输到外部设备或存储器中,可以使用高速接口,例如PCIe、HDMI等,以加快数据传输速度。
需要注意的是,在进行带符号位加法运算时,需要考虑符号位的影响。
在加法运算中,正数和负数之间可以进行加减运算,但是需要注意结果的符号。
因此,在进行带符号位加法运算时,需要将输入数据先进行符号扩展,以确保运算结果的正确性。
总之,使用FPGA进行超大位宽带符号位加法运算可以提高运算速度和准确性,需要根据具体应用场景和需求选择合适的技术和方法。

数据通路原理一、概述数据通路是计算机中负责数据传输和处理的核心部分,它承担着将数据从输入端传输到输出端的任务。
数据通路原理是指数据在计算机中传输和处理的基本原理和机制。
本文将从数据通路的定义、组成部分、工作原理、优化方法等多个方面进行详细探讨。
二、数据通路的组成部分数据通路由多个组成部分组成,包括输入寄存器、输出寄存器、运算单元、控制单元等。
2.1 输入寄存器输入寄存器是数据通路中的一个重要组成部分,它负责接收来自外部的数据,并将其存储在寄存器中以备后续处理。
输入寄存器通常由一组触发器构成,可以按照字节或字的形式存储数据。
2.2 输出寄存器输出寄存器是数据通路中的另一个重要组成部分,它负责将处理后的数据从数据通路输出到外部设备。
输出寄存器通常也由一组触发器构成,可以按照字节或字的形式输出数据。
2.3 运算单元运算单元是数据通路中的核心部分,它负责对输入数据进行各种运算操作,包括加法、减法、乘法、除法等。
运算单元通常由算术逻辑单元(ALU)和寄存器文件组成。
2.4 控制单元控制单元是数据通路中的另一个重要组成部分,它负责控制数据在数据通路中的流动和处理过程。
控制单元通常由状态机或控制存储器实现,可以根据指令序列来控制数据的传输和处理。
三、数据通路的工作原理数据通路的工作原理可以分为以下几个步骤:指令获取、指令解码、操作数获取、运算执行、结果写回。
3.1 指令获取在数据通路中,指令是通过指令寄存器从内存中获取的。
指令寄存器将指令存储在其中,并根据指令的地址从内存中读取指令。
3.2 指令解码指令解码是将获取到的指令解析为具体的操作和操作数。
控制单元根据指令的类型和操作码来确定下一步的操作,并将相应的控制信号发送给运算单元和寄存器文件。
3.3 操作数获取操作数获取是根据指令中的地址或寄存器编号从寄存器文件中获取相应的操作数。
操作数可以是寄存器中的数据,也可以是内存中的数据。
3.4 运算执行运算执行是根据指令中的操作码和操作数对数据进行具体的运算操作。
基于流水线技术的并行高效FIR滤波器设计数字可以滤除多余的噪声,扩展信号频带,完成信号预调,转变信号的特定频谱重量,从而得到预期的结果。
数字滤波器在DVB、无线通信等数字信号处理中有着广泛的应用。
在数字信号处理中,传统滤波器通过高速乘法累加器实现,这种办法在下一个采样周期到来期间,只能举行有限操作,从而限制了带宽。
现实中的信号都是以一定的序列进入处理器的,因此处理器在一个时光周期内只能处理有限的位数,不能彻低并行处理。
基于并行流水线结构的FIR滤波器可以使笔者设计的64阶或者128阶滤波器与16阶滤波器的速度一样快,其显著特点是在算法的每一个阶段存取数据。
FPGA结构使得以采样速率处理数字信号成为常数乘法器的抱负载体,提高了囫囵系统的性能。
因为设计要求的差异,如字长、各级输出的保留精度等不同,在囫囵设计过程中,各个环节也有所不同,这就需要按照不同的要求对数据举行不同的处理,如截断、扩展等,从而设计出既满足设计需要,又节约FPGA资源的。
1FIR并行滤波器结构数字滤波器主要通过乘法器、加法器和移位寄存器实现。
串行处理方式在阶数较大时,处理速度较慢。
而现代数字信号处理要求能够迅速、实时处理数据,并行处理数据能够提高信号处理能力,其结构1所示。
从上面的算法可以看出,处理数据的采样时钟对每一个抽头来说都是并行的,并且加法器和移位寄存器采纳级联方式,完成了累加器的功能,综合了加法器和移位寄存器的优点,而且这种算法的各级结构相同,便利扩展,实现了随意阶数的滤波器。
算法中,真正占用系统资源的是乘法器。
假如将系数量化成二进制,就能采纳移位寄存器和加法器实现乘法功能。
对于一个特定的滤波器,因为它有固定的系数,乘法功能就是一个长数乘法器。
下面将研究乘法器的设计问题。
图1 数字滤波器结构图2FIR并行滤波器的乘法器设计第1页共4页。
计算机组成原理中的流水线与并行计算计算机组成原理是计算机科学中的重要课程,涉及到计算机硬件的各个层面和组成部分。
在计算机组成原理中,流水线和并行计算是两个重要的概念,它们在提高计算机性能和效率方面发挥着重要作用。
一、流水线的概念与原理流水线是一种将任务分解为多个阶段并分别处理的技术。
在计算机中,流水线将指令执行过程分为多个步骤,并在不同的处理器上同时执行这些步骤,以提高整体的执行速度。
流水线的原理可以简单地用装配线的概念来解释。
就像工厂的装配线一样,每个工人负责在流水线上的一个工作站上完成一个特定的任务,然后将产品传递给下一个工人进行下一步处理。
这样,整个生产过程可以并行进行,从而提高了效率。
在计算机中,流水线处理的阶段通常包括取指(Instruction Fetch)、译码(Instruction Decode)、执行(Execute)、访存(Memory Access)和写回(Write Back)等。
每个阶段负责完成特定的任务,然后将结果传递给下一个阶段。
这样,计算机可以同时处理多个指令,提高了整体的运行速度。
二、并行计算的概念与应用并行计算是指在计算过程中同时进行多个操作或任务的技术。
与流水线不同的是,并行计算更强调多个任务的同时执行。
在计算机组成原理中,并行计算被广泛应用于多核处理器和分布式系统中。
例如,现代的计算机中常常使用多核处理器,每个核心可以同时执行不同的任务,从而提高计算机的整体性能。
另外,分布式系统中的多台计算机可以同时工作,通过任务的分配和协调来完成复杂的计算任务。
并行计算的应用包括科学计算、数据处理、图像处理等领域。
在科学计算中,大规模的模拟和计算问题可以通过将任务分配给多个处理器来加速计算过程。
在数据处理和图像处理中,可以同时处理多个数据项或图像,从而提高处理的效率和速度。
三、流水线与并行计算的关系流水线和并行计算是紧密相关的概念,它们都旨在提高计算机的性能和效率。
流水线的实现可以看作是一种简单形式的并行计算,其中不同的阶段可以同时执行。
软件设计师计算机体系结构考点:流水线技术【考法分析】本考点涉及的考查形式有:(1)流水线相关理论概念;(2)流水线相关计算。
【要点分析】1.流水线理论概念(1)流水线是指在程序执行时多条指令重叠进行操作的一种准并行处理实现技术。
各种部件同时处理是针对不同指令而言的,它们可同时为多条指令的不同部分进行工作,以提高各部件的利用率和指令的平均执行速度。
(2)流水线建立时间:1条指令执行时间。
(3)流水线周期:执行时间最长的一段。
2、流水线相关计算:(1)流水线执行时间(理论公式):(t1+t2+..+tk)+(n-1)*∆t。
(2)流水线执行时间(实践公式):k*∆t +(n-1)*∆t。
(3)流水线吞吐率:TP = 指令条数/ 流水线执行时间。
(4)流水线最大吞吐率1 / ∆t。
(5)流水线加速比:顺序执行时间/流水线执行时间。
【备考点拨】吞吐率:单位时间内流水线处理机流出的结果。
对指令而言就是单位时间内执行的指令数。
如果流水线子过程所用的时间不一样,则吞吐率P应为(最长子过程的倒数)。
流水线开始工作,需要经过一段时间才能达到最大吞吐率。
【相关考题】1.下列关于流水线方式执行指令的叙述中,不正确的是()。
A.流水线方式可提高单条指令的执行速度B.流水线方式下可同时执行多条指令C.流水线方式提高了各部件的利用率D.流水线方式提高了系统的吞吐率2.流水线的吞吐率是指单位时间流水线处理的任务数,如果各段流水的操作时间不同,则流水线的吞吐率是()的倒数。
A. 最短流水段操作时间B. 各段流水的操作时间总和C. 最长流水段操作时间D. 流水段乘以最长流水段操作时间。
单片机指令的并行执行与流水线技术单片机(Microcontroller,简称MCU),是一种集成了中央处理器(CPU)、存储器和输入/输出接口等功能于一体的集成电路。
在现代电子设备中,单片机已经得到了广泛的应用。
为了提高单片机的运行效率,人们逐渐引入了并行执行和流水线技术。
本文将探讨单片机指令的并行执行和流水线技术,以及其对系统性能的提升作用。
一、并行执行的概念及优势:1.1 并行执行的基本原理并行执行是指同时执行两条或多条指令的技术,通过同时处理多个指令,可以提高系统的运行效率。
由于单片机的计算能力和存储能力有限,采用并行执行可以有效地利用有限的资源,提高指令执行的速度。
1.2 并行执行的优势(1)提高运算速度:并行执行允许同时处理多个指令,从而减少了指令执行的等待时间,大大提高了程序的运行速度。
(2)提高系统吞吐量:对于一些需要较长时间的操作,通过并行执行可以在运行这些操作过程中同时执行其他指令,从而提高了整个系统的吞吐量。
(3)降低功耗消耗:并行执行可以在同一时间内处理多个指令,从而使得系统在同样的时间内完成更多的任务,减少了系统的工作时间,进而降低了功耗消耗。
二、单片机的流水线技术:2.1 流水线技术的基本原理流水线技术是指将一个任务分成多个子任务,在不同的处理单元中分别执行,通过并行工作提高整个系统的效率。
在单片机中,流水线技术将指令的执行过程划分成多个阶段,每个阶段由不同的处理单元负责执行,实现指令的并行处理。
2.2 流水线技术的特点(1)提高效率:流水线技术将指令执行过程分解成多个阶段,不同阶段可以同时进行,从而提高了整个系统的执行效率。
(2)减少延迟:通过将指令的执行过程划分成多个阶段,可以减少指令执行过程中的等待时间,降低延迟。
(3)增加吞吐量:流水线技术可以同时处理多个指令,从而提高系统的吞吐量,加快数据处理的速度。
三、并行执行与流水线技术的应用案例:3.1 ARM Cortex-M系列处理器ARM Cortex-M系列处理器是一类广泛应用于单片机系统中的处理器,它采用了并行执行和流水线技术,提供了高性能和低功耗的解决方案。
流水线与并行处理1. 概述流水线技术导致了关键路径的缩短,从而可以提高时钟速度或采样速度,或者可以在同样速度下降低功耗。
在并行处理中,多个输出在一个时钟周期内并行地计算。
这样,有效采样速度提高到与并行级数相当的倍数。
与流水线类似,并行处理也能够用来降低功耗。
考虑3阶有限冲激响应(FIR )数字滤波器:y(n) = ax(n) + bx(n-1) + cx(n-2) (1-1)其框图实现示意图如图1所示:图1 一个3阶FIR 滤波器关键路径(或者处理一个新样点所需要的最小时间)由1个乘法与2个加法器时间来限定。
如果T M 是乘法所用的时间,T A 是加法操作需要的时间,T sample 是采样周期,则必须满足:T sample ≥ T M + 2T A (1-2)因而,采样频率(f sample )(也称为吞吐率或迭代速率),由下式给出:f sample ≤ A M T T 21 (1-3)流水线采用沿着数据通路引入流水线锁存器(本人理解是寄存器)的方法来减小有效关键路径(effective critical path )。
并行处理提高采样频率是采用复制硬件的方法,以使几个输入能够并行的处理,而几个输出能够在同一时间产生出来。
2. FIR 数字滤波器的流水线其流水线实现是通过引入两个附加锁存器而得到的,如图2所示:图2 流水线FIR滤波器,其中垂直虚线代表一个前馈割集关键路径现在由T M + 2T A减小为T M + T A。
在这种安排下,当左边的加法器启动当前迭代计算的同时,右边的加法器正在完成前次迭代结果的计算。
必须注意到,在一个M级流水线系统中,从输入到输出的任一路径上的延时原件数目是(M-1),它要大于在原始时序电路中同一路径上的延时元件数。
虽然流水线技术减小了关键路径,但是它付出了增加迟滞(latency)的代价。
迟滞实质上是流水线系统第一个输出数据的时间与原来时序系统第一个输出数据时间相比的滞后。
流水线技术缺点:增加了锁存器数目和增加了系统的迟滞。
下面要点需要注意:(1)一个架构的速度(或时钟周期)由任意两个锁存器间、或一个输入与一个锁存器间、或者一个锁存器与一个输出间、或输入与输出间路径中最长的路径限定。
(2)这个最长的路径或“关键路径”可以通过在架构中适当插入流水线锁存器来减小。
(3)流水线锁存器只能按照穿过任一图的“前馈割集(feed-forward cutset)”的方式插入。
割集:割集是一个图的边的集合,如果从图中移去这些边,图就成为不相连的了。
前馈割集:如果数据在割集的所有边上都沿前进的方向移动,这个割集就称为前馈割集。
3.并行技术注意到并行处理与流水线技术互为对偶的这一特点是十分有趣,若一个计算能够排成流水线,它也能并行的处理。
两种技术都发掘了计算中可供利用的并发性,只是方式不同。
当一组互不相关的计算能够在一个流水线系统中按交替方式计算时,则它们也能够利用重复的硬件按并行处理的模式计算。
3阶FIR滤波器系统是一个单输入单输出(SISO)系统,可描述如下:y(n) = ax(n) + bx(n-1) + cx(n-2) (3-1)为了获得一个并行处理结构,SISO系统必须转换为MISO(多输入多输出)系统。
例如,下列方程组描述一个每个时钟周期由3个输入的并行系统(即并行处理的级数L=3)。
此处k表示时钟周期。
可以看出,在第k个时钟周期,有三个输入x(3k), x(3k+1), x(3k+2)被处理,同时输出中产生3个样点。
并行处理系统也称为块处理系统,而每个时钟周期内处理的输入个数被称为块尺寸。
由于MISO的结构,在任意一条线处插入一个锁存器会产生一个有效延时,等于L个对应于采样率的时钟周期。
每个延时原件称为一个块延时(也称为L级减慢,L-slow)。
例如,把信号x(3k)延迟一个时钟周期将导致信号x(3k-3)而非x(3k-1),因为x(3k-1)已经是另一条输入线的输入。
3级并行FIR滤波器的框图架构如图3所示:图3 一个块处理的例子其细节图如图4所示:图4 块尺寸为3的3阶FIR滤波器的并行结构处理注意,块或并行处理系统的关键路径保持不变,而且时钟周期(T clk)必须满足:T clk≥ T M + 2T A (3-2)但是,由于3个样点是在同一个时钟周期内而不是三个时钟周期处理的,因此迭代周期由下式确定:Titer = Tsample=L1Tclk≥31(TM+ 2TA) (3-3)重要的是要理解在并行系统中T clk≠T sample,而在流水线系统中T clk=T sample,下图给出了一个完整的并行处理系统,它包含串-并转换器和并-串转换器:图5 块尺寸为4的完全并行处理系统其细节如下图所示:现在人们会问,当能够用流水线达到同样好的效果时,为什么还要并行处理呢?为什么要复制和使用这么多硬件呢?回答是,流水线存在一个基本的限制,就是输入/输出(I/O)的瓶颈问题。
考虑图6的芯片组:图6 一个芯片组图例如,若假定输出管腿、输入管腿和两个芯片之间连线的延时总和为8ns,必须大于或等于8ns。
若关键路径的计算时间小于8ns,则I/O延时的那么Tclk限制将占主导地位,该系统为通信受限的系统。
这实质上意味着,流水线仅在关键路径计算时间大于通信或I/O延时边界时才可以使用,一旦达到此边界后,流水线就不能进一步提高速度了。
这时,流水线必须结合并行处理才能进一步提高该架构的速度。
作为一个例子,考虑图7的并行滤波器:图7 块尺寸为3的3阶FIR滤波器的并行处理架构假定一个乘法的计算时间(TM)是10ut,一个加法的计算时间为2ut。
细粒流水线可用到并行滤波器中来进一步缩小关键路径。
在这种情况下,乘法器分拆为两个较小的单元m1和m2,其计算时间分别为7ut和3ut。
流水线锁存器插入到穿过乘法器的水平割集上,如下图所示。
虽然这些水平割集看起来似乎是无效的,但是实际上它们是有效的,因为去掉这些割集的边就断开了元件间的连接。
于是通过并行处理与流水线的结合,采样周期减至:(3-4) 并行处理也被通过减慢是中来减少功耗,这种方法减少功耗是由于时钟方面的原因,相比之下,流水线系统需要工作在更快的时钟下,才能保持等价的吞吐率或采样速度。
进一步说,更不希望使用细粒度流水线,如位级流水线,因为硬件开销与迟滞时间都会由于锁存器的显著增加而增加。
4.流水线与并行处理的功耗减低利用流水线和并行处理有两个主要的优点:1)高速度2)低功耗由前面章节已经看出流水线与并行处理能够增加采样速度。
现在考虑在采样速度不需要增加的情况下如何利用这些技术来降低功耗。
回顾一下两个公式,一个是计算CMOS电路传播延时的公式,另一个是计算功耗的公式。
传播延时Tpd与在关键路径上各种晶体管栅极和杂散电容的充放电荷密切相关,对CMOS电路,传播延时可写为:T pd =2arg)(techVVkVC(4-1)其中Ccharge表示在单个时钟周期里充放电的电容,即沿着关键路径的电容,V 0是电源电压,Vt是阈值电压。
参数k是工艺参数μ、W/L和Cox的函数。
CMOS电路的功耗可用下列方程来估计:P = Ctotal2V f (4-2)其中Ctotal 代表电路中的总电容,V是电源电压,f是电路的时钟频率。
图8 3阶FIR滤波器细粒度流水线与并行处理相结合的架构4.1 用流水线降低功耗:流水线结构可以用来降低FIR滤波器的功耗,令P seq = Ctotal2V f (4-3)表示原始滤波器的功耗。
注意f = 1/Tseq ,其中Tseq原始时序滤波器的时钟周期。
现在考虑一个M级流水线系统,其关键路径缩短为原始路径长度的1/M,一个时钟周期内充放电电容减小为Ccharge/M,注意总电容没有变化。
如果时钟速度保持不变,即时钟频率f保持不变,在原来对电容Ccharge充放电的同样时间内,现在只需对Ccharge /M进行充放电,这意味着,电源电压可以降低到βV,其中β是一个小于1的常数。
这样,流水线滤波器的功耗将为:P pip = Ctotalβ22V f = β2P seq (4-4)因此,和原始系统相比流水线系统的功耗降低了β2倍。
图9 原始系统和3级流水线系统的关键路径功耗降低因子β可以通过考察原始滤波器和流水线滤波器传播时之间的关系来确定。
原始滤波器的传播延时是(4-5)流水线滤波器的传播延时是(4-6)应该注意的是,时钟周期Tclk 通常被设置为等于电路中的最大传播延时Tpd。
因为对于这两个滤波器来说使用相同的时钟速度,根据上述两个公式,从下列二次方程可以解出β,(4-7) 一旦得到了β,流水线滤波器降低的功耗就可以由下面公式算出:P pip = Ctotalβ22V f = β2P seq (4-8)4.2 用并行处理降低功耗和流水线一样,并行处理也可以通过降低电源电压来降低功耗。
在一个L 路并行系统中,充电电容通常不变,而总电容增大L倍。
为了保持同样的采样速度,L级并行电路的时钟周期必须增加到LTseq ,其中Tseq是由公式4-5决定的时序电路的传播延时。
这意味着Ccharge的充电时间是LTseq 而不是Tseq。
换句话说,同样的电容有了更长的充电时间。
这就意味着电源电压可以降低到βV。
图10 顺序流水线系统和3级流水线系统的关键路径对传播延时的考虑可以再次用来计算L级并行系统的电源电压。
原始系统的传播延时由公式3-13给出,而L级并行系统的传播延时由下式给出:(4-9)根据公式3-13和3-22可以得到下列二次方程来就出β:(4-10)一旦求出β,L路并行系统的功耗可以计算如下:(4-11) 其中Pseq是由4-3给出的原始时序系统的功能。
所以,和流水线系统一样,L路并行系统功耗为原时序系统的β2倍。
4.3 流水线和并行处理的结合流水线技术和并行处理技术可以结合起来降低功耗。
原理是一样的,即流水线降低1个时钟周期内充放电电容,而并行处理则增加对原电容的充电放电时钟周期。
图11并行流水线滤波器的传播延时如下:(4-12)根据该方程,得到下列二次方程:(4-13) 应该注意的是,电源电压并不能通过使用更多级的流水线和并行处理而无限地降低,因为存在一个由工艺参数和噪声容限决定的电源电压下限。
结论:本节内容介绍了非递归数字滤波器中的流水线和并行处理方法。
这两种方法都可以用来提高滤波器的采样频率。
在流水线中,流水线锁存器放置在SFG中的前馈割集处,是关键路径的计算时间降低。
其结果使时钟频率的以提高,从而采样频率提高。
在并行处理中,复制原始的串行系统的硬件,得到一个MIMO并行系统。
在这种情况下,时钟频率不变,采样频率却增加了。
此外,还说明了流水线和并行处理在低功耗设计中的应用。