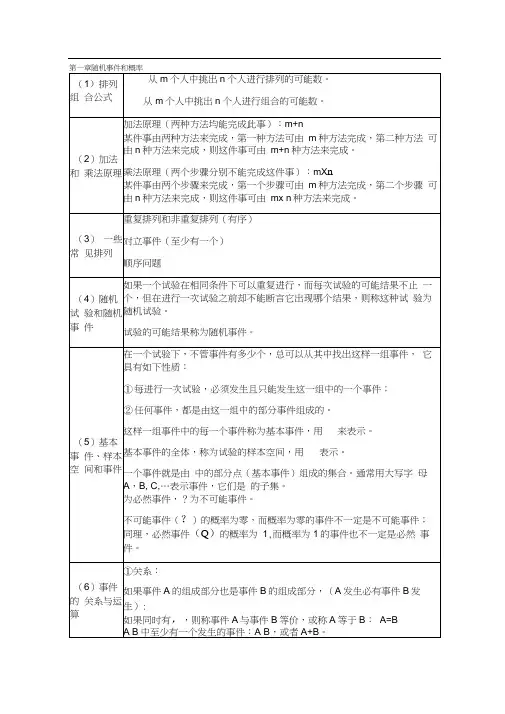
常用数理统计公式
- 格式:doc
- 大小:157.00 KB
- 文档页数:1

概率论与数理统计公式定理全总结一、概率论公式:1.基本概率公式:对于随机试验E,事件A的概率可以表示为P(A)=事件A的样本点数/所有样本点数。
2.条件概率公式:对于事件A和事件B,若P(B)>,则事件A在事件B发生的条件下的概率可以表示为P(A,B)=P(A∩B)/P(B)。
3.全概率公式:对于互不相容事件A1,A2,...,An,它们的和事件为全样本空间S,且概率P(Ai)>,则对于任意事件B有P(B)=Σ(P(Ai)×P(B,Ai))。
4.贝叶斯公式:对于互不相容事件A1,A2,...,An,它们的和事件为全样本空间S,且概率P(Ai)>,则对于任意事件B,有P(Ai,B)=(P(B,Ai)×P(Ai))/Σ(P(B,Ai)×P(Ai))。
二、数理统计公式:1.期望:随机变量X的期望E(X)=Σ(Xi×P(Xi)),其中Xi为随机变量X的取值,P(Xi)为随机变量X取值为Xi的概率。
2. 方差:随机变量X的方差Var(X) = Σ((Xi - E(X))^2 ×P(Xi)),其中Xi为随机变量X的取值,E(X)为随机变量X的期望,P(Xi)为随机变量X取值为Xi的概率。
3. 协方差:随机变量X和Y的协方差Cov(X,Y) = E((X - E(X))(Y - E(Y))),其中E(X)和E(Y)分别为随机变量X和Y的期望。
4. 相关系数:随机变量X和Y的相关系数ρ(X,Y) = Cov(X,Y) / √(Var(X) × Var(Y)),其中Cov(X,Y)为随机变量X和Y的协方差,Var(X)和Var(Y)分别为随机变量X和Y的方差。
三、概率论与数理统计定理:1.大数定律:对于独立同分布的随机变量X1,X2,...,Xn,它们的均值X̄=(X1+X2+...+Xn)/n,当n趋向于无穷大时,X̄趋向于X的期望E(X)。


数理统计定理及公式数理统计是应用数学的一个分支,研究收集、整理、分析和解释数据的方法和技术。
在数理统计中,有一些重要的定理和公式,用于描述和计算概率、分布、样本统计量和假设检验。
1. 大数定理(Law of Large Numbers):在重复多次独立实验的情况下,随着实验次数的增多,样本均值会趋近于总体均值。
大数定理是数理统计的基础之一,它是对样本均值的收敛性质的描述。
数学表达式为:其中,X1、X2、..、Xn是来自总体的独立同分布的随机变量,μ是总体的均值,n是样本大小。
2. 中心极限定理(Central Limit Theorem):在若干相互独立的随机变量的和的情况下,随着随机变量数量的增大,和的分布趋向于服从正态分布。
中心极限定理是数理统计中非常重要的一个定理,它不仅在理论上解释了为什么正态分布在自然界中具有如此重要的地位,而且提供了许多统计学中方法的理论基础。
数学表达式为:其中,X1、X2、..、Xn是独立同分布的随机变量,μ是总体的均值,σ是总体的标准差,n是样本大小。
3. 伯努利分布(Bernoulli Distribution):又称为两点分布,是最简单的概率分布之一、伯努利分布描述了只有两个可能结果的离散随机试验,如抛硬币的结果。
数学表达式为:其中,p表示事件出现的概率,1-p表示事件不出现的概率,X为随机变量。
4. 正态分布(Normal Distribution):也称为高斯分布,是统计学中最常见的连续型概率分布之一、正态分布具有钟形曲线,均值和标准差决定了曲线的位置和形状。
它在自然界中广泛存在,并且许多现实世界中的随机变量都可以近似地服从正态分布。
数学表达式为:其中,μ是均值,σ是标准差,x是随机变量。
5. t分布(Student's t-distribution):t分布是用于小样本情况下对总体均值进行假设检验的重要工具。
它形状类似于正态分布,但是更扁平,并且具有更重的尾部,以补偿小样本情况下对总体均值的估计不准确性。

数理统计是研究数据收集、整理、分析和解释的一门学科,其中涉及到许多公式和方法。
以下是一些常用的数理统计公式:
1. 均值公式:
均值(平均值)是一组数据的总和除以数据的个数。
均值= (x1 + x2 + ... + xn) / n
2. 方差公式:
方差是一组数据与其均值之差的平方和的平均值。
方差= ((x1 - 平均值)^2 + (x2 - 平均值)^2 + ... + (xn - 平均值)^2) / n
3. 标准差公式:
标准差是方差的平方根,用于衡量数据的离散程度。
标准差= 方差的平方根
4. 相关系数公式:
相关系数用于衡量两个变量之间的线性关系的强度和方向。
相关系数= 协方差/ (x的标准差* y的标准差)
5. 正态分布公式:
正态分布是一种常见的概率分布,其概率密度函数为:f(x) = (1 / (σ * √(2π))) * e^(-(x-μ)^2 / (2σ^2))
6. 估计公式:
估计公式用于根据样本数据估计总体参数。
例如,样本均值可以用来估计总体均值,样本方差可以用来估计总体方差。
这只是数理统计中的一小部分公式,还有许多其他公式和方法,如假设检验、置信区间等。
具体使用哪些公式取决于具体的问题和数据类型。

概率论与数理统计公式概率论是一门研究随机现象规律的数学学科,是现代数学的基础之一、而数理统计则是利用概率论的工具和方法,分析和处理统计数据,从而得出推断、估计、决策等信息的科学。
在概率论与数理统计的学习过程中,掌握一些重要的公式是非常关键的。
下面是一些概率论与数理统计中常用的公式:1.概率公式:-加法公式:P(A∪B)=P(A)+P(B)-P(A∩B)-乘法公式:P(A∩B)=P(A)*P(B,A)-条件概率公式:P(A,B)=P(A∩B)/P(B)2.期望与方差公式:-期望:E(X)=∑(x*P(X=x))- 方差:Var(X) = E((X-μ)^2) = ∑((x-μ)^2 * P(X=x))3.常用概率分布及其特征:-二项分布:P(X=k)=C(n,k)*p^k*(1-p)^(n-k)-泊松分布:P(X=k)=(λ^k*e^(-λ))/k!-正态分布:f(x)=(1/(σ*√(2π)))*e^(-((x-μ)^2)/(2*σ^2))4.样本与总体统计量公式:-样本均值:x̄=(∑x)/n-样本方差:s^2=(∑(x-x̄)^2)/(n-1)-样本标准差:s=√(s^2)5.参数估计公式:-点估计:-总体均值估计:μ的点估计为x̄-总体方差估计:σ^2的点估计为s^2-区间估计:-总体均值的置信区间:x̄±Z*(σ/√n)-总体比例的置信区间:p±Z*√((p*(1-p))/n)6.假设检验公式:-均值检验:-单样本均值检验:t=(x̄-μ0)/(s/√n)-双样本均值检验:t=(x̄1-x̄2)/√((s1^2/n1)+(s2^2/n2))-比例检验:-单样本比例检验:z=(p-p0)/√((p0*(1-p0))/n)-双样本比例检验:z=(p1-p2)/√((p*(1-p))*((1/n1)+(1/n2)))以上是概率论与数理统计中一些常用的公式,这些公式为解决问题提供了有力的工具和方法。

数理统计常用公式1.样本均值的公式:样本均值(x̄)是在一组样本数据中,所有数据的总和除以样本数量的结果。
即:x̄=(x₁+x₂+x₃+...+x̄)/n其中,x₁、x₂、x₃等为样本数据,n为样本数量。
2.总体均值的公式:总体均值(μ)是在一个总体中,所有数据的总和除以总体数量的结果。
在样本数据无法覆盖总体数据的情况下,可以通过样本均值来估计总体均值。
即:μ=(x₁+x₂+x₃+...+x̄)/N其中,x₁、x₂、x₃等为样本数据,N为总体数量。
3.样本方差的公式:样本方差(s²)是一组样本数据与其均值之差的平方和除以样本数量减一的结果。
即:s²=((x₁-x̄)²+(x₂-x̄)²+(x₃-x̄)²+...+(x̄-x̄)²)/(n-1)其中,x₁、x₂、x₃等为样本数据,x̄为样本均值,n为样本数量。
4.总体方差的公式:总体方差(σ²)是一组数据与其均值之差的平方和除以总体数量的结果。
在样本数据无法覆盖总体数据的情况下,可以通过样本方差来估计总体方差。
即:σ²=((x₁-μ)²+(x₂-μ)²+(x₃-μ)²+...+(x̄-μ)²)/N其中,x₁、x₂、x₃等为样本数据,μ为总体均值,N为总体数量。
5.样本标准差的公式:样本标准差(s)是样本方差的平方根。
即:s=√(s²)其中,s²为样本方差。
6.总体标准差的公式:总体标准差(σ)是总体方差的平方根。
即:σ=√(σ²)其中,σ²为总体方差。
7.相关系数的公式:相关系数(r)衡量了两个变量之间线性关系的强度和方向。
其计算公式为:r=Σ((x-x̄)*(y-ȳ))/(√(Σ(x-x̄)²)*√(Σ(y-ȳ)²))其中,x、y为两个变量的取值,x̄、ȳ分别为两个变量的均值,Σ表示求和。

数理统计中的关键公式速查统计学作为一门重要的学科,充斥着大量的数学运算和公式。
掌握统计学中的关键公式对于学习和应用统计学都具有重要的意义。
本文将为大家提供数理统计中的关键公式速查,帮助读者快速准确地找到所需公式。
1. 描述统计学公式1.1 样本均值(Sample Mean)样本均值是评估样本集中趋势的常用方式。
公式:$\bar{x}=\frac{1}{n}\sum_{i=1}^{n}x_i$1.2 样本方差(Sample Variance)样本方差用于衡量样本数据的离散程度。
公式:$s^2=\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{x})^2$1.3 样本标准差(Sample Standard Deviation)样本标准差是样本方差的平方根。
公式:$s=\sqrt{s^2}$1.4 总体均值(Population Mean)总体均值是指整个总体中的变量的平均值。
公式:$\mu=\frac{1}{N}\sum_{i=1}^{N}x_i$1.5 总体方差(Population Variance)总体方差是指整个总体中的变量的离散程度。
公式:$\sigma^2=\frac{1}{N}\sum_{i=1}^{N}(x_i-\mu)^2$1.6 总体标准差(Population Standard Deviation)总体标准差是总体方差的平方根。
公式:$\sigma=\sqrt{\sigma^2}$2. 概率论公式2.1 条件概率(Conditional Probability)条件概率是指事件 A 在事件 B 已经发生的前提下发生的概率。
公式:$P(A|B)=\frac{P(A\cap B)}{P(B)}$2.2 乘法定理(Multiplication Rule)乘法定理适用于计算多个事件同时发生的概率。
公式:$P(A\cap B)=P(A|B)P(B)$2.3 加法定理(Addition Rule)加法定理适用于计算多个事件至少有一个发生的概率。

概率论与数理统计公式以下是概率论与数理统计中常见的公式整理:1.基本概率公式:P(A) = n(A) / n(S),其中A 为事件,n(A) 为事件A 发生的基数,n(S) 为样本空间的基数。
2.条件概率公式:P(A|B) = P(A∩B) / P(B),其中A 和B 为两个事件,P(A∩B) 表示事件A 和事件B 同时发生的概率,P(B) 表示事件B 发生的概率。
3.全概率公式:P(A) = ΣP(A|Bi) * P(Bi),其中Bi 为互不相交的事件,P(Bi) 表示事件Bi 发生的概率,P(A|Bi) 表示在事件Bi 发生的条件下,事件A 发生的概率。
4.贝叶斯公式:P(Bi|A) = P(A|Bi) * P(Bi) / ΣP(A|Bj) * P(Bj),其中Bi 为互不相交的事件,P(Bi) 表示事件Bi 发生的概率,P(A|Bi) 表示在事件Bi 发生的条件下,事件A 发生的概率,P(A|Bj) 表示在事件Bj 发生的条件下,事件A 发生的概率。
5.随机变量的期望值:E(X) = Σxi * P(xi),其中X 为随机变量,xi 为随机变量X 取的第i 个值,P(xi) 表示X 取xi 的概率。
6.随机变量的方差:Var(X) = E((X - E(X))^2),其中X 为随机变量,E(X) 表示X 的期望值。
7.正态分布的概率密度函数:f(x) = (1 / (σ* √(2π))) * e^(-((x-μ)^2 / (2σ^2))),其中μ为正态分布的均值,σ为正态分布的标准差。
8.标准正态分布的概率密度函数:f(x) = (1 / √(2π)) * e^(-x^2 / 2),其中x 为标准正态分布的随机变量。
9.两个随机变量的协方差:Cov(X,Y) = E((X - E(X)) * (Y - E(Y))),其中X 和Y 为两个随机变量,E(X) 和E(Y) 分别表示X 和Y 的期望值。

概率论数理统计公式整理一、概率论公式1.定义公式:-事件概率的定义:若E为随机试验的一个事件,S为样本空间,则事件E发生的概率可以表示为P(E)=n(E)/n(S),其中n(E)表示事件E中元素的个数,n(S)表示样本空间S中元素的总数。
2.概率计算公式:-加法公式:P(A∪B)=P(A)+P(B)-P(A∩B),其中A,B为两个事件。
-条件概率公式:P(A,B)=P(A∩B)/P(B),其中A,B为两个事件,且P(B)≠0。
-乘法公式:P(A∩B)=P(A)P(B,A),其中A,B为两个事件。
3.全概率公式与贝叶斯公式:-全概率公式:设B1,B2,...,Bn为样本空间S的一组互不相容的事件,并且它们构成了对S的一个完全划分,即Bi∩Bj=∅(i≠j),且B1∪B2∪...∪Bn=S,则对于任意事件A,有P(A)=ΣP(A,Bi)P(Bi),其中i=1,2,...,n。
-贝叶斯公式:设B1,B2,...,Bn为样本空间S的一组互不相容的事件,并且它们构成了对S的一个完全划分,即Bi∩Bj=∅(i≠j),且B1∪B2∪...∪Bn=S,则对于任意事件A,有P(Bi,A)=P(A,Bi)P(Bi)/ΣP(A,Bj)P(Bj),其中i=1,2,...,n。
二、数理统计公式1.随机变量的概率分布:-离散型随机变量的概率分布:P(X=x)=p(x),其中x为随机变量X的取值,p(x)为概率质量函数。
- 连续型随机变量的概率密度函数: f(x) ≥ 0,且∫f(x)dx = 12.随机变量的数学期望:- 离散型随机变量的数学期望: E(X) = Σxip(xi),其中xi为随机变量X的取值,p(xi)为X取值为xi的概率。
- 连续型随机变量的数学期望: E(X) = ∫xf(x)dx。
3.方差和标准差:- 离散型随机变量的方差: Var(X) = E[(X - E(X))^2] = Σ(xi - E(X))^2p(xi)。

数理统计公式数理统计公式是数理统计学中的重要内容,通过公式的运用可以对数据进行分析和推断。
本文将介绍几个常用的数理统计公式,包括概率密度函数、期望值、方差和标准差等。
一、概率密度函数(Probability Density Function,简称PDF)是描述连续随机变量的概率分布的函数。
对于一个连续随机变量X,其概率密度函数f(x)满足以下两个条件:1) f(x)≥0,对于所有的x∈R;2) ∫f(x)dx=1,即概率密度函数在整个实数轴上的积分等于1。
概率密度函数可以用来求解连续随机变量的概率。
二、期望值(Expectation)是用来描述随机变量平均取值的一个数学概念。
对于离散随机变量X,其期望值E(X)定义为E(X)=∑xP(X=x),即随机变量X取值的加权平均值,其中P(X=x)表示随机变量X取值为x的概率。
对于连续随机变量X,其期望值E(X)定义为E(X)=∫xf(x)dx,其中f(x)为X的概率密度函数。
三、方差(Variance)是用来描述随机变量离散程度的一个数学概念。
对于随机变量X,其方差Var(X)定义为Var(X)=E[(X-E(X))^2],即随机变量X与其期望值之差的平方的期望值。
方差可以衡量数据的离散程度,方差越大表示数据越分散,方差越小表示数据越集中。
四、标准差(Standard Deviation)是方差的平方根,用来度量随机变量的离散程度。
对于随机变量X,其标准差σ定义为σ=sqrt(Var(X))。
标准差是方差的一种常见的度量方式,它具有与原始数据相同的单位,可以直观地表示数据的离散程度。
除了以上介绍的几个常用的数理统计公式外,数理统计学还有许多其他重要的公式,如协方差、相关系数、似然函数等。
这些公式在实际数据分析和统计推断中起到了重要的作用,帮助我们理解和解释数据背后的规律和特征。
数理统计公式是数理统计学的重要工具,它们可以帮助我们对数据进行分析和推断。
概率密度函数、期望值、方差和标准差是数理统计中常用的公式,通过它们的运用,我们可以更好地理解和解释数据的特征和规律。
数理统计常用公式整理一、概率公式1. 概率的加法公式:P(A∪B) = P(A) + P(B) - P(A∩B)2. 条件概率公式:P(A|B) = P(A∩B) / P(B)3. 乘法公式:P(A∩B) = P(B) × P(A|B) = P(A) × P(B|A)4. 全概率公式:P(B) = ΣP(Ai) × P(B|Ai),其中Ai为样本空间的划分。
5. 贝叶斯公式:P(Ai|B) = P(Ai) × P(B|Ai) / ΣP(Aj) × P(B|Aj),其中Ai为样本空间的划分。
二、随机变量公式1. 期望:E(X) = Σx×P(X=x),其中x为随机变量X的取值,P(X=x)为其概率。
2. 方差:Var(X) = E((X-E(X))^2) = E(X^2) - [E(X)]^23. 协方差:Cov(X,Y) = E((X-E(X))(Y-E(Y)))4. 两个随机变量X和Y的相关系数:ρ(X,Y) = Cov(X,Y) / (σ(X) × σ(Y)),其中σ(X)和σ(Y)分别为X和Y的标准差。
三、常见分布公式1. 二项分布:P(X=k) = C(n,k) × p^k × (1-p)^(n-k),其中n为试验次数,k为成功次数,p为单次试验成功的概率。
2. 泊松分布:P(X=k) = (λ^k × e^(-λ)) / k!,其中λ为单位时间(或单位面积)内随机事件发生的平均次数。
3. 正态分布:f(x) = (1 / (σ×√(2π))) × e^(-(x-μ)^2 / (2σ^2)),其中μ为均值,σ为标准差。
4. t分布:f(t) = (Γ((v+1)/2) / (√(vπ) × Γ(v/2))) × (1 + t^2/v)^(-((v+1)/2)),其中v为自由度。
概率论与数理统计完整公式概率论与数理统计是数学的一个分支,研究随机现象和随机变量之间的关系、随机变量的分布规律、经验规律及参数估计等内容。
在概率论与数理统计的学习中,有许多重要的公式需要掌握。
以下是概率论与数理统计的完整公式。
一、概率论公式:1.全概率公式:设A1,A2,…,An为样本空间S的一个划分,则对任意事件B,有:P(B)=P(B│A1)·P(A1)+P(B│A2)·P(A2)+…+P(B│An)·P(An)2.贝叶斯公式:对于样本空间S的一划分A1,A2,…,An,其中P(Ai)>0,i=1,2,…,n,并且B是S的任一事件,有:P(Ai│B)=[P(B│Ai)·P(Ai)]/[P(B│A1)·P(A1)+P(B│A2)·P(A2)+…+P (B│An)·P(An)]3.事件的独立性:若对事件A,B有P(AB)=P(A)·P(B),则称事件A,B相互独立。
4.概率的乘法公式:对于独立事件A1,A2,…,An,有:P(A1A2…An)=P(A1)·P(A2)·…·P(An)5.概率的加法公式:对事件A,B有:P(A∪B)=P(A)+P(B)-P(AB)6.条件概率的计算:对事件A,B有:P(A,B)=P(AB)/P(B)7.古典概型的概率计算:设事件A在n次试验中发生k次的次数服从二项分布B(n,p),则其概率可表示为:P(X=k)=C(n,k)·p^k·(1-p)^(n-k),其中C(n,k)=n!/[k!(n-k)!]二、数理统计公式:1.样本均值的期望和方差:样本的均值X̄的期望和方差分别为: E(X̄) = μ,Var(X̄) = σ^2 / n,其中μ 为总体的均值,σ^2 为总体方差,n 为样本容量。
2.样本方差的期望:样本方差S^2的期望为:E(S^2)=σ^2,其中σ^2为总体方差。
数理统计中的重要公式整理正文:数理统计是一门研究统计学原理和方法的学科,其重要性不可忽视。
在数理统计中,有一些重要的公式被广泛应用于各类统计问题的求解和分析。
本文将对数理统计中的重要公式进行整理,以帮助读者更好地掌握和应用这些公式。
1. 概率论与数理统计基本公式1.1 概率论基本公式:(1) 加法法则:P(A ∪ B) = P(A) + P(B) − P(A ∩ B)(2) 乘法法则:P(A ∩ B) = P(A)P(B|A) = P(B)P(A|B)(3) 全概率公式:P(A) = ∑ P(A ∩ Bᵢ) = ∑ P(Bᵢ)P(A|Bᵢ)(4) 贝叶斯公式:P(A|B) = P(B|A)P(A) / P(B)1.2 数理统计基本公式:(1) 期望值公式:E(X) = ∑ XᵢP(Xᵢ)(2) 方差公式:Var(X) = E[(X - E(X))²] = E(X²) - [E(X)]²(3) 协方差公式:Cov(X, Y) = E[(X - E(X))(Y - E(Y))] = E(XY) -E(X)E(Y)(4) 相关系数公式:ρ(X, Y) = Cov(X, Y) / σ(X)σ(Y)2. 统计推断中的重要公式2.1 参数估计公式:(1) 矩估计:θ̂= ḡ(m₁, m₂, ..., mₖ)(2) 最大似然估计:θ̂= argmax[∏ f(x; θ)](3) 最小二乘估计:θ̂= argmin[∑ (yᵢ - g(xᵢ; θ))²]2.2 假设检验公式:(1) z检验:z = (x - μ) / (σ/√n)(2) t检验:t = (x - μ) / (s/√n)(3) 卡方检验:χ² = ∑ (Oᵢ - Eᵢ)² / Eᵢ3. 抽样理论中的重要公式3.1 随机变量公式:(1) 期望值公式:E(X) = μ(2) 方差公式:Var(X) = σ²/n(3) 中心极限定理:Z = (X - μ) / (σ/√n) 服从标准正态分布3.2 总体参数估计公式:(1) 基本抽样分布(z分布):z = (X - μ) / (σ/√n)(2) t分布:t = (X - μ) / (s/√n)(3) X²分布:χ² = ∑ (Xᵢ - Eᵢ)² / Eᵢ4. 方差分析中的重要公式4.1 单因素方差分析公式:(1) 总平方和公式:SST = ∑ (xᵢj - x)²(2) 因素平方和公式:SFA = n ∑ (xₖ - x)²(3) 误差平方和公式:SSE = ∑ (xᵢj - xₖ)²4.2 F检验公式:F = (SFA / (k - 1)) / (SSE / (n - k))5. 相关分析中的重要公式5.1 简单线性回归公式:(1) 回归模型:Y = β₀ + β₁X + ε(2) 最小二乘估计公式:β̂₁ = ∑((Xᵢ - X)(Yᵢ - Ȳ)) / ∑((Xᵢ - X)²)β̂₀ = Ȳ - β̂₁X(3) 相关系数公式:r = Cov(X, Y) / (σ(X)σ(Y))6. 抽样调查中的重要公式6.1 简单随机抽样公式:(1) 抽样率:p = n / N(2) 估计总量公式:T = N * (X / n)(3) 估计方差公式:Var(T) = N² * ((1 - p/n) / n) * σ²7. 时间序列分析中的重要公式7.1 平稳时间序列公式:(1) 自协方差公式:γ(h) = Cov(Xₖ, Xₖ₋ₖ) = γ(-h)(2) 自相关系数公式:ρ(h) = Cov(Xₖ, Xₖ₋ₖ) / (σ(Xₖ)σ(Xₖ₋ₖ))通过对这些数理统计中的重要公式的整理,我们可以更加方便地在实际问题中应用这些公式,进行数据分析、参数估计、假设检验等统计推断工作。
概率论与数理统计公式大全一、概率论的常用公式:1.概率的公式:对于事件A,其概率表示为P(A),满足0≤P(A)≤1。
2.加法公式:对于两个互斥事件A和B,其概率表示为P(A∪B),满足P(A∪B)=P(A)+P(B)。
3.减法公式:对于事件A和B,其概率表示为P(A∩B),满足P(A∩B)=P(A)-P(A∪B)。
4.乘法公式:对于两个独立事件A和B,其概率表示为P(A∩B),满足P(A∩B)=P(A)某P(B)。
5.条件概率公式:对于事件A和B,其条件概率表示为P(A,B),满足P(A,B)=P(A∩B)/P(B)。
6.全概率公式:对于一组互斥事件B1,B2,...,Bn,以及事件A,有P(A)=∑(P(A,Bi)某P(Bi))。
7.贝叶斯公式:对于一组互斥事件B1,B2,...,Bn,以及事件A,有P(Bi,A)=P(A,Bi)某P(Bi)/(∑(P(A,Bj)某P(Bj))。
二、数理统计的常用公式:1.均值公式:对于一组数据某1,某2,...,某n,其均值表示为μ=∑(某i)/n。
2.方差公式:对于一组数据某1,某2,...,某n,其方差表示为σ^2=∑((某i-μ)^2)/n。
3.标准差公式:对于一组数据某1,某2,...,某n,其标准差表示为σ=√(σ^2)。
4. 协方差公式:对于两组数据某1,某2,...,某n 和 y1,y2,...,yn,其协方差表示为 Cov(某,y) = ∑((某i - μ某) 某 (yi - μy)) / n。
5. 相关系数公式:对于两组数据某1,某2,...,某n 和 y1,y2,...,yn,其相关系数表示为 r = Cov(某,y) / (σ某某σy)。
6.正态分布的概率计算:对于满足正态分布的一组数据某1,某2,...,某n,可以利用标准正态分布表或计算工具来计算概率P(X≤某)或P(X>某)。
7.置信区间公式:对于一组数据某1,某2,...,某n,其均值μ和置信水平α,可以计算置信区间为某̄±Z(α/2)某(σ/√n)。
常用数理统计公式以下是一些常用的数理统计公式:1. 样本均值 (Sample Mean):x̄ = (Σxi) / n2. 总体均值 (Population Mean):μ = (Σxi) / N3. 样本方差 (Sample Variance):s^2 = (Σ(xi - x̄)^2) / (n - 1)4. 总体方差 (Population Variance):σ^2 = (Σ(xi - μ)^2) / N5. 样本标准差 (Sample Standard Deviation):s=√s^26. 总体标准差 (Population Standard Deviation):σ=√σ^27. 样本协方差 (Sample Covariance):Cov(x, y) = (Σ(xi - x̄)(yi - ȳ)) / (n - 1)8. 总体协方差 (Population Covariance):Cov(X, Y) = (Σ(xi - μx)(yi - μy)) / N9. 样本相关系数 (Sample Correlation Coefficient):r = Cov(x, y) / (sxsy)10. 总体相关系数 (Population Correlation Coefficient):ρ = Cov(X, Y) / (σXσY)11. 样本标准误 (Standard Error of the Mean):SEM=s/√n12. 置信区间 (Confidence Interval):CI=x̄±(zα/2*SEM)13. z分数 (z-Score):z=(x-μ)/σ14. t分数 (t-Score):t=(x-μ)/(s/√n)15. 卡方检验 (Chi-Square Test):Chi^2 = Σ((O - E)^2) / E16. t检验 (t-Test):t=(x̄1-x̄2)/√((s1^2/n1)+(s2^2/n2))17. 方差分析 (Analysis of Variance, ANOVA):F=(MSB/MSE)18. 线性回归方程 (Linear Regression Equation):y=b0+b1*x19. 残差 (Residual):e=y-ŷ20. 判定系数 (Coefficient of Determination):R^2=(SSR/SST)=1-(SSE/SST)这些公式可以用于描述和分析数据集的中心趋势、变异性、相互关系和模型拟合程度。
概率论与数理统计公式整理一、概率论公式:1.加法公式:P(A∪B)=P(A)+P(B)-P(A∩B)2.乘法公式:P(A∩B)=P(A)×P(B,A)其中,P(A)和P(B)表示事件A和B的概率,P(B,A)表示已知事件A发生的条件下事件B发生的概率。
3.全概率公式:P(A)=∑[P(A,B(i))×P(B(i))]其中,B(i)表示互斥事件组,且它们的概率之和为14.贝叶斯公式:P(B(j),A)=P(A,B(j))×P(B(j))/∑[P(A,B(i))×P(B(i))]其中,P(B(j),A)表示已知事件A发生的条件下事件B(j)发生的概率。
5.期望值公式:E(X)=∑[x×P(X=x)]其中,X为一个随机变量,x为X的取值,P(X=x)为X等于x的概率。
6.方差公式:Var(X) = E[(X-E(X))^2]其中,Var(X)表示随机变量X的方差,E(X)表示X的期望值。
二、数理统计公式:1.样本均值公式:样本均值 = (x1 + x2 + ... + xn)/n其中,x1、x2、..、xn为样本中的观测值,n为样本容量。
2.样本方差公式(无偏估计):样本方差 = [(x1-样本均值)^2 + (x2-样本均值)^2 + ... + (xn-样本均值)^2]/(n-1)3.样本标准差公式(无偏估计):样本标准差=样本方差的平方根4.正态分布的标准化公式:Z=(X-μ)/σ其中,X为一个正态随机变量,μ为其均值,σ为其标准差,Z为标准正态分布的变量。
5.正态分布的累积分布函数:P(X≤x)=Φ((x-μ)/σ)其中,Φ表示标准正态分布的累积分布函数。
6.样本之间的协方差公式:Cov(X,Y) = ∑[(x(i)-X均值) × (y(i)-Y均值)]/(n-1)其中,X、Y为两个随机变量,x(i)、y(i)为X、Y的观测值,X均值、Y均值分别为X、Y的样本均值,n为样本容量。
1.
∑
==
n
i i
x n
x 1
1 y n
2
1
2
2
1
)(x
n x x x
L n
i i n
i i
xx -=
-=
∑
∑==
2
1
2
2
1
)(y
n y y y
L n
i i n
i i
yy -=
-=
∑
∑==
y
x n y x y y x x L i n
i i i n
i i xy -=
--=
∑
∑
==1
1
)()(
x b y a ˆˆ-= xx
xy L L b /ˆ= )(ˆˆˆˆx x b y x b a y
-+=+= 2.b 的显著性检验
0:,0:10≠=b H b H
拒
)2(-≥=
n r L L L r a yy
xx xy
3. b 的区间估计
)
2(ˆ)ˆ(-=-=
n t b b
L t e
xx σ
)/)2(ˆˆ(2
/1xx e L n t b b -±∈-ασ 2
ˆˆ
2
--=
n b L yy e
σ 4. 预测y 0
)2()
(11ˆˆ2/12
000-→-+
+
--n t L x x n
y
y xx
e ασ
5. 控制
)ˆˆ(ˆ12/1a u y b
x e -+'=
'-ασ
)ˆˆ(ˆ12/1a u y b
x e --''=''-ασ
6. 点估计
2
σn L b L xx
yy 22
ˆˆ-=
σ
其他:))1(
,(ˆ
2
2
xx
L x
n
a N a
+
→σ)
,(ˆ2
xx
L b N b
σ
→
2
)ˆ,ˆc o v (σ
xx
L x b a
-= 0)ˆ,c o v (=b
y r i n 求i x ,2
i s ,x
方差来源(A, e, S T ) 平方和(S A , S e , S T ) 自由度(r-1, n-r ) 方差(e A S S ,)F 值(e A S S /)
),1(1r n r F ---α大否小接受
区间估计(单) 1.1 μ
σ已知,求2
)
1,0(/U N n
x →-=
σμ
)
(2
1α
σμ-
±
∈u
n
x
1.2 μ
σ未知,求2
)
1(/
U *
-→
-=
n t n
s x μ ))
1((2
1*
-±
∈-
n t
n
s
x α
μ
2.1
2
σ
μ已知,求
)
()
(2
2
2
1
2
n u x
n
i i
χσ
χ
→-=
∑=
)
)
()
(,
)
()
((
2
2/2
1
02
2/12
1
02
n x u x
n x u x
n
i i
n
i i
αασ
∑∑=-=--∈
2.2
2
σ
μ未知,求
)1-(S
12
2
2
*2
n n χ
σ
χ
→-=)( ))
1(S 1,)1(S 1(22/2
*
2
2/12
*2----∈-n x n n x n αασ)()( 区间估计(双) 3.1 212221,u -μσσ已知,求
)
1,0()
()(U 2
2
21
2
1
21N n n u y x →+
---=
σσμ
)
)(()(2
12
2
21
2
1
21α
σσμ-
+
±
-∈-u
n n y x u
3.2
212
22
12
u -=μσσσ,求未知
)
2(11)()(U 212
1
21-+→+---=
n n t n n S u y x W
μ
2
212
*12
)
12()1(*
-+-+-=
n n n S
n S S
W
))
2(11)(()(212
12
1
21-++
±-∈--
n n t
n n S y x u W
α
μ
0-1分布 B (1,p ) EX=P DX= p(1-p)
{}()k n k p p k X P --==1 it x pe p -1(t)+=ϕ 二项分布B (n ,p ) EX=nP DX=n p(1-p)
{}()k n k
k
n p p
C k X P --==1 n
)pe p -1((t)
it x +=ϕ
几何分布(n 重伯努利分布) EX=1/p DX= (1-p)/p 2
{}()
1
1--==n p p n X P
泊松分布p(λ)(k=0,1,2…) EX=λ DX=λ
{}λ
λ
-=
=e
k k X P k
!
))1e (exp((t)it x -=λϕ
均匀分布U (a,b ) EX=(b+a )/2 DX=(b-a)2/12
{}a
b X
P -=
1 )
()
e
e
((t)ait
bit
x
a b it --=ϕ
指数分布 EX=1/λ DX=1/λ2
{}x e X
P λλ-= 1
x )
1((t)
--
=λ
ϕit
正态分布N ⎭
⎬⎫
⎩⎨⎧-=2exp (t)2
2x
t iut σϕ 伽玛分布Γ分布
{}x
e
x
X P βαα
αβ
--Γ=
1
)
( αβ
ϕ--=)1((t )x it
β
α=
EX 2
β
α=DX
2
χ分布 EX=n DX=2n
{}2
2
1
2
2)2
(
x n
n
e
n x X P -
-Γ=
2
x )
21((t)n it -
-=ϕ
F 分布
)2(2
222>-=n n n EX )4()
4()2()2(2222
21212
2>---+=
n n n n n n n DX。