医学杂志论文中常见的统计学错误分析及对策
- 格式:ppt
- 大小:1.61 MB
- 文档页数:39

医学论文常见统计学错误与纠正一、设计与实施1.对象合格标准不明确●只报告来源和时间段,总体不清晰:大杂烩,得不到科学结论;●事前未规定合格标准和排除标准,事后排除;●不报告按照合格标准和排除标准筛选对象的过程。
2.结局指标多而杂--是事先规定的最重要的结局指标,通常以此为准来计算样本量。
常见错误:终点指标过多, 大海捞针临床试验时,不知道哪个指标在组与组间有差异;“确定某个指标后,万一组间没有差异,岂不被动?!”生理、生化、组织学、基因,都做;“内容丰富,显得水平高?!”许多仪器一下子可以做许多项目;“许多项目一一分析,哪个有意义,就报告哪个指标?!”哪些指标可能有组间差异,必须心中有数。
假说:预计将要得到的结论——假说是科研的灵魂心中无数,不要“先上马再说”●指标多,实验工作量大。
大海捞针——碰运气,不是科研!●指标多,翻来覆去分析,制造假阳性!Nature杂志统计学指南:➢常见错误之一。
仅分析1个指标时,P(假阳性)=0.05,P(1次分析不犯错误)=0.95 λ,同时分析2个指标时,P(2次分析均不犯错误) = [P(1 次分析不犯错误)] 2 P(假阳性)=1 - 0.952 ≈ 0.10, 同时分析3 个指标时,P(假阳性)=1 - 0.953 ≈ 0.14 λ同时分析10个指标时,P(假阳性)=1 - 0.9510 ≈ 0. 40➢常见错误之一(Nature) ----多重比较不校正多重比较: 对一组数据作多项比较时,必须说明如何校正α水平,以避免增大第一类错误的机会---- Bonfferoni校正(α/k来校正,k为两两比较次数)3 不重视对照为何必需对照?●消除非研究因素的混杂实验组和对照组受非研究因素的影响尽可能相同,使两组的差异主要反映研究因素的效应。
●鉴别研究因素的效应和自然发展结果。
例如,研究某药物对口腔溃疡模型兔的疗效,口腔溃疡有自愈的倾向,必须有对照扣除自愈效应。
常见错误➢没有对照!千方百计省去对照组,以减少一半工作量!? ω自身前后对照/历史对照/文献对照/ “标准”对照➢对照不当ω对照太弱:安慰剂对照/对照过强:西药+加中药~西药/对照剂量有争议:试验药,大剂量~对照药,中小剂量/对照基线不可比:试验组年轻、病轻~ 对照组年老、病重应当如何?ω事先明确研究假说,例如,新药比常规药好:以常规药为对照ω设计:研究组新药~ 对照组常规药可比性:基线可比、过程可比、终点可比ω保证可比性措施:干预性研究: 随机化观察性研究:匹配4样本量无根据ω干预性研究:“ 500 例患者随机分成两组……” 为什麽500 例?不多不少?500 例从天而降?现成送上门来?ω观察性研究:“ 10年期间A组3000例,B组258例……” ---- 有多少用多少!?应当如何?---- 报告最小样本量估算及其依据1. 比较两组测定值的均数依据:(1)预计欲比较的两总体参数的差值δ(2)预计总体标准差σ(3)允许出现假阳性结果的机会α(4)允许出现假阴性结果的机会β :例:格列美脲、格列苯脲对比研究以HbA1c 为主要终点报告依据✓欲检出HbA1c临床差异≥0.65%✓假定标准差为1.3%✓双侧检验水平0.05✓功效80% ω✓退出率20% 计算:157例2. 比较两组达标率依据:(1)预计一组发生某结局的百分比为π1(2)预计另一组发生某结局的百分比为α(3)允许犯假阳性错误的机会β(4)允许犯假阴性错误的机会π2例:格列美脲、格列苯脲对比研究以HbA1c达标为主要终点(1)预计一组发生某结局的百分比为45%(2)预计另一组发生某结局的百分比为25%(3)允许犯假阳性错误的机会α= 5%(4)允许犯假阴性错误的机会β= 20% 计算: 176 例5. 随机化,说而不做,做而不严处理分配的随机化为什么这么重要?(1) 消除分配处理有意或无意的偏倚。
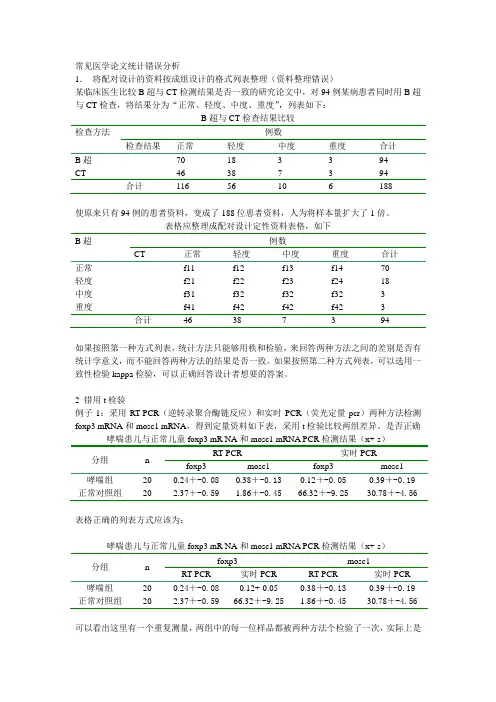
常见医学论文统计错误分析1.将配对设计的资料按成组设计的格式列表整理(资料整理错误)某临床医生比较B超与CT检测结果是否一致的研究论文中,对94例某病患者同时用B超与CT检查,将结果分为“正常、轻度、中度、重度”,列表如下:B超与CT检查结果比较检查方法例数检查结果正常轻度中度重度合计B超70 18 3 3 94CT 46 38 7 3 94 合计116 56 10 6 188使原来只有94例的患者资料,变成了188位患者资料,人为将样本量扩大了1倍。
表格应整理成配对设计定性资料表格,如下B超例数CT 正常轻度中度重度合计正常f11 f12 f13 f14 70轻度f21 f22 f23 f24 18中度f31 f32 f32 f32 3重度f41 f42 f42 f42 3如果按照第一种方式列表,统计方法只能够用秩和检验,来回答两种方法之间的差别是否有统计学意义,而不能回答两种方法的结果是否一致。
如果按照第二种方式列表,可以选用一致性检验kappa检验,可以正确回答设计者想要的答案。
2 错用t检验例子1:采用RT-PCR(逆转录聚合酶链反应)和实时PCR(荧光定量pcr)两种方法检测foxp3 mRNA和mosc1 mRNA,得到定量资料如下表,采用t检验比较两组差异。
是否正确哮喘患儿与正常儿童foxp3 mR NA和mosc1 mRNA PCR检测结果(x+-s)分组nRT-PCR 实时PCRfoxp3 mosc1 foxp3 mosc1哮喘组正常对照组20200.24+-0.082.37+-0.590.38+-0.131.86+-0.450.12+-0.0566.32+-9.250.39+-0.1930.78+-4.56表格正确的列表方式应该为:哮喘患儿与正常儿童foxp3 mR NA和mosc1 mRNA PCR检测结果(x+-s)分组nfoxp3 mosc1RT-PCR 实时PCR RT-PCR 实时PCR哮喘组正常对照组20200.24+-0.082.37+-0.590.12+-0.0566.32+-9.250.38+-0.131.86+-0.450.39+-0.1930.78+-4.56可以看出这里有一个重复测量,两组中的每一位样品都被两种方法个检验了一次,实际上是一个具有重复测量的两因素设计,应该用重复测量的两因素设计定量资料方差分析。

(精品收藏)医学论文中常见统计学概念误用分析医学统计学作为一种认识医学现象数量特征的重要工具,在医学研究的过程中起着非常重大的作用。
但国内外研究者通过调查发现,在现代医学期刊中,统计方法的运用及表述却存在着较多的问题[1,2]。
笔者在医学论文的编辑过程中,也发现有些作者对统计学中最常见、最基本的概念常混淆不清,因此其论文很难符合刊用的要求。
我们知道,概念是逻辑思维的基本要素,只有概念明确,才能准确地表达思想,才能对事物的本质进行客观的描述,才能作出正确的判断和推理,从而得出科学的结论。
为与作者共同提高论文质量,现对编辑工作中经常碰到的一些概念方面的误用问题,试图进行一些粗略的分析。
1概念混淆1.1以比代率比与率是临床医学研究中最常用的相对数指标。
比是表示某一事物或现象各组成部分之间或各个部分在全体中所占的比重或分布。
较常用的有构成比、相对比等。
而率是指某种现象或事件在一定条件下,其实际发生数与可能发生此现象或事件总数的比例。
临床医学论文中很多作者常把构成比当作率进行比较,造成对疾病的发生作出错误估计。
如在研究性别与其疾病发病率的关系文章中,作者把男女的构成比当作发病率,从而得出某种性别的发病率高的错误结论。
还有作者由于对构成比与率的概念不明确,造成计算错误。
如某农村卫生单位对7250名少儿进行粪检,检出蛔虫卵者4300人,需要进行治疗。
因各种原因,有900人未行治疗。
结果:已治率为79.07%,未治率为20.93%。
很明显,这是典型的以构成比代率的例子。
我们根据定义,可计算如下:出现这种错误的原因,是因为不能正确理解比与率的区别所致。
一般来说,率的分子源于分母,但分子、分母具有不同的事件属性,构成比虽然分子也源于分母,但分子、分母具有相同的事件属性。
1.2不同率混用在临床医学研究中,一些具有特殊性质的率很容易用错。
最常见的有发病率与患病率,死亡率与病死率。
发病率与患病率相混淆的原因主要是没有把握住观察、统计的时间。

医学科技论文常见统计学问题分析摘要:针对医学科技论文中常见统计学问题以及稿件退修和编辑加工过程中遇到的共性的统计学问题进行分析,并提出可能避免统计学方面错误的方法及建议,便于科研人员撰写论文时学习借鉴,也为医学期刊编辑处理类似稿件提供参考。
关键词:统计学;医学;科研;论文;问题1描述性分析时存在的统计学问题2统计分析方法不满足假设条件2.1不满足参数检验的数据采用了参数检验方法2.2不满足卡方检验条件的数据采用了卡方检验2.3不满足线性回归条件的数据采用了线性回归分析线性回归模型的前提条件包括线性、独立性、正态性和方差齐性。
其中,线性是指因变量的总体平均值与自变量呈线性关系。
可以通过绘制散点图判断回归关系是否成立[11]。
独立性是指任意2条记录互相独立。
正态性是指模型的误差项需服从正态分布(等价于当自变量某为定值时因变量Y也呈正态分布),而在样本量较大时可以忽略正态性要求。
方差齐性是指在自变量某的取值范围内,不论某取什么值,Y都具有相同的方差,等价于残差的方差齐性。
需要注意的是,线性、正态性和方差齐性通常通过绘制散点图或正态概率图等即可快速判断,但独立性往往容易被研究人员忽视,即纳入分析的研究对象不应有多条记录,如果有部分研究对象有多条记录,则应只保留一条记录,否则不能采用线性回归模型进行分析,只能改用混合效应模型进行分析。
同时,还需注意,如果是多因素回归分析,则上述线性、正态性和方差齐性的条件应在各变量和因变量之间均得以满足。
3结果阐释时存在的问题3.1受制于P值,未按常用界值对数据进行划分在进行多元回归分析之前,比较可取的是先进行单因素回归分析。
如某单因素为连续型变量,且已知其为结局变量的危险因素可能性较大,若将其直接纳入模型进行单因素回归分析,则可能发现其回归系数β无统计学意义(P>0.05),这时某些研究者可能会采用将连续型变量分类的方式以获得较好结果,可能为得到较小的P值而未采用常用的有意义界值进行划分,如在研究血压对某种慢性病的影响时,未按照临床定义的高血压界定值对血压值进行分类,而是以在数据分析时获得最小P值为目标取最佳截断值进行分析,这种方法会使结果产生较大偏倚。




医学论文中常用统计分析方法错误大全在医学研究领域,准确合理地运用统计分析方法对于得出可靠的研究结论至关重要。
然而,在实际的医学论文中,却存在着各种各样的统计分析方法错误,这些错误可能会导致研究结果的偏差,甚至得出错误的结论。
下面,我们就来详细探讨一下医学论文中常见的统计分析方法错误。
一、数据类型判断错误数据类型的正确判断是选择合适统计分析方法的基础。
医学研究中常见的数据类型包括计量资料、计数资料和等级资料。
然而,很多研究者在数据类型判断上出现失误。
例如,将原本应该是计数资料的数据(如疾病的治愈、好转、无效等)当成计量资料进行分析,错误地使用了均值和标准差等统计指标,而应该使用频率和百分比等指标,并采用卡方检验等方法。
二、样本量计算不合理样本量的大小直接影响到研究结果的可靠性和准确性。
一些医学论文在研究设计阶段没有充分考虑样本量的计算,导致样本量过小或过大。
样本量过小,可能会使研究结果缺乏统计学意义,无法检测出真实存在的差异;样本量过大,则会造成资源的浪费,同时增加研究的难度和成本。
正确的样本量计算应该综合考虑研究的设计类型、预期效应大小、检验水准和检验效能等因素。
三、选择错误的统计方法这是医学论文中常见的错误之一。
例如,对于两组独立样本的均数比较,应该使用 t 检验,但如果两组数据的方差不齐,就需要使用校正的 t 检验或者非参数检验方法(如 Wilcoxon 秩和检验)。
然而,很多研究者在这种情况下仍然使用了普通的 t 检验,导致结果不准确。
再比如,对于多组均数的比较,如果方差分析结果有统计学意义,还需要进一步进行多重比较。
但有些研究在这一步没有进行恰当的多重比较方法选择,导致结论不够准确。
四、忽视数据的正态性检验在进行某些统计分析(如 t 检验、方差分析等)时,要求数据服从正态分布。
然而,很多研究者在使用这些方法之前,没有对数据进行正态性检验。
如果数据不服从正态分布,却仍然使用基于正态分布假设的统计方法,就会得出错误的结论。

医学论文撰写中常见的统计学问题及其处理绝大多数的论文撰写,均需通过一定数量临床病例(或资料)的观察,研究事物间的相互关系,以探讨客观存在的新规律。
如确定新诊断、新治疗等措施是否优于原沿用的方法,就需进行两种方法比较,这就涉及统计处理;统计设计又是整个课题研究设计中一个重要的组成部分。
显然,经正确统计处理的结果可信度高,论文的质量也高。
据不完全统计,在难以发表的、巳凝聚着作者心血并花费较长时间与较大财力撰写的研究论文中,约半数以上是由于统计错误致其结果与原文主要结论相违背。
如一文采用某新药引产,96例足月孕妇的产后出血与新生儿低Apgar评分率均为2.1%(各2例),明显低于应用原药引产的19例,其产后出血与新生儿低Apgar评分发生率均为15.8%(各3例,x2=7.164, P?.001)。
故认为采用新药引产是一更安全的措施。
原药引产组例数偏少暂且不谈,该资料比较应采用精确法分析,结果是与原结果恰恰相反(P>0.05),这样上述的主要结论就欠可靠而难以发表,否则论文可起误导作用。
类似问题文稿中还常有出现。
现就文稿中常见的统计问题及其相应的处理方法简述如下。
一、常用的统计术语统计学中常用的概念有总体与样本、随机化与概率、计量与计数、等级资料及正态与偏态分布资料、标准差与标准误等。
如某研究采用经会阴途径测定宫颈长度,以探讨不同宫颈长度与临产时间的关系。
结果显示35例宫颈长度为25〜34 mm者与32例宫颈长为15〜24 mm者临产时间的均值士标准差(士s)各为57.6±58.1与47.3±49.1小时。
该计量资料,经t检验显示t=0.780, P>0.05,并未提示不同宫颈长度的临产时间差异有显著意义;从标准差大于均值,显示各变量值离散程度大,呈偏态分布,故不能采用士,这一算术均数法计算均数。
经偏态转换成近似正态分布资料后结果是:35例与32例的临产时间各为34.5±4.1 与26.7±4.1小时,(t=7.778, P?.001),两组差异有极显著意义。

![[精华版]医学论文中统计学处理常见问题及应对措施](https://uimg.taocdn.com/ea089cb50129bd64783e0912a216147917117ea3.webp)
医学论文中统计学处理常见问题及应对措施1存在问题1)统计软件名称和版本不全。
最常见的问题是作者只写统计软件名称而漏掉了统计软件版本。
2)统计数据描述含糊不清。
如笼统说“用-x±s 表示”,而不分定量资料或定性资料。
3)误用统计学方法并且统计方法描述不详细。
例如:对定量资料盲目套用t检验,多组均数比较没有采用方差分析和q检验;对定性资料,盲目套用χ2检验;非参数检验资料没有采用秩和检验或Ridit检验; 对回归分析没有结合专业知识和散点图选用合适的回归类型,而盲目套用简单直线回归分析;在逻辑上无明显相关的2个或2个以上指标检测结果勉强进行相关性分析等;对随访资料没有使用生存分析等。
另一个问题是统计学方法的描述不详细。
例如: 使用t检验,没有说明是完全随机设计资料的t检验, 还是配对设计资料的t检验;使用方差分析时,没有说明是完全随机设计资料的方差分析,还是随机区组设计资料的方差分析,或是巢式设计资料的方差分析;对于四格表资料,没有交代是一般四格表资料χ2检验, 还是四格表资料的校正的χ2检验。
4)假设检验结果的表达和解释中存在的问题。
假设检验的结果表达没有根据不同的统计分析方法, 给出相应的检验统计量的实际值及相应的值,如t检验的t值、方差分析的F值、卡方检验的χ2值、相关分析的相关系数及相应的r值等。
此外,统计结果的解释存在如下问题:假设检验是在“无效假设”正确(比如2种药物的疗效没有差异) 的前提下,用P值大小说明实际观察结果是否符合“无效假设”。
P值小(如P<0·05或P<0. 01)则怀疑“无效假设”的正确性,应得2种药物疗效的差异有统计学意义或差异有高度统计学意义的结论,而不应得差异显著或差异非常显著的结论;P值大(如P> 0·05),则不能拒绝“无效假设”,应得2种药物疗效的差异无统计学意义的结论,而不应得无差异的结论。
这是典型地把统计结论作为专业结论而犯的错误。
医学论文中常用统计分析方法错误大全在医学研究领域,准确和恰当的统计分析是得出可靠结论的关键。
然而,在众多医学论文中,却存在着各种各样的统计分析方法错误,这些错误可能会导致研究结果的偏差甚至错误解读,从而影响医学研究的质量和临床实践的指导价值。
接下来,我们就来详细探讨一下医学论文中常见的统计分析方法错误。
一、样本量计算错误样本量的合理计算对于研究的可靠性和有效性至关重要。
许多研究在设计阶段未能充分考虑研究的主要目的、预期效应大小、检验效能以及显著性水平等因素,导致样本量过小或过大。
样本量过小可能使研究无法检测到真实存在的差异,从而得出假阴性结论;样本量过大则会造成资源浪费,同时可能增加研究的复杂性和误差。
例如,在一项比较新药物与传统药物疗效的临床试验中,如果预期的疗效差异较小,而研究者没有充分考虑这一点,计算出的样本量不足,那么即使新药物实际上更有效,也可能由于样本量的限制而无法得出有统计学意义的结果。
二、数据类型错误医学研究中数据类型多样,包括计量资料(如身高、体重、血压等)、计数资料(如疾病的发生例数、治愈例数等)和等级资料(如疾病的严重程度分为轻、中、重)。
错误地判断数据类型会导致选择错误的统计分析方法。
例如,将原本属于计数资料的数据(如疾病的治愈与未治愈),错误地当作计量资料进行 t 检验,这样得出的结果是不准确的。
反之,将计量资料当作计数资料处理,也会造成同样的问题。
三、选择错误的统计检验方法不同的研究问题和数据类型需要相应的统计检验方法。
常见的错误包括:在多个组间比较时,错误地使用 t 检验而不是方差分析;在非正态分布的数据中使用参数检验方法;在不符合独立性假设的情况下使用独立样本检验等。
比如,在比较三种不同治疗方法对患者生存率的影响时,应该使用方差分析或非参数的KruskalWallis 检验,而不是多次进行两两t 检验,因为这样会增加一类错误(即假阳性)的概率。
四、忽视方差齐性检验在进行 t 检验和方差分析时,通常需要先进行方差齐性检验。
医学论文常见统计学错误及期刊编辑应对策略分析总之,期刊学术影响力是一个动态过程,在不同的年限其变化趋势或规律可能不同。
在2003-2008年肝病期刊的学术影响力较高,高于CJCR期刊与医药卫生期刊,但仍存在基金论文比低、国际化程度低、发展不平衡等问题;其中(WJG》、《世界华人消化杂志》、《中华肝脏病杂志》的学术影响力居领先地位,但《世界华人消化杂志》的波动较大。
学术影响力变化趋势有5种,其中震荡上升是主要的。
医学论文常见统计学错误及期刊编辑应对策略分析罗明媚叶萍高岩医药150076摘要将近年来医学期刊论文中常见的统计学问题分为统计学方法的误用、不注明统计方法或统计量、不注明所应用的统计分析软件、统计表格的不规使用、率和比混淆等多个方面,并结合实例进行分析,指出目前医学期刊论文的统计学应用现状不容乐观。
从医学期刊编辑的角度提出编审在今后工作中的应对策略和努力方向。
医学统计学应用是医学科学研究中必需的手段,是医学论文中不可缺少的重要组成部分。
胡良平等认为,一篇医学论文的质量主要取决于专业、文字和统计学三个方面,但近年来医学期刊发表的论文中存在大量统计方法误用、统计描述不准确等现象,直接影响着科研结果的科学性和可靠性。
现对我国医学期刊刊载论文中存在的统计学问题进行简要分析,并谈谈为避免这些统计学错误的出现,医学科技期刊编辑在今后工作中的努力方向。
1医学论文中常见的统计学问题1.1统计学方法的误用医学统计中常用的统计学推论方法有很多种,主要是根据实验的数据类型和实验目的来确定使用哪种统计方法。
如,计量资料应用啦验或方差分析,计数资料则应选用x谶秩和检验,这对于医学科研工作者是最为基本的统计学知识。
1.1.1用槛验代替方差分析:处理因素不同,多个处理组均数比较采用凇验代替方差分析,使假阳性的概率增加,又使其检验效率减小,这是最为常见的统计学方法的误用。
如某刊201lt〕Z第8期一文中,将90ff0需剖宫产产妇随机分为A、B、C---组,观察不同剂量盐酸罗哌卡因对麻醉效果的影响,进行三组患者痛觉阻滞最高平面比较。
医学杂志论文中常见的统计学错误分析及对策随着医学科研的发展,统计学在医学杂志论文中扮演着重要的角色。
但是,由于研究者对统计学方法的理解不足或应用不当,常常会出现一些统计学错误。
本文将分析常见的统计学错误,并提出相应的对策,以帮助研究者提高论文质量。
2.样本量不足:样本量的大小对于统计结果的可靠性和代表性至关重要。
样本量不足可能导致结果不具有统计学意义。
因此,研究者在进行实验设计时,应该根据研究目的和预期效应大小,通过统计学方法计算出所需的最小样本量,并确保实际样本量达到或超过计算的结果。
3.忽略数据分布的假设:一些统计学方法要求数据满足特定的分布假设,例如正态分布。
然而,研究者在应用统计方法时往往忽略了这个前提条件,并未对数据的分布进行充分检验。
为了避免这个问题,研究者应该在应用统计方法之前,使用合适的统计检验或图表来检验数据是否符合假设的分布。
4. 未进行多重比较校正:当进行多组比较时,如果未进行多重比较校正,可能会导致假阳性结果的出现,即错误地认为存在差异或关联。
为了避免这种错误,研究者应该在进行多重比较时采用适当的校正方法,例如Bonferroni校正或Benjamini-Hochberg过程。
5.缺乏效应大小的解释:纯粹依靠显著性检验结果来判断研究结果的重要性是不足够的。
研究者应该解释效应的大小,例如使用点估计和置信区间来表示效应的大小范围,并进行实际意义和临床可应用性的讨论。
6.忽略混杂因素的校正:在观察性研究中,混杂因素可能会影响到统计分析的结果。
如果在统计分析中未对混杂因素进行校正,可能会引入偏差。
因此,研究者应该在进行统计分析之前,充分考虑可能的混杂因素,并使用适当的统计方法进行校正。
7.未进行复杂数据分析:对于复杂数据结构,例如多层次数据(例如医生-病人数据)或长期纵向数据,简单的统计方法可能无法提供准确的结果。
研究者应该使用适当的复杂数据分析方法,例如多层次回归分析或混合效应模型,以更好地处理这种类型的数据。
------------------------------------------ 最新资料推荐------------------------------------ 医学科研论文中的统计学问题汇总分析医学科研论文中的统计学问题汇总分析作者:郑华宾ARS医学统计学是一门帮助人们透过偶然现象,分析和判断事物内在规律的科学。
随着医学科研工作的深入,医学统计学的应用越来越广泛。
由于统计学的内容非常丰富,并且仍在不断发展,而医务工作者常因各种原因不愿花费许多精力钻研统计学知识,故医学论文中误用统计学的现象较为严重。
为了减少这一现象,提高论文的水平,现就论文中常见的统计学错误,分析讨论如下。
1 .文中未交待所用统计方法论文中应将所用的统计方法交待清楚,例如,是配对设计的t检验还是成组设计的t检验,是Ridit 分析还是卡方检验,是作相关分析还是作回归推断。
使用不正确的统计方法会得出错误的结论,所以统计方法交待不清或根本不予交待,会使读者对论文结论的正确与否无法判断。
有的作者只提一句经统计学处理后,就写出结论;有的甚至于直接用P值说明问题了事。
正确的做法应写明具体的统计方法,如有特殊情况,还应说明是否采用了校正,这样才有说服力。
严格地说,应写明精确的统计量值和P值,如t值、F值、2 值等,不应笼统地以P0.05或P0.05代替。
此外,最好能交待所使用的计算工具与统计软件名称。
因采用公认的统计软件(如SAS、SPSS等)或程序型计算器进行计算,与手工计算相比,既准确又快捷,其计算结果易于被人接受。
2.使用统计方法时不考虑其应用条件每一种统计方法都有其适用条件。
在表示数值变量资料(计量资料)的平均水平时常用到平均数。
然而平均数有算术平均数(均数)、几何均数和中位数,各有其应用条件。
应用均数时,必须首先确定数据为正态分布。
如果数据是偏态分布,仍用均数表示其平均水平势必导致错误的结论,不少作者没有注意到这一点。
医学论文中常见统计学错误案例分析一、概述在医学研究领域,统计学方法的应用至关重要,它有助于科研人员对复杂数据进行深入的分析与解读,从而得出科学的结论。
由于统计学知识的复杂性和多样性,医学论文中常常会出现各种统计学错误。
这些错误不仅可能影响研究结果的准确性和可靠性,还可能误导读者对研究的理解和评价。
本文旨在通过分析医学论文中常见的统计学错误案例,揭示其产生原因和可能带来的后果,以提高医学科研人员和论文作者在统计学应用方面的准确性和规范性。
常见的医学论文统计学错误包括但不限于样本量计算不当、数据分布误判、统计方法选择错误、假设检验理解偏差、多重共线性问题以及P值解读不当等。
这些错误往往源于对统计学基本概念和方法理解不深入,或是忽视了对数据特征和实际研究问题的综合考量。
通过案例分析,我们可以更直观地了解这些错误在实际研究中的表现形式和潜在影响。
每个案例都将详细剖析错误发生的具体原因,并指出正确的处理方法或避免策略。
这将有助于医学科研人员和论文作者在今后的研究中更加谨慎地应用统计学方法,提高研究质量和学术水平。
本文还将强调加强统计学知识和技能的培训在医学科研中的重要性。
只有具备扎实的统计学基础,才能更好地理解和运用各种统计方法,避免或减少统计学错误的发生。
医学科研人员和论文作者应不断学习和更新统计学知识,提高自己在统计学应用方面的能力和素养。
1. 医学论文中统计学的重要性在医学研究中,统计学扮演着至关重要的角色。
它是确保研究设计合理性、数据收集和分析准确性以及结论可靠性的基石。
通过运用统计学方法,医学研究人员能够系统地评估治疗方法的疗效、疾病的发病机制和预后因素,从而为临床实践和政策制定提供科学依据。
统计学在医学论文中有助于确保研究的内部和外部有效性。
通过运用适当的统计学方法,研究人员可以控制潜在的混杂变量和偏倚,从而提高研究的准确性和可靠性。
这有助于避免由于研究设计不当或数据分析错误而导致的误导性结论。