EVIEWS面板数据分析操作教程之PanelData模型
- 格式:pptx
- 大小:540.96 KB
- 文档页数:38

面板数据模型的分析及Eviews实现一、面板数据和模型概述在经济学研究和实际应用中,我们经常需要同时分析和比较横截面观察值和时间序列观察值结合起来的数据,即:数据集中的变量同时含有横截面和时间序列的信息。
这种数据被称为面板数据(panel data),它与我们以前分析过的纯粹的横截面数据和时间序列数据有着不同的特点。
简单地讲,面板数据因同时含有时间序列数据和截面数据,所以其统计质既带有时间序列的性质,又包含一定的横截面特点。
因而,以往采用的计量模型和估计方法就需要有所调整。
例1 表1中展示的数据就是一个面板数据的例子。
其他类似的例子还有:历次人口普查中有关不同年龄段的受教育状况;同行业不同公司在不同时间节点上的产值等。
这里,不同的年龄段和公司代表不同的截面,而不同时间节点数据反映了数据的时间序列性。
研究和分析面板数据的模型被称为面板数据模型(panel data model)。
它的变量取值都带有时间序列和横截面的两重性。
一般的线性模型只单独处理横截面数据或时间序列数据,而不能同时分析和对比它们。
面板数据模型,相对于一般的线性回归模型,其长处在于它既考虑到了横截面数据存在的共性,又能分析模型中横截面因素的个体特殊效应。
当然,我们也可以将横截面数据简单地堆积起来用回归模型来处理,但这样做就丧失了分析个体特殊效应的机会。
二、一般面板数据模型介绍 符号介绍:ity ——因变量在横截面i 和时间t 上的数值;j it x ——第j 个解释变量在横截面i 和时间t 上的数值;假设:有K 个解释变量,即K j ,,2,1 =;有N 个横截面,即N i ,,2,1 =; 时间指标T t ,,2,1 =。
记第i 个横截面的数据为⎪⎪⎪⎪⎪⎭⎫⎝⎛=iT i i i y y y y21; ⎪⎪⎪⎪⎪⎭⎫⎝⎛=K iT iT iT Ki i i K i i i i x x x x x x x x x X 212221212111;⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=iT i i i μμμμ 21 其中对应的i μ是横截面i 和时间t 时随机误差项。






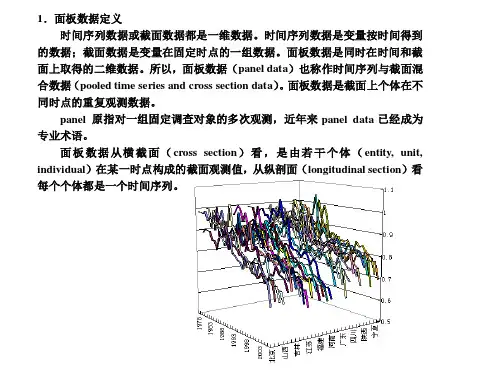


面板数据模型1.面板数据定义。
时间序列数据或截面数据都是一维数据。
例如时间序列数据是变量按时间得到的数据;截面数据是变量在截面空间上的数据。
面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。
面板数据是同时在时间和截面空间上取得的二维数据。
面板数据示意图见图1。
面板数据从横截面(cross section)上看,是由若干个体(entity, unit, individual)在某一时刻构成的截面观测值,从纵剖面(longitudinal section)上看是一个时间序列。
面板数据用双下标变量表示。
例如y i t, i = 1, 2, …, N; t = 1, 2, …, TN表示面板数据中含有N个个体。
T表示时间序列的最大长度。
若固定t不变,y i ., ( i = 1, 2, …, N)是横截面上的N个随机变量;若固定i不变,y. t, (t = 1, 2, …, T)是纵剖面上的一个时间序列(个体)。
图1 N=7,T=50的面板数据示意图例如1990-2000年30个省份的农业总产值数据。
固定在某一年份上,它是由30个农业总产总值数字组成的截面数据;固定在某一省份上,它是由11年农业总产值数据组成的一个时间序列。
面板数据由30个个体组成。
共有330个观测值。
对于面板数据y i t, i = 1, 2, …, N; t = 1, 2, …, T来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data)。
若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data)。
注意:EViwes 3.1、4.1、5.0既允许用平衡面板数据也允许用非平衡面板数据估计模型。
Panel Data模型的EViews操作过程两种模式:Ⅰ. 关于Panel工作文件;Ⅱ. 关于Pool对象。
数据的预处理1.在EXCEL文件中,将每个变量各年的原始数据按照年份顺序排成一列,称之为堆积数据(见表“汇总0”)。
2.输入截面单元的标识(表示地区的符号,前面加_;如:_HB、_NMG等)。
3.将数据表按照时间分类(即排序,见表“汇总”)。
Ⅰ. 关于Panel工作文件的操作过程案例1:我国农村居民消费函数(2000-2010年,27个省市数据,工作文件:NXF)一、输入数据1、创建Panel工作文件选择File / New / Workfile,在出现的创建工作文件对话框中:(1)在文件结构类型中,选择“平衡面板(Balanced Panel)”;(2)输入起始、终止期,截面单元个数。
2.更改截面标识(可以省略)序列crossid 中是以数字1、2、…标记截面标识,为了便于区分,可以重新定义一个字符串序列。
(1)点击object / New object ,选择series Alpha 并输入序列名(设为dq ); (2)双击dq 序列,在打开的序列窗口中粘贴截面标识的字符串序列;(3)双击工作文件窗口中的Range ,在弹出的对话框中,将截面标识的的ID 序列改成新的标识序列:dq3.输入数据键入命令:DATA Y X ,然后用复制+粘贴方式从Excel 文件中将各个变量的堆积数据(注意:数据事先要按照截面单元堆积,本例中是按照“地区”)复制到工作文件之中;此时工作文件中各个变量都是堆积数据。
工作文件中将生成分别表示截面标识和时期标识的两个序列:Crossid — 截面标识二、模型估计过程1.估计混合模型直接在命令窗口键入命令:LS Y C X2.估计变截距模型在方程窗口中点击Estimate按钮,在弹出的方程描述框中选择Panel Options选项卡,此时可以在截面和时期列表中选择None、Fixed、Random,用来选择单因素(或双因素)固定效应、随机效应变截距模型;同时可以选择GMM、GLS、SUR等估计方法。
eviews面板数据模型详解1.已知1996―2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996―2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费 CONSUMEAH CONSUMEBJ CONSUMEFJ CONSUMEHB CONSUMEHLJ CONSUMEJL CONSUMEJS CONSUMEJX CONSUMELN CONSUMENMG CONSUMESD CONSUMESH CONSUMESX CONSUMETJ CONSUMEZJ19961997199819992000200120023607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6 4248.47 4935.95 5181.45 5266.695638.74 6015.11 6631.68 3424.35 4003.71 3834.43 4026.34348.47 4479.75 5069.283110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32 3493.02 3719.91 3890.74 3989.93 4356.06 4654.42 5342.64 2767.84 3032.33105.74 3468.99 3927.75 4195.62 4859.885022104643770.99 4040.63 4143.96 4515.056763.12 6819.94 6866.41 8247.69 8868.19 9336.1 3035.59 3228.713267.7 3492.98 3941.87 4123.01 4710.964679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96 5764.27 6170.14 6217.93 6521.54 7020.22 7952.39 8713.08表9.2 1996―2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入 INCOMEAH INCOMEBJ INCOMEFJ INCOMEHB1996199719981999 5064.62000 5293.55 7432.26 5661.16 4912.88 4810 6800.23 5103.58 5357.79 5129.05 6489.97 4724.11 8140.5 9279.162001 5668.8 8313.08 5984.82 5425.87 5340.46 7375.1 5506.02 5797.01 5535.89 7101.08 5391.05 8958.72002 6032.4 9189.36 6679.68 6100.56 6260.16 8177.64 6335.64 6524.52 6051 7614.36 6234.36 9337.564512.77 4599.27 4770.477332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92 5172.93 6143.64 6485.63 6859.81 4442.81 4958.67 5084.64 5365.034268.5 6017.854595.14 6538.2INCOMEHLJ 3768.31 4090.72 INCOMEJL INCOMEJS INCOMEJX INCOMELN3805.53 4190.58 4206.64 4480.01 3780.2 4071.32 4251.42 4720.58 4207.23 4518.14617.24 4898.61INCOMENMG 3431.81 3944.67 4353.02 4770.53 INCOMESD INCOMESH INCOMESX INCOMETJ INCOMEZJ4890.28 5190.79 5380.08 5808.96 8178.48 8438.893702.69 3989.92 4098.73 4342.61 5967.71 6608.39 7110.54 7649.83 6955.79 7358.72 7836.76 8427.958773.1 10931.64 11718.01 12883.46 13249.810464.67 11715.6表9.3 1996―2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数 1996 PAH PBJ PFJ PHB PHLJ PJL PJS PJX PLN PNMG PSD PSH PSX PTJ PZJ19971998 1001999200020012002 99 98.2 99.5 99 99.3 99.5 99.2 100.1 98.9109.9 101.397.8 100.7 100.5 99.1 102.1 98.7 98.1 96.8 9899.7 100.5 98.3 100.8 98.6 101.3111.6 105.3 102.4 100.6 103.5 103.1 105.9 101.7 99.7 107.1 103.5 98.4 107.1 104.4 100.4 107.2 103.7 99.2 109.3 101.7 99.4 108.410210198.7 100.1 100.8 98.6 100.3 99.5 98.699.9100107.9 103.1 99.3 107.6 104.5 99.3 109.6 102.8 99.4 109.2 102.8100107.9 103.1 98.6 109103.1 99.599.8 101.3 100.6 100.2 99.3 100.2 101.8 101.5 102.510099.6 103.9 99.8 98.9 98.899.6 101.2 10199.899.3 100.5 98.4 99.6 99.1107.9 102.8 99.7(1)建立面板数据工作文件首先建立工作文件。