离散趋势测量法
- 格式:pdf
- 大小:1.39 MB
- 文档页数:14

社会研究的统计应用 李沛良第二篇 统计叙述:单变项与双变项 2~3 简化一个、两个变项之分布1.关于数值中小数的取舍问题。
“四舍五入”之“四舍”没有问题,同时结合“前单五入”,即“五”前面是单数就进位,若是双数则舍掉(0算双数)。
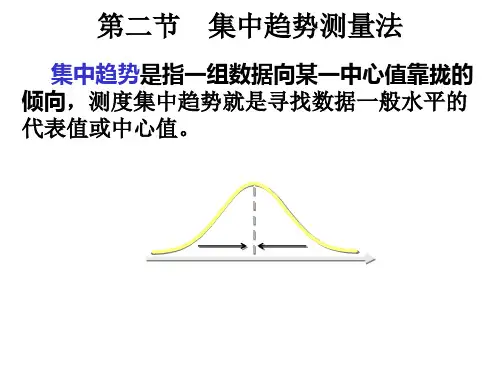
2.所谓集中趋势测量法,就是找出一个数值来代表变项的分布,以反映资料的集结情况。
此法的意义在于,可以根据这个代表值(或称典型值)来估计或预测每个研究对象(即个案)的数值。
这样的估计或预测,当然会有错误,但由于所根据的数值最有代表性,故所发生之错误的总和理应是最小的。
众值 (Mo ):次数最多的值。
中位值(Md ):在一个序列的中央位置之值。
均值 ():变项的各个数值之和,求取一个平均数。
3.离散趋势测量法,是要求出一个值来表示个案与个案之间的差异情况。
该法与集中趋势测量法具有互相补充的作用。
集中趋势测量法所求出的是一个最能代表变项所有资料的值,但其代表性的高度却要视乎各个个案之间的差异情况。
如果个案之间的差异很大,则众值、中位值、均值的代表性就会甚低;此时以这三个值作估计或预测,所犯的错误就会很大。
离异比率(V ):非众值的次数与全部个案数目的比率。
质异指数(IQV ):其作用是求出各个类别之间在理论上最多的可能差异中实际上出现了多少差异。
(k=变项的类别数目,f=每个类别的实际次数)四分位差(Q ):将个案由低至高排列后分为四个等分,第一个四分位置的值Q1与第三个四分位置的值Q3的差异。
标准差(S ):将各数值(x )与其均值()之差的平方和除以全部个案数目,然后取其平方根。
公式中x 与相差,就是表示以均值作为代表值时会引起的偏差或错误。
总之,集中趋势测量法与离散趋势测量法并用,可以一方面知道资料的代表值,有助于估计或预测的工作,另一方面可以知道资料的差异情况,反映估计或预测时会犯的错误。
正态分布与标准值? 简化两个变项之分布 统计相关交互分类与百分表简化相关与消减误差相关测量与假设检定相关测量法,目的是要理解两个变项在“样本”(随机与非随机样本均可)中的相关“强弱”程度及方向。

1·社会学研究:就是运用科学的方法来搜集和分析社会事实,以理解社会现象之间的关系。
2·科学研究:就是运用客观的、逻辑的和系统的方法来搜集事实及分析事实。
3·社会学研究的整个历程,大致上可以分为三个阶段:(1)筹划,(2)执行,(3)总结。
4·初步探索步骤:(1)收集有关的文献,(2)咨询那些对研究的题目有经验、有知识的人,进行了解,(3)观察个案。
5·假设:就是根据我们对问题的了解,假定现象与现象之间的关系。
就是假定某一现象的变化与另一种现象的变化具有某种关系。
假设的方式:函数式(要求变项之数值有高低之分)、差异式(不存在高低之分)6·较为常用的研究方式:实验法、社会调查法。
(皆可验证假设)①实验法的逻辑:有意的改变A变项,然后看看B变项是否随着变化;如果B变项显然是随着A变项的变化而变化,就说明A变项对B变项有影响。
②社会调查法特点:在研究过程中不改变社会现状,只求就地取材,然后以统计方法推算变项与变项之间的关系。
7·能够有效地验证假设的实验法称为典型或理想实验法8·社会调查法可以分为两大类:一是叙述性调查(重点是报道社会事实,较少分析社会事实(即变项)之间的因果关系),一是解释性调查(目的是要证明不同的变项之间是否有因果关系)。
9·全体调查:就是从所有研究对象中搜集资料。
抽样调查:就是从全体的研究对象中科学的抽出一个数目较少的样本,然后据此样本的资料推论全体的情况。
10·个案研究:就是选择一个或几个个案(即研究对象),作深入的接触和观察,目的是对所研究的问题作深入的了解。
11·横剖研究:指的是在同一时期搜集资料,目的是理解各种社会现象(即变项)在某时期的相关情况的研究。
纵贯研究:是指在不同时期搜集的,目的在了解社会现象(即变项)在不同时期中的变动情况的研究。
12·纵贯研究分为两种:趋势研究、同组研究(指的是在不同时期调查相同的样本)。



社会统计学考试必备公式
学院:人文学院
姓名:李军
学号:2011014737
专业:社会学
班级:社会111
时间:2013年6月20日
社会统计学考试必备公式
第二章单变量统计描述分析
直方图:频次密度=频次/组距(条宽)
相对频次密度(频率密度)=相对频次(频率)/组距(条宽)
频次=频率密度*组距
A、集中趋势测量法
众值:m0
B、离散趋势测量法
极值R:观察的最大值-观察的最小值
四分互差Q=Q75-Q25
第三章概率
一、概率的运算
1.当事件A与事件B互不相容时,
P(A+B)=P(A)+P(B)
2. 当事件A与事件B不满足互不相容时,
P(A+B)=P(A)+P(B)-P(AB)
3.A、B相互独立
P(AB)=P(A)P(B)
4. A、B不相互独立
P(AB)=P(A)P(B/A)或P(B)(A/B)
第五章正态分布
第六章参数估计
第七章假设检验的基本概念
1.统计假设
2.原假设与备择假设
3.假设检验的基本原理
4.双边检验与单边检验
第十四章非参数检验。


第五章离散趋势测量一、单项选择题(在各题的备选答案中,只有1项是正确的,请将正确答案的序号,填写在题中的括号内。
每小题2分,共20分)1. 离散系数的主要目的是( )。
A. 反映一组数据的平均水平B. 比较多组数据的平均水平C. 反映一组数据的离散程度D. 比较多组数据的离散程度2. 两组数据的平均数不相等,但是标准差相等。
那么( )。
A. 平均数小的,离散程度小B. 平均数大的,离散程度大C. 平均数大的,离散程度小D. 两组数据离散程度相同二、名词解释(每题4分,共20分)3. 方差与标准差四、计算题(每题 1 5分,共30分)4.某校社会学专业共有两个班级。
期末考试时, 一班同学社会学理论平均成绩为86分,标准差为12分。
二班同学成绩如下所示。
二班同学社会学理论成绩分组数据表按成绩分组(分) 人数(个)60分以下 260~70 770~80 980~90 790~100 5合计30要求:(1) 计算二班同学考试成绩的均值和标准差。
(2) 比较一班和二班哪个班成绩的离散程度更大? (提示: 使用离散系数)5.甲单位人均月收入4500元, 标准差1200元。
乙单位月收入分布如下所示。
乙单位月收入分布表按收入分组(元) 人数(个)3000 分以下1203000~4000 4204000~5000 5405000~6000 4206000 以上300合计1800要求:(1) 计算乙单位员工月收入的均值和标准差。
(2) 比较甲单位和乙单位哪个单位员工月收入的离散程度更大? (提示: 使用离散系数)答案: 1. C 2. C3. 方差与标准差方差(variance) 是各数值与均值离差平方的平均数,它是数值型数据离散趋势最主要的测量值。
(2分)标准差(standard variance) 是方差的平方根,用于测量数值型数据离散趋势。
(2分)4.(1)均值:kkk f f f X f X f X f X ++++++=212211=(55×2+65×7+75×9+85×7+95×5)÷ 30 = 2310 ÷ 30= 77 (4分)方差:()Nf X Xki ii∑=-=122σ()()()()()30577957778597775777652775522222÷⎥⎥⎦⎤⎢⎢⎣⎡⨯-+⨯-+⨯-+⨯-+⨯-= = 4080 ÷ 30= 136标准差: 6619.111362≈==σσ (4分)(2)一班考试成绩的离散系数为:1395.08612=÷==一班一班一班X S V (3分)二班考试成绩的离散系数为:1515.07766.11=÷==二班二班二班X S V (3分)一班V <二班V ,所以说一班成绩的离散程度小于二班。

到这里,有关单变量的描述统计技术已经全部介绍完了。
简单来说,我们共介绍了三种方法,一是化约、简化,即第三章第一节的内容,次数分布、频率分布、统计图、统计表等。
二是集中趋势测量法,即求出一个数值用以代表变量的资料分布,反映资料的集结情况。
三是离散趋势测量法,即求取一个数值来表示个案与个案之间的差异情况。
集中趋势测量法和离散趋势测量法是相互补充的。
我们再一起回顾一下适用于不同测量层次的集中值和离散值。
它们是这一章需要重点掌握的内容,我们先以表格的形式比较一下三个集中值。
四分位差和标准差。
它们在测量层次、敏感程度、计算难度和解释力上也是与这三个集中值一一对应的。
我们不再一一介绍了。
那么极差仅仅考虑了两个极端值,因而带有很大的偶然性,对于大量的处于极端值之间的数值分布情况,以及在中心点周围的集中情况,都无法提供任何信息,主要适用于定序以上层次的变量。
离散系数是一种相对的离散量数统计量,可以用于对同一总体中两种不同的离散值进行比较,或者对两个不同总体中的同一离散值进行比较,适用于定距以上层次的变量。
第三章简化两个变量的分布第一节统计相关的性质大家知道,在社会学研究中,不仅要求我们对社会现象进行描述,而且要求我们对现象的原因进行分析。
因此,我们不但要了解一个变量的情况,更要进一步了解一个变量与另一个变量之间的关系。
例如,在某地区调查100名青年人的最大志愿,假定其中有40%选择快乐家庭,50%选择理想工作,10%选择增广见闻。
我们要问:为什么这些青年人的最大志愿会有不同?又假定我们发现这些青年人的教育水平可以分为高(高中或以上程度)、中(初中程度)、低(小学或以下程度)三个等级,每级人数分别占10%、60%、30%。
据此,我们就可以追问:青年人的志愿与其教育水平是否有关系呢?换言之,是否因为教育水平不同,所以人生志愿也不同。
一、什么是相关?由此,我们可以引入相关这个概念。
所谓相关,是指一个变量的值与另一个变量的值有连带性。

社会研究的统计应用第一章科学方法与社会研究历程1、定类测量层次定类层次是指变项的值只能把研究对象分类,即只能决定研究对象是同类抑或不同类,具有=与≠的数学特质。
定类层次有两个原则,一是互斥性,即类与类之间要互相排斥,每个研究对象只能归入一类;另一个是无遗性,即所有研究对象均有归属,不可遗漏。
适用于简化一个定类变项资料的方法,有次数分布、比例、比率、图示和对比值等。
2、定序测量层次定序层次是指能确定值的次序,即变项的值能把研究对象排列高低或大小,具有>或<的数学特质。
定序层次包括了定类层次的特质。
3、定距测量层次定距层次是指能够确定值与值之间的距离,即变项之值与值间的距离是可以知道的,因为具有加与减的数学特质。
定距层次包括了定序与定类层次的特质。
4、定比测量层次定比测量层次是最高的测量层次,其数值中的零值是绝对的、固定的,因而除了具备分类、排序以及加减的特质外,还具有×与÷的数学特质。
第二章简化一个变项之分布第一节基本技术一、定类层次1、次数分布(f):变项内每一个值在原资料中出现的次数情况。
2、比例(p):就是将每类的次数(f)除以总数(N)。
3、比率:就是把计算比例时的所用的基数变大,使读者容易领会,如可转化为百分率、千分率、万分率等。
4、对比值:对比值就是将两类数值相除,得到一个比值。
二、定序层次1、累加次数(cf):就是把次数逐级相加起来。
分为两种,一种是向上累加,另一种是向下累加。
其作用是使我们容易知道某值以下或以上之次数总和。
2、累加百分率(c%):就是将各级的百分率逐级相加。
三、定距层次1、组限:就是每组的范围,包括上限和下限。
统计表上所标示的组限不是真实的组限。
真实下限=标示下限-0.5;真实上限=标示上限+0.5。
2、组距:就是每个组的宽度,即组的真实上限与真实下限之差。
3、组中点:就是真实上限与真实下限的平均数。
4、矩形图:以一个矩形的面积(长×宽)表示每组数值之次数或百分率的多少。

统计方法统计学中主要有两大类统计方法:叙述统计法和推论统计法。
它们又各自包含许多统计方法,下面将逐一的进行归纳及总结。
一、叙述统计法:帮助简化资料的方法。
单变项叙述统计法:适用于较低层次的统计方法,也可以适用于较高层次。
适用于简化一个定类变项的方法有:1次数分布法:统计资料的次数,是最基本的方法,第一步的统计工作一般是采用次数分布法来简化资料,但不能用来比较两个不同的样本。
2比例法:将每类次数除以总数,使用此方法需要两个样本的总数变成同一个基数。
3比率法:分析定类层次资料时,也可以计算两数值的对比值。
4对比值法:计算两数值的对比。
分析定类层次资料时,也可以用对比值法。
5图示法:就是用图形来简化资料。
使用较多的有长条图、圆瓣图。
适用于简化定序层次的方法有:1.使用于定类的方法都是用于定序的。
2.累加次数法(简称cf):就是把次数逐级相加,使我们容易知道某值以上或以下次数总和,分为向上累加和向下累加。
3.累加百分率法(简称c%):就是将各级的百分率数值逐级相加。
适用于定距层次的方法有:1.累加次数法和累加百分率法。
2.矩形图:以一个矩形的面积大小来表示每组次数或百分率的的多少,长度和宽度均有意义。
3.多角线图:就是把各个矩形的顶端的中点用直线连结起来,其作用是使各组次数(或百分率)的分布情况更显而易见。
集中趋势测量法:就是找出一个数值来代表变项的资料分布,以反映资料的集结情况。
定类变项取众值;定序变项取中位值:1根据原资料求出中位值;2用分组资料取出中位值;定距变项取均值:1根据原资料求出均值;2用分组资料取出均值。
离散趋势测量法:是要求出一个值来表示个案与个案之间的差异情况,与集中趋势测量法有互相补充的作用。
定类变项取离异比率或质异指数;定序变项取四分位差:1根据原资料求出Q1和Q3的位置;2用分组资料来计算四分位差;定距变项取标准差。
两个变量的简化:表示两个变项的相关度。
1.交互分类法:绘制出由条件次数和边缘次数构成的列联表(条件次数表)和百分表。
简述离散趋势的测度离散趋势是指一组数据在数值上的波动或变异程度。
在统计学中,为了测量离散趋势,常用的测度有极差、方差和标准差。
首先,极差是最简单直观的离散趋势测度。
它表示一组数据中最大值与最小值之间的差异程度。
计算极差的公式为最大值减去最小值。
极差的优点在于简单易懂,但它只考虑了最大和最小值,忽略了其他数据的分布情况,所以极差的测度不够全面准确。
其次,方差是衡量数据离散程度的一种常用测度。
方差是各个数据值与其平均值之差的平方和的平均值。
方差的计算公式为所有数据与平均值之差的平方和除以数据个数。
方差的优点在于考虑了每个数据和平均值之间的差异,能够更全面地反映数据的离散程度。
然而,方差的单位是原数据的单位的平方,不够直观,而且方差对异常值比较敏感。
最后,为了解决方差的问题,引入了标准差作为离散趋势的测度。
标准差是方差的正平方根,计算公式是方差的平方根。
标准差的计算结果与原数据有相同的单位,更具直观性。
标准差的优点在于能够衡量数据的稳定性和离散性。
标准差越小,表示数据越稳定,离散趋势越小;标准差越大,表示数据越离散,离散趋势越大。
但标准差也有一个缺点,就是它只能说明数据的波动范围,不能具体说明波动的方向。
除了以上三种测度,还有其他的离散趋势测度方法,比如变异系数、四分位差等。
变异系数是标准差与平均值之比的绝对值。
它的计算公式是标准差除以平均值再乘以100%。
变异系数可以比较不同数据集之间的离散趋势,因为它消除了量纲单位的影响。
四分位差是指将数据分为四个部分,每个部分包含大约25%的数据量。
四分位差的计算方法是将数据按大小排序,然后计算第三个四分位数与第一个四分位数之差。
四分位差能够反映数据的集中趋势和离散趋势。
总之,离散趋势的测度是为了衡量一组数据在数值上的波动程度。
极差、方差和标准差是最常用的三种测度方法。
它们分别从最大值与最小值之差、数据与平均值之差的平方和以及方差求平方根的角度出发,衡量了数据集的离散程度。
第五章 离散趋势测量法 第二节、全距与四分位差• 一、全距• 1、未分组资料计算公式• 全距又称极差,是一组数据的最大值与最小值之差,用表示。
计算公式为: •• 式中, 、分别表示为一组数据的最大值与最小值。
由于全距是根据一组数据的两个极值表示的,所以全距表明了一组数据数值的变动范围。
越大,表明数值变动的范围越大,即数列中各变量值差异大,反之,越小,表明数值变动的范围越小,即数列中各变量值差异小。
2、分组资料计算公式R=最高组上限 - 最低组下限• R=最高组组中组-最低组组中值 • R=最高组组中组-最低组下限 • R=最高组上限-最低组组中值• 如果资料经过整理,并形成组距分配数列,全距可近似表示为: • R ≈最高组上限值-最低组下限值 3、优缺点:优点:计算简单,易于理解。
缺点:(1)受极端值影响大,遇含开口组的资料时无法计算; (2)数据利用率低,信息丧失严重;(3)受抽样变动影响大(一般大样本的全距会比小样本的全距大)。
二、四分位差(inter-quartile range )上四分位数与下四分位数之差的平均数,称为四分位差,亦称为内距或四分间距。
四分位差的计算方法: Q·D=(Q3-Q1) /2四分位差反映了中间50%数据的离散程度,其数值越小,说明中间的数据越集中;数值越大,说明中间的数据越分散。
此外,由于中位数处于数据的中间位置,因此,四分位差的大小在一定程度上也说明了中位数对一组数据的代表程度。
四分位差主要用于测度顺序数据的离散程度。
当然,对于数值型数据也可以计算四分位差,但不适合于分类数据。
优缺点:主要是避免了全距受极端值影响的缺点,其他优缺点同全距:数据利用率低,信息丧失严重;受抽样变动影响大。
max()min()i i R X X =-max()i X min()i X第三节、平均差•平均差是各变量值与其算术平均数离差绝对值的平均数,用A.D表示。
根据掌握资料的不同,平均差有以下两种计算方法:• 1. 简单平均法•对于未分组资料,采用简单平均法。
第五章 离散趋势测量法 第二节、全距与四分位差• 一、全距• 1、未分组资料计算公式• 全距又称极差,是一组数据的最大值与最小值之差,用表示。
计算公式为:••式中, 、 分别表示为一组数据的最大值与最小值。
由于全距是根据一组数据的两个极值表示的,所以全距表明了一组数据数值的变动范围。
越大,表明数值变动的范围越大,即数列中各变量值差异大,反之,越小,表明数值变动的范围越小,即数列中各变量值差异小。
2、分组资料计算公式R=最高组上限 - 最低组下限• R=最高组组中组-最低组组中值 • R=最高组组中组-最低组下限 • R=最高组上限-最低组组中值• 如果资料经过整理,并形成组距分配数列,全距可近似表示为: • R ≈最高组上限值-最低组下限值 3、优缺点:优点:计算简单,易于理解。
缺点:(1)受极端值影响大,遇含开口组的资料时无法计算; (2)数据利用率低,信息丧失严重;(3)受抽样变动影响大(一般大样本的全距会比小样本的全距大)。
二、四分位差(inter-quartile range )上四分位数与下四分位数之差的平均数,称为四分位差,亦称为内距或四分间距。
四分位差的计算方法: Q·D=(Q3-Q1) /2四分位差反映了中间50%数据的离散程度,其数值越小,说明中间的数据越集中;数值越大,说明中间的数据越分散。
此外,由于中位数处于数据的中间位置,因此,四分位差的大小在一定程度上也说明了中位数对一组数据的代表程度。
四分位差主要用于测度顺序数据的离散程度。
当然,对于数值型数据也可以计算四分位差,但不适合于分类数据。
优缺点:主要是避免了全距受极端值影响的缺点,其他优缺点同全距:数据利用率低,信息丧失严重;受抽样变动影响大。
max()min()i i R X X =-m ax()i X min()i X第三节、平均差•平均差是各变量值与其算术平均数离差绝对值的平均数,用A.D表示。
根据掌握资料的不同,平均差有以下两种计算方法:• 1. 简单平均法•对于未分组资料,采用简单平均法。
其计算公式为:2. 加权平均法在资料分组的情况下,应采用加权平均式第四节、方差和标准差•一、概念要点•方差和标准差同平均差一样,也是根据全部数据计算的,反映每个数据与其算术平均数相比平均相差的数值,因此它能准确地反映出数据的差异程度。
但与平均差不同之处是在计算时的处理方法不同,平均差是取离差的绝对值消除正负号,而方差、标准差是取离差的平方消除正负号,这更便于数学上的处理。
因此,方差、标准差是实际中应用最广泛的离中程度度量值。
由于总体的方差、标准差与样本的方差、标准差在计算上有所区别•1、方差是个变量值与其均值离差平方的平均数,标准差是方差的开方。
• 2、离散程度的测度值之一。
• 3、最常用的测度值。
• 4、反映了数据的分布。
•5、反映了各变量值与均值的平均差异。
•6、根据总体数据计算的,称为总体方差或标准差。
根据样本数据计算的,称为样本方差或标准差二、总体的方差和标准差设总体的方差为,标准差为,对于未分组整理的原始资料,方差和标准差的计算公式分别为(二)样本的方差和标准差样本的方差、标准差与总体的方差、标准差在计算上有所差别。
总体的方差和标准差在对各个离差平方平均时是除以数据个数或总频数,而样本的方差和标准差在对各个离差平方平均时是用样本数据个数或总频数减1去除总离差平方和。
4. 方差的数学性质第五节、标准分相对位置的度量:标准分数有了均值和标准差之后,我们可以计算一组数据中各个数值的标准分数,以测度每个数据在该组数据中的相对位置,并可以用它来判断一组数据是否有离群值。
1、定义。
变量值与其平均数的离差除以标准差后的值,称为标准分数,也称标准化值或Z值标准分数也给出了一组数据中各数值的相对位置。
比如,如果某个数值的标准分数为-2,我们就知道该数值低于均值2倍的标准差。
(4.4.21) 式也就是我们常用的统计标准化公式,在对多个具有不同量纲的变量进行处理时,常常需要对各变量数值进行标准化处理。
实际上,z分数只是将原始数据进行了线性变换,它并没有改变一个数据在该组数据中的位置,也没有改变该组数分布的形状,而只是将该组数据变为均值为0、标准差为1•经验法则表明:当一组数据对称分布时•——约有68.27%的数据在平均数加减1个标准差的范围内•——约有95.45%的数据在平均数加减2个标准差的范围内•——约有99.73%的数据在平均数加减3个标准差的范围内。
•由此可见,一组数据中低于或高于平均数3个标准差以上的数据很少。
因此,在统计上,往往将平均数3个标准差以外的数据称为异常值或离群值•2、标准分的特性•(1)对于给定资料,由于算术平均数和标准差都是确定值,所以z是和X一一对应的变量。
•(2)它没有单位,是一个不受原资料单位影响的相对数,因而也适用于不同单位资料的比较。
•(3)均值和方差不同的正态分布经Z分数标准化后,可以转化为标准正态分布,所以Z又称标准正态变量。
•(4)Z分数的数学特性:•Z分数之和等于0;•Z分数的算术平均数等于0;•Z分数的标准差和方差均为1。
3、标准分的主要作用:标准分数的作用主要在两个方面,一是可以表明原始数据在总体分布中的相对位置,二是可以对不同分布的各原始数据进行比较。
第六节离散系数相对离散程度:离散系数用离差的绝对指标除以平均指标来求离差的相对指标,就可以在计量单位不同或平均水平不一的对象间进行直接比较。
这种由绝对离差与其算术平均数的比值,叫变异系数。
•1、全距系数:全距与算术平均数之比。
•2、平均差系数:平均差与算术平均数之比。
•3、标准差系数(最重要和最常用的变异系数)•(1)标准差与其相应的均值之比•(2)消除了数据水平高低和计量单位的影响•(3)测度了数据的相对离散程度•(4)用于对不同组别数据离散程度的比较离散系数是反映一组数据相对差异程度的指标,是各变异指标与其算术平均数的比值。
离散系数是一个无名数,可以用于比较不同数列的变异程度。
离散系数通常用表示,常用的离散系数有平均差系数和标准差系数,其计算公式分别为:[例3.19] 甲乙两组工人的平均工资分别为138.14元、176元,标准差分别为21.32元、24.67元。
两组工人工资水平离散系数计算如下:【例】某管理局抽查了所属的8家企业,其产品销售数据如表,试比较产品销售额与销售利润的离散程度X 1=536.25(万元) X2=32.5215(万元) S 1=309.19(万元) S 2=23.09(万元 ) V 1=S1/X1=0.577 V2=S2/X2=0.710结论: 计算结果表明,V 1<V 2,说明产品销售额的离散程度小于销售利润的离散程度第七节、异众比率• 非众数组的频数占总频数的比率(variation ratio),称为异众比率,用表示。
• 异众比率的计算公式为:•式中:为变量值的总频数;为众数组的频数•异众比率的作用是衡量众数对一组数据的代表性程度的指标。
•异众比率越大,说明非众数组的频数占总频数的比重就越大,众数的代表性就越差;反之,异众比率越小,众数的代表性就越好。
•异众比率主要用于测度分类数据的离散程度,当然,对于顺序数据也可以计算异众比率[例3.10]一家市场调查公司为研究不同品牌饮料的市场占有率,对随机抽取的一家超市进行了调查。
调查员在某天对50名顾客购买饮料的品牌进行了纪录。
整理得不同品牌饮料的频数分布资料如表4.4.1所示,要求根据资料计算异众比率数据类型和所适用的离散程度测度值第八节偏度和峰度数据分布偏态与峰度的测度指标•偏度是对数据分布在偏移方向和程度所作的进一步描述;峰度是用来对数据分布的扁平程度所做的描述。
•对于偏斜程度的描述用偏态系数,扁平程度的描述用峰度系数。
•集中趋势和离中趋势是数据分布的两个重要特征,但要全面了解数据分布的特点,还需要知道数据分布的形状是否对称、偏斜的程度以及分布的扁平程度等。
偏态和峰度就是对这些分布特征的描述。
一、偏态的度量•(一)由算术平均数与众数之间的关系求偏态系数•任何一个频数分布的算术平均数与众数之间的差异情况,与这个频数分布的形态有固定的关系。
若频数分布是对称的,则算术平均数等于众数;若频数分布为右偏,则算术平均数大于众数;若频数分布为左偏,则算术平均数小于众数。
用其二者的差量除以标准差,即可求得偏态系数,•(二)动差法•动差又称矩,原是物理学上用以表示力与力臂对重心关系的术语,这个关系和统计学中变量与权数对平均数的关系在性质上很类似,所以统计学也用动差来说明频数分布的性质。
•二、峰度的度量•峰度是用来衡量分布的集中程度或分布曲线的尖峭程度的指标。
•当峰度β>0时,表示分布的形状比正态分布更瘦更高,这意味着分布比正态分布更集中在平均数周围,这样的分布称为尖峰分布,如图3.4(a);•β=0时,分布为正态分布;•β<0,表示分布比正态分布更矮更胖,意味着分布比正态分布更分散,这样的分布称为平峰分布如图3.4(b)。
[例3.20] 根据例4.5.1中的数据,计算农民家庭人均收入分布的峰度系数结论:偏态系数为正值,而且数值较大,说明农村居民家庭纯收入的分布为右偏分布,即收入较少的家庭占据多数,而收入较高的家庭则占少数,而且偏斜的程度较大【例】根据表中的计算结果,计算农村居民家庭纯收入分布的峰度系数。
结论:由于=3.4>3,说明我国农村居民家庭纯收入的分布为尖峰分布,说明低收入家庭占有较大的比重。