医学论文中常见统计学概念误用分析
- 格式:doc
- 大小:32.00 KB
- 文档页数:3

医学论文中常用统计分析方法错误大全在医学研究领域,统计分析方法的正确应用对于得出科学、可靠的结论至关重要。
然而,在实际的医学论文中,我们常常能发现各种各样的统计分析方法错误,这些错误不仅影响了研究结果的准确性和可信度,还可能导致错误的临床决策。
下面,我们就来详细梳理一下医学论文中常见的统计分析方法错误。
一、样本量不足样本量的大小直接关系到研究结果的可靠性和普遍性。
如果样本量过小,可能无法准确反映总体的特征,导致统计效能不足,从而得出错误的结论。
例如,在比较两种治疗方法的疗效时,如果每组的样本量只有十几例,那么很可能因为偶然因素而得出错误的差异结论。
二、数据类型错误医学研究中数据类型多种多样,包括计量数据(如身高、体重、血压等)、计数数据(如治愈人数、死亡人数等)和等级数据(如病情的轻、中、重)。
如果对数据类型的判断错误,就会选择错误的统计分析方法。
例如,将本来应该是计数数据的治愈率当作计量数据进行 t 检验,这是不正确的。
三、忽视数据分布许多统计方法都有其适用的数据分布条件。
例如,t 检验和方差分析要求数据服从正态分布。
如果数据不服从正态分布而强行使用这些方法,就会得出错误的结果。
在这种情况下,应该先对数据进行正态性检验,如果不满足正态分布,可以考虑使用非参数检验方法,如秩和检验。
四、多重比较问题在医学研究中,常常需要进行多个组之间的比较。
如果不注意控制多重比较带来的误差,就会增加得出错误阳性结果的概率。
例如,在比较多个药物剂量组的疗效时,如果不进行适当的校正(如 Bonferroni 校正),就可能因为多次比较而错误地认为存在显著差异。
五、相关与回归分析的错误相关分析用于研究两个变量之间的线性关系,但不能得出因果关系。
在医学论文中,有时会错误地将相关关系解释为因果关系。
回归分析中,自变量的选择、模型的拟合度评估等方面也容易出现错误。
例如,没有考虑自变量之间的共线性问题,导致回归结果不准确。
六、生存分析的错误生存分析常用于研究疾病的发生、发展和预后。


医学科技论文统计学误用分析1统计学应用中存在的常见问题1.1单因素方差分析(ANOVA)两两比较误用独立样本t检验单因素方差分析设计3组以上的均数比较,如果总体比较有差异,需进行两两比较,一般用SNK法或LSD法。
但部分研究者却将资料进行拆分,应用独立样本t检验进行两两比较,导致第Ⅰ类统计学错误发生率(假阳性率)增加,从而掉进了一个常见的“统计陷阱”,使所得结论可信度大大降低甚至得出错误结论。
SNK法与LSD法虽然并非等价,实质是一致的。
SNK法一般用于经方差分析结果具有统计学意义时才决定进行的两两事后比较,而LSD法可用于方差分析不足以具有统计学意义时也能进行两两比较[1]。
比较两种方法在SPSS的输出结果形式,SNK是“分堆”比较,一目了然,对于组别数较多的研究更为好用,但没有具体P值,而LSD是在进行“两两”比较时,能给出具体的P值。
1.2两两比较时检验水准的重新调定χ2检验或秩和检验3组以上整体比较有差异时,需应用分割法进行两两比较,这时检验水准应由原0.05调定为0.0167,否则会增加第Ⅰ类统计学错误的发生率。
特别当P值处于0.0167~0.05时,按照P<0.0167的标准,差异无统计学意义,而按照P<0.05的标准,却有意义,与事实相悖,出现假阳性,很容易得出错误结论。
这种分割法有时很保守,当行列表资料分组多且为有序时可用Mantel-Haenszel卡方检验,也称线性趋势检验(testforlineartrend)或定序检验(Linear-by-Lineartest)[2]。
统计路径:用SPSS进行计数资料的趋势检验,在输出结果中读取线性关联检验统计量(Linear-by-LinearAssociation,LLA),如P<0.05可得出随着病种级别的升高,检测指标逐渐升高的趋势。
1.3临床诊断试验中的统计学方法应用在临床诊断试验研究中,经常选取单项计量指标或者联合计量指标以诊断某种疾病,若仅用初级统计学方法如t检验、单因素方差分析等往往不能有效挖掘信息,此时应采用受试者工作特征曲线(ROC)对检测结果进行分析评价。


医学期刊论文常见统计学错误1.统计表达和描述方面存在的错误:(1)统计表中数据的含义未表达清楚,令人费解。
(2)统计图方面的主要错误有2个,其一,横坐标轴上的刻度值是随意标上去的,等长的间隔代表的数量不等,在直角坐标系中,从任何一个数值开始作为横轴或纵轴上的第一个刻度值;其二,用条图或复式条图表达连续性变量的变化趋势;(3)运用相对数时,经常混淆“百分比”与“百分率”;(4)在表达多组定量资料时,即使定量资料偏离正态分布很远,仍采用“x珋±s”表达(标准差S>x珋),特别当表中采用标准误Sx珋取代标准差s时,前述的错误很难被察觉出来。
2.定量资料统计分析方面存在的错误:(1)当定量资料不满足参数检验的前提条件时,盲目套用参数检验方法;(2)不管定量资料对应的实验设计类型是什么,一律套用单因素2水平(或叫成组)设计定量资料的t检验或单因素多水平设计定量资料的方差分析。
3.定性资料统计分析方面存在的错误:(1)把χ2检验误认为是处理定性资料的万能工具;(2)忽视资料的前提条件而盲目套用某些定性资料的统计分析方法;(3)盲目套用秩和检验;(4)误用χ2检验实现定性资料的相关分析。
4.简单线性相关与回归分析方面存在的错误:(1)缺乏专业知识,盲目研究某些变量之间的相互关系和依赖关系;(2)不绘制反映2个定量变量变化趋势的散布图,盲目进行简单线性相关与回归分析,常因某些异常点的存在而得出错误的结论;(3)常用直线取代2定量变量之间事实上呈“S形或倒S形”的曲线变化趋势。
5.多因素或多自变量的实验资料进行分析存在的错误:(1)将原本属于多因素实验研究,拆分成一系列单因素的研究来分析,这种“化繁为简、化整为零”的处理,割裂了原先的整体设计,无法研究多因素之间的内在联系或交互作用,容易得出片面、甚至错误的结论;(2)虽然将多个自变量都包括在一个多重线性回归方程或多重Logistic回归方程之中,但整个回归方程没有统计学意义或回归方程中有很多无统计学意义的自变量,就依据这样的回归方程去下结论。
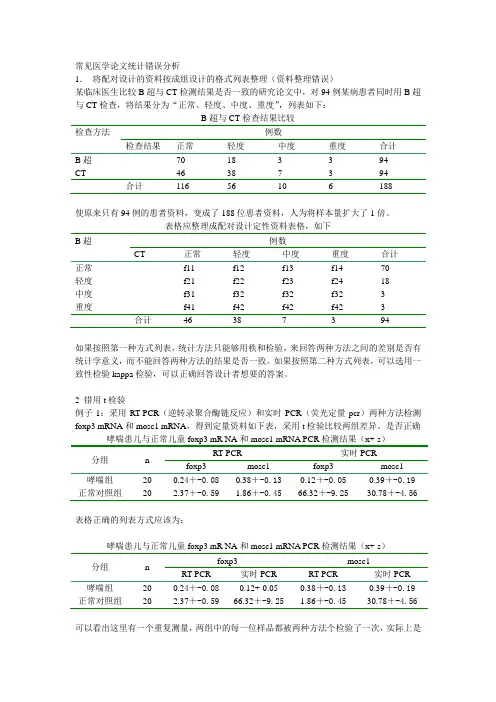
常见医学论文统计错误分析1.将配对设计的资料按成组设计的格式列表整理(资料整理错误)某临床医生比较B超与CT检测结果是否一致的研究论文中,对94例某病患者同时用B超与CT检查,将结果分为“正常、轻度、中度、重度”,列表如下:B超与CT检查结果比较检查方法例数检查结果正常轻度中度重度合计B超70 18 3 3 94CT 46 38 7 3 94 合计116 56 10 6 188使原来只有94例的患者资料,变成了188位患者资料,人为将样本量扩大了1倍。
表格应整理成配对设计定性资料表格,如下B超例数CT 正常轻度中度重度合计正常f11 f12 f13 f14 70轻度f21 f22 f23 f24 18中度f31 f32 f32 f32 3重度f41 f42 f42 f42 3如果按照第一种方式列表,统计方法只能够用秩和检验,来回答两种方法之间的差别是否有统计学意义,而不能回答两种方法的结果是否一致。
如果按照第二种方式列表,可以选用一致性检验kappa检验,可以正确回答设计者想要的答案。
2 错用t检验例子1:采用RT-PCR(逆转录聚合酶链反应)和实时PCR(荧光定量pcr)两种方法检测foxp3 mRNA和mosc1 mRNA,得到定量资料如下表,采用t检验比较两组差异。
是否正确哮喘患儿与正常儿童foxp3 mR NA和mosc1 mRNA PCR检测结果(x+-s)分组nRT-PCR 实时PCRfoxp3 mosc1 foxp3 mosc1哮喘组正常对照组20200.24+-0.082.37+-0.590.38+-0.131.86+-0.450.12+-0.0566.32+-9.250.39+-0.1930.78+-4.56表格正确的列表方式应该为:哮喘患儿与正常儿童foxp3 mR NA和mosc1 mRNA PCR检测结果(x+-s)分组nfoxp3 mosc1RT-PCR 实时PCR RT-PCR 实时PCR哮喘组正常对照组20200.24+-0.082.37+-0.590.12+-0.0566.32+-9.250.38+-0.131.86+-0.450.39+-0.1930.78+-4.56可以看出这里有一个重复测量,两组中的每一位样品都被两种方法个检验了一次,实际上是一个具有重复测量的两因素设计,应该用重复测量的两因素设计定量资料方差分析。


医学论文中常用统计分析方法错误大全在医学研究领域,准确合理地运用统计分析方法对于得出可靠的研究结论至关重要。
然而,在实际的医学论文中,却存在着各种各样的统计分析方法错误,这些错误可能会导致研究结果的偏差,甚至得出错误的结论。
下面,我们就来详细探讨一下医学论文中常见的统计分析方法错误。
一、数据类型判断错误数据类型的正确判断是选择合适统计分析方法的基础。
医学研究中常见的数据类型包括计量资料、计数资料和等级资料。
然而,很多研究者在数据类型判断上出现失误。
例如,将原本应该是计数资料的数据(如疾病的治愈、好转、无效等)当成计量资料进行分析,错误地使用了均值和标准差等统计指标,而应该使用频率和百分比等指标,并采用卡方检验等方法。
二、样本量计算不合理样本量的大小直接影响到研究结果的可靠性和准确性。
一些医学论文在研究设计阶段没有充分考虑样本量的计算,导致样本量过小或过大。
样本量过小,可能会使研究结果缺乏统计学意义,无法检测出真实存在的差异;样本量过大,则会造成资源的浪费,同时增加研究的难度和成本。
正确的样本量计算应该综合考虑研究的设计类型、预期效应大小、检验水准和检验效能等因素。
三、选择错误的统计方法这是医学论文中常见的错误之一。
例如,对于两组独立样本的均数比较,应该使用 t 检验,但如果两组数据的方差不齐,就需要使用校正的 t 检验或者非参数检验方法(如 Wilcoxon 秩和检验)。
然而,很多研究者在这种情况下仍然使用了普通的 t 检验,导致结果不准确。
再比如,对于多组均数的比较,如果方差分析结果有统计学意义,还需要进一步进行多重比较。
但有些研究在这一步没有进行恰当的多重比较方法选择,导致结论不够准确。
四、忽视数据的正态性检验在进行某些统计分析(如 t 检验、方差分析等)时,要求数据服从正态分布。
然而,很多研究者在使用这些方法之前,没有对数据进行正态性检验。
如果数据不服从正态分布,却仍然使用基于正态分布假设的统计方法,就会得出错误的结论。



医学论文中常用统计分析方法错误大全在医学研究领域,准确和恰当的统计分析是得出可靠结论的关键。
然而,在众多医学论文中,却存在着各种各样的统计分析方法错误,这些错误可能会导致研究结果的偏差甚至错误解读,从而影响医学研究的质量和临床实践的指导价值。
接下来,我们就来详细探讨一下医学论文中常见的统计分析方法错误。
一、样本量计算错误样本量的合理计算对于研究的可靠性和有效性至关重要。
许多研究在设计阶段未能充分考虑研究的主要目的、预期效应大小、检验效能以及显著性水平等因素,导致样本量过小或过大。
样本量过小可能使研究无法检测到真实存在的差异,从而得出假阴性结论;样本量过大则会造成资源浪费,同时可能增加研究的复杂性和误差。
例如,在一项比较新药物与传统药物疗效的临床试验中,如果预期的疗效差异较小,而研究者没有充分考虑这一点,计算出的样本量不足,那么即使新药物实际上更有效,也可能由于样本量的限制而无法得出有统计学意义的结果。
二、数据类型错误医学研究中数据类型多样,包括计量资料(如身高、体重、血压等)、计数资料(如疾病的发生例数、治愈例数等)和等级资料(如疾病的严重程度分为轻、中、重)。
错误地判断数据类型会导致选择错误的统计分析方法。
例如,将原本属于计数资料的数据(如疾病的治愈与未治愈),错误地当作计量资料进行 t 检验,这样得出的结果是不准确的。
反之,将计量资料当作计数资料处理,也会造成同样的问题。
三、选择错误的统计检验方法不同的研究问题和数据类型需要相应的统计检验方法。
常见的错误包括:在多个组间比较时,错误地使用 t 检验而不是方差分析;在非正态分布的数据中使用参数检验方法;在不符合独立性假设的情况下使用独立样本检验等。
比如,在比较三种不同治疗方法对患者生存率的影响时,应该使用方差分析或非参数的KruskalWallis 检验,而不是多次进行两两t 检验,因为这样会增加一类错误(即假阳性)的概率。
四、忽视方差齐性检验在进行 t 检验和方差分析时,通常需要先进行方差齐性检验。
医学论文中统计学概念的使用错误【摘要】目的在日常审读医学论文中,经常遇到文章作者错误地使用统计学概念,对调查或实验结果下结论。
方法针对论文中常见统计学错误用举例说明方法进行了阐述。
结果主要错误为:①误用概率;②以“比”代“率”;③对观察单位数不符的几个率直接相加求其总率;④计算相对数们分母过小。
结论写作时稍加留心就可避免此类错误。
【关键词】统计学;率;构成比;相对数1 误用概率(probability)概率是描述随机事件发生的可能性大小的数值,常用P表示。
如某例患者的结果为治愈,这个事件记为A,则该患者治愈的概率可记为P(A),或简记为P,这是医生颇为关心的数值。
假如我们用200例的样本,求得治愈率为75%,这只是一个频率。
在实际工作中,当概率不易求得时,只要观察单位数充分多,可以将频率作为概率的估计值。
但在观察单位数较少时,频率的波动性是很大的,用于估计概率是不可靠的[1]。
随机事件概率的大小在0与1之间,即0≤P≤1,常用小数或百分数表示。
习惯上将P≤0.05,称为小概率事件,表示在一次实验或观察中该事件发生的可能性很小,可以视为很可能不发生。
2 以“比”代“率”2.1 构成比(proportion)又称构成指标,说明某一事物内部各组成部分所占的比重或分布。
常以百分数表示,计算公式为:2.2 率(rate)又称频率指标。
说明某现象发生的频率或强度。
常以百分率(%)、千分率(‰)、万分率(1/万)、十万分率(1/10万)等表示。
计算公式为:医学中常用某一时点发病率、患病率、死亡率、病死率、治愈率等。
2.3 分析时不能以构成比代替率例1:甲、乙两市乙型脑炎普查资料见表1。
由此得出甲市10岁以上患乙型脑炎情况比乙市严重,10岁以下乙市比甲市严重(结论错误,犯以比代率的错误)。
2.4 注意不能用构成比的动态分析代替率的动态分析例2:表2为某市1990年和1995年5种常见传染病的发病情况。
1995年与1990年相比,痢疾的构成比有明显下降,而肝炎、流脑、麻疹及腮腺炎的构成比均上升,但以肝炎的构成比上升最为明显。
医学杂志论文中常见的统计学错误分析及对策随着医学科研的发展,统计学在医学杂志论文中扮演着重要的角色。
但是,由于研究者对统计学方法的理解不足或应用不当,常常会出现一些统计学错误。
本文将分析常见的统计学错误,并提出相应的对策,以帮助研究者提高论文质量。
2.样本量不足:样本量的大小对于统计结果的可靠性和代表性至关重要。
样本量不足可能导致结果不具有统计学意义。
因此,研究者在进行实验设计时,应该根据研究目的和预期效应大小,通过统计学方法计算出所需的最小样本量,并确保实际样本量达到或超过计算的结果。
3.忽略数据分布的假设:一些统计学方法要求数据满足特定的分布假设,例如正态分布。
然而,研究者在应用统计方法时往往忽略了这个前提条件,并未对数据的分布进行充分检验。
为了避免这个问题,研究者应该在应用统计方法之前,使用合适的统计检验或图表来检验数据是否符合假设的分布。
4. 未进行多重比较校正:当进行多组比较时,如果未进行多重比较校正,可能会导致假阳性结果的出现,即错误地认为存在差异或关联。
为了避免这种错误,研究者应该在进行多重比较时采用适当的校正方法,例如Bonferroni校正或Benjamini-Hochberg过程。
5.缺乏效应大小的解释:纯粹依靠显著性检验结果来判断研究结果的重要性是不足够的。
研究者应该解释效应的大小,例如使用点估计和置信区间来表示效应的大小范围,并进行实际意义和临床可应用性的讨论。
6.忽略混杂因素的校正:在观察性研究中,混杂因素可能会影响到统计分析的结果。
如果在统计分析中未对混杂因素进行校正,可能会引入偏差。
因此,研究者应该在进行统计分析之前,充分考虑可能的混杂因素,并使用适当的统计方法进行校正。
7.未进行复杂数据分析:对于复杂数据结构,例如多层次数据(例如医生-病人数据)或长期纵向数据,简单的统计方法可能无法提供准确的结果。
研究者应该使用适当的复杂数据分析方法,例如多层次回归分析或混合效应模型,以更好地处理这种类型的数据。
------------------------------------------ 最新资料推荐------------------------------------ 医学科研论文中的统计学问题汇总分析医学科研论文中的统计学问题汇总分析作者:郑华宾ARS医学统计学是一门帮助人们透过偶然现象,分析和判断事物内在规律的科学。
随着医学科研工作的深入,医学统计学的应用越来越广泛。
由于统计学的内容非常丰富,并且仍在不断发展,而医务工作者常因各种原因不愿花费许多精力钻研统计学知识,故医学论文中误用统计学的现象较为严重。
为了减少这一现象,提高论文的水平,现就论文中常见的统计学错误,分析讨论如下。
1 .文中未交待所用统计方法论文中应将所用的统计方法交待清楚,例如,是配对设计的t检验还是成组设计的t检验,是Ridit 分析还是卡方检验,是作相关分析还是作回归推断。
使用不正确的统计方法会得出错误的结论,所以统计方法交待不清或根本不予交待,会使读者对论文结论的正确与否无法判断。
有的作者只提一句经统计学处理后,就写出结论;有的甚至于直接用P值说明问题了事。
正确的做法应写明具体的统计方法,如有特殊情况,还应说明是否采用了校正,这样才有说服力。
严格地说,应写明精确的统计量值和P值,如t值、F值、2 值等,不应笼统地以P0.05或P0.05代替。
此外,最好能交待所使用的计算工具与统计软件名称。
因采用公认的统计软件(如SAS、SPSS等)或程序型计算器进行计算,与手工计算相比,既准确又快捷,其计算结果易于被人接受。
2.使用统计方法时不考虑其应用条件每一种统计方法都有其适用条件。
在表示数值变量资料(计量资料)的平均水平时常用到平均数。
然而平均数有算术平均数(均数)、几何均数和中位数,各有其应用条件。
应用均数时,必须首先确定数据为正态分布。
如果数据是偏态分布,仍用均数表示其平均水平势必导致错误的结论,不少作者没有注意到这一点。
医学论文中常见统计学错误案例分析一、概述在医学研究领域,统计学方法的应用至关重要,它有助于科研人员对复杂数据进行深入的分析与解读,从而得出科学的结论。
由于统计学知识的复杂性和多样性,医学论文中常常会出现各种统计学错误。
这些错误不仅可能影响研究结果的准确性和可靠性,还可能误导读者对研究的理解和评价。
本文旨在通过分析医学论文中常见的统计学错误案例,揭示其产生原因和可能带来的后果,以提高医学科研人员和论文作者在统计学应用方面的准确性和规范性。
常见的医学论文统计学错误包括但不限于样本量计算不当、数据分布误判、统计方法选择错误、假设检验理解偏差、多重共线性问题以及P值解读不当等。
这些错误往往源于对统计学基本概念和方法理解不深入,或是忽视了对数据特征和实际研究问题的综合考量。
通过案例分析,我们可以更直观地了解这些错误在实际研究中的表现形式和潜在影响。
每个案例都将详细剖析错误发生的具体原因,并指出正确的处理方法或避免策略。
这将有助于医学科研人员和论文作者在今后的研究中更加谨慎地应用统计学方法,提高研究质量和学术水平。
本文还将强调加强统计学知识和技能的培训在医学科研中的重要性。
只有具备扎实的统计学基础,才能更好地理解和运用各种统计方法,避免或减少统计学错误的发生。
医学科研人员和论文作者应不断学习和更新统计学知识,提高自己在统计学应用方面的能力和素养。
1. 医学论文中统计学的重要性在医学研究中,统计学扮演着至关重要的角色。
它是确保研究设计合理性、数据收集和分析准确性以及结论可靠性的基石。
通过运用统计学方法,医学研究人员能够系统地评估治疗方法的疗效、疾病的发病机制和预后因素,从而为临床实践和政策制定提供科学依据。
统计学在医学论文中有助于确保研究的内部和外部有效性。
通过运用适当的统计学方法,研究人员可以控制潜在的混杂变量和偏倚,从而提高研究的准确性和可靠性。
这有助于避免由于研究设计不当或数据分析错误而导致的误导性结论。
(精品收藏)医学论文中常见统计学概念误用分析
医学统计学作为一种认识医学现象数量特征的重要工具,在医学研究的过程中起着非常重大的作用。
但国内外研究者通过调查发现,在现代医学期刊中,统计方法的运用及表述却存在着较多的问题[1,2]。
笔者在医学论文的编辑过程中,也发现有些作者对统计学中最常见、最基本的概念常混淆不清,因此其论文很难符合刊用的要求。
我们知道,概念是逻辑思维的基本要素,只有概念明确,才能准确地表达思想,才能对事物的本质进行客观的描述,才能作出正确的判断和推理,从而得出科学的结论。
为与作者共同提高论文质量,现对编辑工作中经常碰到的一些概念方面的误用问题,试图进行一些粗略的分析。
1概念混淆
1.1以比代率
比与率是临床医学研究中最常用的相对数指标。
比是表示某一事物或现象各组成部分之间或各个部分在全体中所占的比重或分布。
较常用的有构成比、相对比等。
而率是指某种现象或事件在一定条件下,其实际发生数与可能发生此现象或事件总数的比例。
临床医学论文中很多作者常把构成比当作率进行比较,造成对疾病的发生作出错误估计。
如在研究性别与其疾病发病率的关系文章中,作者把男女的构成比当作发病率,从而得出某种性别的发病率高的错误结论。
还有作者由于对构成比与率的概念不明确,造成计算错误。
如某农村卫生单位对7250名少儿进行粪检,检出蛔虫卵者4300人,需要进行治疗。
因各种原因,有900人未行治疗。
结果:已治率为79.07%,未治率为20.93%。
很明显,这是典型的以构成比代率的例子。
我们根据定义,可计算如下:
出现这种错误的原因,是因为不能正确理解比与率的区别所致。
一般来说,率的分子源于分母,但分子、分母具有不同的事件属性,构成比虽然分子也源于分母,但分子、分母具有相同的事件属性。
1.2不同率混用
在临床医学研究中,一些具有特殊性质的率很容易用错。
最常见的有发病率与患病率,死亡率与病死率。
发病率与患病率相混淆的原因主要是没有把握住观察、统计的时间。
前者是指在某一时期内,某人群发生某疾病的数与该人群总数之商,它涉及在这一时间期限内变化了的状态;而后者是某人群的个体在某一时点静态的测量方法。
分析两者的关系,一般来
说,发病率增加,其相应的患病率也增加。
疾病持续的时间对发病率无影响,但对患病率却有影响。
死亡率与病死率也是两个不同含义的指标,不可不加区别地使用。
在进行人群研究时,它们的分子可能相同,但分母不同。
死亡率的分母是同期人口数,反映了观察人口因某病的死亡水平,是一个人口学指标;而病死率的分母是患某病的患者总数,反映了某病的死亡危险性。
一个高的某疾病病死率,并不能说明就有高的某病死亡率。
对某一医院来说,只能计算病死率,而不能计算死亡率。
1.3漏诊与误诊不辩
漏诊与误诊,是两个重要的统计学术语,表达的意义各不相同。
在临床医学研究中,对误诊率与漏诊率的研究分析是不断地提高诊疗水平、改善医疗服务质量的一个有效方法。
但在当前医学期刊中,它们的错用率却非常高。
以A病为例,误诊是将A病诊断为非A病或将非A病诊断为A病,而漏诊是仅将A病没有诊断为A病。
因而,误诊率是在临床诊断中对某种疾病在一定的观察期间对一定数量的诊断例数发生错误诊断的频数,用下式表示:
而漏诊率是表示在临床诊断中对某一种疾病在一定观察期内对一定数量的诊断例数发生遗漏诊断的频度,用下式表示:
如论文《原发性肝癌误诊原因分析(附150例报告)》一文中,作者共收治肝癌161例,入院前外院误诊2个月以上1500例,误诊率为93.17%,其中41例入院时依然未考虑本病误诊率为25.47%。
仔细分析,就可发现文题中的“误诊”实际上应为“漏诊”,入院前及入院时的误诊率应为漏诊率。
实际运用中,较多的是把“漏诊”当“误诊”。
因此,我们在表述误诊这一概念时,应当把“误诊”与“某病”联系起来描述才正确,即“误诊为某病”。
出现这类错误的原因是对这些概念似是而非,没有用科学的态度仔细研究。
2概念缺失
统计工作一般分为收集资料、整理资料和分析资料三个步骤,在每一个步骤中均应运用科学的方法才能完整、准确、有效地对资料加以归纳和总结。
如果没有系统的统计学知识,对某些相关的统计学概念不熟悉、不了解,就谈不上正确地去应用这些知识。
如实验设计需要遵循对照、随机和均衡的原则,常有作者的论文中不设对照组,有的设了对照组,但组内观察对象却不同质,无可比性。
实验分组时受试对象不是统计学上的随机,而是随意和随便分组,这样统计学处理的结果是不能令人信服的。
统计学概念的缺失也常造成计算错误,有作者在计算观念单位不等的几个率的平均率时,将几个率直接相加求平均率,而不是将各观察单位的事件之和除以观察的各人群数之和。
3概念的内涵与外延不明确
概念包括内涵和外延两个方面。
内涵是概念的本质属性,外延是概念的限定范围。
如果对统计学概念的内涵与外延不清,就不能正确地处理统计资料。
所得的结果或没有意义,或达不到预期的效果,或丢失原资料中所蕴藏的信息,甚至会作出违背客观事实的判断。
如有作者用平均数±标准差描述两组病人的腹水丢失量,分别为1765±2001ml,2740±3044ml,经t 检验,两组间无显著性差异。
观察这两组资料,可见平均数均小于标准差,说明其资料是偏态分布而不是正态分布。
我们知道,算术平均数与中位数都是用来描述一组同质计量资料的集中趋势:前者的特征是,它代表一组观察值的平均值,适用于对称分布,尤其是正态分布的资料。
而后者的特征是,在一组按大小顺序排列的观察值中,位次居中的数值即为中位数适用于资料分布不清或明显呈偏态分布的资料。
在这里,这两个概念的特征即为其内涵,适用范围则为其外延。
如果明确了这两个概念的内涵与外延,就会选用中位数而不是算术平均数来描述这两组资料。
本组资料经中位数检验,两组腹水丢失量有显著性差别。
4医学文稿中常见统计学概念误用引起的思考
笔者只是对医学论文中常见统计学概念方面的误用情况做了简单的分析和总结,限于篇幅,不能详细概括出问题的全部。
但有一点是很明确的,即作者只有提高认识,才能在医学研究中自觉地运用统计学原理进行医学资料的科学收集、整理和分析。
客观地说,除预防医学研究运用的方法相对复杂一些外,基础医学及临床医学研究中常用的一些方法还是比较简单,易于理解的。
因此,一些从事医学研究时间不长的年青学者以及以前较少接触统计学的年长研究者,应下功夫打好统计学基础,掌握统计学的基本概念。
另一方面,医学编辑在编审过程中也应严格把关,尽量减少统计处理方面的疏漏,以免因不正确的结论对读者产生误导。